New Fast ApEn and SampEn Entropy Algorithms Implementation and Their Application to Supercomputer Power Consumption


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. New Fast Algorithms
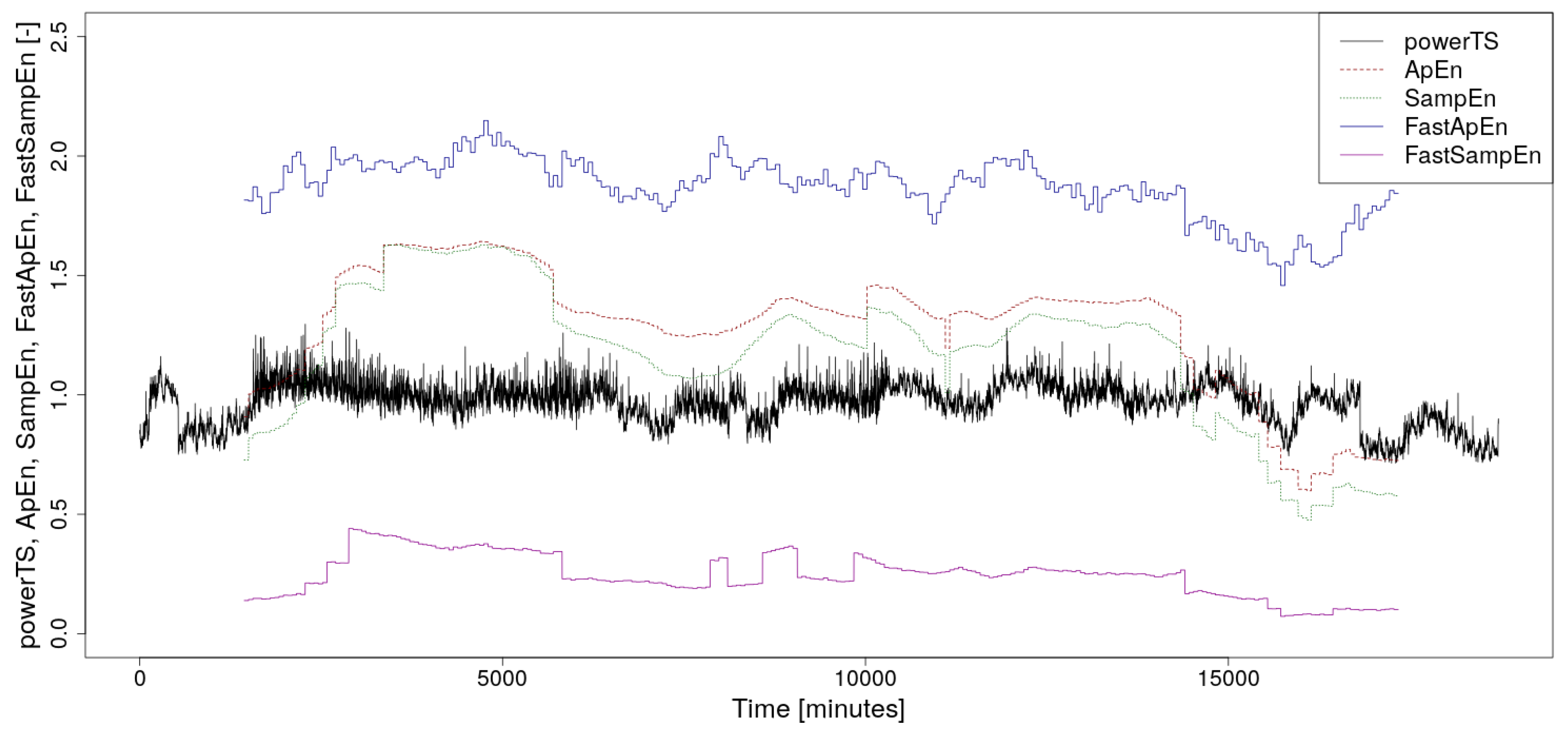
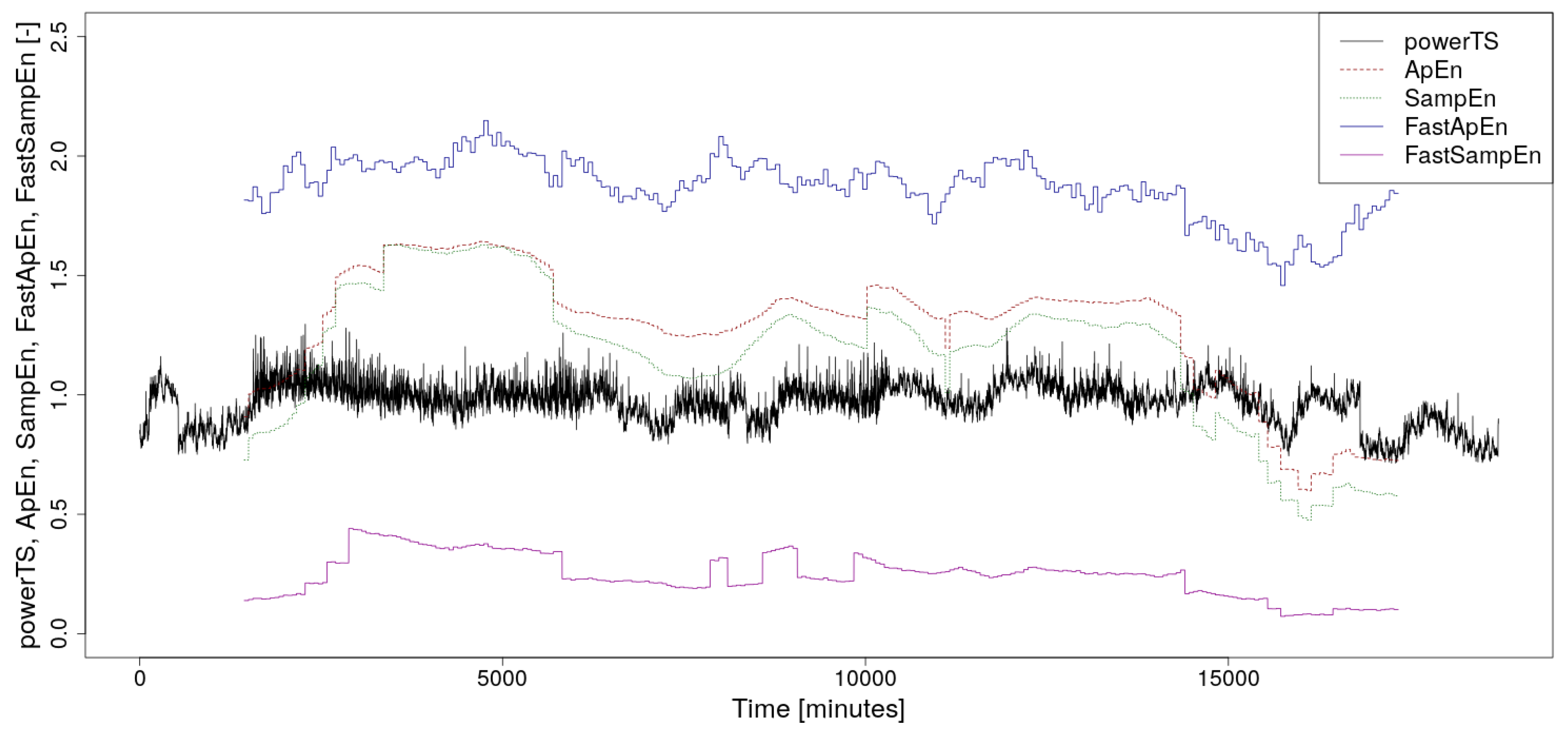
3. Supercomputer Power Consumption Time Series
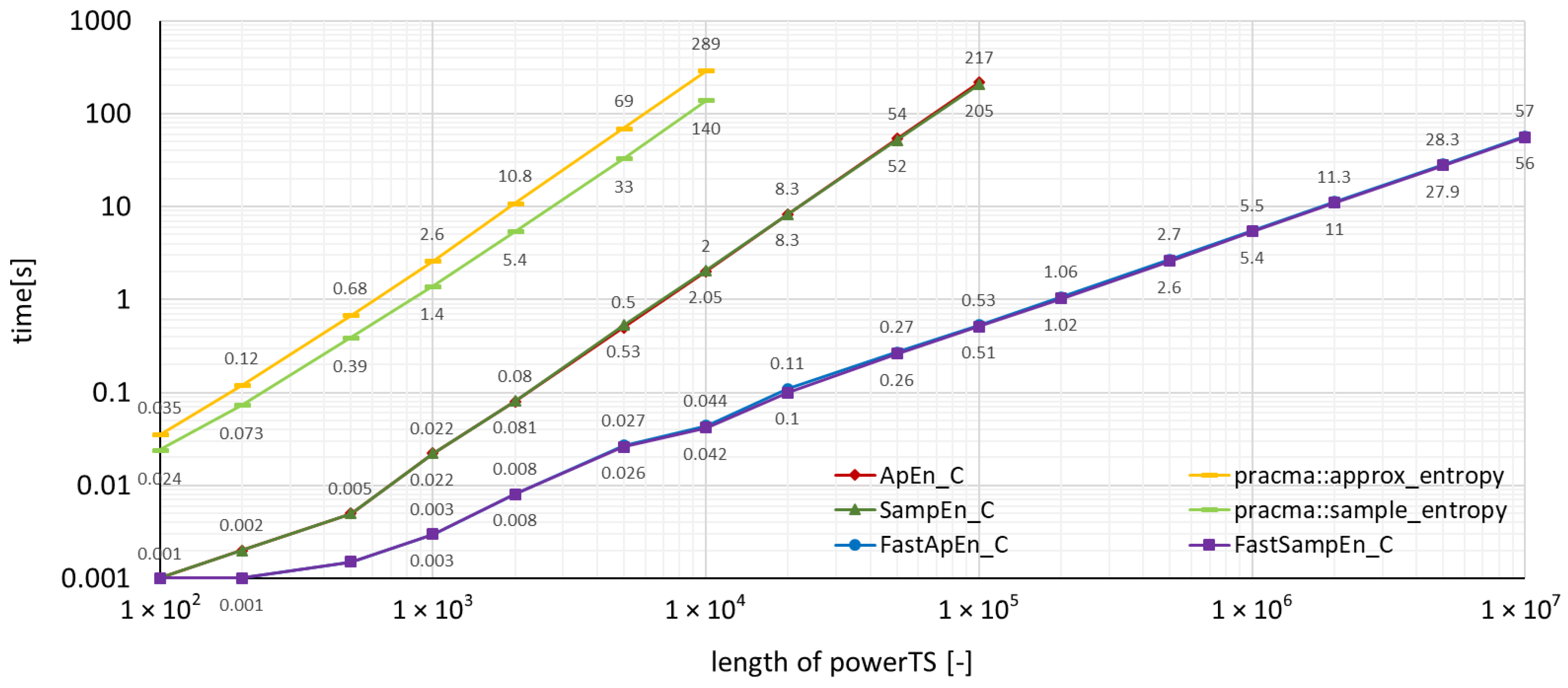
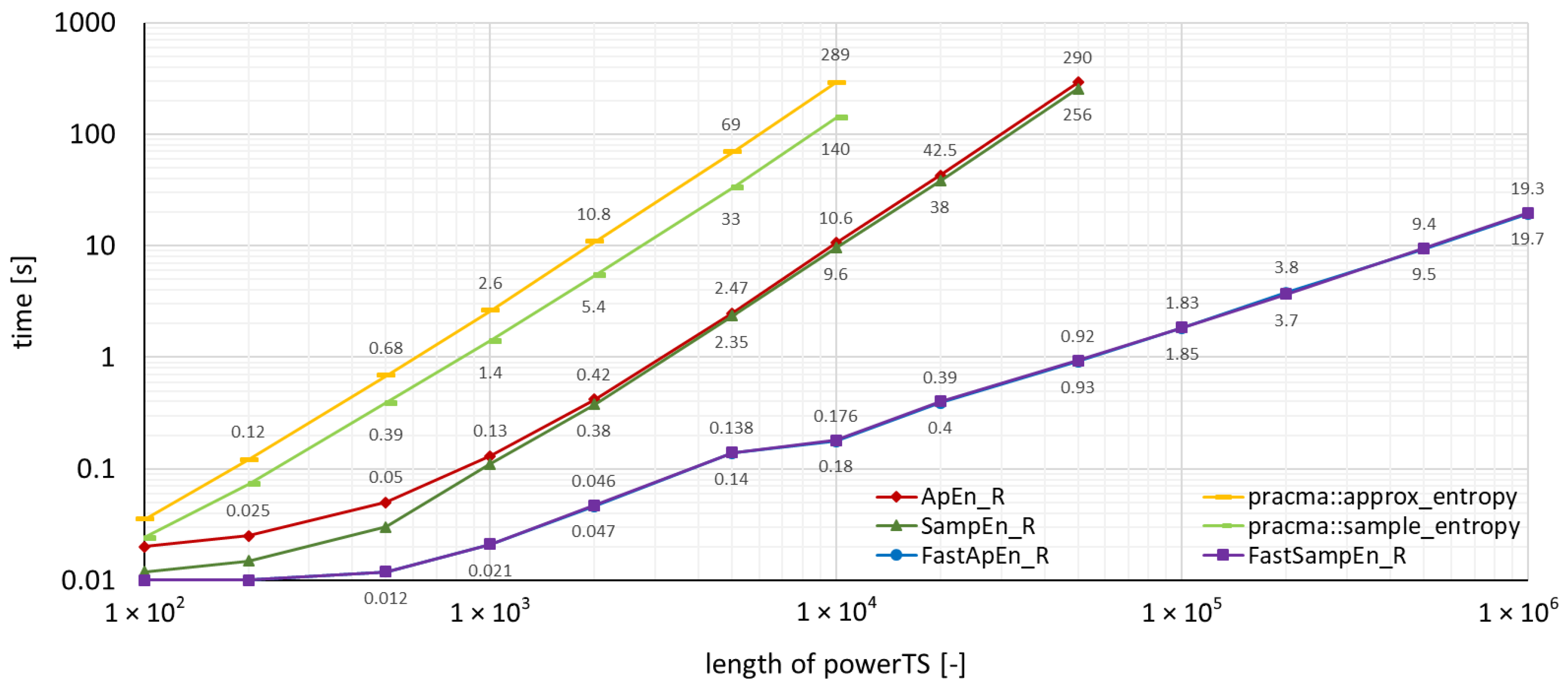
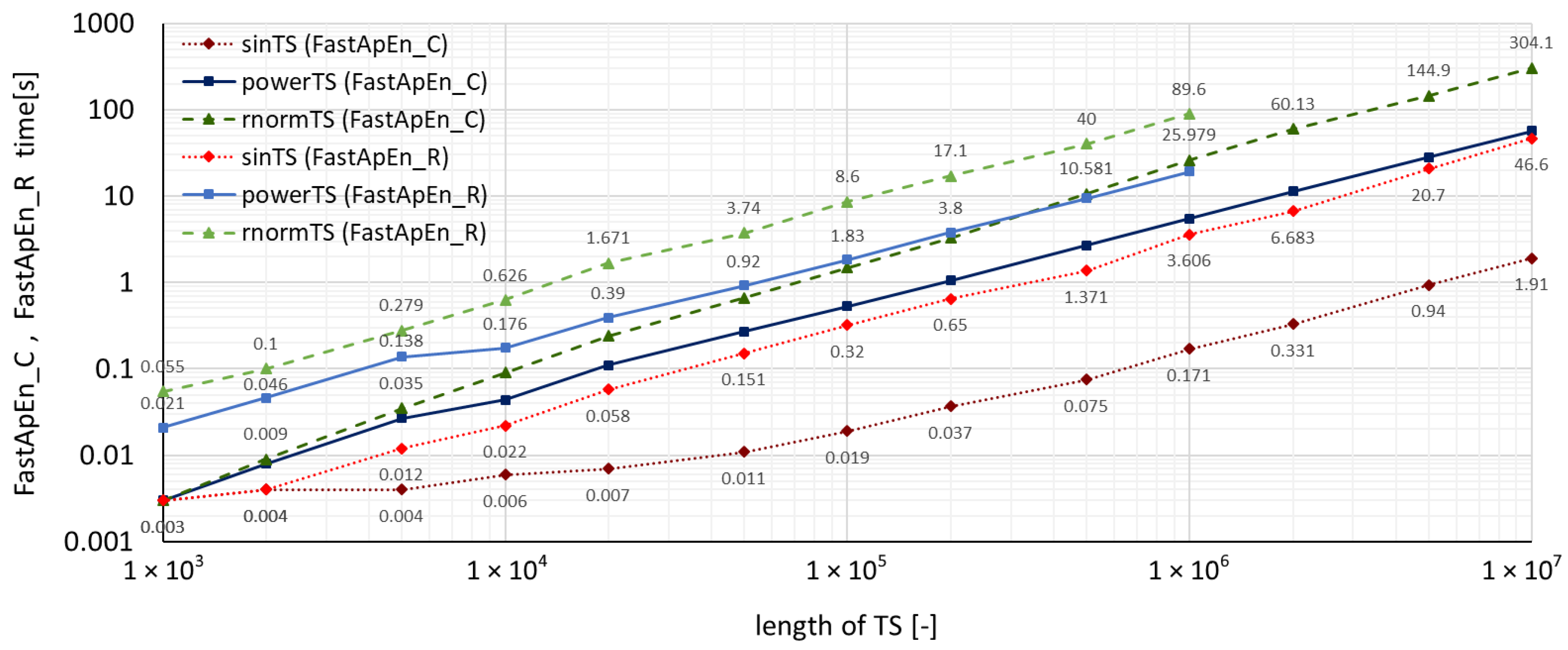
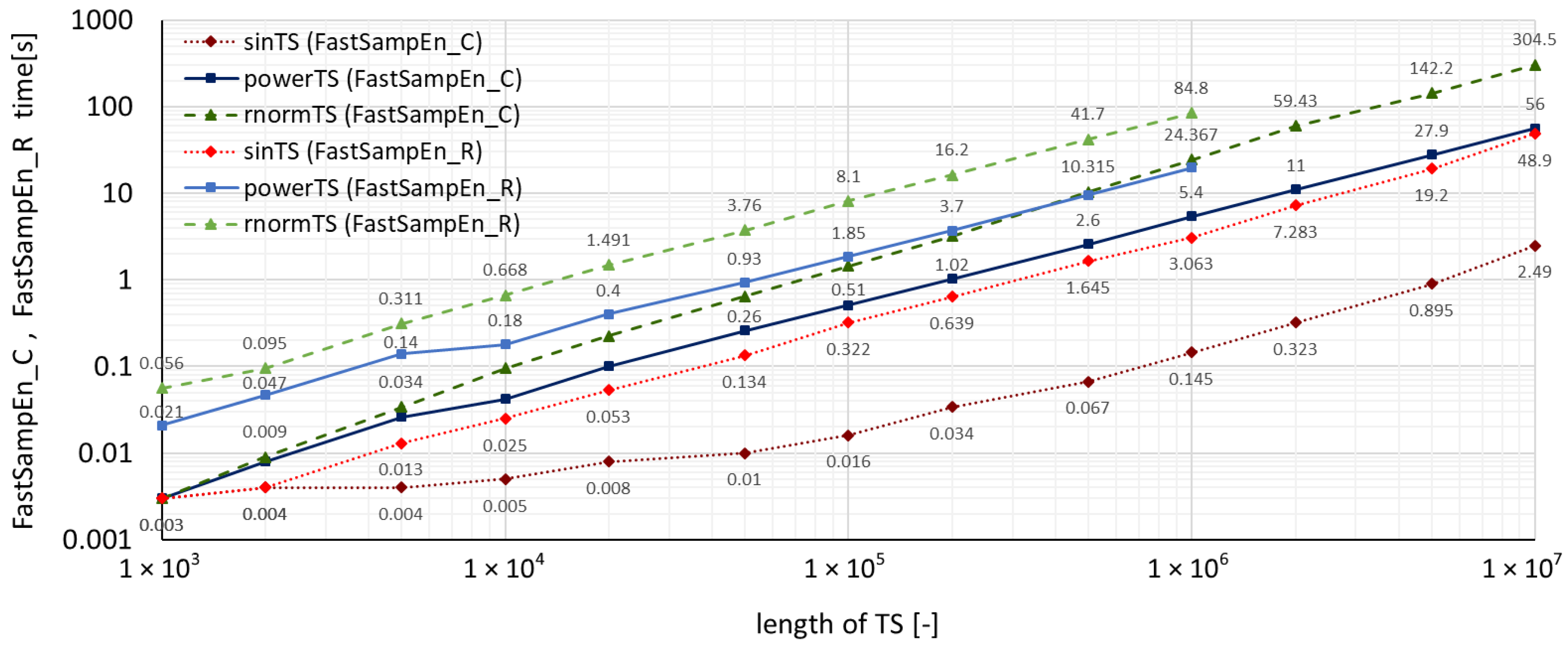
