1. Introduction
In recent years, we have observed rapid advancements in the fields of machine learning and quantum computation. An increasing number of researchers is looking at challenges emerging at the intersection of these two fields, from quantum annealing as an alternative to classical simulated annealing [
1,
2] to quantum parallelism as a source of algorithmic speedup [
3,
4]. Quantum walks [
5,
6], the quantum mechanical analogue of classical random walks, have been shown to provide the potential for exponential speedups over classical computation, in part thanks to an array of exotic properties not exhibited by their classic counterpart, such as interference. The rising popularity of quantum walks can be further understood by looking at the work of Childs [
7], who showed that any quantum computation can be efficiently simulated by a quantum walk on a sparse and unweighted graph, thus elevating quantum walks to the status of universal computational primitives.
In machine learning and pattern recognition, graphs are used as convenient representations for systems that are best described in terms of their structure and classical random walks have been repeatedly and successfully used to analyse such structure [
8,
9,
10,
11,
12]. Indeed, the rich expressiveness of these representations comes with several issues when applying standard machine learning and pattern recognition techniques to them. In fact, these techniques usually require graphs to be mapped to corresponding vectorial representations, which in turn needs a canonical node order to be established first. Graphs with different number of nodes and edges present yet another challenge, as the dimension of the embedding space depends on this information. In this context, classical random walks provide an effective way to compute graph invariants that can be use to characterise their structure and embed them into a vectorial space [
13,
14].
Classical random walks have also been used to successfully define graph kernels [
9,
12,
15,
16,
17,
18]. Graph kernels offer an elegant way to transform the problem from that of finding an explicit permutation invariant embedding to that of defining a positive semi-definite pairwise kernel measure. One can then choose between an array of different kernel methods, the best known example being support vector machines (SVMs) [
19], to solve the pattern analysis task at hand. This is based on the well-known kernel trick. Given a set
X and a positive semi-definite kernel
, there exists a map
into a Hilbert space
H, such that
for all
. Thus, any algorithm that can be formulated in terms of scalar products of the
’s can be applied to a set of data (e.g., vectors, graphs) on which a kernel is defined. In the case of graphs, examples of kernels include the shortest-path kernel [
15], the graphlet kernel [
20], and the Weisfeiler-Lehman subtree kernel [
16]. The common principle connecting these kernels is that of measuring the similarity between two graphs in terms of the similarity between simpler substructures (e.g., paths, subgraphs, subtrees) contained in the original graphs. When the substructures used to decompose the graphs are classical random walks, we obtain kernels like the random walk kernel [
9] or the Jensen-Shannon kernel [
12]. The kernel of Gärtner et al. [
9] counts the number of matching random walks between two graphs while using a decay factor to downweigh the contribution of long walks to the kernel. The kernel of Bai and Hancock [
12], on the other hand, is based on the idea of using classical random walks to associate a probability distribution to each graph and then use the Jensen-Shannon divergence [
21,
22] between these distributions as a proxy for the similarity between the original graphs.
The quantum analogue of the Jensen-Shannon divergence (QJSD) [
23] allows to extend the Jensen-Shannon divergence kernel [
12] to the quantum realm [
17,
18]. While the classical Jensen-Shannon divergence is a pairwise measure on probability distributions, the QJSD is defined on quantum states. As its classical counterparts, the QJSD is symmetric, bounded, always defined, and it has been proved to be a metric for the special case of pure states [
23,
24]. Unfortunately, there is no theoretical proof yet that the same holds for mixed states. Inspired by this quantum divergence measure, Rossi et al. [
18] and Bai et al. [
17] have proposed two different graph kernels based on continuous-time quantum walks. While the kernel of Bai et al. was proved to be positive semi-definite [
17], it has several drawbacks compared to [
18] (for which the positive semi-definiteness has not been proved yet), most notably the need to compute the optimal alignment between the input graphs before the quantum walk-based analysis can commence. Rossi et al. [
18], on the other hand, are able to avoid this by exploiting the presence of interference effects. Given a pair of input graphs, their method establishes a complete set of connections between them and defines the initial states of two walks on this structure so as to highlight the presence of structural symmetries [
18,
25]. However the analysis of Rossi et al. [
18] is limited to the case of undirected graphs and, as mentioned, it falls short of proving the positive semi-definiteness of the kernel.
