In this section we describe the Hellinger distance-based methodology as applied to the compressed data. Since we are seeking to model the streaming independent and identically distributed data, we denote by J the number of observations in a fixed time-interval (for instance, every ten minutes, or every half-hour, or every three hours). Let B denote the total number of time intervals. Alternatively, B could also represent the number of sources from which the data are collected. Then, the incoming data can be expressed as . Throughout this paper, we assume that the density of belongs to a location-scale family and is given by , where . A typical example is a data store receiving data from multiple sources, for instance financial or healthcare organizations, where information from multiple sources across several hours are used to monitor events of interest such as cumulative usage of certain financial instruments or drugs.
3.2. Hellinger Distance Method for Compressed Data
In this section, we describe the Hellinger distance-based method for estimating the parameters of the location scale family using the compressed data. As described in the last section, let be a doubly indexed collection of independent and identically distributed random variables with true density . Our goal is to estimate using the compressed data . We re-emphasize here that the density of depends additionally on , the variance of the sensing random variables .
To formulate the Hellinger-distance estimation method, let
be a class of densities metrized by the
distance. Let
be a parametric family of densities. The Hellinger distance functional
T is a measurable mapping mapping from
to
, defined as follows:
When , then under additional assumptions . Since minimizing the Hellinger-distance is equivalent to maximizing the affinity, it follows that
It is worth noticing here that
To obtain the Hellinger distance estimator of the true unknown parameters , expectedly we choose the parametric family to be density of and to be a non-parametric consistent estimator of . Thus, the MHDE of is given by
In the notation above, we emphasize the dependence of the estimator on the variance of the projecting random variables. We notice here that the solution to (1) may not be unique. In such cases, we choose one of the solutions in a measurable manner.
The choice of the density estimate, typically employed in the literature is the kernel density estimate. However, in the setting of the compressed data investigated here, there are S observations per group. These S observations are, conditioned on independent; however they are marginally dependent (if ). In the case when , we propose the following formula for . First, we consider the estimator
With this choice, the MHDE of is given by, for ,
The above estimate of the density chooses observation from each group and obtains the kernel density estimator using the B independent and identically distributed compressed observations. This is one choice for the estimator. Of course, alternatively, one could obtain different estimators by choosing different combinations of observations from each group.
It is well-known that the estimator is almost surely consistent for as long as and as . Hence, under additional regularity and identifiability conditions and further conditions on the bandwidth , existence, uniqueness, consistency and asymptotic normality of , for fixed , follows from the existing results in the literature.
When and , as explained previously, the true density is a –fold convolution of , it is natural to ask the following question: if one lets , will the asymptotic results converge to what one would obtain by taking . We refer to this property as a continuity property in of the procedure. Furthermore, it is natural to wonder if these asymptotic properties can be established uniformly in . If that is the case, then one can also allow to depend on B. This idea has an intuitive appeal since one can choose the parameters of the sensing random variables to achieve an optimal inferential scheme. We address some of these issues in the next subsection.
