1. Introduction
Let us begin with a mantra: the weighting matrix, usually denoted by
W, is the most characteristic element in a spatial model. Most scholars agree with this commonplace. In fact, spatial models deal primarily with phenomena such as spillovers, trans-boundary competition or cooperation, flows of trade, migration, knowledge, etc. in complex networks. Rarely does the user know about how these events operate in practice. Indeed, they are mostly unobservable phenomena which are, however, required to build the model. Traditionally the gap has been solved by providing externally this information, in the form of a weighting matrix. As an additional remark, we should note that
is not the unique solution to deal with such kind of unobservables ([
1]; for example, develop a latent-variables approach that does not need
), but is the simplest.
Hays et al. [
2] give a sensible explanation about the preference for a predefined
. Network analysts are more interested in the formation of networks, taking units attributes and behaviors as given. This is spatial dependence due to selection, where relations of homophily and heterophily are crucial. The spatial econometricians are more interested in what they call
“computing the effects of alters actions on ego’s actions through the network”; in this case, the patterns of connectivity are taken as given. This form of spatial dependence is due to the influence between the individuals, and the notions of contagion and interdependence are capital. Therefore, if the network is predefined, why not supply it externally?
However, beyond this point, the
issue has been frequent cause of dispute. In the early stages, terms such as “join” or “link” were very common (for instance, in [
3], or [
4]). The focus at that time was mainly on testing for the presence of spatial effects, for which is not so important the specification of a very detailed weighting matrix; contiguity, nearness, rough measures of separation may be appropriate notions for that purpose. The work of Ord [
5] is a milestone in the evolution of this issue because of its strong emphasis on the task of modelling spatial relationships. It is evident that the weights matrix needs more attention if we want to avoid estimation biases and wrong inference. Anselin [
6] and Anselin [
7] puts the
matrix in the center of the debate about specification of spatial models, but, after decades of practicing, the question remains unclear.
The purpose of the so-called
is to “
determine which ... units in the spatial system have an influence on the particular unit under consideration ... expressed in notions of neighborhood and nearest-neighbor” relations, in words of Anselin [
6] (p.16) or “
to define for any set of points or area objects the spatial relationships that exist between them” as stated by Haining [
8] (p. 74). The problem is how should it be done.
Roughly speaking, we may distinguish two approaches: (i) specifying
exogenously; (ii) estimating
from data. The exogenous approach is by far the most popular and includes, for example, use of a binary contiguity criterion, k-nearest neighbors, kernel functions based on distance, etc. The second approach uses the topology of the space and the nature of the data, and takes many forms. We find ad-hoc procedures in which a predefined objective guides the search such as the maximization of Moran’s
I in Kooijman [
9] or the local statistical model of Getis and Aldstadt [
10]. Benjanuvatra and Burridge [
11] develop a quasi-maximum-likelihood,
, algorithm to estimate the weights in
assuming partial knowledge about the form of the weights. More flexible approaches are possible if we have panel information such as in Bhattacharjee and Jensen-Butler [
12] or Beenstock and Felsenstein [
13]. Endogeneity of the weight matrix is another topic introduced recently in the field (i.e., [
14]), which connects with the concept of
coevolution put forward by Snijders et al. [
15] and based on the assumption that in the long run, network connectivity must evolve endogenously with the model. Indeed, much of the recent literature on spatial econometrics revolves around endogeneity, but our contribution pertains to the exogenous approach where remains most part of the applied research.
Before continuing, we may wonder if the
issue, even in our context of pure exogeneity, is really a problem to worry for or it is the
biggest myth of the discipline as claimed by LeSage and Pace [
16]. Their argument is that only dramatic different choices for
would lead to significant differences in the estimates or in the inference. We partly agree with them in the sense that is a bit silly to argue whether it is better the 5 or the 6 nearest-neighbor matrix; surely there will be almost no difference between the two. However, there is consistent evidence, obtained mainly by studies of Monte Carlo [
17,
18,
19,
20] showing that the misspecification of
has a non-negligible impact on the inference of the coefficients of spatial dependence and other terms in the model. Moreover, the magnitude of the bias increases for the estimates of the marginal direct/indirect effects. Therefore, we disagree with the notion that ’
far too much effort has gone into fine-tuning spatial weight matrices’ as stated by LeSage and Pace [
16]. Our impression is that any useful result should be welcomed in this field and, especially, we need practical, clear guides to approach the problem.
