Approximate Entropy and Sample Entropy: A Comprehensive Tutorial

Abstract
:1. Introduction
2. Information and Complexity
2.1. Regularity Statistics
- A: 01010101010101010101
- B: 01101000110111100010
2.2. Information Theory
- Information is the decrease in ambiguity regarding a phenomenon, an increment to our knowledge when we observe a specific event. Realizations of a random variable with low probability are more surprising and add more information. Imagine a series of data whose values change so little that the next value is practically the same as the previous one. If there is an abrupt change and the value increases drastically (this random variable having a high value as an outcome is an event with low probability), there is a high gain of information. Mathematically, information is proportional to the inverse of the probability function of the event, . Therefore, information is an event which induces rational agents to change their beliefs and expectations about a particular situation, with the restrictions of the new information. In the previous example, very likely events (a flat series of data) give little information to the agents, while low probability outcomes (a sudden rise in the value) give more information that will change their beliefs about the process behind the data.
- Uncertainty is something which is possible but is unknown. It is possible that by throwing a dice we get the number five, but throwing a dice does not imply obtaining the number five. We have uncertainty about the number five, but we would not have it for the number 214 in a six-sided dice because it is an impossible event. In the context of IT, uncertainty is the amount of information we expect an experiment to reveal. If the distribution of probabilities is uniform, as in the case of the dice (), there is a maximum uncertainty and the result is more unpredictable. On the other hand, if the probability distribution is more concentrated (a loaded dice with a high probability of obtaining a six), then the result is more predictable and there is a lower uncertainty. Concerning the previous concept, low uncertainty means more information.