Finally, we emphasize here that while we do not require , in applications involving streaming data and privacy problems S tends to greater than one. In problems where the variance of sensing variables are large, one can obtain an overall estimator by averaging over various choices of ; that is,
The averaging improves the accuracy of the estimator in small compressed samples (data not presented). For this reason, we provide results for this general case, even though our simulation and theoretical results demonstrate that for some problems considered in this paper,
S can be taken to be one. We now turn to our main results which are presented in the next subsection. The following
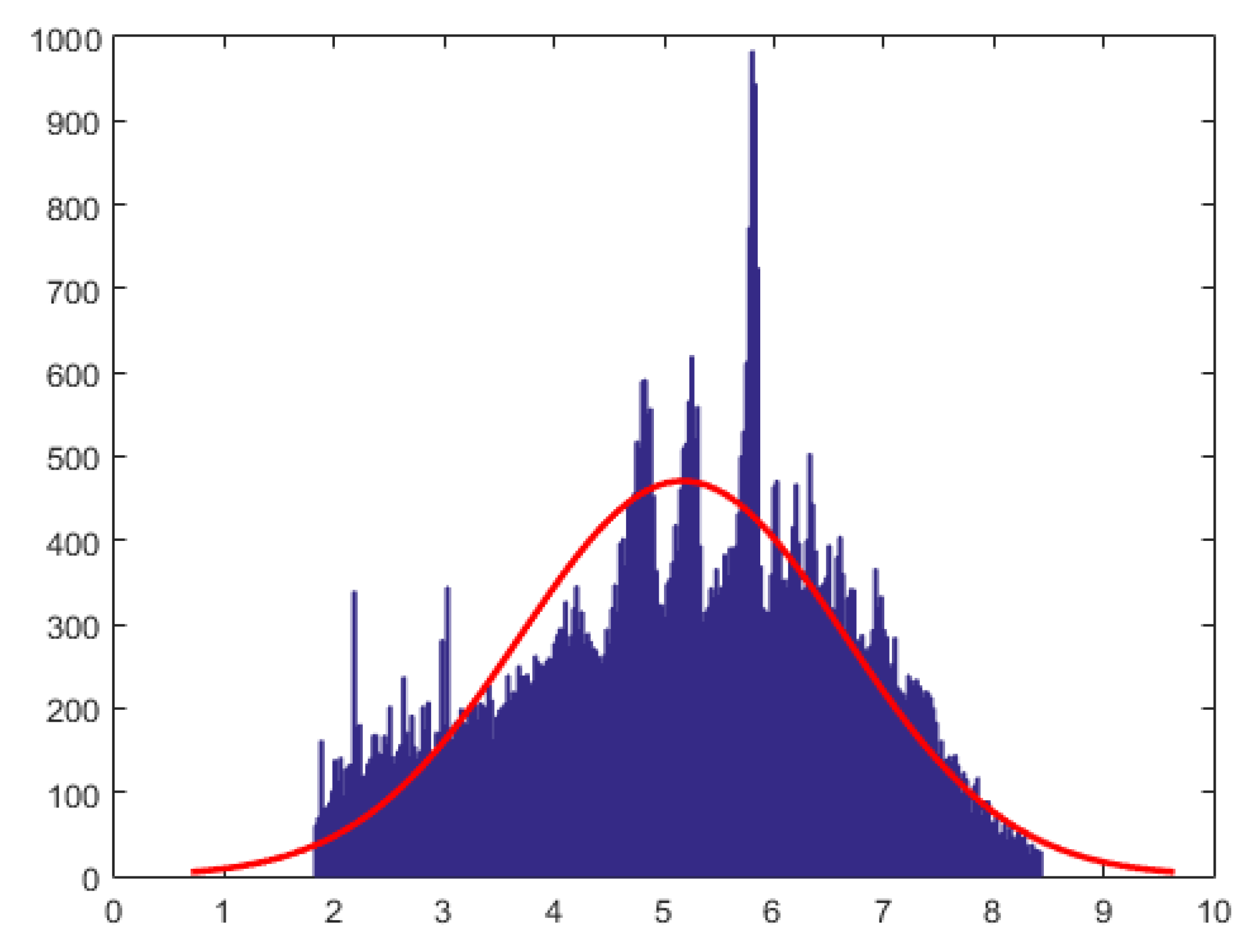
Figure 1 provides a overview of our work.
3.3. Main Results
In this section we state our main results concerning the asymptotic properties of the MHDE of compressed data . We emphasize here that we only store Specifically, we establish the continuity property in of the proposed methods by establishing the existence of the iterated limits. This provides a first step in establishing the double limit. The first proposition is well-known and is concerned with the existence and uniqueness of MHDE for the location-scale family defined in () using compressed data.
Proposition 1. Assume that is a continuous density function. Assume further that if . Then for every , on a set of positive Lebesgue measure, the MHDE in (4) exists and is unique.
Proof. The proof follows from Theorem 2.2 of [
20] since, without loss of generality,
is taken to be compact and the density function
is continuous in
. □
Consistency: We next turn our attention to consistency. As explained previously, under regularity conditions for each fixed , the MHDE is consistent for . The next result says that under additional conditions, the consistency property of MHDE is continuous in .
