Abstract
We consider the k-user successive refinement problem with causal decoder side information and derive an exponential strong converse theorem. The rate-distortion region for the problem can be derived as a straightforward extension of the two-user case by Maor and Merhav (2008). We show that for any rate-distortion tuple outside the rate-distortion region of the k-user successive refinement problem with causal decoder side information, the joint excess-distortion probability approaches one exponentially fast. Our proof follows by judiciously adapting the recently proposed strong converse technique by Oohama using the information spectrum method, the variational form of the rate-distortion region and Hölder’s inequality. The lossy source coding problem with causal decoder side information considered by El Gamal and Weissman is a special case () of the current problem. Therefore, the exponential strong converse theorem for the El Gamal and Weissman problem follows as a corollary of our result.
1. Introduction
We consider the k-user successive refinement problem with causal decoder side information shown in Figure 1, which we refer to as the k-user causal successive refinement problem. The decoders aim to recover the source sequence based on the encoded symbols and causally available private side information sequences. Specifically, given the source sequence , each encoder where compresses into a codeword . At time , for each , the j-th user aims to recover the i-th source symbol using the codewords from encoders , the side information up to time i and a decoding function , i.e., . Finally, at time n, for all , the j-th user outputs the source estimate which, under a distortion measure , is required to be less than or equal to a specified distortion level .
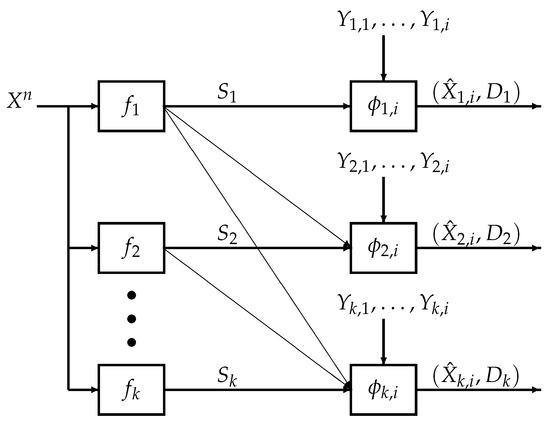
Figure 1.
Encoder-decoder system model for the k-user successive refinement problem with causal decoder side information at time . Each encoder where compresses the source information into codewords . Given accumulated side information and the codewords , decoder reproduces the i-th source symbol as . At time n, for , the estimate for user j is required to satisfy distortion constraint under a distortion measure .
The causal successive refinement problem was first considered by Maor and Merhav in [1] who fully characterized the rate-distortion region for the two-user version. Maor and Merhav showed that, unlike the case with non-causal side information [2,3], no special structure e.g., degradedness, is required between the side information and . Furthermore, Maor and Merhav discussed the performance loss due to causal decoder side information compared with non-causal side information [2,3]. In general, for the k-user successive refinement problem, the loss of performance due to causal decoder side information can be derived using Theorem 1 of the present paper and the results in [2,3] for the k-user case, under certain conditions on the degradedness of the side information in [2,3].
However, Maor and Merhav only presented a weak converse in [1]. In this paper, we strengthen the result in [1] by providing an exponential strong converse theorem for the full k-user causal successive refinement problem, which states that the joint excess-distortion probability approaches one exponentially fast if the rate-distortion tuple falls outside the rate-distortion region.
1.1. Related Works
We first briefly summarize existing works on the successive refinement problem. The successive refinement problem was first considered by Equitz and Cover [4] and by Koshelev [5] who considered necessary and sufficient conditions for a source-distortion triple to be successively refinable. Rimoldi [6] fully characterized the rate-distortion region of the successive refinement problem under the joint excess-distortion probability criterion while Kanlis and Narayan [7] derived the excess-distortion exponent in the same setting. The second-order asymptotic analysis of No and Weissman [8], which provides approximations to finite blocklength performance and implies strong converse theorems, was derived under the marginal excess-distortion probabilities criteria. This analysis was extended to the joint excess-distortion probability criterion by Zhou, Tan and Motani [9]. Other frameworks for successive refinement decoding include [10,11,12,13].
The study of source coding with causal decoder side information was initiated by Weissman and El Gamal in [14] where they derived the rate-distortion function for the lossy source coding problem with causal side information at the decoders (i.e., , see also [15], Chapter 11.2). Subsequently, Timo and Vellambi [16] characterized the rate-distortion regions of the Gu-Effros two-hop network [17] and the Gray-Wyner problem [18] with causal decoder side information; Maor and Merhav [19] derived the rate-distortion region for the successive refinement of the Heegard-Berger problem [20] with causal side information available at the decoders; Chia and Weissman [21] considered the cascade and triangular source coding problem with causal decoder side information. In all the aforementioned works, the authors used Fano’s inquality to prove a weak converse. The weak converse implies that as the blocklength tends to infinity, if the rate-distortion tuple falls outside the rate-distortion region, then the joint excess-distortion probability is bounded away from zero. However, in this paper, we prove an exponential strong converse theorem for the k-user causal successive refinement problem, which significantly strengthens the weak converse as it implies that the joint excess-distortion probability tends to one exponentially fast with respect to the blocklength if the rate-distortion tuple falls outside the rate-distortion region (cf. Theorem 3). As a corollary of our result, for any , the -rate-distortion region (cf. Definition 2) remains the same as the rate-distortion region (cf. Equation (27)). Please note that with weak converse, one can only assert that the -rate-distortion region equals the rate-distortion region when . See [22] for yet another justification for the utility of a strong converse compared to a weak converse theorem.