- Entropy (H) is a measure of the amount of uncertainty associated with a variable X when only its distribution is known. It is a measure of the amount of information we hope to learn from an outcome (observations), and we can understand it as a measure of uniformity. The more uniform the distribution, the higher the uncertainty and the higher the entropy. This definition is important because entropy will ultimately be used to measure the randomness of a series. The entropy H is a function of the probability distribution {} and not a function of the values of the variable in the particular series {}.
2.3. Towards a Measure of Complexity
3. Measuring Randomness
3.1. Approximate Entropy
- The ApEn statistic is independent of any model, which makes it suitable for the analysis of data series without taking into account anything else but the data.
- ApEn is very stable to large and infrequent outliers or numerical artifacts, like Shannon entropy. Large outliers are low probability events, which make a small contribution to the general measure. These events, however, are critical in moment statistics, since the differences between the values and the mean are quantified. Variability can detect deviations from the average value, but it does not worry about the regularity of the data. The best analysis of a series of data would be the combined use of regularity statistics and moment statistics. In this sense, ApEn has been shown to distinguish normal from abnormal data in instances where moment statistic approaches failed to show significant differences [21].
- Due to the construction of ApEn and its foundations in IT, the value of ApEn is non-negative. It is finite for stochastic processes and for deterministic processes with noise. ApEn has a value of 0 for perfectly regular series (as series A in the Section 2.1 or in the previous example).
- ApEn takes the value for totally random binary series, and, in general, the value for alphabets of k symbols [22].
- ApEp is not altered by translations or by scaling applied uniformly to all terms. ApEn is not invariant under coordinate transformations, hence scale must be fixed. Such non-invariance is also common to the differential entropy [19].
- In the original definition of ApEn, preserving order is a relative property. ApEn can vary significantly with the choice of m and r, so it is not an absolute measure. The key to ApEn’s utility is that its relativity is enough to discriminate systems. According to Pincus, in general, given two data series A and B, when ApEn ApEn then ApEn ApEn. However, in reality, this is not a general characteristic of ApEn, some pairs are fully consistent, but others are not [20].
