Heterogeneous Graphical Granger Causality by Minimum Message Length



Abstract
1. Introduction
- (1)
- We used the minimum message length (MML) principle for determination of causal connections in the heterogeneous graphical Granger model.
- (2)
- Based on the dispersion coefficient of the target time series and on the initial maximum likelihood estimates of the regression coefficients, we proposed a minimum message length criterion to select the subset of causally connected time series with each target time series; Furthermore, we derived its form for various exponential distributions.
- (3)
- We found this subset in two ways: by a proposed genetic-type algorithm (HMMLGA), as well as by exhaustive search (exHMML). We evaluated the complexities of these algorithms and provided the code in Matlab.
- (4)
- We demonstrated the superiority of both methods with respect to the comparison methods Lingam [6], HGGM [1] and statistical framework Granger causality (SFGC) [7] in the synthetic experiments with short time series. In the real data experiments without known ground truth, the interpretation of causal connections achieved by HMMLGA was the most realistic with respect to the comparison methods.
- (5)
- To our best knowledge, this is the first work applying the minimum message length principle to the heterogeneous graphical Granger model.
2. Preliminaries
2.1. Graphical Granger Model
2.2. Heterogeneous Graphical Granger Model
2.3. Granger Causality and Graphical Granger Models
2.4. Minimum Message Length Principle
3. Method
3.1. Heterogeneous Graphical Granger Model with Fixed Design Matrix
3.2. Minimum Message Length Criterion for Heterogeneous Graphical Granger Model
- (i)
- the causal graph of the heterogeneous graphical Granger problem (8) can be inferred from the solutions of p variable selection problems, where for each , the set of Granger–causal variables to is found;
- (ii)
- For the estimated set holdswhere andis the minimum message length code of set . It can be expressed aswhere , is the unity matrix of size , , is the log-likelihood function depending on the density function of and matrix is a diagonal matrix depending on link function .
3.3. Log-Likelihood , Matrix and Dispersion for with Various Exponential Distributions
3.4. Variable Selection by MML in Heterogeneous Graphical Granger Model
| Algorithm 1 MML Code for |