As the information spectrum method will be used in this paper to derive an exponential strong converse theorem for the causal successive refinement problem, we briefly summarize the previous applications of this method to network information theory problems. In [23,24,25], Oohama used this method to derive exponential strong converses for the lossless source coding problem with one-helper [26,27] (i.e., the Wyner-Ahlswede-Körner (WAK) problem), the asymmetric broadcast channel problem [28], and the Wyner-Ziv problem [29] respectively. Furthermore, Oohama’s information spectrum method was also used to derive exponential strong converse theorems for content identification with lossy recovery [30] by Zhou, Tan, Yu and Motani [31] and for Wyner’s common information problem under the total variation distance measure [32] by Yu and Tan [33].
1.2. Main Contribution and Challenges
We consider the k-user causal successive refinement problem and present an exponential strong converse theorem. For given rates and blocklength, define the joint excess-distortion probability as the probability that any decoder incurs a distortion level greater than the specified distortion level (see (3)) and define the probability of correct decoding as the probability that all decoders satisfy the specified distortion levels (see (24)). Our proof proceeds as follows. First, we derive a non-asymptotic converse (finite blocklength upper) bound on the probability of correct decoding of any code for the k-user causal successive refinement problem using the information spectrum method. Subsequently, by using Cramér’s inequality and the variational formulation of the rate-distortion region, we show that the probability of correct decoding decays exponentially fast to zero as the blocklength tends to infinity if the rate-distortion tuple falls outside the rate-distortion region of the causal successive refinement problem.
As far as we are aware, this paper is the first to establish a strong converse theorem for any lossy source coding problem with causal decoder side information. Furthermore, our methods can be used to derive exponential strong converse theorems for other lossy source coding problems with causal decoder side information discussed in Section 1.1. In particular, since the lossy source coding problems with causal decoder side information in [1,14] are special cases of the k-user causal successive refinement problem, the exponential strong converse theorems for the problems in [1,14] follow as a corollary of our result.
To establish the strong converse in this paper, we must overcome several major technical challenges. The main difficulty lies in the fact that for the causal successive refinement problem, the side information is available to the decoder causally instead of non-causally. This causal nature of the side information makes the design of the decoder much more complicated and involved, which complicates the analysis of the joint excess-distortion probability. We find that classical strong converse techniques like the image size characterization [34] and the perturbation approach [35] cannot lead to a strong converse theorem due to the above-mentioned difficulty. However, it is possible that other approaches different from ours can be used to obtain a strong converse theorem for the current problem. For example, it is interesting to explore whether two recently proposed strong converse techniques in [36,37] can be used for this purpose considering the fact that the methods in [36,37] have been successfully applied to problems including the Wyner-Ziv problem [29], the Wyner-Ahlswede-Körner (WAK) problem [26,27] and hypothesis testing problems with communication constraints [38,39,40].
2. Problem Formulation and Existing Results
2.1. Notation
Random variables and their realizations are in upper (e.g., X) and lower case (e.g., x) respectively. Sets are denoted in calligraphic font (e.g., ). We use to denote the complement of and use to denote a random vector of length n. Furthermore, given any , we use to denote . We use and to denote the set of positive real numbers and integers respectively. Given two integers a and b, we use to denote the set of all integers between a and b and use to denote . The set of all probability distributions on is denoted as and the set of all conditional probability distributions from to is denoted as . For information-theoretic quantities such as entropy and mutual information, we follow the notation in [34]. In particular, when the joint distribution of is , we use and interchangeably.
2.2. Problem Formulation
Let be a fixed finite integer and let be a joint probability mass function (pmf) on the finite alphabet with its marginals denoted in the customary way, e.g., , . Throughout the paper, we consider memoryless sources , which are generated i.i.d. according to . Let a finite alphabet be the alphabet of the reproduced source symbol for user . Recall the encoder-decoder system model for the k-user causal successive refinement problem in Figure 1.
A formal definition of a code for the causal successive refinement problem is as follows.
Definition 1.
An -code for the causal successive refinement problem consists of
- k encoding functions
- and decoding functions: for each
For , let be a distortion measure. Given the source sequence and a reproduced version , we measure the distortion between them using the additive distortion measure . To evaluate the performance of an -code for the causal successive refinement problem, given distortion specified levels , we consider the following joint excess-distortion probability
For ease of notation, throughout the paper, we use to denote , to denote and to denote .
