Abstract
A class of models for non-Gaussian spatial random fields is explored for spatial field reconstruction in environmental and sensor network monitoring. The family of models explored utilises a class of transformation functions known as Tukey g-and-h transformations to create a family of warped spatial Gaussian process models which can support various desirable features such as flexible marginal distributions, which can be skewed, leptokurtic and/or heavy-tailed. The resulting model is widely applicable in a range of spatial field reconstruction applications. To utilise the model in applications in practice, it is important to carefully characterise the statistical properties of the Tukey g-and-h random fields. In this work, we study both the properties of the resulting warped Gaussian processes as well as using the characterising statistical properties of the warped processes to obtain flexible spatial field reconstructions. In this regard we derive five different estimators for various important quantities often considered in spatial field reconstruction problems. These include the multi-point Minimum Mean Squared Error (MMSE) estimators, the multi-point Maximum A-Posteriori (MAP) estimators, an efficient class of multi-point linear estimators based on the Spatial-Best Linear Unbiased (S-BLUE) estimators, and two multi-point threshold exceedance based estimators, namely the Spatial Regional and Level Exceedance estimators. Simulation results and real data examples show the benefits of using the Tukey g-and-h transformation as opposed to standard Gaussian spatial random fields in a real data application for environmental monitoring.
1. Introduction
Spatial monitoring of physical phenomena has been at the center of many different spatial statistics and signal processing innovations in recent decades. Specific applications in which environmental processes are monitored and spatial field reconstruction is performed include environmental monitoring [1] and weather monitoring [2,3,4], natural phenomena such as temperature [5], precipitation [6], wind speed [7,8,9,10], pollution [11] and signal processing [12,13] to name a few.
In this work, we explore warping maps of Gaussian process models such as those developed in [7] for spatial field reconstruction. It is most commonly the case that spatial field modelling is undertaken with a variation of a Gaussian Process (GP) model due to its direct interpretation and mathematical tractability [14]. GP models are readily characterized by a mean structure and a valid covariance function [14]. Such models have been applied in many different domains for spatial and temporal modelling: [15,16,17] and the classic texts on such Gaussian process models for spatial statistics [18,19]. The warping extensions studied in this work are designed to specifically accommodate a flexible range of non-Gaussian skew and kurtosis attributes in order to demonstrate how to undertake accurate and efficient spatial field reconstruction in a more general class of spatial process models, whilst still maintaining much of the practical interpretation offered by Gaussian process modelling settings.
The significance of adding such warping structure arises since increasingly spatial modellers and data scientists are observing that many types of physical phenomena may have finite dimensional distributions which are not adequately captured by symmetric light tailed Gaussian distributions as is mandated by such classical GP spatial field modelling approaches. The reality is that the skew and kurtosis can play a significant role in spatial field modelling, see discussion in [4,20,21]. As noted in these works, there are many real world settings where the physical process being modelled in the spatial field reconstruction may exhibit features which cannot be captured accurately via GP modelling, as the process may display spatial features at different locations that include excess skewness (asymmetry about the mode), kurtosis and perhaps heavy tails. Hence, the GP will not provide such flexible features if used as the basis upon which to undertake development of estimators for spatial field reconstruction, therefore we wish to extend this class of models. This will in turn influence the accuracy of any spatial field reconstruction estimator built from such statistical model assumptions.
Therefore, when one finds a setting in which GP structure will not adequately capture the spatial field statistical structure, there are numerous approaches that one may proceed with when seeking to perform spatial field reconstruction. The first involves seeking a transformation that will induce properties in the transformed observations of the process more akin to a GP model, see examples in [22,23] for a detailed overview of the subject. Examples include the log-transform, proposed by Galton, which resulted in the nowadays well-known log-normal distribution [24]. The first systematic attempt to fit asymmetric distributions to non-normal data was made by Edgeworth [25]. Karl Pearson defined several probability distributions as solutions to a particular differential equation, which formed the basis for the Pearson family of distributions [26]. Further development was the two-piece distributions, proposed by Fechner, which were developed by binding together two halves of normal curves, each having a different scaling [27]. A more recent work which had a great impact was by Azzalini [28] who provided a rigorous treatment to the analysis of Skew-Normal distributions.
An alternative, recent class of approaches in the statistical machine learning literature has involved the converse of these methods, where one rather warps or “transforms” a GP model to produce an additional structure such as skewness or kurtosis and then works with estimation and spatial field reconstruction of the resultant transformed process. This method has two components—the specification of the sufficient statistical functions for the input GP model and the specification of the functional characteristic of the transformation map.
In this work, we explore the second approach based on warping a GP model. One may consider our approach as exploring a generalised class of processes that act as extensions of the GP family to a much larger family of processes that incorporate parameterised features of skewness and kurtosis that arises directly from the class of warping functions adopted. In this family of models we develop, just like the GP case, we wish to be able to state useful information about the resulting processes finite dimensional distributions: i.e., the marginal and conditional distributions of the process at different locations in space. This can be done by modifying an existing known parametric distribution (Gaussian) by applying a transformation of the random variables pointwise. This concept was first proposed by Tukey in 1977, and further developed in [29,30,31] and in the time series setting by [32]. In this paper, we demonstrate that when one selects the family of Tukey g-and-h model distortion functions, one can derive tractable solutions to spatial field reconstruction estimators that will out-perform classical GP solutions when spatial processes exhibit excess spatial skewness and spatial kurtosis features.
Contributions and Outline
The main contributions developed in this work are twofold: formulating a class of spatial warped GP models based on Tukey g-and-h warping functions. This involves deriving important key properties of the Tukey g-and-h transformation and resulting family of spatial warped GP (Section 2 and Section 3); and using those results to develop new estimation algorithms for efficient spatial field reconstructions (Section 4). Our contributions may be summarised as follows:
- (1)
- In Section 2, we derive mathematical properties of the proposed warped GP models warping function known as the Tukey g-and-h transformation function. This is actually a class of warping functions with sub-classes related to skewness and kurtosis transformations. Since this transformation is not widely known, it is valuable for practitioners to see the basic properties of this class of functions in order to better understand the resulting properties of the warped GP that arise when using this transform. In this regard we explore the transformation and its limiting behaviour (Proposition 2), the existence of the inverse transform (Proposition 1), and its derivatives (Lemma 1). This set of results is instrumental for the analysis of the properties of the Tukey g-and-h process and for the construction of spatial field approximations that form the key application in this paper.
- (2)
- In Section 3, we derive important statistical properties of the warped GP process which include properties of the finite dimensional distributions such as raw and central moments, the multivariate moments (Corollary 1), the population mean and variance (Corollaries 3–4), its higher order multivariate cross moments of any order (Proposition 3), and the index of regular variation (Lemma 2), to determine conditions in terms of the parameters of the g-and-h transform for the existence of all higher order mixed moments. In particular, the cross moments are directly relevant to the construction of efficient spatial field reconstructions for multiple locations in space that are performed in the application section. The tail behaviour of the finite dimensional distributions is captured by the tail index analysis and is relevant to understand models with excess kurtosis relative to a GP model, which is induced by our class of warping function.
- (3)
- In Section 4, we derive the spatial field reconstruction estimators of the Tukey g- and-h random field under five different metrics, most of which are based on the predictive posterior density (Lemma 4).
- (4)
- In Section 5, a detailed set of numerical experiments are provided. This includes both real data cases studies as well as synthetic case studies which were developed to demonstrate key properties of the spatial field reconstruction methods and their accuracy and performance relative to a baseline GP model. In regards to the real data case studies, a sequence of experiments was developed which was based on data obtained from the National Climatic Data Center (NCDC) which included spatial observations of precipitation obtained from ground monitoring stations in the regions of interest. In particular, we took one month of hourly precipitation measurements to fit our warped GP model to obtain a spatial field reconstruction which was compared to a baseline GP model with no warping in order to demonstrate the benefits of a spatial warping framework.
2. Constructing a Flexible Warping Function for Spatial Gaussian Processes
Many families of warping function can be developed for extending the class of GP spatial process models. In this work, we particularly focus on the study of the family of Tukey g-and-h warping functions. When developing the new warped GP class of flexible models, the following list of desirable properties was considered desirable for the resulting warped GP model to posses (see [22]):
- (1)
- Parsimonious and finite number of well interpreted parameters;
- (2)
- Well-separated roles for skewness, kurtosis and the tail behaviour parameters;
- (3)
- Accurate and computationally efficient parameter estimation and tractability;
- (4)
- Derivable and interpretable stochastic properties;
- (5)
- Flexible structures in the marginal, conditional and joint density shapes;
- (6)
- Good inferential properties;
- (7)
- Exact and computationally efficient data generating mechanisms.
Some of these aforementioned properties have been studied before in the context of the class of warping functions we consider, namely the Tukey g-and-h transformed random GP fields, see for example [31,32,33,34,35,36] and the textbook overview in [37].
In this paper, we re-explore these properties and extend them for the purposes of spatial field reconstruction. Therefore, in this section, we first define the fundamental building blocks for deriving the non-Gaussian warped GP fields. As such, we define the basic set of non-linear transformations of univariate and multivariate Gaussian random variables and the resulting Tukey g-and-h univariate and multivariate distributions. We also derive some fundamental properties such as the existence of the inverse transform as well as the derivatives of the distribution that will be important for future results.
Definition 1
(Tukey Transformation [38]). Consider a Gaussian random variable and transformation with parameter vector , where , , and . Then the resultant transformed random variable Y will be from a Tukey law if the corresponding transformation is given by
where the transformation is positive, symmetric, and strictly monotonically increasing for positive values of .
We note that, as a default, we will consider the base transformed random variable W to be Gaussian with and unless otherwise stated. Furthermore, in general the transformation can have many forms, see discussions in [32]. In this manuscript we concentrate on two specific types of transformation directly related to inducing skewness in the warped GP model or inducing kurtosis in the warped GP model. Note that standard GP models can have flexible covariance functions (second order flexibility) but there is no flexibility in the higher order structure relating to third co-moments (co-skewness) and fourth co-moments (co-kurtosis) that can often be observed in real spatial field observation data. Therefore, the use of the Tukey sub-families of warping functions that specifically produce parameterization of such structure in the warped GP model is of practical relevance in flexible reconstruction methods for spatial fields.
Definition 2
(Tukey Family of Transformations).
The Tukey g (skewness) and Tukey h (kurtosis) transformations form two classes of sub-transformations in the Tukey family which are characterised by warping functions given by:
- (1)
- Skew transform:
- (2)
- Kurtosis transform:
- (3)
- Skew-Kurtosis product transform:
for , and .