|
3.5. Search Algorithms
| Algorithm 2 HMMLGA |
|
Computational Complexity of HMMLGA and of exHMML
4. Related Work
5. Experiments
5.1. Implementation and Parameter Setting
5.2. Synthetically Generated Processes
5.2.1. Causal Networks with 5 and 8 Time Series
5.2.2. Performance of exHMML and MMLGA
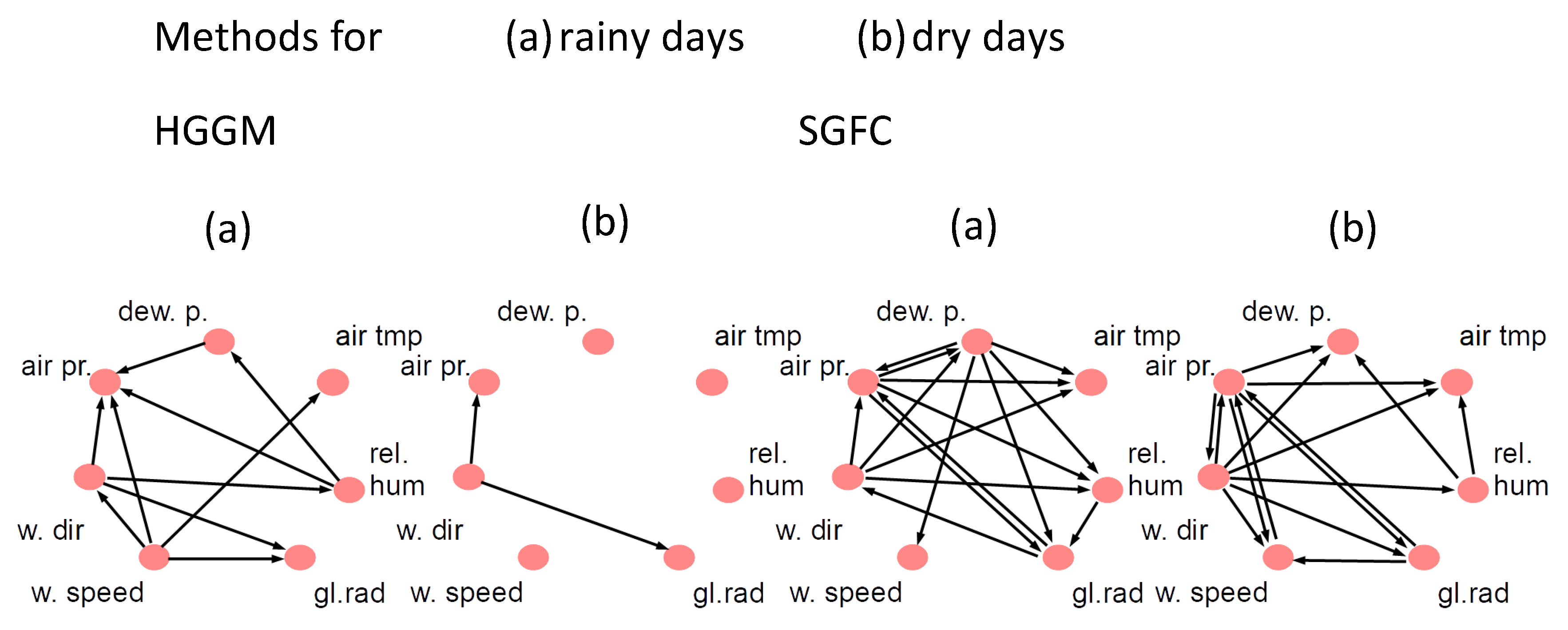
5.3. Climatological Data
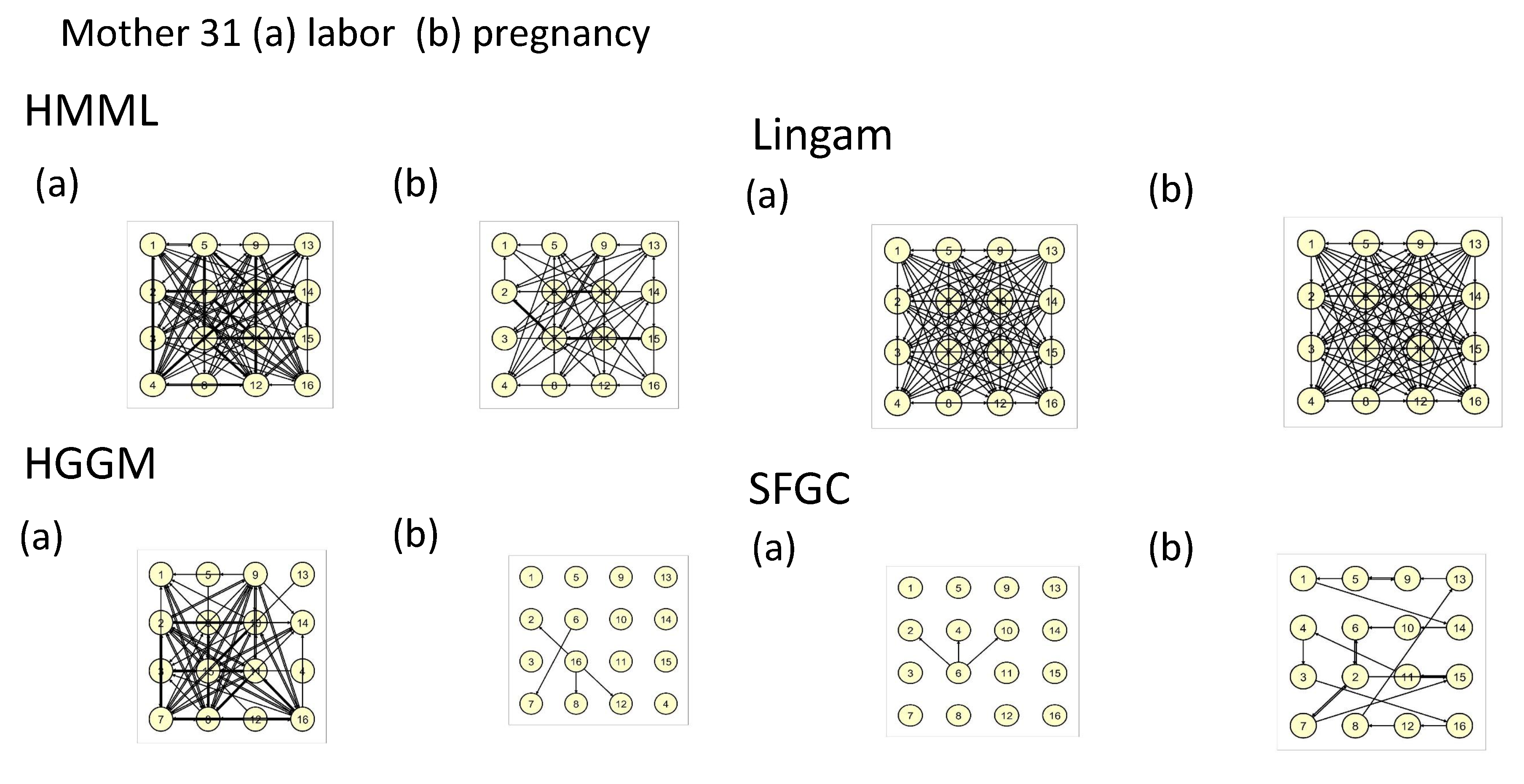
5.4. Electrohysterogram Time Series
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Derivation of the MML Criterion for HGGM
Appendix B. Derivation of Li, Wi, ϕi for Various Exponential Distributions of x i
References
- Behzadi, S.; Hlaváčková-Schindler, K.; Plant, C. Granger Causality for Heterogeneous Processes. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Zou, H. The adaptive lasso and its oracle property. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Hryniewicz, O.; Kaczmarek, K. Forecasting short time series with the bayesian autoregression and the soft computing prior information. In Strengthening Links Between Data Analysis and Soft Computing; Springer: Cham, Switzerland, 2015; pp. 79–86. [Google Scholar]
- Bréhélin, L. A Bayesian approach for the clustering of short time series. Rev. D’Intell. Artif. 2006, 20, 697–716. [Google Scholar] [CrossRef]
- Wallace, C.S.; Boulton, D.M. An information measure for classification. Comput. J. 1968, 11, 185–194. [Google Scholar] [CrossRef]
- Shimizu, S.; Inazumi, T.; Sogawa, Y.; Hyvärinen, A.; Kawahara, Y.; Washio, T.; Hoyer, P.O.; Bollen, K. DirectLiNGAM: A direct method for learning a linear non-Gaussian structural equation model. J. Mach. Learn. Res. 2011, 12, 1225–1248. [Google Scholar]
- Kim, S.; Putrino, D.; Ghosh, S.; Brown, E.N. A Granger causality measure for point process models of ensemble neural spiking activity. PLoS Comput. Biol. 2011, 7, e1001110. [Google Scholar] [CrossRef]
- Arnold, A.; Liu, Y.; Abe, N. Temporal causal modeling with graphical Granger methods. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 66–75. [Google Scholar]
- Shojaie, A.; Michailidis, G. Discovering graphical Granger causality using the truncating lasso penalty. Bioinformatics 2010, 26, i517–i523. [Google Scholar] [CrossRef]
- Lozano, A.C.; Abe, N.; Liu, Y.; Rosset, S. Grouped graphical Granger modeling methods for temporal causal modeling. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 577–586. [Google Scholar]