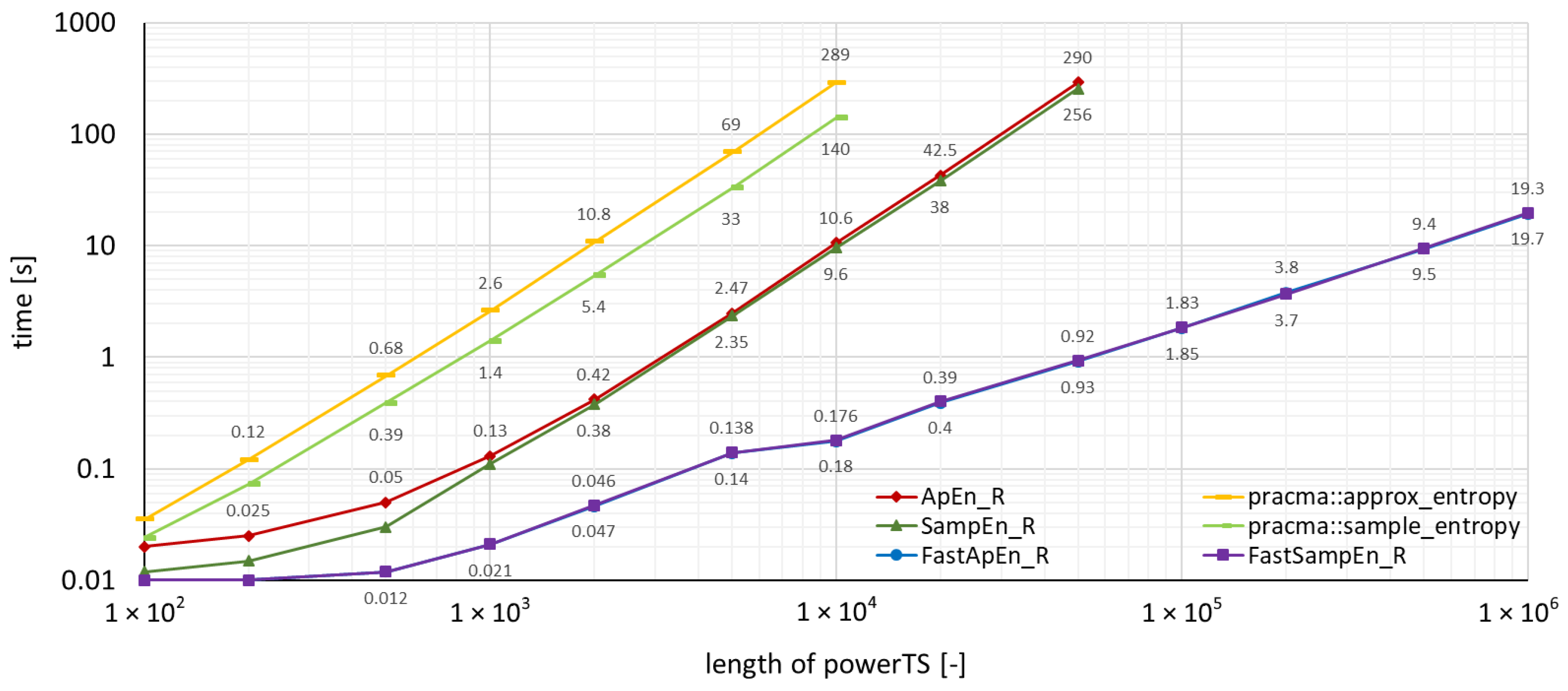
4. Benchmarks and Comparison
5. Conclusions and Future Work
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Installation of TSEntropies Package
Appendix B. TSEntropies Package Content and Implementation
References
- Gottwald, G.A.; Melbourne, I. A new test for chaos in deterministic systems. Proc. R. Soc. Lond. Ser. A 2004, 460, 603–611. [Google Scholar] [CrossRef] [Green Version]
