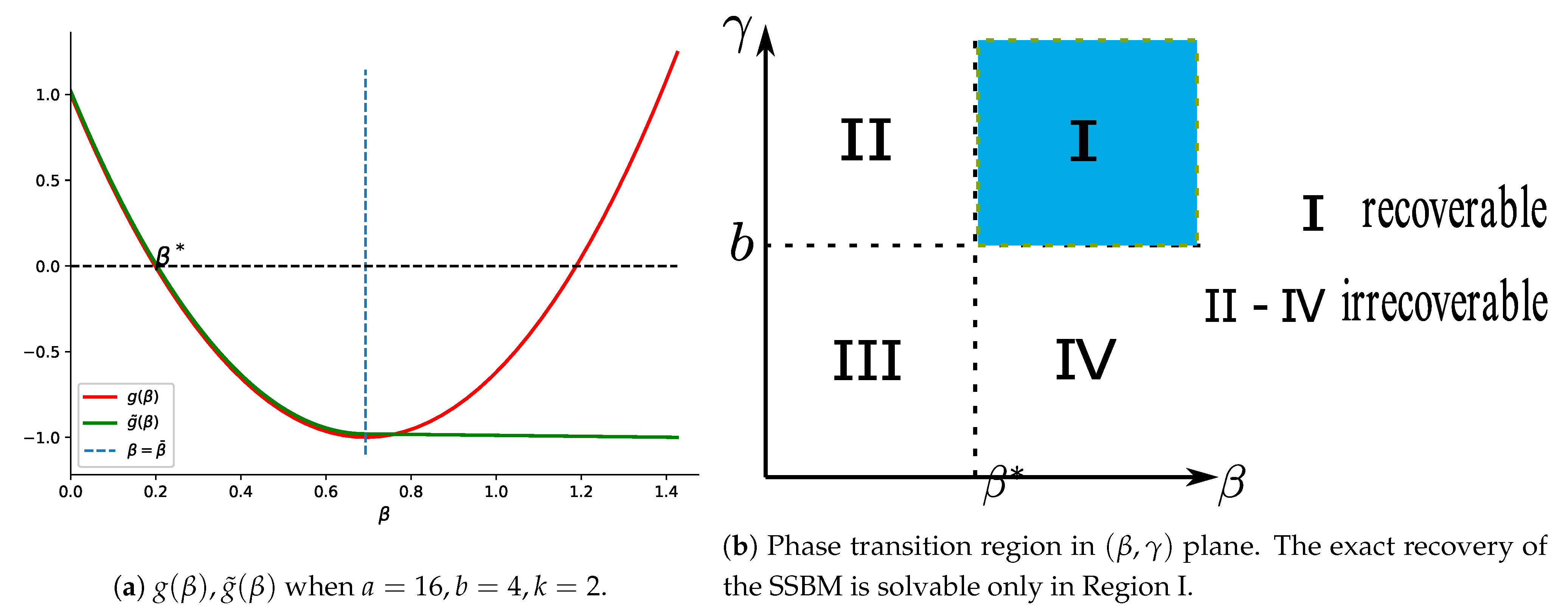
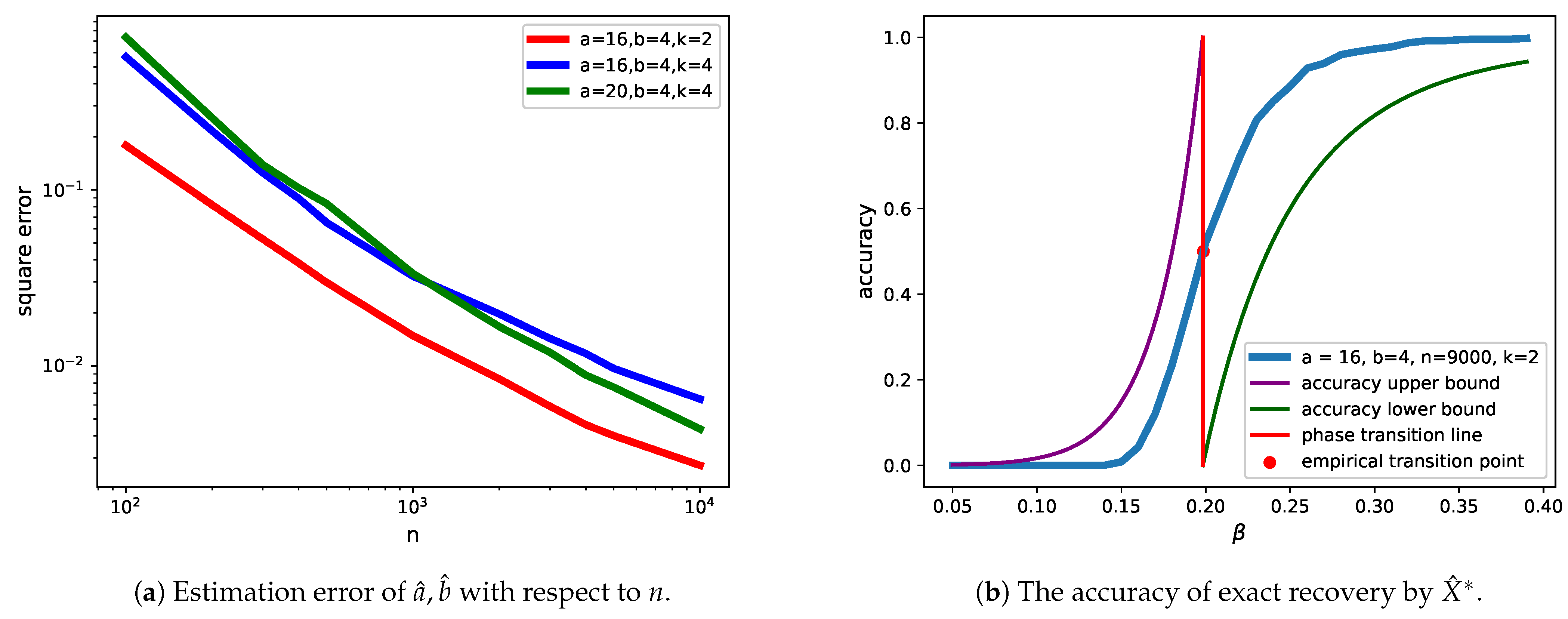
Exact Recovery of Stochastic Block Model by Ising Model


{kind=link}
{kind=link}
Abstract
Share and Cite
Zhao, F.; Ye, M.; Huang, S.-L. Exact Recovery of Stochastic Block Model by Ising Model. Entropy 2021, 23, 65. https://doi.org/10.3390/e23010065
Zhao F, Ye M, Huang S-L. Exact Recovery of Stochastic Block Model by Ising Model. Entropy. 2021; 23(1):65. https://doi.org/10.3390/e23010065
Chicago/Turabian StyleZhao, Feng, Min Ye, and Shao-Lun Huang. 2021. "Exact Recovery of Stochastic Block Model by Ising Model" Entropy 23, no. 1: 65. https://doi.org/10.3390/e23010065
APA StyleZhao, F., Ye, M., & Huang, S.-L. (2021). Exact Recovery of Stochastic Block Model by Ising Model. Entropy, 23(1), 65. https://doi.org/10.3390/e23010065