Proposition 2. Let be a continuous probability density function satisfying the conditions of Proposition 1. Assume that Then, with probability one (wp1) the iterated limits also exist and equals ; that is, for , Proof. Without loss of generality let
be compact since otherwise it can be embedded into a compact set as described in [
1]. Since
is continuous in
and
is continuous in
, it follows that
is continuous in
and
. Hence by Theorem 1 of [
1] for every fixed
and
,
Thus, to verify the convergence of
to
as
, we first establish, using (
6), that
To this end, we first notice that
Also, by continuity,
which, in turn implies that
Thus existence of the iterated limit first as
and then
follows using compactness of
and the identifiability of the model. As for the other iterated limit, again notice notice that for each
,
converges to
with probability one as
converges to 0. The result then follows again by an application of Theorem 1 of [
20]. □
Remark 1. Verification of condition (6) seems to be involved even in the case of standard Gaussian random variables and standard Gaussian sensing random variables. Indeed in this case, the density of is a fold convolution of a Bessel function of second kind. It may be possible to verify the condition (6) using the properties of these functions and compactness of the parameter space Θ. However, if one is focused only on weak-consistency, it is an immediate consequence of Theorems 1 and 2 below and condition (6) is not required. Finally, it is worth mentioning here that the convergence in (6) without uniformity over Θ is a consequence of convergence in probability of to 1 and Glick’s Theorem. Asymptotic limit distribution: We now proceed to investigate the limit distribution of
as
and
. It is well-known that for fixed
, after centering and scaling,
has a limiting Gaussian distribution, under appropriate regularity conditions (see for instance [
20]). However to evaluate the iterated limits as
and
, additional refinements of the techniques in [
20] are required. To this end, we start with additional notations. Let
and let the score function be denoted by
. Also, the Fisher information
is given by
In addition, let
be the gradient of
with respect to
, and
is the second derivative matrix of
with respect to
. In addition, let
and
. Furthermore, let
denote
when
. Please note that in this case,
for all
The corresponding kernel density estimate of
is given by
We emphasize here that we suppress i on the LHS of the above equation since are equal for all .
The iterated limit distribution involves additional regularity conditions which are stated in the Appendix. The first step towards this aim is a representation formula which expresses the quantity of interest, viz., as a sum of two terms, one involving sums of compressed i.i.d. random variables and the other involving remainder terms that converge to 0 at a specific rate. This expression will appear in different guises in the rest of the manuscript and will play a critical role in the proofs.
3.4. Representation Formula
Before we state the lemma, we first provide two crucial assumptions that allow differentiating the objective function and interchanging the differentiation and integration:
Model assumptions on
(D1) is twice continuously differentiable in .
(D2) Assume further that is continuous and bounded.
Lemma 1. Assume that the conditions (D1) and (D2) hold. Then for every and the following holds: Proof. By algebra, note that
Furthermore, the second partial derivative of
is given by
Now using (
D1) and (
D2) and partially differentiating
with respect to
and setting it equal to 0, the estimating equations for
is
Let
be the solution to (
14). Now applying first order Taylor expansion of (
14) we get
where
is defined in (
10), and
is given by
and
is given by
By using the identity,
,
can be expressed as the difference of
and
, where
and
Hence,
where
and
are given in (
9). □
Remark 2. In the rest of the manuscript, we will refer to as the remainder term in the representation formula.
We now turn to the first main result of the manuscript, namely a central limit theorem for as first and then . As a first step, we note that the Fisher information of the density is given by
Next we state the assumptions needed in the proof of Theorem 1. We separate these conditions as (i) model assumptions, (ii) kernel assumptions, (iii) regularity conditions, (iV) conditions that allow comparison of original data and compressed data.
Model assumptions on
(D1’) is twice continuously differentiable in .
(D2’) Assume further that is continuous and bounded.
Kernel assumptions
(B1) is symmetric about 0 on a compact support and bounded in We denote the support of by .
(B2) The bandwidth satisfies , .
Regularity conditions
(M1) The function is continuously differentiable and bounded in at .
(M2) The function is continuous and bounded in at . In addition, assume that
(M3) The function is continuous and bounded in at ; also,
(
M4) Let
be a sequence diverging to infinity. Assume that
where
is the support of the kernel density
and
is a generic random variable with density
.
(M5) Let
Assume .
