Abstract
In financial markets, information constitutes a crucial factor contributing to the evolution of the system, while the presence of heterogeneous investors ensures its flow among financial products. When nonlinear trading strategies prevail, the diffusion mechanism reacts accordingly. Under these conditions, information englobes behavioral traces of traders’ decisions and represents their actions. The resulting effect of information endogenization leads to the revision of traders’ positions and affects connectivity among assets. In an effort to investigate the computational dimensions of this effect, we first simulate multivariate systems including several scenarios of noise terms, and then we apply direct causality tests to analyze the information flow among their variables. Finally, empirical evidence is provided in real financial data.
1. Introduction
During the last few decades, research in finance has pointed to biases and sub-optimal decision-making processes as the drivers of investors’ behavior. Many alternatives have been proposed so as to rethink the strong assumptions of rationality and perfect information. According to Lo and Mackinlay [1] and Lo [2], economic agents’ actions can be influenced by various behavioral biases. The fact that, in terms of expectations, investors appear to be so different, since they do not share the same analytical skills, capital to invest, or even profit-maximizing goals, complicates the identification of patterns in real data. The role of heterogeneity in expectations is crucial. As demonstrated by Assenza et al. [3], in the event of a negative shock, even a small fraction of pessimistic forces coordinate and, due to positive feedback mechanisms, confidence is destroyed, leading to an expansion of market collapse. Hommes [4] presents heterogeneity and heuristics switching as detrimental factors of market dynamics. When positive feedback activates, market prices fluctuate strongly. Frijns et al. [5] relate the stylized facts observed in financial markets to an individual investor’s portfolio selection process, which is significantly driven by their risk perception, behavioral characteristics, and socio-demographic factors. As Peiro [6] shows, heterogeneity in the investment horizon may affect the significance of skewness in the portfolio construction process. In the short term, both fat tails and asymmetry contribute to the non-normality of the return distribution, while in broader horizons kurtosis seems to better explain deviations from normality. This comes in agreement with Prakash et al. [7], who suggest that the shape of a stock return distribution changes with the investment horizon.
Although information constitutes a crucial factor contributing to the evolution of financial systems, heterogeneous investors ensure the flow of information. The trading decision, strongly affected by the linear or nonlinear underlying trading strategies and filtering of news, can give birth to new information that enters the diffusion mechanism of the market and spreads rapidly. In this process, information englobes behavioral traces of traders’ decisions and represents their actions. The endogenization of information creates risk that significantly affects traders’ positions, capital flows, connectivity among assets, and finally asset allocation.
The observed non-normal distribution of asset returns is often attributed to the dominance of irrational investors following active trading strategies. Investors whose actions are affected by anchoring and disposition effects participate in the buildup of a trend-forcing price evolution. Thurner et al. [8] show that trading strategies, characterized by leverage, lead to nonlinear positive feedback mechanisms and the amplification of price movements that generate fat tails and volatility clustering. Along with the presence of fat tails, Daniel and Moskowitz [9] and Barroso and Santa-Clara [10] relate the momentum returns with the presence of negative skewness. Jacobs et al. [11] show that overweighting left-skewed stock returns distributions and underweighting the right-skewed ones can lead to profitable momentum strategies. Ekholm and Pasternack [12] suggest that the manner of releasing positive and negative information induces skewness in the return distribution. Through simulation experiments, Wen et al. [13] provide evidence that biases, such as overconfidence and regret aversion, determine the reaction of investors to nonlinearly received information and lead to skewed and leptokurtic returns. According to Xu [14], the existence of skewness in stock returns may be the result of the invertor’s reaction to the returns themselves. As Ruttiens [15] points out, a rational investor will favor stocks presenting the highest odd moments (expected value and skewness) and the lowest event moments (variance and kurtosis). Other trading characteristics, such as trading volume and heterogeneity, seem to justify the appearance of asymmetry in returns series (Hutson et al. [16]; Albuquerque [17]). Finally, the inability to implement appropriate and effective corporate governance can be the source of positive skewness in data (Bae et al. [18]).
Despite the simplistic character of the assumption of normality, the conventional approach to build a diversified portfolio has appeal due to the ease of implementation. In this framework, practitioners need only to consider for each asset class its mean, variance, and covariances, with the latter introducing the additional restrictive hypothesis of linear relationship for each pair of asset classes. Nevertheless, in dynamically unstable markets where information canalizes traders’ characteristics into prices, diversifying asset portfolios can become a complicated procedure. To this end, research on nonlinear analysis suggests alternative techniques to the standard mean-variance framework of Markowitz [19]. Boginski et al. [20] formulate the portfolio selection problem as the maximum weight s-plex problem in the market graph. Fernandez and Gomez [21] generalize the mean-variance model by using artificial neural networks to calculate the efficient frontier. Huang [22] provides a new definition of risk by taking into consideration investors’ perceptions of the severity level of the potential loss and redefines the portfolio selection problem under this new definition. In line with the empirical evidence about the presence of heavy-tail distributions, Kraft and Steffensen [23] and Diesinger et al. [24] show that assets can be modelled as jump-diffusion processes.
As follows, the trading-based non-normality is linked to high skewness and kurtosis in asset returns and can modify drastically the portfolio (basket of variables) structure. With the aim to investigate the computational dimensions of this effect, we use multivariate systems of variables where several scenarios of disturbances are considered. Then, a set of direct causality measures is employed to analyze the information flow among the variables. In this simulation exercise, the goal is to demonstrate that non-Gaussianity in a system is able to destabilize the fundamentally defined linkages. The impact becomes more pronounced when the initial connectiveness is nonlinear, which technically may be interpreted in terms of trading activity. The empirical validation of the effect of trading information on the variables’ connectiveness is provided through an application to a concentrated and mixed five-stock portfolio.
