Enhancing Edge Attack Strategy via an OWA Operator-Based Ensemble Design in Real-World Networks

Abstract
:1. Introduction
2. Evaluating the Performance of Structural Similarity Index Under Edge Attack Strategy
2.1. Weighted-Edge Attacks Model Based on Structural Similarity Index
2.1.1. Weight of Edge
2.1.2. Three Typical Weighted-Edge Attacks Sequences
2.1.3. Evaluation Metrics
2.2. Index Performance Evaluation
Experiment on Different Networks
3. Edge Attack Strategy Based on Ordered Weighted Averaging Operator
3.1. OWA Operator
3.2. Edge Attack Strategy Based on OWA Operator
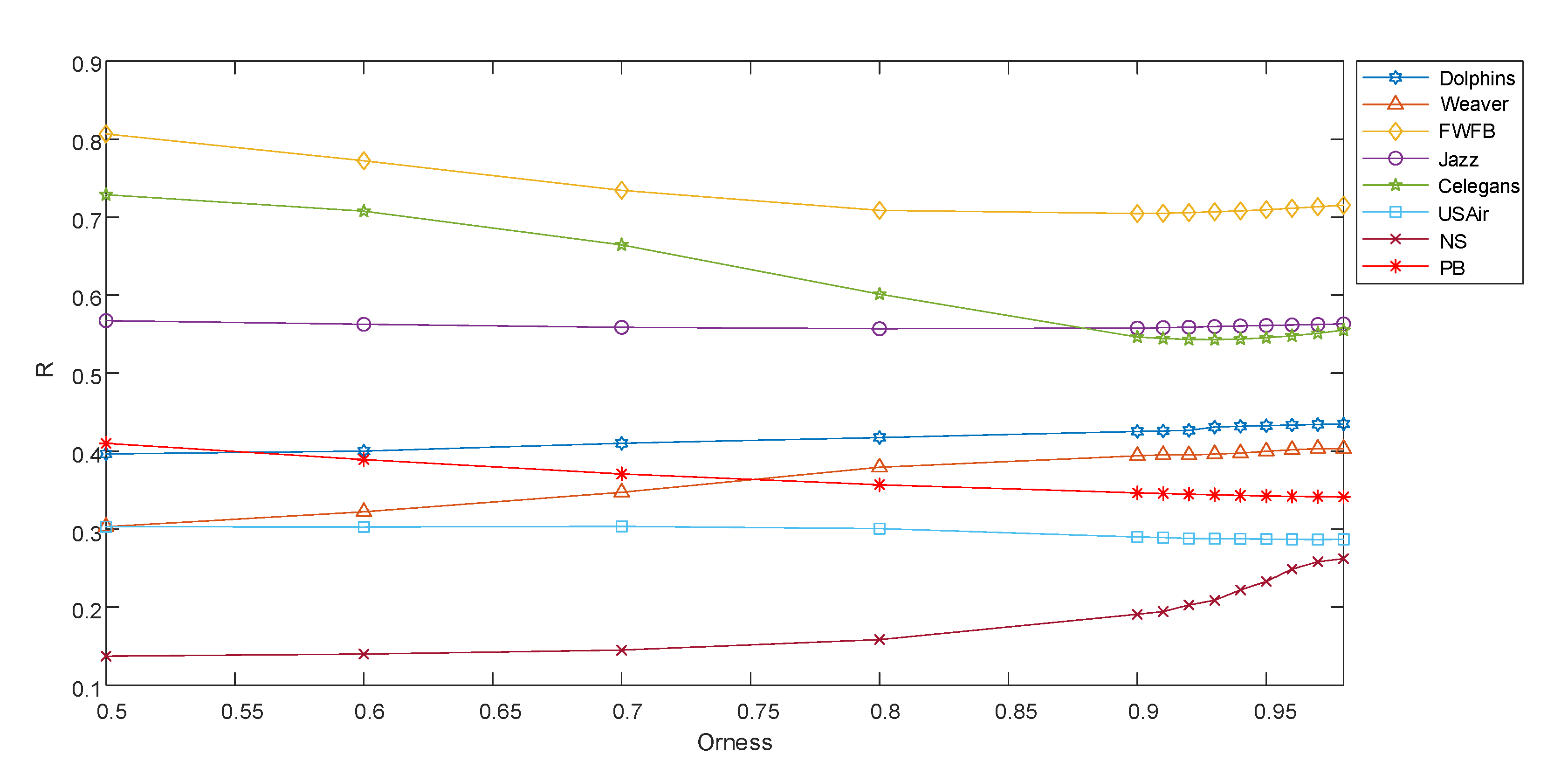
4. Experimental Comparison and Analysis
- Edge betweenness centrality [40]. Edge-betweenness centrality reflects the ratio of the number of shortest paths between pairs of nodes passing through the edge to the total number of shortest paths between all node pairs, defined aswhere is the number of shortest paths from node s to node t, and is the number of shortest paths from s to t that pass through edge E.
