A Two-Moment Inequality with Applications to Rényi Entropy and Mutual Information


1
Department of Electrical and Computer Engineering, Duke University, Durham, NC 27708, USA
2
Department of Statistical Science, Duke University, Durham, NC 27708, USA
Entropy 2020, 22(11), 1244; https://doi.org/10.3390/e22111244
Submission received: 14 September 2020
/
Accepted: 6 October 2020
/
Published: 1 November 2020
(This article belongs to the Special Issue Divergence Measures: Mathematical Foundations and Applications in Information-Theoretic and Statistical Problems)
Abstract
:This paper explores some applications of a two-moment inequality for the integral of the rth power of a function, where . The first contribution is an upper bound on the Rényi entropy of a random vector in terms of the two different moments. When one of the moments is the zeroth moment, these bounds recover previous results based on maximum entropy distributions under a single moment constraint. More generally, evaluation of the bound with two carefully chosen nonzero moments can lead to significant improvements with a modest increase in complexity. The second contribution is a method for upper bounding mutual information in terms of certain integrals with respect to the variance of the conditional density. The bounds have a number of useful properties arising from the connection with variance decompositions.
1. Introduction
The interplay between inequalities and information theory has a rich history, with notable examples including the relationship between the Brunn–Minkowski inequality and the entropy power inequality as well as the matrix determinant inequalities obtained from differential entropy [1]. In this paper, the focus is on a “two-moment” inequality that provides an upper bound on the integral of the rth power of a function. Specifically, if f is a nonnegative function defined on and are real numbers satisfying and , then
where the best possible constant is given exactly; see Propositions 2 and 3 ahead. The one-dimensional version of this inequality is a special case of the classical Carlson–Levin inequality [2,3,4], and the multidimensional version is a special case of a result presented by Barza et al. [5]. The particular formulation of the inequality used in this paper was derived independently in [6], where the proof follows from a direct application of Hölder’s inequality and Jensen’s inequality.
In the context of information theory and statistics, a useful property of the two-moment inequality is that it provides a bound on a nonlinear functional, namely the r-quasi-norm , in terms of integrals that are linear in f. Consequently, this inequality is well suited to settings where f is a mixture of simple functions whose moments can be evaluated. We note that this reliance on moments to bound a nonlinear functional is closely related to bounds obtained from variational characterizations such as the Donsker–Varadhan representation of Kullback divergence [7] and its generalizations to Rényi divergence [8,9].
The first application considered in this paper concerns the relationship between the entropy of a probability measure and its moments. This relationship is fundamental to the principle of maximum entropy, which originated in statistical physics and has since been applied to statistical inference problems [10]. It also plays a prominent role in information theory and estimation theory where the fact that the Gaussian distribution maximizes differential entropy under second moment constraints ([11], [Theorem 8.6.5]) plays a prominent role. Moment–entropy inequalities for Rényi entropy were studied in a series of works by Lutwak et al. [12,13,14], as well as related works by Costa et al. [15,16] and Johonson and Vignat [17], in which it is shown that, under a single moment constraint, Rényi entropy is maximized by a family of generalized Gaussian distributions. The connection between these moment–entropy inequalities and the Carlson–Levin inequality was noted recently by Nguyen [18].
In this direction, one of the contributions of this paper is a new family of moment–entropy inequalities. This family of inequalities follows from applying Inequality (1) in the setting where f is a probability density function, and thus there is a one-to-one correspondence between the integral of the rth power and the Rényi entropy of order r. In the special case where one of the moments is the zeroth moment, this approach recovers the moment–entropy inequalities given in previous work. More generally, the additional flexibility provided by considering two different moments can lead to stronger results. For example, in Proposition 6, it is shown that if f is the standard Gaussian density function defined on , then the difference between the Rényi entropy and the upper bound given by the two-moment inequality (equivalently, the ratio between the left- and right-hand sides of (1)) is bounded uniformly with respect to n under the following specification of the moments:
Conversely, if one of the moments is restricted to be equal to zero, as is the case in the usual moment–entropy inequalities, then the difference between the Rényi entropy and the upper bound diverges with n.
The second application considered in this paper is the problem of bounding mutual information. In conjunction with Fano’s inequality and its extensions, bounds on mutual information play a prominent role in establishing minimax rates of statistical estimation [19] as well as the information-theoretic limits of detection in high-dimensional settings [20]. In many cases, one of the technical challenges is to provide conditions under which the dependence between the observations and an underlying signal or model parameters converges to zero in the limit of high dimension.
This paper introduces a new method for bounding mutual information, which can be described as follows. Let be a probability measure on such that and have densities and with respect to the Lebesgue measure on . We begin by showing that the mutual information between X and Y satisfies the upper bound
where is the variance of ; see Proposition 8 ahead. In view of (3), an application of the two-moment Inequality (1) with leads to an upper bound with respect to the moments of the variance of the density:
where this expression is evaluated at with . A useful property of this bound is that the integrated variance is quadratic in , and thus Expression (4) can be evaluated by swapping the integration over y and with the expectation of over two independent copies of X. For example, when is a Gaussian scale mixture, this approach provides closed-form upper bounds in terms of the moments of the Gaussian density. An early version of this technique is used to prove Gaussian approximations for random projections [21] arising in the analysis of a random linear estimation problem appearing in wireless communications and compressed sensing [22,23].
2. Moment Inequalities
Let be the space of Lebesgue measurable functions from S to whose pth power is absolutely integrable, and for , define
Recall that is a norm for but only a quasi-norm for because it does not satisfy the triangle inequality. The sth moment of f is defined as
where denotes the standard Euclidean norm on vectors.
The two-moment Inequality (1) can be derived straightforwardly using the following argument. For , the mapping is concave on the subset of nonnegative functions and admits the variational representation
where is the Hölder conjugate of r. Consequently, each leads to an upper bound on . For example, if f has bounded support S, choosing g to be the indicator function of S leads to the basic inequality . The upper bound on given in Inequality (1) can be obtained by restricting the minimum in Expression (5) to the parametric class of functions of the form with and then optimizing over the parameters . Here, the constraints on are necessary and sufficient to ensure that .
In the following sections, we provide a more detailed derivation, starting with the problem of maximizing under multiple moment constraints and then specializing to the case of two moments. For a detailed account of the history of the Carlson type inequalities as well as some further extensions, see [4].
