Abstract
We present new PAC-Bayesian generalisation bounds for learning problems with unbounded loss functions. This extends the relevance and applicability of the PAC-Bayes learning framework, where most of the existing literature focuses on supervised learning problems with a bounded loss function (typically assumed to take values in the interval [0;1]). In order to relax this classical assumption, we propose to allow the range of the loss to depend on each predictor. This relaxation is captured by our new notion of HYPothesis-dependent rangE (HYPE). Based on this, we derive a novel PAC-Bayesian generalisation bound for unbounded loss functions, and we instantiate it on a linear regression problem. To make our theory usable by the largest audience possible, we include discussions on actual computation, practicality and limitations of our assumptions.
1. Introduction
Since its emergence in the late 1990s, the PAC-Bayes theory (see the seminal works of [1,2,3], the recent survey by [4] and work by [5]) has been a powerful tool to obtain generalisation bounds and to derive efficient learning algorithms. Generalisation bounds are helpful for understanding how a learning algorithm may perform on future similar batches of data. While the classical generalization bounds typically address the performance of individual predictors from a given hypothesis class, PAC-Bayes bounds typically address a randomized predictor defined by a distribution over the hypothesis class.
PAC-Bayes bounds were originally meant for binary classification problems [6,7,8], but the literature now includes many contributions involving any bounded loss function (without loss of generality, with values in ), not just the binary loss. Our goal is to provide new PAC-Bayes bounds that are valid for unbounded loss functions, and thus extend the usability of PAC-Bayes to a much larger class of learning problems. To do so, we reformulate the general PAC-Bayes theorem of [9] and use it as basic building block to derive our new PAC-Bayes bound.
Some ways to circumvent the bounded range assumption on the losses have been explored in the recent literature. For instance, one approach consists of assuming a tail decay rate on the loss, such as sub-gaussian or sub-exponential tails [10,11]; however, this approach requires the knowledge of additional parameters. Some other works have also looked into the analysis for heavy-tailed losses, e.g., ref. [12] proposed a polynomial moment-dependent bound with f-divergences, while [13] devised an exponential bound that assumes the second (uncentered) moment of the loss is bounded by a constant (with a truncated risk estimator, as recalled in Section 4 below). A somewhat related approach was explored by [14], who do not assume boundedness of the loss, but instead control higher-order moments of the generalization gap through the Efron-Stein variance proxy. See also [5].
We investigate a different route here. We introduce the HYPothesis-dependent rangE (HYPE) condition, which means that the loss is upper-bounded by a term that depends on the chosen predictor (but does not depend on the data). Thus, effectively, the loss may have an arbitrarily large range. The HYPE condition allows us to derive an upper bound on the exponential moment of a suitably chosen functional, which, combined with the general PAC-Bayes theorem, leads to our new PAC-Bayes bound. To illustrate it, we instantiate the new bound on a linear regression problem, which additionally serves the purpose of illustrating that our HYPE condition is easy to verify in practice, given an explicit formulation of the loss function. In particular, we shall see in the linear regression setting that a mere use of the triangle inequality is enough to check the HYPE condition. The technical assumptions on which our results are based are comparable to those of the classical PAC-Bayes bounds; we state them in full detail, with discussions, for the sake of clarity and to make our work accessible.
Our contributions are twofold. (i) We propose PAC-Bayesian bounds holding with unbounded loss functions, therefore overcoming a limitation of the mainstream PAC-Bayesian literature for which a bounded loss is usually assumed. (ii) We analyse the bound, its implications, limitations of our assumptions, and their usability by practitioners. We hope this will extend the PAC-Bayes framework into a widely usable tool for a significantly wider range of problems, such as unbounded regression or reinforcement learning problems with unbounded rewards.
