Machine Learning Techniques to Identify Antimicrobial Resistance in the Intensive Care Unit


 ,
, 
Abstract
1. Introduction
- A clinical sample is taken from the patient (these samples may be of a different nature, e.g., blood, urine, etc.).
- A culture is performed on the previously subtracted clinical sample. The goal of the culture is to increase the number of microorganisms, such as bacteria, by preparing an optimal way to promote their development. It is used because many bacterial species are so morphologically similar that it is impossible to differentiate them only with the use of the microscope. In this case, in order to identify each type of microorganism, their biochemical characteristics are studied by planting them in special culture media. The result of a culture will be positive if the microorganism is correctly identified, and negative otherwise.
- If the culture is positive, the next step is to perform an antibiogram with a determined set of antimicrobials. The antibiogram is constructed from susceptibility testing data and defines the in vitro activity of an antibiotic against a given bacterium (previously isolated in the culture). The antibiogram reflects its ability to inhibit the growth of a bacterium or bacterial population.
- To carry out a statistical analysis showing in a map the relationship between certain bacteria and families of antibiotics of special clinical interest.
- To design a ML classifier to determine the resistance of the P. aeruginosa bacterium to certain families of antibiotics. Taking into account that the result of the antibiogram usually takes 24/48 h, the use of a data-driven system could help to identify and isolate patients in risk of antimicrobial resistance. From a data analysis viewpoint, we will check which ML scheme provides better performance in terms of accuracy, sensitivity, specificity and F1-score.
2. Statistical Approaches
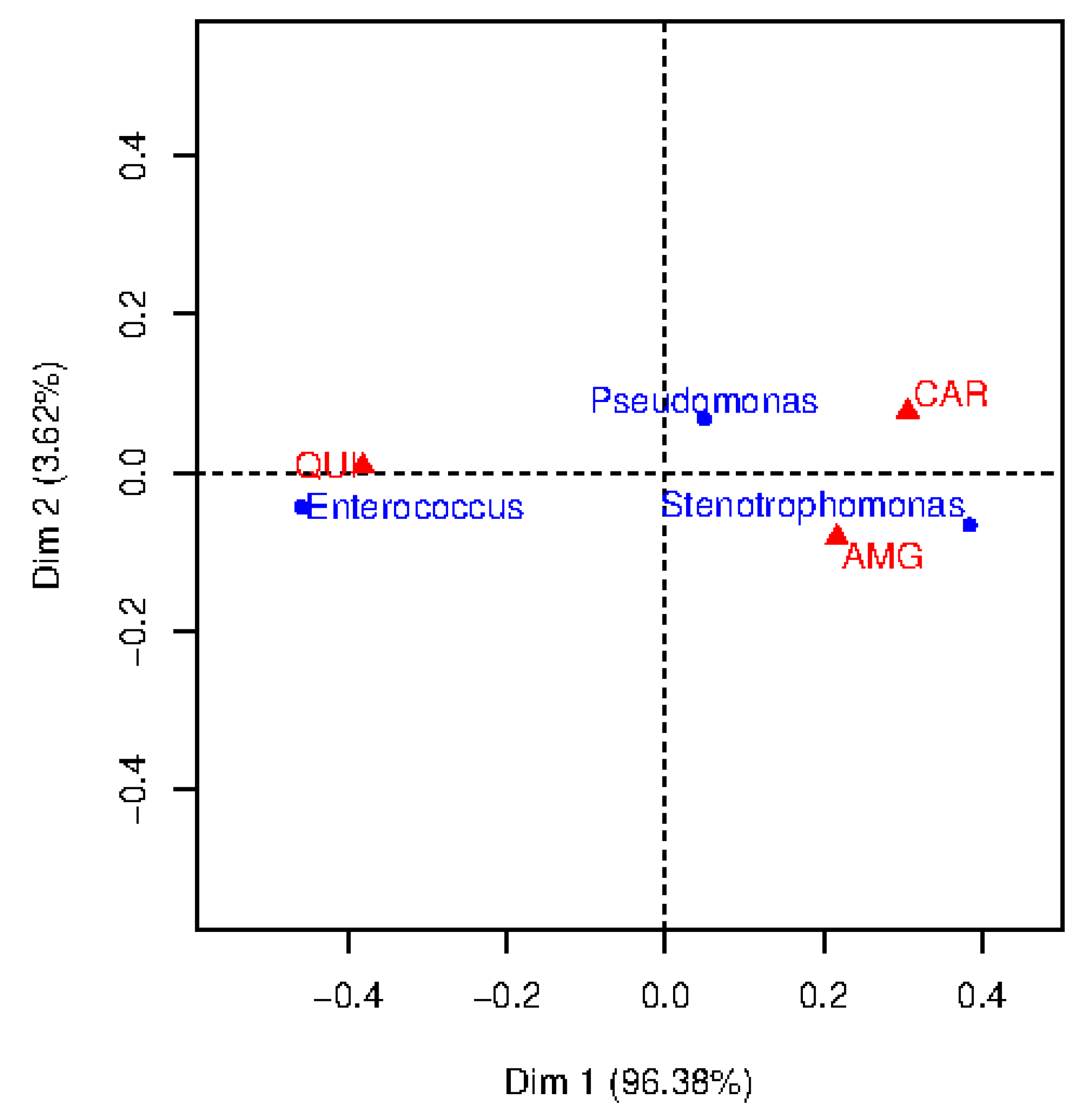
2.1. Correspondence Analysis
2.2. Machine Learning Techniques
2.2.1. Data Pre-Processing
2.2.2. Logistic Regression
2.2.3. Voting k-nn
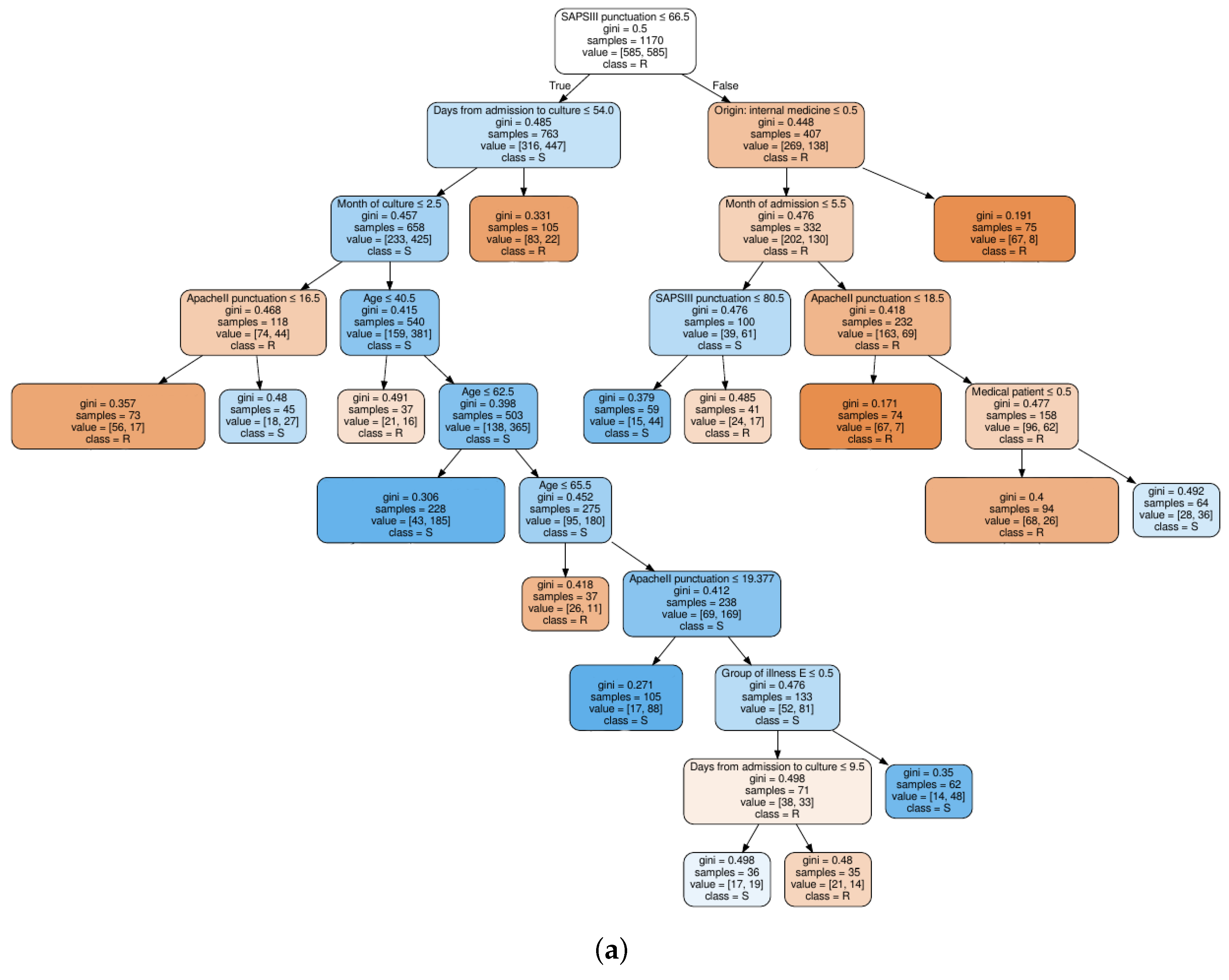
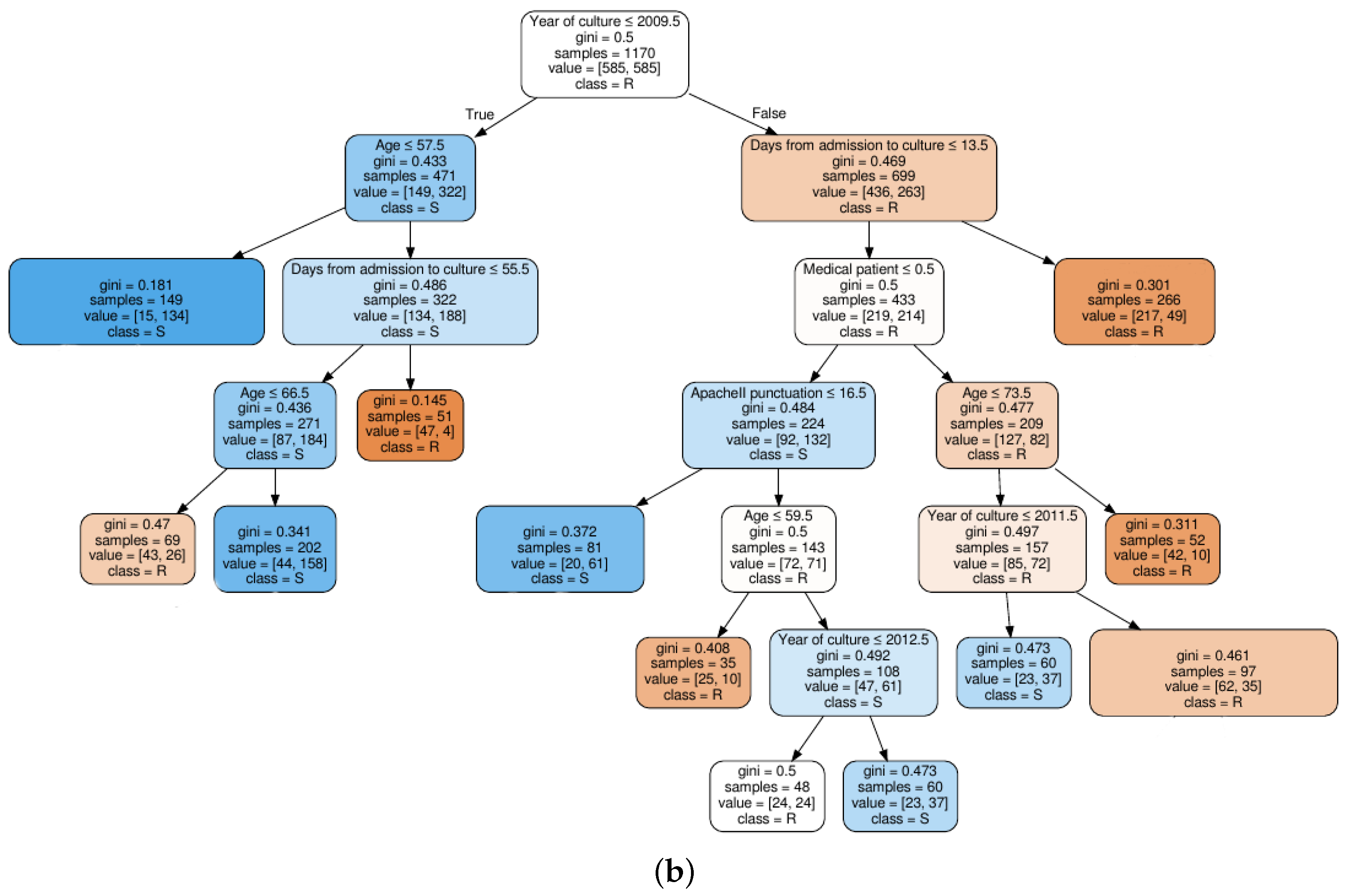
2.2.4. Decision Trees
2.2.5. Random Forest
2.2.6. Multi-Layer Perceptron
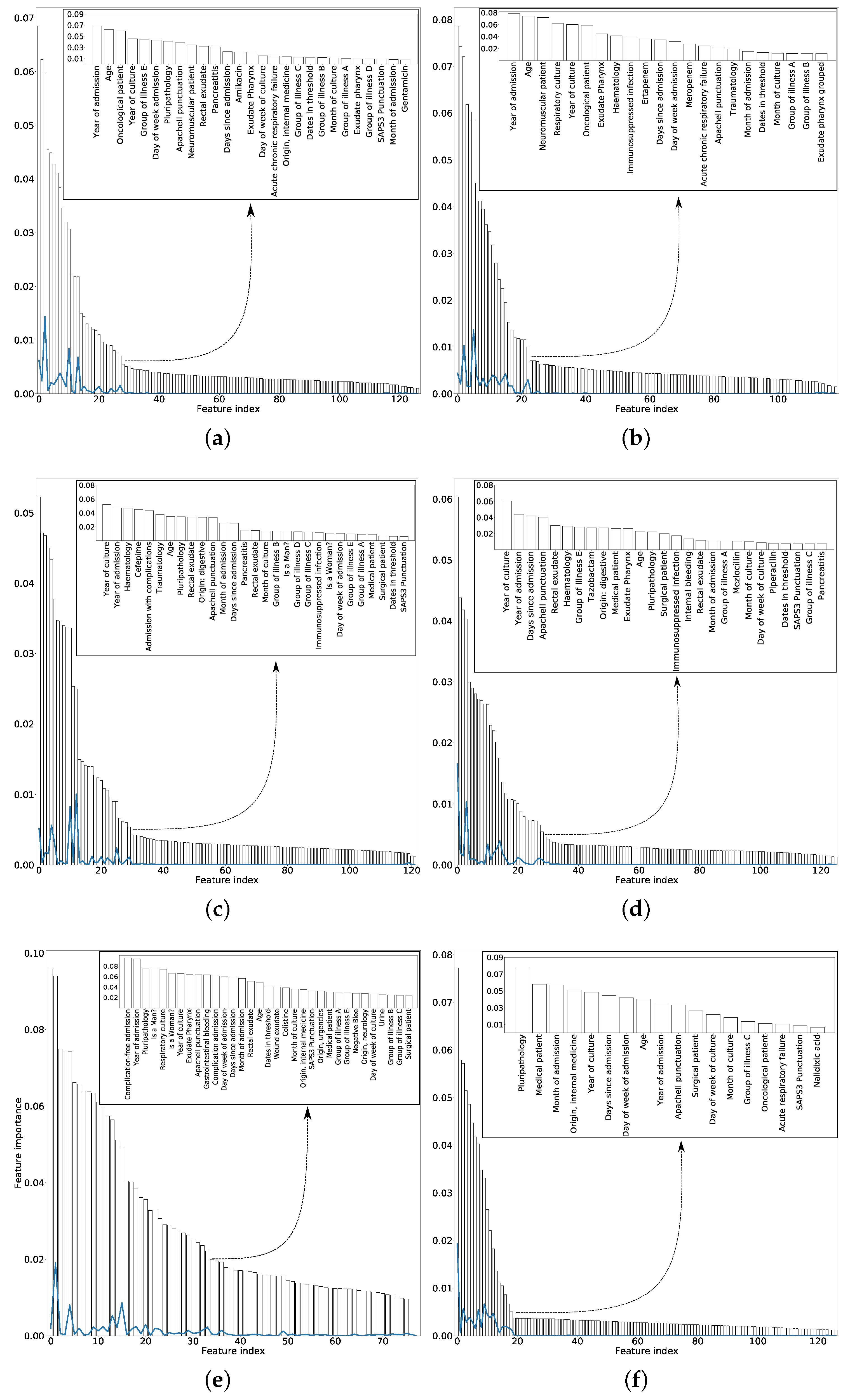
