Abstract
A vital aspect of the Multiple Classifier Systems construction process is the base model integration. For example, the Random Forest approach used the majority voting rule to fuse the base classifiers obtained by bagging the training dataset. In this paper we propose the algorithm that uses partitioning the feature space whose split is determined by the decision rules of each decision tree node which is the base classification model. After dividing the feature space, the centroid of each new subspace is determined. This centroids are used in order to determine the weights needed in the integration phase based on the weighted majority voting rule. The proposal was compared with other Multiple Classifier Systems approaches. The experiments regarding multiple open-source benchmarking datasets demonstrate the effectiveness of our method. To discuss the results of our experiments, we use micro and macro-average classification performance measures.
1. Introduction
Multiple Classifier Systems (MCS) are a popular approach to improve the possibilities of base classification models by building more stable and accurate classifiers [1]. MCS are one of the major development directions in machine learning [2,3]. MCS proved to have a significant impact on the system performance, therefore they are used in many practical aspects [4,5,6,7].
MCS are essentially composed of three stages: generation, selection and fussion or integration. The aim of the generation phase is to create basic classification models, which are assumed to be diverse. This goal is achieved, inter alia, by methods of dividing the feature space [8]. In the selection phase, one classifier (the classifier selection) or a certain subset of classifiers is selected (the ensemble pruning) learned at an earlier stage. The fusion or the integration process combines outputs of base classifiers to obtain an integrated model of classification, which is the final model of MCS. One of the commonly used methods to integrate base classifiers’ outputs is the majority vote rule. In this method each base model has the same impact on the final decision of MCS. To improve the efficiency of MCS the weights are defined and used in the integration process. The use of weights allows to determine the influence of a particular base classifier on the final decision of MCS. The most commonly used approach to determining the weights uses probability error estimators or other factors [9,10,11]. A distance-weighted approach to calculating the weights is also often used in many problems, were the weights are determined [12,13,14]. In general, this approach is based on the query where the appropriate object is located. In this article, we use the feature subspace centroid in the definition of the distance-weighted approach.
There are, in general, two approaches to partition a dataset [15]. In horizontal partitioning the set of data instances is divided into a subset of datasets that are used to learn the base classifiers. Bagging bootstrap sampling to generate a training subset is one of the most used method in this type of datasets partitioning. In the vertical partitioning the feature set is divided into feature subsets that are used to learn the base classifiers. Based on vertical partitioning feature space the forest of decision trees was proposed in [16]. Contrary to the types of dataset partitioning mentioned above, the clustering and selection algorithm [17] is based on the clustering. After clustering, one classifier is selected for each feature subspace. In this algorithm the feature space partition is an independent process from the classifier selection process and precedes this selection. The non-sequential approach to clustering and selection algorithm was probesed in [18,19].
In this work, we propose a novel approach to determining the division feature space into the disjoint feature subspace. Contrary to the clustering and the selection method described above in our proposal the proces of partitioning the feature space follows base classifier learning. Additionally, the proposed approach does not use clustering to define a feature subspace. The partiotion of the feature space is defined by base classifier models, and exactly through their decision boundaries. According to our best knowledge the use of the decision boundary of base models for partitioning feature space is not represented in MCS. Finally, the centroids of proposed feature subspace are used in the weighted majority voting rule to define the final MCS decision.
Given the above, the main objectives of this work can be summarized as follows:
- A proposal of a new partitioning of the feature space whose split is determined by the decision bonduaries of each decision tree node which is a base classification model.
- The proposal of a new weighted majority voting rule algorithm dedicated to the fusion of decision tree models.
- An experimental setup to compare the proposed method with other MCS approaches using different performance measures.
2. Related Works
Classifier integration using the geometrical representation has already been mentioned in [20]. Based on transformations in the geometrical space spread on real-valued, non-categorical features this procedure has proven itself to be more effective in comparison to others, commonly used integration techniques such as majority voting [21]. The authors have studied and proved the effectiveness of an integration algorithm based on averaging and taking median of values of the decision boundary in the SVM classifiers [22]. Next, two algorithms for decision trees were proposed and evaluated [23,24]. They have proven themselves to provide better classification quality and ease of use than referential methods.