- Non-linearity causes a greater value of ApEn [20].
- According to Pincus, from the statistical perspective, it is imperative to eliminate any trend before making meaningful interpretations from the statistical calculations [20]. However, the use of ApEn with raw data series has shown its effectiveness; in the next section we will discuss this in more detail.
- Any steady-state measure that emerges from a model of a deterministic dynamic system can be approximated with arbitrary precision by means of a stochastic Markov chain process [20]. ApEn is part of a general development as an entropy rate for a Markov chain which approximates a process [23], hence it can be used in deterministic and stochastic systems.
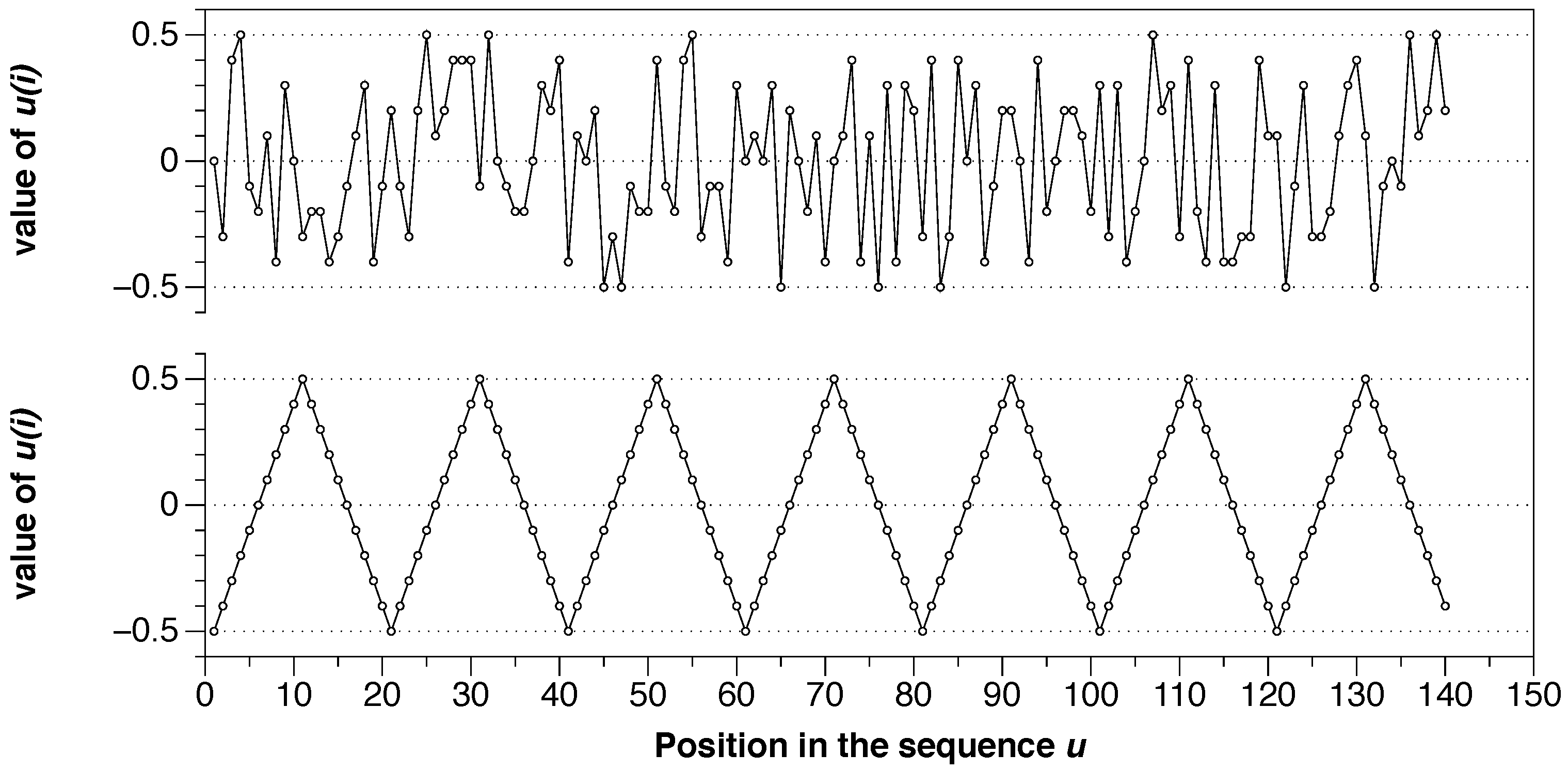
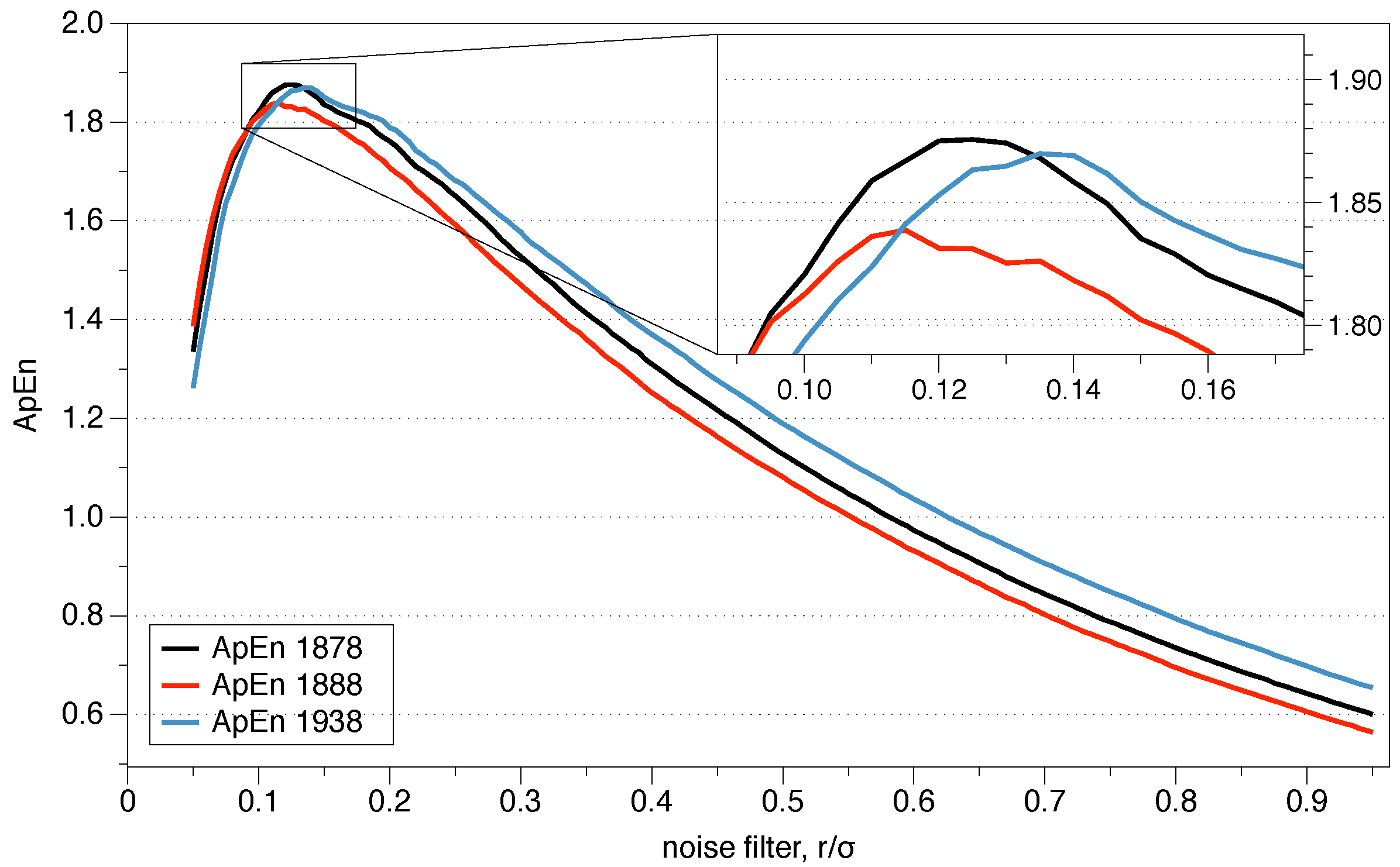
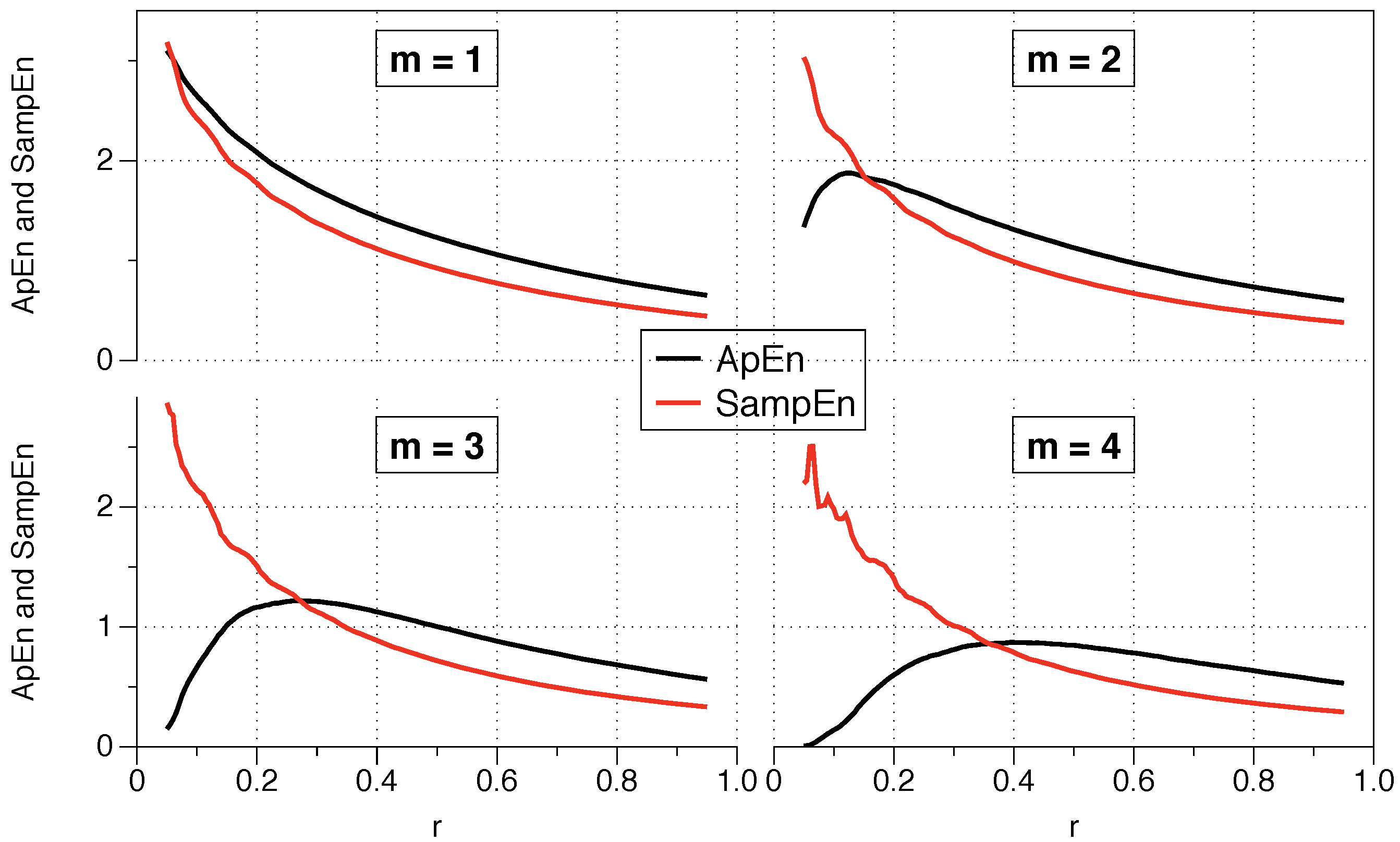
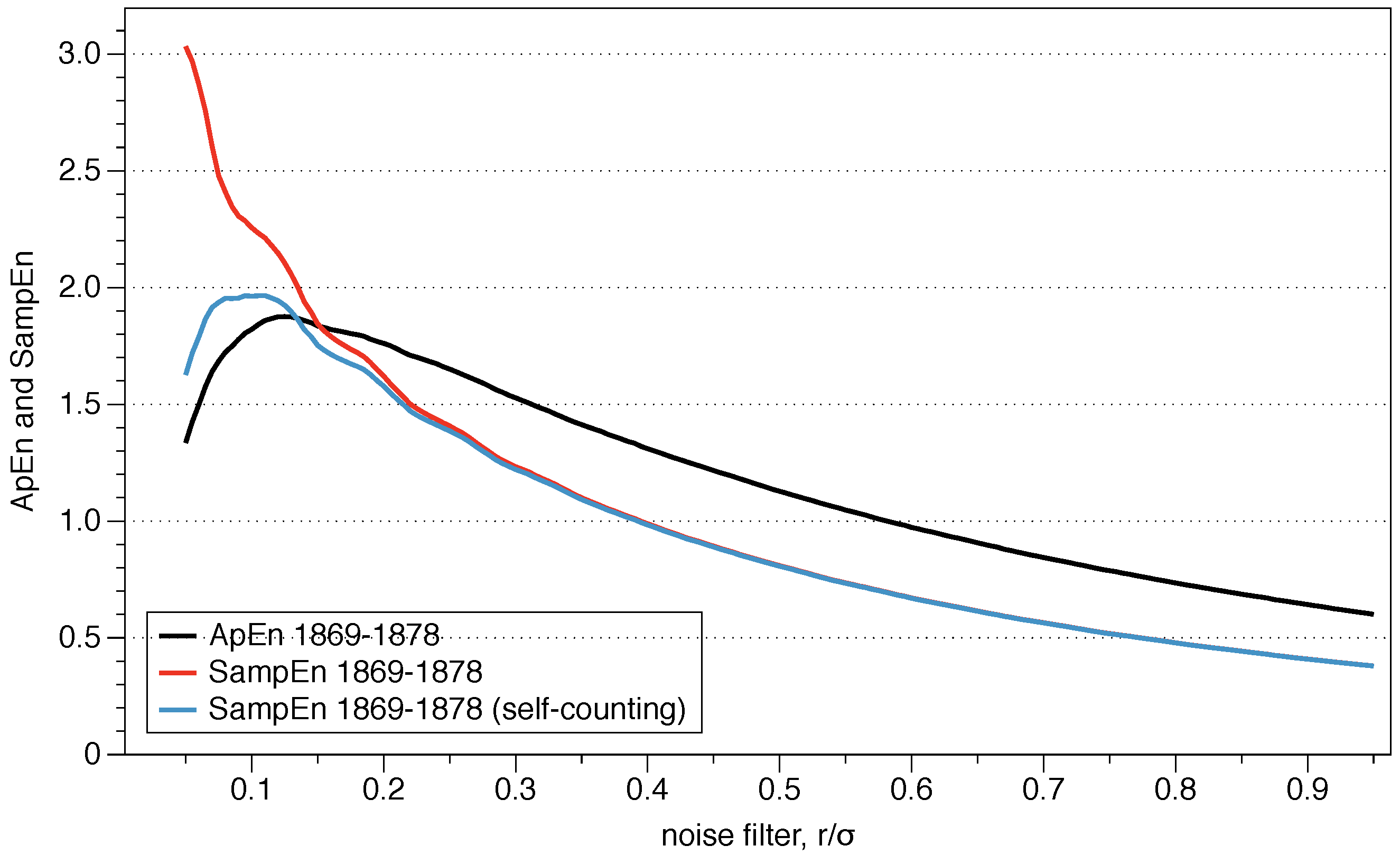
- Recommended values: m must be low, m = 2 or 3 are typical options, and r must be large enough to have a sufficient number of sequences of x-vectors within a distance r from most of the specified vectors, to ensure reasonable estimates of conditional probabilities. The recommended r values are generally in the range of 0.1 to 0.25 standard deviation of the series of data under analysis. ApEn grows with a decrease of r as , exhibiting an infinite variation with r, which implies a great variation in the value of the statistic ApEn with r. We will discuss about the selection of the parameter r and how it connects with the explained theoretical framework in the next Section.
- The number of data required to discriminate between systems is in the range of to , as in the case of chaos theory, but since m is usually a low value, even a series with a small number of data such as N = 100 is adequate for the analysis.
- Systems with a signal-to-noise ratio lower than three, i.e., situations in which the noise is substantial, would compromise the validity of ApEn calculations.
- The greater utility of ApEn arises when the means and the standard deviations of the systems show few changes with the evolution of the system. To compare different data series, it is recommended to normalize these series with respect to their standard deviation before the comparison .
