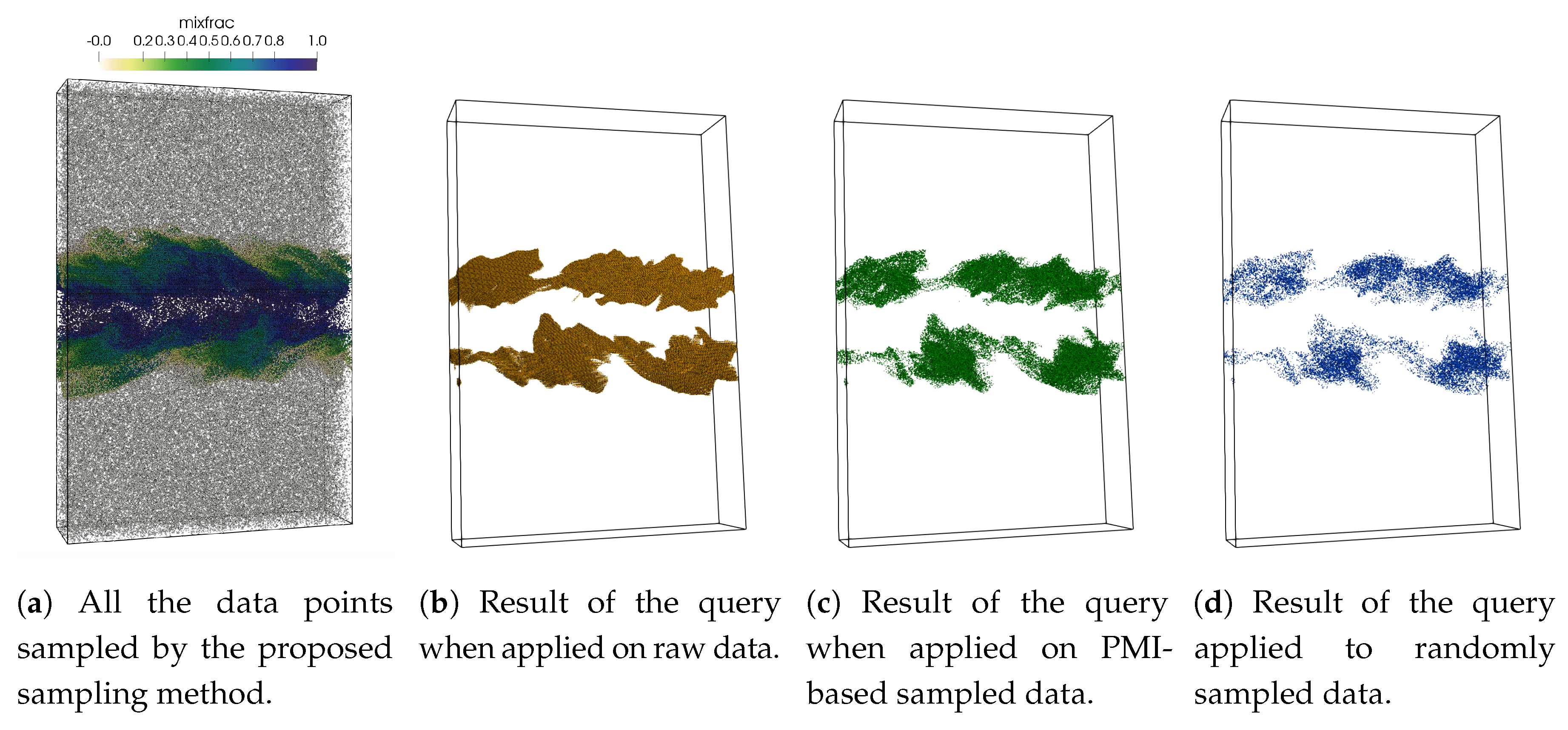
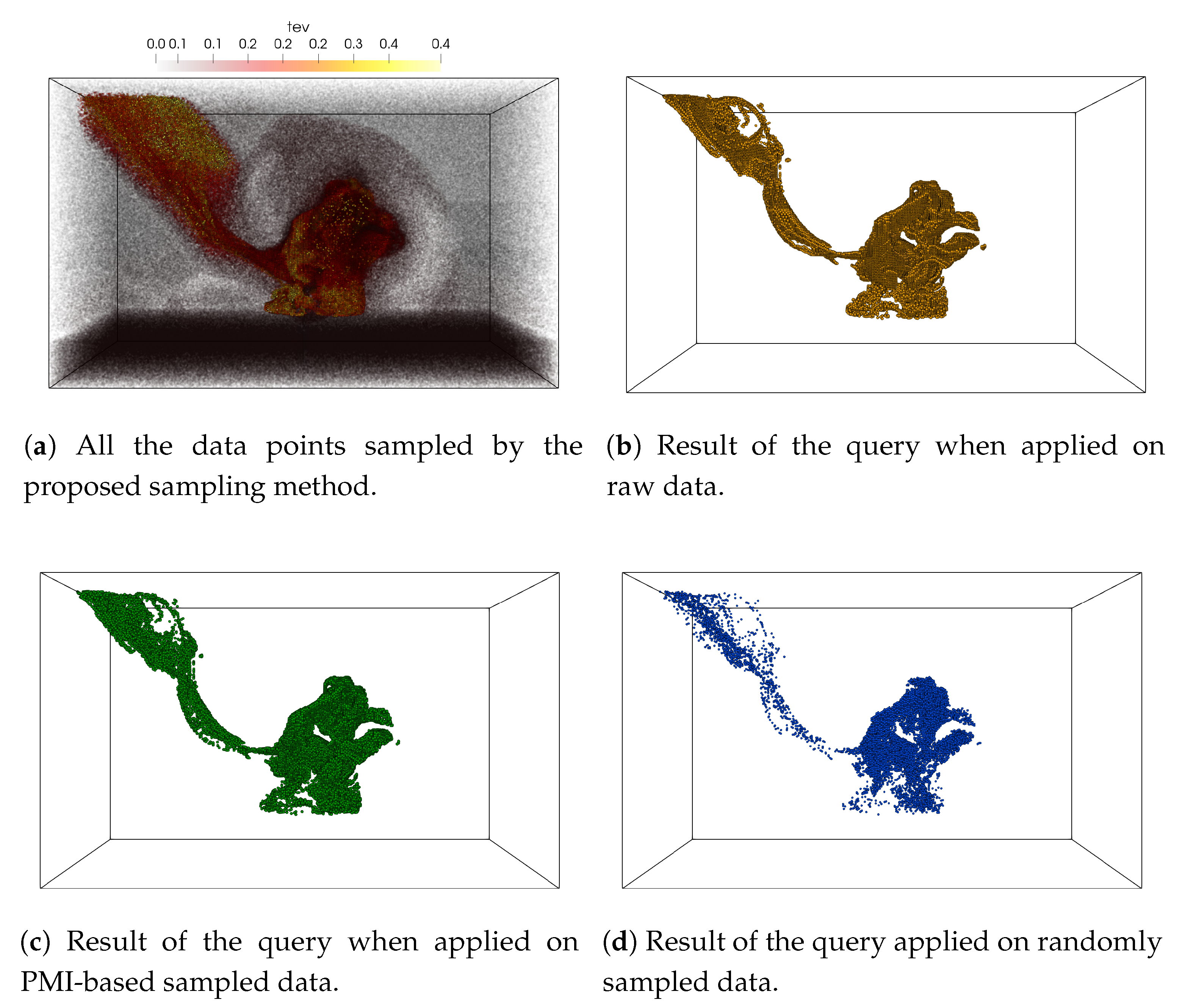
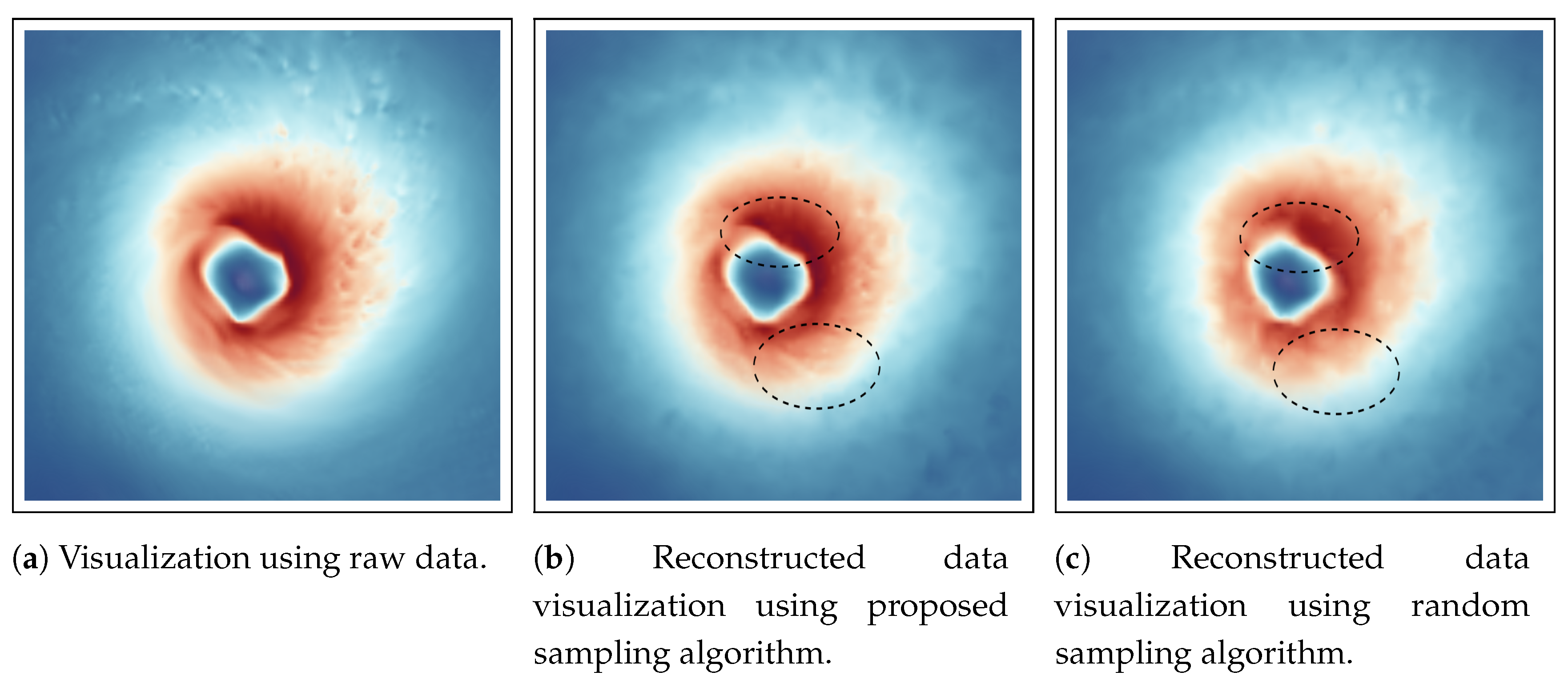
Our primary goal in this work is to develop a data sub-sampling algorithm that considers multiple variables such that the reduced sampled data set preserves the statistical association among those variables with higher fidelity. To achieve this, the proposed sampling scheme samples densely from regions where a subset of selected data variables show a strong statistical association. It has been shown previously [
11,
48] that such associative regions often represent a multivariate feature in scientific data sets where a range of values of multiple variables tends to co-occur frequently. Therefore, considering two variables and a pair of the scalar value selected from them, the existence of a strong statistical association between the value pair can be comprehended if they demonstrate high co-occurrence and the distribution of these value pairs in the spatial domain represents a joint statistical feature. The proposed sampling algorithm samples data points by following such multivariate statistical association and selects more samples from such feature regions such that the feature regions are well preserved. At the end of the sampling process, the output is an unstructured non-uniform set of points. Before we present