Another question of concern are the criticisms of Gibbons and Overman [
21]. As said, it is common in spatial econometrics to assume that the weighting matrix is known, which is the cause of identification problems; this flaw extends to the instruments, moment conditions, etc. There is little to say in relation to this point. In fact, spatial parameters (i.e.,
) and weighting matrix,
, are only jointly identified (we do estimate
). Hays et al. [
2] and Bhattacharjee and Jensen-Butler [
12] agree on this point.
Bavaud [
22] (p. 153), given this controversial debate, was very skeptical, “
there is no such thing as “true”, “universal” spatial weights, optimal in all situations’ and continues by stating that the weighting matrix ’
must reflect the properties of the particular phenomena, properties which are bound to differ from field to field”. We share his skepticism; perhaps it would suffice with a “reasonable” weighting matrix, the best among those considered. In practical terms, this means that the problem of selecting a weighting matrix can be interpreted as a problem of model selection. In fact, different weighting matrices result in different spatial lags of the variables included in the model and different equations with different regressors amounts to a model selection problem.
As said, our intention is to offer new evidence to help the user to select the most appropriate
W matrix for the specification.
Section 2 revises four selection criteria that fit well into the problem of selecting a weighting matrix from among a finite set of them.
Section 3 presents the main features of the Monte Carlo experiment solved in the fourth section.
Section 5 includes a well-known case study which is revised in the light of our findings. The sixth section concludes.
2. Criteria to Select a W Matrix from among A Finite Set
A general spatial panel data econometric model, can be expressed as:
is a
vector of data for the explained variable in period
;
is a
matrix of observed data for the explicative variables, assumed exogenous, in period
t;
is a
vector of error terms in period
t and
a vector of random terms, assumed to be normally distributed (this assumption can be relaxed).
,
,
and
are unknown parameters; the last two parameters are called
spatial correlation parameters. Finally,
and
are two weighting matrices, specified exogenously, that channel the corresponding spill-over effects. Usually, the two matrices are forced to be equal. The model of (
1) is called a Cliff-Ord specification. A Spatial Durbin Model, SDM, results from
; a Spatial Lag Model, SLM, requires that
and
; a Spatial Durbin Error Model, SDEM,
and a Spatial Error Model, SEM, that
and
.
In view of model (
1), it is clear the critical importance played by the weighting matrices. We really need these matrices but there are few clues to build them in applied research; this results in the so-called
issue, partly review in the first section. In recent decades, a very interesting literature has appeared that examines the problem of choosing a matrix among a finite set of them, which is the target of this paper. First, we review the literature devoted to the
J test and then we move to the selection criteria, Bayesian methods and a new procedure based on entropy.
We should recognize that there are other interesting procedures in the literature, like, for example, the model boosting approach of Kostov [
23] and the model averaging of Zhang and Yu [
24], which are not used in our study for reasons of space or computational burden.
Anselin [
25] was the first to raise, formally, the
W issue, suggesting a
Cox statistic in a framework of non-nested models. Leenders [
26], on this basis, elaborates a
J-test using classical augmented regressions. Later, Kelejian [
27] extends the approach of [
26] to a
model, with spatial lags of the endogenous variable and in the error terms, using Generalized Method of Moments,
, estimates. Piras and Lozano [
28] confirm the adequacy of the
J-test to compare different weighting matrices stressing that we should make use of a full set of instruments to increase
accuracy. Burridge and Fingleton [
29] show that the Chi-square asymptotic approximations for the
J-tests produces irregular results, excessively liberal or conservative in a series of leading cases; they suggest a bootstrap resampling approach. Burridge [
30] focuses on the propensity of the spatial
algorithm to deliver spatial parameter estimates lying outside the invertibility region which, in turn, affects the bootstrap; he suggests the use of a
algorithm to remove the problem. Kelejian and Piras [
31] extended the original version of [
27] to account for all the available information, according to the findings of [
28]. Finally, Kelejian and Piras [
32] adapt the
J test to a panel data setting with unobserved fixed effects and additional endogenous variables which reinforces the adequacy of the
framework. Another milestone in the
J test literature is Hagemann [
33], who copes with the reversion problem originated by the lack of a well-defined null hypothesis in the test. He introduces the minimum
J test,
. His approach is based on the idea that if there is a finite set of competing models, only the model with the smallest
J statistic can be the correct one. In this case, the
J statistic will converge to the Chi-square distribution but will diverge if none of the models is correct. The author proposes a wild bootstrap to test if the model with the minimum
J is correct. This approach has been applied by Debarsy and Ertur [
20] to a spatial setting with good results.
