2.4. Measurements
(1). Pot weight
Wj is the weight of a soybean pot on day j after seed germination (kg), which was measured by an electronic balance. All pots were weighed at 6 pm from seed germination to plant harvest.
(2). Soil water content
The soil water content in each pot was calculated according to the pot weight as follows:
where
θj,b is the soil water content in a soybean pot at the beginning of day
j, immediately after irrigation (g g
−1 of soil dry weight);
θj,e is the soil water content at the end of day
j when weighing the pot (g g
−1 of soil dry weight);
θj is the average soil water content on day
j (g g
−1 of soil dry weight);
Wp is the weight of the empty pot (kg);
Ws is the weight of air-dried soil that was loaded into the pot (kg); and
Ij is the irrigation amount for the pot on day
j (kg).
(3). Irrigation amount
Whether the soybeans needed to be irrigated was determined by comparing the soil water content in a pot and the corresponding lower limit. The irrigation amount was calculated as follows:
where
θFC is the soil water at field capacity (g g
−1 of soil dry weight);
θj−1,e is the soil water content in a pot at the end of day (
j − 1) (g g
−1 of soil dry weight); and
θlm is the corresponding lower limit of soil water content for experimental treatment of the pot (g g
−1 of soil dry weight). The irrigation amount was metered by measurement and implemented at 7 am.
(4). Soybean water consumption
The actual evapotranspiration of soybean in each pot was calculated according to the pot weight and irrigation amount by the following formula:
where
ETc,j is the evapotranspiration of soybean on day
j (mm)—it could be converted from kg.
(5). Aboveground biomass and seed yield
Soybean aboveground biomass of three plants in a pot were measured at the end of each growth stage (after seed germination) by breaking the pot. The aboveground accumulated biomass at a given stage was the difference of biomass between this stage and the previous stage. Seed yield and number of seeds in a pot were measured at harvest, and 1000 seed weight was obtained. Seed yield and aboveground biomass were measured by an electronic balance after drying in the sun.
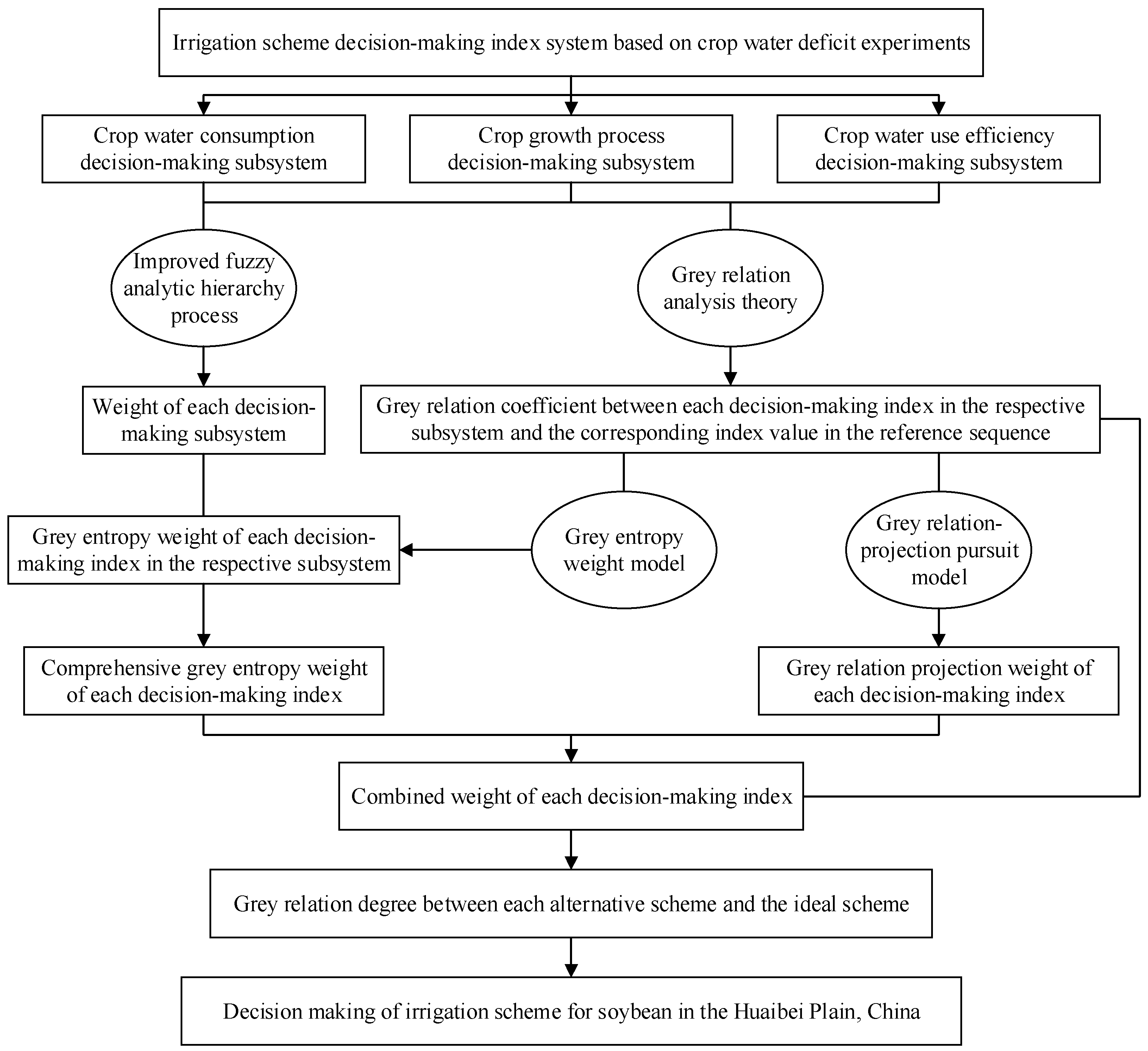
2.5. Irrigation Scheme Decision-Making Model
The process to establish the soybean irrigation scheme decision-making model in this study included the following seven steps (
Figure 3):