- The ApEn algorithm makes use of the data vector instead of using the probabilities associated with the occurrence of each result . ApEn is directly applicable without knowing or assuming anything about the dataset or knowing anything about the process that generates the values.
- The ApEn algorithm require equally spaced measurements over time [7].
- ApEn is a biased statistic. ApEn increases asymptotically with N to ApEn, and the bias arises from two separate sources. First, in the calculation of the correlation integral the vector counts itself to ensure that the logarithms remain finite, underestimating the calculation of conditional probabilities as a consequence of it. If the number of matches between templates is low, the bias can be as high as 20% or 30%. The higher the number of points N, the lower the bias. Second, the concavity of the logarithm implies a bias in all the regularity statistics mentioned in the previous sections. The correlation integral is estimated from the sample value, but the Jensen inequality implies that [21].
- The standard deviation of ApEn(2, 0.15, 1000) determined through Monte Carlo simulations is less than 0.0055 for a large class of models, which indicates that ApEn’s small error bars provide practical utility for the analysis of data.
- If is a typical realization of a Bernuilli process, then entropy of the process [26].
3.2. Cross-ApEn
- cross-ApEn is used with stationary series .
- As the cross-ApEn algorithm analyzes one series versus another, there is no self-counting, so that source of bias which was present in ApEn does not exist in cross-ApEn. However, since the definition is equally logarithmic, it is required that there is at least one match in the pattern count in order to avoid the calculation of a logarithm of zero, situation in which cross-ApEn would remain undefined.
- Like ApEn, it does not verify relative consistency for all data series; therefore, the synchrony or asynchrony between series may depend on the chosen parameters.
- The use of two series, one as template and another as target, makes the analysis directional and depends on which one is the template series and which one is the target one, i.e., in general, cross-ApEn≠ cross-ApEn. If we remember the section on information theory, the Kullback-Leibler distance had the same limitation, .
