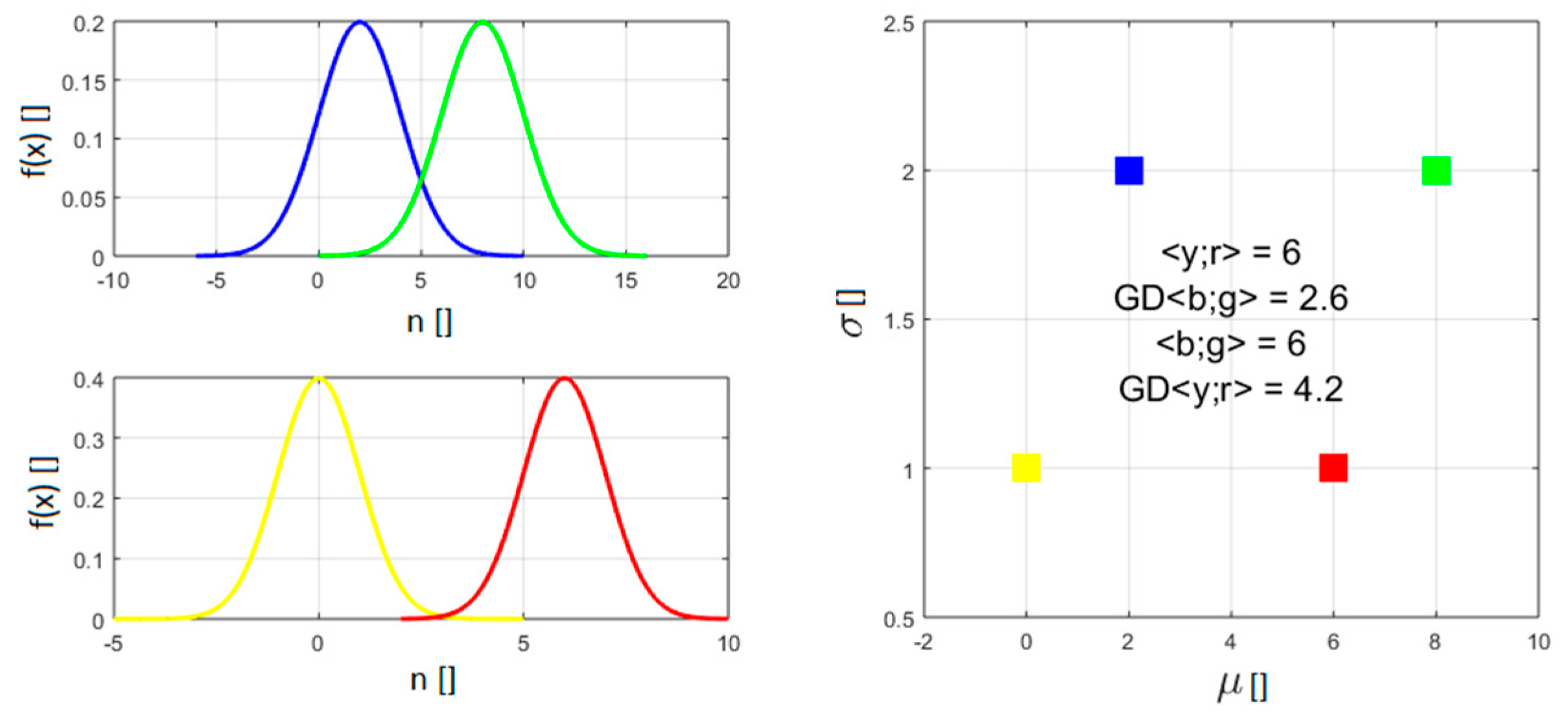
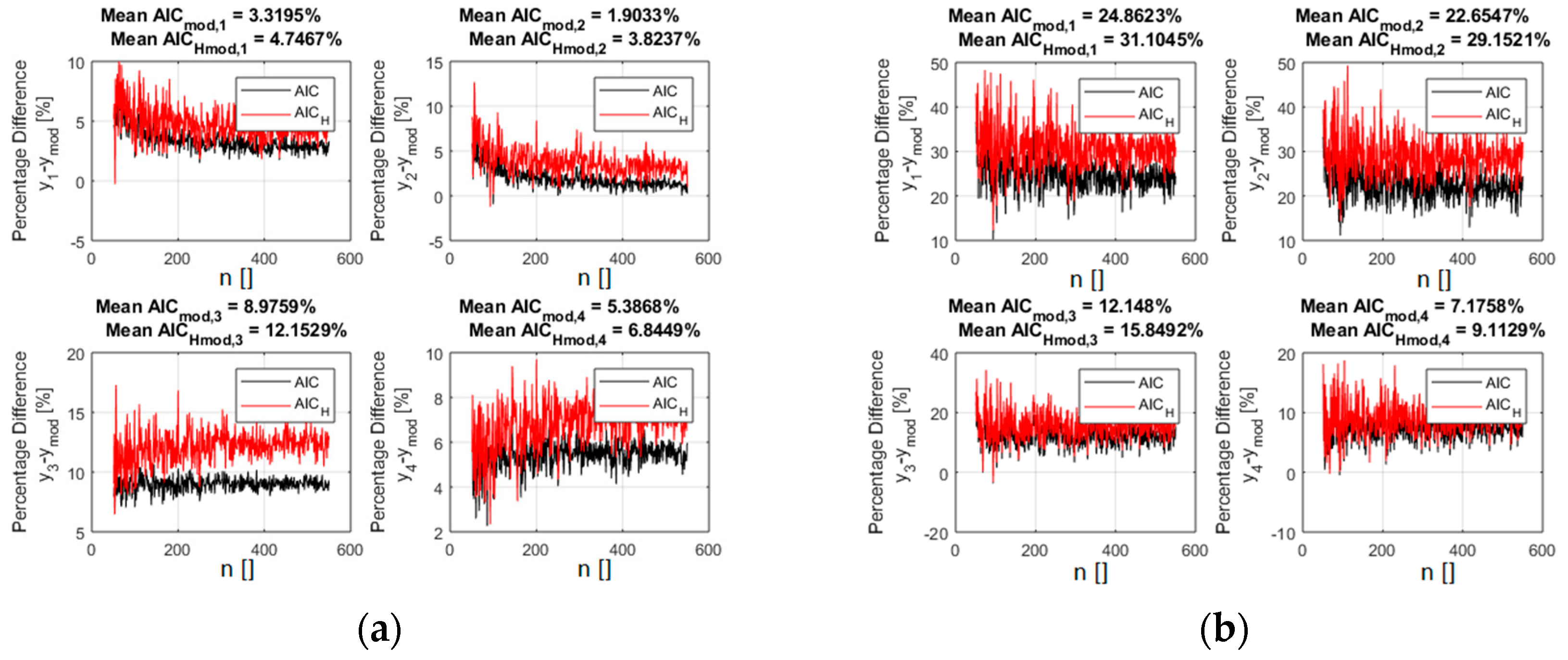
On the Use of Entropy to Improve Model Selection Criteria


 ,
, 
 and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Murari, A.; Peluso, E.; Cianfrani, F.; Gaudio, P.; Lungaroni, M. On the Use of Entropy to Improve Model Selection Criteria. Entropy 2019, 21, 394. https://doi.org/10.3390/e21040394
Murari A, Peluso E, Cianfrani F, Gaudio P, Lungaroni M. On the Use of Entropy to Improve Model Selection Criteria. Entropy. 2019; 21(4):394. https://doi.org/10.3390/e21040394
Chicago/Turabian StyleMurari, Andrea, Emmanuele Peluso, Francesco Cianfrani, Pasquale Gaudio, and Michele Lungaroni. 2019. "On the Use of Entropy to Improve Model Selection Criteria" Entropy 21, no. 4: 394. https://doi.org/10.3390/e21040394
APA StyleMurari, A., Peluso, E., Cianfrani, F., Gaudio, P., & Lungaroni, M. (2019). On the Use of Entropy to Improve Model Selection Criteria. Entropy, 21(4), 394. https://doi.org/10.3390/e21040394