Entropy Ratio and Entropy Concentration Coefficient, with Application to the COVID-19 Pandemic

Institute of Mathematics, University of Greifswald, 17487 Greifswald, Germany
Entropy 2020, 22(11), 1315; https://doi.org/10.3390/e22111315
Submission received: 7 October 2020
/
Revised: 13 November 2020
/
Accepted: 14 November 2020
/
Published: 18 November 2020
(This article belongs to the Special Issue Information theory and Symbolic Analysis: Theory and Applications)
Abstract
:In order to study the spread of an epidemic over a region as a function of time, we introduce an entropy ratio U describing the uniformity of infections over various states and their districts, and an entropy concentration coefficient The latter is a multiplicative version of the Kullback-Leibler distance, with values between 0 and 1. For product measures and self-similar phenomena, it does not depend on the measurement level. Hence, C is an alternative to Gini’s concentration coefficient for measures with variation on different levels. Simple examples concern population density and gross domestic product. Application to time series patterns is indicated with a Markov chain. For the Covid-19 pandemic, entropy ratios indicate a homogeneous distribution of infections and the potential of local action when compared to measures for a whole region.
MSC:
62B10; 94A17; 62P10; 28A801. Introduction
In any statistical data analysis, a first step is to determine two parameters that characterize center (mean, median) and variation of the data. For the Covid-19 pandemic, the mean in any region is the case incidence, given by weekly averages of case numbers per capita. How can we measure variation of infection intensity? In abstract terms, we have a basic probability measure Q, which expresses population size, and another probability measure P, which counts infections. We want to know whether P is uniformly distributed with respect to or whether it is concentrated on certain hotspots.
Similar questions are frequently studied in economy, where P represents market share, wealth, or income, while the basic measure Q again expresses population size. The Gini concentration coefficient G is the standard parameter of variation [1]. It has a clear, interpretable scale, with values that are between zero and one. Zero describes totally uniform distribution, and one is approached when there are many actors, while all income or production is concentrated in the hands of one monopolist. Gini’s coefficient was used for spatial patterns in medicine [2], and it is applied here to Covid-19 case numbers. However, it does not really fit the data structure and the fractal character of the infection measure
Shannon entropy [3] and the relative entropy introduced by Kullback and Leibler [4] have also been used as measures of uniform distribution and concentration. Their values grow with the size of the data, which makes interpretation difficult. In 1971, their use was rejected by Hart [5], since, for the lognormal distribution, a standard model of income distribution, they lead to the ordinary variance. Fractals were not known at this time. However, already in the 1950s, Rényi [6,7] developed entropy concepts that later provided adequate description of fractal measures [8].
Here, we introduce the entropy ratio U which is related to Rényi’s entropy dimension of a measure on a metric space. While Rényi’s theoretical concept is defined as a limit, our parameter U is simply a descriptive statistics of the measures It may vary with the size of the partition on which data of P and Q are given. Our entropy concentration coefficient has the same scale and interpretation as the Gini coefficient. It can be considered as a version of the Kullback–Leibler distance on multiplicative scale.
Entropy concepts indeed seem to be appropriate to describe the spread of an epidemic since there is a strong analogy with Boltzmann’s classical thermodynamical paradigm. A closed system, say molecules in a box with fixed temperature, will approach in the course of time a final state of maximum entropy, which is characterized by uniform distribution of molecules in state space. Under certain conditions, the distance between the actual distribution and the limit distribution is a relative entropy that can be interpreted as a measure of free energy or available work [9].
In the beginning of an epidemic wave, the virus itself will resist this paradigm by creating a fractal structure of hotspots. But if we let the virus do its job, spots will overlap and their number will increase so fast that uniform distribution is approached soon [10]. Of course, reality is not a closed system, and people do their best to avoid this scenario with various containment and lockdown measures. In the language of physics, external forces drive our system away from equilibrium. In this connection, the interpretation of relative entropy as available work seems to be useful for Covid-19. Local and federal authorities in many countries argue on the right type of containment. Measures for a whole country are easier to implement, while local actions can adapt better to a specific situation. The entropy concentration coefficient as a distance to uniform distribution may help to settle such arguments. For small concentration, general measures are justified. When concentration rises, local action becomes more preferable.
We shall now define our concepts, prove their basic properties and compare with Gini’s coefficient. Although Covid-19 was the motivation for our study, it turns out that entropy ratio and entropy concentration coefficient are appropriate parameters for many other phenomena. For this reason, we consider, in Section 3, two small applications to population density and gross domestic product. Section 4 and Section 5 study product spaces and show how entropy ratios are connected with entropy rate of random processes and entropy dimension of measures in Euclidean space. The entropy ratio does not change when the measures are replaced by their products for some We introduce Covid-19 data in Section 6 and study the pandemic in the USA and Germany in Section 7 and Section 8, while using data from Johns Hopkins University and Robert Koch Institut, respectively. The paper is completed with conclusions and Appendix A on the Gini coefficient.
2. Basic Concepts
Independence of intensity and concentration. We take a finite basic space In our application, the n points are the subregions of a region, for example, states of the USA. On this space, two measures and are given. In the example, they count the number of infections and inhabitants in each subregion. and denote the total number of infections and inhabitants in the region. They are important parameters, and is the incidence, or intensity, of the disease in the region.
The parameters of uniformity and concentration should be formally independent of the intensity of the observed phenomenon. For this reason, we divide the measures by their total mass respectively. We obtain two probability measures In other words, we obtain numbers
When we have twice or ten times the number of cases in the same proportions, we obtain the same and Intensity has been eliminated. In the sequel, Q will be the measure that is considered as `uniform distribution’. For this reason, we require for Our standard reference method, the Gini coefficient, is described in the Appendix A of the paper.
Because all terms of H are non-negative. Thus, and only if for one The relative entropy of P with respect to Q was defined in [4].
Jensen’s inequality for the logarithm implies that D is always positive, except for the case where it is zero, cf. [11] (Lemma 2.3.1). For this reason, D is considered to be a kind of distance from P to and is called Kullback-Leibler distance, or Kullback-Leibler divergence, or information gain [7]. Note that D is finite since we assumed If we would interchange P and we would get as soon as for some i (that is, no infections in a subregion).
On the one hand, D is a measure of non-uniformity or concentration of It measures how far the proportions of the deviate from those of the On the other hand, D does not possess a nice bounded scale: when and for some , then As a rule, D admits larger values when the number n of items increases.
The entropy ratio. Instead of , we recommend to take the entropy ratio
as a measure of uniformity, and the entropy concentration coefficient
as a measure of non-uniformity or concentration. It turns out that C has the same properties as Gini’s concentration coefficient.
Proposition 1.
(Basic properties of entropy ratio and entropy concentration coefficient)
- (i)
- and
- (ii)
- and if and only if
- (iii)
- and if and only if there is an i with
- (iv)
- The values of U and C do not depend on the base of the logarithm.
Proof.