2. Simulation Experiment Design
In an attempt to concretize the effect of informational signals in the sense of random disturbances on the connectivity, we use three stochastic systems. Their residual terms are defined in different ways, so that the simulated time series obey irregular characteristics.
The two main stochastic systems, often used in the literature for the evaluation of causality measures, with Gaussian noise terms are (i) a linear vector autoregressive (VAR) of order 4 in five variables (Schelter et al. [25]) and (ii) a nonlinear VAR of order 3 in five variables with linear () and nonlinear couplings () (Montalto et al. [26]) (hereafter, S1 and S2, respectively). In an effort to include alternative forms of nonlinearity in the construction of variables, we built a third system on the basis of S2, in which X1 is described by a noisy Mackey Glass process (Kyrtsou and Terraza [27]). To consider the effect of data length, in all cases four different samples are selected—i.e., 512, 1024, 2048, 4096.
The presence of several lags in the simulated systems as well as the diversity in the nature of the relationships help establish a direct connection with the trading practice in financial markets. The systems evolve because of the combination of value signals (in technical analysis, the indicator signals are usually expressed by an inequality in terms of past values (value signal)), since the current state of each variable depends on past information of the same or other variable. The delay in the system equations measures the speed at which imperfectly reflected information is incorporated into Xt. Lagged information can also be transferred non-propositionally (nonlinear lagged X terms) into Xt, revealing that each variable at time t either over- or under-reacts to the past. Both conditions determine the spreading of information flow and feedback within the system.
2.1. System S1 by Schelter et al. (2006)
The system S1 is represented by the following set of equations.
where .
Based on S1, and by changing the distribution of noise terms , we formulate five additional simulation systems. Their connectivity network remains intact, as shown in Figure 1. In the initial system S1, all the variables present mesokurtic and symmetric behavior.
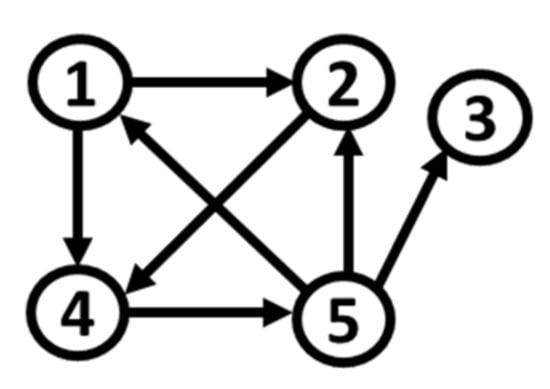
Figure 1.
Path diagram of S1 (the arrows denote the direction of causality).
S1t: S1 with noise terms from a t-Student distribution, with df = 2 degrees of freedom. The generated series exhibit leptokurtic behavior that increases with the sample. Among all the variables, X5, participating in more couplings than the rest, seems to be more sensitive to residual irregularity, having the highest kurtosis and varying skewness values.
S1n: S1 with noise terms from the following GARCH(1,1) model:
where is a Gaussian white noise process with . The resulting time series exhibit leptokurtic and asymmetric behavior. Again, for X5, which is more affected, we obtain the highest kurtosis and positives skewness.
S1b: S1 with noise terms from a beta distribution, with parameters , . All the variables present abnormal negative skewness.
S1g: S1 with noise terms from a GARCH(1,1) model, as defined for S1n, where follows the gamma distribution with parameters , . As in S1n, the simulated time series are leptokurtic and asymmetric. X5 has the most important kurtosis and positive asymmetry as well.
S1f: S1 with noise terms resulting from the following FIGARCH(1,d,1) model:
where is a Gaussian white noise process and . Contrary to the previous versions of S1, where fat tails are assumed in the error term, the obtained kurtosis is slightly above three, even for the largest sample.
2.2. Systems S2 by Montalto et al. (2014) and S3
The system S2 is represented by the following set of equations.
where .
With the aim to complicate the structure of the driving variable in S3, X1 is modelled as a noisy Mackey Glass with c = 10 and τ = 2. The remaining equations are identical to those of S2.
Although the system S2 is disturbed by normally distributed errors, as Table 1 reports, the variables X2, X4, and X5 are leptokurtic and skewed. The resulting non-normality can be explained by the amplification of the information flow towards X2 and X4, as well as by the indirect transmission to X5 via X4. In system S3, similar conclusions can be drawn only for X2 and X4. The moment statistics of X5 clearly converge to their normal distribution values. The appearance of fat tails in systems, where the nonlinear skeletons are perturbed by gaussian noise, has been studied under the term of endogenous heteroskedasticity in Kyrtsou [28] and Ashley [29].

Table 1.
Kurtosis and skewness from 100 realizations of the systems S2 and S3.
Based on S2 and S3, and by modifying the distribution of noise terms , as for S1, we define five additional simulation systems. Their path diagram is represented in Figure 2. In the initial parametrization of S2, even though residuals are white noises, three (X2, X4, and X5) out of five variables obey non-normal characteristics, such as high kurtosis (around 10) and skewness (around 2, either positive or negative). For S3, two (X2 and X4) out of five variables deviate from normality, with lower values of kurtosis (around 8) and skewness (around 1, either positive or negative).