2.1. Multiple Moments
Consider the following optimization problem:
For , this is a convex optimization problem because is concave and the moment constraints are linear. By standard theory in convex optimization (e.g., [24]), it can be shown that if the problem is feasible and the maximum is finite, then the maximizer has the form
The parameters are nonnegative and the ith moment constraint holds with equality for all i such that is strictly positive—that is, . Consequently, the maximum can be expressed in terms of a linear combination of the moments:
For the purposes of this paper, it is useful to consider a relative inequality in terms of the moments of the function itself. Given a number and vectors and , the function is defined according to
if the integral exists. Otherwise, is defined to be positive infinity. It can be verified that is finite provided that there exists such that and are strictly positive and .
The following result can be viewed as a consequence of the constrained optimization problem described above. We provide a different and very simple proof that depends only on Hölder’s inequality.
Proposition 1.
Let f be a nonnegative Lebesgue measurable function defined on the positive reals . For any number and vectors and , we have
Proof.
Let . Then, we have
where the second step is Hölder’s inequality with conjugate exponents and . □
2.2. Two Moments
For , the beta function and gamma function are given by
and satisfy the relation , . To lighten the notation, we define the normalized beta function
Properties of these functions are provided in Appendix A.
The next result follows from Proposition 1 for the case of two moments.
Proposition 2.
Let f be a nonnegative Lebesgue measurable function defined on . For any numbers with and ,
where and
where is defined in Equation (6).
Proof.
Letting and with , we have
Making the change of variable leads to
where and and the second step follows from recognizing the integral representation of the beta function given in Equation (A3). Therefore, by Proposition 1, the inequality
holds for all . Evaluating this inequality with
leads to the stated result. □
The special case admits the simplified expression
where we have used Euler’s reflection formula for the beta function ([25], [Theorem 1.2.1]).
Next, we consider an extension of Proposition 2 for functions defined on . Given any measurable subset S of , we define
where is the n-dimensional Euclidean ball of radius one and
The function is proportional to the surface measure of the projection of S on the Euclidean sphere and satisfies
for all . Note that and .
Proposition 3.
Let f be a nonnegative Lebesgue measurable function defined on a subset S of . For any numbers with and ,
where and is given by Equation (7).
Proof.
Let f be extended to using the rule for all x outside of S and let be defined according to
where is the Euclidean sphere of radius one and is the surface measure of the sphere. In the following, we will show that
Then, the stated inequality then follows from applying Proposition 2 to the function g.
To prove Inequality (11), we begin with a transformation into polar coordinates:
Letting denote the indicator function of the set , the integral over the sphere can be bounded using:
where: (a) follows from Hölder’s inequality with conjugate exponents and , and (b) follows from the definition of g and the fact that
Plugging Inequality (14) back into Equation (13) and then making the change of variable yields
The proof of Equation (12) follows along similar lines. We have
where (a) follows from a transformation into polar coordinates and (b) follows from the change of variable .
Having established Inequality (11) and Equation (12), an application of Proposition 2 completes the proof. □
3. Rényi Entropy Bounds
Let X be a random vector that has a density with respect to the Lebesgue measure on . The differential Rényi entropy of order is defined according to [11]:
Throughout this paper, it is assumed that the logarithm is defined with respect to the natural base and entropy is measured in nats. The Rényi entropy is continuous and nonincreasing in r. If the support set has finite measure, then the limit as r converges to zero is given by . If the support does not have finite measure, then increases to infinity as r decreases to zero. The case is given by the Shannon differential entropy:
Given a random variable X that is not identical to zero and numbers with and , we define the function
where .
The next result, which follows directly from Proposition 3, provides an upper bound on the Rényi entropy.
Proposition 4.
Proof.
This result follows immediately from Proposition 3 and the definition of Rényi entropy. □
The relationship between Proposition 4 and previous results depends on whether the moment p is equal to zero:
- One-moment inequalities: If , then there exists a distribution such that Inequality (15) holds with equality. This is because the zero-moment constraint ensures that the function that maximizes the Rényi entropy integrates to one. In this case, Proposition 4 is equivalent to previous results that focused on distributions that maximize Rényi entropy subject to a single moment constraint [12,13,15]. With some abuse of terminology, we refer to these bounds as one-moment inequalities. (A more accurate name would be two-moment inequalities under the constraint that one of the moments is the zeroth moment.)
- Two-moment inequalities: If , then the right-hand side of Inequality (15) corresponds to the Rényi entropy of a nonnegative function that might not integrate to one. Nevertheless, the expression provides an upper bound on the Rényi entropy for any density with the same moments. We refer to the bounds obtained using a general pair as two-moment inequalities.
The contribution of two-moment inequalities is that they lead to tighter bounds. To quantify the tightness, we define to be the gap between the right-hand side and left-hand side of Inequality (15) corresponding to the pair —that is,
The gaps corresponding to the optimal two-moment and one-moment inequalities are defined according to
3.1. Some Consequences of These Bounds
By Lyapunov’s inequality, the mapping is nondecreasing on , and thus
In other words, the case provides an upper bound on for nonnegative p. Alternatively, we also have the lower bound
which follows from the convexity of .
A useful property of is that it is additive with respect to the product of independent random variables. Specifically, if X and Y are independent, then
One consequence is that multiplication by a bounded random variable cannot increase the Rényi entropy by an amount that exceeds the gap of the two-moment inequality with nonnegative moments.
Proposition 5.
Let Y be a random vector on with finite Rényi entropy of order , and let X be an independent random variable that satisfies . Then,
for all .
Proof.
