1. Introduction
Following the early use of Shannon’s [
1] entropy (
HS) by some theoretical ecologists during the 1950s [
2,
3,
4],
HS has been extensively used in community ecology to quantify species diversity. Ecologists have considered the relative abundance or probability of the
ith symbol in a message or sequence of
N different symbols whose meaning is irrelevant [
1,
5,
6] as the relative abundance or probability of the ith species in a community or assemblage of
S different species whose phylogeny is irrelevant (i.e., all species are considered taxonomically equally distinct) [
4,
7,
8]. This use of
HS implies that the concept of species diversity is directly related to the concept of information entropy, basically representing the amount of information or uncertainty in a probability distribution defined for a set of
N possible symbols [
1] or a set of
S possible species [
4].
HS takes values from 0 to log
2 N or log
2 S and is properly expressed in bits, but it can also be expressed in nats or dits (also called bans, decits, or
Hartleys) if the natural logarithm or the decimal logarithm is calculated [
1,
4,
5,
6,
7,
8].
In recent decades, several ecologists have, however, claimed that
HS is a unsatisfactory diversity index because species diversity actually takes values from 1 to
S and is ideally expressed in units of species (i.e., in the same units as
S). Keeping this perspective in mind, and only considering the number of different symbols as the number of different species and the relative abundances of symbols as the relative abundances of species, Hill [
9] proposed the exponential form of Shannon’s [
1] entropy (
HS) and the exponential form of Rényi’s [
10] second-order entropy (
HR) = the reciprocal of Simpson’s [
11] concentration statistic (
λ) as better alternatives to quantify species diversity, thereby assuming that the amount of information or uncertainty in a probability distribution defined for a set of
S possible species was mathematically equivalent to the logarithm of its related species diversity. Similarly, we can assume that the amount of information or uncertainty (expressed in bits) in a probability distribution defined for a set of
N possible symbols is mathematically equivalent to the binary logarithm of its related symbol diversity. Additionally, we can assume that symbol dominance characterizes the extent of relative abundance inequality among different symbols, particularly between dominant and subordinate symbols, and that symbol diversity equals the number of different symbols (
N) or maximum expected diversity in any given message with equiprobability.
On the basis of these working assumptions, I first use the Lorenz curve [
12] as the key framework to assess symbol dominance, symbol diversity, and information entropy. The contrast between symbol dominance and symbol redundancy is also highlighted. Subsequently, novel measures of symbol dominance (
dC1 and
dC2), symbol diversity (
DC1 and
DC2), and information entropy (
HC1 and
HC2) are derived from Lorenz-consistent statistics that I had previously proposed to quantify dominance and diversity in community ecology [
13,
14,
15,
16,
17] and landscape ecology [
18]. Finally, Lorenz-consistent statistics (
dC1,
dC2,
DC1,
DC2,
HC1, and
HC2) are compared with
HS-based and
HR-based statistics (
dS,
dR,
DS,
DR,
HS, and
HR) to show that the former have better mathematical behavior than the latter when measuring symbol dominance, symbol diversity, and information entropy in hypothetical messages. In this regard, I recently found that the corresponding versions of
dC1,
dC2,
DC1, and
DC2 exhibited better mathematical behavior than the corresponding versions of
dS,
dR,
DS, and
DR when measuring land cover dominance and diversity in hypothetical landscapes [
18]. This better mathematical behavior was inherent to the compatibility of
dC1 and
dC2 with the Lorenz-curve-based graphical representation of land cover dominance [
18].
The Lorenz curve [
12] was introduced in the early twentieth century as a graphical method to assess the inequality in the distribution of income among the individuals of a population. Subsequently, this graphical method and Lorenz-consistent indices of income inequality, such as Gini’s [
19,
20] index and Schutz’s [
21] index, have become popular in the field of econometrics (see reviews in [
22,
23]). More recently, owing to the increasing economic inequality during the present market globalization [
24], some authors have supported the use of Bonferroni’s [
25] curve and Zenga’s [
26] curve and related indices to better assess poverty, as these inequality measures are oversensitive to lower levels of the income distribution [
27,
28,
29]. To me, however, the Lorenz curve represents the best and most logical framework to define satisfactory indices of inequality (dominance) and associated measures of diversity or entropy.