- Nelder, J.; Wedderburn, R. Generalized Linear Models. J. R. Stat. Soc. Ser. A (General) 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Hlaváčková-Schindler, K.; Plant, C. Poisson Graphical Granger Causality by Minimum Message Length. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases 2020 (ECML/PKDD), Ghent, Belgium, 14–18 September 2020. [Google Scholar]
- Granger, C.W. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Mannino, M.; Bressler, S.L. Foundational perspectives on causality in large-scale brain networks. Phys. Life Rev. 2015, 15, 107–123. [Google Scholar] [CrossRef]
- Maziarz, M. A review of the Granger-causality fallacy. J. Philos. Econ. Reflect. Econ. Soc. Issues 2015, 8, 86–105. [Google Scholar]
- Granger, C.W. Some recent development in a concept of causality. J. Econom. 1988, 39, 199–211. [Google Scholar] [CrossRef]
- Lindquist, M.A.; Sobel, M.E. Graphical models, potential outcomes and causal inference: Comment on Ramsey, Spirtes and Glymour. NeuroImage 2011, 57, 334–336. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Spirtes, P.; Glymour, C.N.; Scheines, R.; Heckerman, D. Causation, Prediction, and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Glymour, C. Counterfactuals, graphical causal models and potential outcomes: Response to Lindquist and Sobel. NeuroImage 2013, 76, 450–451. [Google Scholar] [CrossRef] [PubMed]
- Marinescu, I.E.; Lawlor, P.N.; Kording, K.P. Quasi-experimental causality in neuroscience and behavioural research. Nat. Hum. Behav. 2018, 2, 891–898. [Google Scholar] [CrossRef] [PubMed]
- Wallace, C.S.; Freeman, P.R. Estimation and inference by compact coding. J. R. Stat. Soc. Ser. B 1987, 49, 240–252. [Google Scholar] [CrossRef]
- Wallace, C.S.; Dowe, D.L. Minimum message length and Kolmogorov complexity. Comput. J. 1999, 42, 270–283. [Google Scholar] [CrossRef]
- Schmidt, D.F.; Makalic, E. Minimum message length ridge regression for generalized linear models. In Australasian Joint Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2013; pp. 408–420. [Google Scholar]
- Segerstedt, B. On ordinary ridge regression in generalized linear models. Commun. Stat. Theory Methods 1992, 21, 2227–2246. [Google Scholar] [CrossRef]
- Computational Complexity of Mathmatical Operations. Available online: https://en.wikipedia.org/wiki/Computational_complexity_of_mathematical_operations (accessed on 2 October 2020).