- Bridgeness [21]. Edges shared by dfferent communities are critical in connecting the network. Accordingly, the Bridgeness is defined aswhere and are the clique sizes of nodes x and y, respectively. is the clique size of edge E. A fully connected subgraph with k nodes is called a clique of size k.
- FWFB: ACT (under LEWF), SRW (under HEWF) and RWR (under HEWF).
- Celegans: ACT (under LEWF), SRW (under HEWF) and RWR (under HEWF).
- NS: Cos+ (under LEWF), RWR (under LEWF) and Jaccard (under LEWF).
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Shargel, B.; Sayama, H.; Epstein, I.R.; Bar-Yam, Y. Optimization of Robustness and Connectivity in Complex Networks. Phys. Rev. Lett. 2003, 90, 068701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, X.; Gao, J.; Buldyrev, S.V.; Havlin, S.; Stanley, H.E. Robustness of interdependent networks under targeted attack. Phys. Rev. E 2011, 83, 065101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, J.; Buldyrev, S.; Havlin, S.; Stanley, H. Robustness of a Network of Networks. Phys. Rev. Lett. 2010, 107, 195701. [Google Scholar] [CrossRef] [PubMed]
- Shang, Y. Subgraph Robustness of Complex Networks Under Attacks. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 821–832. [Google Scholar] [CrossRef]
- Safaei, F.; Yeganloo, H.; Akbar, R. Robustness on topology reconfiguration of complex networks: An entropic approach. Math Comput Simul 2020, 170, 379–409. [Google Scholar] [CrossRef]
- Li, G.; Hu, J.; Song, Y.; Yang, Y.; Li, H. Analysis of the Terrorist Organization Alliance Network Based on Complex Network Theory. IEEE Access 2019, 7, 103854–103862. [Google Scholar] [CrossRef]
- Xia, C.; Wang, L.; Sun, S.; Wang, J. An SIR model with infection delay and propagation vector in complex networks. Nonlinear Dyn. 2012, 69, 927–934. [Google Scholar] [CrossRef]
- Deng, Y.; Wu, J.; Jin Tan, Y. Optimal attack strategy of complex networks based on tabu search. Physica A 2016, 442, 74–81. [Google Scholar] [CrossRef]
- Johner, N.; Grimaldi, C.; Maeder, T.; Ryser, P. Optimal percolation of disordered segregated composites. Phys. Rev. E 2009, 79, 020104. [Google Scholar] [CrossRef] [Green Version]
- Morone, F.; Makse, H.A. Influence maximization in complex networks through optimal percolation. Nature 2015, 524, 65–68. [Google Scholar] [CrossRef] [Green Version]
- Albert, R.; Jeong, H.; Barabási, A.L. Error and attack tolerance of complex networks. Nature 2000, 406, 378–382. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bellingeri, M.; Cassi, D.; Vincenzi, S. Efficiency of attack strategies on complex model and real-world networks. Physica A 2014, 414, 174–180. [Google Scholar] [CrossRef] [Green Version]
- Nie, T.; Guo, Z.; Zhao, K.; Lu, Z.M. New attack strategies for complex networks. Physica A 2015, 424, 248–253. [Google Scholar] [CrossRef]
- Li, Q.; Liu, S.Y.; Yang, X.S. Neighborhood information-based probabilistic algorithm for network disintegration. Expert Syst. Appl. 2020, 139, 112853. [Google Scholar] [CrossRef]