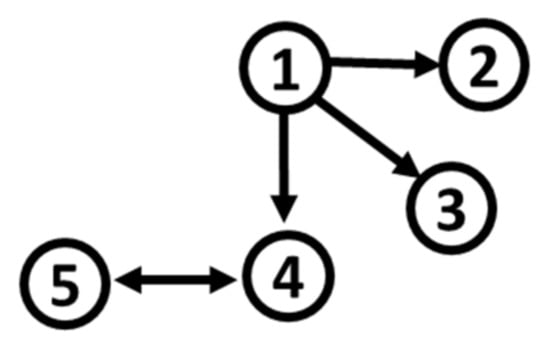
Figure 2.
Path diagram of S2 and S3.
S2t and S3t: S2 and S3 with noise terms from a t-Student distribution, with df = 2 degrees of freedom. The inclusion of t-student disturbances aggravates the non-normality. More specifically, the kurtosis and skewness of variables X2, X4, and X5 double if compared with their respective behavior in the original system S2. In S3, the amplification gives birth to extreme fat-tail and asymmetric behavior for all variables. It is worth noticing that, even for small sample sizes, the kurtosis approaches the value of 250, while the skewness is about 15. This finding refines the view that the nature of shock matters a lot in the propagation mechanism within a system.
S2n and S3n: S2 and S3 with noise terms from the corresponding GARCH(1,1) model, as defined for S1n. Although all the variables are skewed and leptokurtic, the kurtosis and skewness of X2, X4, and X5 reach high values. Again, the amplification of irregularity is more pronounced for S3.
S2b and S3b: S2 and S3 with noise terms from a beta distribution, with parameters , , producing negative skewness. The simulated results show that the beta distribution of the noise terms is imposed on the mean structure of the system, destroying the excess kurtosis we detected for the nonlinearly connected variables X2, X4, and X5 of S2. On the contrary, in S3 the kurtosis turns into platykurtic values.
S2g and S3g: S2 and S3 with noise terms from a GARCH(1,1) model, as for S1g. The distributional characteristics of the system variables are similar to those of the system S2n. It is worth mentioning the steadily negative asymmetry of variable X4 in the case that the residuals follow a GARCH-type process. If we compare the strength of non-Gaussianity between S2 and S3, we come to the conclusion that the specific nonlinearity in the skeleton of the third system favors the detection of higher 3rd and 4th moment statistics via interaction.
S2f and S3f: S2 and S3 with noise terms from a FIGARCH(1,d,1) model, similar to S1. For both systems, clear leptokurtic behavior is detected for X2, X4, and X5, but with a lower intensity. Regarding skewness, we notice a remarkable increase as the sample size rises, with values reaching 5 and 6 (S2 and S3 respectively) for X2, as well as −5 and −6 for X4 (S2 and S3, respectively).
To provide a schematic description of the methodological part, we present the simulation experiment in four steps. First, we simulate the systems S1, S2, and S3. In the second step, we introduce irregularity in the noise terms, as described above. Then, we identify couplings using direct causality methods to capture the information flow. In the last step, performance metrics are applied to verify the consistency of the obtained results.
3. Connectivity Measures and Performance Metrics
After describing the systems, including both linear and nonlinear couplings, together with the irregular characteristics of the residual terms able to give rise to abnormal values for skewness and kurtosis, we apply three multivariate (direct) measures of causality, instead of bivariate ones, to better apprehend the information flow. More specifically, we intend to identify the impact of introducing non-Gaussianity in the stochastic systems S1, S2, and S3 into the connectivity among their variables. Let us consider a multivariate system with variables, where is the driving variable (source), is the response variable (target), and there also confounding variables . The multivariate causality measures capture the direct causal influence from to conditioning on the remaining variables ().
The Restricted Conditional Granger Causality Index (RCGCI) is an extension of the standard Conditional Granger Causality Index (Geweke [30]), including dimension reduction so that the curse of dimensionality can be effectively addressed (Siggiridou and Kugiumtzis [31]). Computationally, a modified backward-in-time selection method is selected to restrict the VAR model. The choice of the appropriate subset of lagged terms is based on the time series property—that is, the dependence structure is closely related to the temporal order of the variables. In this way, the unrestricted VAR is estimated based on the selected lagged variables. Except for the fact that the lagged terms of the driving variables are eliminated, the restricted model is similarly constructed. The RCGCI is then calculated as the logarithm of the ratio of the variances of the restricted () and of the unrestricted model :
The statistical significance of the RCGCI is assessed by a parametric significance test (F-statistic) on the coefficients of the lagged terms of the driving variable in the unrestricted model:
where SSE is the sum of squared errors, while the superscripts U and R denote the unrestricted and restricted models, respectively. is the number of lagged components of in the U-model for , is the largest lag in the U-model, is the data size, and is the total number of U-model coefficients.
In the Partial Mutual Information on Mixed Embedding (PMIME), the dimension reduction is effectuated via a non-uniform embedding scheme (Kugiumtzis [32]). The mixed embedding vector , with varying delays from all the observed variables, is progressively built making use of a conditional mutual information (CMI) criterion. Thus, starting the process with an empty vector , a new vector is formed at each step by adding a component (from any variable), so that the future of the response variable , is best explained:
where stands for the conditional mutual information of and , conditioning on the variables. The PMIME test in terms of conditional mutual information is expressed as follows:
To obtain the probability densities in the estimation of the (conditional) mutual information terms, the nearest neighbors’ estimator (Kraskov et al. [33]) is employed. PMIME becomes zero in the case of no causality; otherwise, it is positive.