- cross-ApEn may fail to judge the synchrony order of two series with respect to a third one [31], situation derived from the lack of relative consistency.
3.3. Sample Entropy
- SampEn does not allow self-counting () while ApEn does.
- The sum of all template vectors is inside the logarithm in SampEn and outside in ApEn. It implies that SampEn considers the complete series and if a template finds a match, then SampEn is already defined, while ApEn needs a match for each template. The Jensen’s inequality tells us that , so that term is greater in SampEn than in ApEn.
- ApEn includes a factor , which makes this statistic dependent on the size of the series, whereas SampEn does not include it.
3.4. Cross-SampEn
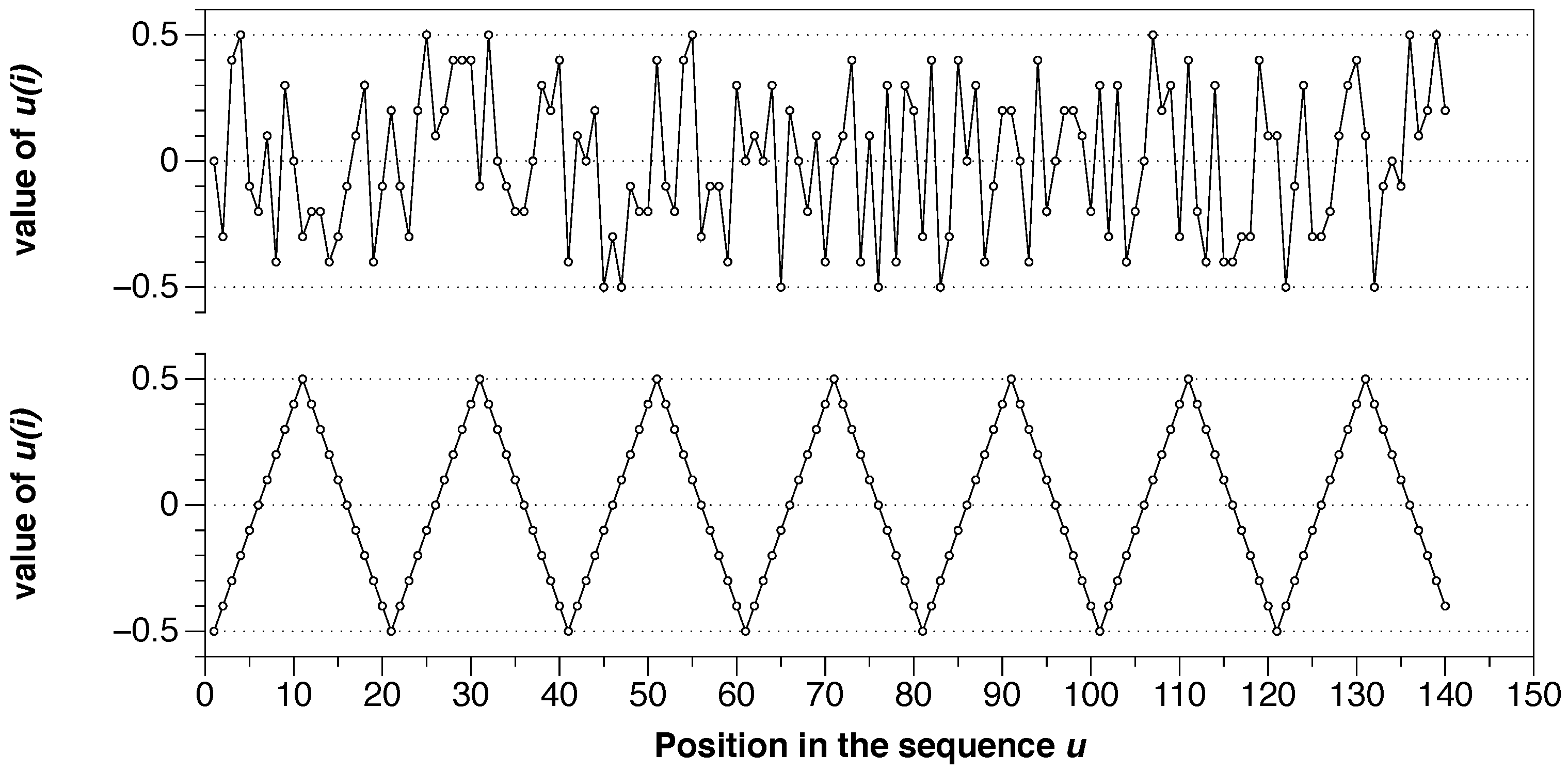
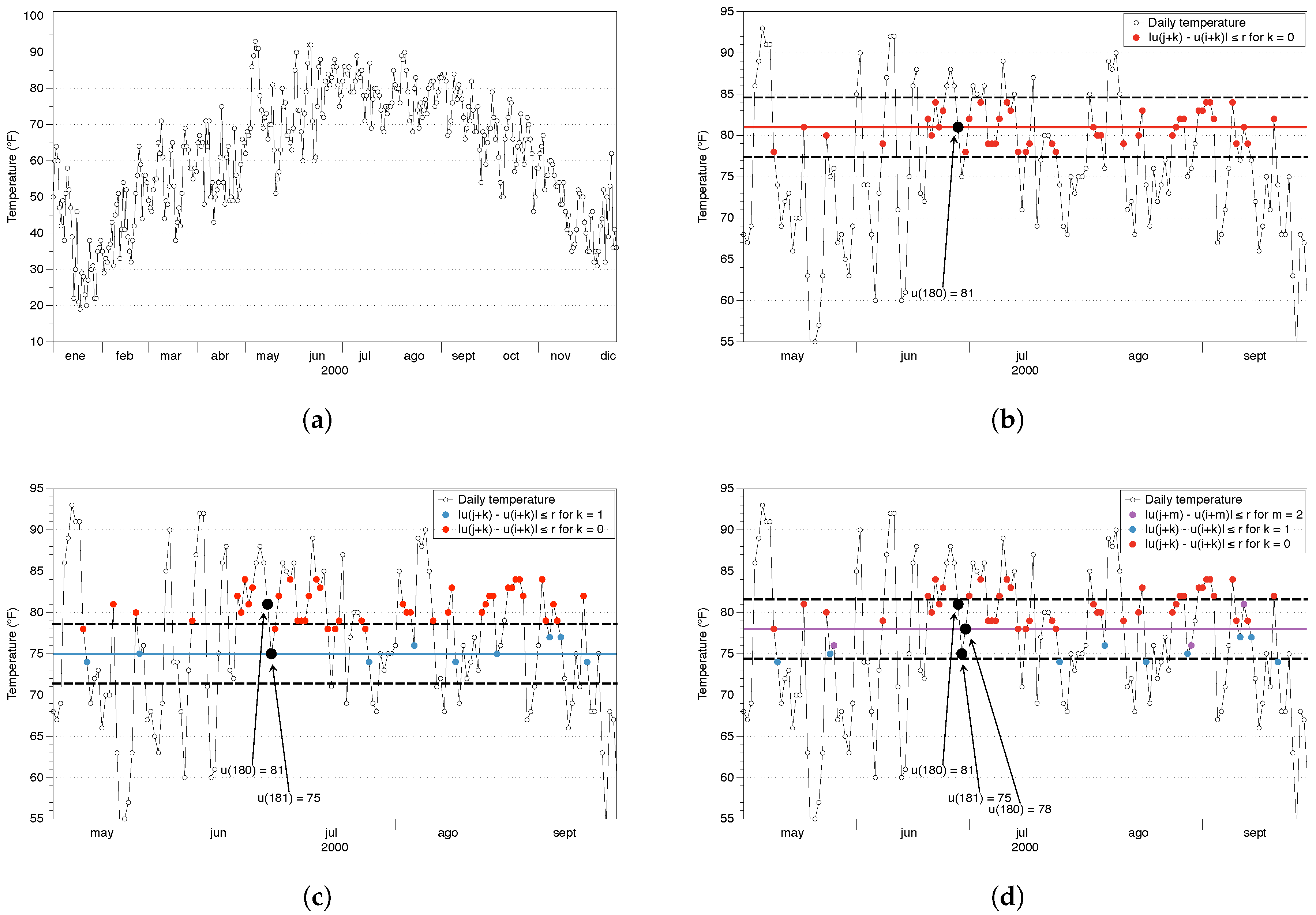
4. ApEn and SampEn: Step by Step Tutorial
4.1. Approximate Entrpy of the New York City Temperature
4.2. Sample Entrpy of the New York City Temperature
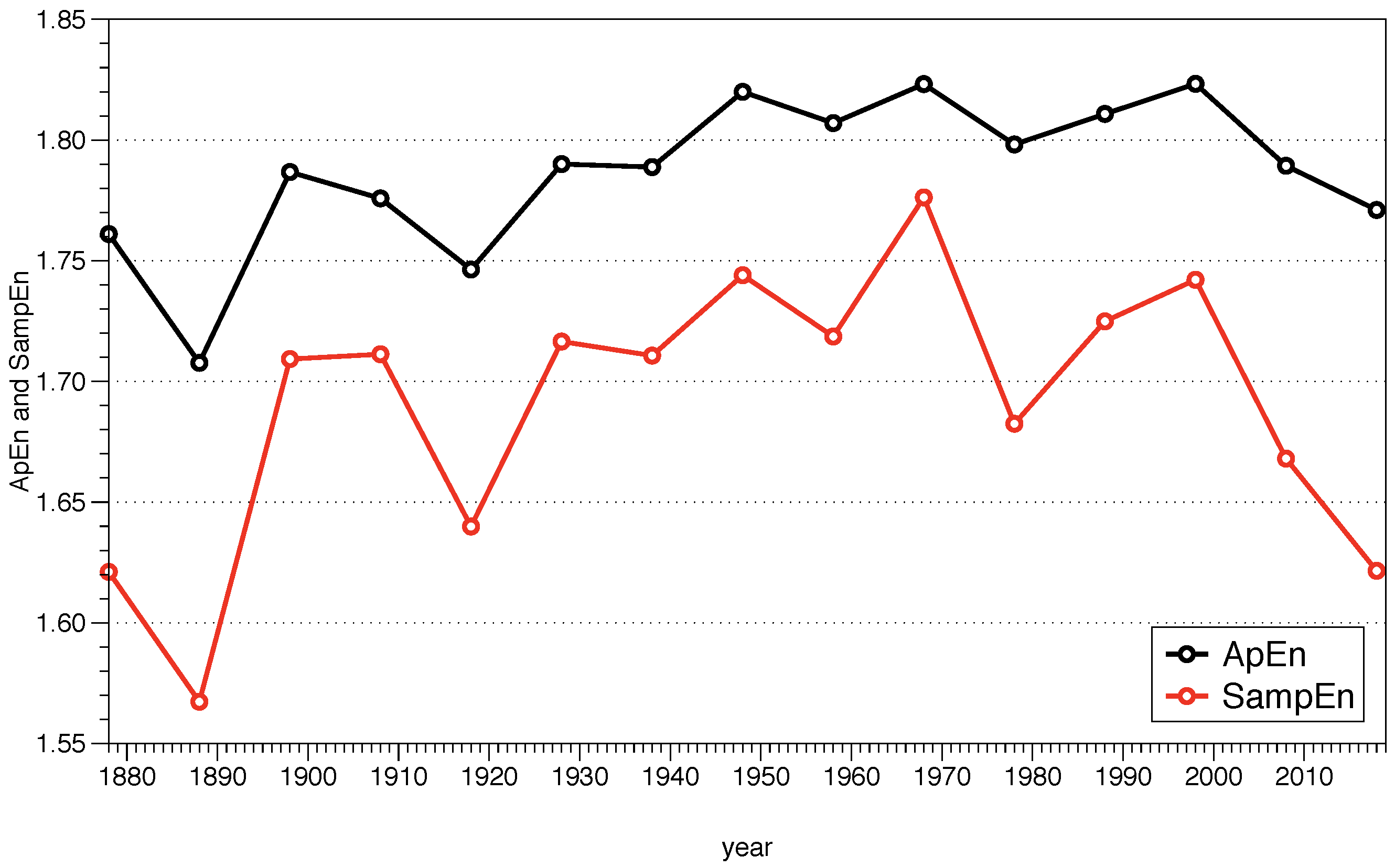
4.3. ApEn vs SampEn
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ApEn | approximate entropy |
| i.i.d. | independent and identically distributed |
| IT | information theory |
| MEP | maximum entropy principle |
| SampEn | sample entropy |
Appendix A. ApEn Code in R
Appendix B. SampEn Code in R
References
- Chaitin, G.J. Randomness and Mathematical Proof. Sci. Am. 1975, 232, 47–52. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics. II. Phys. Rev. 1957, 108, 171–190. [Google Scholar] [CrossRef]
- Kolmogorov, A. On Tables of Random Numbers. Sankhyā Ser. A. 1963, 25, 369–375. [Google Scholar] [CrossRef]
- Golan, A. Information and Entropy Econometrics—A Review and Synthesis. Foundations and Trends in Econometrics, 1st ed.; Now Publishers Inc.: Hanover, MA, USA, 2008. [Google Scholar]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing); Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Nyquist, H. Certain Factors Affecting Telegraph Speed1. Bell Syst. Tech. J. 1924, 3, 324–346. [Google Scholar] [CrossRef]
- Hartley, R.V.L. Transmission of Information. Bell Syst. Tech. J. 1928, 7, 535–563. [Google Scholar] [CrossRef]