(i). Because for and for all the denominator of U is always positive. Thus And follows directly from (see above). (ii). is equivalent to which is equivalent to (iii). means which happens only if some (lv). When we first work with natural logarithm and then change to base we have to divide both denominator and numerator by □
3. Examples
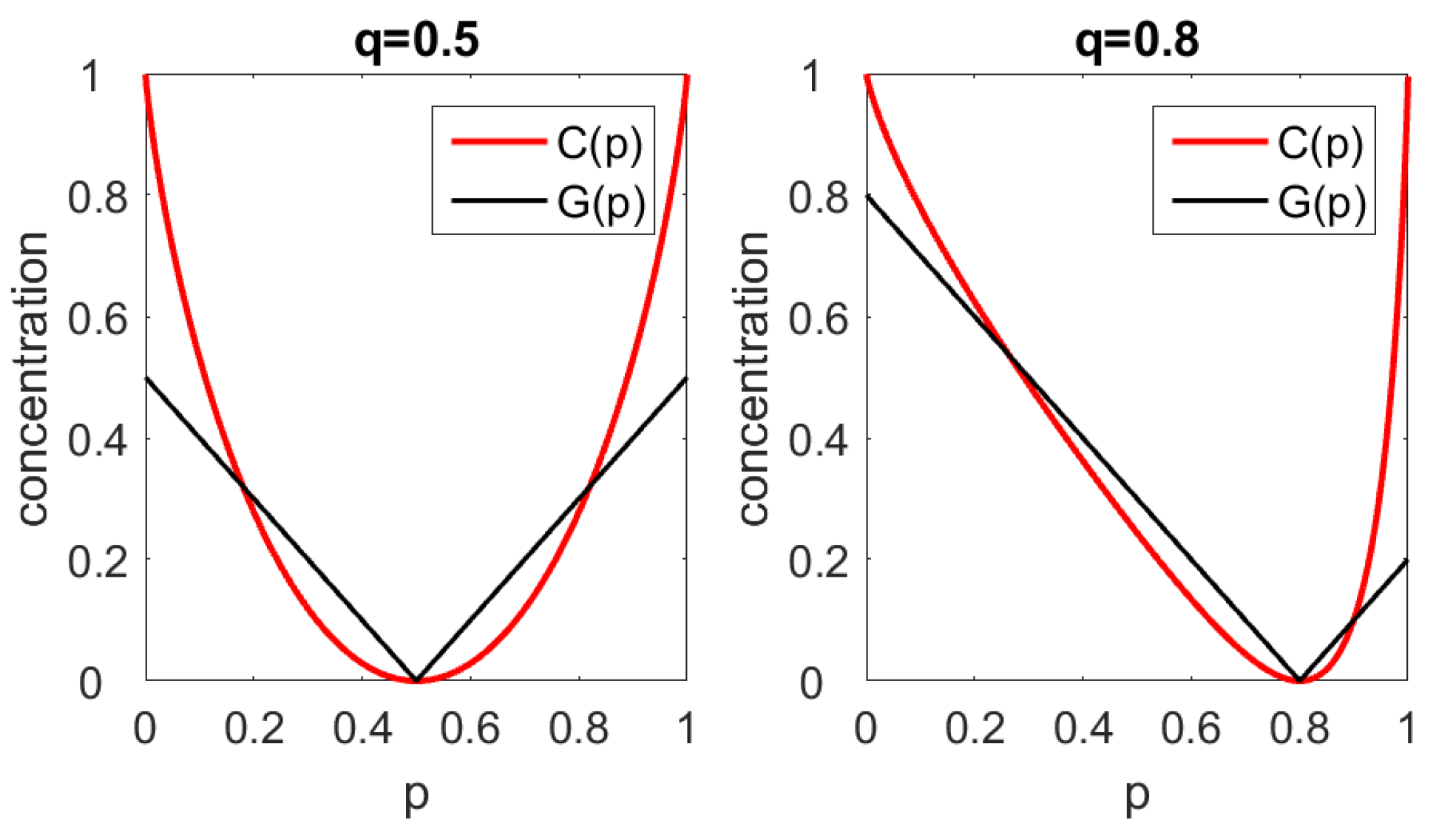
The case of two items. Let Setting and a small calculation gives For , we obtain Figure 1 shows G and C as functions of p while q is fixed at and
For , we have and both coefficients indicate concentration zero. Deviations from this minimum point will be punished stronger by Gini’s coefficient, which is what mathematicians call an -parameter, cf. [1]. Our coefficient C is an -parameter with a quadratic minimum, which assumes small values in the vicinity of the minimum point.
We see that Gini’s coefficient is not perfect in recognizing monopolists. It approaches the value 1 only if and also Our coefficient C will always be 1 for , as shown in Proposition 1.
Population density in Germany. For the 16 federal states and 412 districts of Germany we take the area as and the population size as For both states and districts, we show and C in Table 1. We want to understand to which extend population is concentrated on small areas.
When compared to the world, Germany has only one large town: Berlin, with 3.6 milliion inhabitants, more than 4000 per It is surrounded by five fairly rural states of East Germany, with a population density of between 70 and 220 people per
All three parameters reflect this situation. Deleting Berlin from the statistics must decrease the concentration, and must do so drastically for East Germany. The decrease on the district level is smaller than on state level, since districts of Berlin are well comparable with many urban districts in Germany.
For , all values of districts are much larger than corresponding values of states. In other words, D is biased by sample size Moreover, a value of 0.971 does not say anything, since the scale of D is unbounded. Accordingly, D is rather useless as a concentration measure. The bias of D is known, cf. [11] (Lemma 2.3.3), and this paper started as an attempt to standardize cf. Proposition 1 (v).
However, G is also biased by sample size, with values around 0.5 for districts and around 0.3 for states. According to the concentration of districts without Berlin is larger than concentration of states with Berlin. This is simply not true.
The values of C in Germany are nearly the same on the state and district level. In the East with Berlin, concentration of districts is clearly smaller than concentration of states, because of the size of Berlin as a state. Without Berlin, the eastern states are very similar, while the districts show a similar structure as all over Germany. On the whole, C describes the real situation much better than However, in agreement with Figure 1, the values of C are generally smaller than those of G, since we are fairly near to the minimum point
Gross domestic product. For all countries with more than one million inhabitants, we took the 2020 population projection from the UN population division [12] and the 2019 gross domestic product (GDP) according to the World Bank database [13] (for a few countries, data of a previous year had to be taken). We study the concentration of the GDP among countries, and among collections of countries defined by the UN as sustainable development goal regions. Table 2 shows the Gini and entropy concentration coefficients determined from these data.
This is a typical application of the Gini coefficient. Nevertheless, G is biased by sample size. The values for the world are larger than for the continents, values for regions are smaller than corresponding values for countries. We think that C gives a better picture by showing that inequality in Asia is as large as inequality all over the world, while Africa, Europe, and America without US and Canada show a great degree of homogeneity. When the region US+Canada is included, inequality in America becomes very large, due to the immense economic power of the USA.
The values of C are again generally smaller than those of Hence, C may not be welcome as a measure of economic inequality. It takes small deviations from the equality point less seriously than Gini’s raising suspicion to downplay social differences.
In the Appendix A, we sketch a proof indicating how G depends on sample size. Actually, G was not designed for large lists of data of varying length. The standard applications either involve a small number of enterprises that share a market, or an income distribution in classes like 0–1000 $, 1000–4000 $ etc. which is expected to approximate a smooth density function. The geographical distribution of wealth, as measured in regions and subregions, is much more fragmented.
4. Product Measures
This note studies measures which are given by their values on nested partitions. Unfortunately, our data provide only two partitions—states and districts. However, in stochastic processes and time series analysis, we have an unbounded sequence of nested partitions, indexed by words of length 1,2,... over some alphabet. This setting seems to bear a large potential for the application of entropy ratios. We now introduce product measures and show a basic property of the entropy ratio.
If P is defined on and the probability measure P is defined on then the product measure is defined on by for i in and j in The k-th power is a probability measure on the set of all words of length k over the alphabet The measure assigns, to the word w, the probability
Product measures are at the core of entropy theory. When Shannon [3] characterized entropy axiomatically, the following property played a key role.