Given , the -rate-distortion region for the k-user causal successive refinement problem is defined as follows.
Definition 2.
Given any , a rate-distortion tuple is said to be ε-achievable if there exists a sequence of -codes such that
The closure of the set of all ε-achievable rate-distortion tuples is called the ε-rate-distortion region and is denoted as .
Please note that in Definition 2, is the sum rate of the first j decoders. Using Definition 2, the rate-distortion region for the problem is defined as
2.3. Existing Results
For the two-user causal successive refinement problem, the rate-distortion region was fully characterized by Maor and Merhav (Theorem 1 in [1]). With slight generalization, the result can be extended to the k-user case.
For , let be a random variable taking values in a finite alphabet . For simplicity, throughout the paper, we let
and let be a particular realization of T and its alphabet set, respectively.
Define the following set of joint distributions:
Given any joint distribution , define the following set of rate-distortion tuples
For , Maor and Merhav [1] defined the following information theoretical sets of rate-distortion tuples
Theorem 1.
The rate-distortion region for the causal successive refinement problem satisfies
We remark that in [1], Maor and Merhav considered the average distortion criterion for , i.e.,
instead of the vanishing joint excess-distortion probability criterion (see (6)) in Definition 2. However, with slight modification to the proof of [1], it can be verified (see Appendix A) that the rate-distortion region under the vanishing joint excess-distortion probability criterion, is identical to the rate-distortion region derived by Maor and Merhav under the average distortion criterion.
Theorem 1 implies that if a rate-distortion tuple falls outside the rate-distortion region, i.e., , then the joint excess-distortion probability is bounded away from zero. We strengthen the converse proof of Theorem 1 by showing that if , then the joint excess-distortion probability approaches one exponentially fast as the blocklength n tends to infinity.
3. Main Results
3.1. Preliminaries
In this subsection, we present necessary definitions and a key lemma before stating our main result.
Define the following set of distributions
Throughout the paper, we use to denote and use similarly. Given any such that
for any , define the following linear combination of log likelihoods
Given any and any , define the negative cumulant generating function of as
Furthermore, define the minimal negative cumulant generating function over distributions in as
Finally, given any rate-distortion tuple , define
With the above definitions, we have the following lemma establishing the properties of the exponent function .
Lemma 1.
The following holds.
- (i)
- For any rate-distortion tuple outside the rate-distortion region, i.e., , we have
- (ii)
- For any rate-distortion tuple inside the rate-distortion region, i.e., , we have
The proof of Lemma 1 is inspired by Property 4 in [25], Lemma 2 in [31] and is given in Section 5. As will be shown in Theorem 2, the exponent function is a lower bound on the exponent of the probability of correct decoding for the k-user causal successive refinement problem. Thus, Claim (i) in Lemma 1 is crucial to establish the exponential strong converse theorem which states that the joint excess-distortion probability (see (3)) approaches one exponentially fast with respect to the blocklength of the source sequences.
3.2. Main Result
Define the probability of correct decoding as
Theorem 2.
Given any -code for the k-user causal successive refinement problem such that
we have the following non-asymptotic upper bound on the probability of correct decoding
The proof of Theorem 2 is given in Section 4. Several remarks are in order.
First, our result is non-asymptotic, i.e., the bound in (26) holds for any . To prove Theorem 2, we adapt the recently proposed strong converse technique by Oohama [25] to analyze the probability of correct decoding. We first obtain a non-asymptotic upper bound using the information spectrum of log-likelihoods involved in the definition of (see (16)) and then apply Cramér’s bound on large deviations (see e.g., Lemma 13 in [31]) to obtain an exponential type non-asymptotic upper bound. Subsequently, we apply the recursive method [25] and proceed similarly as in [31] to obtain the desired result. Our method can also be used to establish similar results for other source coding problems with causal decoder side information [16,19,21].
Second, we do not believe that classical strong converse techniques including the image size characterization [34] and the perturbation approach [35] can be used to obtain a strong converse theorem for the causal successive refinement problem (e.g., Theorem 3). The main obstacle is that the side information is available causally and thus complicates the decoding analysis significantly.
Invoking Lemma 1 and Theorem 2, we conclude that the exponent on the right hand side of (26) is positive if and only if the rate-distortion tuple is outside the rate-distortion region, which implies the following exponential strong converse theorem.
Theorem 3.
For any sequence of -codes satisfying the rate constraints in (25), given any distortion levels , we have that if , then the probability of correct decoding decays exponentially fast to zero as the blocklength of the source sequences tends to infinity.