Polianskii and Pokorny have examined a geometric approach to the classification using Voronoi cells [25]. Voronoi cells fulfill the role of the atomic elements being classified. Labels of the nearest training objects are assigned to the boundaries. The algorithms walks along the boundaries and integrates them with respect to the associated class. SVM, NN and random forest classifiers were used in evaluation.
The nearest neighbor algorithm can be used to test which Voronoi cell an object belongs to [26]. By avoiding the calculation of the Voronoi cells geometry, the test appears to be very efficient. On that basis a search lookup was described by Kushilevitz et al. [27]. A space-efficient data structure is utilized to find an approximately nearest neighbor in nearly-quadratic time with respect to the dimensionality.
However, the nearest neighbor algorithms are difficult. The number of prototypes needs to be specified beforehand. Using too many causes high computational complexity. Too few, on the other hand, can result in an oversimplified classification model. This matters especially when datasets are not linearly separable, have island–shaped decision space, etc. There are several ways to solve this problem that can be found in the literature. Applying Generalized Condensed Nearest Neighbor rule to obtain a set of prototypes is one of the possible solutions [28]. In this method a constraint is added, that each of the prototypes has to come from the training dataset. A different approach was proposed by Gou et al. [29]. Firstly, kNN algorithm is used to obtain a certain number of prototypes for each class. Afterwards the prototypes obtained in the first step are transformed by the local mean vectors. This results in a better representation of the distribution of the decision space.
Decision trees are broadly used due to their simplicity, intuitive approach and at the same time good efficiency. The way they classify the objects is by recursive partitioning of the classification space [30]. Although they have first appeared more than three decades ago [31], the decision tree algorithm and its derivatives are in use in a range of industry branches [32].
At some point it has been noticed that the local quality of each of the base classifiers is different. The classifier selection process was introduced in order to choose a subset of base classifiers that have the best classification quality over the region. The selection is called static, when the division can be determined prior to the classification. In the opposite scenario the new pattern is used to test the models’ quality [33]. Kim and Ko [34] have shown a greater improvement in the classification when using local confidence over averaging over the entire decision space.
Another approach to the classifier integration is by using a combination of weighting and local confidence estimation [35]. The authors noticed, that using only a subset of points limited to a certain area in the training process results in a better classification performance.
An article [36] discusses a variation of the majority voting technique. A probability estimate is computed as the ratio of properly classified validation objects over certain geometric constraints known a priori. Regions that are functionally independent from each other are treated separately. The proposed approach provides a significant improvement in the classification quality. The downside of this method is that the knowledge of the domain is necessary to provide a proper division. Additionally, the split of the classification space has to be done manually. The performance of the algorithm was evaluated using a retinal image and classification in its anatomic regions.
An improvement in the weighted majority voting classification can be observed for class–wise approach covered in [37]. For each label weights are determined separately for the objects in the validation dataset.
Random forest, introduced by Breiman in 2001 [38] is one of the most popular ensemble methods. It has proven itself to be very effective and many related algorithms were developed since then. Fernandez et al. studied 179 different classifications algorithms using 121 datasets [39]. The random forest outperforms most of the examined classifiers. It uses decision trees trained on distinct subsets of the training dataset. A majority voting over classifications of every model for an object under test is calculated as the final result.
Numerous algorithms involving gradient boosting and decision trees have emerged. Extreme Gradient Boosting (XGB) is an implementation of one of the most widely spread stacking techniques. It is used especially in machine learning competitions [40,41,42]. In theory subsequent decision trees are trained. Consecutive models minimize the value of loss function left by their predecessors [43]. Another implementation of Gradient Boosting Decision Tree designed with performance in mind, especially when working with datasets with many dimensions, is LightGBM [44]. Compared to the previous library, statistically no loss of performance in the classification is observed, but the process of training can be up to 20 times faster.