Respectively, the Partial Transfer Entropy on Non-Uniform Embedding (PTENUE) is introduced using the non-uniform embedding scheme (Montalto et al. [26]). Although its estimation procedure is identical to that of PMIME, an alternative nearest neighbors’ estimator of Kraskov et al. [33] is employed for computing the probability densities. The PTENUE measure is defined below:
The measure equals zero if causality does not exist; otherwise, it is positive. The nonlinear causality measures PMIME and PTENUE do not require a significance test. Surrogates, though, are incorporated within the estimation algorithm of the measures to form the stopping criterion regarding the mixed embedding vector. Papana et al. [34], Papana [35], and Siggiridou et al. [36,37] have shown that RCGCI, PMIME, and PTENUE outperform a large range of linear and nonlinear, bivariate and multivariate causality measures.
In the fourth step, binary classification metrics such as the sensitivity, specificity, and Matthews correlation coefficient (Tharwat [38]) are employed to evaluate the performance of the tree direct causality measures. In the simulated systems, the causality measures are estimated on the possible pairs of variables for a system of K variables.
The sensitivity metric—i.e., the true positive rate (TPR)—quantifies the true positives (TP) against the number of real positives (P) in the data.
The term true or false refers to the correct or incorrect (spurious) coupling, while positive or negative means the acceptance or rejection of couplings, respectively. If the sensitivity approaches 100%, then more correct causal links are detected over the total link detections.
The specificity metric—i.e., the true negative rate (TNR)—checks the true negatives (TN) against the number of real negatives (N) in the data.
Thus, the specificity provides the percentage of rejection of spurious links over the total number of detected uncoupled cases. The percentage at which the specificity value deviates from 100% denotes the accepted spurious couplings.
Finally, the Mathews’ correlation coefficient (MCC) (Matthews [39]) is a measure of the overall performance, merging information from sensitivity and specificity by considering all the possible correct and spurious couplings, either causal or no causal. If it equals 100%, there is a perfect identification of the pairs of true and no causality.
4. Simulated Series Results
As reported in Table 2, the RCGI correctly identifies the connectivity network of S1 for all the samples. The performance is slightly improved as the time series length increases due to the identification of less spurious detections. The PMIME also correctly indicates connectivity. Again, similar results are obtained for all the time series lengths. However, the percentage of detecting significant causality is larger than the nominal level (5%) for the uncoupled pairs of variables. The true connectivity network of S1 is obtained with PTENUE, independent of the sample size. Less spurious cases are captured as well. On the basis of the performance metrics, the PTENUE outstands the other two measures, achieving the highest mean MCC score (96.66%) over the RCGCI (94.53%) and the PMIME (85.2%). Respectively, their mean sensitivities are very high. The difference in the performance of the measure is affected by its specificity—i.e., the true negative rate.
Table 2.
Outcomes from the binary classification metrics for all the S1 series. RC, PM, and PT stand for the RCGCI, PMIME, and PTENUE measures, respectively.
When a noise term from the t-distribution is added to S1 (S1t), the performance of RCGCI is similar to that of S1. It finds the causal links perfectly well, while the percentages of significant detections for the uncoupled pairs of variables does not exceed 5%. The performance of PMIME does not deteriorate for S1t compared to S1. The true links are detected. However, the percentage of significant detections for the uncoupled pairs of variables varies from 9.85% to 12.85%. The PTENUE performs for S1t as for S1. The true links are found, and a few spurious acceptances arise. In total, the PTENUE has the best mean performance for S1t. RCGCI comes second, with an MCC value very close to that of PTENUE.
Including the GARCH residuals in S1 (S1n) worsens the metrics of the RCGCI. The measure captures the true causal linkages, but for the uncoupled cases the percentage of significant RCGCI values varies from 8.36% to 10.38%. The PMIME gives less acceptances of spurious causalities for S1n. The best performance for the system S1n is achieved by PTENUE.
When beta-distributed errors are considered for S1b, the RCGCI finds the true connectivity network for all n (100%). Similar to S1, also a few spurious links are obtained. The PMIME identifies perfectly the true connections (100%) for all n. The uncoupled links are falsely indicated, with percentages that vary from 9.85% to 12.85%. The PTENUE indicates again the true connections, while a small number of spurious cases appear.
In the case of system S1g, the RCGCI captures the true causalities, but for the uncoupled cases the percentage of significant RCGCI values remains high (from 7.77% to 9.23%). The PMIME performs almost similarly to the RCGCI. The PTENUE continues to be the best measure. When the FIGARCH errors are considered, the PMINE puts forward more false couplings.
Table 3 and Table 4 report the results of the application to the simulated system of Montatlo at al. [26] and the new system S3. As one can see, the RCGI correctly identifies the linear relationships. On the contrary, the nonlinear links are detected with very low percentages. In addition, spurious links are indicated. On the other hand, the PMIME captures more couplings. The performance increases with the sample length. However, in terms of spurious detection the PMIME gives similar results to the RCGCI for S2, while it finds further false couplings for S3. The PTENUE performs closely to the PMIME, but in terms of the mean binary classification metrics for the system S2. However, it is clearly better than the PMIME for S3. The RCGCI achieves a pretty low mean MCC score, mainly due to its low sensitivity.
Table 3.
Outcomes from the binary classification metrics for all S2 series. RC, PM, and PT stand for the RCGCI, PMIME, and PTENUE measures, respectively.
Table 4.
Outcomes from the binary classification metrics for all S3 series. RC, PM, and PT stand for the RCGCI, PMIME, and PTENUE measures, respectively.
In the case of the t-distributed errors in S2, the RCGI correctly detects the true couplings. This percentage increases to 90% for the large sample. Spurious links are also revealed. This effect is more significant in the sample of 4096 observations. The PTENUE shows more true causal links, while fewer spurious relationships than the RCGCI and PMIME detect are found. In terms of performance, the PTENUE overcomes the PMIME. In the third system, the PMINE seems to be more sensitive to the nonlinearity, suggesting an increasing number of spurious couplings.