2. Materials and Methods
2.1. Assessing Symbol Dominance, Symbol Diversity, and Information Entropy within the Framework of the Lorenz Curve
In econometrics, the Lorenz curve [
12] is ideally depicted within a unit (1 × 1) square, in which the cumulative proportion of income (the vertical
y-axis) is related to the cumulative proportion of individuals (the horizontal
x-axis), ranked from the person with the lowest income to the person with the highest income. The 45-degree (diagonal) line represents equidistribution or perfect income equality. Income inequality may be quantified as the maximum vertical distance from the Lorenz curve to the 45-degree line of equidistribution if only differences in income between the rich and the poor are of interest (this measure being equivalent to the value of Schutz’s inequality index), or as twice the area between the Lorenz curve and the 45-degree line of equidistribution if differences in income among all of the individuals are of interest (this measure being equivalent to the value of Gini’s inequality index), with both measures exhibiting the same value whenever income inequality occurs only between the rich and the poor (see reviews in [
22,
23]; also see [
18]). Therefore, in any given population with
M individuals, income inequality takes a minimum possible value of 0 when every person has the same income (= total income/
M, including
M = 1) and a maximum possible value of 1 − 1/
M when a single person has all the income and the remaining
M − 1 people have none, as persons with no income can exist in a population.
If we assume that symbol dominance characterizes the extent of relative abundance inequality among different symbols, particularly between dominant and subordinate symbols, then the Lorenz-curve-based graphical representation of symbol dominance is given by the separation of the Lorenz curve from the 45-degree line of equiprobability, in which every symbol i has the same relative abundance (pi = 1/N, with N = the number of different symbols). This separation may be quantified as the maximum vertical distance from the Lorenz curve to the 45-degree line if only differences in relative abundance between dominant and subordinate symbols are of interest, or as twice the area between the Lorenz curve and the 45-degree line if differences in relative abundance among all symbols are of interest, with both measures giving the same value whenever relative abundance inequality occurs only between dominant and subordinate symbols.
In any given message with equiprobability the relative abundance of each different symbol equals 1/
N, meaning a symbol may be objectively regarded as dominant if its probability (
pd) > 1/
N and as subordinate if its probability (
ps) < 1/
N. I had already used an equivalent method to discriminate between dominant and subordinate species [
13,
14,
15,
16,
17] and between dominant and subordinate land cover types [
18]. Thus, symbol dominance takes a minimum possible value of 0 when every different symbol has the same relative abundance (= 1/
N, including
N = 1), and approaches a maximum possible value of 1 – 1/
N when a single symbol has a relative abundance very close to 1 and the remaining
N −1 symbols have minimum relative abundances (>0), as symbols with no abundance or zero probability do not exist in a message.
In addition, if we assume that symbol diversity equals the number of different symbols or maximum expected diversity (N) in any given message with equiprobability (symbol dominance = 0 because pi = 1/N), then symbol diversity in any given message with symbol dominance > 0 must equal the maximum expected diversity minus the impact of symbol dominance on it; that is, symbol diversity = N – (N × symbol dominance) = N (1 – symbol dominance). This Lorenz-consistent measure of symbol diversity is a function of both the number of different symbols and the equal distribution of their relative abundances (i.e., symbol diversity is a probabilistic concept free of semantic attributes), taking values from 1 to N (maximum diversity if pi = 1/N) and being properly expressed in units of symbols. Therefore, symbol diversity/N = 1 – symbol dominance (i.e., symbol dominance triggers the inequality between symbol diversity and its maximum expected value).