Let and let and denote the support sets of Z and Y, respectively. The assumption that X is nonnegative means that . We have
where (a) follows from Proposition 4, (b) follows from Equation (18) and the definition of , and (c) follows from Inequality (16) and the assumption . Finally, recalling that completes the proof. □
3.2. Example with Log-Normal Distribution
If , then the random variable has a log-normal distribution with parameters . The Rényi entropy is given by
and the logarithm of the sth moment is given by
With a bit of work, it can be shown that the gap of the optimal two-moment inequality does not depend on the parameters and is given by
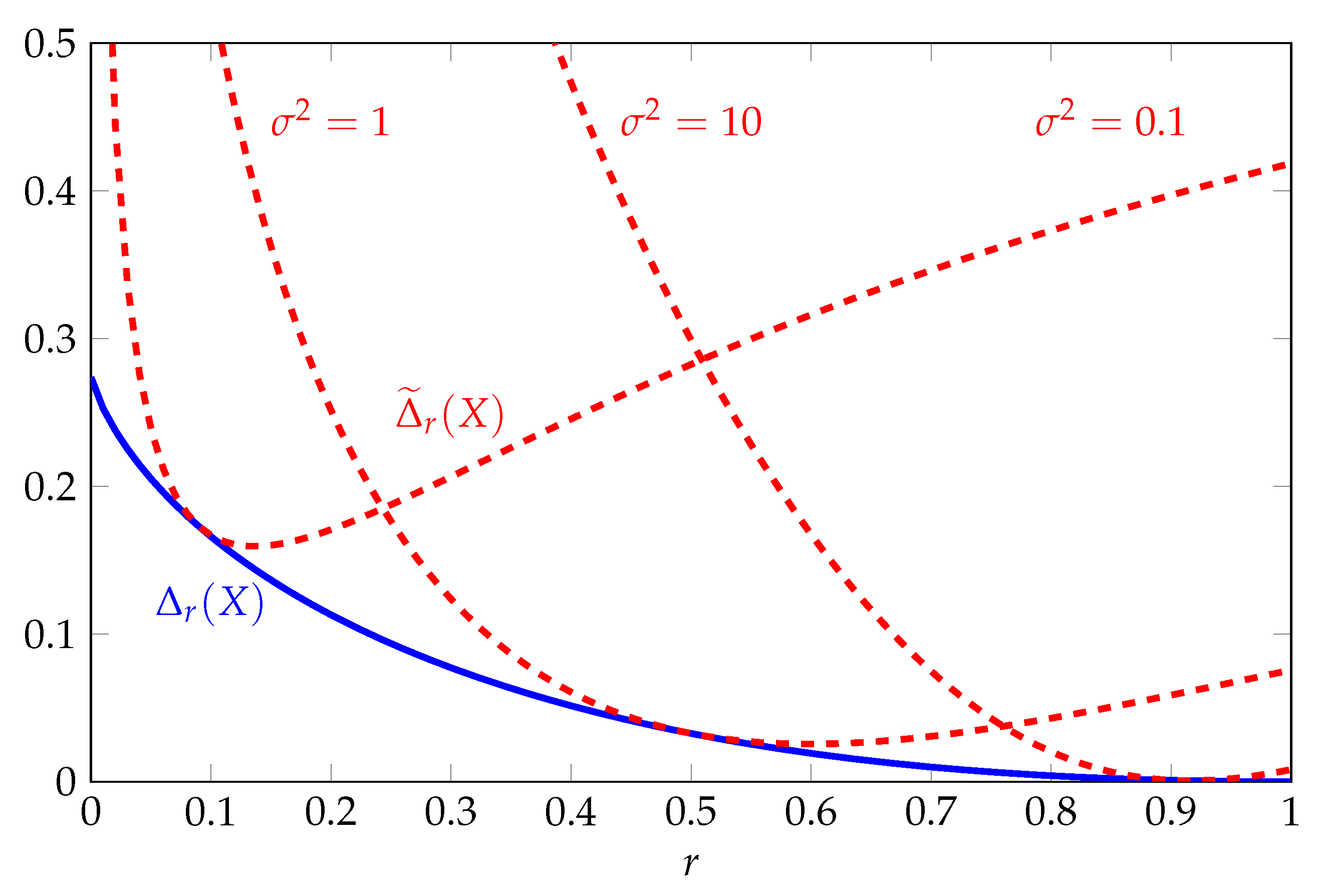
The details of this derivation are given in Appendix B.1. Meanwhile, the gap of the optimal one-moment inequality is given by
The functions and are illustrated in Figure 1 as a function of r for various . The function is bounded uniformly with respect to r and converges to zero as r increases to one. The tightness of the two-moment inequality in this regime follows from the fact that the log-normal distribution maximizes Shannon entropy subject to a constraint on . By contrast, the function varies with the parameter . For any fixed , it can be shown that increases to infinity if converges to zero or infinity.
3.3. Example with Multivariate Gaussian Distribution
Next, we consider the case where is an n-dimensional Gaussian vector with mean zero and identity covariance. The Rényi entropy is given by
and the sth moment of the magnitude is given by
The next result shows that as the dimension n increases, the gap of the optimal two-moment inequality converges to the gap for the log-normal distribution. Moreover, for each , the following choice of moments is optimal in the large-n limit:
The proof is given in Appendix B.3.