For the systems S2n, S3n, and S2g, S3g considering the GARCH residual terms, the measures produce almost identical results. The RCGI indicates the true couplings, giving comparable percentages of acceptance with S2t. The spurious detections are high, approaching 30%. The PMIME captures effectively the true connections, but at the same time it shows spurious ones. According to the sensitivity metric, the PTENUE performs as well as the PMIME, but gives fewer wrong causalities. This performance is concretized through the highest mean MCC.
Regarding S2b, the RCGCI captures efficiently both the linear and nonlinear linkages, and the percentage of spurious cases is lower than in the previously analyzed versions of the system S2. Both the PMIME and the PTENUE find the true connectivity. Nevertheless, the latter indicates a smaller number of spurious couplings. The high MCC values show that the PTENUE stands out. The significant difference between the system S3b refers to the poor performance of the RCGCI, since the number of false detections rises to 37.73%.
Finally, when the FIGARCH error term is considered in S2 and S3, the linear measure fails significantly to indicate the correct causal relationships and suggests equally high false ones. The nonlinear tools perform better, giving a lower rate of false acceptances than RCGCI for S2, except PMINE for S3, which reaches 23.93% spurious couplings.
Comparing the rate of acceptance of false causalities (specificity) between the systems S1, S2, and S3, we can conclude that more spurious couplings emerge in the nonlinear systems S2 and S3 due to the common source of driving (X1→X2, X3, X4) and the transitive indirect paths (X1→X4↔X5). It is also worth emphasizing that, among the spurious causalities, the bidirectional coupling between X2 and X4 (by definition uncoupled) is steadily detected by all measures in all samples. Therefore, we believe that the high rate of acceptance of couplings which are not derived from the initial formulation of the systems S2 and S3 indicates the creation of new structures because of the propagation.
To further deploy our rationale, we calculate the mutual information among the variables of all versions of S2 and S3. As can be seen in Table 5, when the error term obeys irregular properties that differs in intensity and nature, the dependence rises. In fact, the higher mutual information coefficient is obtained for the initially uncoupled pair X2 and X4. It occurs associatively that S2 stands out as a nonlinearly self-exciting process. According to Ocker et al. [40], in nonlinearly self-exciting processes nonlinearities impose bidirectional couplings and the structure expands. The detected spuriosity varies depending on the disturbance term that obviously affects the amplification within the nonlinear skeleton of the model. More specifically, when the noise term presents a more volatile or asymmetric profile, it imposes its own structure on the endogenous part, then amplification is braked, and the number of spurious couplings decreases.
Table 5.
Mutual information between the variables of various S2 systems for n = 4096 (the values for the respective systems are denoted in different colors).
On the contrary, in Table 6, where the driver variable X1 is generated by a noisy Mackey–Glass process, a higher level of mutual information is achieved among the variables of the system S3b. Apparently, the interaction of the beta distribution with the skeleton of S3 is spread out rapidly. In this specific model, the linear RCGCI gives around 40% spurious couplings in contrast to the nonlinear measures that identify only 10% of the false linkages.
Table 6.
Mutual information between the variables of the various S3 systems for n = 4096 (the values for the respective systems are denoted in different colors).
Regardless of the sample size of the nonlinear systems under study, we observe that a significant divergence in performance between the linear and the nonlinear causality measures is associated with nonlinear relationships among the variables. In this line, for all the causality forms and disturbance terms the simulation results show that the PTENUE decodes correctly the true linkages and gives lower rates of false couplings.
5. Application to Real Financial Data
With the aim to provide empirical evidence about the impact of heterogeneity in information on the connectivity of variables, we built two different stock portfolios. Following the simulated systems’ construction, the first portfolio A is composed of five stocks from the French stock exchange index CAC40 to reproduce the properties of a concentrated structure. The respective listed companies are Total (FP) from the energy sector, Sanofi (SAN) from the healthcare sector, L’Oreal (OR) and Danone (BN) from the consumer defensive sector, and BNP Paribas (BNP) from the financial services sector. The required heterogeneity is achieved by considering three big capitalization stocks (FP, SAN, OR) together with two lower capitalization stocks (BN, BNP). In the second portfolio named B, the goal is to combine two different (preferably independent) concentrated structures so as to emphasize the contribution of their dynamics to the overall behavior of the portfolio. For this reason, we replace the lower capitalization stocks BN and BPN with Cipla limited (Cipla) from the healthcare sector and Britannia industries limited from the consumer defensive sector of the national stock exchange index of India NIFTY. The absence of lead-lag relationship between NIFTY and European stock indexes is pointed out by Choudhary and Singhal [41].
With a focus on considering heterogeneous investment time horizons, we select four distinct samples for each portfolio—i.e., 500, 1000, 2000, and 4000 data points—starting from the most recent observation of the dataset (i.e., 30/04/2020). The Table 7 and Table 8 report the 3rd and 4th moment statistics of all the stock returns series. The results show that the variables are highly skewed and leptokurtic. However, the maximum values of skewness and kurtosis (value in red) are obtained for different sample lengths, confirming the fact that the incorporation of historical information reveals heterogeneous aspects of investors’ activity and eventually variations in market conditions. Non-normality in the short-run subsample of 500 observations represents more speculative dimensions of trading. On the contrary, when deviations from Gaussianity become evident in longer samples, one should look at the volatile reaction of long-term-oriented investors. Deviations depend on the stock nature and do not rise or decrease proportionally with the sample size.
Table 7.
Kurtosis and skewness of the stock returns in portfolio A.
