Large-Scale Person Re-Identification Based on Deep Hash Learning

Abstract
1. Introduction
2. Related Work
3. CFNPHL Methods
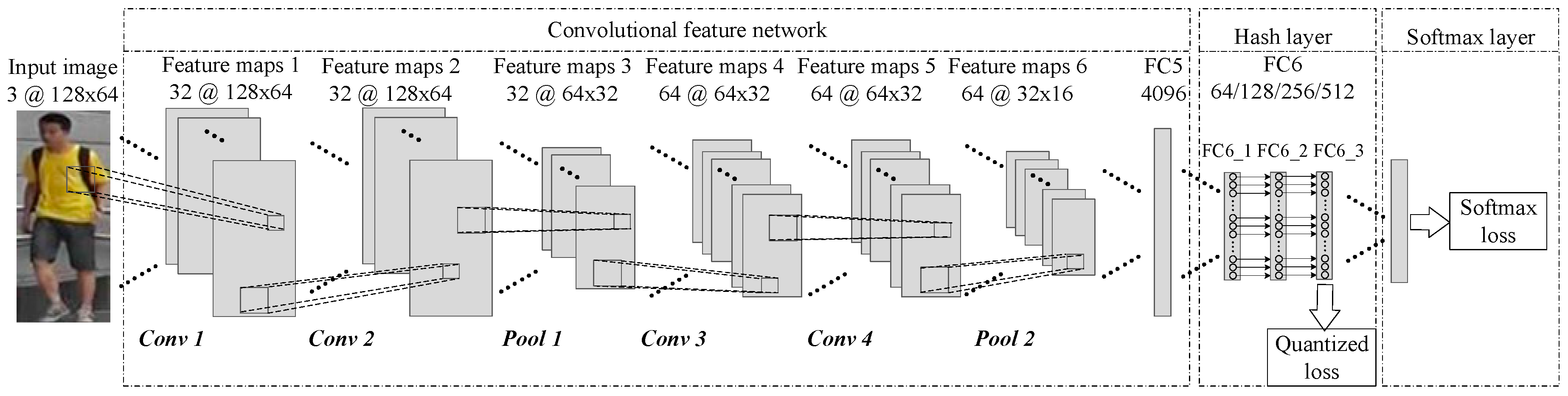
3.1. Convolutional Feature Network
3.2. Hash Layer of the Network
3.3. Loss Function of Network
3.3.1. Quantized Loss Function of the FC6_3 layer in the Hash Layer.
3.3.2. The Softmax Cross-Entropy Loss Function
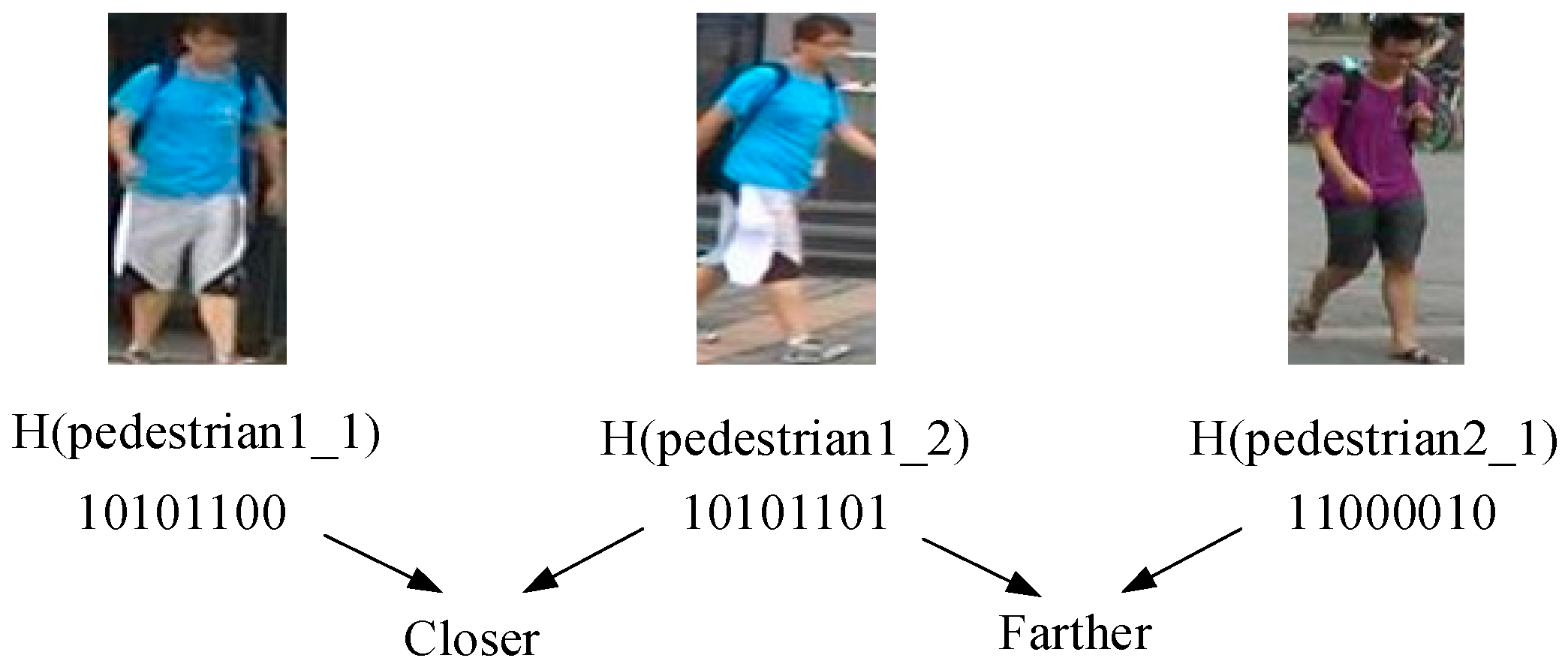
3.4. Distance Re-Identification of Hash Code in a Pedestrian Image
4. Experiments
4.1. Datasets
4.2. Settings
4.3. Results and Analysis
4.3.1. Comparison Across Diverse Hash Methods
4.3.2. Influence of Variant Dimension of Hash Code on CMC and mAP
4.3.3. Ignorance of the Quantized Loss Function Proposed
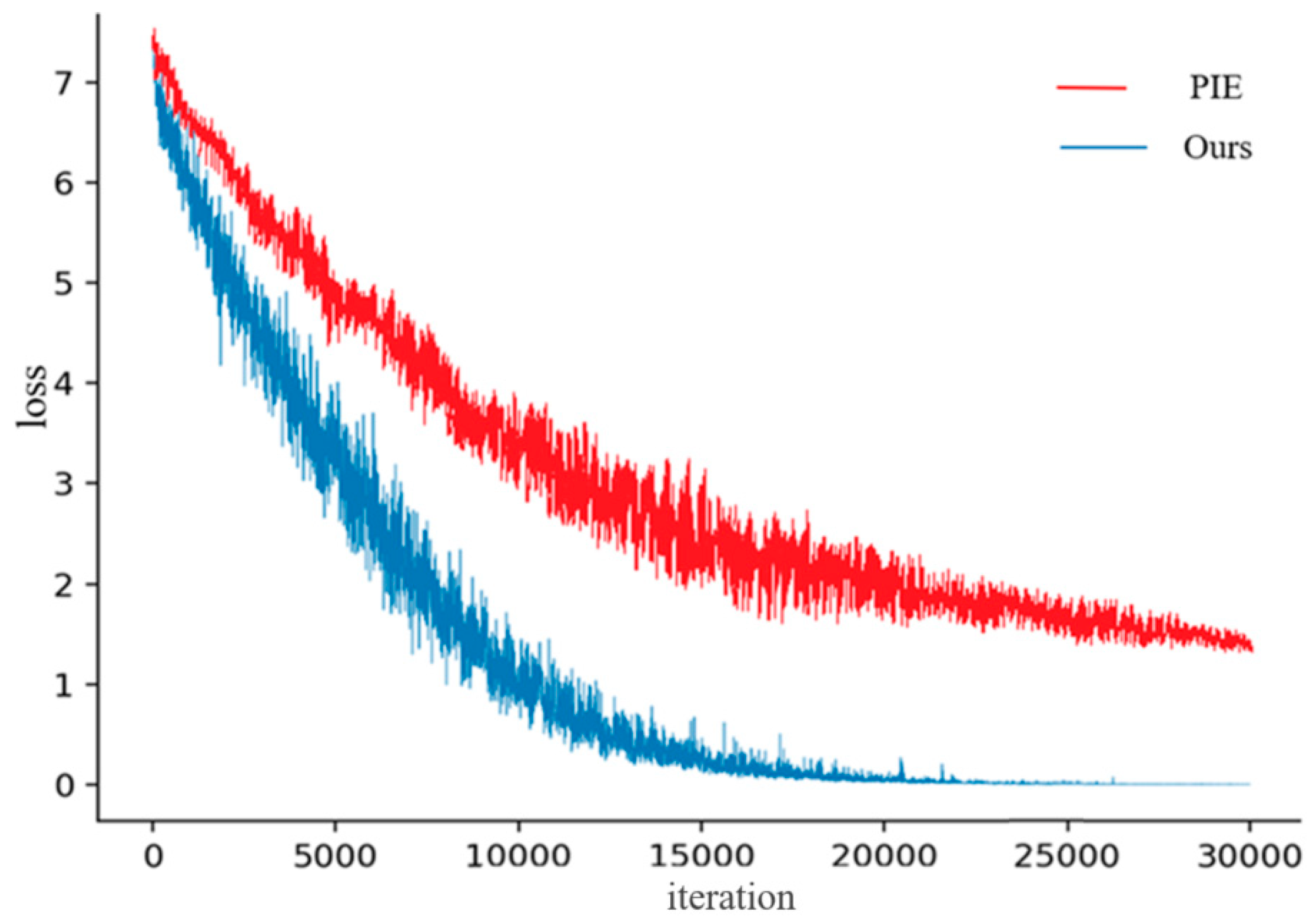
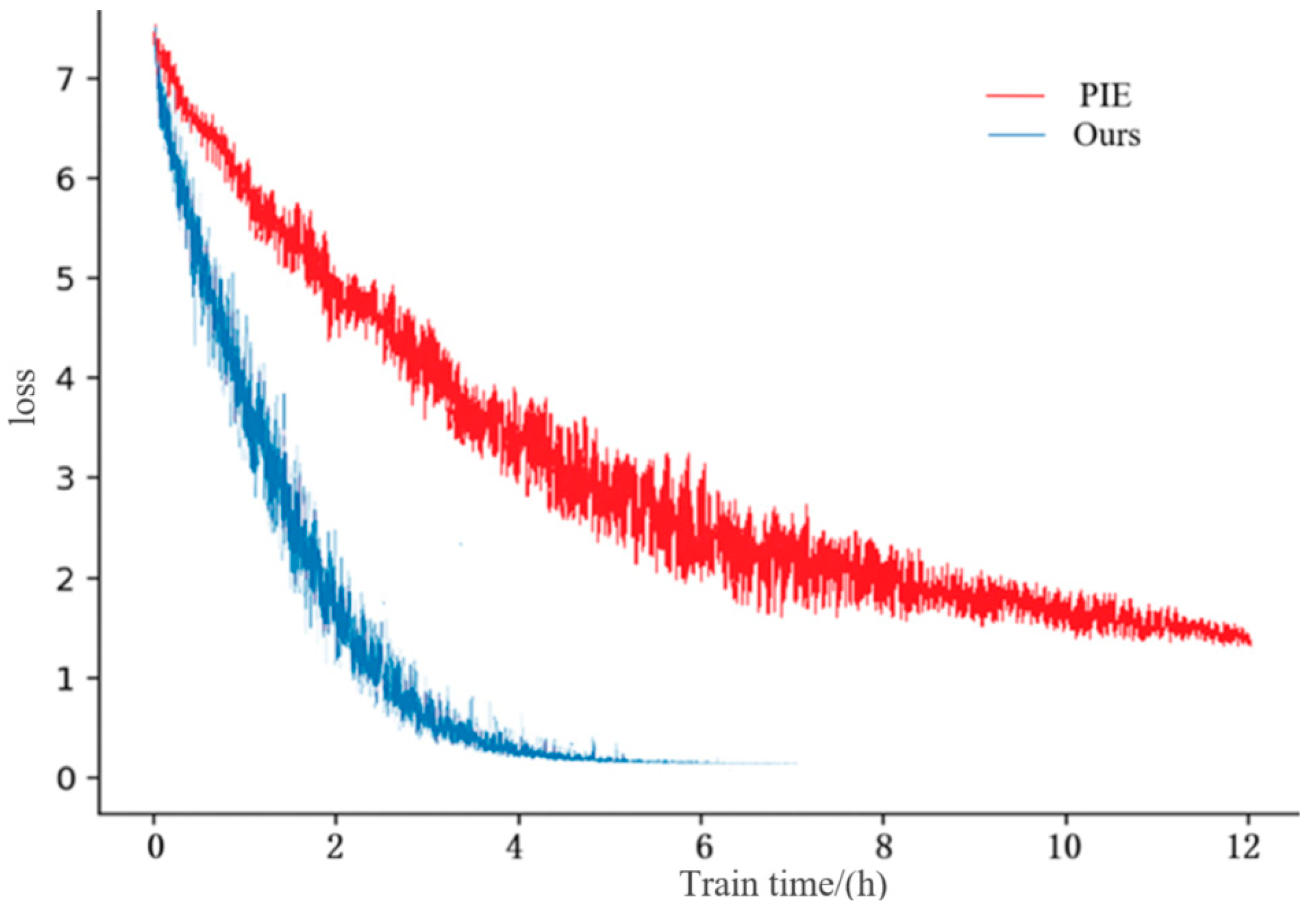
4.3.4. Comparative Experiment Analysis of Pedestrian Re-Identification on the PIE Method
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, C.; Chen, C.L.; Chen, C.L.; Lin, X.G. Person re-identification: What Features Are Important? European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 391–401. [Google Scholar]
- Gray, D.; Brennan, S.; Tao, H. Evaluating appearance models for recognition, reacquisition, and tracking. In Proceedings of the IEEE International Workshop on Performance Evaluation for Tracking and Surveillance, Rio de Janeiro, Brizil, 20 September 2007. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Davis, J.V.; Kulis, B.; Jain, P.; Sra, S.; Dhillon, I. Information-theoretic metric learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–26 June 2007; pp. 209–216. [Google Scholar]
- Wang, J.; Kumar, S.; Chang, S.-F. Semi-supervised hashing for scalable image re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3424–3431. [Google Scholar]