2.3. Entropy Criterion for Feature Selection
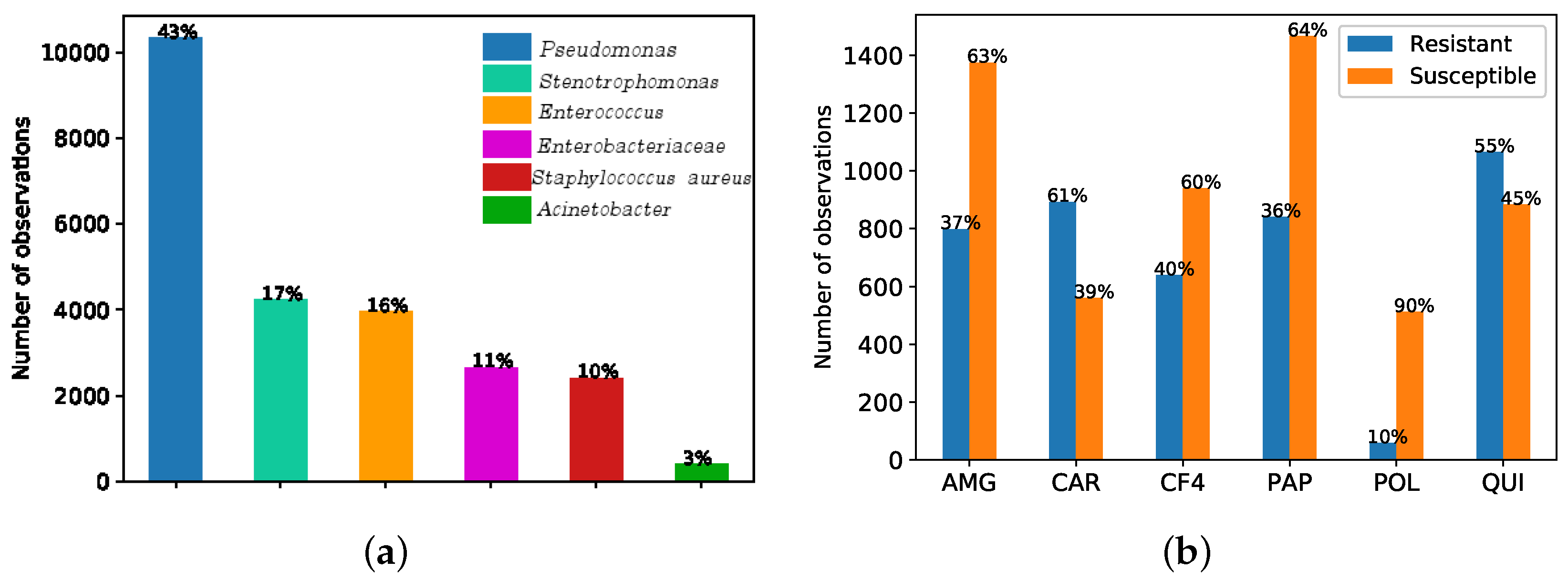
3. Data Set Description
- Demographic and clinical features (D&C): age, gender, clinical origin before admission to the ICU, destination after discharge from the ICU, reason for admission, comorbidities, date of admission and date from discharge from the ICU, APACHE II (Acute Physiology and Chronic Health Evaluation, version 2) [53] or SAPS 3 (Simplified Acute Physiology Score, version 3) [54], etc. APACHE II and SAPS 3 are scores used to predict the mortality risk for patients admitted to ICU. APACHE II is performed within 24 h after admission in the ICU and SAPS 3 within one hour. Both of them are related to mortality and severity of illness. Comorbidities are divided in seven groups: Group A (associated with cardiovascular events); group B (kidney failure, arthritis); group C (respiratory problems); group D (pancreatitis, endocrine); group E (epilepsy, dementia); group F (diabetes, arteriosclerosis); and group G (neoplasms). If a patient has more than two comorbidities, the feature named “pluripathology” gets the value 1 assigned.