It should also be evident that the reciprocal of symbol diversity refers to the concentration of relative abundance in the same symbol, and consequently may be regarded as a Lorenz-consistent measure of symbol redundancy = 1/(N (1 − symbol dominance)). This redundancy measure is a function of both the fewness of different symbols and the unequal distribution of their relative abundances, taking values from 1/N to 1 (maximum redundancy if N = 1). Thus, symbol dominance (relative abundance inequality among different symbols) and symbol redundancy are distinct concepts, although the value of the former affects the value of the latter.
Lastly, if we assume that information entropy is mathematically equivalent to the binary logarithm of its related symbol diversity, then the resulting Lorenz-consistent measure of information entropy = log2 (N (1 − symbol dominance)). This entropy measure takes values from 0 to log2 N (maximum entropy if pi = 1/N) and is properly expressed in bits, quantifying the amount of information or uncertainty in a probability distribution defined for a set of N possible symbols. Obviously, the degree of uncertainty attains a minimum value of 0 as symbol redundancy reaches a maximum value of 1.
2.2. Deriving Measures of Symbol Dominance, Symbol Diversity, and Information Entropy from Lorenz-Consistent Statistics
Following the theoretical approach of assessing symbol dominance, symbol diversity, and information entropy within the framework of the Lorenz curve, novel measures of symbol dominance (
dC1 and
dC2), symbol diversity (
DC1 and
DC2), and information entropy (
HC1 and
HC2) are derived from Lorenz-consistent statistics, which I had previously proposed to quantify species dominance and diversity [
13,
14,
15,
16,
17] and land cover dominance and diversity [
18]. In this derivation the number of different species or land cover types is considered as the number of different symbols, and the probabilities of species or land cover types are considered as the probabilities of symbols:
where
N is the number of different symbols or maximum expected diversity,
pd > 1/
N is the relative abundance of each dominant symbol,
ps < 1/
N is the relative abundance of each subordinate symbol,
pi and
pj are the relative abundances of two different symbols in the same message,
L is the number of dominant symbols,
G is the number of subtractions between the relative abundances of dominant and subordinate symbols, and
K =
N (
N − 1)/2 is the number of subtractions between all pairs of relative symbol abundances.
The dominance statistic
dC1 refers to the average absolute difference between the relative abundances of dominant and subordinate symbols (Equation (1)), with its value being equivalent to the maximum vertical distance from the Lorenz curve to the 45-degree line of equiprobability (see also [
18]). Accordingly, the value of
DC1 equals the number of different symbols minus the impact of symbol dominance (
dC1) on the maximum expected diversity (Equation (2)). The binary logarithm of this subtraction is the associated measure of information entropy (Equation (3)).
Likewise, the dominance statistic
dC2 refers to the average absolute difference between all pairs of relative symbol abundances (Equation (4)), with its value being equivalent to twice the area between the Lorenz curve and the 45-degree line of equiprobability (see also [
18]). Accordingly, the value of
DC2 equals the number of different symbols minus the impact of symbol dominance (
dC2) on the maximum expected diversity (Equation (5)). The binary logarithm of this subtraction is the associated measure of information entropy (Equation (6)).
Despite the above dissimilarities between Lorenz-consistent statistics of symbol dominance, symbol diversity, and information entropy,
dC1 =
dC2 = 0,
DC1 =
DC2 =
N, and
HC1 =
HC2 = log
2 N if there is equiprobability (
pi = 1/
N, including
N = 1); and
dC1 =
dC2 > 0,
DC1 =
DC2 <
N, and
HC1 =
HC2 < log
2 N whenever relative abundance inequality occurs only between dominant and subordinate symbols. In this regard, it is worth noting that
dC1 is comparable to Schutz’s [
21] index of income inequality (also known as the Pietra ratio or Robin Hood index) and
dC2 is comparable to Gini’s [
19,
20] index of income inequality. In fact, Gini’s index and Schutz’s index take the same value whenever income inequality occurs only between the rich and the poor (see reviews in [
22,
23]; also see [
18]). However, there is a particular difference between the measurement of symbol dominance (
dC1 and
dC2) and the measurement of income inequality (Schutz’s index and Gini’s index): income inequality can reach a maximum value of 1 − 1/
M when a single person has all the income and the remaining
M – 1 people have none (as individuals with no income are considered to measure income inequality), but symbol dominance can only approach a maximum value of 1 – 1/
N when a single symbol has a relative abundance very close to 1 and the remaining
N – 1 symbols have minimum relative abundances (as symbols with no abundance or zero probability cannot be considered to measure symbol dominance).