These set of Tukey transformations modify the tail behaviour and the skewness relative to the base distribution, in this case the GP model which has finite dimensional Gaussian distributions point-wise in space. As such, the warped GP model will be able to produce a class of processes which, point-wise in space, will have distributions that are less symmetric around the mode. In particular they can accommodate left or right skewness, depending on the sign of g in the warping transform . Furthermore, they can be heavier tailed than a Gaussian probability distribution, via leptokurtic transform , and the strength of kurtosis relative to the Gaussian at each spatial point is controlled by parameter h. The Tukey g-and-h transformation is known to encompass a large range of distributions and this is further explained in [31,32]. This is one of the most desirable properties of this transformation.
Before proceeding in using this family of warping functions to define a warped GP spatial process, it will be useful to provide a few basic properties of this class of transform, that whilst are simple to mathematically verify, are also highly useful in developing further the specification of the properties of the resulting warped processes.
When working with warped GPs it is valuable to be able to evaluate the transformed finite dimensional density at a single location in space point-wise when performing tasks such as hyper-parameter estimation via the likelihood and also for spatial field reconstruction. Therefore, it is of relevance to ask if the warping function is invertible, as such a property leads one to obtaining a tractable expression for the finite dimensional distributions. We show in Proposition 1 the conditions under which the inverse of the warping function exists. Consequently, we can be sure that should we satisfy these conditions for the warping function, then in the case of the Tukey g-and-h transformation, it does accommodate a closed form distribution representation which will be tractable up to performing a simple univariate root search, as we will see later in Proposition 5.
Proposition 1
(Inverse of the Tukey g-and-h transformation).
The inverse of the Tukey g-and-h transformation exists if and
Proof.
See Appendix A. □
Remark 1.
The result in Proposition 1 affirms the existence of the inverse of this transformation but does not provide an analytical expression for the inverse. In practice, one needs to find the inverse using simple univariate root search computational methods in order to facilitate evaluation of the warped distributions or densities point-wise. The existence of the inverse is still critical to verify for the warping transform of the GP, as it will be used to facilitate expression of the spatial processes finite dimensional distributions, which will in turn be used for specification of the likelihood for use in calibration and spatial field estimation and reconstruction.
It will also be useful to provide simple characterisations of the derivatives of the warping functions up to third order, as these will be used numerous times in the warped GP spatial field reconstruction estimation frameworks to capture the moments, mode and curvature approximations (covariance) point-wise. The derivatives of the Tukey g-and-h transform are given in Lemma 1 by simple algebra.
Lemma 1
(Derivatives of Tukey g-and-h transform).
The first three derivatives of the Tukey g-h transform are given by:
Tukey Warped Spatial Gaussian Process
One may now proceed to developing a characterisation of a warped GP spatial process based around the Tukey family of skewness and kurtosis transformations. We begin by providing a definition of the GP that will set the notation we will use to specify the spatial trend and spatial covariance operator for the input GP spatial model. This GP model will serve as our base distribution (process) to generate non-Gaussian fields, i.e., warped GP processes. Then we will show how one can construct the warped GP model based on the Tukey g-and-h random field transform.
Definition 3.
Gaussian Process (GP) [14]:
Denote by a stochastic process parameterised by , where Then, the random function is a Gaussian process if all its finite dimensional distributions are Gaussian, where for any , the random vector is jointly normally distributed [14].
We can therefore interpret a GP as formally defined by the following class of random functions:
At each point the function valued process is characterised by the mean function parameterised by , and the spatial dependence between any two points is given by the covariance function (Mercer kernel) , parameterised by , see detailed discussion in [14].
It will be useful to make the following notational definitions for the prior mean vector, cross correlation vector and auto-correlation matrix, respectively:
with is the manifold of symmetric positive definite matrices. is the covariance function.
We now provide a formal definition of the Tukey g-and-h process.
Definition 4.
Spatial Tukey Warped Gaussian Process:
Denote by a warped spatial stochastic process parameterised by points in space . Then, is a Tukey warped Gaussian Process if all its m-point finite dimensional distributions, for any , are jointly distributed according to the random vector obtained by an elementwise Tukey transformation of the underlying spatial Gaussian process on points with , given by for any , where are jointly normally distributed from a spatial Gaussian Process .
3. Properties of the Spatial Tukey Warped Gaussian Process
Having developed a basic definition of the warped GP model based on a Tukey family of warping functions, we can now study the basic properties of this spatial process by first exploring its finite dimensional distributions. Such basic finite dimensional multi-point characterisations are useful for preparing spatial field reconstruction estimators for these warped GP models. This starts with the model for a single point in space (univariate marginal warped GP model in Section 3.1), followed by specification of the properties of multiple-points in space (multivariate finite dimensional marginal warped GP model in Section 3.3).
3.1. Spatial Tukey Warped Gaussian Characterisation at a Single Point in Space
At any point in space one may consider the properties of the single location warped GP model and its properties. In this case, at one location we may consider as input a standard GP with zero spatial mean and spatial covariance function k giving a Gaussian random variable . Then the baseline reference Tukey g-and-h warped random variable is obtained by setting where and to give:
In the next proposition, we demonstrate that the warped Gaussian model will include the classical Gaussian model as a limiting case. This result is most readily proven for the setting of a single point in space, where we show that has a Gaussian law under some special specification of the warping function or its parameters.
Proposition 2
(Limiting case: Gaussian distribution as a special case).
The random variable , where , in the limit and , reduces to
By setting we recover , i.e., .
Proof.
See Appendix B. □
Remark 2.
The parameter modifies the skewness relative the base distribution, in this case the Gaussian. A positive value of g indicates a positive skew in the transformed distribution and a negative value of g indicates a negative skew. The parameter h indicates a transformation in the kurtosis relative to the base distribution and to guarantee existence of moments, one may consider a restricted range such as .
We can also easily characterise the tail behaviour of the propose g-and-h warping transform to demonstrate how the h parameter in the transform is able to produce leptokurtic behaviour in the resulting warped Gaussian density. One way to understand this is to demonstrate that the resulting warped distribution function has a property of regular variation, in other words it can be expressed as a power law tail decay and a slowly varying function.
Therefore, we briefly study regular variation of a distribution of the Tukey g-and-h distribution, which is a measure of the heaviness of tails of a distribution. Later, we connect this to the existence of the n-th moment. The index of the regular variation for the Tukey g-and-h distribution has been studied in [32,39], we summarise this result below for a generic base Gaussian distribution with . It is important to understand under what conditions one has finite first and second order moments for a model with a specific kurtosis transform if one is to develop classes of linear spatial field reconstruction based on first and second moment local approximations. An advantage of the Tukey g-and-h warping function is that one can set conditions of the warping functions through simple parameter space restrictions to ensure existence of appropriate moments for use in spatial field reconstructions. The following result in Lemma 2 is meaningful to accommodate this analysis.
Lemma 2.
Consider a location and input GP random variable then the Tukey g-and-h random variable with parameters has an index of regular variation for its survival function given by:
Proof.
See Appendix C. □
3.2. Spatial Tukey Warped Gaussian Characterisation at Multiple Points in Space
One then readily extends the model development from the univariate Tukey g-and-h random variable, that characterises the warped GP model at a single location , to a multiple-location specification at points which requires specification of a multivariate Tukey g-and-h random vector . Such extensions have for instance been specified in constructions in [4,31,35] where the single point to multiple point extension is obtained by applying an element-wise Tukey g-and-h transformation to a Multivariate Normal distribution, with mean vector and covariance matrix such that based on the GP covariance kernel k at two points in space . This gives for the j-th location the transformed random variable
In understanding the basic properties of the resulting multivariate warped random vector for the Tukey g-and-h model at multiple spatial locations, we can study the exponential moments (Lemma 3) which will be instrumental in deriving many of the properties of the warped GP models spatial field reconstruction estimators.
Although the Tukey g-and-h multivariate random vector and the Tukey g-and-h processes have been defined previously in the aforementioned works. They have not been carefully studied from the perspective of deriving closed form results for their higher order cross moments or spatial moments of any order, including cross covariance, cross skewness and cross kurtosis. In this section, our goal is therefore to derive certain desirable properties which help to characterize the Tukey g-and-h processes further than just their definition.
To achieve these spatial cross moment characterisations it will be useful to first state a result for the quadratic exponential moments of a multivariate normal random vector. This form of moment structure will arise naturally when expressing the cross moments of the class of warped GP model developed under Tukey transforms. Furthermore, these closed form results will be useful for developing computationally efficient and interpretable spatial field reconstructions based on a spatial Tukey warped GP model class.
Lemma 3
(Exponential Moments of a Gaussian Random Vector).
Consider a m-variate random vector distributed as with diagonal matrix such that and , then the quadratic exponential moments of are given by:
where,
Proof.
See Appendix D. □
This result can now be developed into a core component, to characterise the raw cross moments and cross central moments, for the warped GP model. We again consider m-points in space in a vector . Let us first describe the generic equation for an m-variate raw cross moment of a spatial Tukey warped GP model.
Proposition 3
(Spatial Tukey Warped GP Raw Moments for m Points in Space).
Consider the m-point spatial Tukey warped GP model with random vector . Assume w.l.o.g. a standardised transform with location and scale parameters given by , pointwise and selected such that existence of finite cross moments of orders for holds. Then the raw spatial m-point cross moments of orders are given by:
where
and is a diagonal matrix with known elements
Proof.
See Appendix E. □
This general result is then instrumental in producing practical examples of raw m-location cross moments of the spatial Tukey warped GP model of orders denoted by as well as the centralised cross moments denoted by , which are obtained by this same identity coupled with a binomial sum expansion to accommodate the centering transform at each of the locations to .
This result generalises the previous results in the literature for moments of a Tukey g-and-h process which previously only explored pairwise ( points) second and first order moments, where as this result obviously provides generalised point cross moment expressions of any orders. This is a significant extension in characterising this family of warped GP models, which no-longer have sufficient statistics (functions) given solely by mean and covariance functions.
3.3. Practical cross Moment Special Cases for Spatial Field Reconstruction of Tukey Warped GP Models
The result in Proposition 3, whilst very general, can be used to readily express a few core identities of relevance to spatial field reconstruction estimators at multiple locations in space, when one assumes to have observations consistent with a class of spatial Tukey warped GP models.
In particular, we will state the moments and conditions for their existence in terms of the Tukey h parameter in the warping function as well as the two-point cross moments.
Corollary 1
(Single Location Central Moments of Spatial Tukey Warped Gaussian Process).