(M6) The score function has a regular central behavior relative to the smoothing constants, i.e.,
Furthermore,
(M7) The density functions are smooth in an sense; i.e.,
(M1’) The function is continuously differentiable and bounded in at .
(M2’) The function is continuous and bounded in at . In addition, assume that
(M3’) The function is continuous and bounded in at . also,
Assumptions comparing models for original and compressed data
(O1) For all ,
(O2) For all ,
Theorem 1. Assume that the conditions (B1)–(B2), (D1)–(D2) , (D1’)–(D2’), (M1)–(M7), (M1’)–(M3’), and (O1)–(O2) hold. Then, for every the following holds:where G is a bivariate Gaussian random variable with mean 0 and variance , where is defined in (15). Before we embark on the proof of Theorem 1, we first discuss the assumptions. Assumptions (
B1) and (
B2) are standard assumptions on the kernel and the bandwidth and are typically employed when investigating the asymptotic behavior of divergence-based estimators (see for instance [
1]). Assumptions (
M1)–(
M7) and (
M1’)–(
M3’) are regularity conditions which are concerned essentially with
continuity and boundedness of the scores and their derivatives. Assumptions (
O1)–(
O2) allow for comparison of
and
. Returning to the proof of Theorem 1, using representation formula, we will first show that
, and then prove that
in probability. We start with the following proposition.
Proposition 3. Assume that the conditions (B1), (D1)–(D2), (M1)–(M3), (M1’)–(M3’), (M7) and (O1)–(O2) hold. Then,where G is given in Theorem 1. We divide the proof of Proposition 3 into two lemmas. In the first lemma we will show that
Next in the second lemma we will show that first letting and then allowing
We start with the first part.
Lemma 2. Assume that the conditions (D1)–(D2), (D1’)–(D2’), (M1)–(M3), (M1’)–(M3’) and (O1)–(O2) hold. Then, with probability one, the following prevails: Proof. Using representation formula in Lemma 1. First fix
. It suffices to show
We begin with
. By algebra,
can be expressed as
It suffices to show that as
,
, and
. We first consider
. By Cauchy-Schwarz inequality and assumption (
M2), it follows that there exists
,
where the last convergence follows from the
convergence of
and
. Hence, as
,
. Next we consider
. Again, by Cauchy-Schwarz inequality and assumption (
M2), it follows that
. Hence
. Turning to
, by similar argument, using Cauchy-Schwarz inequality and assumption (
M3), it follows that
. Thus, to complete the proof, it is enough to show that
We start with the first term of (
16). Let
We will show that
. By algebra, the difference of the above two terms can be expressed as the sum of
and
, where
converges to zero by Cauchy-Schwarz inequality and assumption (
O2), and
converges to zero by Cauchy-Schwarz inequality, assumption (
M2’) and Scheffe’s theorem. Next we consider the second term of (
16). Let
We will show that
. By algebra, the difference of the above two terms can be expressed as the sum of
and
, where
converges to zero by Cauchy-Schwarz inequality and assumption (
O1), and
converges to zero by Cauchy-Schwarz inequality, assumption (
M3’) and Scheffe’s theorem. Therefore the lemma holds. □
Lemma 3. Assume that the conditions (B1), (D1)–(D2), (D1’)–(D2’), (M1)–(M3), (M3’), (M7) and (O1)–(O2) hold. Then, first letting , and then Proof. First fix
. Please note that using
, we have that
Since
’s are i.i.d. across
l, using Cauchy-Schwarz inequality and assumption (
B1), we can show that there exists
,
converging to zero as
by assumption (
M7). Also, the limiting distribution of
is
as
. Now let
It is enough to show that as
the density of
converges to the density of
. To this end, it suffices to show that
. However, this is established in Lemma 2. Combining the results, the lemma follows. □
Proof of Proposition 3. The proof of Proposition 3 follows immediately by combining Lemmas 2 and 3. □
We now turn to establishing that the remainder term in the representation formula converges to zero.