- Rissanen, J. Stochastic Complexity in Statistical Inquiry; World Scientific: Singapore, 1989; Volume 15, p. 188. [Google Scholar]
- Barron, A.; Rissanen, J.; Yu, B. The minimum description length principle in coding and modeling. IEEE Trans. Inf. Theory 1998, 44, 2743–2760. [Google Scholar] [CrossRef]
- Hansen, M.; Yu, B. Model selection and minimum description length principle. J. Am. Stat. Assoc. 2001, 96, 746–774. [Google Scholar] [CrossRef]
- Hansen, M.H.; Yu, B. Minimum description length model selection criteria for generalized linear models. Lect. Notes Monogr. Ser. 2003, 40, 145–163. [Google Scholar]
- Marx, A.; Vreeken, J. Telling cause from effect using MDL-based local and global regression. In Proceedings of the 2017 IEEE International Conference on Data Mining, New Orleans, LA, USA, 18–21 November 2017; pp. 307–316. [Google Scholar]
- Marx, A.; Vreeken, J. Causal inference on multivariate and mixed-type data. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Volume 2018, pp. 655–671. [Google Scholar]
- Budhathoki, K.; Vreeken, J. Origo: Causal inference by compression. Knowl. Inf. Syst. 2018, 56, 285–307. [Google Scholar] [CrossRef]
- Hlaváčková-Schindler, K.; Plant, C. Graphical Granger causality by information-theoretic criteria. In Proceedings of the European Conference on Artificial Intelligence 2020 (ECAI), Santiago de Compostela, Spain, 29 August–2 September 2020; pp. 1459–1466. [Google Scholar]
- McIlhagga, W.H. Penalized: A MATLAB toolbox for fitting generalized linear models with penalties. J. Stat. Softw. 2016, 72. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T.; Tibshirani, R. On the “degrees of freedom” of the lasso. Ann. Stat. 2007, 35, 2173–2192. [Google Scholar] [CrossRef]
- Available online: https://meteo.boku.ac.at/wetter/mon-archiv/2020/202009/202009.html (accessed on 5 September 2020).
- Zentralanstalt für Meteorologie und Geodynamik 1190 Vienna, Hohe Warte 38. Available online: https://www.zamg.ac.at/cms/de/aktuell (accessed on 5 September 2020).
- Alexandersson, A.; Steingrimsdottir, T.; Terrien, J.; Marque, C.; Karlsson, B. The Icelandic 16-electrode electrohysterogram database. Nat. Sci. Data 2015, 2, 1–9. [Google Scholar] [CrossRef]
- Available online: https://www.physionet.org (accessed on 5 September 2020).