Step 1: According to the targets of decision-making, the irrigation scheme decision-making index system was divided into three aspects of crop water consumption, crop growth process, and crop water use efficiency. Specifically, the index system could be denoted as {x*(k, j)|k = 1, 2, 3; j = 1, 2, …, nk}, where x*(k, j) was the decision-making index j in the k-th decision-making subsystem; nk was the number of indices in the k-th subsystem; k = 1, 2, 3, respectively, represented crop water consumption, crop growth process, and crop water use efficiency subsystems; and n was the total number of decision-making indices and n = n1 + n2 + n3. Therefore, the samples of irrigation scheme decision-making index were described as {x*(i, k, j)|i = 1, 2, …, N; k = 1, 2, 3; j = 1, 2, …, nk}, where N was the number of alternative irrigation schemes. The normalized samples x(i, k, j) were obtained according to Equations (6) and (7).
For an index (positive index), the larger the index value was, the more efficient the irrigation scheme was. This index value was normalized by the following formula [
29]:
where
x*(
i,
k,
j) and
x*(
i,
k,
j) represent the minimum and maximum values of the decision-making index
j in the
k-th subsystem among all irrigation schemes, respectively.
Additionally, for an index (negative index), the smaller the index value was, the more efficient the scheme was. This index value was normalized as follows [
29]:
Step 2: Grey relation analysis (GRA) as proposed by Deng [
36], is an effective scheme decision-making method. First, the reference sequence of the ideal irrigation scheme {
x0(
k,
j) =
x(
i,
k,
j)|
i = 1, 2, …,
N;
k = 1, 2, 3;
j = 1, 2, …,
nk} was generated, by taking the largest normalized value of each decision-making index in the respective subsystem among all alternative irrigation schemes. Then, the absolute difference between a sample sequence and the reference sequence was obtained as follows [
20]:
where ∆(
i,
k,
j) is the absolute difference between the index
j in the
k-th subsystem for the scheme
i and the corresponding index value in the reference sequence.
Accordingly, the grey relation coefficient between the index
j in the
k-th subsystem for the scheme
i and the corresponding index value in the reference sequence
ξ(
i,
k,
j) was determined as follows [
20]:
where
∆(
i,
k,
j) and
∆(
i,
k,
j) represent the minimum and maximum absolute differences among all indices in the
k-th subsystem for all schemes, respectively;
λ is the distinguishing coefficient, which is selected from 0 to 1. In this study,
λ took 0.5 for guaranteeing a good calculation stability and a moderate distinguishing ability [
20,
36].
Step 3: An improved fuzzy analytic hierarchy process based on the accelerating genetic algorithm (AGA-FAHP) [
28] was used to calculate the weight of each subsystem {
wsub,k|
k = 1, 2, 3}.