- Features related to bacterial cultures (BC): the type of clinical sample used in the test (i.e., throat, urine, sputum, feces, wound, etc.), the date on which the culture was carried out and the bacteria found in the culture (if detected).
- Features related to the antibiograms (AT). If the culture is positive, an antibiogram is carry out, which includes: the set of antibiotics tested for each bacteria detected in the culture, their result (susceptibility or resistance) and the date on which the results were obtained, among others.
4. Results
4.1. Visualization Based on CA
4.2. Antimicrobial Resistance Identification
4.2.1. Experimental Set-Up
- Antimicrobial family 1. Aminoglycosides (AMG).
- Antimicrobial family 2. Carbapenemics (CAR).
- Antimicrobial family 3. 4G Cephalosporins (CF4).
- Antimicrobial family 4. Broad spectrum antibiotics (PAP).
- Antimicrobial family 5. Polymixines (POL).
- Antimicrobial family 6. Quinolones (QUI).
4.2.2. Feature Selection
4.3. Classification Results
- LR: penalty coefficient C in regularization. For obtaining it, we have considered two grids of values. The first grid explores values logarithmically spaced in the range between 0.01 and 10. A second grid was subsequently used around the best value found.
- k-NN: number of neighbors k. A range between 1 to 49 was considered, only taking odd values to address ties.
- DT: maximum depth of the tree, from 1 to 35. For the minimum number of samples per leaf, we considered the 0.5%, 1% and 2% of the samples.
- RF: number of trees (estimators) in the forest {10, 30, 50, 100 to 150}. For the maximum depth of each tree and the minimum samples per leaf, the same range of values considered in decision trees has been explored.
- MLP: one and two hidden layers were considered. For the first hidden layer, the number of neurons ranged from 50 to 70; and from 0 (no hidden layer) to 5 in the second hidden layer. Different activation functions have been considered, logistic, tanh and relu. For the L2 penalty coefficient, we have considered two grids of values. The first grid explores values logarithmically spaced in the range between 0.01 and 10. A second grid was subsequently used around the best value found in steps of 0.01.
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Michael, C.A.; Dominey-Howes, D.; Labbate, M. The antimicrobial resistance crisis: Causes, consequences, and management. Front. Public Health 2014, 2, 145. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Xie, S.; Ahmed, S.; Wang, F.; Gu, Y.; Zhang, C.; Chai, X.; Wu, Y.; Cai, J.; Cheng, G. Antimicrobial activity and resistance: Influencing factors. Front. Pharmacol. 2017, 8, 364. [Google Scholar] [CrossRef] [PubMed]
- Depardieu, F.; Podglajen, I.; Leclercq, R.; Collatz, E.; Courvalin, P. Modes and modulations of antibiotic resistance gene expression. Clin. Microbiol. Rev. 2007, 20, 79–114. [Google Scholar] [CrossRef] [PubMed]
- Nee, P. Critical care in the emergency department: Severe sepsis and septic shock. Emerg. Med. J. 2006, 23, 713–717. [Google Scholar] [CrossRef] [PubMed]
- Shankar-Hari, M.; Harrison, D.; Rubenfeld, G.; Rowan, K. Epidemiology of sepsis and septic shock in critical care units: Comparison between sepsis-2 and sepsis-3 populations using a national critical care database. Br. J. Anaesth. 2017, 119, 626–636. [Google Scholar] [CrossRef]
- Driessen, R.G.; van de Poll, M.C.; Mol, M.F.; van Mook, W.N.; Schnabel, R.M. The influence of a change in septic shock definitions on intensive care epidemiology and outcome: Comparison of sepsis-2 and sepsis-3 definitions. Infect. Dis. 2018, 50, 207–213. [Google Scholar] [CrossRef]
- Paoli, C.J.; Reynolds, M.A.; Sinha, M.; Gitlin, M.; Crouser, E. Epidemiology and Costs of Sepsis in the United States—An Analysis Based on Timing of Diagnosis and Severity Level. Crit. Care Med. 2018, 46, 1889. [Google Scholar] [CrossRef]
- Fernando, S.; Reardon, P.; Rochwerg, B.; Shapiro, N.; Yealy, D.; Seely, A.; Perry, J.J.; Barnaby, D.P.; Murphy, K.; Tanuseputro, P.; et al. Sepsis-3 Septic Shock Criteria and Associated Mortality Among Infected Hospitalized Patients Assessed by a Rapid Response Team. Chest 2018, 154, 309–316. [Google Scholar] [CrossRef]
- Sterling, S.; Miller, W.; Pryor, J.; Puskarich, M.; Jones, A. The Impact of Timing of Antibiotics on Outcomes in Severe Sepsis and Septic Shock: A Systematic Review and Meta-Analysis. Crit. Care Med. 2015, 43, 1907–1915. [Google Scholar] [CrossRef]
- Sherwin, R.; Winters, M.; Vilke, G.; Wardi, G. Does Early and Appropriate Antibiotic Administration Improve Mortality in Emergency Department Patients with Severe Sepsis or Septic Shock? J. Emerg. Med. 2017, 53, 588–595. [Google Scholar] [CrossRef]
- Fitousis, K.; Moore, L.; Hall, J.; Moore, F.; Pass, S. Evaluation of empiric antibiotic use in surgical sepsis. Am. J. Surg. 2010, 200, 776–782. [Google Scholar] [CrossRef] [PubMed]
- Ferrer, R.; Martin-Loeches, I.; Phillips, G.; Osborn, T.; Townsend, S.; Dellinger, R.; Artigas, A.; Schorr, C.; Levy, M.M. Empiric antibiotic treatment reduces mortality in severe sepsis and septic shock from the first hour: Results from a guideline-based performance improvement program. Crit. Care Med. 2014, 42, 1749–1755. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, E.; Sherman, G.; Ward, S.; Fraser, V.; Kollef, M. The influence of inadequate antimicrobial treatment of bloodstream infections on patient outcomes in the ICU setting. Chest 2000, 118, 146–155. [Google Scholar] [CrossRef] [PubMed]
- Garnacho-Montero, J.; Gutiérrez-Pizarraya, A.; Escoresca-Ortega, A.; Fernández-Delgado, E.; López-Sánchez, J. Adequate antibiotic therapy prior to ICU admission in patients with severe sepsis and septic shock reduces hospital mortality. Crit. Care 2015, 19, 302. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Kollef, M.; Sherman, G.; Ward, S.; Fraser, V. Inadequate antimicrobial treatment of infections: A risk factor for hospital mortality among critically ill patients. Chest 1999, 115, 462–474. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Global Action Plan to Control the Spread and Impact of Antimicrobial Resistance in Neisseria gonorrhoeae; World Health Organization: Geneva, Switzerland, 2012. [Google Scholar]
- European Center for Disease Prevention and Control. The Bacterial Challenge: Time to React; European Center for Disease Prevention and Control: Stockholm, Sweden, 2009. [Google Scholar]
- O’neill, J. Tackling Drug-Resistant Infections Globally: Final Report and Recommendations; Review on Antimicrobial Resistance; 2016. Available online: https://amr-review.org/Publications.html (accessed on 14 June 2019).