Kullback and Leibler [4] (Theorem 3.1) proved the product formula for relative entropy, and Rényi [7] used it as first axiom for characterizing relative entropy:
Proposition 2.
(Product invariance of entropy ratio)
for all probability measures on Ω and each positive integer
Proof.
It is custom to also consider infinite product measures on the space of all sequences over the alphabet [3,11]. The basic sets in X are the cylinder sets
for words in For each level we can consider the partition of X into the cylinder sets of all words of length These partitions form a nested sequence: each refines Proposition 2 implies
Proposition 3.
(Entropy ratio on infinite products) The measures on the infinite product space X have the same entropy ratio with respect to all partitions
It should be noted that, even in the entropy ratio can change if we use other partitions. It is not allowed to split partition sets into small pieces where is large, and leaves the cylinder sets big where is small. This is known from everyday news: if there are ten reports from districts with more infections than average, and only one report from a district below average, we shall overestimate the danger.
There are various ways to realize infinite product measures in the plane. THe construction of self-similar measures by iterated function systems is a standard method which includes the decimal and the binary number system and can generate fancy fractals [14,15]. The above proposition says that under certain self-similarity assumptions, the entropy ratio of two measures in the plane will be the same for a sequence of nested partitions.
We do not pretend that a division into states and districts, together with the Covid-19 infection distribution, will fulfil any self-similarity conditions. However, it is natural to expect that the entropy ratios for two nested partitions coincide – in situations where the measure is fractal and the subdivision of the sets of the first partition has nothing to do with the measures This is a kind of null hypothesis which says that P and Q show the same amount of statistical variation on different levels. In reality, there are deviations from the hypothesis, as discussed in Section 6, Section 7 and Section 8.
5. Entropy Ratios for Processes and Fractal Measures
To show connections with theory, in this section we consider random processes as in Shannon’s work [3]. Let and Subsequently, is the space of 01-sequences, and models sequences of flips of a fair coin. This is the standard uniform distribution: each cylinder set of level k has measure The denominator in the entropy ratio then equals for the partition of X into cylinder sets of level for any probability measure on In particular, when is a product measure itself, then, for the partition , we have , which is with base 2 logarithms, a well-known fact. The limit of for is called entropy rate [3,11]. For finite alphabets, we have
Proposition 4.
(Entropy rate from entropy ratios) Let Q be the equidistribution on a finite alphabet Ω and a probability measure on Subsequently, the entropy ratios on are the entropies per letter in words of length They converge to the entropy rate of
Incidentally, in the first version of this paper, we suggested to take the entropy as denominator in order to standardize the relative entropy When all partition sets have the same Q-measure, then the quantity agrees with Unfortunately, this does not hold in applications: adminstrative districts differ a lot in population size. Therefore, was replaced by
Using the correspondence between 01-sequences and binary numbers , the space with its uniform distribution can be represented as the unit interval with the ordinary length measure. The cylinder sets correspond to intervals The product measure corresponds to a fractal measure with dense support in This correspondence is one-to-one, except for a countable set, which has measure zero. We shall see now that the entropy rate of coincides with the Hausdorff dimension of the measure
The entropy dimension of a finite measure on was defined by Rényi [6] as
where denotes the partition of into d-dimensional dyadic cubes of side length Here, we have Obviously, Rényi had in mind the connection between dyadic cubes and 01-words. In 1982, Young proved that the entropy dimension and Hausdorff dimension of a measure coincide if the measure is homogeneous in the sense that pointwise dimension is the same almost everywhere [8] (Section 4). Without going into further detail (see [15] for Hausdorff and pointwise dimension), we just note that on the unit cube, where the volume measure is a probability, the term behind the limit is the entropy ratio Thus
Proposition 5.
(Entropy ratios approximate fractal dimension)
Let μ be a probability measure on which fulfils the homogeneity condition of [8]. Let λ denote the volume measure and the partition of the unit cube into dyadic cubes of side length Subsequently, the entropy ratios on these partitions converge to the Hausdorff dimension of
It should be added that a quotient of logarithms, like U, is the typical form of a fractal dimension [15]. Great effort was invested in proving the existence of entropy rates and dimension limits [11,15]. Our point here is that, in real-world situations, limits are hard to determine, but the first terms of the sequence have a descriptive power and can be calculated.
Young’s homogeneity condition is fulfilled for the product measures and for the Markov chains that we consider now. We assume that is generated by a Markov chain, which does not permit the word 11. The transition probabilities are and The stationary distribution is given as and On the interval, the corresponding measure lives on those binary numbers that have no two consecutive digits 1. They form a Cantor set Here, denote the subsets of A that consist of binary numbers with first digit 0 and 1, respectively. They fulfil the equations
where and assign to the values and respectively.
The similarity maps and have factors and respectively. Accordingly, the Hausdorff dimension of can be determined from the equation [14,15]. We get where is the golden mean. For every t between 0 and 1, is a measure on A, which has dimension smaller than or equal to
The measure has maximal dimension when or In this case is the normalized Hausdorff measure on This is the uniform distribution on so it seems clear that it has the smallest distance to the uniform distribution on which is, minimal concentration In this case, all of the cylinder sets have measure for some and entropy ratios can be expressed with Fibonacci numbers as For any Markov chain, we can easily determine entropy ratios by matrix calculation, however. Table 3 shows how the concentration values approach their limit. The first step away from the uniform distribution is decisive, and the convergence slows down after the second step.
It seems interesting to determine similar distances between empirical distributions and model distributions, taking, for instance, time series of order patterns derived from high-frequency biomedical measurements, as in [16].
6. The Global Covid-19 Pandemic
We study Covid data for two reasons. On the one hand, even though they are given only on two levels, they give a good testbed, since they are determined every day. We can determine time series of concentration coefficients, and their graphs give much more information than the tables in Section 3. On the other hand, we provide a little tool for the investigation of previous waves of infection which perhaps can help to prevent the next one. We refrain from evaluating countries or political measures. That would require much more care, including study of social and economic aspects.
The numbers of positively tested cases and deaths are taken as seven-day sums per 100,000 inhabitants of the region. The data come from the database of Johns Hopkins University [17]. Weekly averages smooth out random variations of the daily numbers as well as systematic variations caused by weekends where administrations have no office hours. Sums are taken instead of averages, since seven days is the typical period for which an infected person remains infectious [18]. Thus, the sum over one week is a measure of the infection potential or Covid activity in a region. Such sums have become the basis of government decisions in Germany [19], and a main criterion for defining hotspots of the pandemic in the USA [20]. The seven-day sums are updated every day, which results in a daily time series for each country and province. See [17,21] for more details.