the details of the sampling technique, first we introduce the information theoretic measure pointwise mutual information that allows us to quantify multivariate associativity for each data point and then present the sampling algorithm that uses pointwise information as the sample selection criterion.
3.2.1. Multivariate Pointwise Information Characterization
To perform multivariate statistical association driven sampling, characterization of importance of each data point is essential. In the multivariate data set, each data point has a value tuple consisting of values from each data variable associated with it. Consider a bivariate example where
X and
Y are two variables and at each data point, we have a value pair
. Here,
x is a specific value of variable
X and
y for variable
Y. For each such value pair, the shared information needs to be quantified so that we can identify data points (associated with each value pair) having a higher statistical association. Information theoretic measure pointwise mutual information (PMI) allows us to quantify such shared information. Given two random variables
X and
Y, if
x is an observation of
X and
y for
Y, then the PMI value for the value pair
is expressed as:
where
is the probability of a particular occurrence
x of
X,
is the probability of
y of variable
Y and,
is their joint probability. PMI was first introduced by Church and Hanks [
26] for the quantification of word association directly from computer readable corpora. When
,
, which means
x and
y have higher information sharing between them. If
, then
indicating the two observations follow complementary distribution. When
x and
y do not have any significant information overlap then
and
0. In this case,
x and
y are considered as statistically independent. Note that, the mutual information
yields the expected PMI value over all possible instances of variable
X and
Y [
27].
By estimating PMI values for each value pair, the shared information content for each value pair can be quantified and since each data point is associated with a value pair, we can now quantify the importance of each data point by analyzing its PMI value. If the value pair associated with a data point has high PMI value, then it is considered more important in our sampling algorithm since high PMI value indicates strong co-occurrence and therefore strong statistical association [
26]. Furthermore, previous researchers also showed that such high PMI valued regions in multivariate data sets generally correspond to multivariate features [
48] where multiple variables demonstrate a strong statistical association. Hence, using PMI the strength of statistical association for each data point can be quantified effectively.