The -th central moment at location is given by:
As stated in Proposition 4 below, the results that allow one to connect the idea of regular variation to the existence of moments of a certain power are provided. One should then understand that as the tails of the distribution become heavier (as measured by the index of regular variation), the integrals involved in the calculation of moments may cease to converge to a finite value. As such, one can formally state the relationship between the moment existence and the regular variation index as follows in Proposition 4.
Proposition 4
(Existence of Moments of Single Location Spatial Tukey Warped GP).
For the -th moment to exist in Corollary 1 we have to ensure that the following inequality holds:
Proof.
The existence proof is based on the fact that the for the n-th moment to exist for a random variable, the index of regular variation of the random variable must be strictly greater than n. Thus, from Lemma 2, we get:
where , for the Tukey g-and-h process at the location . □
Next we can express, as a special case for two points in space , the cross moments of order as follows.
Corollary 2
(Two Location Cross Central Moments of Spatial Tukey Warped Gaussian Process).
The -th and the -th order cross moment between two locations and
where:
Proof.
This is direct application for points of Proposition 3. □
We note that with these results one may simply recover the mean at location with giving:
and the variance at location with as follows:
It will also be practically useful for the spatial field reconstructions to state the cross spatial covariance between the spatial field at new location and existing observed points . These cross spatial covariance results will be critical for derivation of the multiple point Spatial-Best Linear Unbiased Estimator class we term the (S-BLUE) spatial field reconstruction. Consider the joint description of a location and the locations of the observations by the set . We also define as the covariance at any two locations and . Then we obtain the following quantities using the aforementioned derivations applied to obtain these cross moments:
Having derived these properties of the Tukey g-and-h random field we are now ready to derive the results for various field reconstruction metrics.
4. Field Reconstruction for Spatial Tukey Warped Gaussian Processes
In many real world settings, for spatial field modelling and analysis, the spatial fields finite dimensional distributions or process may not be used explicitly in modelling and instead a selection of relevant point estimators will be used to characterise a statistical summary of the warped Gaussian process, in our case the Tukey g-and-h warped spatial processes. In this section, we propose estimators and show how to solve, for a variety of practically relevant spatial field point estimators, often called in spatial statistics “spatial field reconstruction” or “spatial field approximation/estimation” [7,8]. In our case, we tailored the spatial field reconstructions to three classes of estimator with varying efficacy and computational cost in construction.
We have formulated this spatial field reconstruction context in terms of classical risk minimization through a loss function formulating the class of estimator which is resolved with respect to the spatial process, namely the warped GP model. We are assuming the warped GP model is calibrated and here the exercise is not in calibration of this models hyper parameters for the spatial covariance kernel and warping skew and kurtosis parameters, namely g and h, respectively, but rather in regards to approximating efficiently point estimators for the spatial field at any collection of target locations.
In this regard we derive five different estimators for various important quantities often considered in spatial field reconstruction problems. The multi-point Minimum Mean Squared Error (MMSE) estimators, the multiple point Maximum A-Posteriori (MAP) estimators, an efficient class of multiple-point linear estimators based on the Spatial-Best Linear Unbiased (S-BLUE) estimators, and two multi-point threshold exceedance based estimators, namely the Spatial Regional and Level Exceedance estimators.
Throughout the remainder of the manuscript, in order to simplify the notation, we will denote process at location simply by . To perform spatial field reconstruction, under the assumption that the data generating process for the spatial observations is a spatial Tukey warped GP, one may approach the problem under a Bayesian paradigm. One may then develop field reconstruction estimators, at an arbitrary location , at which one has not observed the process, based on the predictive posterior density at any location in space, , denoted . Here we denote as the measurements obtained from the sensors that observe the process at N locations . This approach is widely used and is the standard in many applications in sensor networks [1,2,3,4,6,7,8,9,10]
To proceed with development of the conditional probability of prediction of the distribution of the spatial field, at unobserved location , we need to specify the warped spatial GP’s density, given in Lemma 4. This result shows how to predict the spatial field at the new unobserved location conditional on the observations of the warped GP spatial field at observed locations . Due to the structure of the warping spatial process developed, we are able to analytically express the first two moments for the predictive condition mean and covariance in close form. This is critical for efficient development of point estimators for the spatial field reconstructions that will be developed in following sections.
Lemma 4
(Predictive Posterior Density at Location ).
The predictive posterior density is given by:
where and
Note that here denotes the prior mean of all the observations and denotes a pointwise application of the inverse.
Proof.
A derivation of this conditional predictive density for a general g-and-h density with Guassian input process is given in [31]. □
Furthermore, we may derive based on this predictive density the first two predictive conditional moments which we state in the following corollaries describing the posterior mean and posterior variance of the Tukey g-h process at some arbitrary location . There are obtained explicitly using results derived in Proposition 3 and the distribution characteristics specified in Section 3.
Corollary 3
(Posterior Predictive Mean at an Arbitrary Location ).
Corollary 4
(Posterior Predictive Variance at an Arbitrary Location ).
4.1. Spatial Field Reconstruction Risk Functionals and Loss Functions
In developing estimators formally for the spatial field reconstruction we introduce a set of different loss functions. These will characterise the risk functionals to be minimized with respect to the warped GP model in order to represent the spatial field reconstructions of different estimator types. We have developed five different spatial field reconstruction estimators that we formalise below based on the conditional predictive posterior distribution.
Based on the predictive posterior density, various point estimators, like the MMSE and the MAP estimators can be derived. These estimators provide a pointwise estimator of the intensity of the spatial filed, at location . This enables us to reconstruct the whole spatial field by evaluating on a fine grid of points.
We first define a set of objective functions that covers different aspects of spatial regression and hence we calculate different estimators, each one having its special characteristic. We then derive explicitly each of the estimators in closed form expressions.
- (1)
- Minimum Mean Squared Estimator (MMSE) estimatorThe MMSE estimator minimises the MSE by utilising a squared loss function:Then, the MMSE spatial field reconstruction estimator is given byThe conditional expectation is the estimate that minimises the conditional MMSE and the minimum value is given by the conditional variance shown below:
- (2)
- Maximum A-Posteriori (MAP) estimator:The MAP estimator is the mode of the predictive posterior density and utilizes the loss function:Then, the MAP spatial field reconstruction estimator is given by
- (3)
- Spatial-Best Linear Unbiased Estimator (S-BLUE):The S-BLUE utilises the same loss function as the MMSE estimator, but is restricted to the linear family of estimators, given by:where and
- (4)
- Spatial Regional and Level Exceedance estimators:There are a few ways of characterizing the spatial exceedance of these processes, either through the region or the location of the spatial exceedance given a user defined threshold and the tolerance. The other characteristic is the level at which the random process exceeds the given threshold at a given location. We define these characterizations mathematically as follows:
- (a)
- Spatial-Regional Right Tail Exceedance (S-RTE):
- (b)
- Spatial-Regional Left Tail Exceedance (S-LTE):where T is the pre-defined threshold and is the user defined tolerance. Here we are interested in the locations at which the above exceedance is observed. The function , i.e., it is a binary map in space indicating the locations at which the process exceeds a pre-defined threshold with a specified probability . These locations may form points, lines or surfaces in . It is useful to define exceedances on both tails due to the presence of skewness and kurtosis which affects the tail behaviour asymmetrically.
- (c)
- Spatial-Level Exceedance (S-LE):Here we are interested to find the minimum quantile level at which the process exceeds the given threshold T at a given location . The function , i.e.,
Now that we have specified various metrics by which the field reconstruction can be carried out, we detail each of the estimators.
4.2. Spatial Field Reconstruction Estimator Derivations
All the aforementioned objective functions except for the S-BLUE require the knowledge of the predictive posterior distribution conditioned on the observations and the sensor locations, given in Lemma 4. We begin by deriving the classical predictive spatial field estimator based on the minimum mean square error for the warped spatial GP.
Lemma 5
(MMSE spatial field reconstruction estimator [31]).
The MMSE spatial field reconstruction function is given by the mean of the predictive posterior which is of the form similar to the one described in Corollary 3 and is given by:
The Mean Squared Error (MSE) is given by the variance of the predictive posterior which is of the form similar to the one described in Corollary 4 and is given by:
Remark 3.
The expression for the uncertainty associated with the MMSE estimate is shown in Equation (40). We can see that the expression depends on the predictive posterior density parameter , which in turn depends on the observations as seen from Lemma 4. This is significantly different from the GP, where the uncertainty does no depend on the observations and only depends on the covariances between the locations at which the data were observed. This influences applications that involve experimental design problems like sensor placement, sensor selection, etc, in that just knowing the information of the locations alone is no longer sufficient for the Tukey g-h process and repeated experiments may need to be performed for evaluating the characteristics of just one location set.
Remark 4.
Note that the existence of the MMSE at a location is given by, . We also know that . This means that for a given value of the parameter h, there may arise a case when the Tukey g-and-h population mean at a location does not exist but the conditional mean can exist. This is because as we gather observations around the location of interest, we reduce and hence the effect of the kurtosis parameter on the conditional MMSE.
Proposition 5
(MAP spatial field reconstruction estimator:).
The spatial MAP estimator is obtained from the solution to the following optimisation problem:
where is the solution to the following optimsation problem.
Proof.
See Appendix F. □
Remark 5.
The optimisation problem in specified in Proposition 5, to obtain the MAP estimate of the Tukey g-and-h process at a location does not admit analytical solutions and hence has to be dealt with numerically. To this end, one can solve this one-dimensional optimisation through standard techniques such as Newton methods adopting a simple gradient descent (since we can obtain the derivatives of this expression at all values of ).
Proposition 6
(MAP spatial variance:).
The variance of the spatial MAP estimator is given by the hessian of the posterior GH distribution at a location , evaluated at the optimum value obtained from Proposition 5. It is represented as follows:
where is the mode of the GH distribution at and is the Gaussian pdf with mean and variance as derived in Lemma 4.
Proof.
See Appendix G. □
We now state a few corollaries for finding the solution to the optimisation problem posed for finding the MAP estimate at any arbitrary location. These are the cases when the parameters and .
Proposition 7
(S-BLUE spatial field reconstruction estimator:).
The Spatial-Best Linear Unbiased Estimator (S-BLUE) at any location is given by:
where and . In addition, is just the prior mean of the observations .
The exceedance problem of the Tukey g-and-h process, as described in the objective functions, given by Equations (36) and (37) are reduced to the problem of obtaining the multivariate quantile level sets of the process at d locations. First we look at univariate description of the quantile function at just one location. Then we will see that the existence of a tractable quantile Tukey g-and-h function enables us to reduce the exceedance problems to the description of these quantile function along with the user given parameters.