In this paper, we address these issues in the following way:
We define a novel kernel for directed graphs based on [
18] and the work of Chung [
26] on directed Laplacians;
We extend the work of [
18] by incorporating additional node-level topological information using two well-known structural signatures, the Heat Kernel Signature [
27] and the Wave Kernel Signature [
28];
We give a formal proof of the positive definiteness of the undirected kernel for the case where the Hamiltonian is the graph Laplacian and the starting state satisfies several constraints;
We propose a simple yet efficient quantum algorithm to compute the kernel;
We perform an empirical comparison of the performance of the kernel for both directed and undirected graphs and for different choices of the Hamiltonian.
We perform an extensive set of experimental evaluations and we find that:
Adding the edge directionality information allows to better discriminate between the different classes, even when compared with other commonly used kernels for directed graphs;
In most cases the incorporation of the node-level topological information results in a significant improvement over the performance of the original kernel;
The optimal Hamiltonian (in terms of classification accuracy) depends on the dataset, as already suggested in [
18];
The constraints we enforce to ensure the positive definiteness of the kernel disrupt the phase of the initial state, leading to a decrease in classification accuracy.
The remainder of this paper is organised as follows.
Section 2 reviews the fundamental concepts of graph theory and quantum mechanics needed to understand the present paper.
Section 3 introduces the quantum-walk based similarity measure, analyses it from a theoretical perspectives, and illustrates how it can be adapted to work on both undirected and directed graphs. Finally,
Section 4 discusses the results of our experimental evaluation and
Section 5 concludes the paper.
3. Graph Similarity from Quantum Walks
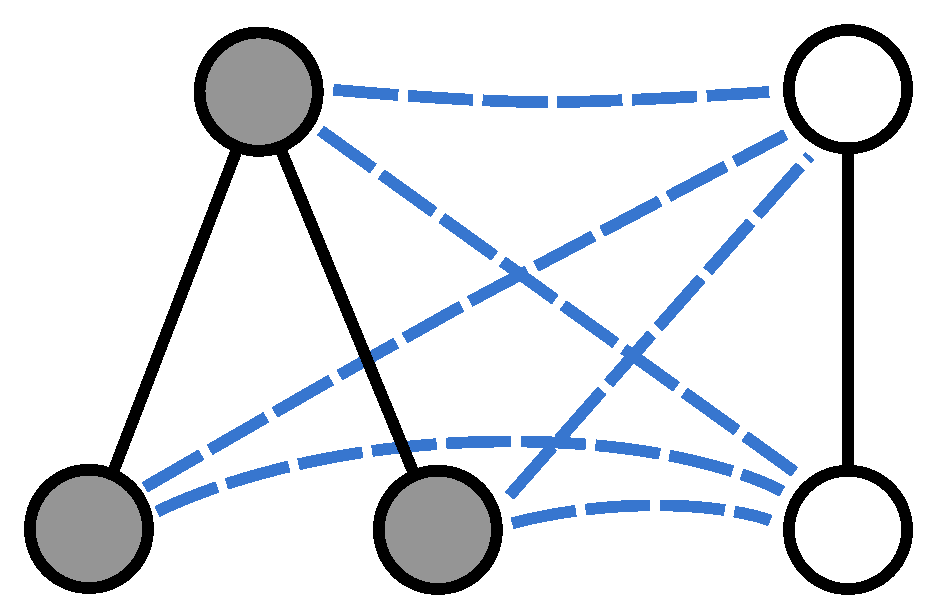
Given two undirected graphs
and
, we merge them into a larger structure by establishing a complete set of connections between the two node sets. More specifically, we construct a graph
where
,
, and
only if
and
.