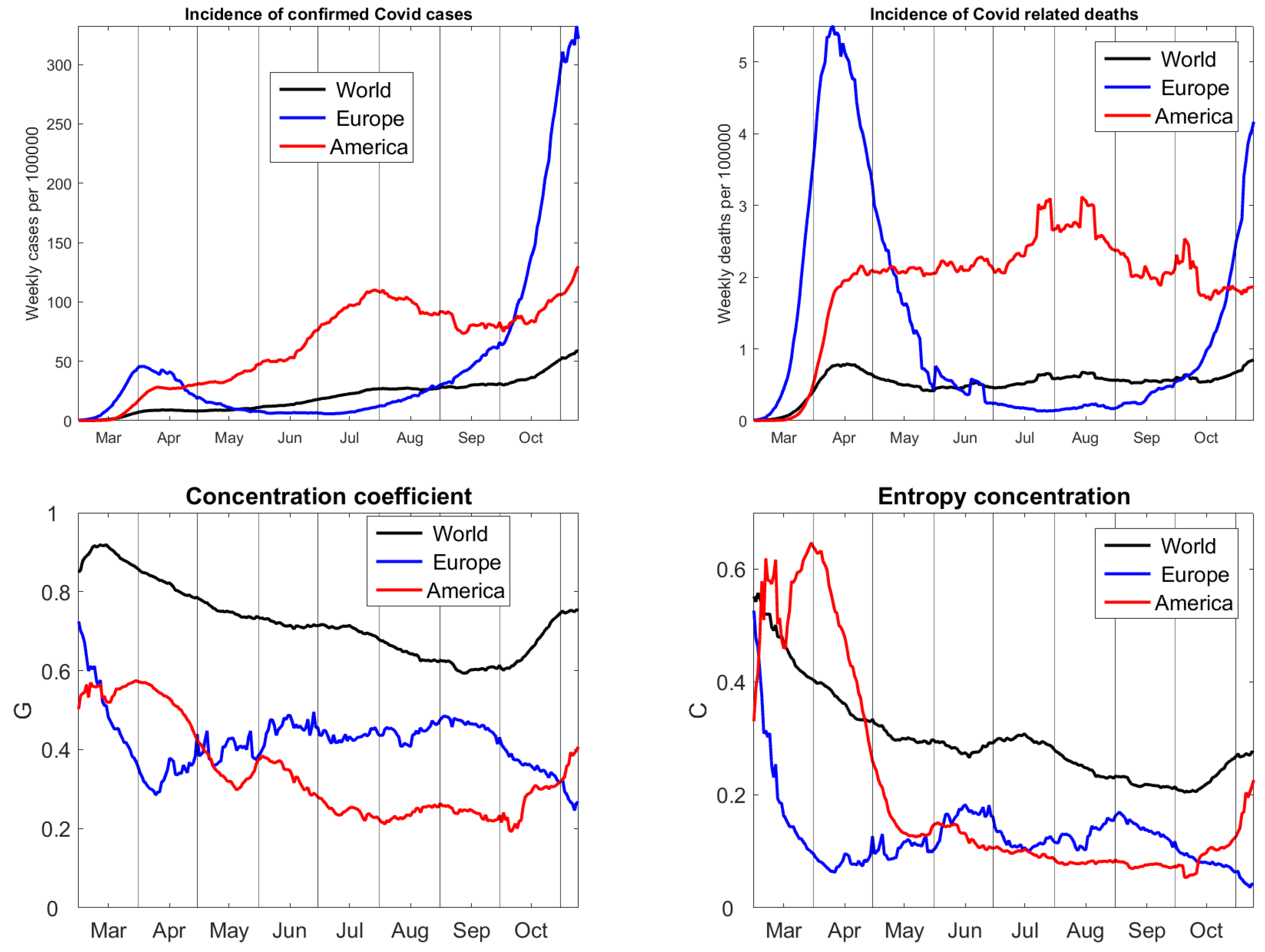
Figure 2 shows a global view, summarizing the values of 55 large countries, including 23 from Europe, three from North, and six from South America. The number of cases on the whole world is continuously increasing, with slow growth in August and September. The worldwide number of deaths remained almost constant at about six Covid-related deaths per one million people and week. In Europe, there was a wave of infections in March and April, and, now, there is a much larger second wave of cases. The first wave came with large numbers of deaths which lasted only for few weeks. The death rate of the second wave is now twice as large as in America. The number of cases in America increased from March to July, declined in August and is rising again. The number of deaths in America remained on a level four times as large as the world’s average for a long time, higher in July and August, and lower in October. The two rectangular peaks come from irregularities in the data, when a statistical office reported one thousand more deaths on a single day which they did not count before. We did not smooth the data. Because we take seven-day sums, irregularities of a day remain in the time series for 13 days. As a matter of fact, errors, like negative daily numbers of deaths, appear quite frequently in Europe (for instance, France, Spain, Germany) and in the USA, but not in Brazil or Iran.
Time series of concentration coefficients were calculated for cases only. For deaths, they look similar, but more distorted due to the irregularities in the data. Gini’s G and our C show a similar time course. The pandemic becomes increasingly spread over the world, but the concentration increased since October because of the second wave in Europe. In Europe, raise of concentration from April to June indicated desrease of cases in various countries, while the second wave now hits all of Europe, causing uniform distribution of infections. In America, the situation has been constant for several months, but since October the concentration rises, probably due to an improvement in Brazil and Peru and increase of cases in Argentina and the US.
At second glance, we recognize the sample size bias of The worldwide concentration is large because of Asian countries, like China, Vietnam, and Thailand, which have almost no cases. However, it is not as large as indicated by The difference between Gini concentration levels of America and Europe is too large and seems to be caused by the fact that we had 23 countries from Europe and only nine from America. The American values have less variation, when compared with the world and Europe. Therefore, the initial concentration of the pandemic in the north-east of the US in March/April is underestimated. For entropy concentration, the variation is larger and the initial concentration in New York is more correct. For the world, the initial maximum concentration (without counting Wuhan) was rather in the beginning of March, as shown by than in the middle of March, as indicated by Altogether, entropy concentration gives a more correct description than Gini’s coefficient. However, the values of C are considerably smaller than those of
