1. Introduction
The way in which students learn and teachers teach has changed considerably due to the rise of information and communications technologies in higher education. For example, online and blended courses’ (partially or fully) use of the Internet to deliver course content and instructions to learners, transform face-to-face learning into online learning [
1]. Learning Management Systems (LMSs), which offer online learning materials, such as course content, quizzes, assignments, and forums, are considered as one way of supporting online learning. Teachers that use LMSs can simply manage and provide learning resources, and also monitor students’ learning progress as almost every action of the teachers and students in such systems are logged [
2]. Gaining insight into the online behavior of students enables teachers to improve learning and teaching. However, it is worth mentioning that the data stored by LMSs is mainly raw and provides no solid information or measurements of existing theoretical concepts. Additionally, as many students using LMSs fail to adapt to the requirement of such environments, LMSs also create pedagogical challenges (besides their benefits) for teachers. Therefore, a better understanding of the process, and whether and how these data can be used for improving the learning process, is crucial [
3,
4].
There have been several studies revolving regarding the fundamental success or failure factors of online learning. For example, Azevedo et al. [
5] and Hooshyar et al. [
6] highlighted several challenges, e.g., self-pacing and self-regulation, more effort, rapid learning, etc., that usually hinder students from adapting to LMSs. Among all, procrastination—especially a tendency to put off completing tasks—and a lack of time are underlined by students as the main reasons when asked about their failure or dropping out of an online course (e.g., [
7,
8]). Tuckman [
9] and Cerezo et al. [
10] have stressed the negative effect of procrastination on learning achievement in students, whereas, similarly, Cerezo et al. [
11] and Visser et al. [
12] named procrastination as the most observed behavior in online learning which jeopardizes students’ academic success. Identifying students with learning difficulties in a course—and informing their teachers and themselves to take the necessary measures—is considered as one important step in improving student performance, leading to their academic success [
13]. Educational Data Mining (EDM) is an emerging field focusing on developing methods that mine educational data to understand the behavior of students to possibly identify those with learning difficulties at early stages. The application of EDM techniques to educational data gives instructors the opportunity to take appropriate decisions which will eventually improve learning and lead to the improvement of academic success [
14].
There has been extensive research employing EDM approaches to predict grades or the performance of students in a course. To do so, surprisingly, they mostly focus on students’ past performance (e.g., cumulative GPA) and/or non-academic factors (e.g., gender, age) to build their predictive models without considering students’ activity data [
15]. Such predictive models in many cases simply fail to consider that many non-academic indicators (e.g., gender, race, socio-economic status) or past performance factors cannot be influenced by either students or teachers. In many situations, these models may negatively affect students’ performance and discourage them—if students are made aware that such variables are used in the prediction of their performance—because they may assume that their past circumstances have already set them up for (future) failure [
16]. Instead, more research should use students’ activity data—which can, logically, be among the best indicators of students’ performance and course grade—during the course to develop their predictive models.
Given the importance of procrastination as an underlying indicator (which is related to students’ activity and performance in a course, not their past performance) for predicting students’ performance in a course and the success of advanced EDM approaches in predicating students’ performance, there are only a very few studies that have taken into account the application of EDM techniques for prediction of students’ performance in a course through their procrastination behaviors. Yet, though the related research shows good performance and has proven to be useful (e.g., [
17]), they ignore some important factors, for example, including underlying factors of procrastination behaviors (e.g., inactive time which is the time that goes by from when assignments become open until students view it for the first time), employing and comparing advanced EDM approaches, and considering practitioners by proposing simple and easy-to-implement EDM approaches which are yet precise, indicating a research gap. Research filling this gap could shed a light on useful means for enhancing EDM research in higher education.