Additionally, because the reciprocal of symbol diversity refers to the concentration of relative abundance in the same symbol (as already explained in
Section 2.1), two Lorenz-consistent statistics of symbol redundancy are
RC1 = 1/
DC1 and
RC2 = 1/
DC2.
RC1 and
RC2 take values from 1/
N to 1 (maximum redundancy if
N = 1), and therefore their mathematical behavior can considerably differ from the mathematical behavior of Gatlin’s [
30] classical redundancy index (
RG = 1 –
HS/log
2 N). Indeed, since
RG takes a maximum value of 1 if
N = 1 and a minimum value of 0 if
pi = 1/
N [
30],
RG should be regarded as a combination of redundancy and dominance (see also [
15]).
2.3. Comparing Lorenz-Consistent Statistics with HS-Based and HR-Based Statistics
Lorenz-consistent statistics of symbol dominance (
dC1 and
dC2), symbol diversity (
DC1 and
DC2), and information entropy (
HC1 and
HC2) are compared with statistics based on Shannon’s [
1] entropy (
HS) and Rényi’s [
10] second-order entropy (
HR). More specifically, on the basis of Hill’s [
9] proposals for measuring diversity and Camargo’s [
17] proposals for measuring dominance, the
HS-based and
HR-based statistics are:
where
pi is the relative abundance or probability of the
ith symbol in a message or sequence of
N different symbols.
Although
dC1 =
dC2 =
dS =
dR = 0,
DC1 =
DC2 =
DS =
DR =
N, and
HC1 =
HC2 =
HS =
HR = log
2 N whenever there is equiprobability, differences in mathematical behavior between Lorenz-consistent statistics and
HS-based and
HR-based statistics were examined by computing all these statistics for the ten probability distributions (I–X) described as hypothetical messages in
Table 1. As we can see, the hypothetical message V is the primary or starting distribution, having two different symbols with probabilities of 0.6 and 0.4. From distribution V to I, the probabilities of all different symbols are successively halved by doubling their number, with the whole relative abundance of dominant symbols that must be transferred to subordinate symbols to achieve equiprobability remaining steady (= 0.1). From distribution V to X, only the probabilities of subordinate symbols are successively halved by doubling their number, with the whole relative abundance of dominant symbols that must be transferred to subordinate symbols to achieve equiprobability approaching the probability of the single dominant symbol (= 0.6). Accordingly, the degree of dominance in each dominant symbol is given by the positive deviation of its probability (
pd) from the expected equiprobable value of 1/
N, while the degree of subordination in each subordinate symbol is given by the positive deviation of its probability (
ps) from 1/
N. Thus, in each probability distribution or hypothetical message, symbol dominance = symbol subordination = the average absolute difference between the relative abundances of dominant and subordinate symbols (Equation (1)) = the whole relative abundance of dominant symbols that must be transferred to subordinate symbols to achieve equiprobability (
Ptransfer values in
Table 1).