7. States and Counties in the USA
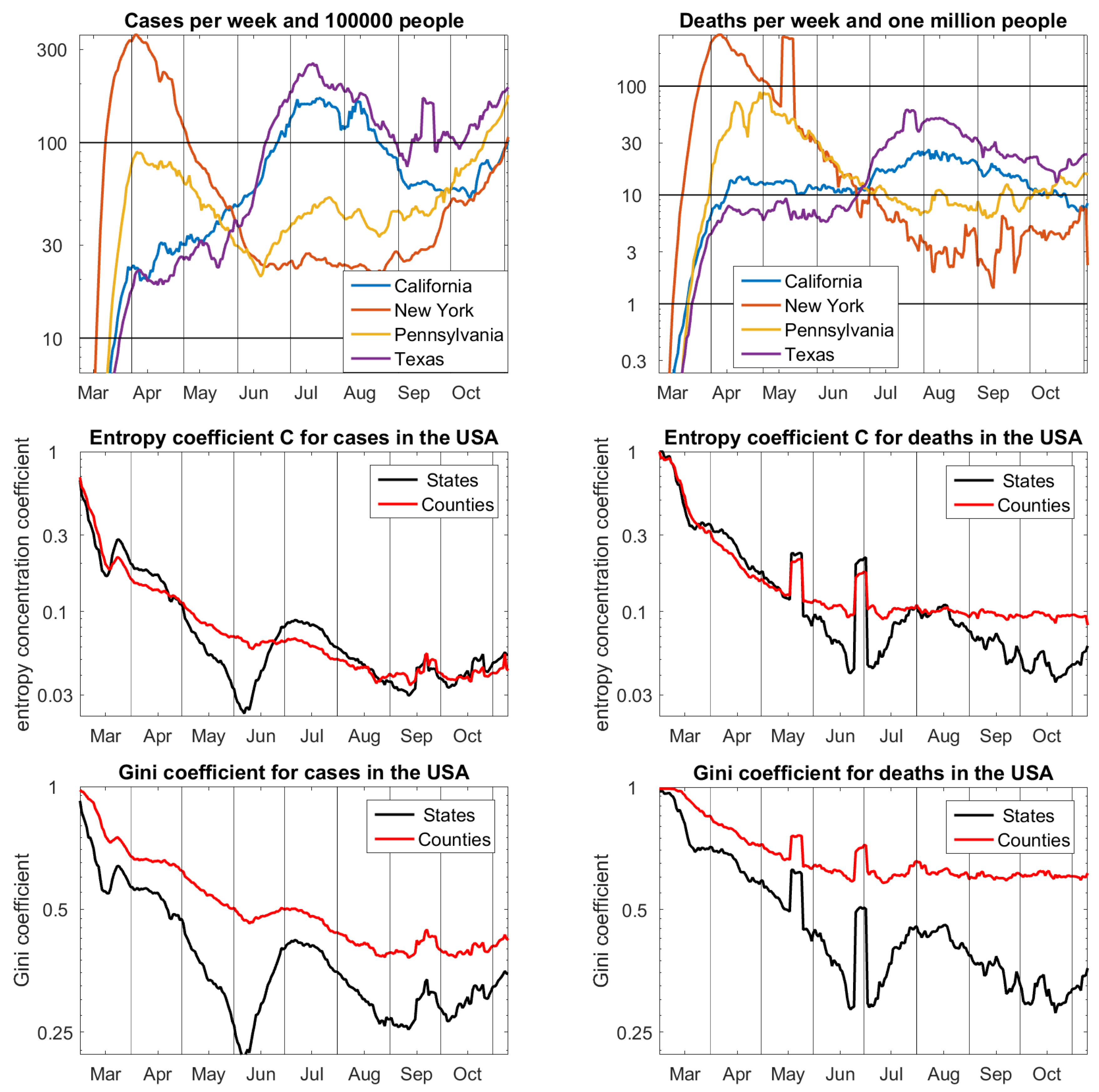
The most comprehensive public dataset of the pandemic, maintained by the Johns Hopkins University, contains case and death numbers of 3143 counties of the 51 federal states of the USA. For Figure 3, we have chosen four states that represent the time development. New York suffered a lot in the beginning of the pandemic and has now shown the smallest numbers of cases for some months. Pennsylvania had a similar development, less dramatic in the beginning, and with more recent infections. In California and Texas, the peak of the pandemic came in summer. Curiously, all four, and a number iof other states, had approximately the same number of cases in the beginning of June, and the same number of deaths in the end of June. This is reflected by the concentration coefficients.
In March, the pandemic first concentrated near Seattle and then in New York and the northeast of the US, which results in concentration values that are near one. For this reason, C and G are shown by logarithmic scale on and respectively. With this modification, it is surprising how similar C and G are as functions of time. Once again, it becomes apparent how much G is pushed by sample size. The picture of C with values of the same magnitude for states and counties seems to be correct. The concentration values for deaths in counties look almost constant since June. They are greater than corresponding values of states and greater than values for cases. Different conditions of cities and countryside could be a reason. Among others, large intensive care units are usually in cities. The two peaks in the concentration functions for deaths come from data irregularities in New York and New Jersey, respectively. Because these were spread over various counties in one state, they disturb the function of states more than the function of counties.
8. States and Districts in Germany
We use the case-related public file RKI COVID19 [22] of Robert Koch Institut, the health authority in charge of epidemic. These data allow for determining accurate case fatality rates, the distribution of daily cases in 16 federal states and 412 districts, and their joint distribution with six age classes.
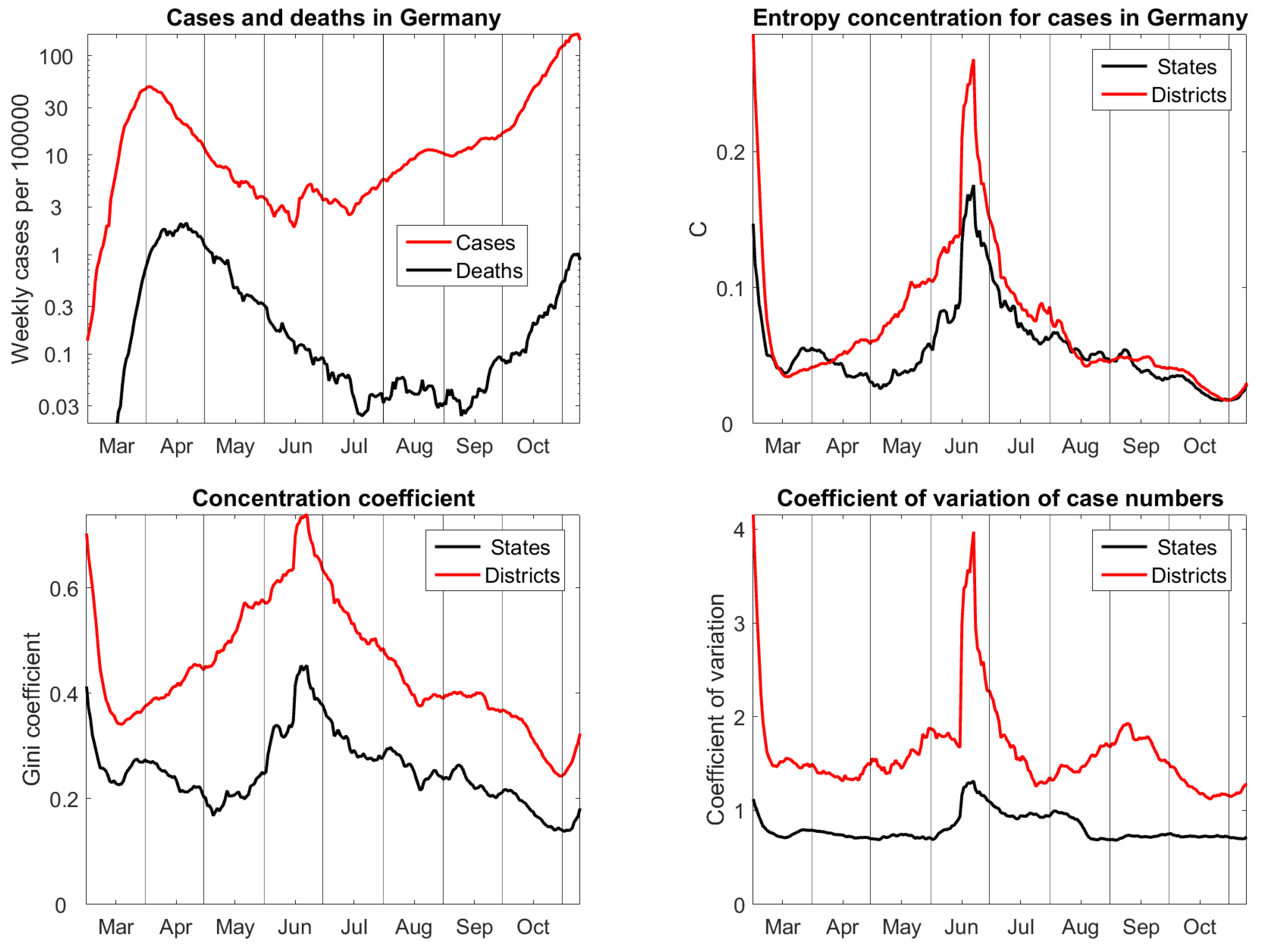
Figure 4 shows the cases and deaths on a logarithmic scale. Germany is one of the European countries with mild impact of the first Covid-19 wave. The case fatality rate was about 5% in April and then decreased tremendously, below 0.5%. In June, the cases reached a minimum. Just at this time, there was a big outbreak in the main meat enterprise, which caused the big peak in concentration functions. Since July, cases have been continuously rising, and deaths followed since September.