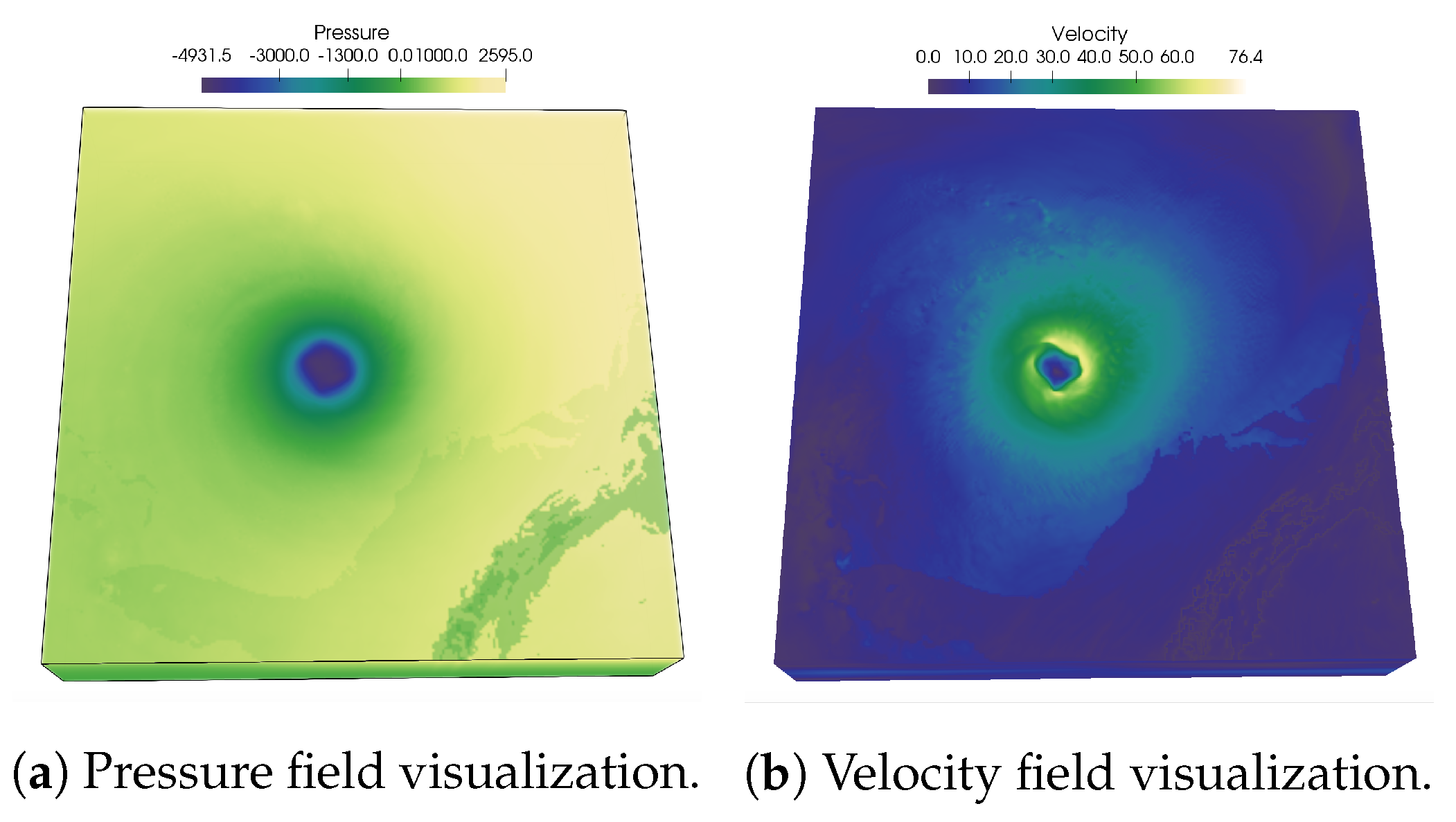
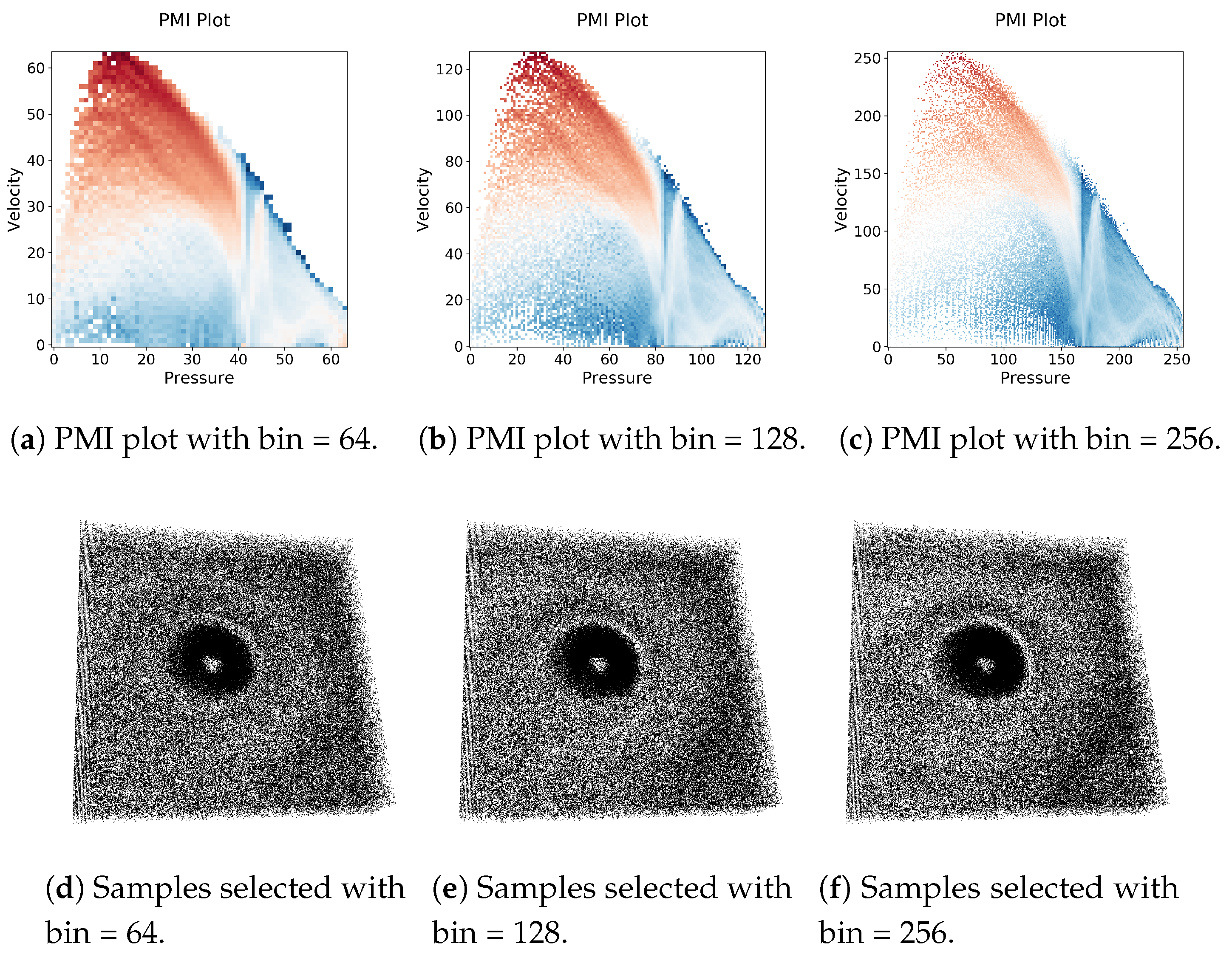
In
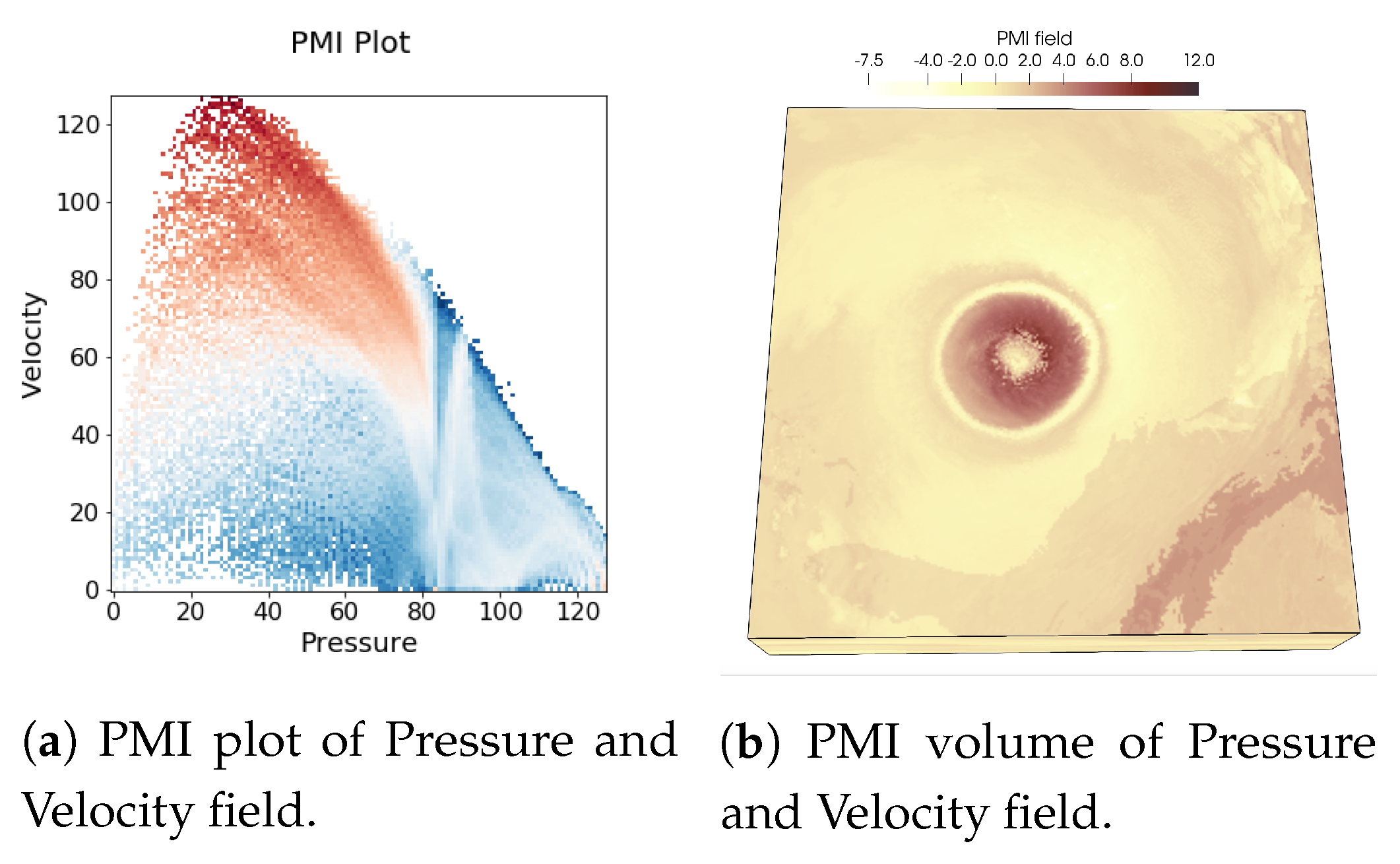
Figure 1, renderings of two scalar fields, Pressure, and Velocity, of Hurricane Isabel data set is shown to illustrate the usefulness of PMI values in characterizing multivariate association. As PMI values can be computed for each value pair of two variables, a 2-D PMI plot can be obtained where the PMI values of all value pairs can be studied. Such a PMI plot for Pressure and Velocity variables is shown in
Figure 2a. The x-axis of the plot contains values of Pressure and the y-axis contains values of Velocity (Note that, the computation of PMI values are done on a histogram space and hence, the axes in plot
Figure 2a show the bin ids. The scalar value that represents the bin center for each bin can be trivially computed from the range of data values for each variable). The white regions in the plot represent value pairs with zero PMI value. As we can see from this plot, the lower values of Pressure and moderate to high values of Velocity has higher PMI values (seen from the red regions in the plot). Now, since each spatial point in the data set has a Pressure and Velocity value associated with it, we can easily construct a new scalar field, called PMI field as suggested in [
48] by assigning the PMI value at each grid point. Visualization of such a PMI field is provided in
Figure 2b. This PMI field can be considered as an association field between Pressure and Velocity, and high PMI valued regions in this field will indicate regions that demonstrate a higher statistical association. From
Figure 2b, we can observe that the high PMI valued data points are located on the eyewall of the hurricane (the dark reddish region at the center in
Figure 2b). This is an important feature in Isabel data set and the eyewall of a hurricane typically represents the region where the most destructive high-velocity wind exists. Hence, the above discussion demonstrates the effectiveness of PMI in quantifying statistical association for each data point in the spatial domain. To preserve such statistical associative features while performing data sampling, in this work, we use PMI values as the sampling criterion for determining whether data point will be selected or not. The proposed sampling algorithm selects data points densely where the data points have high PMI values. In