To proceed with these results it will be useful to state the following Lemma 6 that provides expressions for the marginal and conditional quantile functions of the Tukey g-and-h process.
Lemma 6
(Marginal and Conditional Quantile functions of the Tukey g-and-h process).
- (1)
- Marginal Quantile Function:The univariate marginal quantile function of the Tukey g-and-h process at any arbitrary location is described as follows:where , and denotes the inverse cdf of the standard normal distribution.
- (2)
- Conditional Quantile Function:The univariate conditional quantile function of the Tukey g-and-h process at any arbitrary location is described as follows:where . Furthermore, is the inverse cdf of the standard normal distribution.
Proof.
See Appendix H. □
Proposition 8
(Spatial region of right tail exceedance estimator).
The region of right tail exceedance described in Equation (36) is reduced to finding the quantile level sets at the user given tolerance to see if it exceeds the given threshold. This is a binary estimate at location , that is characterized by:
where is the quantile as seen from Lemma 6. The region is created by accumulating all the locations that produce 1 in the binary estimate.
Remark 6.
We note that derivation of the left tail exceedance spatial field reconstruction estimator follows analogously the result obtained in Proposition 8 with a reversal of the inequality and a quantile level
Proposition 9
(Spatial level of exceedance estimator).
The region of exceedance described in Equation (38) is reduced to finding the quantile level sets at the user given tolerance to see if it exceeds the given threshold. This is a binary estimate at location , that is characterized by:
where as seen in Lemma 6.
Note that in Propositions 8 and 9, we used to denote the unobserved spatial field location. In these cases the quantile function is essentially the conditional quantile function from the conditional predictive posterior distribution obtained in Lemma 4.
5. Experimental Results: Warped Gaussian Process Spatial Field Reconstructions
In this section, we look at results concerning spatial field reconstruction based on a warped GP model of the Tukey g-and-h family of spatial processes. We consider both central estimators of spatial field as well as exceedance spatial maps. We compare the warped GP reconstructions of the Tukey g-and-h processes to those one would obtain had one miss-specified the model and applied a classical standard GP field reconstruction. It is of interest to assess the ability of the Tukey g-and-h process to detect attributes of spatial skewness and kurtosis, compared to the GP in a range of different settings. We consider both synthetic as well as real data studies to illustrate the Tukey g-and-h model developed.
5.1. Simulation Setup
In these case studies we model the physical phenomenon or spatial process that is partially observed by a Tukey transformation of an underlying GP over a spatial grid where and . We work with the well known squared exponential kernel, with a known unit variance and known length-scale. We also subtract the mean to obtain a zero mean GP. Furthermore, the parameters are assumed to be known and are set to different values within the allowable range, to test various cases. This allows us to demonstrate, on a synthetic case study, the importance of developing spatial field reconstructions that accommodate warped spatial GP structures for spatial skewness and kurtosis by comparing the loss in accuracy if one applies just a standard GP model.
Moreover, we have N sensors with known locations, spread uniformly over the spatial grid region of interest. We vary N to study the effect of the number of sensors on different regression estimators. To this end, we use the normalised spatial mean squared error (N-MSE) to characterize the performance of the different estimators and we define it as follows:
where J is the number of spatial locations to regress and T is the number of trials of the Tukey g-and-h process simulation. In addition, is the maximum value of the simulated process across all locations and trials and similarly is the minimum value of the simulated process.
We outline the following test scenarios studied in this setting.
- (1)
- Scenario 1: We compare the performance of the different estimators such as, MMSE (Equation (39)), S-MAP (Equation (41)), S-BLUE (Equation (35)) to the Gaussian Process estimate in various scenarios such as, small g and h with low spatial correlation, high spatial correlation and other such combinations of g, h and l.
- (2)
- Scenario 2: We characterize the exceedance estimation ability of the Tukey g-and-h process as shown in Proposition 8 (g,h), through spatial ROC curves compared to a Gaussian process.
- (3)
- Scenario 3: We adopt real data case studies for the US and we apply our estimators on the noisy observed US precipitation data sets [40]. We consider a spatial field reconstruction that involves latitudes between 34 and 43 degrees and longitudes between −110 and −100 degrees and we compare the different spatial field reconstruction estimators and their performance on real data versus a classical Gaussian process model.
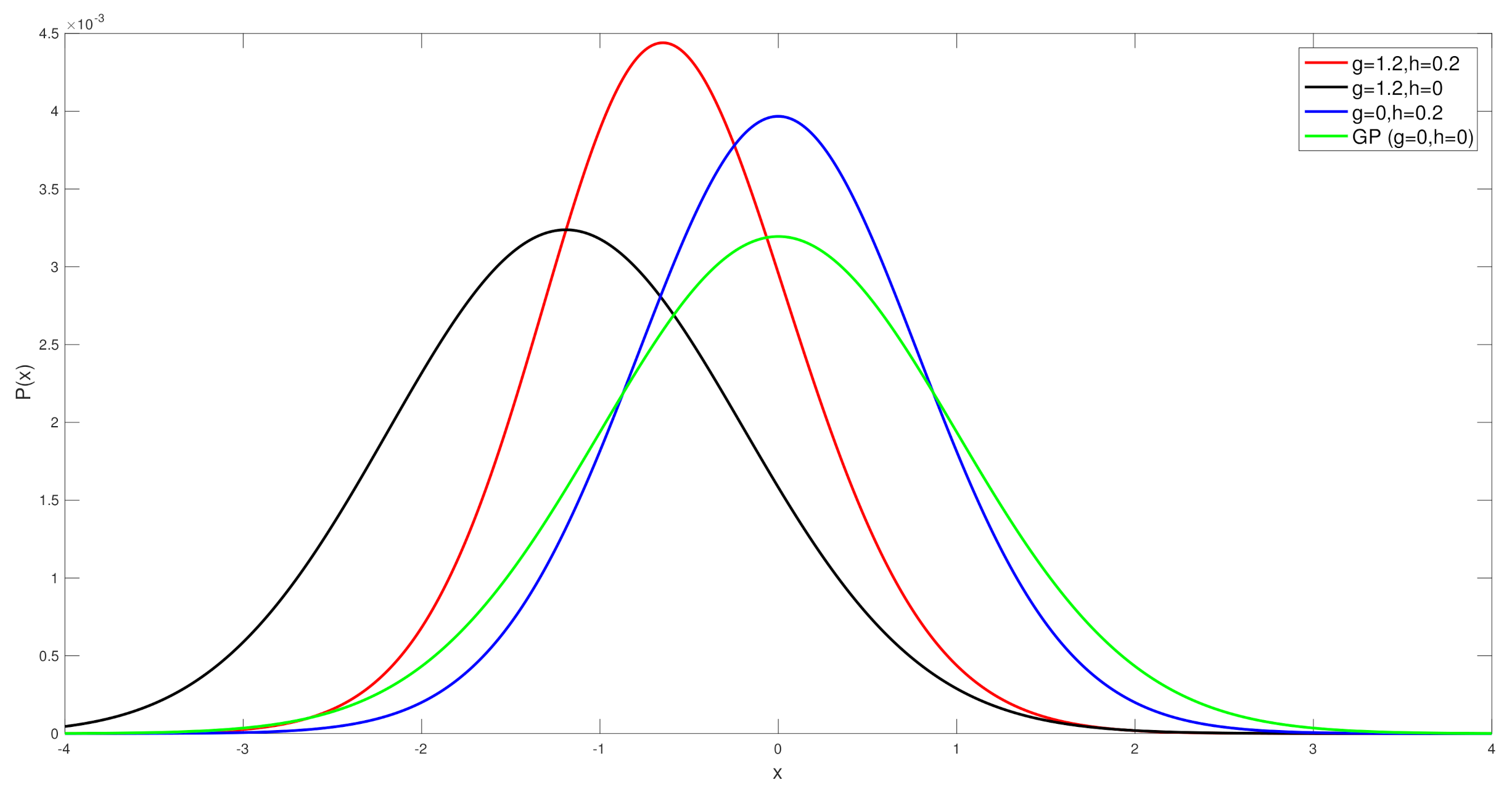
Before we look at the simulation results, we show the actual differences in the distribution of the Tukey g-and-h finite dimensional distribution, with the parameters that are used in the simulation case studies, in order to compare to the Gaussian distribution, see Figure 1. This allows us to demonstrate clearly that at each spatial field location one would expect that skewness and kurtosis will be meaningful to consider in constructing the spatial field reconstruction estimators.
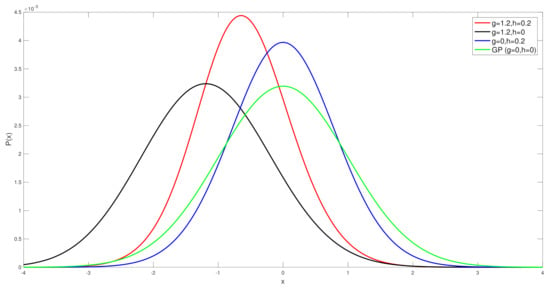
Figure 1.
Comparison of the standard Gaussian distribution to the Tukey g-and-h distributions with values from .