The experts were invited to compare the importance of crop water consumption, crop growth process, and crop water use efficiency decision-making subsystems in pairs, and, then, the fuzzy complementary judgment matrix
Asub = (
akl)
3×3 was obtained. The AGA-FAHP method was used to test and correct the consistency of
Asub and calculate
wsub,k. Specifically, if
Asub satisfied the full consistency, the following equation would be established [
28]:
where the left item in Equation (10) is the consistency index of
Asub. If the result of this consistency index was less than a critical value, it showed that
Asub had a satisfactory consistency; otherwise,
Asub should be corrected. The corrected
Asub was denoted as
Bsub = (
bkl)
3×3, and the ordering weights of element in
Bsub were still recorded as {
wsub,k|
k = 1, 2, 3}. Furthermore,
Bsub met the following formula [
28]:
where
Bsub is regarded as the optimal fuzzy consistency judgment matrix of
Asub when the result of
CIC reached a minimum value;
CIC(3) is the consistency index coefficient;
d is a non-negative parameter and selected from 0 to 0.5 for guaranteeing the relationship of importance between two decision-making subsystems [
28].
When the result of
CIC(3) was less than a critical value, it indicated that
Asub had a satisfactory consistency and the obtained subsystem weights were acceptable; otherwise, the parameter
d was adjusted until
Asub met a satisfactory consistency. Based on plenty of numerical experiments and relevant research [
28,
37], the matrix was considered to have a satisfactory consistency when the value of
CIC was less than 0.20 in this study.
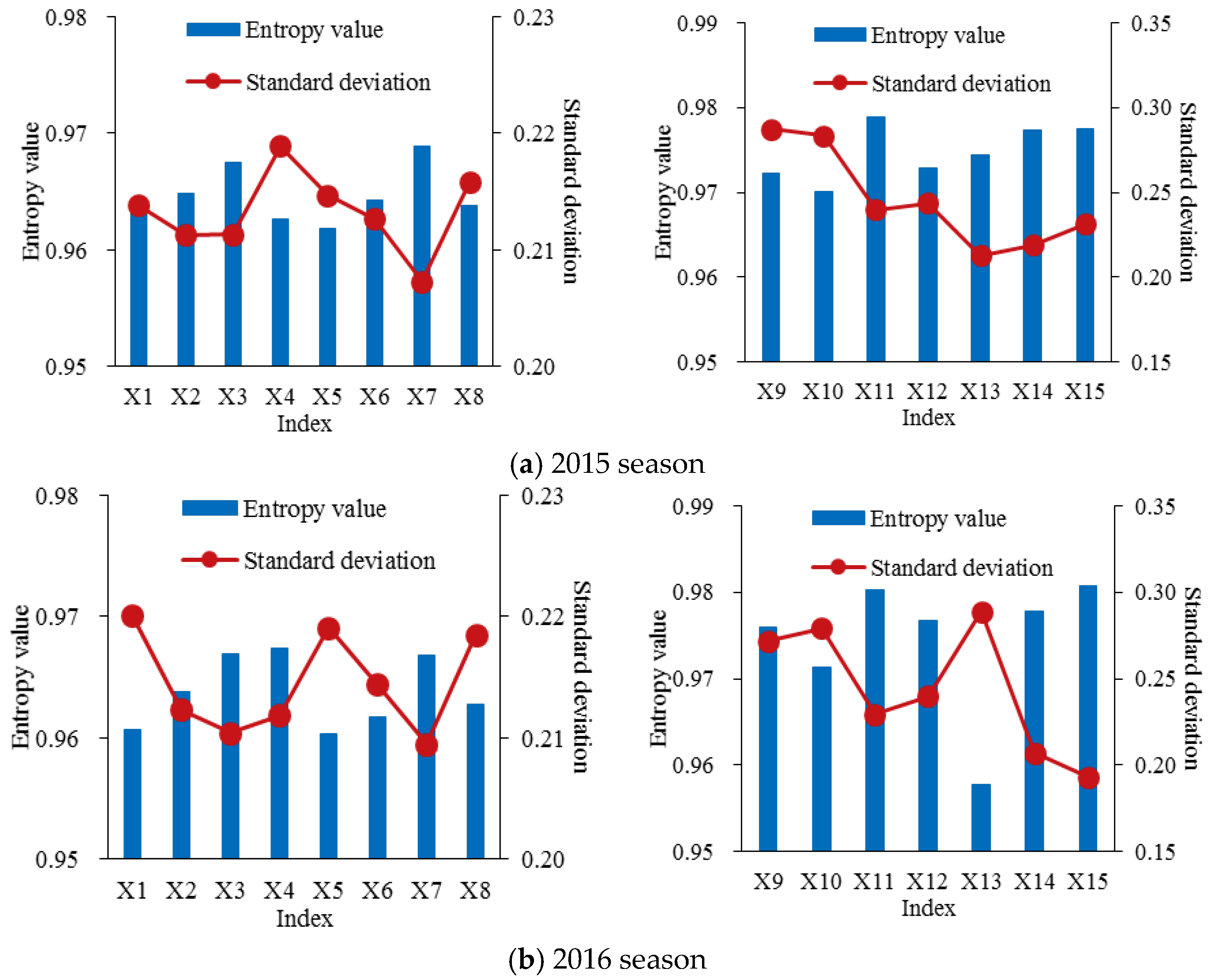
Step 4: A grey entropy weight method combined with the AGA-FAHP was proposed to determine the weight of each index in the respective subsystem {we(k, j)|k = 1, 2, 3; j = 1, 2, …, nk}.