- Zellner, A. Optimal Information Processing and Bayes’s Theorem. Am. Stat. 1988, 42, 278–280. [Google Scholar]
- Zellner, A. [Optimal Information Processing and Bayes’s Theorem]: Reply. Am. Stat. 1988, 42, 283–284. [Google Scholar] [CrossRef]
- Zellner, A. An Introduction to Bayesian Inference in Econometrics; John Wiley: Chichester, NY, USA, 1996. [Google Scholar]
- Lindley, D.V. On a Measure of the Information Provided by an Experiment. An. Math. Stat. 1956, 27, 986–1005. [Google Scholar] [CrossRef]
- Sinai, Y. On the Notion of Entropy of a Dynamical System. Dokl. Russ. Acad. Sci. 1959, 124, 768–771. [Google Scholar]
- Grassberger, P.; Procaccia, I. Estimation of the Kolmogorov entropy from a chaotic signal. Phys. Rev. A 1983, 28, 2591–2593. [Google Scholar] [CrossRef] [Green Version]
- Takens, F. Invariants related to dimension and entropy. In Atlas do 13 Coloquio Brasileiro de Matematica; Instituto de Matemática Pura e Aplicada: Rio de Janeiro, Brazil, 1983. [Google Scholar]
- Eckmann, J.P.; Ruelle, D. Ergodic theory of chaos and strange attractors. Rev. Mod. Phys. 1985, 57, 617–656. [Google Scholar] [CrossRef]
- Pincus, S. Approximate entropy (ApEn) as a complexity measure. Chaos Int. J. Nonlinear Sci. 1995, 5, 110–117. [Google Scholar] [CrossRef]
- Pincus, S.M.; Goldberger, A.L. Physiological time-series analysis: what does regularity quantify? Am. J. Physiol. Heart Circul Physiol. 1994, 266, H1643–H1656. [Google Scholar] [CrossRef]
- Pincus, S.M.; Huang, W.M. Approximate entropy: Statistical properties and applications. Commun. Stat. Theor. Methods 1992, 21, 3061–3077. [Google Scholar] [CrossRef]
- Pincus, S.; Kalman, R.E. Not all (possibly) “random” sequences are created equal. Proc. Natl. Acad. Sci. USA 1997, 94, 3513–3518. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximating Markov chains. Proc. Natl. Acad. Sci. USA 1992, 89, 4432–4436. [Google Scholar] [CrossRef]
- Rukhin, A.L. Approximate Entropy for Testing Randomness. J. Appl. Probabil. 2000, 37, 2000. [Google Scholar] [CrossRef]
- Pincus, S. Approximate Entropy as an Irregularity Measure for Financial Data. Econom. Rev. 2008, 27, 329–362. [Google Scholar] [CrossRef]