The entropy concentration coefficients for states and districts do almost coincide since July, and they show a continuous approach to uniform distribution, with exception of the very last week. However, in spring, the concentration of districts was higher than concentration of states. This is true, because many districts with small population density recovered very fast from the first wave, so that for several weeks there were between 100 and 200 districts each day without cases. On state level, the differences were smaller. The outbreak in the meat factory appeared in the federal state with the largest population, but in a district of average size that explains why the peak is so much bigger for districts than for states.
Gini coefficients show similar features as the entropy concentration coefficients but their bias on sample size is obvious. In the search for concentration measures we also calculated standard deviations of case numbers or probabilities with respect to the weights They gave no reasonable result, no matter whether we took ordinary or logarithmic scale. The only variant worth mentioning is given by coefficients of variation of the case numbers (for the the parameter is the same). That is, the standard deviation divided by mean. Figure 4 shows that they admit no natural scale and have a bias. Actually they do not show much change in time, except for the meat factory outbreak. The parameter C clearly performs the best, and our null hypothesis of equal concentration for the two partitions is confirmed by the remarkable coincidence of the two time series.
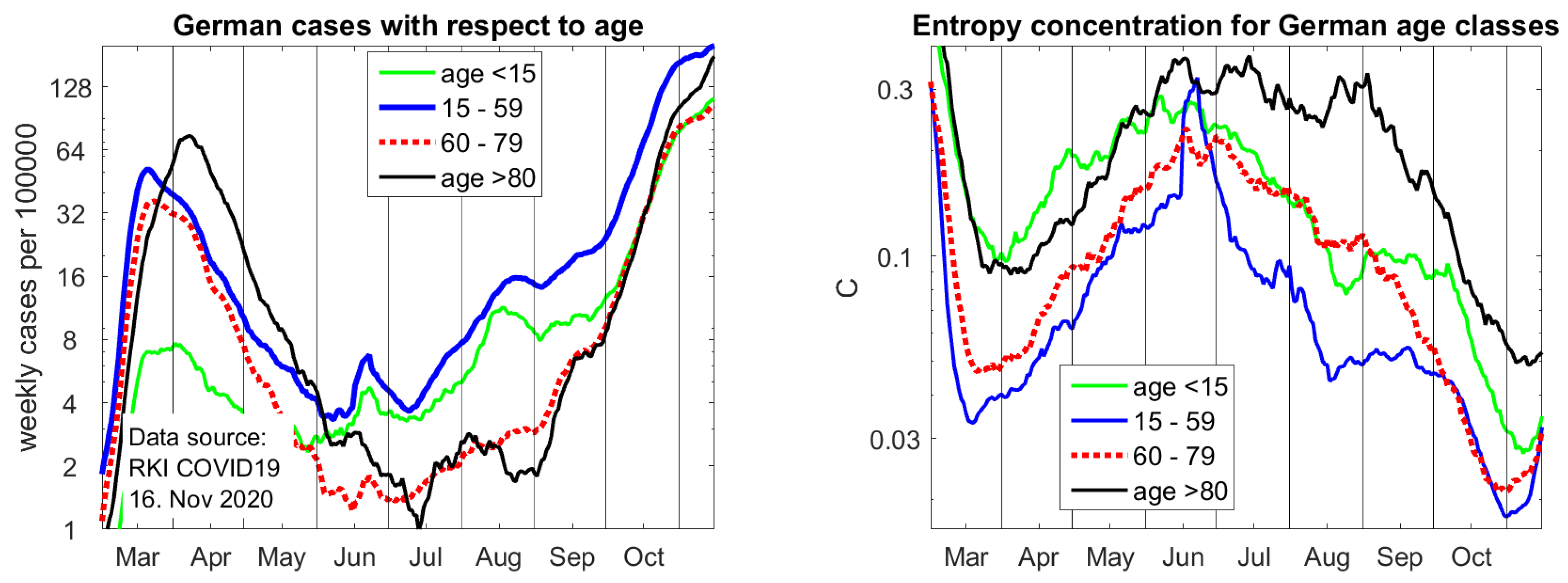
Because Covid deaths are the most frequent among old people, it is very important to study the age dependence of cases, as shown on the left of Figure 5. There are four age classes: children below 15, the working population in the age of 15 up to 59, the elderly with 60 to 79 years, who have case fatality rate of about 2%, and the very vulnerable group of age 80 and above, who now have a case fatality of about 12% (in spring, fatality rates were much higher since even among old people, only cases with serious symptoms were tested). The last group, represented by nearly six-million inhabitants of Germany, needs the most protection.
Until August, the seven-day incidence of people above 80 was very low, only 2 per 100,000. In September, the number raised to eight and, on November 10, it is 138. Simple calculation shows that this is more or less the number of deaths in this group, which we can expect all over Germany two weeks later. Approximately 60% of all Covid deaths come from this age class. So it is possible to predict deaths in Germany two weeks in advance. It should be noted that the rise of infections of old people is not due to their careless behavior or lack of protection. More likely, the number of infections have risen in all age classes, but younger people do not easily get tested anymore.
For our study, it is interesting to consider the concentration functions C in different age classes. We use the districts that give more information. It can be seen that cases in the group of working age 15–59 are most uniformly spread, certainly due to their mobility. The outbreak in the meat factory is almost restricted to this group. The infections in the group of children and the group of elderly above 80 were more concentrated in certain districts. However, with the progress of the second wave, they have also become uniformly spread. While local action was perhaps still good in September, it is quite reasonable that a partial lockdown for all Germany took effect on November 2. There is an upwards trend in the most recent concentration coefficients, which indicates that, like in March, districts with a small population density are already improving. However, incidences are still growing.
9. Conclusions
We intended to describe the spread of the Covid-19 pandemic, given by daily numbers of confirmed cases and deaths in various regions. The question is how uniform the distribution of infections is with respect to the distribution of population. The Kullback–Leibler distance can be applied, but it is biased by sample size and has an unbounded scale. The well-established Gini coefficient can be used and it has a unit scale, but it is strongly influenced by sample size. It was not designed for data sampled in many regions and districts. When countries are compared by Gini coefficients, with respect to the inequality of income say, then a smooth income distribution is calculated for every country. The Covid data structure of cases and deaths reflects the spatial distribution of infections, which is more fragmented. Many variables can be sampled in this way: air and water pollution, precipitation, wealth, crime, etc.
An entropy concentration coefficient C was introduced. It has the same scale and basic properties as the Gini coefficient and it seems to be much less dependent on sample size. The new coefficient is a multiplicative version of the Kullback–Leibler divergence and can be interpreted as distance of a probability measure P from a uniform distribution. When the uniform distribution is volume in Euclidean space, and P is homogeneous, then U approximates the Hausdorff dimension of When the uniform distribution is the product measure of an equidistribution on a finite alphabet, then is connected with the entropy rate. In the setting of random processes and empirical distributions of long time series, we anticipate applications of
We analysed data of the global pandemic, of counties in the US and of districts in Germany. The concentration coefficient C as a function of time becomes small when infections become widespread. Its growth can indicate improvement, sometimes earlier than the decline of cases. Large values of C also appear in the initial stage of an epidemic, and for big local outbreaks. In Germany, age groups—in particular, the vulnerable group of elderly above 80—develop differently with respect to concentration. A referee suggested that cross-correlation between countries and age classes could be further studied by forecasting and backcasting analysis, while using detrended cross-correlation coefficients, as in [23]. All in all, the entropy concentration coefficient is an interesting new parameter.