Outline.Section 2 introduces our notation and definition of the HYPE condition and provides a general PAC-Bayesian bound, which is valid for any learning problem complying with a mild assumption. For the sake of completeness, we present how our approach (designed for the unbounded case) behaves in the bounded case (Section 3). This section is not the core of our work, but rather serves as a safety check and particularises our bound to more classical PAC-Bayesian assumptions. We also provide numerical experiments. Section 4 introduces the notion of softening functions and particularises Section 2’s PAC-Bayesian bound. In particular, we make explicit all terms in the right-hand side. Section 5.1 extends our results to linear regression (which has been studied from the perspective of PAC-Bayes in the literature, most recently by [15]). We also experimentally illustrate the behaviour of our bound. Finally, Section 6 presents, in detail, related works and Section 7 contains all proofs of the original claims we make in the paper.
2. Framework and Preliminary Results
The learning problem is specified by three variables consisting of a set of predictors, the data space , and a loss function .
For a given positive integer m, we consider size-m datasets. The space of all possible datasets of this fixed size is ; an arbitrary element of this space is . We denote S as a random dataset: where the random data points are independent and sampled from the same distribution over . We call the data-generating distribution. The assumption that the ’s are independent and identically distributed is typically called the i.i.d. data assumption. It means that the random sample S (of size m) has distribution which is the product of m copies of .
For any predictor , we define the empirical risk of h over a sample s, denoted , and the theoretical risk of h, denoted , as:
respectively, where denotes the expectation with respect to . Finally, we define the risk gap for any and . Often, is referred to as the generalisation gap.
Notice that for a random dataset S, the empirical risk is random, with expected value , where the expectation under the distribution of the random sample S.
In general, denotes an expectation under the distribution . When we want to emphasize the role of the random variable we write or instead of . We use a similar convention for expectations related to any other distributions and random quantities. We now introduce the key concept to our analysis.
Definition 1.
(HYPE). A loss function is said to satisfy the hypothesis-dependent range (HYPE) condition if there exists a function such that for every predictor h. We then say that ℓ is HYPE(K) compliant.
Let be the set of probability distributions on . We assume that all considered probability measures on are defined on a fixed -algebra over , while the notation hides the -algebra, for simplicity. For , the notation indicates that is absolutely continuous with respect to P (i.e., if for measurable ). We write to indicate that and , i.e., these two distributions are absolutely continuous with respect to each other.
We now recall a result from Germain et al. [9]. Note that while implicit in many PAC-Bayes works (including theirs), we make it explicit that both the prior P and the posterior Q must be absolutely continuous with respect to each other. We discuss this restriction below.
Theorem 1.
(Adapted from [9], Theorem 2.1.) For any with no dependency on data, for any function , define the exponential moment:
If F is convex, then for any , with probability of at least over random samples S, simultaneously for all such that we have:
The proof is deferred to Section 7.1. Note that the proof in [9] requires that , although it is not explicitly stated; we highlight this in our own proof. While is classical and necessary for the to be meaningful, appears to be more restrictive. In particular, we have to choose Q such that it has the exact same support as P (e.g., choosing a Gaussian and a truncated Gaussian is not possible). However, we can still apply our theorem when P and Q belong to the same parametric family of distributions, e.g., both ‘full-support’ Gaussian or Laplace distributions, but these are just two examples and there are many others.
Note that Alquier et al. [10] (Theorem 4.1) adapted a result from Catoni [8], which only requires . This comes at the expense of what Alquier et al. [10] (Definition 2.3) called a Hoeffding’s assumption, which means that the exponential moment is assumed to be bounded by a function depending only on the hyperparameters (such as the dataset size m or parameters given by Hoeffding’s assumption). Our analysis does not require this assumption, which might prove restrictive in practice.
Theorem 1 may be seen as a basis to recover many classical PAC-Bayesian bounds. For instance, , recovers McAllester’s bound as recalled in [4] (Theorem 1). To get a usable bound, the outstanding task is to bound the exponential moment . Note that a previous attempt has been made in [11], as described in Section 6.1 below. Furthermore, under the assumption that the distribution P has no dependency on the data, we may swap the order of integration in the exponential moment thanks to Fubini-Tonelli’s theorem and the positiveness of the exponential:
This is the starting point for the way that the exponential moment was handled in several works in the PAC-Bayes literature. Essentially, for a fixed h, one may upper-bound the innermost expectation (with respect to S) using standard exponential moment inequalities.