Figure 1 shows an example pair of graphs and their union.
The intuition of Rossi et al. [
18] was to define two mixed quantum states on this new graph describing the time-evolution of two quantum walks specifically designed to amplify constructive and destructive interference effects. To this end, we define two independent quantum walks with starting states
We can then associate the following quantum states to the graph,
Given these two states, we finally make use of the QJSD to compute the similarity between the input graphs in terms of the dissimilarity between the
and
, i.e.,
Since the quantum states
and
represent the evolution of two quantum walks that emphasize destructive and constructive interference, respectively, we expect that the more similar the input graphs are, the more dissimilar
and
are. In the extreme case where
and
and isomorphic, it can be shown that
[
18].
In [
18], the authors suggest to consider the limit of
for
, which in turn allows to rewrite Equation (
11) as
where
is the set of distinct eigenvalues of the Hamiltonian
, i.e., the eigenvalues
with multiplicity
, and
is the projection operator on the subspace spanned by the
eigenvectors
associated with
. Similarly, one can work out the limit of
for
. This in turn has the effect of making the computation of the kernel easier in addition to allowing us to drop the time parameter
T, yielding
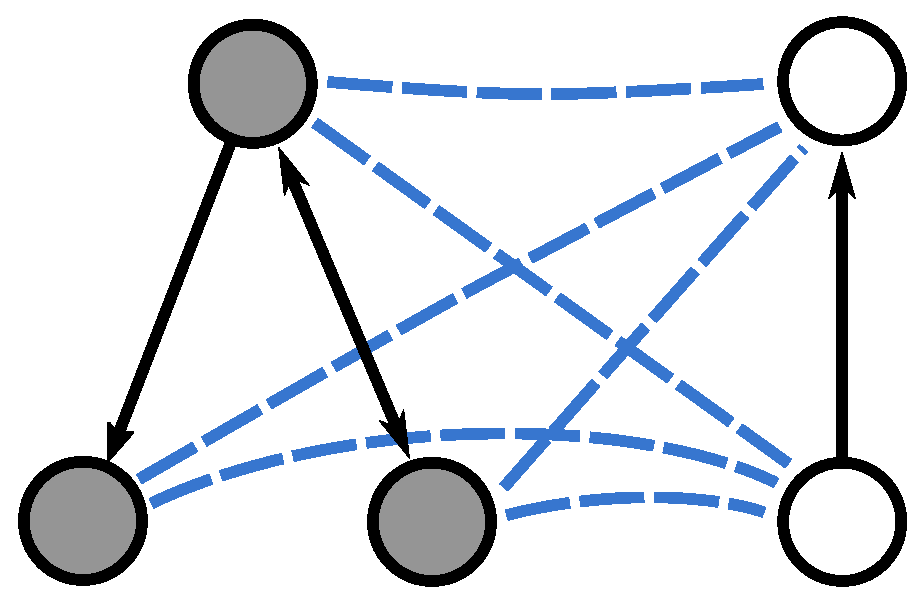
3.1. Extension to Directed Graphs
The kernel described in the previous subsection can only be computed for undirected graphs. In order to cope with directed graphs, we propose using the directed graph Laplacian introduced by Chung [
26]. We first merge the two directed input graphs
and
as done in the undirected case, i.e., we create a complete set of undirected edges connecting the nodes of
to the nodes of
. Note, however, that the resulting merge graph is directed, as a consequence of the edges in
and
being directed (see
Figure 2). Hence we define the starting states
and
similarly to Equation (
10), but using the out degree instead:
To compute the Hamiltonian and thus and , we proceed as follows. Let us define the classical random walk transition matrix M for the directed graph G as the matrix with elements , where we use the convention that when the out-degree of u is zero, i.e., , we let .