- World Health Organization. Antimicrobial Resistance: Global Report on Surveillance; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- Nguyen, M.; Long, S.W.; McDermott, P.F.; Olsen, R.J.; Olson, R.; Stevens, R.L.; Tyson, G.H.; Zhao, S.; Davis, J.J. Using machine learning to predict antimicrobial MICs and associated genomic features for nontyphoidal Salmonella. J. Clin. Microbiol. 2019, 57, e01260-18. [Google Scholar] [CrossRef] [PubMed]
- Moradigaravand, D.; Palm, M.; Farewell, A.; Mustonen, V.; Warringer, J.; Parts, L. Prediction of antibiotic resistance in Escherichia coli from large-scale pan-genome data. PLoS Comput. Biol. 2018, 14, e1006258. [Google Scholar] [CrossRef] [PubMed]
- Su, M.; Satola, S.W.; Read, T.D. Genome-Based prediction of bacterial antibiotic resistance. J. Clin. Microbiol. 2019, 57, e01405-18. [Google Scholar] [CrossRef]
- Biemer, J.J. Antimicrobial susceptibility testing by the Kirby-Bauer disc diffusion method. Ann. Clin. Lab. Sci. 1973, 3, 135–140. [Google Scholar]
- Andrews, J.M. Determination of minimum inhibitory concentrations. J. Antimicrob. Chemother. 2001, 48, 5–16. [Google Scholar] [CrossRef]
- Miller, R.; Walker, R.; Baya, A.; Clemens, K.; Coles, M.; Hawke, J.; Henricson, B.; Hsu, H.; Mathers, J.; Oaks, J.; et al. Antimicrobial susceptibility testing of aquatic bacteria: Quality control disk diffusion ranges for Escherichia coli ATCC 25922 and Aeromonas salmonicida subsp. salmonicida ATCC 33658 at 22 and 28 C. J. Clin. Microbiol. 2003, 41, 4318–4323. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, T. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Duda, O.; Hart, P.; Stork, D. Pattern Classification; John Wiley & Sons: New York, NY, USA, 2001. [Google Scholar]
- Ripley, B. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: Berlin, Germany, 2013. [Google Scholar]
- Triantafyllidis, A.K.; Tsanas, A. Applications of Machine Learning in Real-Life Digital Health Interventions: Review of the Literature. J. Med. Internet Res. 2019, 21, e12286. [Google Scholar] [CrossRef] [PubMed]
- Revuelta-Zamorano, P.; Sánchez, A.; Rojo-Álvarez, J.; Álvarez Rodríguez, J.; Ramos-López, J.; Soguero-Ruiz, C. Prediction of Healthcare Associated Infections in an Intensive Care Unit Using Machine Learning and Big Data Tools. In XIV Mediterranean Conference on Medical and Biological Engineering and Computing; Springer: Cham, Switzerland, 2016; pp. 840–845. [Google Scholar]
- Martínez-Agüero, S.; Lérida-García, J.; Álvarez Rodríguez, J.; Mora-Jiménez, I.; Soguero-Ruiz, C. Estudio de la evolución temporal de la resistencia antimicrobiana de gérmenes en la unidad de cuidados intensivos. In Proceedings of the XXXVI Congreso Anual de la Sociedad Española de Ingeniería Biomédica (CASEIB 2018), Ciudad Real, Spain, 21–23 November 2018. [Google Scholar]
- Lérida-García, J.; Martínez-Agüero, S.; Álvarez Rodríguez, J.; Mora-Jiménez, I.; Soguero-Ruiz, C. Análisis de correspondencias para el estudio de la sensibilidad antibiótica de gérmenes en la UCI. In Proceedings of the XXXVI Congreso Anual de la Sociedad Española de Ingeniería Biomédica (CASEIB 2018), Ciudad Real, Spain, 21–23 November 2018. [Google Scholar]
- Greenacre, M.J. Correspondence Analysis; Academic Press: London, UK, 1984. [Google Scholar]
- Rao, C.R. A review of canonical coordinates and an alternative to correspondence analysis using Hellinger distance. Questiió 1995, 19, 1–3. [Google Scholar]
- Cohen, G.; Hilario, M.; Sax, H.; Hugonnet, S.; Geissbuhler, A. Learning from imbalanced data in surveillance of nosocomial infection. Artif. Intell. Med. 2006, 37, 7–18. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2008, 21, 1263–1284. [Google Scholar]
- Yen, S.J.; Lee, Y.S. Under-sampling approaches for improving prediction of the minority class in an imbalanced dataset. In Intelligent Control and Automation; Springer: Berlin, Germany, 2006; pp. 731–740. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discover and data Mining; Kluwer Academic Publishers: Norwell, MA, USA, 1998. [Google Scholar]
- Lee, K.C.; Orten, B.; Dasdan, A.; Li, W. Estimating conversion rate in display advertising from past erformance data. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 768–776. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Quinlan, J. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Chapman and Hall: London, UK, 1984. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Amari, S. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Wittner, B.; Denker, J. Strategies for teaching layered neural networks classification tasks. Available online: https://papers.nips.cc/paper/85-strategies-for-teaching-layered-networks-classification-tasks (accessed on 18 June 2019).