In this work, we will use Theorem 1 with , where , and is a convex function. In this case, the high-probability inequality of the theorem takes the form:
Our goal is to control for a fixed h, when . This will readily give us control on the exponential moment . To do so, we propose the following theorem:
Theorem 2.
Let be a fixed predictor and . If the loss function ℓ is HYPE(K) compliant, then for we have:
Proof.
Let . Then:
We now apply Hoeffding’s lemma, for any , the random (in ) variable is centered, taking values in , so that:
and finally:
□
The strength of this result lies in the fact that , is a decreasing factor in m, when , and more generally, one can control how fast the exponential moment will explode when m grows by the choice of the hyperparameter .
For convenient cross-referencing, we state the following rewriting of Theorem 1.
Theorem 3.
Let the loss ℓ be HYPE(K) compliant. For any with no data dependency, for any and for any , with probability of at least over size-m random samples S, simultaneously for all Q such that we have:
Proof.
We first apply Theorem 1 with . More precisely, we use Equation (1) with . We then conclude with Theorem 2. □
3. Safety Check: The Bounded Loss Case
3.1. Theoretical Results
At this stage, the reader might wonder whether this new approach allows for the recovery of known results in the bounded case: the answer is yes.
In this section, we study the case where ℓ is bounded by some constant . In other words, we consider the case that . We provide a bound, valid for any choice of “priors” P and “posteriors” Q such that , which is an immediate corollary of Theorem 3.
Proposition 1.
Let ℓ be HYPE(K) compliant, with constant, and let . Let be a distribution with no data dependency. Then, for any , with probability of at least over random m-samples S, simultaneously for all such that we have:
Remark 1.
We provide Proposition 1 to evaluate the robustness of our approach. For instance, by comparing it with the PAC-Bayesian bound found in Germain et al. [11]. This discussion can be found in Section 6.1, where the bound from Germain et al. [11] is presented in detail.
Remark 2.
At first glance, a naive remark: in order to control the rate of convergence of all the terms of the bound in Proposition 1 (as is often the case in classical PAC-Bayesian bounds), then the only case of interest is in fact . However, one could notice that the factor is not optimisable, while the KL is. In this way, if it appears that is too big, in practice, one wants to have the ability to attenuate its influence as much as possible and this may lead us to consider . The following lemma answers this question.
Lemma 1.
For any given , the function reaches its minimum at
Proof.
The explicit calculus of the and the resolution of provides the result. □
Remark 3.
Lemma 1 indicates that with a fixed “prior” P and “posterior” Q, taking , gives the optimised value of the bound in Proposition 1. We numerically show in Section 3.2 (first experiment there) that optimising α leads to significantly better results.
Now the only remaining question is how to optimise the KL divergence. To do so, we may need to fix an “informed prior” to minimise the KL divergence with an interesting posterior. This idea has been studied by [16,17] and, more recently, by Mhammedi et al. [18], Rivasplata et al. [5], among others. We will adapt it to our problem in the simplest way.
We now introduce some additional notation. For a sample and , we define and . Then, similarly, for a random sample S, we have the splits and .
Proposition 2.
Let ℓ be HYPE(K) compliant, with constant , and . Consider any “priors” (possibly dependent on ) and (possibly dependent on ). Then, for any , with probability of at least over random size-m samples S, simultaneously for all such that and we have:
Proof.
Let be as stated in Proposition 2. We first notice that by using Proposition 1 on the two halves of the sample, we obtain, with a probability of at least :
and also with probability at least :
Hence, with a probability of at least , both inequalities hold, and the result follows by adding them and dividing by 2. □
Remark 4.
One can notice that the main difference between Proposition 2 and Proposition 1 lies in the implicit PAC-Bayesian paradigm that our priors must not depend on the data. With this last proposition, we implicitly allow to depend on and on , which can in practice lead to far more accurate priors. We numerically show this fact in Section 3.2’s second experiment. Note that this idea is not new and has been studied, for instance, in [19] for the specific case of SVMs.
3.2. Numerical Experiments
Our experimental framework has been inspired by the work of [18].