Vertical or horizontal partitioning can be used to force the diversity between base classifiers [30]. The datasets of extreme sizes are classified better using horizontal partitioning compared to bagging, boosting or other ensemble techniques [45].
3. Proposed Method
The proposed method is based on previous works of authors, but suggests a slightly different approach [23,24]. While the cited articles used static division into regions of competence, this paper presents an algorithm with a dynamic approach. The main goal of introducing the dynamically generated Voronoi cells is to achieve better performance than with other referential methods of the decision tree commitee ensembling: majority voting and random forest.
Before proceeding with the algorithm, datasets are normalized to the unit cube (every feature takes values in range of ) and two most informative features are extracted. Feature extraction is conducted using ANOVA method.
The first step of the presented algorithm is training a pool of base decision trees. To make sure the classifiers are different from one another, they are trained on the random subsets of the dataset. Having a commitee of decision trees trained, we are extracting rectangular regions that fulfill the following properties:
- Their area is maximal.
- Every point they span is labeled with the same label by every single classifier (labels can differ across different classifiers). In other words regions span over the area of objects equally labelled by the classifier points.
In practice this means, that the entire space is divided along every dimension at all the split points of every decision tree. This way the regions are of the same class as indicated by every model.
Having the space divided into subspaces, midpoints are calculated. Let us denote by S the set of obtained subspaces and by and the range of subspace s along axis and respectively. The midpoint of subspace s will be denoted as . For every subspace and every label the weight is calculated using the following formula:
where is the euclidean distance between the points and , is the number of classifiers that classify the subspace s with the label , is the correction which purpose is to make the sum of weights equal 1 and is a function that returns 1 if and s are neighbors and 0 otherwise, i.e.,
It’s important to notice, that according to the Formula (2), for every subspace s. This is because the contribution of the subspace itself is reflected by the second summand of the Equation (1). The term was chosen in the denominator, because then the subspace makes up half of the weight’s value, i.e.,
The process of obtaining subspaces is depicted in the Figure 1. Let us suppose, that all the base decision trees (colorful lines on subfigure a) are oriented in the same way - all the points below the decision boundary are classified by the given decision tree with a single label, different from all the objects above the line. As it was stated before, the competence regions are obtained by splitting the entire space at the splitpoints of all the decision trees (subfigure b). When calculating the weight of the label for each region, the region itself (filled with dark grey in subfigure c) together with its neighbors (lightgrey in subfigure c) are considered. Whereas the region itself contributes to half of its weight, contributions from every neighbor depend on the distance between its midpoint and the midpoint of the considered region. The entire procedure is presented in Algorithm 1.
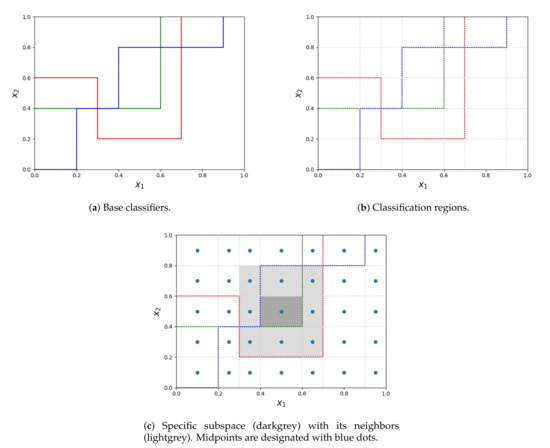
Figure 1.