From the Perron-Frobenius theorem we know that for a strongly connected directed graph, i.e., a directed graph where there exists a path between every pair of vertices and there are no sinks, the transition matrix
M has a unique non-negative left eigenvector
[
32], i.e.,
, where
is the eigenvalue associated with
. According to the Perron-Frobenius theorem, if
M is aperiodic we also have that
, and thus
, implying that the random walk on the directed graph
G with transition matrix
M will converge to a stationary probability distribution.
Let
be the diagonal matrix with the elements of
on the diagonal. Then Chung [
26] defines the Laplacian matrix of the directed graph
G as
Similarly, the normalised Laplacian of
G is defined as
where
I denotes the identity matrix.
Please note that while the adjacency matrix of a directed graph is clearly not Hermitian, both the normalised Laplacian and the Laplacian defined in Equations (
16) and (
17) are symmetric and thus can used as the Hamiltonian governing the quantum walks evolution. An alternative to this would have been to symmetrize the graph edges effectively making the graph undirected, however as we will show in the experimental part this causes the loss of important structural information.
We would like to stress that the method of Chung [
26] is not the only way to associate a (normalised) Laplacian matrix to a directed graph. We are aware of at least one different method proposed by Bauer [
33]. However we decide to focus on the definition proposed by Chung [
26] as this has been successfully applied to the analysis of directed graphs in pattern recognition and network science [
34,
35,
36].
3.2. Integrating Local Topological Information
In [
31] it was shown that for the case of undirected attributed graphs
and
, where
is a function assigning attributes to the nodes of the graph
, it is possible to effectively incorporate the information on the pairwise similarity between the attributes of the two graphs by allowing the adjacency matrix of the merged graph to be weighted. More specifically, for each
and
, the authors proposed to label the edge
with a real value
representing the similarity between
and
.
While in this paper we only deal with unattributed graphs, we propose using a similar method to incorporate additional node-level structural information into the kernel. More specifically, given an undirected graph
and a node
, we capture the structure of the graph from the perspective of
v using two well known spectral signatures based on the graph Laplacian, the Heat Kernel Signature (HKS) [
27] and the Wave Kernel Signature (WKS) [
28]. The signatures simulate a heat diffusion and wave propagation process on the graph, respectively. The result is in both cases a series of vectors characterising the graph topology centered at each node. In graph matching, particularly in computer vision applications [
27,
28], this is used to match pairs of nodes with similar (in an Euclidean sense) vectorial representations under the assumption that these describe structurally similar nodes in the original graph.
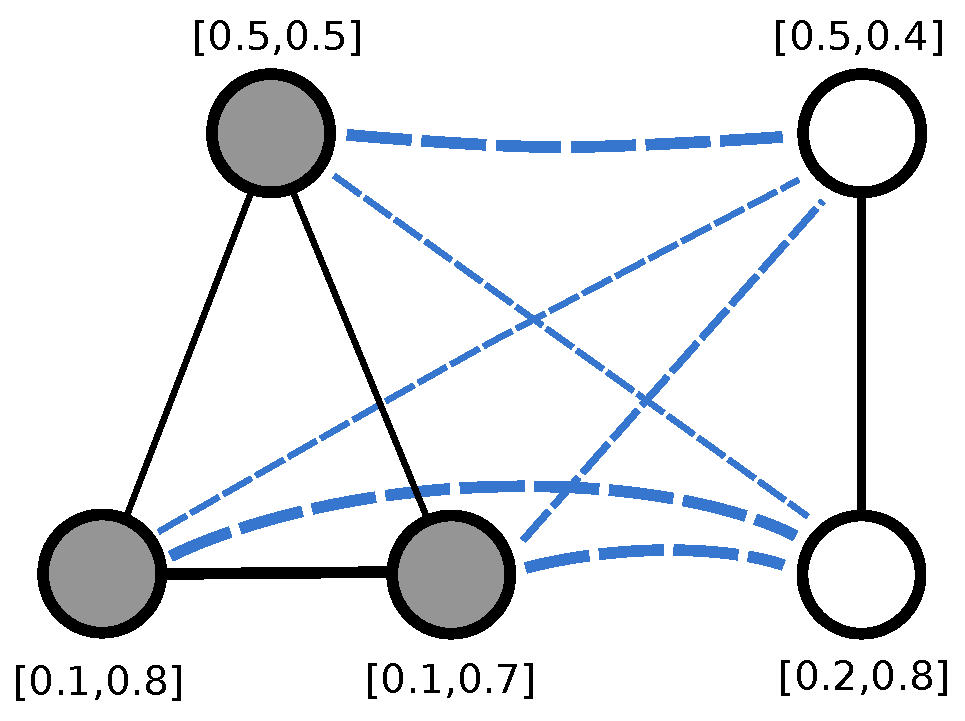
Given two nodes
, we compute their spectral signatures
and
using either HKS or WKS and we label the edge
with the real value
Please note that the signatures are computed on the original graphs, not on the merged one. Then the adjacency matrix of the graph obtained by merging
and
becomes