- Chen, S.Z.; Guo, C.C.; Lai, J.H. Deep Ranking for Person Re-identification via Joint Representation Learning. IEEE Trans. Image Process. 2015, 25, 2353–2367. [Google Scholar] [CrossRef] [PubMed]
- Datarm, M.; Immorlicam, N.; Indyk, P.; Mirroknim, V.S. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, New York, NY, USA, 8–11 June 2004; pp. 253–262. [Google Scholar]
- Gong, Y.; Lazebnik, S. Iterative quantization: A procrustean approach to learning binary codes. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 35, 2916–2929. [Google Scholar] [CrossRef] [PubMed]
- Weissm, Y.; Torralbam, A.; Fergus, R. Spectral hashing. In Proceedings of the 21st International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10December 2008. [Google Scholar]
- Yum, X.; Zhangm, S.; Lium, B.; Linm, Z.; Metaxasm, D. Large-Scale Medical Image Search via Unsupervised PCA Hashing. In Proceedings of the Computer Vision & Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Jin, Z.; Li, C.; Lin, Y.; Cai, D. Density Sensitive Hashing. IEEE Trans. Cybern. 2013, 44, 1362–1371. [Google Scholar] [CrossRef]
- Heo, J.P.; Lee, Y.; He, J.; Chang, S.; Yoon, S. Spherical hashing. In Proceedings of the CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Zhu, X.; Zhang, L.; Huang, Z. A Sparse Embedding and Least Variance Encoding Approach to Hashing. IEEE Trans. Image Process. 2014, 23, 3737–3750. [Google Scholar] [CrossRef] [PubMed]
- Kulis, B.; Darrell, T. Learning to Hash with Binary Reconstructive Embeddings. In Proceedings of the NIPS’09 Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009. [Google Scholar]
- Norouzi, M.E.; Fleet, D.J. Minimal Loss Hashing for Compact Binary Codes. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June– 2 July 2011. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. Semantic hashing. Inter. J. Approx. Reason. 2009, 50, 969–978. [Google Scholar] [CrossRef]