Table 8.
Kurtosis and skewness of the stock returns in portfolio B.
The application of the causality measures to the portfolios A and B helps to further illustrate the above heterogeneity. The resulting path diagrams per measure and sample are presented in Figure 3 and Figure 4. The complex interdependence between stocks is clearly indicated by the either no-causality or sparse structure captured by the linear RCGCI measure. The implementation of PMIME and PTENUE indicates rich linkages among the variables. At first glance, it seems that the strong causal forms detected by both nonlinear tools are consistent in the shorter and longer samples (i.e., 500 and 4000 points). This diversity in patterns can eventually reflect the fact that investors may be willing to take more on risk over longer periods (Andries, et al. [42]), or when the risk-free rate turns negative (Baars, et al. [43]).

Figure 3.
Path diagrams for portfolio A.

Figure 4.
Path diagrams for portfolio B.
Although the stock systems are composed of only five variables, the intensity of spreading for the small and large samples among the variables of portfolio A slightly differs between PMIME and PTENUE. It turns out that the combination of domestic stocks generates a nonlinearly interconnected portfolio. Of course, introducing more variables would allow richer dynamics to unfold. Therefore, in the small sample (500 obs.) of the mixed portfolio B, mixing two different sets of stocks affects the consistency of couplings and interrupts the complex pattern of portfolio A. The decrease in the standard deviation from 2.6% (portfolio A) to 1.6% (portfolio B) along with the increase in mean return from −0.106% to 0.033% is an appealing effect of the changes in connectivity over the short-term period, including the first months of the coronavirus pandemic. Respectively, the slump in the skewness value from −1.73 (portfolio A) to −0.10 (portfolio B) illustrates the tight link between the nature of stock connectivity and portfolio asymmetry that reflects the trading activity (Horwitz [44]).
Additionally, the fact that the visual representation of both portfolios is time-varying brings out the role of heterogeneity in financial markets in terms of trading horizons and the subsequent complexity of information signals. Evidence about horizon-dependent behavior has been provided by Prat [45] for the equity premium in the US stock market data over the period 1871–2008. Conclusions regarding the horizon-dependent causality between the US and the China ETF markets that increases in the long-term have been also drawn by Nie at al. [46].
Looking closer at the evolution of dependence in portfolios A and B as far as information accumulates and sample size increases will shed light on the beneficial side of the resulting dynamics. To do so, we calculate the mutual information coefficient among the stock returns. The results for the concentrated portfolio A, reported in Table 9, show that the dependence clearly intensifies as the number of observations increases. Thereby, holding stocks for a short period of time by focusing on the recent performance of the respective firms could potentially turn into a beneficial decision under favorable market conditions. When conditions deteriorate and volatility bursts, it is possible to take advantage of the nonlinear connectivity within the concentrated structures by fusing appropriately different pools of assets in an effort to address trading heterogeneity, such as the case of portfolio B.
Table 9.
Mutual information between the stock returns of portfolios A and B.
6. Implications
The endogenization of information and the subsequent amplification within the system has a significant effect on variables’ connectiveness. The increasing nonlinearity and the presence of endogenous heteroskedasticity in the simulated systems S2 and S3, together with the appearance of new couplings detected as spurious by the specific statistical measures, can have several exploitable implications for the trading practice and portfolio construction. The property of nonlinearly self-exciting process applies in the set of real variables as well, where their connectivity relies upon the underlying dynamics of the data time horizon. Although, in the long run, the concentrated portfolio A and the mixed portfolio B are characterized by the rich nonlinear association of their components, in the short run mixing two different pools of stocks in portfolio B affects the connectivity and risk measurement. This finding emphasizes the importance of investors’ risk profile and time horizon in the asset allocation process.
From a broader perspective, the presence of escalating nonlinear dependences among stocks justifies the need to deal with the curse of dimensionality in financial portfolios. In complex financial markets, where the number of variables influencing the asset prices can be huge, selecting a subset able to capture market risk is an appalling challenge. Green and Hollifield [47] show that estimation errors as a result of the optimization of many assets lead to not well diversified portfolios. Nonlinear interactions among stock returns can also affect the performance of standard asset pricing models. According to Chicheportiche and Bouchaud [48], portfolios generated by nonlinear approaches outperform the Markowitz mean-variance model, while Laloux et al. [49] show that, due to the high level of noise and instability of the dependence structure, over time the use of the covariance matrix underestimates portfolio risk.
Under conditions of strong nonlinear association, a diffusion of biased information among assets can modify a portfolio’s characteristics and impact its performance. Remedies for this effect include the dynamical revising of the portfolio structure or updating asset allocation. On the other hand, exploiting informational evolution through investing in concentrated portfolios, possibly combined with style investing, can be an additional alternative. Although risky, a steady preference of individual investors for concentrated portfolios and active trading has been recorded in the literature. This is likely attributed to the existence of behavioral biases. Individual investors overestimate either the quality of their private information or their ability to interpret it (Odean [50]; Barber and Odean [51]). However, trading aggressively could also reflect their attempts to exploit superior private signals (Kyle [52]). As shown in Ivkovic et al. [53] investments made by concentrated investors can perform significantly better than the investments made by those diversifying across many stocks. Moreover, the concentration is more significant for stocks with greater information asymmetries. When the concentration increases, the risk increases nonlinearly (Horwitz [44]). Although concentrated portfolios frequently present substantial tracking errors to the benchmark, investors’ information processing is capable of transforming a theoretically suboptimal decision into a beneficial investment strategy delivering high abnormal returns (Choi et al. [54]).