The process of extracting subspaces from base classifiers and determining neighbors for a subspace.
| Algorithm 1: Classification algorithm using dynamic regions of competence obtained from decision trees. |
|
4. Experimental Setup
The algorithm was implemented in Scala. Decision tree and random forest implementation from Spark MlLib were used [46]. The statistical analysis was performed with Python and libraries Numpy, Scipy and Pandas [47,48,49]. Matplotlib was used for plotting [50]. In Spark’s implementation the bottommost elements (leaves) are classified with a single label. The algorithm performs a greedy, recursive partitioning in order to maximize the information gain in every tree node. Gini impurity is used as the homogeneity measure. Continuous feature discretization is conducted using 32 bins. The source code used to conduct experiments is available online (https://github.com/TAndronicus/dynamic-dtree).
The experiments were conducted using open-source benchmarking datasets from repositories UCI and KEEL [51,52]. Table 1 describes the datasets used with the number of features, instances and imbalance ratio.

Table 1.
Descriptions of datasets used in experiments (name with abbreviation, number of instances, number of features, imbalance ratio).
The imbalance ratio was given to stress the fact that accuracy is not a reliable metric when comparing the performance of the presented algorithm and the reference. It is calculated as the quotient of the count of objects with the major label (most frequent) and the objects with minor label (least common): [53]. If the value of Imb equals 1, then the dataset is balanced—all classes have the same amount of instances. The larger the value, the more imbalanced the dataset is. Some of the datasets are highly imbalanced, because of the low imbalance ratio, so other metrics other than average accuracy should be considered when comparing the performance of classifiers. The reason is explained in the following example. Suppose for a binary classification problem. When a classifier labels all the test objects with the label of the major class, its accuracy is . In the parentheses, together with the names, abbreviations of the datasets names were placed by which they will be further referenced for brevity.
The experiments were conducted according to the procedure described in Section 3 and repeated 10 times for each hyperparameter set. Together with integrated classifiers, referential methods were evaluated: majority voting of the base classifiers and random forest. The results were averaged. was taken as the number of base classifiers.
5. Results
The purpose of the experiments was to compare the classification performance measures obtained by the proposed algorithm (with the subscript i) with the known methods as references: majority voting (subscript ) and random forest (subscript ). The experiments were conducted 10 times for each setup and the results were averaged. Because we conducted experiments on the multiclass datasets, as the classification evaluation metrics we use micro- and macro-average precision, recall and F-score which is the harmonic mean of precision and recall. For this reason F-score takes both false positives and false negatives into account. Additionally, we present the results for overall accuracy. The F-score was computed alongside the accuracy because of the high imbalance of multiple datasets used, as it was indicated in Section 4. The F-score describes the quality of a classifier much better than the overall accuracy for the datasets with a high imbalance ratio and gives a better performance measure of the incorrectly classified cases than the overall accuracy. Accuracy can be in this case artificially high. The metrics are calculated as defined in [54]. In the Table 2 the results are gathered: average accuracy, micro- and macro-average F-score, while the Table 3 and Table 4 show results for micro- and macro-average respectively. Together with the mentioned metrics, Friedman ranks are presented in the last row – the smaller the rank, the better the classifier performs. However, it should be noted that for micro-average performance measures the result obtained for precision and recall are the same. This result is justified by the micro-averaging disadvantage, because for the frequent single-label per instance problems [55].
Table 2.
Average accuracy and f-scores for the random forest, the majority voting and the proposed algorithm together with Friedman ranks.
Table 3.
Micro-average precision and recall for the random forest, the majority voting and the proposed algorithm together with Friedman ranks.
Table 4.
Macro-average precision and recall for the random forest, the majority voting and the proposed algorithm together with Friedman ranks.
6. Discussion
For the proposed weighting method of the decision tree integration all the calculated classification performance measures are better than of the referrential algorithms as indicated by the Friedman ranks. This statement holds true for all the classification performance measures that have been used. Post-hoc Nemenyi test after Friedman ranking requires the difference in ranks of 0.38 to define a significant statistical difference between the algorithms. For performance measure this condition is met, which means that the proposed method achieves statistically better results than the reference methods and . Whereas for performacne measure there is no such property as shown in the Figure 2. The micro-average measure counts the fraction of instances predicted correctly across all classes. For this reason the micro-average can be a more useful metric than macro-average in the class imbalance dataset. Thus, the results show that the proposed method improves the classification results, in particular of imbalanced datasets. This conclusion is confirmed by the values obtained for other performance measures. And so for micro-avarage precision and recall the difference in ranks betwenn and indicated the statistical differences in the results. The corresponding difference for and algorithms is very close to being able to state the statistical differences in the results because it is equal 0.36 (see Table 3). In case of macro-avarage precision the obtained results do not indicate significant difference in this performance measure. Whereas for macro-avarage recall (see Table 4) the obtained avarage Friedman ranks are equal for and algorithms.