Funding
This research received no external funding.
Acknowledgments
The author is grateful to all three referees for their constructive criticism of the first version of the paper. He thanks Mariano Matilla for the invitation to join the special issue on Information theory and Symbolic Analysis, and Bernd Pompe for a number of helpful discussions.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. The Gini Coefficient
Definition of Given the in (1), we renumber the n items in such a way that For an epidemic, this means ordering subregions by increasing incidence. To save notation, we assume the renumbering has already been done. Now, take the cumulative probabilities and for Let and note that The polygonal line which connects the successive points in the -plane is called Lorenz curve. Due to the assumption of increasing quotients, the Lorenz curve runs below the line The Gini coefficient G is twice the area between Lorenz curve and line For details, see any statistics textbook for economists or [1].
Now, we show that the Gini coefficient increases when the partition determining the is refined. It is enough to prove this for a basic step of refinement, where one partition set is subdivided into two. It would be interesting to modify the geometric proof so that under stochastic model assumptions the increase can be quantified. The area described below can easily be calculated.
Proposition A1.
(Gini coefficient increases under refinement)
Let G be the Gini coefficient for probabilities with for Now suppose that one pair of probabilties is splitted: and Then the new Gini coefficient is larger than except for the case where
Proof.
We can assume For the Lorenz curve connecting the points defined above, we add one more vertex with and When then is on the Lorenz curve and Otherwise, is below the Lorenz curve, and connecting the points with increasing the area between the new Lorenz curve and the line is enlarged by the triangle with vertices and
However, in that case, we have to reorder the points, which will lead to even more enlargement. To save notation, we only consider one step of reordering. We assume that so that and must interchange order. In that case the point A of the Lorenz curve is replaced by and the parallelogram with vertices will be added to the area between Lorenz curve and line
When has to be arranged still further down, then more of these parallelograms will be added. The same holds for ordering above Those parallelograms are constructed with vector instead of The more and differ, the more parallelograms have to be added in order to obtain from □
References
- Wikipedia. Gini Coefficient. Available online: https://en.wikipedia.org/wiki/Gini_coefficient (accessed on 6 October 2020).
- Brown, M. Using Gini-Style indices to evaluate the spatial patterns of health practitioners. Soc. Sci. Med. 1994, 38, 1243–1256. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef] [Green Version]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Hart, P.E. Entropy and other measures of concentration. J. R. Stat. Soc. Ser. 1971, 134, 73–85. [Google Scholar] [CrossRef]
- Rényi, A. Dimension, entropy and information. In Transactions of the second Prague Conference on Information Theory, Statistical Decision Functions, Random Processes; Czech Academy of Sciences: Prague, Czech Republic, 1957; pp. 545–556. [Google Scholar]
- Rényi, A. Wahrscheinlichkeitsrechnung mit einem Anhang über Informationstheorie; VEB Deutscher Verlag der Wissenschaften: Berlin, Germany, 1962; English translation: Probability Theory, North Holland, The Netherlands, 1970. [Google Scholar]
- Young, L.S. Dimension, entropy and Lyapunov exponents. Ergod. Theory Dyn. Syst. 1982, 2, 109–124. [Google Scholar] [CrossRef] [Green Version]
- Müller, I.; Weiss, W. Entropy and Energy; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Ferguson, N.M.; Laydon, D.; Nedjati-Gilani, G.; Imai, N.; Ainslie, K.; Baguelin, M.; Bhatia, S.; Boonyasiri, A.; Cucunuba, P.Z.; Cuomo-Dannenburg, G.; et al. Impact of non-pharmaceutical interventions (NPIs) to reduce COVID-19 mortality and healthcare demand. Imp. Coll. Lond. 2020. [Google Scholar] [CrossRef]
- Gray, R.M. Entropy and Information Theory; Springer: Berlin/Heidelberg, Germany, 1990. [Google Scholar]
- United Nations, Department of Economic and Social Affairs, Population Division. World Population Prospects, Standard Projections. Available online: https://population.un.org/wpp/Download/Standard/Population/ (accessed on 30 October 2020).
- The World Bank. World Bank Open Data, Gross Domestic Product. Available online: https://data.worldbank.org/indicator/NY.GDP.MKTP.CD (accessed on 30 October 2020).
- Barnsley, M.F. Fractals Everywhere, 2nd ed.; Academic Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Falconer, K.J. Fractal Geometry: Mathematical Foundations and Applications, 3rd ed.; J. Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Bandt, C. A new kind of permutation entropy used to classify sleep stages from invisible EEG microstructure. Entropy 2017, 19, 197. [Google Scholar] [CrossRef] [Green Version]
- Johns Hopkins University. Coronavirus COVID-19 Global Cases by the Center for Systems Science and Engineering. Available online: https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html;https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series (accessed on 10 November 2020).
- World Health Organization. Criteria for Releasing COVID-19 Patients from Isolation. Available online: https://www.who.int/news-room/commentaries/detail/criteria-for-releasing-covid-19-patients-from-isolation (accessed on 6 November 2020).
- Robert Koch Institut. Daily Situation Reports. Available online: https://www.rki.de/EN/Home/homepage_node.html (accessed on 10 November 2020).
- Oster, A.M.; Kang, G.J.; Cha, A.E.; Beresovsky, V.; Rose, C.E.; Rainisch, G.; Porter, L.; Valverde, E.E.; Peterson, E.B.; Driscoll, A.K.; et al. Trends in Number and Distribution of COVID-19 Hotspot Counties in the United States, March 8 to July 15, 2020. In Morbidity and Mortality Weekly Reports; Centers for Disease Control and Prevention: Atlanta, GA, USA, 21 August 2020; p. 69. [Google Scholar]
- Roser, M.; Ritchie, H.; Ortiz-Ospina, E.; Hasell, J. Coronavirus Pandemic (Covid-19). Available online: https://ourworldindata.org/coronavirus (accessed on 10 November 2020).
- Robert Koch Institut. RKI COVID19 Database. Available online: https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/dd4580c810204019a7b8eb3e0b329dd6_0 (accessed on 10 November 2020).
- Contreras-Reyes, J.E.; Idrovo-Aguirre, B.J. Backcasting and forecasting time series using detrended cross-correlation analysis. Phys. A 2020, 560, 125109. [Google Scholar] [CrossRef]
Figure 1.
Gini coefficient and entropy concentration coefficient as functions of for fixed values of Left: Right:
Figure 1.