As a result of Theorem 3, we conclude that for every , the -rate distortion region (see Definition 2) satisfies that
i.e., a strong converse holds for the k-user causal successive refinement problem. Using the strong converse theorem and Marton’s change-of-measure technique [41], similarly to Theorem 5 in [31], we can also derive an upper bound on the exponent of the joint excess-distortion probability. Furthermore, applying the one-shot techniques in [42], we can also establish a non-asymptotic achievability bound. Applying the Berry-Esseen theorem to the achievability bound and analyzing the non-asymptotic converse bound in Theorem 2, similarly to [25], we conclude that the backoff from the rate-distortion region at finite blocklength scales on the order of . However, nailing down the exact second-order asymptotics [43,44] is challenging and is left for future work.
Our main results in Lemma 1, Theorems 2 and 3 can be specialized to the settings in [1,14] with and decoders (users) respectively.
4. Proof of the Non-Asymptotic Converse Bound (Theorem 2)
4.1. Preliminaries
Given any -code with encoding functions and and decoding functions , we define the following induced conditional distributions on the encoders and decoders: for each ,
For simplicity, in the following, we define
and let be a particular realization and the alphabet of G respectively. With above definitions, we have that the distribution satisfies that for any ,
In the remaining part of this section, all distributions denoted by P are induced by the joint distribution .
To simplify the notation, given any , we use to denote and we use to denote . Similarly, we use and . For each , let auxiliary random variables be and for all . Please note that as a function of , the Markov chain holds under . Throughout the paper, for each , we let
and let be a particular realization of and the alphabet of , respectively.
For each , let be arbitrary distributions where and . Given any positive real number and rate-distortion tuple , define the following subsets of :
4.2. Proof Steps of Theorem 2
We first present the following non-asymptotic upper bound on the probability of correct decoding using the information spectrum method.
Lemma 2.
For any -code satisfying (25), given any distortion levels , we have
The proof of Lemma 2 is given in Appendix B and is divided into two steps. First, we derive a n-letter non-asymptotic upper bound which holds for certain arbitrary n-letter auxiliary distributions. Subsequently, we single-letterize the derived bound by proper choice of auxiliary distributions and careful decomposition of induced distributions of .
Subsequently, we will apply Cramér’s bound on Lemma 2 to obtain an exponential type non-asymptotic upper bound on the probability of correct decoding. For simplicity, we will use to denote and use to denote . To present our next result, we need the following definitions. Given any and any satisfying (15), let be the weighted sum of log likelihood terms in the summands to the right of the inequalities in , i.e.,
Furthermore, given any non-negative real number , define the following negative cumulant generating function
Recall the definition of in (19). Please note that is a linear combination of the rate-distortion tuple. Using Lemma 2 and Cramér’s bound (Lemma 13 in [31]), we obtain the following non-asymptotic exponential type upper bound on the probability of correct decoding, whose proof is given in in Appendix D.
Lemma 3.
For any -code satisfying the conditions in Lemma 2, given any distortion levels , we have
For subsequent analyses, let be the lower bound on the Q-maximal negative cumulant generating function obtained by optimizing over the choice of auxiliary distributions , i.e.,
Here the supremum over is taken since we want the bound to hold for favorable auxiliary distributions and the infimum over is taken to yield a non-asymptotic bound.
In the following, we derive a relationship between and (cf. (18)), which, as we shall see later, is a crucial step in proving Theorem. For this purpose, given any such that
let
Then we have the following lemma which shows that in Equation (44) can be lower bounded by a scaled version of in Equation (18).
Lemma 4.
Given any satisfying (15) and (45), for θ defined in (46), we have:
The proof of Lemma 4 uses Hölder’s inequality and the recursive method in [25] and is given in Appendix E.
Combining Lemmas 3 and 4, we conclude that for any -code satisfying the conditions in Lemma 2 and for any , given any satisfying (45), we have
where (49) follows from the definitions of in (19) and in (46), and (50) is simply due to the definition of in (20).
5. Proof of Properties of Strong Converse Exponent: Proof of Lemma 1
5.1. Alternative Expressions for the Rate-Distortion Region
In this section, we present preliminaries for the proof of Lemma 1, including several definitions and two alternative characterizations of the rate-distortion region (cf. (7)).
Recall that we use to denote . First, paralleling (9), we define the following set of joint distributions
Please note that compared with (9), the deterministic decoding functions are now replaced by stochastic functions, which are characterized by transition matrices and induce Markov chains, and the cardinality bounds on auxiliary random variables are changed accordingly. Using the definitions of and (cf. (10)), we can define the following rate-distortion region denoted by where the subscript “ran” refers to the randomness of the stochastic functions in the definition of :
As we shall see later, .
To present the alternative characterization of the rate-distortion region using supporting hyperplanes, we need the following definitions. First, we let be the following set of joint distributions
Please note that are the same as (cf. (51)) except that the cardinality bounds are reduced. Given any satisfying (15), define the following linear combination of achievable rate-distortion tuples
Recall the definition of linear combination of rate-distortion tuples in (19) and let be the following collection of rate-distortion tuples defined using supporting hyperplane :
Finally, recall the definitions of the rate-distortion region in (7) and the characterization in (11). Similarly to Properties 2 and 3 in [25], one can establish the following lemma, which states that: (i) the rate-distortion region for the k-user causal successive refinement problem remains unchanged even if one uses stochastic decoding functions; and (ii) the rate-distortion region has alternative characterization in terms of supporting hyperplanes in (54).