- Shilnikov, L.P. A case of the existence of a denumerable set of periodic motion. Sov. Math. Dokl 1965, 6, 163–166. [Google Scholar]
- Clausius, R. The Mechanical Theory of Heat, Nine Memoirs on the Development of Concept of “Entropy”; John Van Voorst, 1 Paternoster Row: London, UK, 1867. [Google Scholar]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, 2039–2049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tomčala, J. Acceleration of time series entropy algorithms. J. Supercomput. 2019, 75, 1443–1454. [Google Scholar] [CrossRef]
- IT4Innovations (2020): Anselm, Salomon, DGX-2, and Barbora Supercomputer Clusters Located at IT4Innovations, National Supercomputing Center. VSB—Technical University of Ostrava, Czech Republic. Available online: https://www.it4i.cz/en (accessed on 3 August 2020).
- Tomčala, J. Predictability and Entropy of Supercomputer Infrastructure Consumption. In Chaos Complex Systems, Proceedings of the 5th International Interdisciplinary Chaos Symposium, 9–12 May 2019, Antalya, Turkey; Stavrinides, S., Ozer, M., Eds.; Springer: Cham, Switzerland, 2020; Volume 10, pp. 59–66. [Google Scholar] [CrossRef]
- Tomcala, J. TSEntropies: Time Series Entropies. R package. 2018. Available online: https://CRAN.R-project.org/package=TSEntropies (accessed on 3 August 2020).
- Borchers, H.W. Pracma: Practical Numerical Math Functions. R package. 2019. Available online: https://CRAN.R-project.org/package=pracma (accessed on 3 August 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: https://www.R-project.org (accessed on 3 August 2020).



© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tomčala, J. New Fast ApEn and SampEn Entropy Algorithms Implementation and Their Application to Supercomputer Power Consumption. Entropy 2020, 22, 863. https://doi.org/10.3390/e22080863
Tomčala J. New Fast ApEn and SampEn Entropy Algorithms Implementation and Their Application to Supercomputer Power Consumption. Entropy. 2020; 22(8):863. https://doi.org/10.3390/e22080863
Chicago/Turabian StyleTomčala, Jiří. 2020. "New Fast ApEn and SampEn Entropy Algorithms Implementation and Their Application to Supercomputer Power Consumption" Entropy 22, no. 8: 863. https://doi.org/10.3390/e22080863
APA StyleTomčala, J. (2020). New Fast ApEn and SampEn Entropy Algorithms Implementation and Their Application to Supercomputer Power Consumption. Entropy, 22(8), 863. https://doi.org/10.3390/e22080863