5.2. Scenario 1: Spatial Field Reconstruction on Synthetic Data
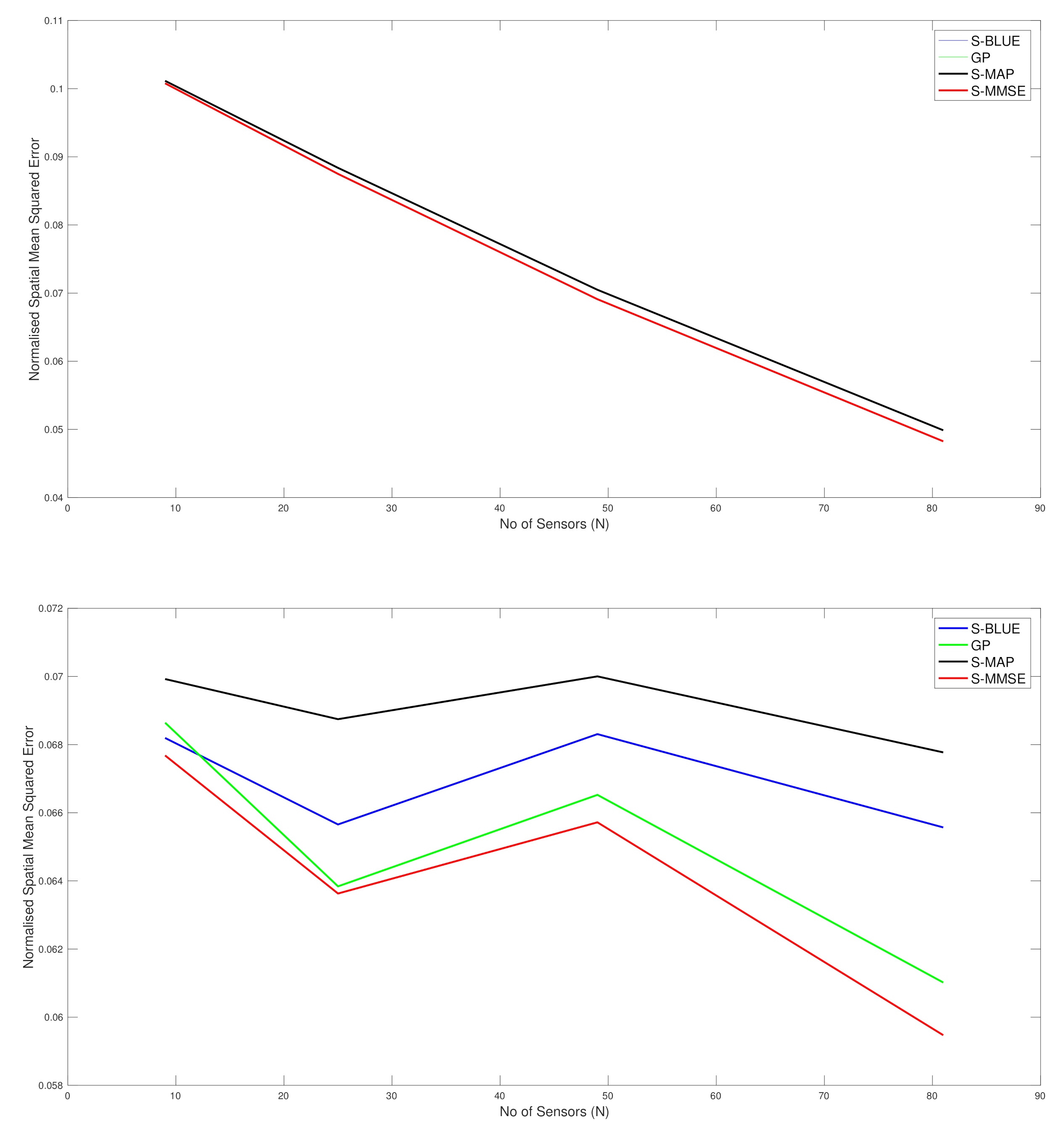
In this section, we present the estimation performance of the Spatial-BLUE estimator, GP estimator, Spatial-MAP estimator and the Spatial MMSE estimator. The results here are shown for a synthetic data set constructed with given parameter values for g, h and l, using a squared exponential kernel. The study utilised 50 realisations of the Tukey g-and-h random field and the average spatial Mean Squared Error reported below is the average across the 50 realisations and all the locations in space where the field was reconstructed. To study the variation across the number of sensors, we used and spread it uniformly across the field.
As we can see in the first top sub-figure in Figure 2, this is the situation in which the true spatial field process is very close to Gaussian as the settings was used and therefore with both l values only two curves are seen for the different spatial field reconstructions and they are basically almost indistinguishable. The difference reflects the very slight skew and kurtosis still present in the target warped spatial Gaussian process since g and h were not set exactly to 0. Basically in this scenario we see that the curve associated with the S-BLUE and the S-MAP coincide, as is the case with the S-MMSE and the GP curves. Furthermore all the estimators perform better as the number of sensors increase. Overall the difference in the reconstruction accuracy is negligible between the four estimators as is expected since the values of g and h are very close to 0 as is to be expected. This is simply a case study to illustrate that our spatial field reconstructions for the warped spatial GP model can recover a classical GP reconstruction if the target spatial field truly has this characterisation.
In the bottom subplot of Figure 2, we see that with some significant increase in g and h values that adds to the warped spatial GP skewness and kurtosis, then in this case the standard GP spatial field reconstructions degrade in accuracy. The classical GP estimate is unable to account for the significant non-linearities in the transform that induce the skewness and kurtosis in the spatial field, while the other estimators that we have derived for spatial field reconstruction specifically in the setting of warped spatial GP significantly outperform the classical GP reconstructions of comparative loss functional type, especially as the number of sensors increase. We also observe that the linearisation of the spatial field reconstruction provides an efficient estimator computationally compared to the MMSE estimator but the cost of this computational efficiency is a loss in accuracy due to the attempt to linearise locally the highly non-linear spatial field warping transforms. We see that it becomes particularly effective to use an efficient linear S-BLUE estimator in settings in which observation coverage is sparse and sensors are placed sparsely in the spatial region of interest. In these cases we show that the S-BLUE estimator performs comparatively with the more computationally expensive MMSE estimators.
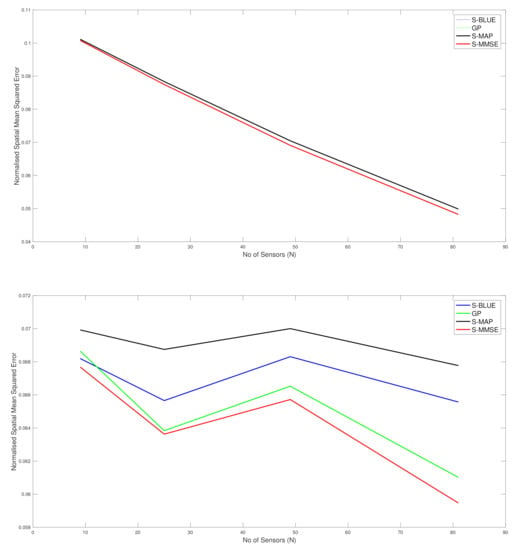
Figure 2.
Plots of comparison of the N-MSE as a function of number of sensors (N). Top Subplot: , , . Bottom Subplot: , , .
Figure 2.
Plots of comparison of the N-MSE as a function of number of sensors (N). Top Subplot: , , . Bottom Subplot: , , .
5.3. Scenario 2: Spatial Exceedance on Synthetic Data
In the exceedance examples, we characterize the spatial region of exceedance estimator (Proposition 8) and its left tail equivalent, and the region of exceedance (Proposition 9). We treat these problems as a detection problem, since we obtain a binary estimate at each location. We characterize such performance via plots of the Receiver Operating Characteristic (ROC) curves associated with different values of N. In these illustrations we use and the threshold is varied from the minimum value of the realisations of the Tukey g-and-h field to the maximum value of the realisations. Once the predictive distribution is obtained at the target locations, we calculate the binary estimate of exceedance at each target location and finally to obtain the required probabilities of detection and false alarms, we collate the proportion of false alarms and correct detection at all locations and get the probabilities of false alarms and detection.
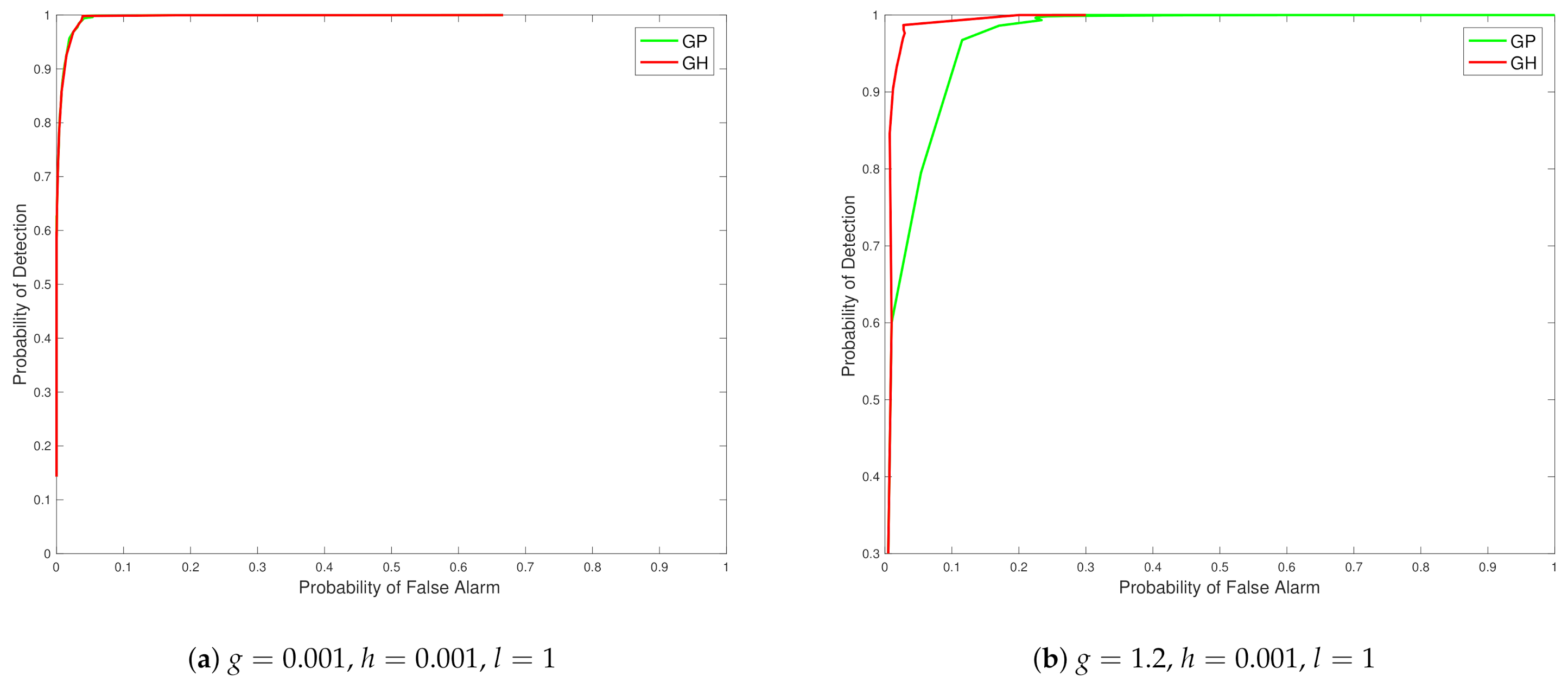
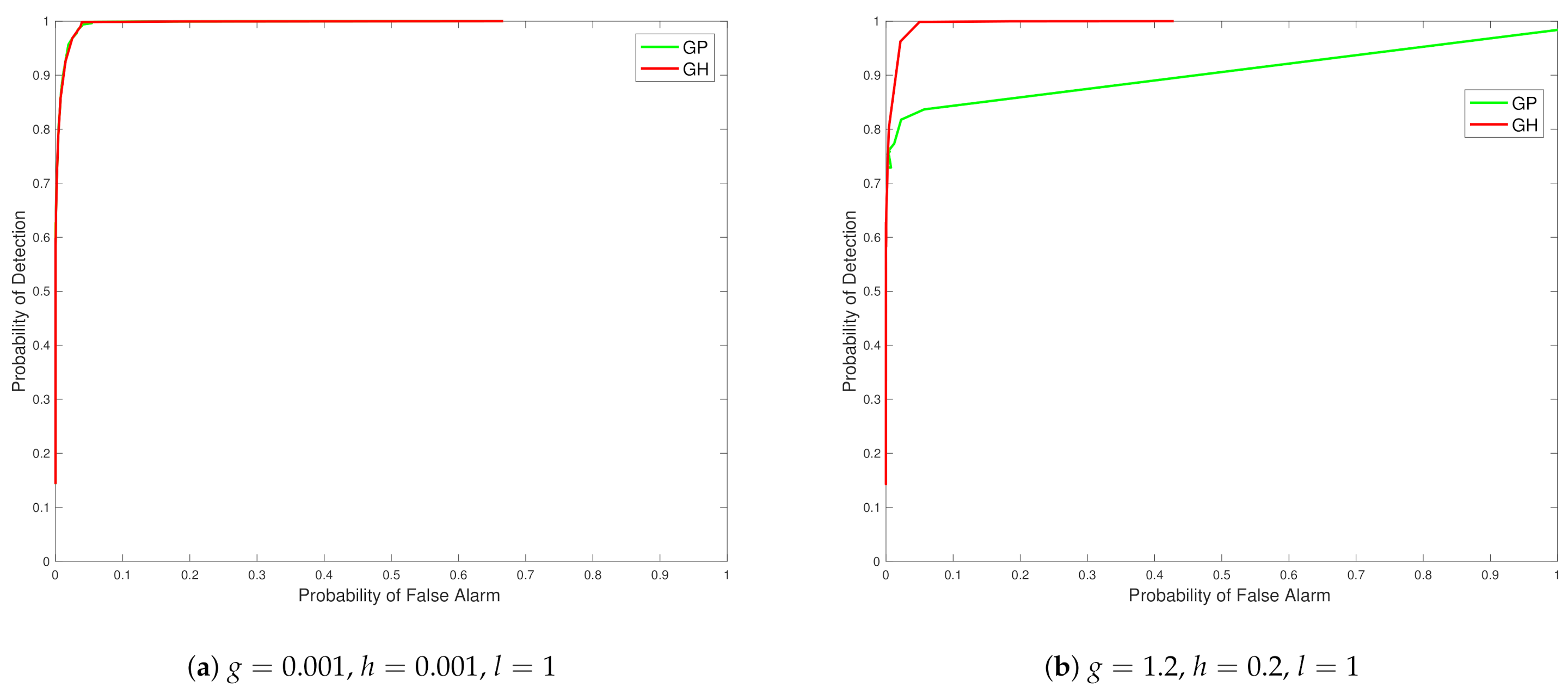