Lemma 4. Assume that the assumptions (B1)–(B2), (M1)–(M6) hold. Then Proof. Using Lemma 2, it is sufficient to show that
converges to 0 in probability as
. Let
We first deal with
, which can be expressed as the sum of
and
, where
Now consider
. Let
be arbitrary but fixed. Then, by Markov’s inequality,
Now since
are independent and identically distributed across
l, it follows that
Now plugging (
19) into (
18), interchanging the order of integration (using Tonelli’s Theorem), we get
where
C is a universal constant, and the last convergence follows from conditions (
M5)–(
M6). We now deal with
. To this end, we need to calculate
. Using change of variables, two-step Taylor approximation, and assumption (
B1), we get
Now plugging in (
20) into (
17) and using conditions (
M3) and (
M6), we get
Convergence of (
21) to 0 now follows from condition (
M6). We next deal with
. To this end, by writing our the square term of
, we have
We will show that the RHS of (
22) converges to 0 as
We begin with the first term. Please note that by Cauchy-Schwarz inequality,
the last term converges to 0 by (
M4). As for the second term, note that, a.s., by Cauchy-Schwarz inequality,
Now taking the expectation and using Cauchy-Schwarz inequality, one can show that
where
. The convergence to 0 of the RHS of above inequality now follows from condition (
M4). Finally, by another application of the Cauchy-Schwarz inequality,
The convergence of RHS of above inequality to zero follows from (M4). Now the lemma follows. □
Proof of Theorem 1. Recall that
where
and
are given in (
9). Proposition 3 shows that
; while Lemma 4 shows that
in probability. The result follows from Slutsky’s theorem. □
We next show that by interchanging the limits, namely first allowing to converge to 0 and then letting the limit distribution of is Gaussian with the same covariance matrix as Theorem 1. We begin with additional assumptions required in the proof of the theorem.
Regularity conditions
(
M4’) Let
be a sequence diverging to infinity. Assume that
where
is the support of the kernel density
and
is a generic random variable with density
.
(M5’) Let
Assume that .
(M6’) The score function has a regular central behavior relative to the smoothing constants, i.e.,
Furthermore,
(M7’) The density functions are smooth in an sense; i.e.,
Assumptions comparing models for original and compressed data
(V1) Assume that
(V2) is continuous in the sense that implies that , where the expectation is with respect to distribution .
(V3) Assume that for all , .
(V4) Assume that for all , .
Theorem 2. Assume that the conditions (B1)–(B2), (D1’)–(D2’), (M1’)–(M7’), (O1)–(O2) and (V1)–(V4) hold. Then,where G is a bivariate Gaussian random variable with mean 0 and variance . We notice that in the above Theorem 2 that we use conditions (
V2)–(
V4) which are regularity conditions on the scores of the
fold convolution of
while
facilitates comparison of the scores of the densities of the compressed data and that of the
fold convolution. As before, we will first establish (a):
and then (b):
in probability. We start with the proof of (a).
Proposition 4. Assume that the conditions (B1)–(B2), (D1’)–(D2’), (M1’)–(M3’), (M7’), (O1)–(O2), and (V1)–(V2) hold. Then, We divide the proof of Proposition 4 into two lemmas. In the first lemma, we will show that
In the second lemma, we will show that first let , then let ,
Lemma 5. Assume that the conditions (B1)–(B2), (D1’)–(D2’), (M1’)–(M3’), (O1)–(O2), and (V1)–(V2) hold. Then, Proof. By algebra,
can be expressed as the sum of
,
,
,
and
, where
We will show that
where
is given in (
7). First consider
. it converges to zero as
by Cauchy-Schwarz inequality and assumption (
O2). Next we consider
. We will first show that
To this end, notice that by Cauchy-Schwarz inequality and boundedness of
in
, it follows that there exists a constant
C such that
It suffices to show that
converges to
in
. Since
and
, by dominated convergence theorem,
. Next we will show that
In addition, by Cauchy-Schwarz inequality, boundedness of
in
and Scheffe’s theorem, we have that
converges to zero as
Next we consider
. it converges to zero by Cauchy-Schwarz inequality and assumption (
M2’). Thus (
24) holds. Now let
we will show that
and
First consider
. It converges to zero by Cauchy-Schwarz inequality and assumption (
M2’). Next we consider
. It converges to zero by Cauchy-Schwarz inequality and
convergence of
and
. Therefore
.