Section 3.2.3 the proposed pointwise information-driven sampling algorithm is presented in detail.
3.2.2. Generalized Pointwise Information
In the above section, we introduced the information theoretic measure PMI which allows quantification of statistical association for each data point which is applicable for two variables only. In this section, we provide a generalized extension of PMI which enables us to use more than two variables while analyzing statistical association for data points for sampling. Watanabe in their work [
65] first quantified the total shared information among multiple variables as:
The quantity
is termed as
total correlation where
n represents the number of variables,
represents the probability of a specific value
of
variable
, and
indicates the joint probability of the value tuple
. Note that, total correlation quantifies the total shared information among multiple variables and does quantify importance for each data point. Later, from the above definition, Tim Van de Cruys defined a new information theoretic measure called
specific correlation [
27], which is analogous to PMI for multiple variables:
As can be seen, specific correlation (
) presented in Equation (
4) is a natural extension of bi-variate PMI depicted in Equation (
2). Specific correlation measure follows similar statistical properties as PMI discussed above, and higher values of specific correlation indicate stronger statistical association.
3.2.3. Pointwise Information-Guided Multivariate Sampling
In the above section, we presented pointwise mutual information (PMI) and a generalized extension of it which allows us to quantify the importance of each data point in terms of their statistical association considering multiple variables. In the following, we propose a novel sampling algorithm, which uses such pointwise information measure as a sampling criterion such that multivariate statistical association driven sampling can be done. Using pointwise information assigned to each data point, the proposed sampling scheme accepts data points with higher likelihood when the pointwise information value is high indicating a high statistical association. As a result, the sub-sampled data set is able to preserve the multivariate association with higher fidelity and facilitates efficient visual query and analysis.