Lemma 5.
The rate-distortion region for the causal successive refinement problem satisfies
5.2. Proof of Claim (i)
Recall that we use T (cf. (8)) to denote the collection of random variables and use similarly to denote a realization of T and its alphabet, respectively. For any (recall (53)), any satisfying (15) and any , for any , paralleling (16) and (17), define the following linear combination of log likelihoods and its negative cumulative generating function:
For simplicity, we let
Furthermore, paralleling the steps used to go from (18) to (21) and recalling the definition of in (19), let
To prove Claim (i), we will need the following two definitions of the tilted distribution and the dispersion function:
Please note that is positive and finite.
The proof of Claim (i) in Lemma 1 is completed by the following lemma which relates in Equation (21) to in Equation (62).
Lemma 6.
The following holds.
- (i)
- For any rate-distortion tuple ,
- (ii)
- For any rate-distortion tuple outside the rate-distortion region, i.e., , there exists such that:
The proof of Lemma 6 is inspired by [25,31] and given in Appendix F. To prove Lemma 6, we use the alternative characterizations of the rate-distortion region in Lemma 5 and analyze the connections between the two exponent functions and .
5.3. Proof of Claim (ii)
Recall the definition of the linear combination of rate-distortion tuple in Equation (19). If a rate-distortion tuple falls inside the rate-distortion region, i.e., , then there exists a distribution (see (53)) such that for any satisfying (15), we have the following lower bound on :
Recall the definition of in (17). Simple calculation establishes
Combining (68) and (69), by concavity of in , it follows that for any ,
Using the definition of in (18), it follows that
where (71) follows from (recall (14)), (72) follows from the result in (70), (73) follows from the definitions of in (17) and in (53), and (74) follows from the result in (67).
Using the definition of in (21) and the result in (74), we conclude that for any ,
The proof of Claim (ii) is completed by noting that
6. Conclusions
We considered the k-user causal successive refinement problem [1] and established an exponential strong converse theorem using the strong converse techniques proposed by Oohama [25]. Our work appears to be the first to derive a strong converse theorem for any source coding problem with causal decoder side information. The methods we adopted can also be used to obtain exponential strong converse theorems for other source coding problems with causal decoder side information. This paper further illustrates the usefulness and generality of Oohama’s information spectrum method in deriving exponential strong converse theorems. The discovered duality in [45] between source coding with decoder side information [46] and channel coding with encoder state information [47] suggests that Oohama’s techniques [25] can also be used to establish the strong converse theorem for channel coding with causal encoder state information, e.g., [48,49,50].
There are several natural future research directions. In Theorem 2, we presented only a lower bound on the strong converse exponent. It would be worthwhile to obtain an exact expression for the strong converse exponent and thus characterize the speed at which the probability of correct decoding decays exponentially fast with respect to the blocklength of source sequences when the rate-distortion tuple falls outside the rate-distortion region. Furthermore, one can explore whether the methods in this paper can be used to establish strong converse theorems for causal successive refinement under the logarithmic loss [51,52], which corresponds to soft decoding of each source symbol. Finally, one can also explore extensions to continuous alphabet by considering Gaussian memoryless sources under bounded distortion measures and derive second-order asymptotics [44,53,54,55,56] for the causal successive refinement problem.
Author Contributions
Formal analysis, L.Z.; Funding acquisition, A.H.; Supervision, A.H.; Writing—original draft, L.Z.; Writing—review & editing, A.H.
Funding
This work was partially supported by ARO grant W911NF-15-1-0479.
Acknowledgments
The authors acknowledge anonymous reviewers for helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Replacing (6) with Definition 2, we can define the -rate-distortion region under the average distortion criterion. Furthermore, let
Maor and Merhav [1] showed that for ,
Actually, in Section 7 of [1], in order to prove that , it was already shown that . Furthermore, it is straightforward to show that the above results hold for any finite . Thus, to prove Theorem 1, it suffices to show
For this purpose, given any , let
From the problem formulation, we know that for all . Now consider any rate-distortion tuple , then we have (4) to (6). Therefore, for any ,
As a result, we have . Thus establishes that .
Appendix B. Proof of Lemma 2
Recall the definition of G and in (30). Given any and , let be arbitrary distributions. For simplicity, given each , we use to denote and use to denote where . Similarly we use and .
Given any positive real number , define the following sets:
Then we have the following non-asymptotic upper bound on the probability of correct decoding.
Lemma A1.
Given any -code satisfying (25) and any distortion levels , we have
The proof of Lemma A1 is given in Appendix C.