- Xia, R.; Pan, Y.; Lai, H. Supervised hashing for image re-identification via image representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec, Canada, 27–31 July 2014. [Google Scholar]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-Scalable Deep Hashing with Regularized Similarity Learning for Image Re-identification and Person Re-Identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef] [PubMed]
- Peng, T.; Li, F. Image Re-identification Based on Deep Convolutional Neural Networks and Binary Hashing Learning. J. Electron. Inform. Technol. 2016, 38, 2068–2075. [Google Scholar]
- Bazzani, L.; Cristani, M.; Murino, V. Symmetry-driven accumulation of local features for human characterization and re-identification. Comput. Vis. Image Und. 2013, 117, 130–144. [Google Scholar] [CrossRef]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S. Person re-identification by Local Maximal Occurrence representation and metric learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lisanti, G.; Karaman, S.; Masi, I. Multichannel-Kernel Canonical Correlation Analysis for Cross-View Person Reidentification. ACM Trans. Multimedia Comput. Communi. Appli. 2017, 13, 1–19. [Google Scholar] [CrossRef]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical Gaussian Descriptor for Person Re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yang, Y.; Yang, J.; Yan, J.; Liao, S.; Yi, D.; Li, S. Salient Color Names for Person Re-identification. Lect. Note. Comput. Sci. 2014, 8689, 536–551. [Google Scholar]
- Zhao, R.; Ouyang, W.; Wang, X. Unsupervised Salience Learning for Person Re-identification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose Invariant Embedding for Deep Person Re-identification. arXiv 2017, arXiv:1701.07732. [Google Scholar] [CrossRef] [PubMed]