Given a user-specified sampling fraction
(
) as an input parameter to the sampling algorithm, the proposed sampling scheme outputs a sub-sampled data set containing
points where
N is the total number of data points. In order to sample data points using their pointwise information, in this work, we use a multivariate distribution-based approach. Consider a bivariate example, where
X and
Y are two data variables using which sampling will be done. Firstly, the joint probability distribution of these two variables is estimated using a histogram. The univariate histograms of variable
X and
Y can be estimated by marginalizing the joint histogram. Since we are considering two variables to describe the sampling algorithm in this example, the joint histogram, in this case, is a 2D histogram. Each bin center in this 2D histogram represents a value pair
for the two variables for the bin
. Also, given the joint and univariate distributions of variables
X and
Y, the PMI value for each value pair
for the bin
(
where B is the number of bins) can be estimated by following Equation (
1). Therefore, a PMI value is assigned to each 2D histogram bin. Since each bin contains multiple data points, all the data points belonging to a specific 2D histogram bin is assigned with the PMI value of the current bin. In this way, all the data points are assigned a PMI value, same as its bin center’s PMI value. Finally, the normalized PMI values assigned to each 2D histogram bin is treated as the acceptance probability for the data points in that bin. For example, if a bin in the 2D histogram has normalized PMI value
, then
of the data points from this bin will be selected. Since the sampling criterion, i.e., the normalized PMI value represents the strength of statistical association for multivariate data, this sampling technique will accept more sample points from the 2D histogram bins where the value of PMI is high. As a result, the final sub-sampled data set will preserve the strong statistically associative regions with higher fidelity.