In addition, disparities in mathematical behavior between Lorenz-consistent statistics and
HS-based and
HR-based statistics were examined by computing all these statistics for the ten probability distributions (XI–XX) described as hypothetical messages in
Table 2, where differences in relative abundance or probability occur not only between dominant and subordinate symbols (as in
Table 1), but also among dominant symbols and among subordinate symbols. However, because the
Ptransfer value equals 0.25 in all hypothetical messages, only changes in the allocation of relative abundance between dominant and subordinate symbols (but not among dominant symbols or among subordinate symbols) seem to be of real significance for probability distributions to achieve the reference distribution (involving equiprobability) or to deviate from it. The reasons for this are evident: in the case of a dominant symbol increasing its relative abundance at the expense of other dominant symbols (
Table 2, relative abundances
p1–
p5 in probability distributions XVI–XIX), the resulting proportional abundance of all the dominant symbols is the same as before the transfer, since the increase in the probability of a dominant symbol (becoming more dominant) is compensated by an equivalent decrease in the probability of other dominant symbols (becoming less dominant); similarly, in the case of a subordinate symbol increasing its relative abundance at the expense of other subordinate symbols (
Table 2, relative abundances
p6–
p10 in probability distributions XII–XV), the resulting proportional abundance of all the subordinate symbols is the same as before the transfer, since the increase in the probability of a subordinate symbol (becoming less subordinate) is compensated by an equivalent decrease in the probability of other subordinate symbols (becoming more subordinate or rare).
Probability distributions in
Table 1 and
Table 2 were selected to better assess differences in mathematical behavior between Lorenz-consistent statistics (Camargo’s indices) and
HS-based and
HR-based statistics. Otherwise, when using probability distributions that were chosen at random, we could obtain results that do not allow us to appreciate significant differences between the respective mathematical behaviors.
3. Results and Discussion
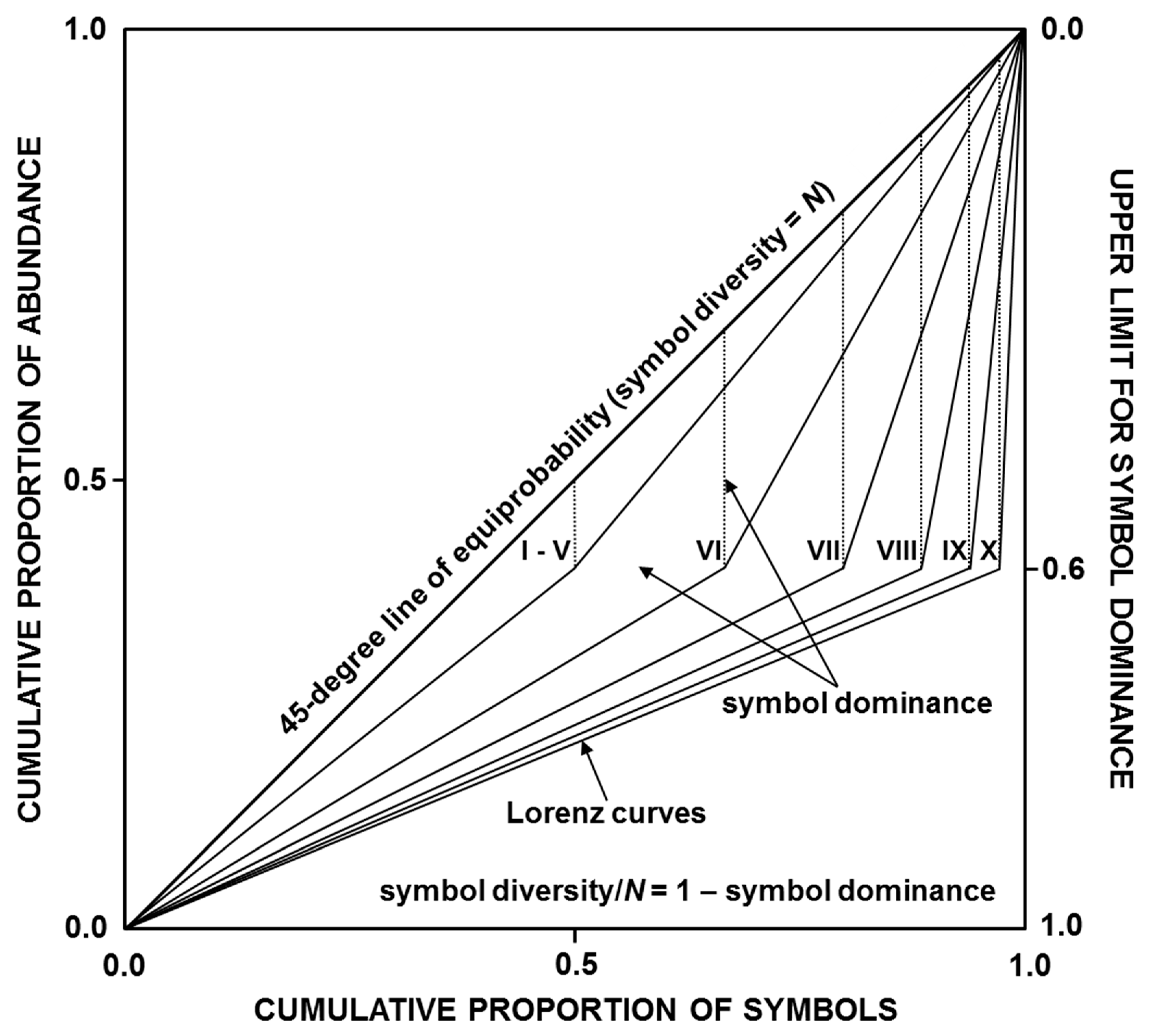
The Lorenz-curve-based graphical representation of symbol dominance (relative abundance inequality among different symbols) is shown in