In the remainder of this subsection, we single-letterize the bound in Lemma A1. Recall that given any , we use to denote . Recalling that the distributions starting with P are all induced by the joint distribution in (31) and using the choice of auxiliary random variables , we have
where (A16) follows from the Markov chain , (A19) follows from the Markov chain , (A22) follows from the Markov chain , and (A25) follows from the Markov chain .
Furthermore, recall that for , are arbitrary distributions where and . Please note that Lemma A1 holds for arbitrary choices of distributions where and . The proof of Lemma 2 is completed by using Lemma A1 with the following choices of auxiliary distributions and noting that :
Appendix C. Proof of Lemma A1
Recall the definition of the probability of correct decoding in (24) and the definitions of sets in (A7) to (A13). For any -code, we have that
where (A34) follows from the union bound and the fact that for any two sets and . The proof of Lemma A1 is completed by showing that
In the remainder of this subsection, we show that (A35) holds. Recall the joint distribution of G in (31). In the following, when we use a (conditional) distribution starting with P, we mean that the (conditional) distribution is induced by the joint distribution in (31).
Using the definition of in (A7),
Similarly to (A37), it follows that
Furthermore, using the definition of in (A10) and the union bound,
Furthermore, using the definition of in (A11),
where (A49) follows since for all , and (A51) follows since .
Using the definition of in (A12) and the union bound similarly to (A47), it follows that
where (A53) follows since for all and (A55) follows since .
Appendix D. Proof of Lemma 3
For any satisfying (15), for , define (cf. (33) to (36)) and for , define
Furthermore, let
Using Lemma 2 and definitions in (A56) to (A59), we obtain that
where (A62) follows from Cramér’s bound in Lemma 13 of [31] and (A63) follows from the definition of in (42).
Choose such that
i.e.,
The proof of Lemma 3 is completed by combining (A63) and (A65).
Appendix E. Proof of Lemma 4
Recall that for each , we use to denote and use similarly. Recall that the auxiliary random variables are chosen as and for all . Using the definition of in (41), define
Recall the joint distribution of G in (31). For each , define
Combining (42) and (A69),
Furthermore, similar to Lemma 5 of [25], we obtain the following lemma, which is critical in the proof of Lemma 4.
Lemma A2.
For each ,
Furthermore, for each , define
Using Lemma A2 and (A74), it follows that for each ,
Recall that the auxiliary distributions can be arbitrary distributions. Following the recursive method in [25], for each , we choose such that
Let , where and , be induced by . Using the definition of in (A66), we define
In the following, for simplicity, we let . Combining (A74) and (A75), we obtain that for each ,
where (A80) results from Hölder’s inequality, (A81) follows from the definitions of in (17) and in (A77), (A82) follows from the result in (46), and (A84) follows from the definition of in (18) and the fact it is sufficient to consider distributions with cardinality bounds and for the optimization problem in (A83) (the proof of this fact is similar to Property 4(a) in [25] and thus omitted).
The proof of Lemma 4 is completed by combining (A72) and (A84).
Appendix F. Proof of Lemma 6
Appendix F.1. Proof of Claim (i)
For any (see (14)), let (see (53)) be chosen such that and for all .
In the following, we drop the subscript of distributions when there is no confusion. For any satisfying (15) and
using the definition of in (17), we obtain
where (A87) follows since (i) with our choice of , we have
and (ii) the following equality holds
Equation (A89) follows from Hölder’s inequality, (A90) follows from the concavity of for and the choice of which ensures for all , (A92) follows by applying Hölder’s inequality and recalling that , and (A93) follows from the definition of in (58).
Therefore, for any satisfying (15) and (A85), using the definition of in (18) and the result in (A93), we have that
Recalling the definition of in (21) and using the result in (A96), we have
where (A100) follows since
and (A101) follows by choosing and (A102) follows from the definition of in (62).
Appendix F.2. Proof of Claim (ii)
Recall the definitions of in (57) and in (63). By simple calculation, one can verify that
Applying Taylor expansion to at around and combining (A105), (A106), we have that for any and any , there exists such that
where (A108) follows from the definitions in (57), (63) and (64).
Using the definitions in (54), (57) and (60) and the result in (A108), we have that for any ,
For any rate-distortion tuple outside the rate-distortion region, i.e., , from Lemma 5, we conclude that there exists satisfying (15) such that for some positive
Using the definition of in (62), we have
where (A114) follows from the results in (A110), (A111) and the inequality
resulting from the constraints that satisfying (15) and .