The above sampling technique is similar in spirit to the importance sampling algorithms in statistics [
66,
67] where Monte Carlo methods are used for estimating statistical expectations of one distribution by sampling from another distribution. In our algorithm, we use PMI values as the importance criterion while selecting data points. The selection of points from each 2D histogram bin is done using rejection sampling method [
64]. To determine whether to select a data point belonging to bin
having normalized PMI value
, first we generate a sample
s drawn from a standard uniform distribution
. If
then the data point is selected. This sample selection process is repeated for all the data points for each bin. It is to be noted that, since the sampling algorithm is expected to store
n data points according to the user-specified sampling fraction
, the proposed sampling scheme first scales the normalized PMI values by applying a scaling factor
such that the following condition is satisfied:
where
is the frequency of the 2D histogram bin
and
B is the number of histogram bins. The scaling factor
scales the PMI values to ensure that the total number of data points selected finally meets the desired sampling fraction
. Estimation of
for a given sampling fraction
is straightforward. First we compute the number of data points
that would be picked without any scaling by evaluating
. If
then scaling factor
, else scaling factor
. Please note that the above sampling algorithm naturally extends to multi-variable domain (i.e., more than two variables) and for the characterization of the statistical association in such cases, the generalized definition of pointwise statistical association, i.e., the specific correlation measure presented in Equation (
4) can be used without the loss of any generality.