- Qi, M.; Bai, Y.; Li, X.; Deng, H.; Wang, T. Optimal Disintegration Strategy in Multiplex Networks under Layer Node-Based Attack. Appl. Sci. 2019, 9, 3968. [Google Scholar] [CrossRef]
- Bao, Z.; Cao, Y.; Ding, L.; Wang, G. Comparison of cascading failures in small-world and scale-free networks subject to vertex and edge attacks. Physica A 2009, 388, 4491–4498. [Google Scholar] [CrossRef]
- Wang, J.W.; Rong, L.L. Robustness of the western United States power grid under edge attack strategies due to cascading failures. Saf. Sci. 2011, 49, 807–812. [Google Scholar] [CrossRef]
- Xie, F.; Cheng, S.; Chen, D.; Zhang, G. Cascade-based attack vulnerability in complex networks. J. Tsinghua Univ. Sci. Technol. 2011, 51, 1252–1257. [Google Scholar]
- Hao, Y.; Jia, L.; Wang, Y. Edge attack strategies in interdependent scale-free networks. Physica A 2020, 540, 122759. [Google Scholar] [CrossRef]
- Yin, Y.; Liu, Q.; Zhang, C.; Zhou, J. Survivability analysis of weighted-edge attacks on complex networks with incomplete information. Physica A 2019, 531, 120957. [Google Scholar] [CrossRef]
- Cheng, X.Q.; Ren, F.X.; Shen, H.W.; Zhang, Z.K.; Zhou, T. Bridgeness: A local index on edge significance in maintaining global connectivity. J. Stat. Mech. Theory Exp. 2010, 2010, P10011. [Google Scholar] [CrossRef] [Green Version]
- Qi, M.; Tan, S.Y.; Deng, H.; Wu, J. Evaluating link significance in maintaining network connectivity based on link prediction. Chaos 2019, 29, 083120. [Google Scholar] [CrossRef] [PubMed]
- He, Y.L.; Liu, J.N.; Hu, Y.X.; Wang, X.Z. OWA operator based link prediction ensemble for social network. Expert Syst. Appl. 2015, 42, 21–50. [Google Scholar] [CrossRef]
- Wu, M.; Wu, S.; Zhang, Q.; Xue, C.; Kan, H.; Shao, F. Enhancing link prediction via network reconstruction. Physica A 2019, 534, 122346. [Google Scholar] [CrossRef]
- Li, K.; Tu, L.; Chai, L. Ensemble-model-based link prediction of complex networks. Comput. Netw. 2020, 166, 106978. [Google Scholar] [CrossRef]
- Wang, J.W.; Rong, L.L. Vulnerability of Effective Attack on Edges in Scale-Free Networks due to Cascading Failures. Int. J. Mod. Phys. C 2009, 20, 1291–1298. [Google Scholar] [CrossRef]
- Deng, Y.; Wu, J.; Xiao, Y.; Li, Y. Efficient disintegration strategies with cost constraint in complex networks: The crucial role of nodes near average degree. Chaos 2018, 28, 061101. [Google Scholar] [CrossRef]
- Zeng, A.; Liu, W. Enhancing network robustness against malicious attacks. Phys. Rev. E 2012, 85, 066130. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69. [Google Scholar] [CrossRef] [Green Version]
- Van Dijk, R.E.; Kaden, J.C.; Argüelles-Ticó, A.; Dawson, D.A.; Burke, T.; Hatchwell, B.J. Cooperative investment in public goods is kin directed in communal nests of social birds. Ecol. Lett. 2014, 17, 1141–1148. [Google Scholar] [CrossRef] [Green Version]
- Ulanowicz, R.; Bondavalli, C.; Egnotovich, M. Network Analysis of Trophic Dynamics in South Florida Ecosystem, FY 97: The Florida Bay Ecosystem; Ref. No. [UMCES]CBL 97-075; United States Geological Service Biological Resources Division: Coral Gables, FL, USA, 1998; pp. 98–123.