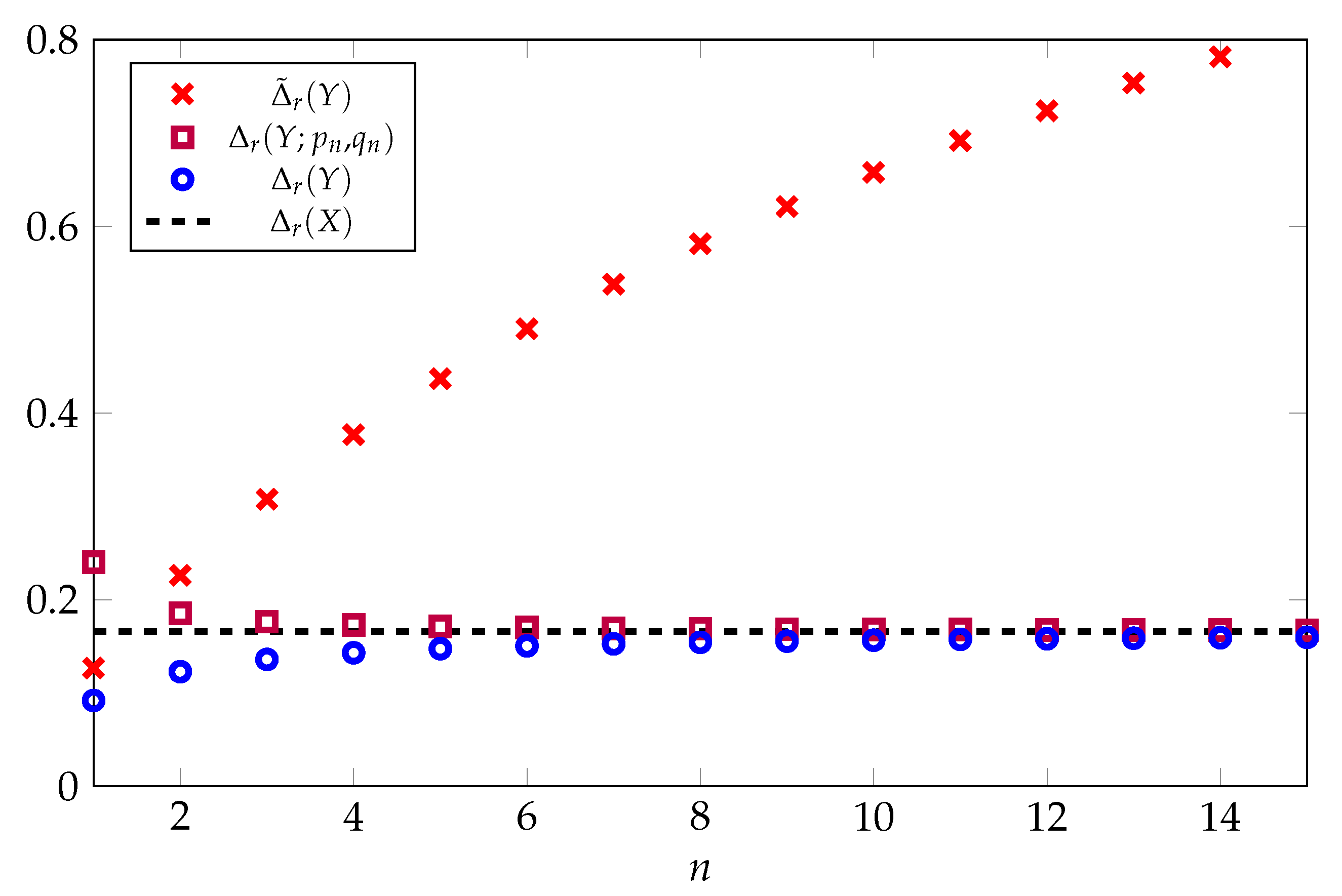
Proposition 6.
Figure 2 provides a comparison of , , and as a function of n for . Here, we see that both and converge rapidly to the asymptotic limit given by the gap of the log-normal distribution. By contrast, the gap of the optimal one-moment inequality increases without bound.
3.4. Inequalities for Differential Entropy
Proposition 4 can also be used to recover some known inequalities for differential entropy by considering the limiting behavior as r converges to one. For example, it is well known that the differential entropy of an n-dimensional random vector X with finite second moment satisfies
with equality if and only if the entries of X are i.i.d. zero-mean Gaussian. A generalization of this result in terms of an arbitrary positive moment is given by
for all . Note that Inequality (22) corresponds to the case .
Inequality (23) can be proved as an immediate consequence of Proposition 4 and the fact that is nonincreasing in r. Using properties of the beta function given in Appendix A, it is straightforward to verify that
Combining this result with Proposition 4 and Inequality (16) leads to
Using Inequality (10) and making the substitution leads to Inequality (23).
Another example follows from the fact that the log-normal distribution maximizes the differential entropy of a positive random variable X subject to constraints on the mean and variance of , and hence
with equality if and only if X is log-normal. In Appendix B.4, it is shown how this inequality can be proved using our two-moment inequalities by studying the behavior as both p and q converge to zero as r increases to one.
4. Bounds on Mutual Information
4.1. Relative Entropy and Chi-Squared Divergence
Let P and Q be distributions defined on a common probability space that have densities p and q with respect to a dominating measure . The relative entropy (or Kullback–Leibler divergence) is defined according to
and the chi-squared divergence is defined as
Both of these divergences can be seen as special cases of the general class of f-divergence measures and there exists a rich literature on comparisons between different divergences [8,26,27,28,29,30,31,32]. The chi-squared divergence can also be viewed as the squared distance between and . The chi-square can also be interpreted as the first non-zero term in the power series expansion of the relative entropy ([26], [Lemma 4]). More generally, the chi-squared divergence provides an upper bound on the relative entropy via
The proof of this inequality follows straightforwardly from Jensen’s inequality and the concavity of the logarithm; see [27,31,32] for further refinements.
Given a random pair , the mutual information between X and Y is defined according to
From Inequality (25), we see that the mutual information can always be upper bounded using
The next section provides bounds on the mutual information that can improve upon this inequality.
4.2. Mutual Information and Variance of Conditional Density
Let be a random pair such that the conditional distribution of Y given X has a density with respect to the Lebesgue measure on . Note that the marginal density of Y is given by . To simplify notation, we will write and where the subscripts are implicit. The support set of Y is denoted by .
The measure of the dependence between X and Y that is used in our bounds can be understood in terms of the variance of the conditional density. For each y, the conditional density evaluated with a random realization of X is a random variable. The variance of this random variable is given by
where we have used the fact that the marginal density is the expectation of . The sth moment of the variance of the conditional density is defined according to
The variance moment is nonnegative and equal to zero if and only if X and Y are independent.