Gini coefficient and entropy concentration coefficient as functions of for fixed values of Left: Right:
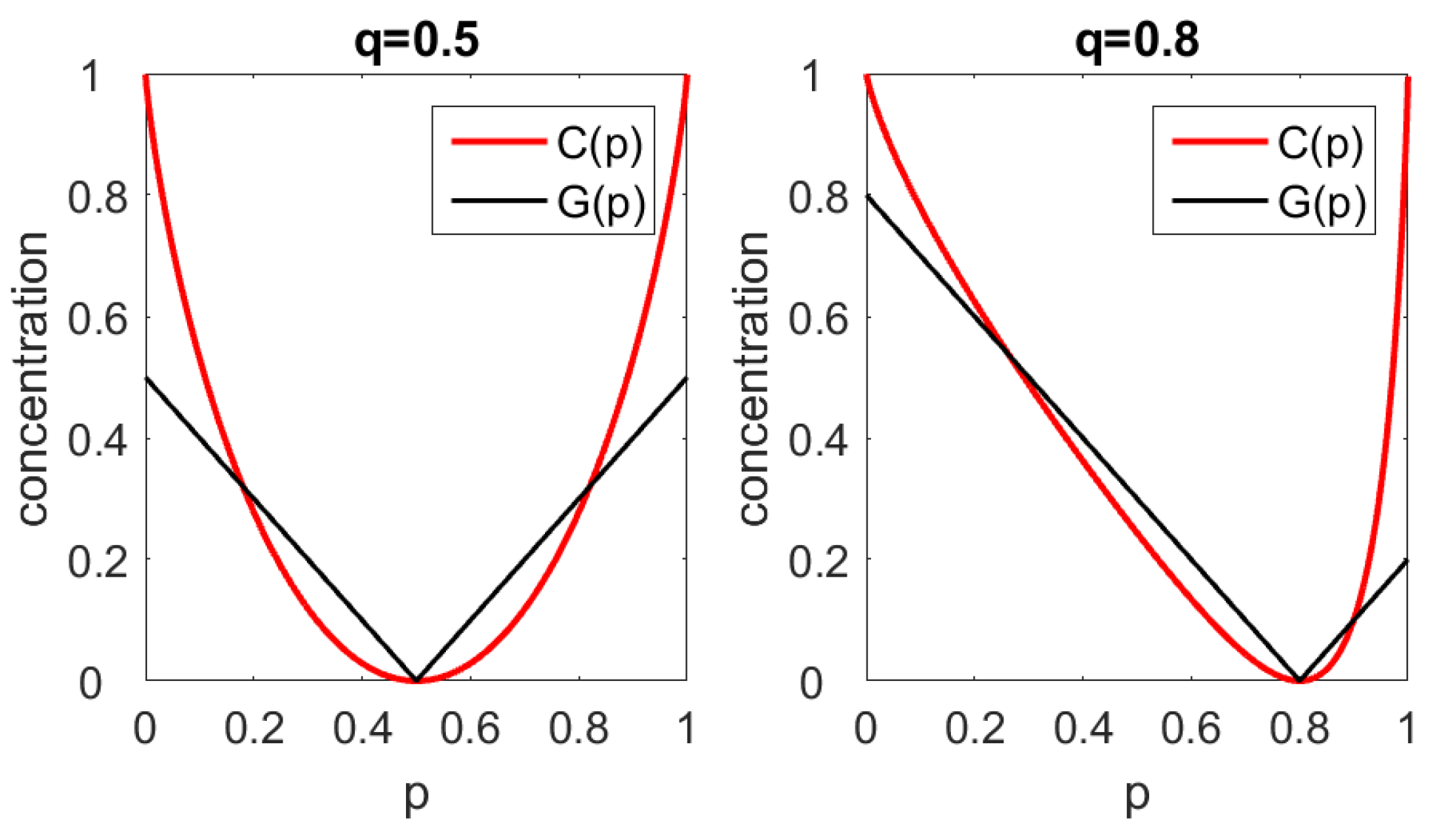
Figure 2.
Time series of the pandemic. The upper row describes the intensity of the pandemic, with cases on the left and deaths on the right. The lower row specifies the non-uniformity of the distribution of cases, with Gini coefficients on the left and entropy concentration coefficients on the right. Data from Johns Hopkins University [17], updated 10 November 2020.
Figure 2.
Time series of the pandemic. The upper row describes the intensity of the pandemic, with cases on the left and deaths on the right. The lower row specifies the non-uniformity of the distribution of cases, with Gini coefficients on the left and entropy concentration coefficients on the right. Data from Johns Hopkins University [17], updated 10 November 2020.

Figure 3.
Upper row: cases and deaths for four representative states of the USA. Middle row: entropy concentration coefficients for the partitions into 51 states and 3143 counties on logarithmic scale. Lower row: Gini coefficients are very similar, but larger and not adapted to sample size. Data from Johns Hopkins University [17], 10 November 2020.
Figure 3.
Upper row: cases and deaths for four representative states of the USA. Middle row: entropy concentration coefficients for the partitions into 51 states and 3143 counties on logarithmic scale. Lower row: Gini coefficients are very similar, but larger and not adapted to sample size. Data from Johns Hopkins University [17], 10 November 2020.

Figure 4.
Upper left: cases and deaths in Germany. Upper right: entropy concentration coefficients for the 16 federal states and 412 districts. Lower row: Gini coefficient and coefficient of variation are biased by sample size. Data from Robert Koch Institut [22], updated 10 Nov 2020.
Figure 4.
Upper left: cases and deaths in Germany. Upper right: entropy concentration coefficients for the 16 federal states and 412 districts. Lower row: Gini coefficient and coefficient of variation are biased by sample size. Data from Robert Koch Institut [22], updated 10 Nov 2020.

Figure 5.
Left: case incidence with respect to age. Right: entropy concentration coefficients of cases for age groups. These figures were updated in proof on 16 November since the most recent concentration coefficients already indicate improvement in part of the country while case incidences are still rising.
Figure 5.
Left: case incidence with respect to age. Right: entropy concentration coefficients of cases for age groups. These figures were updated in proof on 16 November since the most recent concentration coefficients already indicate improvement in part of the country while case incidences are still rising.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Concentration of population in German states and districts.
| Parameter | Germany | without Berlin | East with Berlin | East without Berlin |
|---|---|---|---|---|
| D for states | 0.260 | 0.184 | 0.618 | 0.089 |
| D for districts | 0.650 | 0.580 | 0.971 | 0.469 |
| G for states | 0.336 | 0.309 | 0.390 | 0.227 |
| G for districts | 0.528 | 0.509 | 0.539 | 0.414 |
| C for states | 0.098 | 0.073 | 0.262 | 0.054 |
| C for districts | 0.101 | 0.092 | 0.183 | 0.101 |
Table 2.
Concentration of gross domestic product in countries and regions.
| Parameter | World | Asia | Africa | Europe | America | without US, Ca |
|---|---|---|---|---|---|---|
| number of regions/countries | 19/159 | 5/47 | 5/49 | 4/35 | 4/25 | 3/23 |
| G for regions | 0.575 | 0.379 | 0.291 | 0.282 | 0.441 | 0.012 |
| G for countries | 0.621 | 0.496 | 0.412 | 0.340 | 0.471 | 0.190 |
| C for regions | 0.218 | 0.210 | 0.092 | 0.102 | 0.382 | 0.0004 |
| C for countries | 0.182 | 0.177 | 0.088 | 0.067 | 0.269 | 0.034 |
Table 3.
Concentration of Markov Fibonacci measure on words of length k.
| k | 1 | 2 | 3 | 4 | 5 | 6 | ∞ |
|---|---|---|---|---|---|---|---|
| 0.0406 | 0.2382 | 0.2588 | 0.2671 | 0.2739 | 0.2783 | 0.30576 | |
| 0.1977 | 0.0206 | 0.0083 | 0.0068 | 0.0044 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bandt, C. Entropy Ratio and Entropy Concentration Coefficient, with Application to the COVID-19 Pandemic. Entropy 2020, 22, 1315. https://doi.org/10.3390/e22111315
AMA Style
Bandt C. Entropy Ratio and Entropy Concentration Coefficient, with Application to the COVID-19 Pandemic. Entropy. 2020; 22(11):1315. https://doi.org/10.3390/e22111315
Chicago/Turabian StyleBandt, Christoph. 2020. "Entropy Ratio and Entropy Concentration Coefficient, with Application to the COVID-19 Pandemic" Entropy 22, no. 11: 1315. https://doi.org/10.3390/e22111315
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.