Figure 3 shows an example of two graphs with 2-dimensional signatures and their merged graph. For ease of presentation, the weight of each edge is shown by varying its thickness, i.e., the thicker the edge the higher the weight and the more similar the signatures of the connected nodes. Here we decided to compute the similarity between each pair of nodes in
, effectively turning
and
into two weighted cliques, i.e., complete weighted graphs, where the weights on the edges encode the pairwise nodes similarity. While at first sight it may seem like we are discarding the original structure of
and
, note that this is actually encoded in the node signatures and thus the edge weights. In
Section 4 we run an extensive set of experiments to determine if integrating node-level structural information improves the ability of the kernel to distinguish between structurally similar graphs.
3.3. Kernel Properties
Consider a pair of graphs
and
, with
n and
m nodes respectively. Here we consider the case where we take the graph Laplacian to be the Hamiltonian of the system and we assume that the input graphs are undirected. Let
and
be the Laplacian of
and
respectively. Then the Laplacian of the merged graph is
We can provide a full characterization of the eigensystem of L. Let and be eigenvectors of and , respectively, with corresponding eigenvalues v and w. Further, assume that and are not Fiedler vectors, i.e., and . Then is an eigenvector of L with eigenvalue and is an eigenvector of L with eigenvalue . The remaining eigenvectors of L are of eigenvalue 0 and of eigenvalue . In the following, we will denote with the orthogonal projector on the eigenspace of of eigenvalue , if is an eigenvalue of , 0 otherwise. For the special case of the 0 eigenspace, we eliminate the constant eigenvector . is similarly defined for .
Under this eigendecomposition we can write
and
as the following sums of rank-1 matrices:
with the eigenvalues of
L being
. Similarly,
Please note that each matrix in the summation is a rank-1 matrix and the matrices are orthogonal to each other as a consequence of the projectors being orthogonal to each others. This in turn implies that the size of the spectra of
and
is the same and it is equal to the number of distinct eigenvalues in
. More precisely, for each
, excluding those derived from the two Fiedler vectors of
and
, there exists a non-zero eigenvalue of both
and
of the form
In addition, we have two eigenvalues of the form
for
, and
for
.
In other words the two density matrices, despite having different eigenspaces, have identical spectra induced from the eigenspaces orthogonal to the Fiedler vector and differ only in the values due to the extremal eigenvalues of L.
Turning our attention to the arithmetic mean of the two density matrices in Equation (
14), we have
Again, this is a summation of rank-1 matrices orthogonal to one-another, resulting in eigenvalues of the form
corresponding to the (distinct) eigenvalues of
and
, respectively, excluding the eigenspace component induced by the Fiedler vectors, as well as the two eigenvector from the extremal eigenvalues of
LLet us define the function
We can now compute the QJSD kernel between the graphs
and
as
Assuming that the initial states are normalised in such a way that
and
, the last terms disappear and we have
This leads us to the following final observation. Let
and
be two discrete distributions with values in
and
, respectively, defined as
where
is the Dirac delta function. Then we have
where
denotes the classical Jensen-Shannon divergence. Now we can prove the following:
Theorem 1. Using the Laplacian as the Hamiltonian and normalizing and such that and , then the quantum Jensen-Shannon kernel is positive definite.