- Geng, M.; Wang, Y.; Xiang, T.; Tian, Y. Deep Transfer Learning for Person Re-identification. arXiv 2016, arXiv:1611.05244. [Google Scholar]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Yang, Y. Improving Person Re-identification by Attribute and Identity Learning. arXiv 2017, arXiv:1703.07220. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Matsukawa, T.; Suzuki, E. Person re-identification using CNN features learned from combination of attributes. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated Siamese Convolutional Neural Network Architecture for Human Re-Identification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Liu, H.; Feng, J.; Qi, M.; Jiang, J.; Yan, S. End-to-End Comparative Attention Networks for Person Re-identification. IEEE Trans. Image Process. 2017. [Google Scholar] [CrossRef]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 201.
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond triplet loss: A deep quadruplet network for person re-identification. arXiv 2017, arXiv:1704.01719. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro. arXiv 2017, arXiv:1701.07717. [Google Scholar]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camera Style Adaptation for Person Re-identification. arXiv 2018, arXiv:1711.10295. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. arXiv 2017, arXiv:1711.08565. [Google Scholar]
- Qian, X.; Fu, Y.; Xiang, T.; Wang, W.; Wu, Y.; Jiang, Y.; Xue, X. Pose-Normalized Image Generation for Person Re-identification. arXiv 2017, arXiv:1712.02225. [Google Scholar]