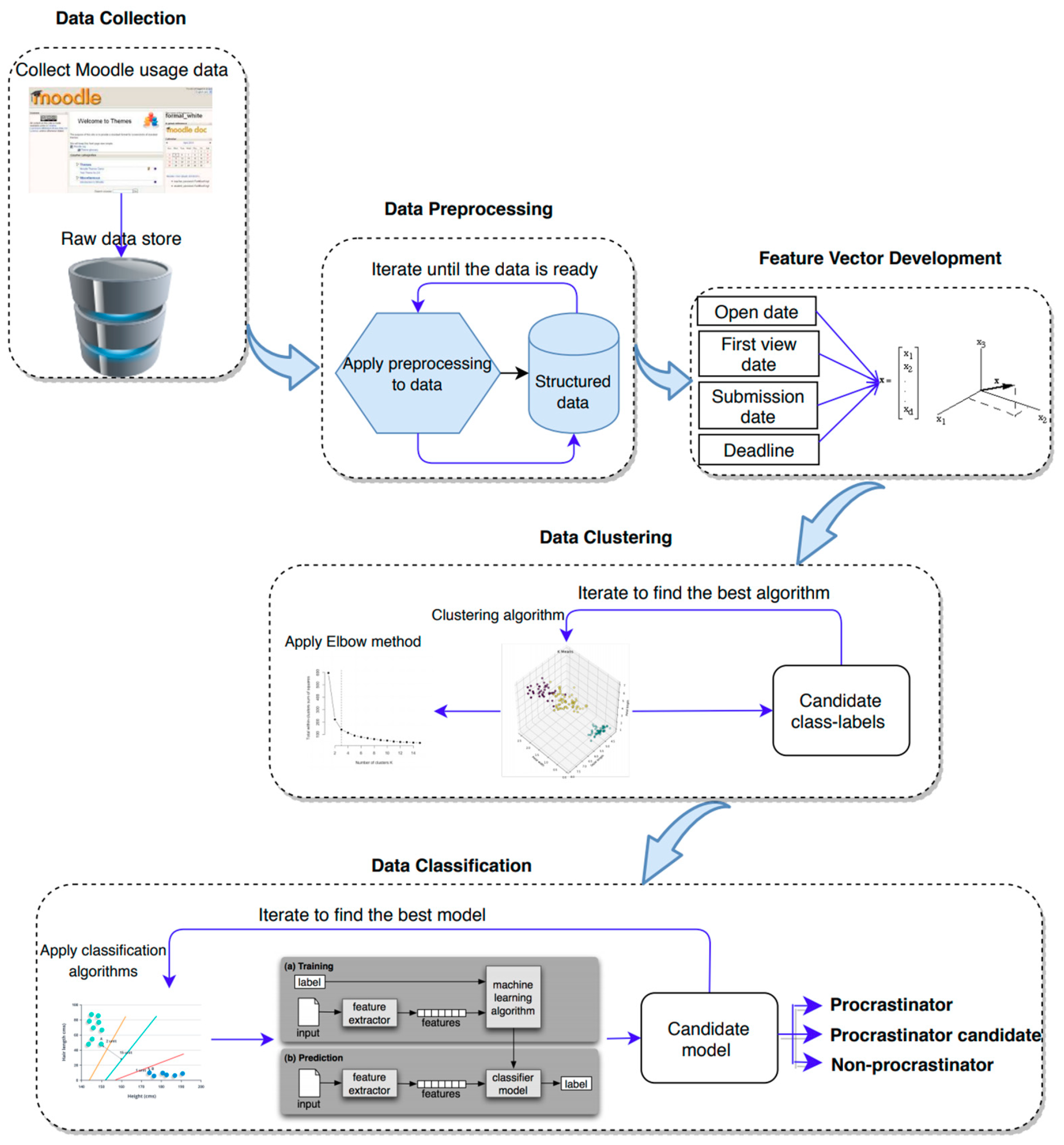
In this work, to address these issues, we propose an algorithm, called PPP, for predicting students’ performance through procrastination behaviors using their assignment submission data. To do so, we first build feature vectors representing the submission behavior of students for each assignment, using inactive and spare time. We then use clustering and classification methods to put students into different procrastination behavior categories based on their submission behavior. As both types of quantitative variables are usually used in building feature vectors in EDM research (continuous and categorical), we consider both types of variables to investigate which works best in PPP. To this aim, we formulate our research question as follows:
How accurately can our proposed algorithm predict students’ performance through their procrastination behaviors?