From the ROC curves in Figure 3 we see that the Tukey g-and-h distribution in different cases outperforms the Gaussian process in all the scenarios created, with closest performance, in Figure 3 subplot a, corresponding to cases when the generated synthetic data is from settings of g and h parameters in which the data generating mechanism is closest to no skewness or kurtosis effects. The case of a distinct model with regard to a Gaussian model, where skewness and kurtosis is non-negligible, is then shown in Figure 3 subplot b.
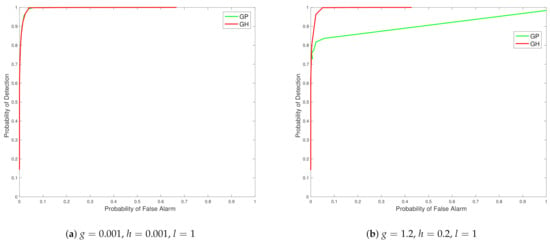
Figure 3.
Plots of ROC curves comparing the Tukey g-and-h distribution to the Gaussian process for different values of g and h.
Now Figure 4 contains the ROC curve corresponding to , and . In subfigure a of Figure 4 one can see a scenario case that is close again to the Gaussian setting, with the difference between the case in Figure 3 subplot a being purely the scale parameter of the covariance kernel function, l. Therefore, as expected we see very close performance in the ROC curve in this setting when comparing the Gaussian and Tukey g-and-h models. In Figure 4 subplot b, we see the case with high positive skew and almost zero kurtosis. We notice that the false alarm rate for the quantile exceedance is extremely low and specifically we defined the exceedance as the right tail exceedance. This may be due to the fact that the estimation of the Tukey g-and-h posterior, at all the target locations, depend on the data from the sensors which tend to be considerably positively skewed (), without heavy tails. Since, the GP estimation involves the actual observations (without any transformation), the predictive distribution tends to have a mean with a high positive value and since there is the asymmetry and the lack of heavy tails, the GP also exhibits a reasonably low false alarm rate for the right tail exceedance that is comparable to the Tukey g-and-h process. However, for the same case if we calculate the left tail exceedance as characterized in Proposition 9, we notice that these ROC curves exhibit a higher range of false alarms and detection rate and we obtain the following figure.
In addition, we observed that when we considered the case , , which is negatively skewed with 0 kurtosis, we noticed that the above trend is reversed, i.e., the right tail exceedance exhibited a larger false alarm rate and the left tail exceedance exhibited a very small rate of false alarms.

Figure 4.
Plots of ROC curves comparing the Tukey g-and-h distribution to the Gaussian process for different values of g and h.
Figure 4.
Plots of ROC curves comparing the Tukey g-and-h distribution to the Gaussian process for different values of g and h.
5.4. Scenario 3: Spatial Field Reconstruction on Real Spatial Sensor Data for Hourly Precipitation
In this section, we show results of spatial field reconstruction on the US precipitation dataset, available at https://www.ngdc.noaa.gov (accessed on 1 January 2020). This shows the hourly precipitation in digital data set DSI-3240, archived at the National Climatic Data Center (NCDC). It is obtained from US National Weather Service (NWS), Federal Aviation Administration (FAA), and cooperative observer stations in the United States of America, Puerto Rico, the US Virgin Islands, and various Pacific Islands. We extract data for one month (November 1994) from the sensors within the area shown in the map in Figure 5.
Here, to evaluate the performance of our estimators, we estimate the parameters from the US precipitation dataset corresponding to the data from the above locations. For both the Tukey g-and-h and the GP we use an underlying GP with zero mean and a squared exponential kernel where the length-scale and the variance are estimated appropriately. In addition, the Tukey g-and-h requires estimation of two additional parameters namely the skew parameter g and the kurtosis parameter h. After a maximum likelihood estimation in both cases, we obtain the estimates of the Tukey g-and-h to be , , and and the estimates for the GP are and .
Additionally, we define a normalised version of the median of absolute deviations for the comparison of our estimates on the real data. It is defined as follows:
where J is the number of spatial locations to regress and T is the number of trials of the Tukey g-and-h process simulation. In addition, is the maximum value of the simulated process across all locations and trials and similarly is the minimum value of the simulated process.
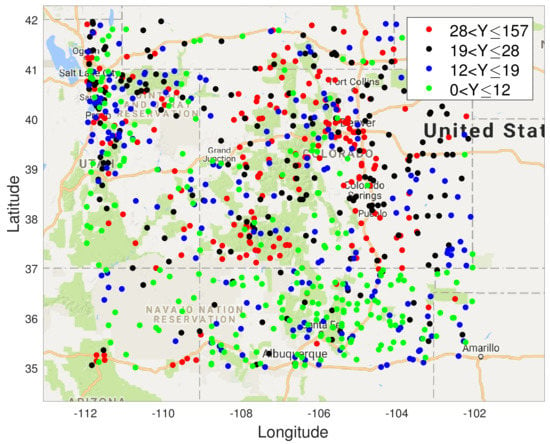
Figure 5.
USA map with sensor locations measuring precipitation in 4 states showing the average precipitation for the month of November 1994 at 850 locations. The values (in mm) are colour coded according to the ranges shown.
Figure 5.
USA map with sensor locations measuring precipitation in 4 states showing the average precipitation for the month of November 1994 at 850 locations. The values (in mm) are colour coded according to the ranges shown.