The grey relation coefficient between the index
j in the
k-th subsystem for the scheme
i and the corresponding index value in the reference sequence, could be converted into a probability variable
p(
i,
k,
j) based on information entropy theory as follows:
Then, the corresponding entropy value
e(
k,
j) was obtained by the following formula [
38]:
Considering the consistency among the initial weight of each index reflected by entropy value, a complementary judgment matrix
Aek = (
ujqk)
nk×nk was built as follows:
Furthermore, the elements in
Aek were obtained according to the following formula [
28]:
Similarly, according to the method for determining the weight of the decision-making subsystem, the AGA-FAHP method was used to obtain the optimal consistency judgment matrix
Bek = (
vjqk)
nk×nk and the grey entropy weight of each index in the respective subsystem
we(
k,
j) by solving the following optimization issue [
28]:
Moreover, the comprehensive grey entropy weight of each decision-making index {
wE(
k,
j)|
k = 1, 2, 3;
j = 1, 2, …,
nk} was calculated by the following formula:
Step 5: In addition, a grey relation–projection pursuit model was also built to determine the weight of each decision-making index {
wP(
k,
j)|
k = 1, 2, 3;
j = 1, 2, …,
nk}. In this study, the grey relation coefficient between the index
j in the
k-th subsystem for the scheme
i and the corresponding index value in the reference sequence
ξ(
i,
k,
j), was used to construct the projection eigenvalue of the scheme
i. Specifically, a one-dimensional projection eigenvalue was obtained by synthesizing the high-dimensional data {
ξ(
i,
k,
j)|
i = 1, 2, …,
N;
k = 1, 2, 3;
j = 1, 2, …,
nk} according to the grey relation–projection pursuit model as follows:
where
Z(
i) is the one-dimensional projection eigenvalue of an
n-dimensional grey relation coefficient
ξ(
i,
k,
j) for the alternative irrigation scheme
i;
y = (
y(1, 1), …,
y(1,
n1),
y(2, 1), …,
y(2,
n2),
y(3, 1), …,
y(3,
n3)) is the
n-dimensional unit projection vector.
Furthermore, according to projection pursuit theory, the obtained projection eigenvalue point
Z(
i) should satisfy a certain distribution characteristic [
29,
30,
39]. In detail, the distribution of local projection points within a given distance should be as concentrated as possible, and, meanwhile, the overall distribution of all projection points should be as scattered as possible. Therefore, for calculating a relatively optimal unit projection vector
y, the following projection index function
Q(
y) was established [
29,
30,
39]:
where
SZ is the standard deviation of projection eigenvalue series
Z(
i) and
DZ is the local density of
Z(
i). The corresponding calculation formulas are shown as follows [
29,
39]:
where
is the average value of
Z(
i);
R is the window breadth of local density and the value usually is
θSZ. In this study, the value of
θ was 0.1 [
39].
r(
i,
m) represents the distance between any two projection eigenvalues
Z(
i) and
Z(
m);
U is the unit step function, the function value is 1 when [
R −
r(
i,
m)] ≥ 0 and is 0 when [
R −
r(
i,
m)] < 0.