In the Monte Carlo experiment that follows, we know that there is a correct model so are going to use only the first part of the procedure of [
33]. Assuming a collection of
M different weighting matrices, such as:
, the
approach works as follows:
We need the estimates of the
m models; in each case, the same equation is employed but with a different weighting matrix belonging to
. Following Burridge [
30] and given that our interest lies on the small sample case, the models are estimated by
.
For each model, we obtain the battery of J statistics as usual, after estimating, also by , the corresponding extended equations.
The chosen matrix is the one associated with the minimum J statistic. As said, we stop the procedure here, thus avoiding the wild bootstrap to test if this matrix is, indeed, the correct one.
Another popular method for choosing between models deals with the so-called
Information Criteria. Most are developed around a loss function, such as the
Kullback-Leibler,
, quantity of information which measures the closeness of two density functions. One of them corresponds to the true probability distribution that generated the data, obviously not known, the other is the distribution estimated from the data. The criteria differ in the role assigned to the aprioris and in the way of solving the approximation to the unknown true density function [
34]. The two most common procedures are the
[
35] and the Bayesian
criteria [
36]. The first compares the models on equal basis whereas the second incorporates the notion of model of the null. Both criteria are characterized by their lack of specificity in the sense that the selected model is the closest to the true model, as measured by
. We should note that as indicated by Potscher [
37], a good global fit does not necessarily mean that the model be the best alternative to estimate the parameters of interest.
and
lead to simple expressions that depend on the accuracy of the
estimation plus a penalty term related to the number of parameters entering the model; that is:
where
means the estimated log-likelihood at the
estimates,
,
k is the number of non-zero parameters in the model and
n the number of observations. For the case that we are considering the models only differ in the weighting matrix, so
k and
n are the same in every case. This means that the decision depends on the estimated log-likelihood or, what is the same, on the balance between the estimated variance and the Jacobian term. Please note that for a standard SLM, we can write:
, being
the standard deviation and
the corresponding spatial dependence coefficient. To minimize any of the two statistics in (
2) the objective is to maximize the concentrated estimated log-likelihood,
. In sum, the
Information Criteria approach implies:
Estimate by of the M models corresponding to each weighting matrix in .
For each model, we obtain the corresponding statistic ( produces the same results).
The matrix in the model with minimum statistic should be chosen.
An important part of the recent literature on spatial econometrics has Bayesian grounds, which extends also to the topic of choosing a weighting matrix. The Bayesian framework is well equipped to cope with these types of problems using the concept of
posterior probability as the basis for taking a decision. There are excellent reviews in [
38,
39,
40], Besag and Higdon [
41] and especially, [
42,
43,
44]. For the sake of completeness, let us highlight the main points in this approach.
The analysis is made conditional to a model, which is not under discussion. Moreover, we have a collection of
M weighting matrices in
, a set of
k parameter in
, some of which are of dispersion,
, others of position,
, and others of spatial dependence,
and
, and a panel data set with
observations in
y. The point of departure is the joint probability of data, parameters and matrices:
where
;
are the prior distributions and
the likelihood for
y conditional on the parameters and the matrix. Bayes’ rule leads to the posterior joint probability for matrices and parameters:
whose integration over the space of parameters,
, produces the posterior probability for matrix
:
The presence of spatial structures in the model complicates the resolution of (
5) which requires of numerical integration. The priors are always a point of concern and, usually, practitioners prefer diffuse priors. LeSage and Pace [
42] (Section 6.3) suggest
, a
conjugate prior for
and
where
, being
X the matrix of the exogenous variables in the model, and
an inverse gamma,
. For the parameter of spatial dependence, they suggest a
distribution, being
d the amplitude of the sampling space of
. The defaults in the
codes of LeSage [
45] are
,
and
. In brief, the
Bayesian approach implies the following:
This paper advocates for a selection procedure based on the notion of
entropy, which is used as a measure of the information contained in a distribution of probability. Let us assume a univariate continuous variable,
y, whose probability density function is
; then,
entropy is defined as:
being
I the domain of the random variable
y. As known, higher
entropy means less information and more uncertainty about
y. Our case fits with Shannon’s framework [
46]: we observe a random variable,
y, and there is a finite set of rival distribution functions capable of having generated the data. Our decision problem is well defined because each distribution function differs from the others only in the weighting matrix; the other elements are the same. However, we are not interested in the Laplacian principle of indifference (select the density with maximum
entropy, less informative, to avoid uncertain information). Quite the opposite: in our case there is no uncertain information and we are looking for the more informative probability distribution, so our objective is to minimize
entropy.