Which classification method offers superior predictive power, when using various numbers of classes in the feature vectors? What is the effect of using continuous versus categorical feature vectors on different classification methods?
Our proposed algorithm contributes to EDM research in multiple ways: (1) It predicts students’ performance through their procrastination behavior using their submission data; (2) it considers fundamental variables of students’ procrastination behaviors, including students’ behavioral patterns, before the due date of assignments, to establish a comprehensive students’ submission behavior; (3) it takes into account the benefits of cluster analysis to semantically ensure the appropriateness of the clusters to the procrastination behavior of students; and (4) it takes into account both continuous and categorical feature vectors to study the effect of different feature types of prediction power of our algorithm.
The outline of this paper is as follows:
Section 2 reviews the related studies in the area of academic procrastination, EDM research, and its application in a procrastination context.
Section 3 lays out our proposed methodology.
Section 4 revolves around the experimental results. Finally,
Section 5 and
Section 6 offer discussions and the conclusion of this study, respectively.
5. Discussion
We proposed in this study a novel algorithm for automatic assessment of students’ performance through procrastination behaviors by using their assignment submission data (called PPP). PPP can, in a timely manner, predict and identify students facing learning difficulties at the beginning of the semester and provide educators with an opportunity to intervene when necessary (by taking necessary remedial actions). For example, educators can keep those students that are flagged procrastinators or procrastination candidates by PPP under observation and provide them with further assistance in completing their assignments. More interestingly, instructors can offer feedback to all three groups of students—procrastinators, procrastination candidates, and non-procrastinators—according to PPP. Offering timely feedback (produced through different means, such as the prediction of students’ future behaviors and learning difficulties) to students rather than giving feedback at the end of semester is an important factor in their academic performance. As reported by many researchers, e.g., [
52,
53], regular, timely, and appropriate feedback plays an important role in both reducing procrastination tendencies and boosting students’ performance. Michinov et al. [
53] stated that informing students about their peers’ performance could potentially reduce their procrastination tendencies, whereas Tuckman [
52] noticed that encouraging and motivating students could lead to decreased procrastination tendencies.
PPP has been designed and developed to automatically detect different type of procrastination behaviors and could be considered as a generalized approach, making it a good candidate for providing personalized learning for students with different needs. To develop PPP, we firstly, in a novel way, calculated spare time and inactive time—time that goes by from when a student submits the assignments until the assignment is due and time that goes by from when assignments becomes open until a student views it for the first