When the value of
Q(
y) reached a relative maximum, an optimal
y was obtained. The question could be solved by the following optimization function based on the AGA [
29,
39]:
Correspondingly, the grey relation projection weight of each decision-making index was calculated according to the optimized
y [
29,
30,
39]:
Step 6: The combined weight {
wC (
k,
j)|
k = 1, 2, 3;
j = 1, 2, …,
nk} of grey entropy weight
wE(
k,
j) and grey relation projection weight
wP(
k,
j) for each decision-making index in the respective subsystem was obtained according to minimum relative entropy theory [
40]:
The optimization problem in Equation (23) could be further converted to the following equation according to the Lagrange multiplier method [
28]:
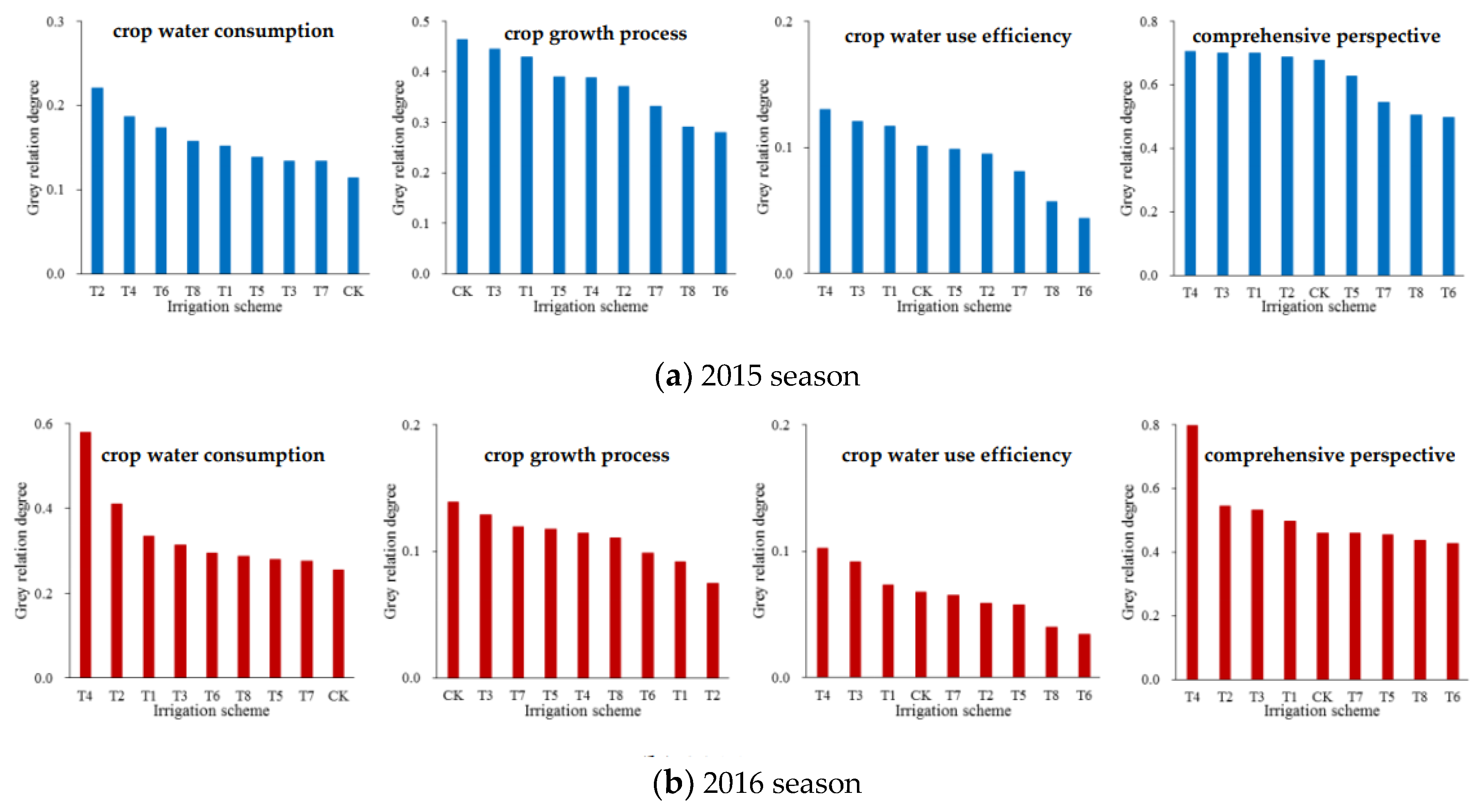
Step 7: Finally, the grey relation degree between each alternative irrigation scheme and the ideal scheme was calculated. Furthermore, the larger the value of the grey relation degree was, the more effective the alternative scheme was. The grey relation degree for an alternative irrigation scheme was obtained by summing the product of the grey relation coefficient and combined weight for each decision-making index as follows [
20]:
where
G(
i) represents the grey relation degree between the alternative irrigation scheme
i and the ideal scheme.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}