As with the other three cases, the application of this principle requires the complete specification of the distribution function, which means that the user knows the form of the model (Equations (
8)–(
10) below, except the
matrix); additionally we add a Gaussian distribution. Next, we should remind that for the case of a
multivariate normal random variable,
, the entropy is:
. This measure does not depend, directly, on first order moments (parameters of position of the model) but on second order moments (dependence and dispersion parameters). For example, in the case of the
of (
10) below, the entropy is:
where
. Please note that the covariance matrix for
y in the
is
. If
u is indeed a white noise random term with variance
, the covariance matrix of
y is simply
. Let us note that the covariance matrix of
y in the
of (
8) coincides with that of the
case. The covariance matrix for the
equation is
, everything else remains the same.
To apply the Entropy criterion we must go through the following steps:
Estimate each one of the M versions of the model that we are considering. As said, each model differs only in the weighting matrix. We obtain the estimates for reasons given above.
For each model, we obtain the corresponding value of the entropy, in the statistic.
The decision criterion consists in choosing the weighting matrix corresponding to the model with minimum value of entropy.
3. Description of the Monte Carlo Study
This part of the paper is devoted to the design of the Monte Carlo experiment conducted to calibrate the performance of the four criteria presented so far for selecting
: the
procedure, the
Bayesian approach, the
criterion and the
entropy measure. The objective of the analysis is to identify the most reliable method to select the most adequate weighting matrix for a spatial model, given the data of the variables and the form of the model itself. The parameters are also unknown for the user and must be estimated. In this context, if the matrix is misspecified, and the estimated parameters will be biased, which will impact the four criteria described in
Section 2 in different ways. Our Monte Carlo study generates sequences of data of the explained and explicative variables, for different scenarios, and applies the four criteria to select the (unknown)
W. Moreover, our focus is on small sample sizes. As will be clear soon, the four criteria have good behavior even in small samples, so it is not necessary to employ very large sample sizes.
We are going to simulate a panel setting, with three of the most common Data Generating Processes,
DGPs in what follows, in the applied literature on spatial econometrics; namely, the spatial Durbin Model,
of (
8), the Spatial Durbin Error Model,
in expression (
9) and the Spatial Lag Model of (
10),
. Main conclusions can be extended to other processes such as the Spatial Error Model, which are not replicated here (details on request from the authors).
Only one exogenous regressor, x variable, appears in the right hand side of the equations whose observations are obtained from a normal distribution, , where ; the same applies with respect to the error terms: , where . The two variables are not related, . Our space is made of hexagonal pieces which are arranged regularly, one next to the others without discontinuities nor empty spaces.
A weighting matrix appears in the three equations, which is not observable, and the user must take decisions to continue with the analysis. The problem consists in choosing one matrix from among a finite set of alternatives which in our simulation are composed by three candidates:
is built using the traditional contiguity criterion between spatial units; the weights in
are the inverse of the distance between the centroids of the spatial units,
; whereas
incorporates a cut-off point to the connections in
, so that
being
the set of 4 nearest neighbors to
i. To keep things simple, the same weighting matrix appears with the endogenous and exogenous variables in (
8) and with the exogenous and error terms in (
9). Following usual practice, every matrix has been row-standardized, which implies that the three matrices are non-nested. In what follows we will use
as the true matrix.