- Pincus, S.; Singer, B.H. Randomness and degrees of irregularity. Proc. Natl. Acad. Sci. USA 1996, 93, 2083–2088. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; Chen, X.; Kanters, J.; Solomon, I.; Chon, K. Automatic Selection of the Threshold Value for Approximate Entropy. IEEE Trans. Biomed. Eng. 2008, 55, 1966–1972. [Google Scholar] [PubMed]
- Castiglioni, P.; Di Rienzo, M. How the threshold “r” influences approximate entropy analysis of heart-rate variability. Comput. Cardiol. 2008, 35, 561–564. [Google Scholar]
- Chon, K.H.; Scully, C.G.; Lu, S. Approximate entropy for all signals. IEEE Eng. Med. Biol. Mag. 2009, 28, 18–23. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.M.; Mulligan, T.; Iranmanesh, A.; Gheorghiu, S.; Godschalk, M.; Veldhuis, J.D. Older males secrete luteinizing hormone and testosterone more irregularly, and jointly more asynchronously, than younger males. Proc. Natl. Acad. Sci. USA 1996, 93, 14100–14105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Phys. Heart Circul. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skoric, T.; Sarenac, O.; Milovanovic, B.; Japundzic-Zigon, N.; Bajic, D. On Consistency of Cross-Approximate Entropy in Cardiovascular and Artificial Environments. Hindawi Complex. 2017. [Google Scholar] [CrossRef]
- Pincus, S.M.; Gladstone, I.M.; Ehrenkranz, R.A. A regularity statistic for medical data analysis. J. Clin. Monit. 1991, 7, 335–345. [Google Scholar] [CrossRef]
- Grassberger, P.; Schreiber, T.; Schaffrath, C. Nonlinear Time Sequence Analysis. Int. J. Bifur. Chaos 1991, 1, 521–547. [Google Scholar] [CrossRef]
- Montesinos, L.; Castaldo, R.; Pecchia, L. On the use of approximate entropy and sample entropy with centre of pressure time-series. J. NeuroEng. Rehabil. 2018, 15, 116. [Google Scholar] [CrossRef] [PubMed]
- Ryan, G.; Mosca, A.; Chang, R.; Wu, E. At a Glance: Pixel Approximate Entropy as a Measure of Line Chart Complexity. IEEE Trans. Visual. Comput. Graph. 2019, 25, 872–881. [Google Scholar] [CrossRef] [PubMed]