We now turn to show that
. First fix
B and express
as the sum of
,
,
,
, and
, where
First consider
. It converges to zero as
by Cauchy-Schwarz inequality and assumption (
O1). Next consider
. By similar argument as above and boundedness of
, it follows that (
27) holds. Next consider
. It converges to zero as
by Cauchy-Schwarz inequality and assumption (
M3’). Now let
we will show that
and
. First consider
. It converges to zero by Cauchy-Schwarz inequality and assumption (
M3’) as
. Finally consider
. It converges to zero by Cauchy-Schwarz inequality and
convergence of
and
. Thus
. Now letting
, the proof of (
23) follows using arguments similar to the one in Lemma 2. □
Lemma 6. Assume that the conditions (B1)–(B2),(D1’)–(D2’), (M1’)–(M3’), (M7’), (O1)–(O2), and (V1)–(V2) hold. Then, first letting , and then letting Proof. First fix
B. We will show that as
We will show that the RHS of (
29) converges to zero as
and the RHS of (30) converges to zero in probability as
. First consider the RHS of (
29). Since
which converges to zero as
by assumption (
V1). Next consider the RHS of (30). Since
By assumption (
V2), it follows that as
, (30) converges to zero in probability. Now letting
, we have
and
where the last convergence follows by assumption (
M7’). Hence, using the Central limit theorem for independent and identically distributed random variables it follows that the limiting distribution of
is
, proving the lemma. □
Proof of Proposition 4. The proof of Proposition 4 follows by combining Lemmas 5 and 6. □
Lemma 7. Assume that the conditions (M1’)–(M6’) and (V1)–(V4) hold. Then, Proof. First fix
B. Let
we will show that as
,
. By algebra,
can be written as the sum of
and
, where
First consider
. It is bounded above by
, which converges to zero as
by assumption (
V1), where
C is a constant. Next consider
. We will show that
converges to
In fact, the difference of
and the above formula can be expressed as the sum of
,
and
, where
First consider
. Please note that
which converges to 0 as
by assumptions (
V3) and (
V4). Next we consider
. Since
which converges to zero as
due to assumption (
V2). Finally consider
, which can be expressed as the sum of
and
, where
First consider
. Notice that
where the last convergence follows by Cauchy-Schwarz inequality and assumption (
V4). Next we consider
. By Cauchy-Schwarz inequality, it is bounded above by
Equation (
31) converges to zero as
by boundedness of
and
convergence between
and
, where the
convergence has already been established in Lemma 5. Now letting
, following similar argument as Lemma 4 and assumptions (
M1’)–(
M6’), the lemma follows. □
Proof of Theorem 2. Proposition 4 shows that first letting then , ; while Lemma 7 shows that in probability. The theorem follows from Slutsky’s theorem. □
Remark 3. The above two theorems (Theorems 1 and 2) do not immediately imply the double limit exists. This requires stronger conditions and more delicate calculations and will be considered elsewhere.
3.5. Robustness of MHDE
In this section, we describe the robustness properties of MHDE for compressed data. Accordingly, let , where denotes the uniform density on the interval , where is small, , , and . Also, let , , , , and . Before we state the theorem, we describe certain additional assumptions-which are essentially continuity conditions-that are needed in the proof.
Model assumptions for robustness analysis
(O3) For and all ,
(O4) For and all ,
Theorem 3. (i) Let and assume that for all , and assume that the assumptions of Proposition 1 hold, also assume that is unique for all z. Then, is a bounded, continuous function of z and(ii) Assume further that the conditions (V1), (M2)-(M3), and (O3)-(O4) hold. Then, Proof. Let
denote
and let
denote
We first show that (
32) holds. Let
be fixed. Then, by triangle inequality,
We will show that the first term of RHS of (
33) is equal to zero. Suppose that it is not zero, without loss of generality, by going to a subsequence if necessary, we may assume that
as
. Since
minimizes
, it follows that
for every
. We now show that as
,
To this end, note that as
for every
y,
Therefore, as
where
Now, by Cauchy-Schwarz inequality and Scheffe’s theorem, it follows that as
,
and
. Therefore, (
35) holds. By Equations (
34) and (
35), we have
for every
. Now consider
where
. Since
is a non-negative and strictly convex function with
as the unique point of minimum. Hence
unless
on a set of Lebesgue measure zero, which by the model identifiability assumption , is true if and only if
. Since
, it follows that
Since
. This implies that
which contradicts (
36). The continuity of
follows from Proposition 2 and the boundedness follows from the compactness of
. Now let
, the second term of RHS of (
33) converges to zero by Proposition 2.