- Gleiser, P.; Danon, L. Community Structure in Jazz. Adv. Complex Syst. 2003, 6, 565–573. [Google Scholar] [CrossRef] [Green Version]
- Watts, D.J.; Strogatz, H.S. Collective dynamics of ’small world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Physica A 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adamic, L.A.; Glance, N. The Political Blogosphere and the 2004 U.S. Election: Divided They Blog. In Proceedings of the 3rd International Workshop on Link Discovery (LinkKDD05), Chicago, IL, USA, 21–24 August 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 36–43. [Google Scholar] [CrossRef]
- Wu, J.; Yue-Jin, T.; Deng, H.Z.; Da-Zhi, Z. Normalized entropy of rank distribution: A novel measure of heterogeneity of complex networks. Chin. Phys. 2007, 16, 1576. [Google Scholar] [CrossRef]
- Yager, R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. Syst. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- O’Hagan, M. Aggregating template or rule antecedents in real-time expert systems with fuzzy set logic. In Proceedings of the Twenty-Second Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 31 October–2 November 1988; Volume 2, pp. 681–689. [Google Scholar]
- Freeman, L. A Set of Measures of Centrality Based on Betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Goyal, P.; Batra, S.; Singh, A. A literature review of security attack in mobile ad-hoc networks. Int. J. Comput. Appl. 2010, 9, 11–15. [Google Scholar] [CrossRef]
- Dziubiński, M.; Goyal, S. Network design and defence. Games Econ. Behav. 2013, 79, 30–43. [Google Scholar] [CrossRef] [Green Version]
- Goyal, S.; Vigier, A. Attack, defence, and contagion in networks. Rev. Econ. Stud. 2014, 81, 1518–1542. [Google Scholar] [CrossRef]
- Goyal, S.; Jabbari, S.; Kearns, M.; Khanna, S.; Morgenstern, J. Strategic network formation with attack and immunization. In Proceedings of the 12th International Conference on Web and Internet Economics, Montreal, QC, Canada, 11–14 December 2016; pp. 429–443. [Google Scholar]
- Zeng, C.; Ren, B.; Li, M.; Liu, H.; Chen, J. Stackelberg game under asymmetric information in critical infrastructure system: From a complex network perspective. Chaos 2019, 29, 083129. [Google Scholar] [CrossRef] [PubMed]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw-Hill, Inc.: New York, NY, USA, 1986. [Google Scholar]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaud. Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Sørensen, T.; Sørensen, T.; Sørensen, T.; SORENSEN, T.; Sorensen, T.; Sorensen, T.; Biering-Sørensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons. Biol. Skar. 1948, 5, 1–34. [Google Scholar]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical Organization of Modularity in Metabolic Networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leicht, E.A.; Holme, P.; Newman, M.E. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Ou, Q.; Jin, Y.D.; Zhou, T.; Wang, B.H.; Yin, B.Q. Power-law strength-degree correlation from resource-allocation dynamics on weighted networks. Phys. Rev. E 2007, 75, 021102. [Google Scholar] [CrossRef] [Green Version]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Chebotarev, P.; Shamis, E. The matrix-forest theorem and measuring relations in small social groups. arXiv 2006, arXiv:math/0602070. [Google Scholar]