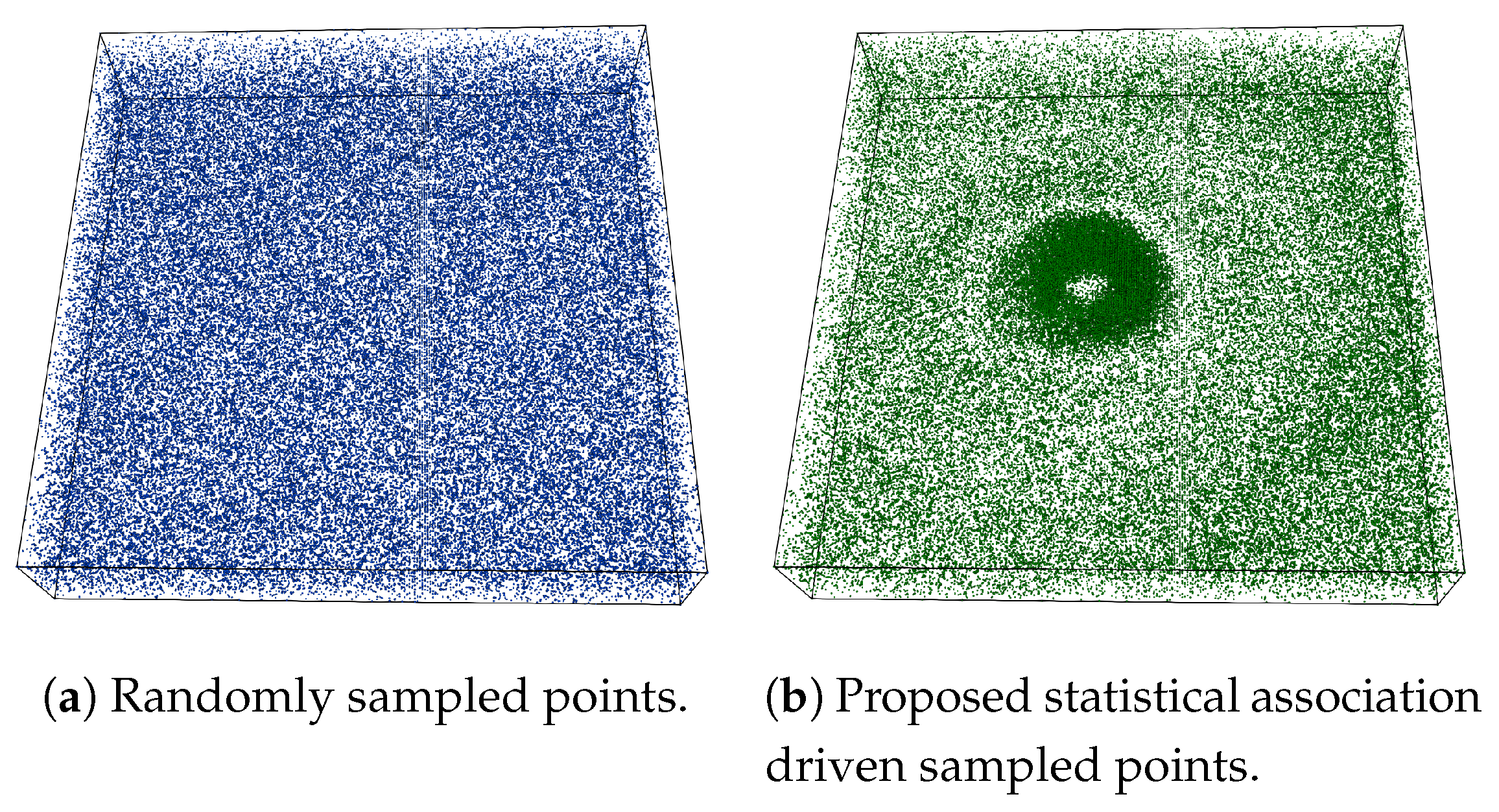
An example of the proposed sampling algorithm is provided in
Figure 3 using Isabel data set where Pressure and Velocity variables are used while sampling data points. The sampling fraction for this example is set to
, i.e.,
of total data points are selected in the sub-sampled data. In
Figure 3a a point rendering of the sampled data produced by the random sampling algorithm is shown and
Figure 3b depicts the point samples picked by the proposed association driven sampling algorithm. It can be observed that, since given the variables Pressure and Velocity, the eyewall region of hurricane Isabel data set has a higher statistical association (as observed in the PMI field in
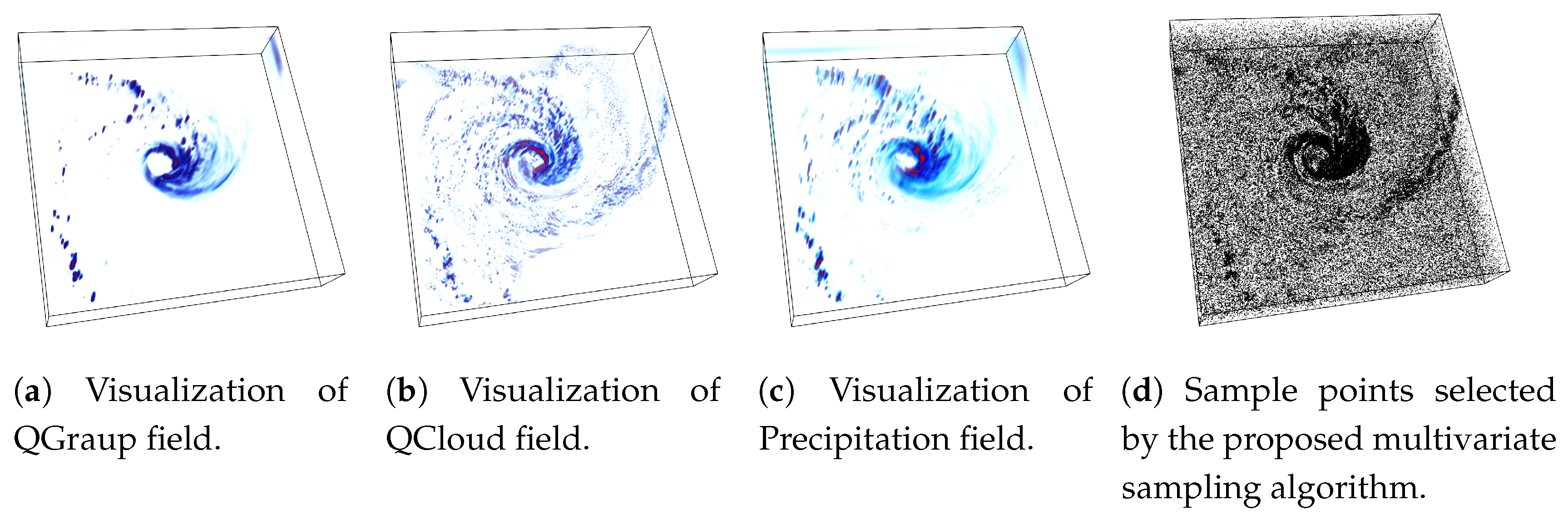
Figure 2b), the proposed sampling algorithm selects data points densely from such multivariate feature regions to preserve the feature more accurately. Another example of the proposed sampling algorithm applied to three variables (QGraup, QCloud, and Precipitation) of Hurricane Isabel data is shown in
Figure 4.
Figure 4a–c provide the visualization of the raw data for the three variables respectively and in
Figure 4d we show the sample points selected by the proposed multivariate sampling algorithm. Note that, since this example uses three variables together, we have used the generalized pointwise information measure, specific correlation presented in Equation (
4) for computing the multivariate statistical association for the data points considering three variables. It can be seen that the cloud and rain bands show strong statistical association and as a result, more data points are selected from such regions (the dark black regions in
Figure 4d).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}