The function is defined according to
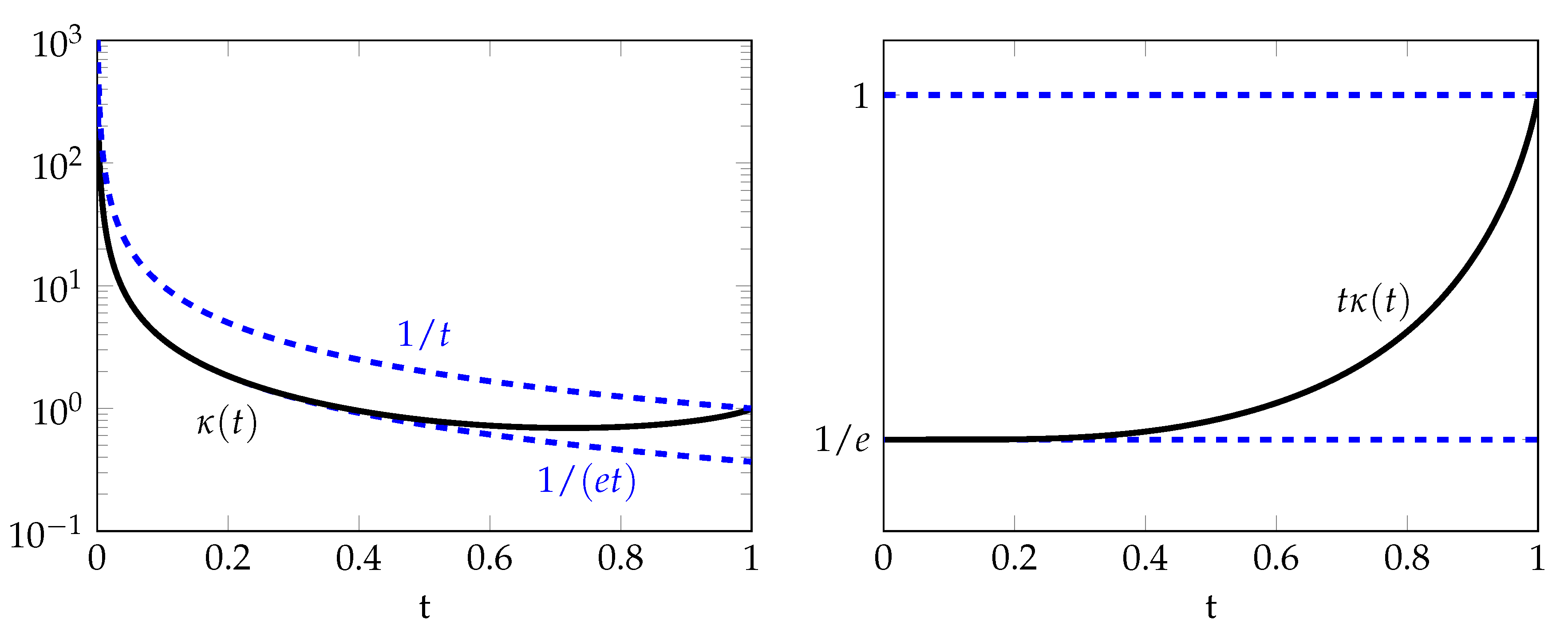
The proof of the following result is given in Appendix C. The behavior of is illustrated in Figure 3.
Proposition 7.
The function defined in Equation (29) can be expressed as
where
and denotes Lambert’s W- function, i.e., is the unique solution to the equation on the interval . Furthermore, the function is strictly increasing on with and , and thus
where the lower bound is tight for small values of and the upper bound is tight for values of t close to 1.
We are now ready to give the main results of this section, which are bounds on the mutual information. We begin with a general upper bound in terms of the variance of the conditional density.
Proposition 8.
For any , the mutual information satisfies
Proof.
We use the following series of inequalities:
where (a) follows from the definition of mutual information, (b) follows from Inequality (25), and (c) follows from Bayes’ rule, which allows us to write the chi-square in terms of the variance of the conditional density:
Inequality (d) follows from the nonnegativity of the variance and the definition of . □
Evaluating Proposition 8 with recovers the well-known inequality . The next two results follow from the cases and , respectively.
Proposition 9.
For any , the mutual information satisfies
where .
Proof.
Starting with Proposition 8 and applying Hölder’s inequality with conjugate exponents and leads to
where we have used the fact that . □
Proposition 10.
For any , the mutual information satisfies
where and
with .
Proof.
Evaluating Proposition 8 with gives
Evaluating Proposition 3 with leads to
Combining these inequalities with the expression for given in Equation (8) completes the proof. □
The contribution of Propositions 9 and 10 is that they provide bounds on the mutual information in terms of quantities that can be easy to characterize. One application of these bounds is to establish conditions under which the mutual information corresponding to a sequence of random pairs converges to zero. In this case, Proposition 9 provides a sufficient condition in terms of the Rényi entropy of and the function , while Proposition 10 provides a sufficient condition in terms of evaluated with two difference values of s. These conditions are summarized in the following result.
Proposition 11.
Let be a sequence of random pairs such that the conditional distribution of given has a density on . The following are sufficient conditions under which the mutual information of converges to zero as k increases to infinity:
- There exists such that
- There exists such that
4.3. Properties of the Bounds
The variance moment has a number of interesting properties. The variance of the conditional density can be expressed in terms of an expectation with respect to two independent random variables and with the same distribution as X via the decomposition:
Consequently, by swapping the order of the integration and expectation, we obtain
where
The function is a positive definite kernel that does not depend on the distribution of X. For , this kernel has been studied previously in the machine learning literature [33], where it is referred to as the expected likelihood kernel.
The variance of the conditional density also satisfies a data processing inequality. Suppose that forms a Markov chain. Then, the square of the conditional density of Y given U can be expressed as
where . Combining this expression with Equation (30) yields
where we recall that are independent copies of X
Finally, it is easy to verify that the function satisfies
Using this scaling relationship, we see that the sufficient conditions in Proposition 11 are invariant to scaling of Y.
4.4. Example with Additive Gaussian Noise
We now provide a specific example of our bounds on the mutual information. Let be a random vector with distribution and let Y be the output of a Gaussian noise channel
where is independent of X. If has finite second moment, then the mutual information satisfies
where equality is attained if and only if X has zero-mean isotropic Gaussian distribution. This inequality follows straightforwardly from the fact that the Gaussian distribution maximizes differential entropy subject to a second moment constraint [11]. One of the limitations of this bound is that it can be loose when the second moment is dominated by events that have small probability. In fact, it is easy to construct examples for which does not have a finite second moment, and yet is arbitrarily close to zero.
Our results provide bounds on that are less sensitive to the effects of rare events. Let denote the density of the standard Gaussian distribution on . The product of the conditional densities can be factored according to
where the second step follows because is invariant to orthogonal transformations. Integrating with respect to y leads to
where we recall that . For the case , we see that is a Gaussian kernel, thus
A useful property of is that the conditions under which it converges to zero are weaker than the conditions needed for other measures of dependence. Observe that the expectation in Equation (34) is bounded uniformly with respect to . In particular, for every and , we have
where we have used the inequality and the fact that . Consequently, converges to zero whenever X converges to a constant value x in probability.