We now turn to part (ii) of the Theorem. First fix
Since
minimizes
over
. By Taylor expansion of
around
, we get
where
is a point between
and
,
and
can be expressed the sum of
and
, where
We will first establish (
40). Please note that as
by definition
Thus,
In addition, by assumptions (
O3) and (
O4),
is continuous in
. Therefore, to prove (
40), it suffices to show that
We begin with
. Notice that
In addition, in order to pass the limit inside the integral, note that, for every component of matrix
, we have
where
represents the absolute function for each component of the matrix, and
Now choosing the dominating function
and applying Cauchy-Schwarz inequality, we obtain that there exists a constant
C such that
which is finite by assumption (
M2). Hence, by the dominated convergence theorem, (
43) holds. Turning to (
42), notice that for each component of the matrix
,
where
denotes the absolute function for each component. Now choosing the dominating function
and applying the Cauchy-Schwarz inequality it follows, using (
M3), that
Finally, by the dominated convergence theorem, it follows that
Therefore (
40) follows. It remains to show that (
41) holds. To this end, note that
Now taking partial derivative of
with respect to
, it can be expressed as the sum of
,
and
, where
By dominated convergence theorem (using similar idea as above to find dominating functions), we have
Hence, by L’Hospital rule, (
41) holds. It remains to show that
We start with (
44). Since for fixed
, by the above argument, it follows that
it is enough to show
which is proved in Lemma 2. Hence (
44) holds. Next we prove (
45). By the argument used to establish (40), it is enough to show that
However,
and the RHS of the above inequality converges to zero as
from assumption (
V1). Hence (
46) holds. This completes the proof. □
Our next result is concerned with the behavior of the influence function when first and then or . The following three additional assumptions will be used in the proof of part (ii) of Theorem 4.
Model assumptions for robustness analysis
(O5) For and all , is bounded in .
(O6) For and all , is bounded in .
(O7) For and all ,
Theorem 4. (i) Let and assume that for all , assume that the assumptions of Proposition 1 hold, also assume that is unique for all z. Then, is a bounded, continuous function of z such that(ii) Assume further that the conditions (O3)–(O7) hold. Then, Proof. Let
denote
and let
denote
. First fix
; then by the triangular inequality,
The first term of RHS of (
47) is equal to zero due to proposition 2. Now let
, then the second term on the RHS of (
47) converges to zero using similar argument as Theorem 3 with density converging to
. This completes the proof of I). Turning to (ii), we will prove that
Recall from the proof of part (ii) of Theorem 3 that
We will now show that for fixed
We begin with (
50). A standard calculation shows that
can be expressed as the sum of
,
and
, where
It can be seen that
converges to zero as
by Cauchy-Schwarz inequality and assumption (
O3); also,
converges to zero as
by Cauchy-Schwarz inequality, assumption (
O5) and Scheffe’s theorem. Hence (
50) follows. Similarly (
51) follows as
by Cauchy-Schwarz inequality, assumption (
O4), assumption (
O6) and Scheffe’s theorem.
Now let
. Using the same idea as in Theorem 3 to find dominating functions, one can apply the dominated convergence Theorem to establish that
Hence (
48) follows. Finally, it remains to establish (
49). First fix
; we will show that
Please
can be expressed as the sum of
,
and
, where
It can be seen thatr
converges to zero as
by Cauchy-Schwarz inequality and assumption (
O7);
converges to zero as
by Cauchy-Schwarz inequality, boundedness of
in
, and Scheffe’s theorem. Therefore, (
52) holds. Finally, letting
and using the same idea as in Theorem 3 to find the dominating function, it follows by the dominated convergence theorem and L’Hospital rule that (
49) holds. This completes the proof of the Theorem. □
Remark 4. Theorems 3 and 4 do not imply that the double limit exists. This is beyond the scope of this paper.
In the next section, we describe the implementation details and provide several simulation results in support of our methodology.








{kind=link}
{kind=link}
{kind=link}
{kind=link}