time, respectively—for developing feature vectors which represent students’ submission behaviors. It should be noted that, unlike many existing works that ignore the actual students’ behavioral patterns (for example, one can submit his/her assignment on-time, but be a candidate for future procrastination) before the homework due date in the decision-making of their proposed approach, PPP takes into account on-time, late, or non-submissions, and the students’ behavioral patterns before the homework due date to have a comprehensive students’ submission behavior during the whole semester.
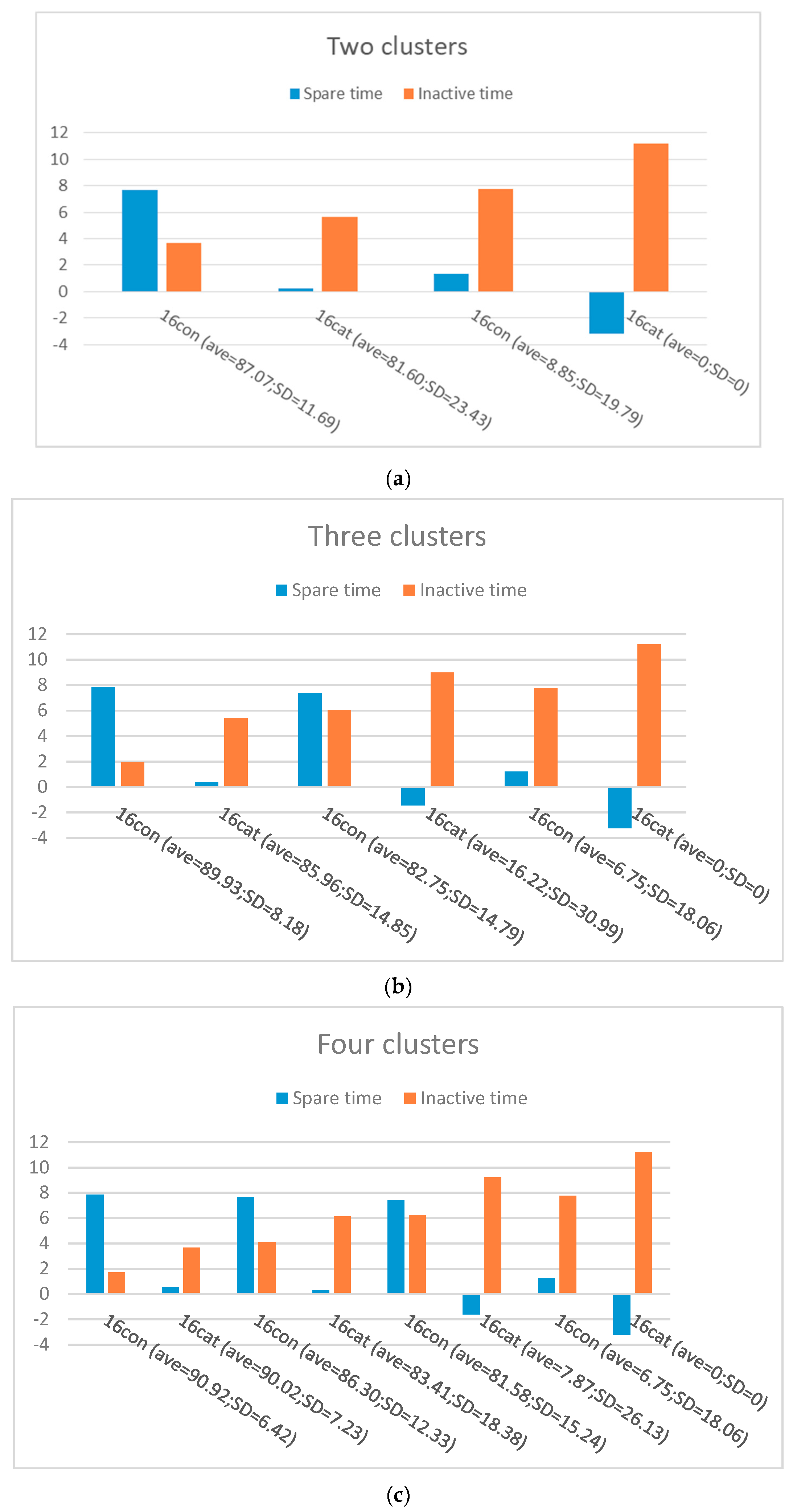
Secondly, using the feature vectors and Algorithm 2, we clustered students with similar behaviors in different groups, namely procrastinators, procrastination candidates, and non-procrastinators. Spectral clustering is used in this study (see Algorithm 2) to identify different clusters. In two clusters, Cluster A and B, with a small and rather large inactive times, and large and small spare time are considered as the non-procrastinators group (with a high average score) and procrastinators (with a low average score), respectively. In three clusters, Cluster A and C have the highest and lowest average score, smallest and largest inactive time, and largest and smallest spare time, respectively. Therefore, Cluster A is considered as non-procrastinators group and Cluster C as procrastinators. Cluster B, however, is regarded as procrastination candidate group with a medium average score (average = 61.45). Regarding four clusters, cluster A, B, and C appear to have a high average score, and cluster D has a very low average score. Cluster A and B with a small inactive time and bigger spare time compared to other clusters, and higher average scores can be considered as non-procrastinators. Cluster D, with the lowest average score, which has the largest inactive time and smallest spare time than the other three clusters, can be seen as procrastinators, while Cluster C with a relatively high average score, large inactive time, and small spare time can be called procrastination candidates. These findings suggest that the larger the average inactive time and the smaller the average of spare time is, the lower the average of assignment score of the students is. Additionally, this analysis indicates that no more distinct (significant) clusters can be achieved beyond three clusters. The Elbow method also implies that three clusters is the optimal number for our data. On the other hand, it is apparent that, for more personalization (personalized intervention), more clusters can be formed (a higher value for k) as the number of classes increases. Consequently, we conclude that two and four clusters of students result in either grouping procrastinators and procrastination candidates together (coarse clusters), or having some part of the procrastination candidates’ group shared with non-procrastinators (too detailed clusters), respectively, as our analysis showed the more clusters that are formed, the more groups of non-procrastinators emerge (reducing procrastination candidates). According to our analysis and the Elbow method, three clusters is the optimal number, which is well connected to the rationalization behind PPP (he correlation between spare time, inactive time, and average score of each cluster of students).