- Mikkelsen, E.; Johansen, P.; Fuglsang-Frederiksen, A.; Uldbjerg, N. Electrohysterography of labor contractions: Propagation velocity and direction. Acta Obstet. Gynecol. Scand. 2013, 92, 1070–1078. [Google Scholar] [CrossRef]
- Agresti, A. Categorical Data Analysis; Section 12.3.3.; John Wiley and Sons: Hoboken, NJ, USA, 2003; Volume 482. [Google Scholar]
- Huber, P.J. The behavior of maximum likelihood estimates under nonstandard conditions. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 221–233. [Google Scholar]





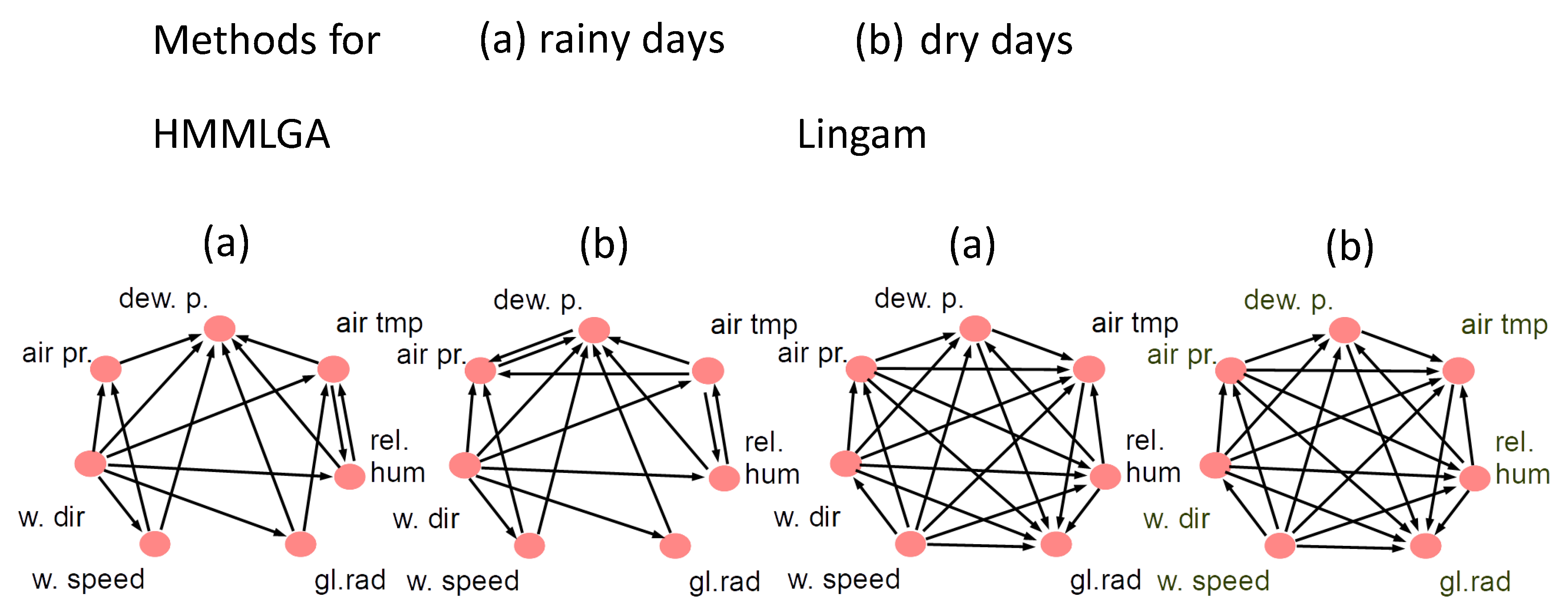{kind=link}
{kind=link}
{kind=link}
{kind=link}
| dense g. 18, | 100 | 300 | 500 | 1000; | sparse g. 8, | 100 | 300 | 500 | 1000 |
| exHMML | 0.69 | 0.83 | 0.82 | 0.88 | exHMML | 0.70 | 0.72 | 0.72 | 0.67 |
| HMMLGA | 0.73 | 0.90 | 0.89 | 0.90 | HMMLGA | 0.73 | 0.76 | 0.74 | 0.67 |
| HGGM | 0.5 | 0.48 | 0.54 | 0.52 | HGGM | 0.52 | 0.36 | 0.66 | 0.36 |
| LINGAM | 0.57 | 0.58 | 0.62 | 0.58 | LINGAM | 0.58 | 0.54 | 0.69 | 0.45 |
| SFGC | 0.33 | 0.26 | 0.26 | 0.33 | SFGC | 0.14 | 0.35 | 0.44 | 0.31 |
| dense g. 18, | 100 | 300 | 500 | 1000; | sparse g. 8, | 100 | 300 | 500 | 1000 |
| exHMML | 0.71 | 0.73 | 0.83 | 0.83 | exHMML | 0.67 | 0.80 | 0.80 | 0.68 |
| HMMLGA | 0.82 | 0.79 | 0.87 | 0.92 | HMMLGA | 0.67 | 0.73 | 0.77 | 0.70 |
| HGGM | 0.44 | 0.37 | 0.40 | 0.39 | HGGM | 0.53 | 0.47 | 0.65 | 0.36 |
| LINGAM | 0.71 | 0.58 | 0.58 | 0.65 | LINGAM | 0.33 | 0.52 | 0.74 | 0.46 |
| SFGC | 0.43 | 0.55 | 0.42 | 0.63 | SFGC | 0.35 | 0.59 | 0.42 | 0.38 |
| dense g. 52, | 100 | 300 | 500 | 1000; | sparse g. 15, | 100 | 300 | 500 | 1000 |