Figure 2.
Friedman ranks for calculated metrics together with Nemenyi critical values.
7. Conclusions
This paper presents a new approach for determining MCS. Contrary to the clustering and selection method we propose that the feature space partition is based on decision bonduaries defined by base classifier models. It means that we propose to use learned base classification models instead of clustering to determine the feature subspace. The centroids of the proposed feature subspace are used in the weighted majority voting rule to define the final MCS decision. In particular, a class label prediction for each feature subspace is based on adjacent feature subspaces.
The experimental results show that the proposed method may create an ensemble classifier that outperforms the commonly used methods of combining decision tree models—the majority voting and RF. Especially, the results show that the proposed method statistically improves the classification results measured by the mico-avarage classification performance measure.
According to our best knowledge the use of the decision boundary of base models to partition feature space is not represented in MCS. On the other hand, the proposed approach has also a drawback, because it uses geometrical centroids of defined feature subspaces. Consequently, our future research needs to be aimed at finding centroids of objects belonging to particular feature subspaces. Additionally, we can consider another neighborhood of a given feature subspace necessary to determine the decision rule. This neighborhood may, for example, depend on the number of objects in particular the feature subspace.
Author Contributions
Conceptualization, R.B. and J.B.; methodology, R.B.; software, J.B.; validation, R.B. and J.B.; formal analysis, J.B.; investigation, J.B.; resources, R.B.; data curation, J.B.; writing—original draft preparation, J.B.; writing—review and editing, R.B. and J.B.; visualization, R.B. and J.B.; supervision, R.B.; project administration, R.B.; funding acquisition, R.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Science Centre, Poland under the grant no. 2017/25/B/ST6/01750.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MV | Majority Voting |
| RF | Random Forest |
| SVM | Support Vector Machine |
References
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev.-Data Mining Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Andrysiak, T. Machine learning techniques applied to data analysis and anomaly detection in ECG signals. Appl. Artif. Intell. 2016, 30, 610–634. [Google Scholar] [CrossRef]
- Burduk, A.; Grzybowska, K.; Safonyk, A. The Use of a Hybrid Model of the Expert System for Assessing the Potentiality Manufacturing the Assumed Quantity of Wire Harnesses. LogForum 2019, 15, 459–473. [Google Scholar] [CrossRef]
- Dutta, V.; Choraś, M.; Pawlicki, M.; Kozik, R. A Deep Learning Ensemble for Network Anomaly and Cyber-Attack Detection. Sensors 2020, 20, 4583. [Google Scholar] [CrossRef]
- Heda, P.; Rojek, I.; Burduk, R. Dynamic Ensemble Selection–Application to Classification of Cutting Tools. In International Conference on Computer Information Systems and Industrial Management; Springer: Berlin/Heidelberg, Germany, 2020; pp. 345–354. [Google Scholar]
- Xiao, J. SVM and KNN ensemble learning for traffic incident detection. Physica A 2019, 517, 29–35. [Google Scholar] [CrossRef]
- Rokach, L. Decomposition methodology for classification tasks: A meta decomposer framework. Pattern Anal. Appl. 2006, 9, 257–271. [Google Scholar] [CrossRef]
- Burduk, R. Classifier fusion with interval-valued weights. Pattern Recognit. Lett. 2013, 34, 1623–1629. [Google Scholar] [CrossRef]