To study some further properties of these bounds, we now focus on the case where X is a Gaussian scalar mixture generated according to
with A and U independent. In this case, the expectations with respect to the kernel can be computed explicitly, leading to
where are independent copies of U. It can be shown that this expression depends primarily on the magnitude of U. This is not surprising given that X converges to a constant if and only if U converges to zero.
Our results can also be used to bound the mutual information by noting that forms a Markov chain, and taking advantage of the characterization provided in Equation (31). Letting and with be mutually independent leads to
In this case, is a measure of the variation in U. To study its behavior, we consider the simple upper bound
which follows from noting that the term inside the expectation in Equation (37) is zero on the event . This bound shows that if then is bounded uniformly with respect to distributions on U, and if , then is bounded in terms of the th moment of U.
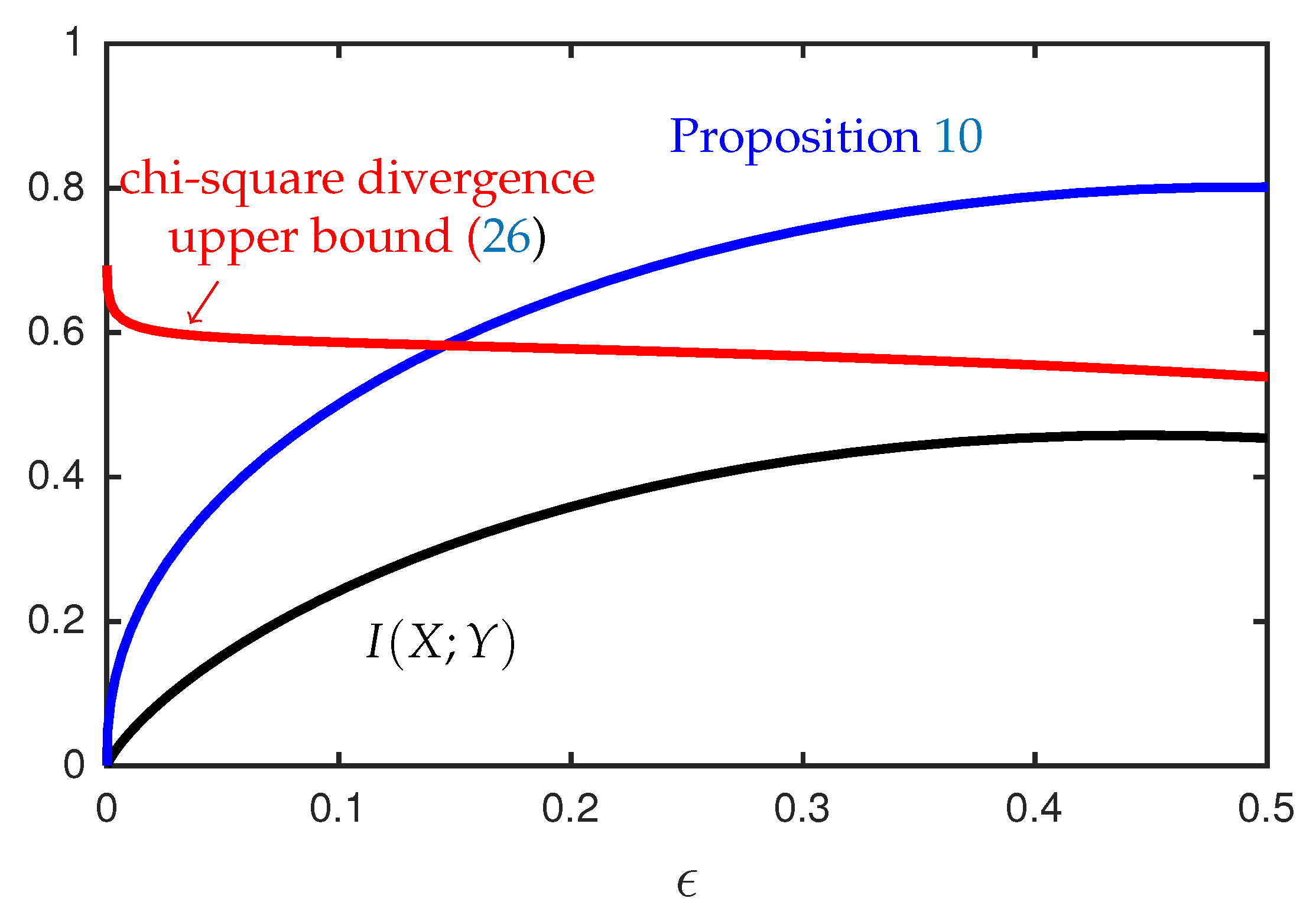
In conjunction with Propositions 9 and 10, the function provides bounds on the mutual information that can be expressed in terms of simple expectations involving two independent copies of U. Figure 4 provides an illustration of the upper bound in Proposition 10 for the case where U is a discrete random variable supported on two points, and X and Y are generated according to Equations (32) and (35). This example shows that there exist sequences of distributions for which our upper bounds on the mutual information converge to zero while the chi-squared divergence between and is bounded away from zero.
5. Conclusions
This paper provides bounds on Rényi entropy and mutual information that are based on a relatively simple two-moment inequality. Extensions to inequalities with more moments are worth exploring. Another potential application is to provide a refined characterization of the “all-or-nothing” behavior seen in a sparse linear regression problem [34,35], where the current methods of analysis depend on a complicated conditional second moment method.
Funding
This research was supported in part by the National Science Foundation under Grant 1750362 and in part by the Laboratory for Analytic Sciences (LAS). Any opinions, findings, conclusions, and recommendations expressed in this material are those of the author and do not necessarily reflect the views of the sponsors.
Conflicts of Interest
The author declares no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. The Gamma and Beta Functions
This section reviews some properties of the gamma and beta functions. For , the gamma function is defined according to Binet’s formula for the logarithm for the gamma function ([25], [Theorem 1.6.3]) gives
where the remainder term is convex and nonincreasing with and . Euler’s reflection formula ([25], [Theorem 1.2.1]) gives
Appendix B. Details for Rényi Entropy Examples
This appendix studies properties of the two-moment inequalities for Rényi entropy described in Section 3.