Three different small cross-sectional sample sizes, n, have been used ; that is enough because higher values of this parameter only improve marginally the results. For the same reason, the number of cross-sections in the panel, T, are limited to only three, . The values for the coefficient of spatial dependence, , ranges from negatives to positives, . Other global parameters are those associated with the constant term, , the x variable, , and its spatial lag, .
In sum, each case consists in:
Generate the data using a given weighting matrix, and a spatial equation, , , or . There are 216 cases of interest for each equation (6 values in , 3 values in n, 3 values in T, 2 values in and 2 values in ).
The spatial equation is assumed to be known so the model can be estimated by maximum likelihood, , once the user supplies a matrix.
Compute the four selection criteria, , Posterior probability, entropy and for the three alternative weighting matrices for each draw.
Select the corresponding matrix according to each criterion and compare the result with the true matrix () in the .
The process has been replicated 1000 times.
Please note that the selection of the matrix is made conditional on a correct specification of the equation. We are perfectly aware that this dichotomy is artificial; in fact, both decisions are intimately related because the same matrix, but in different equations, plays different roles and bears different information. However, this point is not further developed in the present paper. To give some intuition, we include the results corresponding to the case of a wrong specification (i.e., estimate a
model whereas the true model in the
is a
). MATLAB
® codes to replicate these simulations are freely downloadable from
https://sites.google.com/site/mherreragomez/principal/Codes.
4. Results of the Monte Carlo Study
This section summarizes the results obtained in the Monte Carlo simulation described previously and, we must admit, they are a bit surprising: in strictly quantitative terms, the
and the
entropy measures are the best criteria. What is more striking, according to our results the
Bayesian approach, although it does well in general, it is clearly the third criterion. Finally, the
approach is the worst alternative among the four candidates. The last two observations are puzzling given the strong support that the two procedures have received in recent decades.
Table 1 presents the percentage of correct selections attained by each criterion after aggregating all the cases in our simulation. Each percentage accumulates 126,000 items. A number in
bold indicates that the respective criterion reaches the maximum rate of correct selections.
dominates at the extremes of the range of values for the spatial dependence coefficient, whereas is the best for medium to low values of . The differences between the two are always lower to percentage points (in fact, the average proportion of correct selections is statistically equal with a confidence of 99%). is a good criterion for medium to large values of but its performance weakens for small values of this parameter (in fact, is fourth in ). Finally, the curve of correct selections of the is too flat.