- Li, W.; Wang, X. Locally Aligned Feature Transforms across Views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3594–3601. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. arXiv 2016, arXiv:1609.01775. [Google Scholar]
- Turpin, A.; Scholer, F. User performance versus precision measures for simple search tasks. In Proceedings of the SIGIR ‘06 Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 11–18. [Google Scholar]
- Liu, C. POP: Person Re-identification Post-rank Optimisation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Parameter Setting |
|---|---|---|
| Conv1 | 128 × 64 × 32 | 3 × 3, 32, pad = 0 |
| Conv2 | 128 × 64 × 32 | 3 × 3, 32, pad = 0 |
| Pool1 | 64 × 32 × 32 | 2 × 2, max pool, stride = 2 |
| Conv3 | 64 × 32 × 64 | 3 × 3, 64, pad = 0 |
| Conv4 | 64 × 32 × 64 | 3 × 3, 64, pad = 0 |
| Pool2 | 32 × 16 × 64 | 2 × 2, max pool, stride = 2 |
| FC5 | 4096 | 4096 |
| Method | CUHK02 [40] | Market-1501 [41] | DukeMTMC [42] | |||
|---|---|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | Rank-1 | mAP | |
| LSH [7] | 20.3 | 17.1 | 23.5 | 21.6 | 23.3 | 20.5 |
| PCA-RR [8] | 26.8 | 24.1 | 34.3 | 29.5 | 29.5 | 27.6 |
| SH [9] | 18.1 | 16 | 28.6 | 25.9 | 27.9 | 24.1 |
| PCAH [10] | 14.3 | 13 | 18.9 | 16.5 | 15.4 | 11.5 |
| SPH [12] | 21.4 | 19.5 | 28.4 | 24.2 | 26.3 | 23.3 |
| SELVE [13] | 15.7 | 12.5 | 19.2 | 16.4 | 16.1 | 12.4 |
| BRE [14] | 23.4 | 21.9 | 30.4 | 26.1 | 25.4 | 23.4 |
| MLH [15] | 27.7 | 25.3 | 35.1 | 29.3 | 28.8 | 26.0 |
| Our | 29.3 | 27.5 | 38.1 | 34.4 | 31.5 | 30.2 |
| Dataset | Hash Code Dimension | CMC | mAP | |||
|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | Rank-20 | |||
| CUHK02 [40] | 64 | 14.2 | 18.1 | 25.4 | 31.9 | 13.3 |
| 128 | 24.1 | 31.3 | 39.2 | 46.7 | 22.1 | |
| 256 | 29.3 | 34.4 | 44.3 | 51.8 | 27.5 | |
| 512 | 33.1 | 40.2 | 47.4 | 57.2 | 31.4 | |
| Market-1501 [41] | 64 | 17.4 | 24.2 | 29.6 | 40.1 | 17.1 |