Appendix B.1. Log-Normal Distribution
Let X be a log-normal random variable with parameters and consider the parametrization
where and . Then, we have
Combining these expressions with Equation (A4) leads to
We now characterize the minimum with respect to the parameters . Note that the mapping is convex and symmetric about the point . Therefore, the minimum with respect to is attained at . Meanwhile, mapping is convex and attains its minimum at . Evaluating Equation (A6) with these values, we see that the optimal two-moment inequality can be expressed as
By Equation (A4), this expression is equivalent to Equation (A1). Moreover, the fact that decreases to zero as r increases to one follows from the fact that decreases to zero and x increases to infinity.
Next, we express the gap in terms of the pair . Comparing the difference between and leads to
where . In particular, if , then we obtain the simplified expression
This characterization shows that the gap of the optimal one-moment inequality increases to infinity in the limit as either or .
Appendix B.2. Multivariate Gaussian Distribution
Let be an n-dimensional Gaussian vector and consider the parametrization
where and . We can write
Furthermore, if
then is finite and is given by
where
Here, we note that the scaling in Equation (21) corresponds to and , and thus the condition Inequality (A7) is satisfied for all . Combining the above expressions and then using Equations (A1) and (A4) leads to
Next, we study some properties of . By Equation (A1), the logarithm of the gamma function can be expressed as the sum of convex functions:
where . Starting with the definition of and then using Jensen’s inequality yields
where . Using the inequality leads to
where .
Appendix B.3. Proof of Proposition 6
Let . For fixed , we use to denote the function defined in Equation (A8) and we use to denote the right-hand side of Equation (A9). These functions are defined to be equal to positive infinity for any pair such that Inequality (A7) does not hold.
Note that the terms and converge to zero in the limit as n increases to infinity. In conjunction with Equation (A11), this shows that converges pointwise to a limit given by
At this point, the correspondence with the log-normal distribution can be seen from the fact that is equal to the right-hand side of Equation (A6) evaluated with .
To show that the gap corresponding to the log-normal distribution provides an upper bound on the limit, we use
Here, the last equality follows from the analysis in Appendix B.1, which shows that the minimum of is a attained at and .
To prove the lower bound requires a bit more work. Fix any and let . Using the lower bound on given in Inequality (A10), it can be verified that
Consequently, we have
To complete the proof we will show that for any sequence that converges to one as n increases to infinity, we have
To see why this is the case, note that by Equation (A4) and Inequality (A5),
Therefore, we can write
where is bounded uniformly for all n. Making the substitution , we obtain
Next, let . The lower bound in Inequality (A10) leads to
The limiting behavior in Equation (A14) can now be seen as a consequence of Inequality (A15) and the fact that, for any sequence converging to one, the right-hand side of Inequality (A16) increases without bound as n increases. Combining Inequality (A12), Inequality (A13), and Equation (A14) establishes that the large n limit of exists and is equal to . This concludes the proof of Proposition 6.
Appendix B.4. Proof of Inequality (uid39)
Given any and let
We need the following results, which characterize the terms in Proposition 4 in the limit as r increases to one.
Lemma A1.
The function satisfies
Proof.
Starting with Equation (A4), we can write
As r converges to one, the terms in the exponent converge to zero. Note that completes the proof. □
Lemma A2.
If X is a random variable such that is finite in a neighborhood of zero, then and are finite, and
Proof.
Let . The assumption that is finite in a neighborhood of zero means that is finite for all positive integers m, and thus is real analytic in a neighborhood of zero. Hence, there exist constants and , depending on the distribution of X, such that
where and . Consequently, for all r such that , it follows that
Taking the limit as r increases to one completes the proof. □
We are now ready to prove Inequality (24). Combining Proposition 4 with Lemma A1 and Lemma A2 yields
The stated inequality follows from evaluating the right-hand side with , recalling that corresponds to the limit of as r increases to one.
Appendix C. Proof of Proposition 7
The function can be expressed as
where . For , the bound implies that . Noting that , we conclude that .
Next, we consider the case . The function is continuously differentiable on with
Under the assumption , we see that is increasing for all u sufficiently close to zero and decreasing for all u sufficiently large, and thus the supremum is attained at a stationary point of on . Making the substitution leads to
For , it follows that , and thus has a unique root that can be expressed as
where Lambert’s function is the solution to the equation on the interval on .
Lemma A3.
The function is strictly increasing on with and .
References
- Dembo, A.; Cover, T.M.; Thomas, J.A. Information Theoretic Inequalities. IEEE Trans. Inf. Theory 1991, 37, 1501–1518. [Google Scholar] [CrossRef] [Green Version]
- Carslon, F. Une inégalité. Ark. Mat. Astron. Fys. 1934, 25, 1–5. [Google Scholar]
- Levin, V.I. Exact constants in inequalities of the Carlson type. Doklady Akad. Nauk. SSSR (N. S.) 1948, 59, 635–638. [Google Scholar]
- Larsson, L.; Maligranda, L.; Persson, L.E.; Pečarić, J. Multiplicative Inequalities of Carlson Type and Interpolation; World Scientific Publishing Company: Singapore, 2006. [Google Scholar]
- Barza, S.; Burenkov, V.; Pečarić, J.E.; Persson, L.E. Sharp multidimensional multiplicative inequalities for weighted Lp spaces with homogeneous weights. Math. Inequalities Appl. 1998, 1, 53–67. [Google Scholar] [CrossRef] [Green Version]
- Reeves, G. Two-Moment Inequailties for Rényi Entropy and Mutual Information. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 664–668. [Google Scholar]
- Gray, R.M. Entropy and Information Theory; Springer-Verlag: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- van Erven, T.; Harremoës, P. Rényi Divergence and Kullback–Liebler Divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef] [Green Version]