In Figure 6 and Figure 7 we show results for a real data spatial field reconstructions for the S-Blue, GP, S-MAP and S-MMSE results. In Figure 7, we see that the ratio
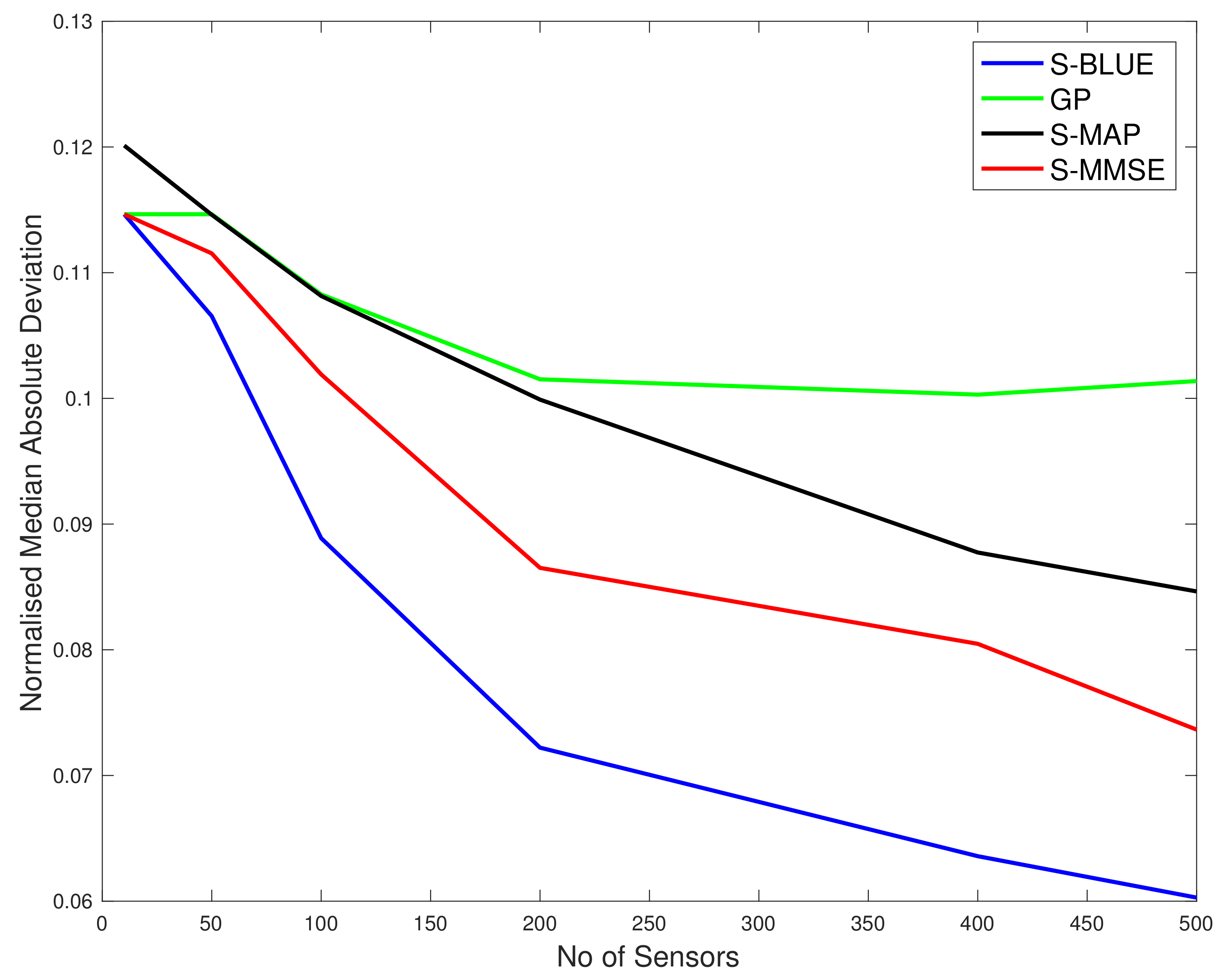
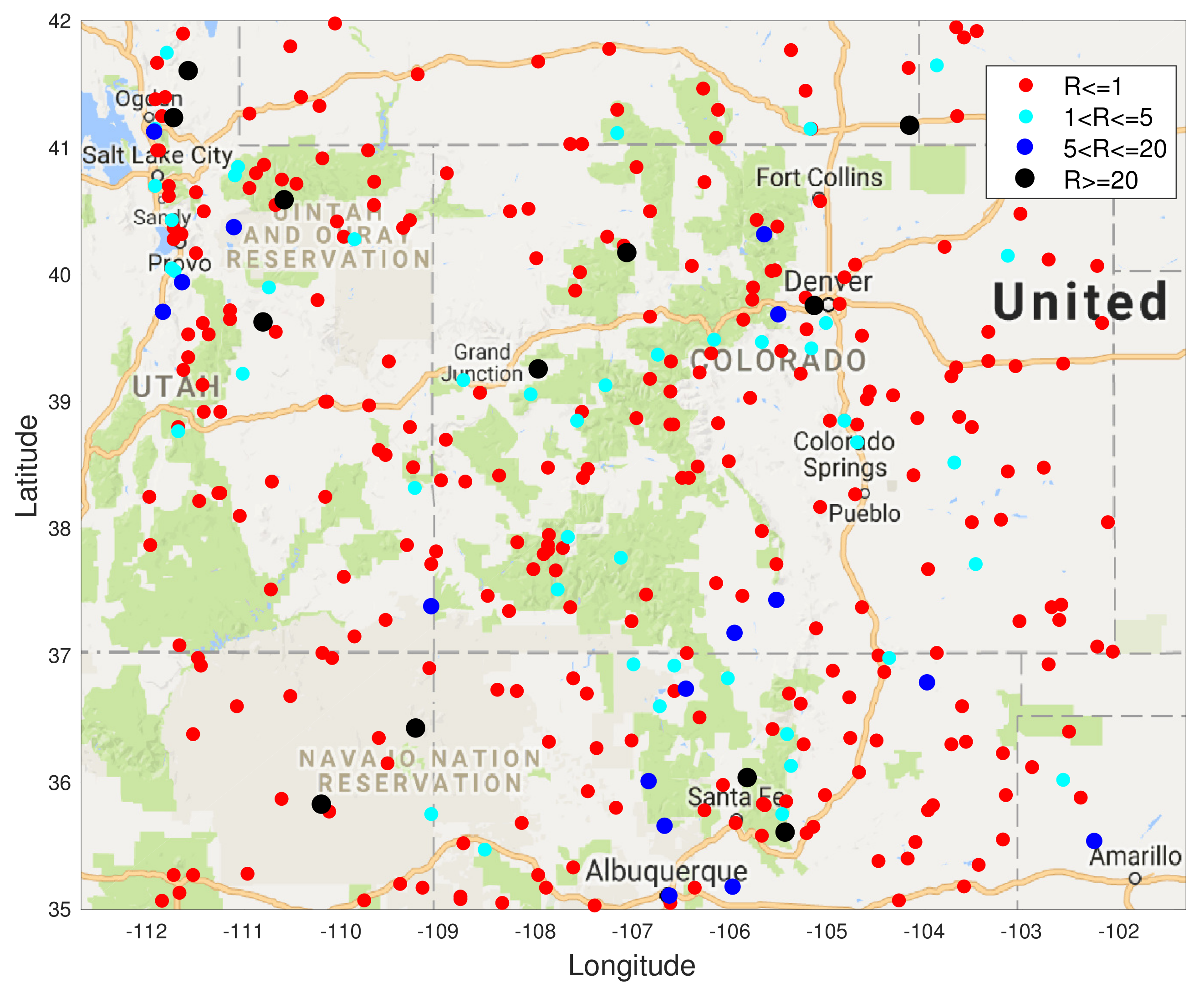
in the majority (80%) of the test locations is less than or equal to 1, which means that the S-BLUE estimator performs better than the GP at those locations. The light blue markers indicated the locations where this ratio is between 1 and 5, which is around 11% of the test data. Similarly the dark blue markers and the black markers represent the small percentage of the locations where the GP performs better than the S-BLUE. We notice that these locations are generally concentrated in the corners of the grid, which might explain the presence of a few outliers as the main factor that affects the estimates is the covariance between the test location and the sensor locations. We can see from Figure 6, any estimator of the Tukey g-and-h process performs much better than the GP. Particularly in both cases the S-BLUE estimate performs the best in this case and this maybe because in the real data we do not have multiple realisations of the data, thus to get a good estimate we should exploit the spatial information well and the S-BLUE estimate does that precisely, as it requires the spatial Tukey g-and-h covariance, which enables it to produce better estimates and these estimates improve as the number of sensor locations having data increase. Moreover, we notice that the N-MSE of the GP increases as the number of sensors increases and this shows that we are fitting the data with a model that is biased.
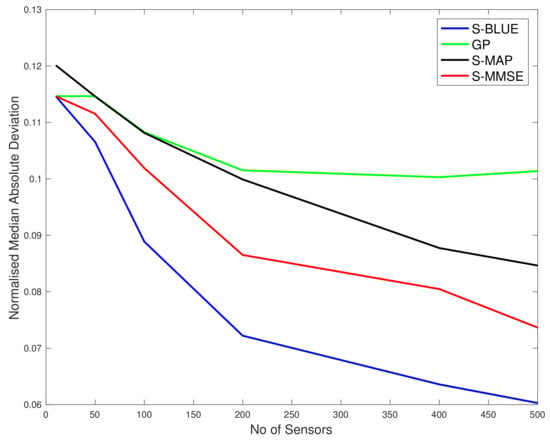
Figure 6.
The N-MAD comparison between the various Tukey g-and-h estimators and the Gaussian process.
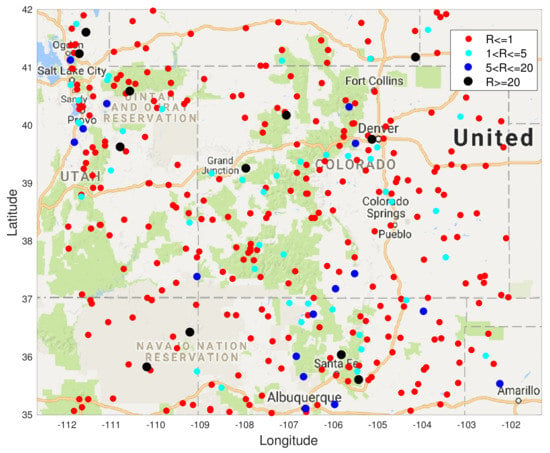
Figure 7.
The ratio R of the N-MSE of the S-BLUE estimate and the GP estimate at each of the test locations when , i.e., 500 locations were used as the training set.
6. Conclusions
We study in detail various aspects regarding Tukey g-and-h processes from its construction and derivation of n-variate cross moments, which helped us develop three different estimators for spatial regression, the MMSE, S-BLUE and the S-MAP. We discuss their derivation through the predictive posterior distribution. In addition, we define the right tail and the left tail exceedance estimators using the quantile level sets of these processes. Finally, we test the performance of our estimators on a simulated data setting and the US precipitation dataset. We find that although the Gaussian process is a useful model, we show that it suffers when the data exhibits heavy-tailedness and/or skewness, where the Tukey g-and-h process is better suited and is also practically applicable. The flexibility of the construction and the estimation of the Tukey g-and-h process can enable us to incorporate even more complex spatial and temporal patterns through different kernels much like the Gaussian process whilst enabling a way to account for non-Gaussian behaviour which arises in many real world applications.
Author Contributions
Conceptualization, G.W.P. and I.N.; methodology, G.W.P., I.N. and S.G.N.; software, S.G.N. and I.N.; validation, G.W.P., I.N. and S.G.N.; formal analysis, G.W.P. and I.N.; investigation, G.W.P. and I.N.; resources, T.M. and I.N.; data curation, I.N.; writing—original draft preparation, G.W.P., I.N. and S.G.N.; writing—review and editing, G.W.P., I.N. and T.M.; visualization, I.N.; supervision, I.N., G.W.P. and T.M.; project administration, I.N.; funding acquisition, T.M. and I.N. All authors have read and agreed to the published version of the manuscript.
Funding
Funding was provided for research travel by T.M. and the Institute of Statistical Mathematics.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All real data utilised is available at the cited source location.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Proposition 1
To prove that the inverse of the transformation exists we prove that it is a bijection.
Firstly, we notice that the transformation is continuous in , since it is essentially the difference of two exponential functions. The Intermediate Value Theorem states that if a function f is continuous in an interval and , then there exists such that . We apply a version of this theorem to a function f that is continuous in an open interval.