- Mao, S.; Jiao, L.; Xiong, L.; Gou, S.; Chen, B.; Yeung, S.K. Weighted classifier ensemble based on quadratic form. Pattern Recognit. 2015, 48, 1688–1706. [Google Scholar] [CrossRef]
- Woźniak, M.; Graña, M.; Corchado, E. A survey of multiple classifier systems as hybrid systems. Inf. Fusion 2014, 16, 3–17. [Google Scholar] [CrossRef]
- Aguilera, J.; González, L.C.; Montes-y Gómez, M.; Rosso, P. A new weighted k-nearest neighbor algorithm based on newton’s gravitational force. In Iberoamerican Congress on Pattern Recognition; Montes-y Gómez, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 305–313. [Google Scholar]
- Ksieniewicz, P.; Burduk, R. Clustering and Weighted Scoring in Geometric Space Support Vector Machine Ensemble for Highly Imbalanced Data Classification. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 128–140. [Google Scholar]
- Geler, Z.; Kurbalija, V.; Ivanović, M.; Radovanović, M. Weighted kNN and constrained elastic distances for time-series classification. Expert Syst. Appl. 2020, 113829. [Google Scholar]
- Guggari, S.; Kadappa, V.; Umadevi, V. Non-sequential partitioning approaches to decision tree classifier. Future Computing Inform. J. 2018, 3, 275–285. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Kuncheva, L.I. Clustering-and-selection model for classifier combination. In KES’2000. Fourth International Conference on Knowledge-Based Intelligent Engineering Systems and Allied Technologies. Proceedings (Cat. No. 00TH8516); IEEE: Piscataway, NJ, USA, 2000; Volume 1, pp. 185–188. [Google Scholar]
- Jackowski, K.; Wozniak, M. Algorithm of designing compound recognition system on the basis of combining classifiers with simultaneous splitting feature space into competence areas. Pattern Anal. Appl. 2009, 12, 415. [Google Scholar] [CrossRef]
- Lopez-Garcia, P.; Masegosa, A.D.; Osaba, E.; Onieva, E.; Perallos, A. Ensemble classification for imbalanced data based on feature space partitioning and hybrid metaheuristics. Appl. Intell. 2019, 49, 2807–2822. [Google Scholar] [CrossRef]
- Pujol, O.; Masip, D. Geometry-Based Ensembles: Toward a Structural Characterization of the Classification Boundary. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1140–1146. [Google Scholar] [CrossRef]
- Burduk, R. Integration Base Classifiers in Geometry Space by Harmonic Mean. In Artificial Intelligence and Soft Computing; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 585–592. [Google Scholar]
- Burduk, R.; Biedrzycki, J. Integration and Selection of Linear SVM Classifiers in Geometric Space. J. Univers. Comput. Sci. 2019, 25, 718–730. [Google Scholar]
- Biedrzycki, J.; Burduk, R. Integration of decision trees using distance to centroid and to decision boundary. J. Univers. Comput. Sci. 2020, 26, 720–733. [Google Scholar]
- Biedrzycki, J.; Burduk, R. Weighted scoring in geometric space for decision tree ensemble. IEEE Access 2020, 8, 82100–82107. [Google Scholar] [CrossRef]
- Polianskii, V.; Pokorny, F.T. Voronoi Boundary Classification: A High-Dimensional Geometric Approach via Weighted M onte C arlo Integration. In International Conference on Machine Learning; Omnipress: Madison, WI, USA, 2019; pp. 5162–5170. [Google Scholar]
- Biau, G.; Devroye, L. Lectures on the Nearest Neighbor Method; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kushilevitz, E.; Ostrovsky, R.; Rabani, Y. Efficient search for approximate nearest neighbor in high dimensional spaces. SIAM J. Comput. 2000, 30, 457–474. [Google Scholar] [CrossRef]
- Kheradpisheh, S.R.; Behjati-Ardakani, F.; Ebrahimpour, R. Combining classifiers using nearest decision prototypes. Appl. Soft. Comput. 2013, 13, 4570–4578. [Google Scholar] [CrossRef]