| 128 | 27.2 | 31.1 | 36.4 | 47 | 25.9 | |
| 256 | 33.1 | 35.4 | 45.9 | 56.3 | 31.2 | |
| 512 | 38.1 | 46.3 | 55.2 | 65.8 | 34.4 | |
| DukeMTMC [42] | 64 | 15.1 | 17.2 | 22.3 | 28.3 | 14.5 |
| 128 | 25.5 | 30.3 | 39.1 | 42.5 | 24.1 | |
| 256 | 31.5 | 38.1 | 40.5 | 46.1 | 30.2 | |
| 512 | 36.5 | 40.5 | 47.8 | 54.9 | 33.5 | |
| Dataset | Method | CMC | mAP | |||
|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | Rank-20 | |||
| CUHK02 [40] | Our- | 24.2 | 32.8 | 41.9 | 49.3 | 20.2 |
| Our | 29.3 | 34.4 | 44.3 | 51.8 | 27.5 | |
| Market-1501 [41] | Our- | 28.7 | 31.0 | 40.8 | 53.2 | 25.4 |
| Our | 33.1 | 35.4 | 45.9 | 56.3 | 31.2 | |
| DukeMTMC [42] | Our- | 27.3 | 34.9 | 0.371 | 0.413 | 24.3 |
| Our | 31.5 | 38.1 | 40.5 | 46.1 | 30.2 | |
| Method | Rank-1 | mAP |
|---|---|---|
| PIE [26] | 78.65 | 53.87 |
| Ours | 38.1 | 34.4 |
| Method | Test Time (min) | |||
|---|---|---|---|---|
| PIE [26] | 25.3 | |||
| Ours | 64 bits | 128 bits | 256 bits | 512 bits |
| 5.4 | 7.1 | 11.5 | 17.7 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.-Q.; Yu, C.-C.; Chen, X.-X.; Zhou, L. Large-Scale Person Re-Identification Based on Deep Hash Learning. Entropy 2019, 21, 449. https://doi.org/10.3390/e21050449
Ma X-Q, Yu C-C, Chen X-X, Zhou L. Large-Scale Person Re-Identification Based on Deep Hash Learning. Entropy. 2019; 21(5):449. https://doi.org/10.3390/e21050449
Chicago/Turabian StyleMa, Xian-Qin, Chong-Chong Yu, Xiu-Xin Chen, and Lan Zhou. 2019. "Large-Scale Person Re-Identification Based on Deep Hash Learning" Entropy 21, no. 5: 449. https://doi.org/10.3390/e21050449
APA StyleMa, X.-Q., Yu, C.-C., Chen, X.-X., & Zhou, L. (2019). Large-Scale Person Re-Identification Based on Deep Hash Learning. Entropy, 21(5), 449. https://doi.org/10.3390/e21050449