Proof. The proof descends directly from the derivations above and from the fact that the classical Jensen-Shannon divergence is conditionally negative-definite [
37]. □
3.4. Kernel Computation
The issue of efficiently computing the QJSD kernel is that of computing the entropies of
,
, and of their mean. Here we will discuss a general quantum approach to estimate the entropy of an infinite-time average mixing matrix starting from a pure state. Following [
18], we write the infinite-time average mixing matrix as
where
is the Hamiltonian and
is the projector onto its
eigenspace. If
is a pure state, then the eigenvectors corresponding to non-zero eigenvalues of
are of the form
for
, and the corresponding eigenvalues are
We already used this property in the previous section for the special case of the graph Laplacian as the Hamiltonian, but it holds in general.
It is important to note that the lambdas here are energy levels of the system, i.e., possible observed values using the Hamiltonian as an observable, and the probability of observing an energy state from the state is . This means that the von Neumann entropy of is equivalent to the classic Shannon entropy of the energy levels of the (pure) initial state, i.e., the entropy of the possible observations from the pure initial state using the Hamiltonian as the observable.
The quantum algorithm to estimate the von Neumann entropy of the infinite-time average mixing matrix
is as follows. First, we create several systems in the initial pure state
and we observe their energy using
as the observable. Then we use any entropy estimator for finite (discrete) distributions, using the energies as samples. Algorithms such as [
38] or [
39] are particularly interesting because they work well in the under-sampled case.
In the special case considered in Theorem 1, we can make the estimation even more efficient noting that we can observe independently from and , and in particular we can perform a single set of observation for each graph and reuse them in every pairwise computation for the kernel. In this case, the samples from the first graph are used to estimate the entropy , the samples from the second graph are used to estimate , and the two sample-sets are merged to estimate .
4. Experiments
In this section, we evaluate the accuracy of the proposed kernel in several classification tasks. Our aim is to investigate (1) the importance of the choice of the Hamiltonian; (2) the integration of node-level structural signatures; and (3) the ability to incorporate edge directionality information using the Laplacians proposed by Chung [
26]. To this end, we make use of the following datasets of undirected graphs (see
Table 1):
MUTAG [
40] is a dataset consisting originally of 230 chemical compounds tested for mutagenicity in Salmonella typhimurium [
41]. Among the 230 compounds, however, only 188 (125 positive, 63 negative) are considered to be learnable and thus are used in our simulations. The 188 chemical compounds are represented by graphs. The aim is predicting whether each compound possesses mutagenicity.
PPIs (Protein-Protein Interaction) is a dataset collecting protein-protein interaction networks related to histidine kinase [
42] (40 PPIs from Acidovorax avenae and 46 PPIs from Acidobacteria) [
43]. The graphs describe the interaction relationships between histidine kinase in different species of bacteria. Histidine kinase is a key protein in the development of signal transduction. If two proteins have direct (physical) or indirect (functional) association, they are connected by an edge. The original dataset comprises 219 PPIs from 5 different kinds of bacteria with the following evolution order (from older to more recent): Aquifex 4 and Thermotoga 4 PPIs from Aquifex aelicus and Thermotoga maritima, Gram-Positive 52 PPIs from Staphylococcus aureus, Cyanobacteria 73 PPIs from Anabaena variabilis and Proteobacteria 40 PPIs from Acidovorax avenae. There is an additional class (Acidobacteria 46 PPIs) which is more controversial in terms of the bacterial evolution since they were discovered.