- Gou, J.; Zhan, Y.; Rao, Y.; Shen, X.; Wang, X.; He, W. Improved pseudo nearest neighbor classification. Knowl.-Based Syst. 2014, 70, 361–375. [Google Scholar] [CrossRef]
- Rokach, L. Decision forest: Twenty years of research. Inf. Fusion 2016, 27, 111–125. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Tan, P.N.; Steinbach, M.M.; Kumar, V. Introduction to Data Mining; Addison-Wesley: Boston, MA, USA, 2005. [Google Scholar]
- Ponti, M.P. Combining Classifiers: From the Creation of Ensembles to the Decision Fusion. In Proceedings of the 2011 24th SIBGRAPI Conference on Graphics, Patterns, and Images Tutorials, Alagoas, Brazil, 28–30 August 2011; pp. 1–10. [Google Scholar]
- Kim, E.; Ko, J. Dynamic Classifier Integration Method. In Multiple Classifier Systems; Oza, N.C., Polikar, R., Kittler, J., Roli, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 97–107. [Google Scholar]
- Sultan Zia, M.; Hussain, M.; Arfan Jaffar, M. A novel spontaneous facial expression recognition using dynamically weighted majority voting based ensemble classifier. Multimed. Tools Appl. 2018, 77, 25537–25567. [Google Scholar] [CrossRef]
- Hajdu, A.; Hajdu, L.; Jonas, A.; Kovacs, L.; Toman, H. Generalizing the majority voting scheme to spatially constrained voting. IEEE Trans. Image Process. 2013, 22, 4182–4194. [Google Scholar] [CrossRef] [PubMed]
- Rahman, A.F.R.; Alam, H.; Fairhurst, M.C. Multiple Classifier Combination for Character Recognition: Revisiting the Majority Voting System and Its Variations. In Document Analysis Systems V; Lopresti, D., Hu, J., Kashi, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 167–178. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Taieb, S.B.; Hyndman, R.J. A gradient boosting approach to the Kaggle load forecasting competition. Int. J. Forecast. 2014, 30, 382–394. [Google Scholar] [CrossRef]
- Sheridan, R.P.; Wang, W.M.; Liaw, A.; Ma, J.; Gifford, E.M. Extreme Gradient Boosting as a Method for Quantitative Structure-Activity Relationships. J. Chem Inf. Model. 2016, 56, 2353–2360. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In NIPS’17 Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3149–3157. [Google Scholar]
- Chawla, N.V.; Hall, L.O.; Bowyer, K.W.; Kegelmeyer, W.P. Learning Ensembles from Bites: A Scalable and Accurate Approach. J. Mach. Learn. Res. 2004, 5, 421–451. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 2015, 17, 1235–1241. [Google Scholar]
- Oliphant, T. NumPy: A guide to NumPy; Trelgol Publishing: Spanish Fork, UT, USA, 2006. [Google Scholar]
- Jones, E.; Oliphant, T.; Peterson, P. SciPy: Open Source Scientific Tools for Python. Available online: https://www.mendeley.com/catalogue/cc1d80ce-06d6-3fc5-a6cf-323eaa234d84/ (accessed on 20 September 2020).
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2020; van der Walt, S., Millman, J., Eds.; pp. 56–61. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://ergodicity.net/2013/07/ (accessed on 20 September 2020).
- Alcalá-Fdez, J.; Fernández, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult.-Valued Log. Soft Comput. 2011, 17. [Google Scholar]
- Ortigosa-Hernández, J.; Inza, I.; Lozano, J.A. Measuring the class-imbalance extent of multi-class problems. Pattern Recognit. Lett. 2017, 98, 32–38. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inform. Process Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Van Asch, V. Macro- and Micro-Averaged Evaluation Measures; Basic Draft; CLiPS: Antwerpen, Belgium, 2013; Volume 49. [Google Scholar]


© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).