Future research on the impact of connectivity among financial assets will include high-dimensional simulated systems, as well as the evaluation of real stock portfolios built under different statistical scenarios.
Author Contributions
Methodology, analysis, presentation, and writing, C.K., C.M. and A.P.; data curation, C.M. and A.P.; supervision, C.K. All authors have read and agreed to the published version of the manuscript.
Funding
This project received funding from the Hellenic Foundation for Research and Innovation (HFRI) and the General Secretariat for Research and Technology (GSRT) under Grant Agreement No. 794.
Acknowledgments
The authors would like to thank the academic editor and two anonymous referees for their valuable suggestions and comments.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analysis, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Lo, A.W.; Mackinlay, A.C. A Non-Random Walk Down Wall Street; Princeton University Press: Princeton, NJ, USA, 1999. [Google Scholar]
- Lo, A.W. Reconciling efficient markets with behavioral finance: The adaptive markets hypothesis. J. Invest. Consult. 2005, 7, 21–44. [Google Scholar]
- Assenza, T.; Brock, W.A.; Hommes, C.H. Animal Spirits, Heterogeneous Expectations, and the Amplification and Duration of Crises. Econ. Inq. 2017, 55, 542–564. [Google Scholar] [CrossRef]
- Hommes, C.H. The heterogeneous expectations hypothesis: Some evidence from the lab. J. Econ. Dyn. Control 2011, 35, 1–24. [Google Scholar] [CrossRef]
- Frijns, B.; Koellen, E.; Lehnert, T. On the determinants of portfolio choice. J. Econ. Behav. Organ. 2008, 66, 373–386. [Google Scholar] [CrossRef]
- Peiro, A. Skewness in individual stocks at different investment horizons. Quant. Financ. 2002, 2, 139–185. [Google Scholar] [CrossRef]
- Prakash, A.J.; Chang, C.-H.; Pactwa, T.E. Selecting a portfolio with skewness: Recent evidence from US, European, and Latin American equity markets. J. Bank. Financ. 2003, 27, 1375–1390. [Google Scholar] [CrossRef]
- Thurner, S.; Farmer, D.; Geanakoplos, J. Leverage causes fat tails and clustered volatility. Quant. Financ. 2012, 12, 695–707. [Google Scholar] [CrossRef]
- Daniel, K.; Moskowitz, T.J. Momentum crashes. J. Financ. Econ. 2016, 122, 221–247. [Google Scholar] [CrossRef]
- Barroso, P.; Santa-Clara, P. Momentum has its moments. J. Financ. Econ. 2015, 116, 111–120. [Google Scholar] [CrossRef]
- Jacobs, H.; Regele, T.; Weber, M. Expected Skewness and Momentum. 2016. Available online: https://ssrn.com/abstract=2600014 (accessed on 20 September 2020).
- Ekholm, A.; Pasternack, D. The negative news threshold—An explanation for negative skewness in stock returns. Eur. J. Financ. 2005, 11, 511–529. [Google Scholar] [CrossRef]
- Wen, F.; Huang, D.; Lan, Q.; Yang, X. Numerical Simulation for Influence of Overconfidence and Regret Aversion on Return Distribution. Syst. Eng. Theory Pract. 2007, 27, 10–18. [Google Scholar] [CrossRef]
- Xu, J. Price convexity and skewness. J. Financ. 2007, 62, 2521–2552. [Google Scholar] [CrossRef]
- Ruttiens, A. Mathematics of the Financial Markets: Financial Instruments and Derivatives Modelling; Valuation and Risk Issues; Wiley editions: West Sussex, UK, 2013. [Google Scholar]
- Hutson, E.; Kearney, C.; Lynch, M. Volume and skewness in international equity markets. J. Bank. Financ. 2008, 32, 1255–1268. [Google Scholar] [CrossRef]
- Albuquerque, R. Skewness in Stock Returns, Periodic Cash Payouts, and Investor Heterogeneity. In CEPR Discussion Papers; DP7573; Centre for Economic Policy Research (CEPR): London, UK, 2009. [Google Scholar]
- Bae, K.-H.; Lim, C.; Wei, K.C.J. Corporate governance and conditional skewness in the world’s stock markets. J. Bus. 2006, 79, 2999–3028. [Google Scholar] [CrossRef]
- Markowitz, H. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Boginski, V.; Butenko, S.; Shirokikh, O.; Trukhanov, S.; Lafuente, J.G. A network-based data mining approach to portfolio selection via weighted clique relaxations. Ann. Oper. Res. 2014, 216, 23–34. [Google Scholar]
- Fernandez, A.; Gomez, S. Portfolio selection using neural networks. Comput. Oper. Res. 2007, 34, 1177–1191. [Google Scholar] [CrossRef]
- Huang, X. Portfolio selection with a new definition of risk. Eur. J. Oper. Res. 2008, 186, 351–357. [Google Scholar] [CrossRef]
- Kraft, H.; Stefensen, M. Asset allocation with contagion and explicit bankruptcy procedures. J. Math. Econ. 2009, 45, 147–167. [Google Scholar] [CrossRef]
- Diesinger, P.; Kraft, H.; Seifried, V. Asset allocation and liquidity breakdowns: What if your broker does not answer the phone? Financ. Stoch. 2010, 14, 343–374. [Google Scholar] [CrossRef][Green Version]
- Schelter, B.; Winterhalder, M.; Hellwig, B.; Guschlbauer, B.; Lucking, C.H.; Timmer, J. Direct or indirect? Graphical models for neural oscillators. J. Physiol. Paris 2006, 99, 37–46. [Google Scholar] [CrossRef] [PubMed]