PTC (Predictive Toxicology Challenge) dataset records the carcinogenicity of several hundred chemical compounds for Male Rats (MR), Female Rats (FR), Male Mice (MM) and Female Mice (FM) [
44]. These graphs are very small and sparse. We select the graphs of Male Rats (MR) for evaluation. There are 344 test graphs in the MR class.
COIL Columbia Object Image Library consists of 3D objects images of 100 objects [
45]. There are 72 images per object taken in order to obtain 72 views from equally spaced viewing directions. For each view a graph was built by triangulating the extracted Harris corner points. In our experiments, we use the gray-scale images of five objects.
NCI1 The anti-cancer activity prediction dataset consists of undirected graphs representing chemical compounds screened for activity against non-small cell lung cancer lines [
46]. Here we use only the connected graphs in the dataset (3530 out of 4110).
We also make use of the following directed graphs datasets:
Shock The Shock dataset consists of graphs from a database of 2D shapes [
47]. Each graph is a medial axis-based representation of the differential structure of the boundary of a 2D shape. There are 150 graphs divided into 10 classes, each containing 15 graphs. The original version contains directed trees each with a root node, the undirected version has been created by removing the directionality.
Alzheimer The dataset is obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) [
48] and concerns interregional connectivity structure for functional magnetic resonance imaging (fMRI) activation networks for normal and Alzheimer subjects. Each image volume is acquired every two seconds with blood oxygenation level dependent signals (BOLD). The fMRI voxels here have been aggregated into larger regions of interest (ROIs). The different ROIs correspond to different anatomical regions of the brain and are assigned anatomical labels to distinguish them. There are 96 anatomical regions in each fMRI image. The correlation between the average time series in different ROIs represents the degree of functional connectivity between regions which are driven by neural activities [
49]. Subjects fall into four categories according to their degree of disease severity:
AD—full Alzheimer’s (30 subjects),
LMCI—Late Mild Cognitive Impairment (34 subjects),
EMCI—Early Mild Cognitive Impairment (47 subjects),
HC—Normal Healthy Controls (38 subjects). The LMCI subjects are more severely affected and close to full Alzheimerś, while the EMCI subjects are closer to the healthy control group (Normal). A directed graph with 96 nodes is constructed for each patient based on the magnitude of the correlation and the sign of the time-lag between the time-series for different anatomical regions. To model causal interaction among ROIs, the directed graph uses the time lagged cross-correlation coefficients for the average time series for pairs of ROIs. We detect directed edges by finding the time-lag that results in the maximum value of the cross-correlation coefficient. The direction of the edge depends on whether the time lag is positive or negative. We then apply a threshold to the maximum values to retain directed edges with the top 40% of correlation coefficients. This yields a binary directed adjacency matrix for each subject, where the diagonal elements are set to zero. Those ROIs which have missing time series data are discarded. In order to fairly evaluate the influence caused by edges directionality, an undirected copy has been created as well. In particular, let
be the adjacency matrix of a directed graph. Then its projection over the symmetric matrices space will be given by
.
4.1. Experimental Framework
With these datasets to hand, we aim to solve a graph classification task using as binary C-Support Vector Machine (C-SVM) [
19]. We perform 10-fold cross validation, where for each sample we independently tune the value of
C, the SVM regularizer constant, by considering the training data from that sample. The process is averaged over 100 random partitions of the data, and the results are reported in terms of average accuracy ± standard error. Recall that in classification tasks, the accuracy is intended as the fraction of the data occurrences that are assigned the correct class label. In our case, an occurrence is a graph. Moreover, we contrast the performance of the kernel with that of other well-established alternative graph kernels, namely the shortest-path kernel [
15] (
), the classic random walk kernel [
9] (
) and the the Weisfeiler-Lehman subtree kernel [
16] (
).