References
- Maor, A.; Merhav, N. On Successive Refinement with Causal Side Information at the Decoders. IEEE Trans. Inf. Theory 2008, 54, 332–343. [Google Scholar] [CrossRef]
- Tian, C.; Diggavi, S.N. On multistage successive refinement for Wyner–Ziv source coding with degraded side informations. IEEE Trans. Inf. Theory 2007, 53, 2946–2960. [Google Scholar] [CrossRef]
- Steinberg, Y.; Merhav, N. On successive refinement for the Wyner-Ziv problem. IEEE Trans. Inf. Theory 2004, 50, 1636–1654. [Google Scholar] [CrossRef]
- Equitz, W.H.; Cover, T.M. Successive refinement of information. IEEE Trans. Inf. Theory 1991, 37, 269–275. [Google Scholar] [CrossRef]
- Koshelev, V. Estimation of mean error for a discrete successive-approximation scheme. Probl. Peredachi Informatsii 1981, 17, 20–33. [Google Scholar]
- Rimoldi, B. Successive refinement of information: Characterization of the achievable rates. IEEE Trans. Inf. Theory 1994, 40, 253–259. [Google Scholar] [CrossRef]
- Kanlis, A.; Narayan, P. Error exponents for successive refinement by partitioning. IEEE Trans. Inf. Theory 1996, 42, 275–282. [Google Scholar] [CrossRef]
- No, A.; Ingber, A.; Weissman, T. Strong Successive Refinability and Rate-Distortion-Complexity Tradeoff. IEEE Trans. Inf. Theory 2016, 62, 3618–3635. [Google Scholar] [CrossRef]
- Zhou, L.; Tan, V.Y.F.; Motani, M. Second-Order and Moderate Deviation Asymptotics for Successive Refinement. IEEE Trans. Inf. Theory 2017, 63, 2896–2921. [Google Scholar] [CrossRef]
- Tuncel, E.; Rose, K. Additive successive refinement. IEEE Trans. Inf. Theory 2003, 49, 1983–1991. [Google Scholar] [CrossRef]
- Chow, J.; Berger, T. Failure of successive refinement for symmetric Gaussian mixtures. IEEE Trans. Inf. Theory 1997, 43, 350–352. [Google Scholar] [CrossRef]
- Tuncel, E.; Rose, K. Error exponents in scalable source coding. IEEE Trans. Inf. Theory 2003, 49, 289–296. [Google Scholar] [CrossRef]
- Effros, M. Distortion-rate bounds for fixed- and variable-rate multiresolution source codes. IEEE Trans. Inf. Theory 1999, 45, 1887–1910. [Google Scholar] [CrossRef]
- Weissman, T.; Gamal, A.E. Source Coding With Limited-Look-Ahead Side Information at the Decoder. IEEE Trans. Inf. Theory 2006, 52, 5218–5239. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Timo, R.; Vellambi, B.N. Two lossy source coding problems with causal side-information. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, South Korea, 28 June–3 July 2009; pp. 1040–1044. [Google Scholar] [CrossRef]
- Gu, W.H.; Effros, M. Source coding for a simple multi-hop network. In Proceedings of the International Symposium on Information Theory (ISIT 2005), Adelaide, SA, Australia, 4–9 September 2005. [Google Scholar]
- Gray, R.; Wyner, A. Source coding for a simple network. Bell Syst. Tech. J. 1974, 53, 1681–1721. [Google Scholar] [CrossRef]
- Maor, A.; Merhav, N. On Successive Refinement for the Kaspi/Heegard–Berger Problem. IEEE Trans. Inf. Theory 2010, 56, 3930–3945. [Google Scholar] [CrossRef]
- Heegard, C.; Berger, T. Rate distortion when side information may be absent. IEEE Trans. Inf. Theory 1985, 31, 727–734. [Google Scholar] [CrossRef]
- Chia, Y.K.; Weissman, T. Cascade and Triangular source coding with causal side information. In Proceedings of the 2011 IEEE International Symposium on Information Theory Proceedings, St. Petersburg, Russia, 31 July–5 August 2011; pp. 1683–1687. [Google Scholar] [CrossRef]
- Fong, S.L.; Tan, V.Y.F. A Proof of the Strong Converse Theorem for Gaussian Multiple Access Channels. IEEE Trans. Inf. Theory 2016, 62, 4376–4394. [Google Scholar] [CrossRef]
- Oohama, Y. Exponent Function for One Helper Source Coding Problem at Rates outside the Rate Region. arXiv 2015, arXiv:1504.05891. [Google Scholar]
- Oohama, Y. New Strong Converse for Asymmetric Broadcast Channels. arXiv 2016, arXiv:1604.02901. [Google Scholar]
- Oohama, Y. Exponential Strong Converse for Source Coding with Side Information at the Decoder. Entropy 2018, 20, 352. [Google Scholar] [CrossRef]
- Ahlswede, R.; Korner, J. Source coding with side information and a converse for degraded broadcast channels. IEEE Trans. Inf. Theory 1975, 21, 629–637. [Google Scholar] [CrossRef]
- Wyner, A.D. On source coding with side information at the decoder. IEEE Trans. Inf. Theory 1975, 21, 294–300. [Google Scholar] [CrossRef]
- Korner, J.; Marton, K. General broadcast channels with degraded message sets. IEEE Trans. Inf. Theory 1977, 23, 60–64. [Google Scholar] [CrossRef]
- Wyner, A.D.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Tuncel, E.; Gündüz, D. Identification and Lossy Reconstruction in Noisy Databases. IEEE Trans. Inf. Theory 2014, 60, 822–831. [Google Scholar] [CrossRef]
- Zhou, L.; Tan, V.Y.F.; Motani, M. Exponential Strong Converse for Content Identification with Lossy Recovery. IEEE Trans. Inf. Theory 2018, 64, 5879–5897. [Google Scholar] [CrossRef]
- Wyner, A. The common information of two dependent random variables. IEEE Trans. Inf. Theory 1975, 21, 163–179. [Google Scholar] [CrossRef]
- Yu, L.; Tan, V.Y.F. Wyner’s Common Information Under Rényi Divergence Measures. IEEE Trans. Inf. Theory 2018, 64, 3616–3632. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Gu, W.; Effros, M. A strong converse for a collection of network source coding problems. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, South Korea, 28 June–3 July 2009; pp. 2316–2320. [Google Scholar] [CrossRef]
- Liu, J.; van Handel, R.; Verdú, S. Beyond the Blowing-Up Lemma: Optimal Second-Order Converses via Reverse Hypercontractivity. Preprint. Available online: http://web.mit.edu/jingbo/www/preprints/msl-blup.pdf (accessed on 17 April 2019).