- Montalto, A.; Faes, L.; Marinazzo, D. MuTE: A MATLAB toolbox to compare established and novel estimators of the multivariate transfer entropy. PLoS ONE 2014, 9, e109462. [Google Scholar] [CrossRef] [PubMed]
- Kyrtsou, C.; Terraza, M. It is possible to study chaotic and ARCH behaviour jointly? Application of a noisy Mackey-Glass equation in the Paris Stock Exchange returns series. Comput. Econ. 2003, 21, 257–276. [Google Scholar] [CrossRef]
- Kyrtsou, C. Re-examining the sources of heteroskedasticity: The paradigm of noisy chaotic models. Phys. A Stat. Mech. Its Appl. 2008, 387, 6785–6789. [Google Scholar] [CrossRef]
- Ashley, R.A. On the origins of conditional heteroscedasticity in time series. Korean Econ. Rev. 2012, 28, 5–25. [Google Scholar]
- Geweke, J. Measurement of linear dependence and feedback between multiple time series. J. Am. Stat. Assoc. 1982, 77, 304–313. [Google Scholar] [CrossRef]
- Siggiridou, E.; Kugiumtzis, D. Granger causality in multivariate time series using a time-ordered restricted vector autoregressive model. IEEE Trans. Signal Process. 2016, 64, 1759–1773. [Google Scholar] [CrossRef]
- Kugiumtzis, D. Direct-coupling information measure from nonuniform embedding. Phys. Rev. E 2013, 87, 062918. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef]
- Papana, A.; Kyrtsou, C.; Kugiumtzis, D.; Diks, C. Simulation study of direct causality measures in multivariate time series. Entropy 2013, 15, 2635–2661. [Google Scholar] [CrossRef]
- Papana, A. Non-Uniform Embedding Scheme and Low-Dimensional Approximation Methods for Causality Detection. Entropy 2020, 22, 745. [Google Scholar] [CrossRef]
- Siggiridou, E.; Koutlis, C.; Tsimpiris, A.; Kimiskidis, V.K.; Kugiumtzis, D. Causality networks from multivariate time series and application to epilepsy. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 4041–4044. [Google Scholar]
- Siggiridou, E.; Koutlis, C.; Tsimpiris, A.; Kugiumtzis, D. Evaluation of Granger causality measures for constructing networks from multivariate time series. Entropy 2019, 21, 1080. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 15, 81–93. [Google Scholar] [CrossRef]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochim. Biophys. Acta 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Ocker, G.K.; Josić, K.; Shea-Brown, E.; Buice, M.A. Linking structure and activity in nonlinear spiking networks. PLoS Comput. Biol. 2017, 13, e1005583. [Google Scholar] [CrossRef]
- Choudhary, S.; Singhal, S. International linkages of Indian equity market: Evidence from panel co-integration approach. J. Asset Manag. 2020, 21, 333–341. [Google Scholar] [CrossRef]
- Andries, M.; Eisenbach, M.T.; Schmalz, C.M. Horizon-dependent risk aversion and the timing and pricing of uncertainty. In Federal Reserve Bank of New York Staff Reports; Federal Reserve Bank of New York: New York, NY, USA, 2019; no. 703. [Google Scholar]
- Baars, M.; Cordes, H.; Mohrschladt, H. How negative interest rates affect the risk-taking of individual investors: Experimental evidence. Financ. Res. Lett. 2020, 32, 101179. [Google Scholar] [CrossRef]
- Horwitz, R. Hedge Fund Risk Fundamentals: Solving the Risk Management and Transparency Challenge; Bloomberg Press: New York, NY, USA, 2004. [Google Scholar]
- Prat, G. Equity risk premium and time horizon: What do the U.S. secular data say? Econ. Model. 2013, 34, 76–88. [Google Scholar] [CrossRef]
- Nie, H.; Jiang, Y.; Yang, B. Do different time horizons in the volatility of the US stock market significantly affect the China ETF market? Appl. Econ. Lett. 2018, 25, 747–751. [Google Scholar] [CrossRef]
- Green, N.R.; Holliefiled, B. When Will Mean-Variance Efficient Portfolios Be Well Diversified? J. Financ. 1993, 45, 1785–1809. [Google Scholar] [CrossRef]
- Chicheportiche, R.; Bouchaud, J.P. A nested factor model for non-linear dependencies in stock returns. Quant. Financ. 2015, 15, 1789–1804. [Google Scholar] [CrossRef]
- Laloux, L.; Cizeau, P.; Potters, M.; Bouchaud, J.P. Random matrix theory and financial correlations. Int. J. Theor. Appl. Financ. 2000, 3, 391–397. [Google Scholar] [CrossRef]
- Odean, T. Are Investors Reluctant to Realize Their Losses? J. Financ. 1998, 53, 1775–1798. [Google Scholar] [CrossRef]
- Barber, B.M.; Odean, T. Trading is Hazardous to Your Wealth: The Common Investment Performance of Individual Investors. J. Financ. 2000, 55, 773–806. [Google Scholar] [CrossRef]
- Kyle, A. Continuous Auctions and Insider Trading. Econometrica 1985, 53, 1315–1335. [Google Scholar] [CrossRef]
- Ivkovic, Z.; Clemens, S.; Weisbenner, S. Portfolio Concentration and the Performance of Individual Investors. J. Financ. Quant. Anal. 2008, 43, 613–656. [Google Scholar] [CrossRef]
- Choi, N.; Fedenia, M.; Skiba, H.; Sokolyk, T. Portfolio concentration and performance of institutional investors worldwide. J. Financ. Econ. 2017, 123, 189–208. [Google Scholar] [CrossRef]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).