| exHMML | 0.68 | 0.78 | 0.79 | 0.82 | exHMML | 0.69 | 0.73 | 0.77 | 0.64 |
| HMMLGA | 0.84 | 0.67 | 0.66 | 0.87 | HMMLGA | 0.57 | 0.69 | 0.7 | 0.56 |
| HGGM | 0.16 | 0.17 | 0.17 | 0.17 | HGGM | 0.2 | 0.09 | 0.18 | 0.17 |
| LINGAM | 0.62 | 0.54 | 0.51 | 0.55 | LINGAM | 0.28 | 0.33 | 0.4 | 0.19 |
| SFGC | 0.32 | 0.21 | 0.35 | 0.20 | SFGC | 0.3 | 0.24 | 0.22 | 0.19 |
| dense g. 52, | 100 | 300 | 500 | 1000; | sparse g. 15, | 100 | 300 | 500 | 1000 |
| exHMML | 0.59 | 0.64 | 0.56 | 0.75 | exHMML | 0.58 | 0.84 | 0.80 | 0.69 |
| HGGMGA | 0.77 | 0.72 | 0.63 | 0.79 | HMMLGA | 0.42 | 0.69 | 0.70 | 0.56 |
| HGGM | 0.16 | 0.16 | 0.18 | 0.17 | HGGM | 0.17 | 0.10 | 0.18 | 0.19 |
| LINGAM | 0.62 | 0.54 | 0.51 | 0.55 | LINGAM | 0.27 | 0.33 | 0.40 | 0.18 |
| SFGC | 0.36 | 0.45 | 0.82 | 0.83 | SFGC | 0.29 | 0.29 | 0.24 | 0.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hlaváčková-Schindler, K.; Plant, C. Heterogeneous Graphical Granger Causality by Minimum Message Length. Entropy 2020, 22, 1400. https://doi.org/10.3390/e22121400
Hlaváčková-Schindler K, Plant C. Heterogeneous Graphical Granger Causality by Minimum Message Length. Entropy. 2020; 22(12):1400. https://doi.org/10.3390/e22121400
Chicago/Turabian StyleHlaváčková-Schindler, Kateřina, and Claudia Plant. 2020. "Heterogeneous Graphical Granger Causality by Minimum Message Length" Entropy 22, no. 12: 1400. https://doi.org/10.3390/e22121400
APA StyleHlaváčková-Schindler, K., & Plant, C. (2020). Heterogeneous Graphical Granger Causality by Minimum Message Length. Entropy, 22(12), 1400. https://doi.org/10.3390/e22121400