- Lü, L.; Jin, C.H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Lü, L. Link prediction based on local random walk. EPL 2010, 89, 58007. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | N | E | r | C | |||
|---|---|---|---|---|---|---|---|
| Dolphins | 62 | 159 | 5.13 | 3.36 | −0.04 | 0.30 | 0.1275 |
| Weaver | 117 | 304 | 5.19 | 4.46 | 0.06 | 0.66 | 0.1412 |
| FWFB | 128 | 2075 | 32.42 | 1.78 | −0.11 | 0.33 | 0.0633 |
| Jazz | 198 | 2742 | 27.70 | 2.24 | 0.02 | 0.63 | 0.1041 |
| C.elegans | 297 | 2148 | 14.46 | 2.46 | −0.16 | 0.31 | 0.1296 |
| USAir | 332 | 2126 | 12.81 | 2.74 | −0.21 | 0.75 | 0.3528 |
| NS | 379 | 914 | 4.82 | 6.04 | −0.08 | 0.80 | 0.1083 |
| PB | 1222 | 16714 | 27.36 | 2.74 | −0.22 | 0.36 | 0.2418 |
| ACT | RWR | Katz | LocalPath | CN | Salton | Jaccard | Sørenson | HPI | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.3889 | 0.8889 | 0.5000 | 0.5000 | 0.4444 | 0.6111 | 0.6111 | 0.6111 | 0.7778 | ||
| −0.4444 | −0.8333 | −0.5556 | −0.5556 | −0.5000 | −0.6667 | −0.6667 | −0.6667 | −0.8333 | ||
| r | 0.1111 | −0.3889 | −0.1111 | −0.1111 | −0.0556 | −0.2222 | −0.2222 | −0.2222 | −0.1667 | |
| C | −0.5000 | −0.2222 | −0.6111 | −0.6111 | −0.6667 | −0.5000 | −0.5000 | −0.5000 | −0.3333 | |
| −0.6111 | −0.1111 | −0.3889 | −0.3889 | −0.4444 | −0.2778 | −0.2778 | −0.2778 | −0.3333 | ||
| HDI | LHN | AA | RA | PA | LHNII | MFI | Cos+ | LRW | SRW | |
| 0.6111 | 0.8333 | 0.5556 | 0.5556 | 0.2222 | 0.8333 | 0.8333 | 0.6667 | 0.7778 | 0.8333 | |
| −0.6667 | −0.8889 | −0.6111 | −0.6111 | −0.2778 | −0.7778 | −0.7778 | −0.6111 | −0.7222 | −0.7778 | |
| r | −0.2222 | −0.2222 | −0.1667 | −0.1667 | −0.0556 | −0.4444 | −0.4444 | −0.5000 | −0.5000 | −0.4444 |
| C | −0.5000 | −0.2778 | −0.5556 | −0.5556 | −0.3333 | −0.1667 | −0.1667 | −0.3333 | −0.2222 | −0.1667 |
| −0.2778 | −0.2778 | −0.3333 | −0.3333 | −0.6667 | −0.0556 | −0.0556 | 0.0000 | 0.0000 | −0.0556 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Y.; Ren, B.; Zeng, C.; Yang, Y.; Liu, H. Enhancing Edge Attack Strategy via an OWA Operator-Based Ensemble Design in Real-World Networks. Entropy 2020, 22, 830. https://doi.org/10.3390/e22080830
Feng Y, Ren B, Zeng C, Yang Y, Liu H. Enhancing Edge Attack Strategy via an OWA Operator-Based Ensemble Design in Real-World Networks. Entropy. 2020; 22(8):830. https://doi.org/10.3390/e22080830
Chicago/Turabian StyleFeng, Yuan, Baoan Ren, Chengyi Zeng, Yuyuan Yang, and Hongfu Liu. 2020. "Enhancing Edge Attack Strategy via an OWA Operator-Based Ensemble Design in Real-World Networks" Entropy 22, no. 8: 830. https://doi.org/10.3390/e22080830