Figure 1. Estimated values of symbol dominance are 0.1 (I–V, with five Lorenz curves perfectly superimposed), 0.267 (VI), 0.4 (VII), 0.489 (VIII), 0.541 (IX), and 0.57 (X), with all these dominance values being equivalent to the respective Ptransfer values in
Table 1. Additionally, estimated values of symbol diversity are 28.8 (I), 14.4 (II), 7.2 (III), 3.6 (IV), 1.8 (V), 2.199 (VI), 3.0 (VII), 4.599 (VIII), 7.803 (IX), and 14.19 (X) symbols, and estimated values of information entropy are 4.848 (I), 3.848 (II), 2.848 (III), 1.848 (IV), 0.848 (V), 1.137 (VI), 1.585 (VII), 2.202 (VIII), 2.964 (IX), and 3.827 (X) bits.
Differences in mathematical behavior between Lorenz-consistent statistics (
dC1,
dC2,
DC1,
DC2,
HC1, and
HC2) and
HS-based and
HR-based statistics (
dS,
dR,
DS,
DR,
HS, and
HR) are shown in
Table 3. Because
dC1,
dC2,
DC1,
DC2,
HC1, and
HC2 are Lorenz-consistent, their estimated values match estimated values of symbol dominance, symbol diversity, and information entropy concerning
Figure 1. In fact, estimated values of
dC1 and
dC2 are equivalent to the respective
Ptransfer values in
Table 1. By contrast, estimated values of
dS,
dR,
DS,
DR,
HS, and
HR do not match estimated values of symbol dominance, symbol diversity, and information entropy concerning
Figure 1, while
dS and
dR exhibit values even greater than the upper limit for symbol dominance (= 0.6). Consequently,
DS and
DR can underestimate symbol diversity when differences in relative abundance between dominant and subordinate symbols are large or can overestimate it when such differences are relatively small.
The observed shortcomings in the measurement of symbol dominance (using
dS and
dR) and symbol diversity (using
DS and
DR) seem to be a consequence of the mathematical behavior of the associated entropy measures (
HS and
HR). As we can see in
Table 3, from distribution V to I, where the
Ptransfer value remains relatively small = 0.1 (
Table 1), inequalities between entropy measures result in
HS values >
HR values >
HC1 and
HC2 values. On the contrary, from distribution VII to X, where the
Ptransfer approaches a higher value of 0.6 (
Table 1), inequalities between entropy measures result in
HC1 and
HC2 values >
HS values >
HR values. In fact, whereas the normalized entropies of
HC1 and
HC2 increase from distribution VII to X, the normalized entropies of
HS and
HR decrease markedly.