- Atar, R.; Chowdharry, K.; Dupuis, P. Abstract. Robust Bounds on Risk-Sensitive Functionals via Rényi Divergence. SIAM/ASA J. Uncertain. Quantif. 2015, 3, 18–33. [Google Scholar] [CrossRef] [Green Version]
- Rosenkrantz, R. (Ed.) E. T. Jaynes: Papers on Probability, Staistics and Statistical Physics; Springer: Berlin/Heidelberg, Germany, 1989. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Lutwak, E.; Yang, D.; Zhang, G. Moment-entropy inequalities. Ann. Probab. 2004, 32, 757–774. [Google Scholar] [CrossRef]
- Lutwak, E.; Yang, D.; Zhang, G. Moment-Entropy Inequalities for a Random Vector. IEEE Trans. Inf. Theory 2007, 53, 1603–1607. [Google Scholar] [CrossRef]
- Lutwak, E.; Lv, S.; Yang, D.; Zhang, G. Affine Moments of a Random Vector. IEEE Trans. Inf. Theory 2013, 59, 5592–5599. [Google Scholar] [CrossRef]
- Costa, J.A.; Hero, A.O.; Vignat, C. A Characterization of the Multivariate Distributions Maximizing Rényi Entropy. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Lausanne, Switzerland, 30 June–5 July 2002. [Google Scholar] [CrossRef]
- Costa, J.A.; Hero, A.O.; Vignat, C. A Geometric Characterization of Maximum Rényi Entropy Distributions. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Seattle, WA, USA, 9–14 July 2006; pp. 1822–1826. [Google Scholar]
- Johnson, O.; Vignat, C. Some results concerning maximum Rényi entropy distributions. Ann. de l’Institut Henri Poincaré (B) Probab. Stat. 2007, 43, 339–351. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.H. A simple proof of the Moment-Entropy inequalities. Adv. Appl. Math. 2019, 108, 31–44. [Google Scholar] [CrossRef]
- Barron, A.; Yang, Y. Information-theoretic determination of minimax rates of convergence. Ann. Stat. 1999, 27, 1564–1599. [Google Scholar] [CrossRef]
- Wu, Y.; Xu, J. Statistical problems with planted structures: Information-theoretical and computational limits. In Information-Theoretic Methods in Data Science; Rodrigues, M.R.D., Eldar, Y.C., Eds.; Cambridge University Press: Cambridge, UK, 2020; Chapter 13. [Google Scholar]
- Reeves, G. Conditional Central Limit Theorems for Gaussian Projections. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 3055–3059. [Google Scholar]
- Reeves, G.; Pfister, H.D. The Replica-Symmetric Prediction for Random Linear Estimation with Gaussian Matrices is Exact. IEEE Trans. Inf. Theory 2019, 65, 2252–2283. [Google Scholar] [CrossRef]
- Reeves, G.; Pfister, H.D. Understanding Phase Transitions via Mutual Information and MMSE. In Information-Theoretic Methods in Data Science; Rodrigues, M.R.D., Eldar, Y.C., Eds.; Cambridge University Press: Cambridge, UK, 2020; Chapter 7. [Google Scholar]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1970. [Google Scholar]
- Andrews, G.E.; Askey, R.; Roy, R. Special Functions; Vol. 71, Encyclopedia of Mathematics and its Applications; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Nielsen, F.; Nock, R. On the Chi Square and Higher-Order Chi Distrances for Approximationg f-Divergences. IEEE Signal Process. Lett. 1014, 1, 10–13. [Google Scholar]
- Sason, I.; Verdú, S. f-Divergence Inequalities. IEEE Trans. Inf. Theory 2016, 62, 5973–6006. [Google Scholar] [CrossRef]
- Sason, I. On the Rényi Divergence, Joint Range of Relative Entropy, and a Channel Coding Theorem. IEEE Trans. Inf. Theory 2016, 62, 23–34. [Google Scholar] [CrossRef]
- Sason, I.; Verdú, S. Improved Bounds on Lossless Source Coding and Guessing Moments via Rényi Measures. IEEE Trans. Inf. Theory 2018, 64, 4323–4326. [Google Scholar] [CrossRef] [Green Version]
- Sason, I. On f-divergences: Integral representations, local behavior, and inequalities. Entropy 2018, 20, 383. [Google Scholar] [CrossRef] [Green Version]
- Melbourne, J.; Madiman, M.; Salapaka, M.V. Relationships between certain f-divergences. In Proceedings of the Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 24–27 September 2019; pp. 1068–1073. [Google Scholar]
- Nishiyama, T.; Sason, I. On Relations Between the Relative Entropy and χ2-Divergence, Generalizations and Applications. Entropy 2020, 22, 563. [Google Scholar] [CrossRef]
- Jebara, T.; Kondor, R.; Howard, A. Probability Product Kernels. J. Mach. Learn. Res. 2004, 5, 818–844. [Google Scholar]
- Reeves, G.; Xu, J.; Zadik, I. The All-or-Nothing Phenomenon in Sparse Linear Regression. In Proceedings of the Conference On Learning Theory (COLT), Phoenix, AZ, USA, 25–28 June 2019. [Google Scholar]
- Reeves, G.; Xu, J.; Zadik, I. All-or-nothing phenomena from single-letter to high dimensions. In Proceedings of the IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Guadeloupe, France, 15–18 December 2019. [Google Scholar]
- Grenié, L.; Molteni, G. Inequalities for the beta function. Math. Inequalities Appl. 2015, 18, 1427–1442. [Google Scholar] [CrossRef] [Green Version]
- Milgrom, P.; Segal, I. Envelope Theorems for Arbitrary Choice Sets. Econometrica 2002, 70, 583–601. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Comparison of upper bounds on Rényi entropy in nats for the log-normal distribution as a function of the order r for various .
Figure 1.
Comparison of upper bounds on Rényi entropy in nats for the log-normal distribution as a function of the order r for various .

Figure 2.
Comparison of upper bounds on Rényi entropy in nats for the multivariate Gaussian distribution as a function of the dimension n with . The solid black line is the gap of the optimal two-moment inequality for the log-normal distribution.
Figure 2.
Comparison of upper bounds on Rényi entropy in nats for the multivariate Gaussian distribution as a function of the dimension n with . The solid black line is the gap of the optimal two-moment inequality for the log-normal distribution.

Figure 3.
Graphs of and as a function of t.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Reeves, G. A Two-Moment Inequality with Applications to Rényi Entropy and Mutual Information. Entropy 2020, 22, 1244. https://doi.org/10.3390/e22111244
AMA Style
Reeves G. A Two-Moment Inequality with Applications to Rényi Entropy and Mutual Information. Entropy. 2020; 22(11):1244. https://doi.org/10.3390/e22111244
Chicago/Turabian StyleReeves, Galen. 2020. "A Two-Moment Inequality with Applications to Rényi Entropy and Mutual Information" Entropy 22, no. 11: 1244. https://doi.org/10.3390/e22111244
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.