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Torkkola, K. Feature extraction by non parametric mutual information maximization. J. Mach. Learn. Res. 2003, 3, 1415–1438. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Knaus, W.A.; Draper, E.A.; Wagner, D.P.; Zimmerman, J.E. APACHE II: A severity of disease classification system. Crit. Care Med. 1985, 13, 818–829. [Google Scholar] [CrossRef] [PubMed]
- Metnitz, P.G.; Moreno, R.P.; Almeida, E.; Jordan, B.; Bauer, P.; Campos, R.A.; Iapichino, G.; Edbrooke, D.; Capuzzo, M.; Le Gall, J.R.; et al. SAPS 3—From evaluation of the patient to evaluation of the intensive care unit. Part 1: Objectives, methods and cohort description. Intensive Care Med. 2005, 31, 1336–1344. [Google Scholar] [CrossRef] [PubMed]
- Soguero-Ruiz, C.; Hindberg, K.; Rojo-Alvarez, J.L.; Skrøvseth, S.O.; Godtliebsen, F.; Mortensen, K.; Revhaug, A.; Lindsetmo, R.O.; Augestad, K.M.; Jenssen, R. Support vector feature selection for early detection of anastomosis leakage from bag-of-words in electronic health records. IEEE J. Biomed. Health Inform. 2016, 20, 1404–1415. [Google Scholar] [CrossRef]
- Low, D.E. What is the relevance of antimicrobial resistance on the outcome of community-acquired pneumonia caused by Streptococcus pneumoniae?(should macrolide monotherapy be used for mild pneumonia?). Infect. Dis. Clin. 2013, 27, 87–97. [Google Scholar] [CrossRef]
- French, G.L. Clinical impact and relevance of antibiotic resistance. Adv. Drug Deliv. Rev. 2005, 57, 1514–1527. [Google Scholar] [CrossRef]
- Zilahi, G.; McMahon, M.A.; Povoa, P.; Martin-Loeches, I. Duration of antibiotic therapy in the intensive care unit. J. Thorac. Dis. 2016, 8, 3774–3780. [Google Scholar] [CrossRef]
- Ulukilic, A.; Cevahir, F.; Mese, E.A. Risk factors for multidrug-resistant Gram-negatives in the first episode of intensive care unit infection. In Proceedings of the 27th European Congress of Clinical Microbiology and Infectious Diseases (ECCMID), Vienna, Austria, 22–25 April 2017. [Google Scholar]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Stewart, W.F.; Sun, J. Generating multi-label discrete patient records using generative adversarial networks. arXiv 2017, arXiv:1703.06490. [Google Scholar]
Sample Availability: The dataset analyzed during the current study are not publicly available but they could be available from the corresponding author on reasonable request. |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type—Feature | Category | Subcategory | # feat. | Mean ± std |
|---|---|---|---|---|
| D&C—Age | - | - | 1 | 62 ± 14 |
| D&C—SAPS3 | - | - | 1 | 61 ± 14 |
| D&C—ApacheII | - | - | 1 | 20 ± 7 |
| BC—Days from | - | - | ||
| adm. to culture | - | - | 1 | 12.1 ± 18.4 |
| BC—Culture Date | Year, | - | 3 | 2010 ± 4, |
| Month, Day | - | 6 ± 3, 2 ± 2 | ||
| Type—Feature | Category | Subcategory | # feat. | % of obs. |
| D&C—Gender | Male Female | - | 1 1 | 61.37 38.63 |
| D&C—Diagnosis | Groups | A, B, C, D, | 8 | 14.9, 11.3, 25.1 |
| E, F, G, pluripathology | 7.6,8.8, 25, 28.9 | |||
| D&C—Patient type | - | Surgical, Medical, Trauma | 3 | 100 |
| D&C—Reason for admission | Surgery | Scheduled with (without) complications, Urgent with (without) complications | 4 | 25.6 |
| Respiratory | Chronic acute respiratory insufficiency, respiratory failure, Respiratory other | 3 | 21.2 | |
| Cardiovascular | Heart failure, Ischemic heart disease, Severe arrhythmia, Cardiorespiratory arrest, Hypovolemia, Cardiovascular other | 6 | 16.7 | |
| Infection | Serious infection, Immune-compromised infection | 2 | 16.2 | |
| Other medical | Digestive haemorrhage, Diabetic decompensation, Acute renal failure, Hepatic insufficiency, Voluntary intoxication, Pancreatitis | 6 | 9.7 | |
| Neurology | Stroke, Epilepsy, Alteration of the awareness level, Neuromuscular, Neurological other | 5 | 9.0 | |
| Trauma | Severe trauma | 1 | 0.8 | |
| D&C— Origin | Emergency | - | 1 | 27.4 |
| General surgery | - | 1 | 26.7 | |
| Internal medicine | - | 1 | 11.1 | |