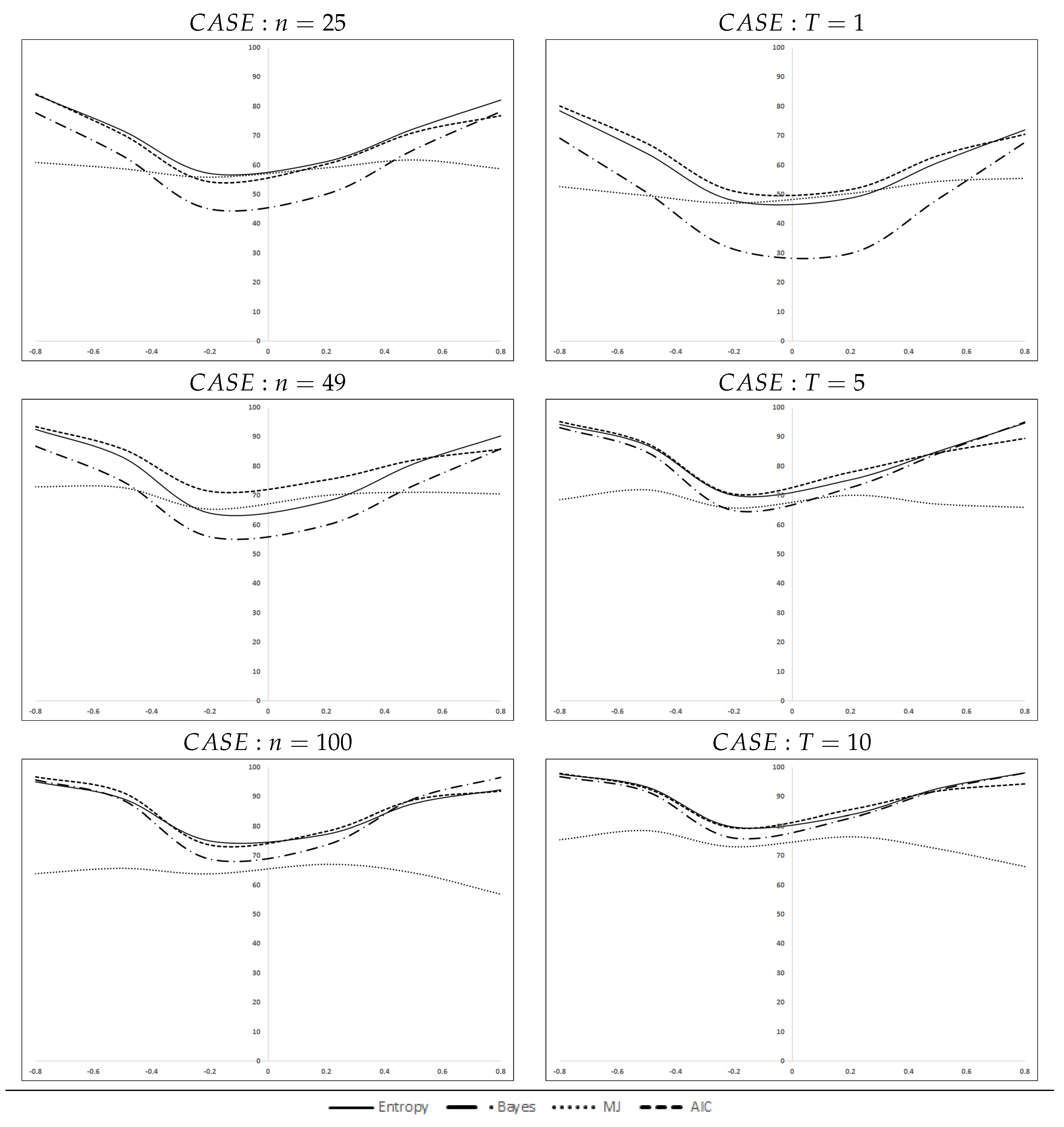
Figure 1 disaggregates the accumulated percentages by number of spatial units, left, or number of cross-sections, right. Please note that in each case, the data represent aggregated percentages (i.e., in the case
we aggregate the three cross-sections corresponding to
,
and
). These figures ratify the ordering set out above. The behavior of the
criterion is striking: its curves of correct selections are very flat, with unexpected drops at the extremes of the interval for
when the sample size (
n or
T) increases. The other three criteria, as expected, react positively to the sample size or to higher values of
. Apparently, the improvement is more relevant for the time dimension,
T, than for the cross-sectional size
n, especially for high values of the spatial coefficient. Finally, there is a certain asymmetry in all the curves.
Table 2,
Table 3,
Table 4 and
Table 5 present the details by type of
. A quick look at the tables reveals that bold percentages are concentrated, mainly, in the
entropy and
columns.
The prevalence of both criteria is quite regular for the four cases shown in the tables. The preference extends to the case of correctly specified models, as in
Table 2,
Table 3 and
Table 4, and also for misspecified equations, as in
Table 5, for negative and especially for positive values of the spatial coefficient, for small and large number of individuals in the sample (
n) and for simple to large panels (
T). Overall,
entropy attains the highest rate in
of the 144 cases in
Table 2,
Table 3,
Table 4 and
Table 5, followed by
,
,
Bayes,
, and
,
.
The complete relation of results for the 756 different experiments in the study of Monte Carlo (3
ns, 3
Ts, 6
s, 2
s, 2
s and four configurations for the DGP/estimated equation pair; note that the parameter
does not intervene in the SLM equation) appear in
Table A1–
Table A12 in the
Appendix. We want to stress the good results attained in the case of small samples (
and
) where the average rate of correct selections for
entropy and
is usually above
(a little worse for the other two criteria). Very often, the percentage exceeds
at the extremes of the spatial parameter interval,
. The average rate increases up to 75–80%, for the case of
and
and continues improving when
, where most cases have a rate of correct selections above
. In general, the rate of correct selections is nearly
, using 5 to 10 cross-sections.
In a similar vein, the increase in the cross-sectional size, n, when the number of cross-sections, T, remains constant also has positive effects in the four criteria. The rate of correct selections for the case of a hundred of spatial units is above , on average, for the case of a single cross-section (). These percentages improve quickly once the time dimension of the panel increases; it is also clear that the improvement depends on the type of DGP (stronger for SDM or SLM models and weaker for the SDEM and for the misspecified equation case).