Now , where this function is continuous in . Let and . Since for any arbitrary and since is continuous in this interval then there exists a such that . Hence this function is surjective.
To prove that it is injective, we use the derivative information presented in Lemma 1. The first derivative of the Tukey g-and-h transform is given by:
We know that the kurtosis parameter is always non-negative and hence we need to find the sign of , since is always positive.
Consider , we then have that
From the above expression to determine the sign of M, we just have to consider the sign of . We know that when , and when , , and therefore .
Hence the derivative is positive and this means that the transform is strictly increasing and as a result it is injective. Since it is surjective and injective, we show that this Tukey g-and-h transformation has an inverse.
Appendix B. Proof of Proposition 2
We have the random variable , where . Then we have that
The limit of the function as and is given by:
Let, and . Now the functions are separable in g and h, and the limit exists and can be evaluated separately if and only if the limits in g and h exist independently. We know that:
Both the limits exist independently in g and h. Hence, . Furthermore, we know that . Then Finally,
As a corollary, the special case when, and , we get
Appendix C. Proof of Proposition 2
The index of regular variation for the survival function associated with random variable Y is where:
For a generic transformation with parameters , let be the Gaussian pdf of the underlying distribution and be the Gaussian cdf and let . Then, to find the limit we do as follows:
Let and . We get by repeatedly applying L-Hospitals rule and . Hence .
Appendix D. Proof of Lemma 3
We begin by writing an explicit expression for the expectation:
Now consider the integrand of the high-dimensional integral shown above. We would like to complete the squares of this term, in order to get an unnormalised multivariate normal pdf, such that we can evaluate this integral with ease. In this regard, we do the following:
Now substituting this results into the integral we obtain that:
where
Appendix E. Proof of Proposition 3
We begin by using Equation (3)
The last line can be obtained from Lemma 3, using the following substitution
Which gives us the following result:
where
Appendix F. Proof of Proposition 5
Appendix G. Proof of Proposition 6
The uncertainty is given by the second derivative of the GH distribution at location evaluated at the mode of the distribution , which is obtained by solving the optimisation problem in Proposition 5. Our goal is to get the following quantity:
Hence evaluating at , we get:
Appendix H. Proof of Lemma 6
Let us consider the Tukey g-h process at a location , then , where .
Rewriting the above equation in terms of the quantile function we get:
We can apply the same proof to the Tukey g-h process at location , where we replace , by the predictive posterior parameters, which gives us the conditional quantile function.
References
- Hart, J.K.; Martinez, K. Environmental sensor networks: A revolution in the earth system science? Earth-Sci. Rev. 2006, 78, 177–191. [Google Scholar] [CrossRef] [Green Version]
- Rajasegarar, S.; Havens, T.C.; Karunasekera, S.; Leckie, C.; Bezdek, J.C.; Jamriska, M.; Gunatilaka, A.; Skvortsov, A.; Palaniswami, M. High-resolution monitoring of atmospheric pollutants using a system of low-cost sensors. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3823–3832. [Google Scholar] [CrossRef]
- Kottas, A.; Wang, Z.; Rodríguez, A. Spatial modeling for risk assessment of extreme values from environmental time series: A Bayesian nonparametric approach. Environmetrics 2012, 23, 649–662. [Google Scholar] [CrossRef]
- Murakami, D.; Peters, G.W.; Yamagata, Y.; Matsui, T. Participatory sensing data tweets for micro-urban real-time resiliency monitoring and risk management. IEEE Access 2016, 4, 347–372. [Google Scholar] [CrossRef]
- Stahl, K.; Moore, R.; Floyer, J.; Asplin, M.; McKendry, I. Comparison of approaches for spatial interpolation of daily air temperature in a large region with complex topography and highly variable station density. Agric. For. Meteorol. 2006, 139, 224–236. [Google Scholar] [CrossRef]
- Zhang, X.; Srinivasan, R. GIS-Based Spatial Precipitation Estimation: A Comparison of Geostatistical Approaches1. JAWRA J. Am. Water Resour. Assoc. 2009, 45, 894–906. [Google Scholar] [CrossRef]
- Nevat, I.; Peters, G.W.; Septier, F.; Matsui, T. Estimation of spatially correlated random fields in heterogeneous wireless sensor networks. IEEE Trans. Signal Process. 2015, 63, 2597–2609. [Google Scholar] [CrossRef] [Green Version]
- Nevat, I.; Peters, G.W.; Collings, I.B. Random field reconstruction with quantization in wireless sensor networks. IEEE Trans. Signal Process. 2013, 61, 6020–6033. [Google Scholar] [CrossRef]
- Nevat, I.; Peters, G.W.; Septier, F.; Matsui, T. Wind storm estimation using a heterogeneous sensor network with high and low resolution sensors. In Proceedings of the IEEE International Conference on Communications (ICC 2015), London, UK, 8–12 June 2015; pp. 4865–4870. [Google Scholar]
- Thorarinsdottir, T.L.; Gneiting, T. Probabilistic forecasts of wind speed: Ensemble model output statistics by using heteroscedastic censored regression. J. R. Stat. Soc. Ser. (Stat. Soc.) 2010, 173, 371–388. [Google Scholar] [CrossRef]
- Rajaona, H.; Septier, F.; Armand, P.; Delignon, Y.; Olry, C.; Albergel, A.; Moussafir, J. An adaptive Bayesian inference algorithm to estimate the parameters of a hazardous atmospheric release. Atmos. Environ. 2015, 122, 748–762. [Google Scholar] [CrossRef]
- Hua, X.; Ono, Y.; Peng, L.; Cheng, Y.; Wang, H. Target detection within nonhomogeneous clutter via total Bregman divergence-based matrix information geometry detectors. IEEE Trans. Signal Process. 2021, 69, 4326–4340. [Google Scholar] [CrossRef]
- Ollila, E.; Tyler, D.E.; Koivunen, V.; Poor, H.V. Compound-Gaussian clutter modeling with an inverse Gaussian texture distribution. IEEE Signal Process. Lett. 2012, 19, 876–879. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Banerjee, S.; Gelfand, A.E.; Finley, A.O.; Sang, H. Gaussian predictive process models for large spatial data sets. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2008, 70, 825–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gramacy, R.B.; Apley, D.W. Local Gaussian process approximation for large computer experiments. J. Comput. Graph. Stat. 2015, 24, 561–578. [Google Scholar] [CrossRef]
- Gu, D.; Hu, H. Spatial Gaussian process regression with mobile sensor networks. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1279–1290. [Google Scholar]
- Cressie, N.A. Statistics for Spatial Data; Wiley Online Library: River Street Hoboken, NJ, USA, 1993. [Google Scholar] [CrossRef]
- Gneiting, T.; Genton, M.G.; Guttorp, P. Geostatistical space-time models, stationarity, separability, and full symmetry. Monogr. Stat. Appl. Probab. 2006, 107, 151. [Google Scholar]
- Genton, M.G. Skew-Elliptical Distributions and Their Applications: A Journey beyond Normality; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Tagle, F.; Castruccio, S.; Genton, M.G. A Multi-Resolution Spatial Model for Large Datasets Based on the Skew-t Distribution. arXiv 2017, arXiv:1712.01992. [Google Scholar]
- Ley, C. Flexible modelling in statistics: Past, present and future. J. Société Française Stat. 2015, 156, 76–96. [Google Scholar]
- Rubio, F.J. Modelling of Kurtosis and Skewness: Bayesian Inference and Distribution Theory. Ph.D. Thesis, University of Warwick, Coventry, UK, 2013. [Google Scholar]
- Galton, F. The geometric mean, in vital and social statistics. Proc. R. Soc. Lond. 1879, 29, 365–367. [Google Scholar]
- Edgeworth, F.Y. XLII. The law of error and the elimination of chance. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1886, 21, 308–324. [Google Scholar] [CrossRef]
- Pearson, K. Contributions to the mathematical theory of evolution. Philos. Trans. R. Soc. London. 1894, 185, 71–110. [Google Scholar]
- Fechner, G.T. Kollektivmasslehre; Engelmann: Leipzig, Germany, 1897. [Google Scholar]
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Hoaglin, D.C.; Peters, S.C. Software for Exploring Distribution Shape; Laboratory for Information and Decision Systems, Massachusetts Institute of Technology: Cambridge, MA, USA, 1979. [Google Scholar]
- Hoaglin, D.C. Summarizing shape numerically: The g-and-h distributions. In Exploring Data Tables, Trends, and Shapes; Wiley: New York, NY, USA, 1985; pp. 461–513. [Google Scholar]
- Xu, G.; Genton, M.G. Tukey g-and-h Random Fields. J. Am. Stat. Assoc. 2017, 112, 1236–1249. [Google Scholar] [CrossRef]
- Peters, G.W.; Chen, W.Y.; Gerlach, R.H. Estimating Quantile Families of Loss Distributions for Non-Life Insurance Modelling via L-Moments. Risks 2016, 4, 14. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.Y.; Peters, G.W.; Gerlach, R.H.; Sisson, S.A. Dynamic Quantile Function Models. Quant. Financ. 2021. to appear. [Google Scholar] [CrossRef] [Green Version]
- Peters, G.W.; Sisson, S. Bayesian Inference, Monte Carlo Sampling and Operational Risk. J. Oper. Risk 2006, 1, 27–50. [Google Scholar] [CrossRef]
- Field, C.; Genton, M.G. The multivariate g-and-h distribution. Technometrics 2006, 48, 104–111. [Google Scholar] [CrossRef]
- Jeong, J.; Yan, Y.; Castruccio, S.; Genton, M.G. A Stochastic Generator of Global Monthly Wind Energy with Tukey g-and-h Autoregressive Processes. arXiv 2017, arXiv:1711.03930. [Google Scholar] [CrossRef] [Green Version]
- Cruz, M.G.; Peters, G.W.; Shevchenko, P.V. Fundamental Aspects of Operational Risk and Insurance Analytics: A Handbook of Operational Risk; John Wiley & Sons: New York, NY, USA, 2014. [Google Scholar]
- Tukey, J.W. Modern techniques in data analysis. In Proceedings of the NSF-Sponsored Regional Research Conference; Southern Massachusetts University: North Dartmouth, MA, USA, 1977. [Google Scholar]
- Degen, M.; Embrechts, P.; Lambrigger, D.D. The quantitative modeling of operational risk: Between g-and-h and EVT. ASTIN Bull. J. Iaa 2007, 37, 265–291. [Google Scholar] [CrossRef] [Green Version]
- US Precipitation Data Web-Site. 2015. Available online: https://www.ncdc.noaa.gov/cdo-web/ (accessed on 1 January 2020).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).