- Lee, G.; Fattinger, S.; Mouthon, A.L.; Noirhomme, Q.; Huber, R. Electroencephalogram approximate entropy influenced by both age and sleep. Front. Neuroinf. 2013, 7, 33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Souza, G.M.; Ribeiro, R.V.; Santos, M.G.; Ribeiro, H.L.; Oliveira, R.F. Approximate Entropy as a measure of complexity in sap flow temporal dynamics of two tropical tree species under water deficit. Anais da Academia Brasileira de Ciencias 2004, 76, 625–630. [Google Scholar] [CrossRef] [PubMed]
- Caldirola, D.; Bellodi, L.; Caumo, A.; Migliarese, G.; Perna, G. Approximate Entropy of Respiratory Patterns in Panic Disorder. Am. J. Psychiat. 2004, 161, 79–87. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, L.; Miao, S.; Cheng, M.; Gao, X. A new switching parameter varying optoelectronic delayed feedback model with computer simulation. Sci. Rep. 2016, 6, 22295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metzger, R.A.; Doherty, J.F.; Jenkins, D.M. Using Approximate Entropy as a speech quality measure for a speaker recognition system. In Proceedings of the 2016 Annual Conference on Information Science and Systems (CISS), Princeton, NJ, USA, 15–18 March 2016; pp. 292–297. [Google Scholar] [CrossRef]
- Pincus, S.; Kalman, R.E. Irregularity, volatility, risk, and financial market time series. Proc. Natl. Acad. Sci. USA 2004, 101, 13709–13714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
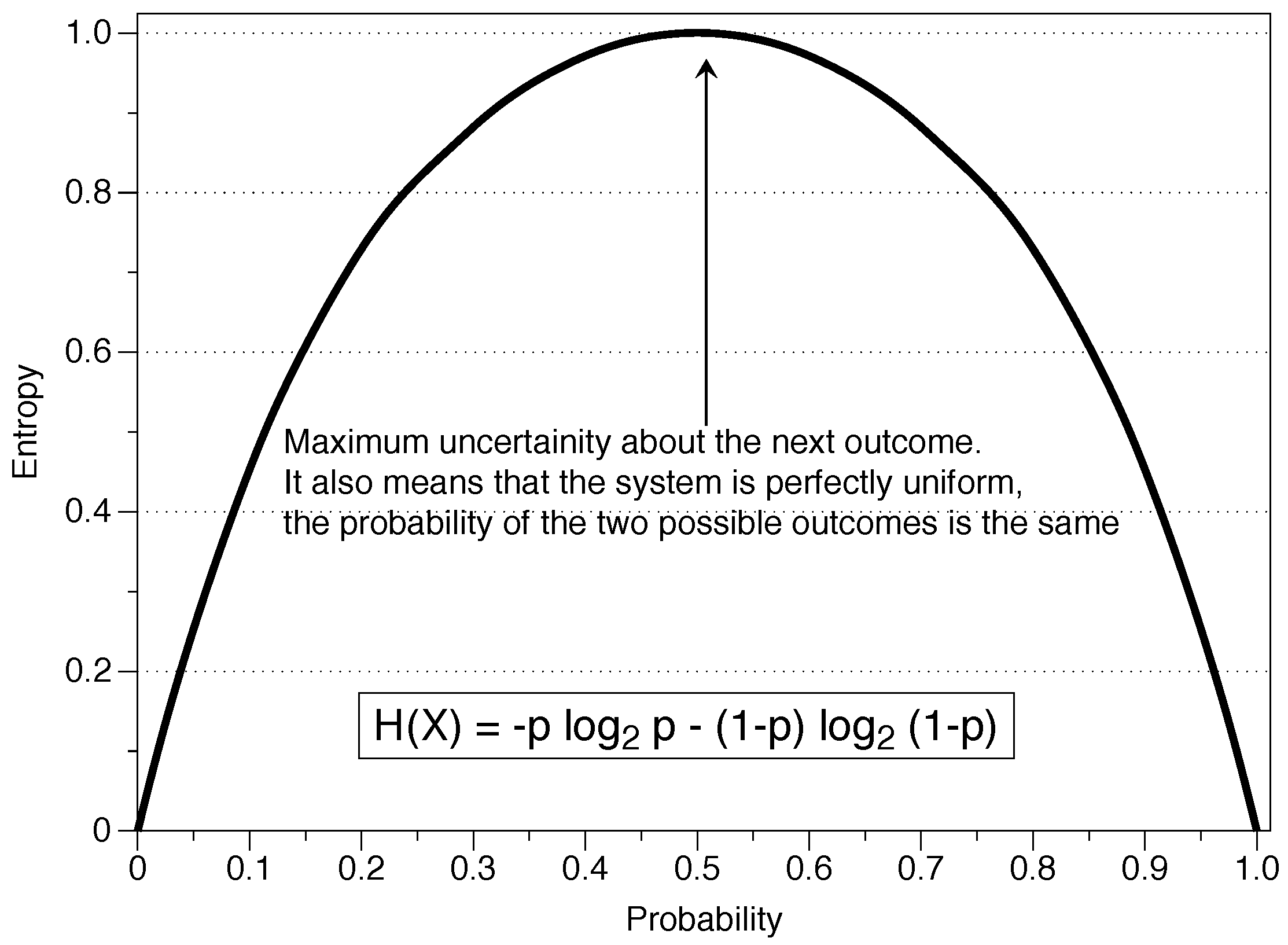









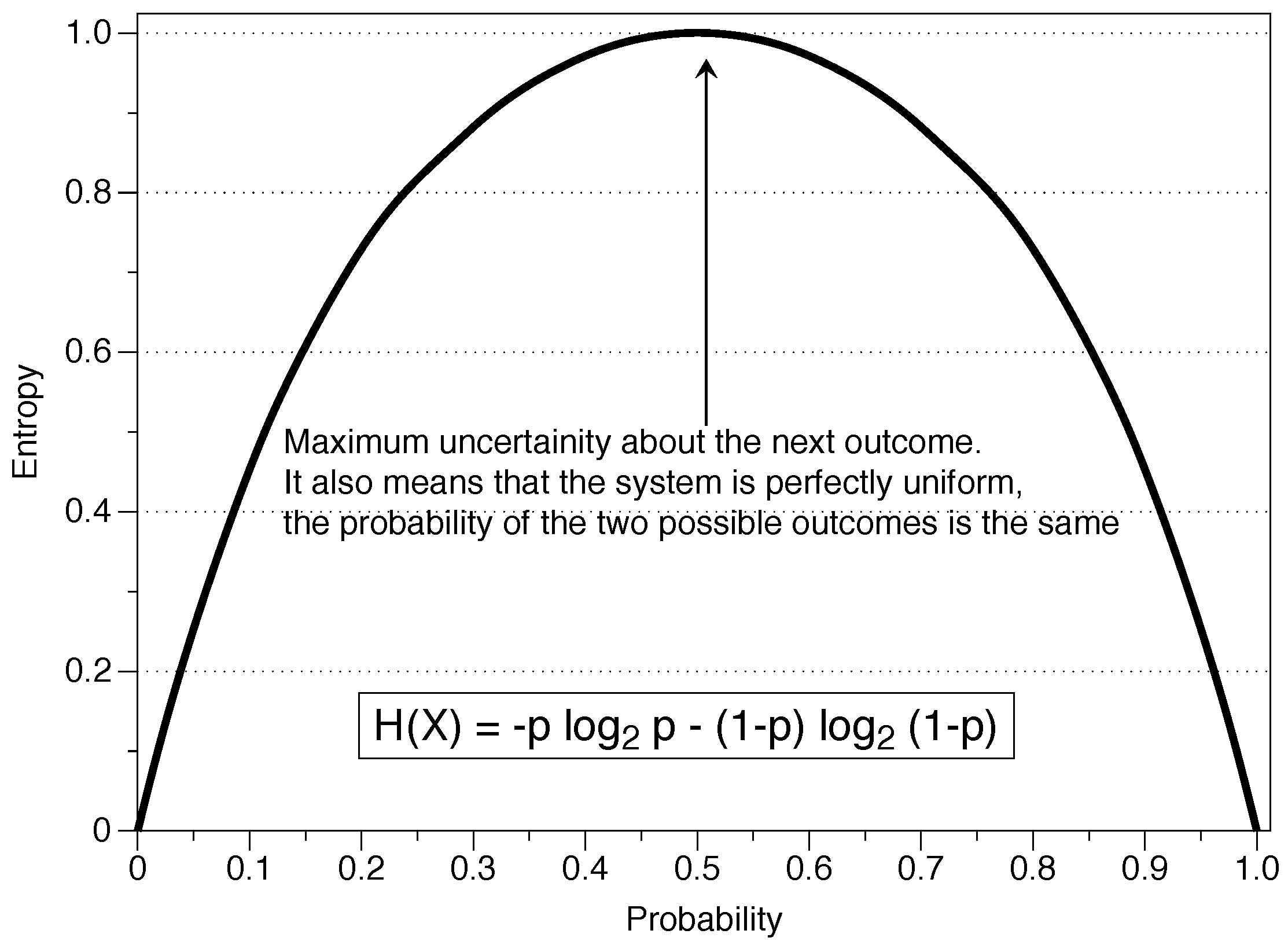{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
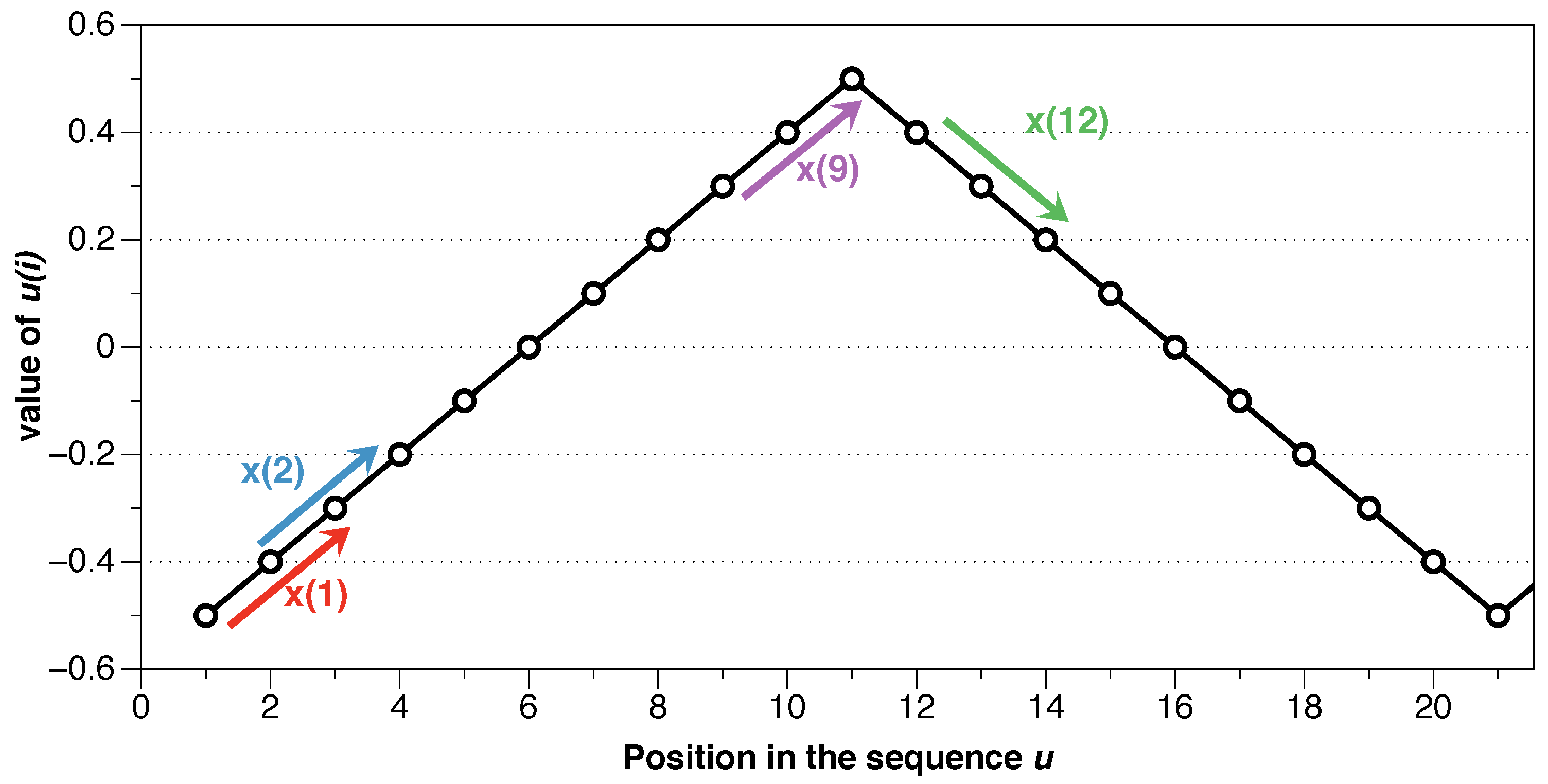
| Block | x(1) | x(2) | x(3) | x(4) | x(5) | x(6) | x(7) | x(8) | x(9) | x(10) | x(11) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Possibles | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 |
| Matches | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delgado-Bonal, A.; Marshak, A. Approximate Entropy and Sample Entropy: A Comprehensive Tutorial. Entropy 2019, 21, 541. https://doi.org/10.3390/e21060541
Delgado-Bonal A, Marshak A. Approximate Entropy and Sample Entropy: A Comprehensive Tutorial. Entropy. 2019; 21(6):541. https://doi.org/10.3390/e21060541
Chicago/Turabian StyleDelgado-Bonal, Alfonso, and Alexander Marshak. 2019. "Approximate Entropy and Sample Entropy: A Comprehensive Tutorial" Entropy 21, no. 6: 541. https://doi.org/10.3390/e21060541