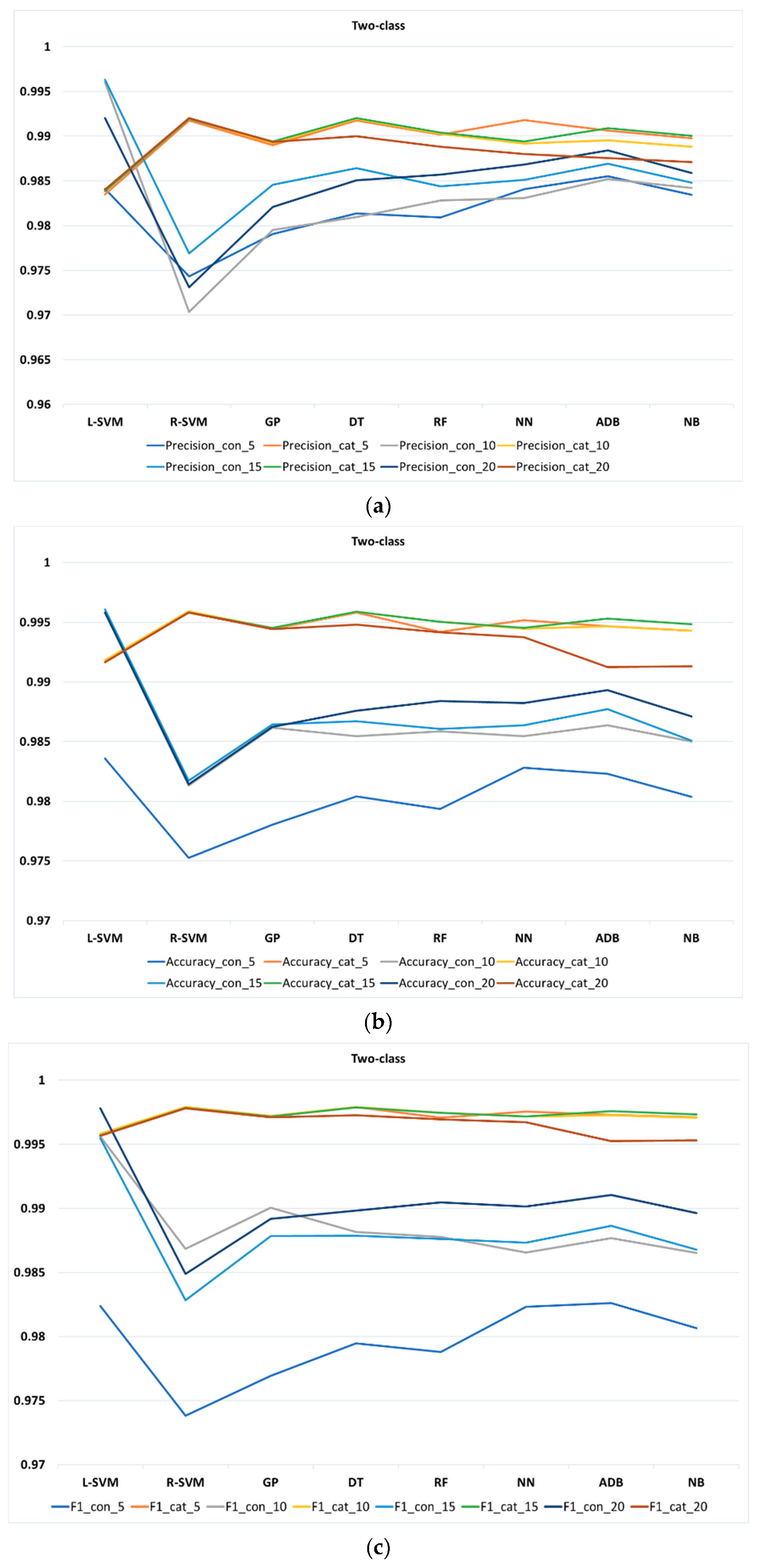
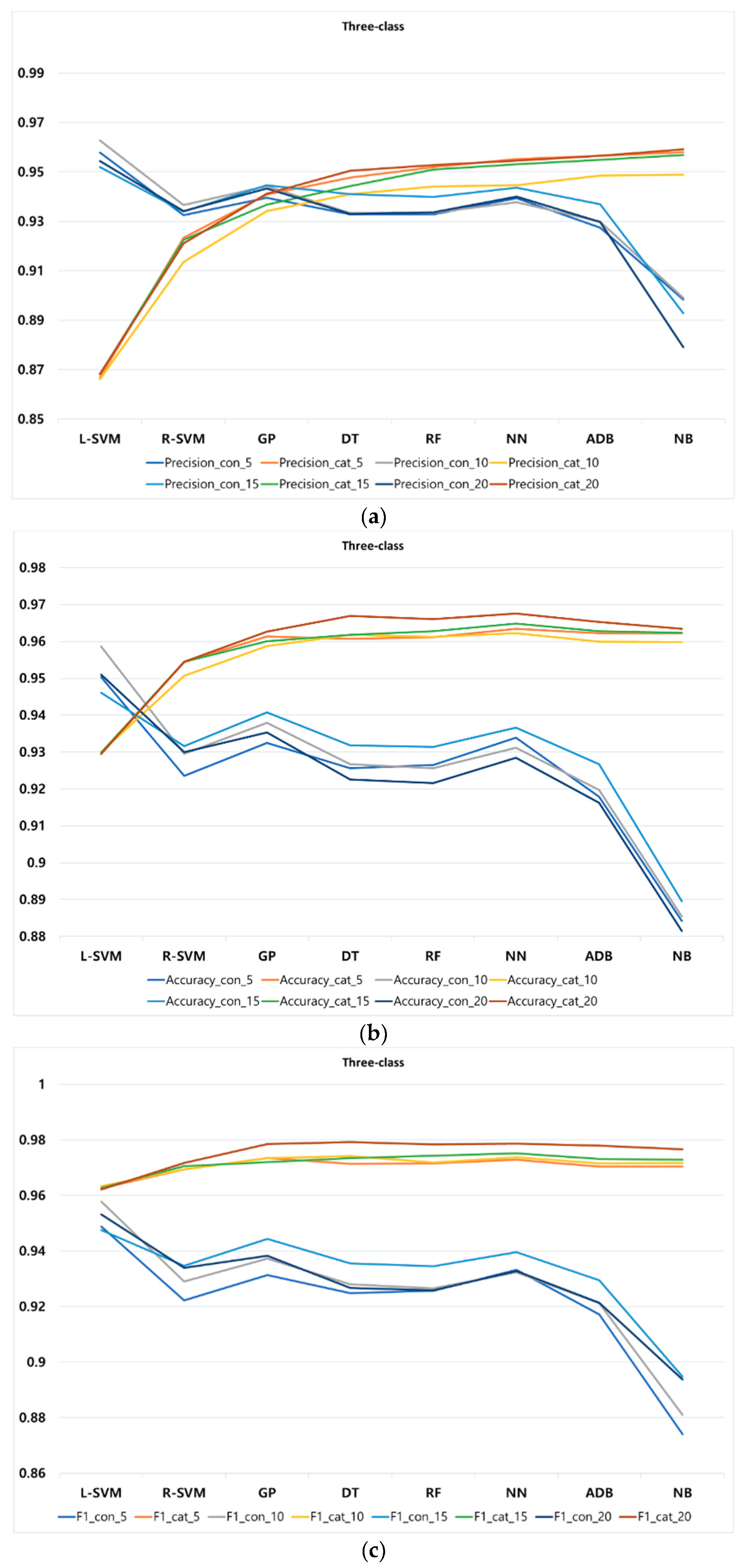
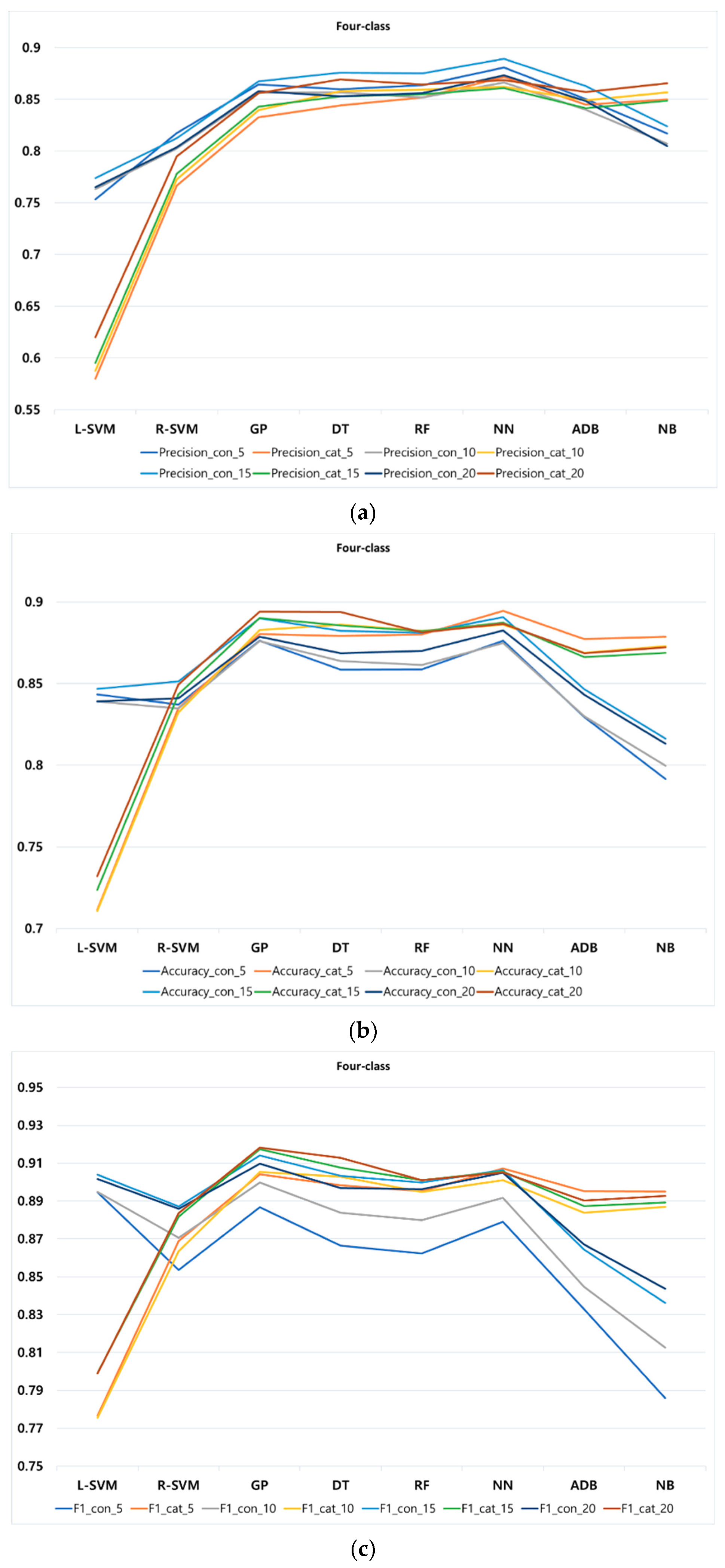
As a third step, we compared eight different classification methods, using four performance metrics of precision, accuracy, F1 score, and recall, to find the most suitable classifier for predicting students’ procrastination behaviors. According to our findings, the accuracy of the classification methods is almost higher with a smaller number of classes and all methods appear to be sensitive to the increment in the number of classes. In other words, the accuracy of the classification methods mostly increases with the decrement in class numbers. According to our findings, regarding the average of all performance metrics at different k-fold for all classification methods, among all classification methods, L-SVM and R-SVM are the best in two-class, at different k-fold, with continuous and categorical features, respectively. For three-class, L-SVM and NN are the best performed methods at different k-fold for continuous and categorical features, respectively. In four-class, NN mostly performs the best in both continuous and categorical feature at different k-fold.