We divide our experiments into two parts. We first evaluate the influence of the Hamiltonian on the classification accuracy, where the Hamiltonian is chosen to be one between (1) the adjacency matrix (
); (2) the Laplacian (
); or (3) the normalised Laplacian of the graph (
). Here we also consider the positive definite version of the kernel discussed in
Section 3.3 (
). In the same experiment, we test if the addition of node signatures benefits the kernel performance, where the signature is either the (1) HKS or the (2) WKS, denoted as
and
respectively. In the second experiment we test the performance of our kernel for the classification of directed graphs. Please note that all the alternative kernels we consider are also able to cope with directed graphs. Here we test both our competitiveness against these kernels as well as the increase or decrease in performance compared to the case where we remove the edge directionality information.
4.2. Undirected Graphs
Table 2 shows the results of the classification experiments on undirected graphs. The best and second best performing kernels are highlighted in bold and italic, respectively. While the kernels based on the quantum Jensen-Shannon divergence yield the highest accuracy in 4 out of 5 datasets, it is clear that no specific combination of Hamiltonian and structural signatures is optimal in all cases. However, we observe that with the exception of the PPI dataset, both the choice of the Hamiltonian and the use or not of structural signatures has little or no impact on the performance of the kernel, which remains highly competitive when compared to the shortest-path, random walks, graphlet, and Weisfeiler-Lehman kernels. The performance gain is particularly evident when compared to the kernel based on classical random walks, which is consistently outperformed by the kernels based on quantum walks. This in turn is a confirmation of the increased ability of capturing subtle structural similarities of quantum walks with respect to their classical counterpart, as well as a clear statement of the robustness of the proposed kernel to the choice of its parameters. We do observe a tendency of the Laplacian + WKS combination to perform better on datasets with average graph size >100 (PPI and COIL), however this would need more extensive experiments to be validated.
We would like to stress that there are indeed alternative strategies to the one proposed in
Section 3.2 to integrate the node signatures information. For example, instead of creating a pair of weighted cliques, one could retain the original graphs structure and compute the similarity only between nodes connected by edges in
,
, and
. Another approach could have been to restrict the weighting only to the edges in
, similarly to what done by Rossi et al. in [
31]. However we found little or no difference in terms of classification accuracy between these alternative solutions and thus we decided to omit these results for ease of presentation.
Finally, the performance of the positive definite kernel
deserves a closer inspection. In contrast to the other quantum-walk based kernels, in this case the performance is often significantly lower and the dependency on the addition of the node-level structural signatures higher. Unlike the other kernels, in this case we had to enforce several constraints on the initial state in order to guarantee the positive definiteness of the resulting kernel (see
Section 3.3). However one of this constraints, i.e., the requirement that the two parts of the initial amplitude vector corresponding to
and
both sum to zero, causes the phase of the initial state to differ from that of the other kernels. While the initial states defined in Equation (
10) are such that
has equal phase on both
and
, while
has opposite phase on
and
, enforcing the constraint of
Section 3.3 leads to a change of sign (and thus of phase) for the smallest (in absolute value) components of the initial state. This in turn invalidates the assumption that
and
are designed to stress constructive and destructive interference, respectively, and thus affects the ability of the kernel to distinguish between similar/dissimilar graphs.
4.3. Directed Graphs
Table 3 shows the results of the classification experiments on directed graphs. We compare the kernels on the two directed graphs dataset, as well as their undirected versions, and we highlight again the best performing kernel for each dataset. Please note that when the graphs are directed we cannot choose the (potentially asymmetric) adjacency matrix as the Hamiltonian. We first observe that preserving the edge directionality information leads to a higher or similar classification accuracy for most kernels, with the exception of the shortest-path kernel on the Shock dataset. Please note that the graphs in this dataset are trees, and as such in the directed version there may be pairs of nodes for which a shortest-path does not exist, leading to the observed decrease in classification performance. In general, we observe that both in the directed and undirected case our kernel is the best performing, with the normalised Laplacian being the Hamiltonian that leads to the highest classification accuracy in 3 out of 4 datasets.





{kind=link}
{kind=link}
{kind=link}