| Others | Anesthesia, Dermatology, Digestive, Gastrointestinal, Hematology, Nefrology, Neumology, Neurology, Oncology, Other hospital, Others, Otorrinolaringology, Psychiatry, Surgery, Traumatology, Urology, Ophthalmology | 19 | 34.8 | |
| BC—Type of sample | Exudate | Rectal, Nasal, Axillary, Pharyngeal, Inguinal, Wound, Urethral, Press ulcer | 20 | 91.9 |
| Others | Blood, Catheter, Urine, Feces, Abscess, Abdominal abscess, Respiratory, Drainage, Abdominal drainage, Abdominal fluid, Sputum, Pleural, Bronchoalveolar lavage, Secretion, Peritoneal liquid, Ascitic liquid, Biliary liquid | 29 | 8.1 | |
| AT—Antibiotics | Others | Amikacin, Gentamicin, Gentamicin high load synergy, Kanamycin high load synergy, Tobramycin, Imipenem, Meropenem, Ertapenem, Ceftazidime, Cefepime, Piperacillin, Ticarcillin, Mezlocillin, Colistin, Ciprofloxacin, Levofloxacin, Norfloxacin, Nalidixic acid, Ofloxacin, Moxifloxacin | 20 | 100 |
| Fam. Antim. | AMG | CAR | QUI | |
|---|---|---|---|---|
| Bacterial Types | ||||
| Pseudomonas | 802 | 897 | 1065 | |
| Stenotrophomonas | 712 | 633 | 368 | |
| Enterococcus | 396 | 250 | 1085 | |
| Fam. Antim. | AMG | CAR | QUI | |
|---|---|---|---|---|
| Bacterial Types | ||||
| Pseudomonas | 2.8 | 13.8 | 2.8 | |
| Stenotrophomonas | 64.9 | 41.0 | 153.7 | |
| Enterococcus | 35.0 | 122.2 | 208.8 | |
| AMG | CAR | CF4 | PAP | POL | QUI | |
|---|---|---|---|---|---|---|
| Total observations | 2177 | 1458 | 1582 | 2309 | 570 | 1952 |
| # of observations in the minority class | 802 | 560 | 642 | 842 | 58 | 884 |
| (%) | (36% R) | (38% S) | (41% S) | (36% S) | (10% R) | (45% R) |
| FS | Model | Hyperparameter | AMG | CAR | CF4 | PAP | POL | QUI |
|---|---|---|---|---|---|---|---|---|
| FS1 | LR | Penalty coefficient | 0.73 | 0.62 | 0.48 | 0.13 | 0.05 | 0.01 |
| k-nn | N° neighbors | 1 | 1 | 1 | 1 | 5 | 1 | |
| DT | Max. depth | 22 | 23 | 31 | 20 | 22 | 20 | |
| Min. samples per leaf | 5 | 4 | 8 | 6 | 5 | 6 | ||
| RF | Max. depth | 37 | 25 | 30 | 38 | 14 | 20 | |
| Min. samples per leaf | 5 | 4 | 4 | 6 | 5 | 6 | ||
| N° of tress | 50 | 100 | 30 | 50 | 50 | 100 | ||
| MLP | Activation function | Relu | Relu | Relu | Relu | Relu | Relu | |
| L2 penalty coefficient | 0.02 | 0.01 | 0.01 | 0.01 | 0.20 | 0.05 | ||
| N° of neurons | 59 | 60 | 59 | 62 | 58 | 61 | ||
| FS2 | LR | Penalty coefficient | 0.04 | 1.50 | 0.12 | 1.01 | 0.01 | 0.05 |
| k-nn | N° neighbours | 1 | 1 | 1 | 1 | 7 | 1 | |
| DT | Max. depth | 22 | 15 | 41 | 19 | 3 | 4 | |
| Min. samples per leaf | 5 | 4 | 5 | 6 | 1 | 20 | ||
| RF | Max. depth | 30 | 18 | 18 | 22 | 26 | 30 | |
| Min. samples per leaf | 5 | 4 | 4 | 6 | 4 | 6 | ||
| N° of trees | 50 | 50 | 50 | 50 | 30 | 30 | ||
| MLP | Activation function | Relu | Relu | Sigmoid | Relu | Relu | Relu | |
| L2 penalty coefficient | 0.01 | 0.01 | 0.10 | 0.01 | 0.13 | 0.03 | ||
| N° of neurons | 64 | 64 | 62 | 63 | 59 | 57 |
| Family | Model | Accuracy | Specitivity | Sensitivity | F1-score | ||||
|---|---|---|---|---|---|---|---|---|---|
| FS1 | FS2 | FS1 | FS2 | FS1 | FS2 | FS1 | FS2 | ||
| AMG | LR | 78.2 ± 1.2 | 75.3 ± 1.7 | 80.0 ± 1.9 | 77.2 ± 2.7 | 76.5 ± 1.8 | 73.5 ± 2.4 | 77.8 ± 1.2 | 74.8 ± 1.7 |
| k-nn | 79.3 ± 1.6 | 83.3 ± 1.9 | 84.0 ± 2.5 | 86.5 ± 2.2 | 74.5 ± 2.1 | 80.3 ± 2.0 | 78.1 ± 1.3 | 82.7 ± 2.0 | |
| DT | 77.0 ± 1.2 | 78.6 ± 2.3 | 78.0 ± 3.7 | 81.7 ± 2.5 | 75.9 ± 2.6 | 76.6 ± 2.7 | 76.5 ± 1.1 | 78.0 ± 2.6 | |
| RF | 80.1 ± 1.6 | 80.8 ± 1.2 | 80.0 ± 2.3 | 81.3 ± 2.4 | 80.0 ± 2.0 | 80.2 ± 2.0 | 80.0 ± 1.6 | 80.5 ± 1.5 | |
| MLP | 80.8 ± 1.3 | 78.3 ± 1.0 | 83.0 ± 2.1 | 82.0 ± 1.7 | 78.6 ± 1.7 | 75.0 ± 1.2 | 80.1 ± 1.3 | 77.9 ± 1.1 | |
| CAR | LR | 77.3 ± 1.4 | 74.8 ± 2.3 | 76.0 ± 3.0 | 72.0 ± 3.4 | 78.7 ± 2.8 | 77.8 ± 3.1 | 77.6 ± 1.8 | 75.5 ± 2.3 |
| k-nn | 79.9 ± 1.6 | 81.5 ± 1.4 | 80.0 ± 2.8 | 80.3 ± 2.5 | 80.1 ± 2.5 | 82.7 ± 2.2 | 79.8 ± 1.7 | 81.6 ± 1.7 | |
| DT | 78.1 ± 2.2 | 79.4 ± 2.0 | 80.0 ± 2.6 | 83.7 ± 3.4 | 75.8 ± 2.7 | 76.2 ± 3.2 | 77.3 ± 2.7 | 78.9 ± 2.0 | |