The value of parameter , as expected, has only a slight impact in the four criteria; on the contrary, the signal of plays a crucial role in the and cases. Another interesting feature is the asymmetry of the selection curves that tends to be diluted with T. Negative spatial dependence helps to better detect the correct weighting matrix, especially when the number of time cross-sections is small. The asymmetry is evident in entropy, Bayes and , but it is more diffused in the case which remains highly inelastic to the value of .
To complete the picture, we estimate a
response-surface for each
/Estimated equation combination, with the aim of modelling the empirical probability of choosing the correct weighting matrix for each criterion,
. As usual, a logit transformation of the empirical probabilities is carried out, so the estimated equation is:
where
is the logit transformation, often known as the
logit,
r the number of replications of each experiment (1000 in all the cases);
assures that the
logit is defined even when the probability of correct selection is 0 or 1 [
47];
is an intercept term,
the design matrix whose columns reflect the conditions of each experiment,
is a vector of parameters and
the error term assumed to be independent and identically distributed (this assumption is reasonable if all experiments come from the same study, as ours, and are obtained under identical circumstances; [
48]). Recall that the number of observations in the
response-surface equations is 216 (so
), except for the SLM case where the number of observations is 108.
Table 6 shows the results for the four
/Estimated equation combinations.
In general, the estimates confirm previous facts. The main factor influencing the empirical probability of choosing the correct weights matrix is the spatial parameter, absolute value of
in
Table 6. Its contribution is crucial in all the cases, without exceptions, and occurs in the expected direction: higher values of
facilitate the selection of the correct weighting matrix. The second more influential factor is the parameter
, associated with spatial spillovers. Also, its impact is beneficial for all the cases though it appears to be more important for the
Bayesian and
criteria. Sample size is crucial and
T has a relatively higher impact than
n. Finally, as said before, parameter
is not significant in any circumstance, except for the
case; this means that the
signal-to-noise ratio should not be a major factor to consider when the problem is selecting the best weighting matrix.
Table 7 completes the
response-surface analysis with the
F tests of equality in the coefficients of the estimates of
Table 6. According to the sequence of
F tests, the most dissimilar method is the
approach, and then
Bayes. On the other hand,
entropy and
emerge as quasi-similar strategies to compare weighting matrices, almost indistinguishable in the four types of
.
5. Empirical Application: Ertur and Koch (2007)
The case study in this section is based on a well-known economic growth model estimated by Ertur and Koch (2007) using a cross-section of 91 countries for the period 1960–1995. The purpose of this section is to illustrate the use of the selection procedures discussed before.
Ertur and Koch [
49] build a growth equation to model technological interdependence between countries using spatial externalities. The main hypotheses of interaction are that the stock of knowledge in one country produces externalities that cross-national borders and spill over into neighboring countries, with an intensity which decreases with distance. The authors use a geographical distance measure.
The benchmark model assumes an aggregated Cobb-Douglas production function with constant returns to scale in labor and physical capital:
where
is output,
is the level of reproducible physical capital,
is the level of labor in the period
t, and
is the aggregate level of technology specified as:
The aggregate level of technology in a country i depends on three elements. First, a certain proportion of technological progress is exogenous and identical in all countries: , where is a constant rate of technological growth. Second, each country’s aggregate level of technology increases with the aggregate level of physical capital per worker with parameter capturing the strength of home externalities by physical capital accumulation. Finally, the third term captures the external effects of knowledge embodied in capital located in a different country, whose impact crosses national borders at a diminishing intensity, . The terms represent the connectivity between country i and its neighbors; these weights are assumed to be exogenous, non-negative, and finite.