- Tyagi, H.; Watanabe, S. Strong Converse using Change of Measure. arXiv 2018, arXiv:1805.04625. [Google Scholar]
- Ahlswede, R.; Csiszár, I. Hypothesis testing with communication constraints. IEEE Trans. Inf. Theory 1986, 32, 533–542. [Google Scholar] [CrossRef]
- Salehkalaibar, S.; Wigger, M.; Wang, L. Hypothesis testing in multi-hop networks. arXiv 2017, arXiv:1708.05198. [Google Scholar]
- Cao, D.; Zhou, L.; Tan, V.Y.F. Strong Converse for Hypothesis Testing Against Independence over a Two-Hop Network. arXiv 2018, arXiv:1808.05366. [Google Scholar]
- Marton, K. Error exponent for source coding with a fidelity criterion. IEEE Trans. Inf. Theory 1974, 20, 197–199. [Google Scholar] [CrossRef]
- Yassaee, M.H.; Aref, M.R.; Gohari, A. A technique for deriving one-shot achievability results in network information theory. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 1287–1291. [Google Scholar]
- Kostina, V.; Verdú, S. Fixed-length lossy compression in the finite blocklength regime. IEEE Trans. Inf. Theory 2012, 58, 3309–3338. [Google Scholar] [CrossRef]
- Tan, V.Y.F. Asymptotic Estimates in Information Theory with Non-Vanishing Error Probabilities. Found. Trends Commun. Inf. Theory 2014, 11, 1–184. [Google Scholar] [CrossRef]
- Pradhan, S.S.; Chou, J.; Ramchandran, K. Duality between source coding and channel coding and its extension to the side information case. IEEE Trans. Inf. Theory 2003, 49, 1181–1203. [Google Scholar] [CrossRef]
- Slepian, D.; Wolf, J.K. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Gelfand, S. Coding for channel with random parameters. Probl. Contr. Inf. Theory 1980, 9, 19–31. [Google Scholar]
- Shannon, C.E. Channels with side information at the transmitter. IBM J. Res. Dev. 1958, 2, 289–293. [Google Scholar] [CrossRef]
- Sigurjónsson, S.; Kim, Y.H. On multiple user channels with state information at the transmitters. In Proceedings of the International Symposium on Information Theory (ISIT 2005), Adelaide, SA, Australia, 4–9 September 2005; pp. 72–76. [Google Scholar]
- Zaidi, A.; Shitz, S.S. On cooperative multiple access channels with delayed CSI at transmitters. IEEE Trans. Inf. Theory 2014, 60, 6204–6230. [Google Scholar] [CrossRef]
- Shkel, Y.Y.; Verdú, S. A single-shot approach to lossy source coding under logarithmic loss. IEEE Trans. Inf. Theory 2018, 64, 129–147. [Google Scholar] [CrossRef]
- Courtade, T.A.; Weissman, T. Multiterminal source coding under logarithmic loss. IEEE Trans. Inf. Theory 2014, 60, 740–761. [Google Scholar] [CrossRef]
- Strassen, V. Asymptotische abschätzungen in shannons informationstheorie. In Transactions of the Third Prague Conference on Information Theory etc; Czechoslovak Academy of Sciences: Prague, Czech Republic, 1962; pp. 689–723. [Google Scholar]
- Hayashi, M. Information spectrum approach to second-order coding rate in channel coding. IEEE Trans. Inf. Theory 2009, 55, 4947–4966. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Poor, H.V.; Verdú, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Kostina, V. Lossy Data Compression: Non-Asymptotic Fundamental Limits. Ph.D. Thesis, Department of Electrical Engineering, Princeton University, Princeton, NJ, USA, 2013. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).