| RF | 82.4 ± 1.7 | 82.2 ± 1.7 | 78.0 ± 4.0 | 82.0 ± 3.1 | 86.8 ± 3.1 | 82.5 ± 2.6 | 83.2 ± 1.5 | 82.5 ± 1.6 | |
| MLP | 81.9 ± 1.5 | 79.0 ± 1.9 | 81.0 ± 3.3 | 78.6 ± 2.5 | 82.6 ± 2.9 | 80.2 ± 2.1 | 82.3 ± 1.5 | 79.2 ± 1.8 | |
| CF4 | LR | 68.7 ± 2.0 | 67.8 ± 1.3 | 70.0 ± 3.1 | 68.1 ± 2.3 | 67.9 ± 2.6 | 67.1 ± 2.1 | 68.2 ± 2.3 | 67.3 ± 1.8 |
| k-nn | 77.7 ± 1.5 | 75.6 ± 1.6 | 80.0 ± 2.7 | 78.9 ± 2.6 | 75.2 ± 2.4 | 72.9 ± 2.6 | 77.0 ± 1.4 | 74.7 ± 2.0 | |
| DT | 71.0 ± 1.1 | 74.6 ± 2.2 | 74.4 ± 3.7 | 78.0 ± 3.6 | 67.9 ± 3.2 | 71.8 ± 3.1 | 70.3 ± 1.4 | 73.9 ± 2.4 | |
| RF | 75.8 ± 1.9 | 78.0 ± 1.8 | 72.0 ± 4.3 | 77.2 ± 3.7 | 79.4 ± 3.0 | 79.6 ± 3.3 | 76.7 ± 1.7 | 78.2 ± 1.8 | |
| MLP | 77.0 ± 1.5 | 75.8 ± 1.4 | 81.0 ± 4.5 | 77.4 ± 3.6 | 73.4 ± 3.7 | 75.1 ± 2.7 | 76.6 ± 1.1 | 75.3 ± 1.9 | |
| PAP | LR | 69.0 ± 1.4 | 67.7 ± 1.4 | 68.0 ± 2.8 | 65.9 ± 3.0 | 70.4 ± 2.5 | 70.2 ± 2.5 | 69.1 ± 1.6 | 68.1 ± 1.4 |
| k-nn | 78.3 ± 1.6 | 78.4 ± 1.4 | 82.0 ± 2.5 | 81.3 ± 2.2 | 74.8 ± 2.4 | 76.3 ± 2.7 | 77.4 ± 1.9 | 77.7 ± 1.7 | |
| DT | 72.6 ± 2.2 | 74.6 ± 2.0 | 74.0 ± 3.5 | 78.1 ± 4.1 | 70.9 ± 2.6 | 71.1 ± 3.5 | 71.7 ± 2.5 | 73.4 ± 2.3 | |
| RF | 75.2 ± 1.5 | 75.6 ± 1.2 | 71.0 ± 3.0 | 73.0 ± 3.0 | 79.5 ± 2.7 | 78.3 ± 2.4 | 75.7 ± 1.8 | 76.1 ± 1.4 | |
| MLP | 78.2 ± 1.7 | 75.4 ± 1.4 | 78.0 ± 1.8 | 76.3 ± 2.3 | 78.0 ± 3.3 | 74.4 ± 1.9 | 78.1 ± 2.4 | 75.1 ± 1.8 | |
| POL | LR | 68.1 ± 6.3 | 70.95 ± 6.8 | 63.0 ± 7.7 | 65.1 ± 10.0 | 73.4 ± 6.3 | 76.3 ± 8.4 | 69.6 ± 6.6 | 71.4 ± 6.9 |
| k-nn | 63.9 ± 7.2 | 70.5 ± 7.0 | 68.0 ± 12.5 | 74.0 ± 6.7 | 61.4 ± 11.8 | 67.4 ± 7.4 | 63.0 ± 9.3 | 69.2 ± 9.0 | |
| DT | 60.6 ± 5.2 | 72.1 ± 6.9 | 65.0 ± 12.2 | 69.3 ± 14.6 | 57.0 ± 11.6 | 75.5 ± 7.9 | 58.3 ± 7.8 | 71.5 ± 7.0 | |
| RF | 65.3 ± 7.9 | 68.9 ± 6.9 | 58.0 ± 15.0 | 66.4 ± 11.2 | 74.2 ± 11.2 | 73.4 ± 6.6 | 68.4 ± 6.9 | 70.0 ± 6.2 | |
| MLP | 67.7 ± 3.5 | 70.8 ± 6.2 | 75.0 ± 7.6 | 71.0 ± 12.4 | 60.5 ± 9.2 | 71.5 ± 9.5 | 64.4 ± 2.3 | 71.3 ± 5.8 | |
| QUI | LR | 72.1 ± 2.1 | 71.8 ± 1.5 | 70.0 ± 2.8 | 71.6 ± 2.4 | 74.2 ± 2.5 | 72.2 ± 2.6 | 72.7 ± 2.1 | 71.9 ± 1.9 |
| k-nn | 86.8 ± 1.1 | 90.1 ± 1.3 | 86.0 ± 1.6 | 90.2 ± 1.9 | 87.6 ± 1.7 | 90.5 ± 1.7 | 86.8 ± 1.3 | 90.0 ± 1.4 | |
| DT | 81.8 ± 1.7 | 82.3 ± 1.5 | 83.7 ± 2.8 | 85.0 ± 2.8 | 80.1 ± 2.2 | 79.6 ± 2.2 | 81.4 ± 2.1 | 81.7 ± 1.7 | |
| RF | 82.5 ± 1.8 | 83.6 ± 1.4 | 79.0 ± 2.9 | 84.6 ± 2.4 | 86.0 ± 2.9 | 83.6 ± 2.0 | 82.9 ± 1.7 | 83.7 ± 1.3 | |
| MLP | 87.1 ± 1.4 | 83.4 ± 2.0 | 87.0 ± 0.8 | 82.7 ± 1.8 | 87.0 ± 1.0 | 84.8 ± 1.7 | 86.7 ± 1.7 | 83.7 ± 2.0 | |
| Antimicr. Family | Accuracy | Specificity | Sensitivity | F1-Score |
|---|---|---|---|---|
| AMG | 82.2 ± 1.7 | 86.0 ± 2.3 | 78.7 ± 2.3 | 81.6 ± 1.9 |
| CAR | 79.6 ± 2.1 | 81.0 ± 3.5 | 78.3 ± 2.8 | 79.0 ± 2.0 |
| CF4 | 74.9 ± 2.1 | 77.0 ± 3.7 | 72.6 ± 2.6 | 74.3 ± 2.0 |
| PAP | 77.1 ± 1.7 | 80.0 ± 2.9 | 74.0 ± 2.5 | 76.1 ± 1.8 |
| POL | 68.5 ± 7.0 | 62.0 ± 14.2 | 78.1 ± 12.2 | 70.3 ± 7.2 |
| QUI | 88.1 ± 1.6 | 88.0 ± 2.1 | 88.7 ± 2.1 | 88.0 ± 1.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez-Agüero, S.; Mora-Jiménez, I.; Lérida-García, J.; Álvarez-Rodríguez, J.; Soguero-Ruiz, C. Machine Learning Techniques to Identify Antimicrobial Resistance in the Intensive Care Unit. Entropy 2019, 21, 603. https://doi.org/10.3390/e21060603
Martínez-Agüero S, Mora-Jiménez I, Lérida-García J, Álvarez-Rodríguez J, Soguero-Ruiz C. Machine Learning Techniques to Identify Antimicrobial Resistance in the Intensive Care Unit. Entropy. 2019; 21(6):603. https://doi.org/10.3390/e21060603
Chicago/Turabian StyleMartínez-Agüero, Sergio, Inmaculada Mora-Jiménez, Jon Lérida-García, Joaquín Álvarez-Rodríguez, and Cristina Soguero-Ruiz. 2019. "Machine Learning Techniques to Identify Antimicrobial Resistance in the Intensive Care Unit" Entropy 21, no. 6: 603. https://doi.org/10.3390/e21060603
APA StyleMartínez-Agüero, S., Mora-Jiménez, I., Lérida-García, J., Álvarez-Rodríguez, J., & Soguero-Ruiz, C. (2019). Machine Learning Techniques to Identify Antimicrobial Resistance in the Intensive Care Unit. Entropy, 21(6), 603. https://doi.org/10.3390/e21060603