Following Solow, the authors assume that a constant fraction of output
, in every country
i, is saved and that labor grows exogenously at the rate
. Also, they assume a constant and identical annual rate of depreciation of physical capital for all countries, denoted
(assumed as a constant value equal 0.05 in the literature). The evolution of output per worker in country
i is governed by the usual fundamental dynamics of the Solow equation which, after some manipulations, lead to a steady-state real income per worker [
49] (p. 1038, Equation (
9)):
This is a spatially augmented Solow model and coincides with the predictor obtained by Solow adding spill-over effects. In terms of spatial econometrics, we have a
Spatial Durbin Model,
, which can be expressed as:
Equation (
15) is estimated using information on real income, investment and population growth for a sample of 91 countries for the period
. Regarding the spatial weighting matrix, [
49] consider two geographical distance functions: the inverse of squared distance (which is the main hypothesis) and the negative exponential of squared distance (to check robustness in the specification). We also consider a third matrix based on the inverse of the distance.
Let us call the three weighting matrices as
,
and
which are row-standardized:
where:
with
as the great-distance (i.e., the shortest distance between two points on the surface of a sphere) between the capitals of countries
i and
j.
The authors analyze several specifications checking for different theoretical restrictions and alternative spatial equations. We concentrate our revision in the so-called non-restricted equation, in the sense that it includes more coefficients than advised by theory.
Table 8 presents the SDM version of this equation using the three alternative weighting matrices specified before (the first two columns coincide with those in Table I, columns 3–4, pp. 1047, of [
49]). The last four rows in the Table show the value of the selection criteria corresponding to each case.
The preferred model by [
49] is the
which coincides with the selection attained by minimum
entropy, the
Bayesian posterior probability and
. The selection of the
approach is
.
Other results in [
49] refer to the Spatial Error Model version of the steady-state equation of (
14), or
model. The intention of the authors is to visualize the presence of spatial correlation in the traditional non-spatial Solow equations; we use this case as an example of selection of weighting matrices in misspecified models. The main results appear in
Table 9 (which can be compared with columns 2–3 of Table II, in [
49] (p. 1048)).
The selection of the most adequate matrix does not change. Using the values of entropy criterion we select the model in which intervenes the matrix , the same as with the Bayesian approach and the criterion; continues selecting .
6. Conclusions
Much of the applied spatial econometrics literature seems to prefer an exogenous approximation to the matrix. Implicitly, it is assumed that the user has relevant knowledge with respect to the way individuals in the sample interact. In recent years, new literature advocates for a more data driven approach to the issue. We strongly support this tendency, which should be dominant in the future; however, our focus in this study is on the exogenous approach.
The problem posed in the paper is very frequent in applied work: the user has a finite collection of weighting matrices, they all are coherent with the case of study, and one needs to select one of them. Which is the best ? We can address this question using different proposals: the Bayesian posterior probability, the J approach with all its variants, by means of simple model selection criteria, such as or and several other alternatives not used in this study. We add a fourth one, based on the entropy of the estimated distribution function. This new criterion h(y) is a measure of uncertainty, and fits well with the decision problem. The h(y) statistics depends on the estimated covariance matrix of the corresponding model offering a more complete picture of the suitability of the distribution function (related to a particular choice of ), to deal with the data at hand.
The conclusions of our Monte Carlo experiment are very illuminating. First, we can confirm that it is possible to identify, with confidence, the true weighting matrix (if it really exists); in this sense, the selection criteria do a good job. However, the four criteria should not be taken as indifferent, especially in samples of small size (n or T). The ordering is clear: entropy and in first place and then Bayesian posterior probability doing slightly worse; the appears always in the last position. As shown in the paper, the value of the spatial parameter has a great impact to guarantee a correct selection, but this aspect is unobservable to the researcher. However, the user effectively controls the amount of information involved in the exercise, and this is also a key factor. The advice is clear: use as much information as you have because the quality of the decision improves with the amount of information. Once again, the way the information accrues is not neutral: the length of the time series in the panel is more relevant than the number of cross-sectional units in the sample.
Our final recommendation for applied researchers is to care for the adequacy of the weighting matrix and, in case of having various candidates, take a decision using well-defined criteria such as those examined in the paper. The case of study presented in
Section 5 illustrates the procedure.
As avenues for future research, let us mention the possibility of combining different matrices into a single one, as pursued in model averaging or in fuzzy logic, which offers new, flexible alternatives. Moreover, this study assumes that the user knows the form of the equation which is, very often, an unrealistic assumption. This constraint poses new challenges and can be solved by using a more general framework where both the model and the matrix should be chosen. It is clear that not all the four criteria are well equipped to work in the new scenarios.



{kind=link}