This remarkable finding would indicate that
HC1 and
HC2 can quantify the amount of information or uncertainty in a probability distribution more efficiently than
HS and
HR, particularly when differences between higher and lower probabilities are maximized by increasing the number of small probabilities (as shown in
Table 3 regarding data in
Table 1). After all, within the context of classical information theory, the information content of a symbol is an increasing function of the reciprocal of its probability [
1,
5,
6,
10] (also see [
31,
32]).
Other relevant disparities in mathematical behavior regarding measures of symbol dominance, symbol diversity, and information entropy are shown in
Table 4. The respective values of
dC1,
DC1, and
HC1 remain identical from distribution XI to XX, since
dC1 is sensitive only to differences in relative abundance between dominant and subordinate symbols. On the other hand, because
dC2 is sensitive to differences in relative abundance among all different symbols, the respective values of
dC2,
DC2, and
HC2 do not remain identical from distribution XI to XX, even though they are equal in XII and XVI, in XIII and XVII, in XIV and XVIII, and in XV and XIX, as in each of these distribution pairs changes in the allocation of relative abundance among dominant symbols and among subordinate symbols are equivalent. A similar pattern of values is observed concerning
dR,
DR, and
HR, but not regarding
dS,
DS, and
HS, whose respective values remain distinct from distribution XI to XX.
4. Concluding Remarks
This theoretical analysis has shown that the Lorenz curve is a proper framework for defining satisfactory measures of symbol dominance, symbol diversity, and information entropy (
Figure 1 and
Table 3 and
Table 4). The value of symbol dominance equals the maximum vertical distance from the Lorenz curve to the 45-degree line of equiprobability when only differences in relative abundance between dominant and subordinate symbols are quantified which is equivalent to the average absolute difference between the relative abundances of dominant and subordinate symbols =
dC1 (Equation (1)) or equals twice the area between the Lorenz curve and the 45-degree line of equiprobability when differences in relative abundance among all symbols are quantified, which is equivalent to the average absolute difference between all pairs of relative symbol abundances =
dC2 (Equation (4)). Symbol diversity =
N (1 – symbol dominance) (i.e.,
DC1 =
N (1 –
dC1) and
DC2 =
N (1 –
dC2)) and information entropy = log
2 symbol diversity (i.e.,
HC1 = log
2 DC1 and
HC2 = log
2 DC2). Additionally, the reciprocal of symbol diversity may be regarded as a satisfactory measure of symbol redundancy (i.e.,
RC1 = 1/
DC1 and
RC2 = 1/
DC2).
This study has also shown that Lorenz-consistent statistics (
dC1,
dC2,
DC1,
DC2,
HC1, and
HC2) have better mathematical behavior than
HS-based and
HR-based statistics (
dS,
dR,
DS,
DR,
HS, and
HR), exhibiting greater coherence and objectivity when measuring symbol dominance, symbol diversity, and information entropy (
Table 3 and
Table 4). However, considering that the 45-degree line of equiprobability (
Figure 1) represents the reference distribution (
pi = 1/
N), and that only changes in the allocation of relative abundance between dominant and subordinate symbols (but not among dominant symbols or among subordinate symbols) seem to have true relevance for probability distributions to achieve the reference distribution or to deviate from it (
Table 2), the use of
dC1,
DC1, and
HC1 may be more practical and preferable than the use of
dC2,
DC2, and
HC2 in measuring symbol dominance, symbol diversity, and information entropy. In this regard, it should be evident that if the number of different symbols (
N) is fixed in any given message, increasing differences in relative abundance between dominant and subordinate symbols necessarily imply decreases in symbol diversity and information entropy, whereas decreasing differences in relative abundance between dominant and subordinate symbols necessarily imply increases in symbol diversity and information entropy, with these two variables taking a maximum if
pi = 1/
N. By contrast, increasing or decreasing differences in relative abundance among dominant symbols or among subordinate symbols will not affect symbol diversity and information entropy, since the decrease or increase in the information content of a dominant or subordinate symbol is compensated by an equivalent increase or decrease in the information content of other dominant or subordinate symbols.


{kind=link}