As mentioned in previous sections, beyond three-class no significant group can be formed, therefore, we focus more on the comparison of the classification methods in three-class. It should be noted that in case educators intend to respond to students in a more personalized way, more classes could be considered in our proposed approach. A comparison of various metrics for three-class reveals that, for categorical features, NN outperforms other methods with precision, recall, accuracy, and F1-score of 95%, 96%, 96%, and 97%, respectively, whereas for continuous features L-SVM could achieve precision, recall, accuracy, and F1-score of 95%, outperforming other methods. Observe that by increasing the number of classes, some of these methods may perform slightly lower than others. In our approach, categorical features perform slightly better and more robust compared to continuous features. Furthermore, an increment in the number of classes results in a decrement of the prediction power of the classification methods. By employing different number of k-fold on the methods, we also found that, in our proposed approach, most of the methods tend to be rather stable using small or large k-folds. In other words, overall, classification methods show a slight increment or decrement of precision, accuracy, and F1-score at different k-folds, indicating the stability of our proposed approach.
Consequently, PPP proved to successfully predict students’ performance through their procrastination behaviors with an accuracy of 96%. Regarding the variable types used in feature vectors, we found categorical features to be more robust and perform slightly better than continuous features in PPP.
6. Conclusions
Students’ procrastination tendency is frequently named by several researchers as an important factor negatively influencing performance of students in online learning, making its prediction a very useful task for both educators and students. In this study, we proposed a novel algorithm, called PPP, which uses students’ assignment submission behavior to predict their performance through procrastination behavior. PPP, unlike existing works, not only considers late or non-submissions, but also investigates students’ behavioral patterns before a homework due date. The proposed approach, shown in Algorithm 3, is flexible and, in an automatic way, identifies students with different sorts of learning difficulties in various online learning environments as they mostly share the same characteristics as Moodle (e.g., they all mostly log opening, due, submission, and students’ first view date of the assignments and courses). To predict students’ procrastination tendencies, PPP firstly builds a feature vector representing the submission behavior of students for each assignment, using inactive and spare time. It then uses clustering and classification methods to put students into different procrastination behavior categories based on their submission behavior. A course including 242 students from the University of Tartu in Estonia was used to evaluate the effectiveness of PPP. The results reveal that in labelling students using clustering, two and four clusters of students results in either coarse clusters or too detailed clusters, as our analysis showed that the more clusters are formed, the more groups of non-procrastinators emerge (reducing procrastination candidates). As our analysis and the Elbow method show, three clusters is the optimal number, which is well connected to the rationalization behind PPP (correlation between spare time, inactive time, and average score of each cluster of students). Another important task was to classify students using the labels. In this phase, we compared eight different classification methods to find the most suitable classifier for predicting students’ procrastination behavior. Our findings in this regard show that the accuracy of the classification methods is almost higher with a smaller number of classes and all methods appeared to be sensitive to the increment in the number of classes. NN, with an accuracy of 96%, showed a better performance using categorical features compared to other classification methods, while L-SVM perform the best in continuous features with an accuracy of 95%. Finally, regarding the variable types used in the feature vectors, we found categorical features to be more robust and perform slightly better than continuous features. In conclusion, PPP could successfully predict students’ performance through their procrastination behavior with an accuracy of 96%.
In future work, we aim to extend our study by using feature vectors of different lengths from different courses. Additionally, we intend to create different hybrid feature vectors using students’ submission behavior to investigate the effect of various time-related indicators on the procrastination behavior of students.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