Settings. We generate synthetic data for classification, and we are using the 0–1 loss. The data space is with . The set of predictors is parameterised with d-dimensional ‘weight’ vectors: . For simplicity, we identify with w and we also identify the space , with the weight space . For and , we define the loss as , where . We want to learn an optimised predictor given a dataset where . To do so, we use regularised logistic regression and compute:
where is a fixed regularisation parameter.
We also restrict the probability distributions (over ), considered for this learning problem. We consider the Gaussian distribution with centre and diagonal covariance with .
Parameters. We set . We approximately solve Equation (2) by using the minimize function of the optimisation module in Python, with the Powell method. To approximate gaussian expectations, we use Monte-Carlo sampling.
Synthetic data. We generate synthetic data for according to the following process: for a fixed sample size m, we draw under the multivariate Gaussian distribution and for each i we compute the label if as: where is the vector formed by the d first digits of the number .
Normalisation trick. Given the predictors shape, we notice that for any :
Thus, the value of the prediction is exclusively determined by the sign of the inner product, and this quantity is definitely not influenced by the norm of the vector. Then, for any sample S, we call the normalisation trick the fact of considering instead of in our calculations. This process will not deteriorate the quality of the prediction and will considerably enhance the value of the KL divergence.
3.2.1. First Experiment
Our goal here is to highlight the point discussed in Remark 2, e.g., the influence of the parameter in Proposition 1. We arbitrarily fix , and define our naive prior as . For a fixed dataset S, we define our posterior as , with (for ) such that it is minimising the bound among candidates. We computed two curves: first, Proposition 1 with second, Proposition 1 again with equals to the value proposed in Lemma 1. Notice that to compute this last bound, we first optimised our choice of posterior with and then optimised , to be consistent with Lemma 1. Indeed, we proved this lemma by assuming that the KL divergence was already fixed, hence our optimisation process is in two steps. Note that we chose to apply the normalisation trick here, we then obtained the left curve of Figure 1.
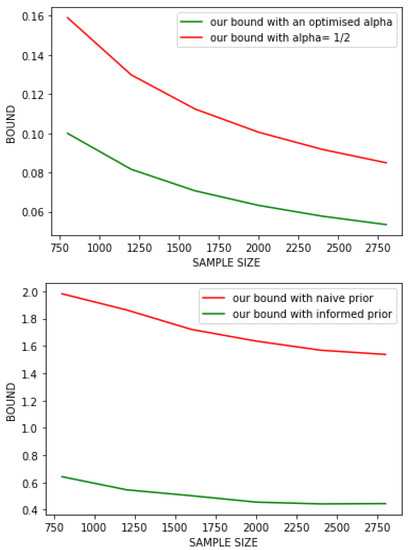
Figure 1.
Above, result of the first experiment which highlight the importance of optimising . Below, result of the second experiment which show how effective an informed prior is.
Discussion. From this curve, we formulate several remarks. First, we remark on this specific case, our theorem provides a tight result in practice (with an error rate lesser than for the bound with optimised alpha). Second, we can now confirm that choosing an optimised leads to a tighter bound. In further studies, it will be relevant to adjust with regards to the different terms of our bound instead of looking for an identical convergence rate for all terms.
3.2.2. Second Experiment
We now study Proposition 2 to see if an informed prior effectively provides a tighter bound than a naive one. We will use the notations introduced in Proposition 2. For a dataset S, we define as the vector resulting from the optimisation of Equation (2) on . Similarly, we define . We arbitrarily fix , and define our informed priors as: and . Finally, we define our posterior as , with (for ) with optimising the bound among the same candidate than the first experiment. We computed two curves: first, Proposition 1 with optimised accordingly to Lemma 1 secondly, Proposition 2 with optimised as well, and informed priors as defined above. We chose to not apply the normalisation trick here, we then obtained the right curve of Figure 1.
Discussion. It is clear, that with this framework, having an informed prior is a powerful tool to enhance the quality of our bound. Notice that we voluntarily chose to not apply the normalisation trick here. The reason is that this trick appears to be too powerful in practice, and applying it leads to counterproductive results; to highlight our point: the bound without informed prior would be tighter than the one with informed prior. Furthermore, this trick is linked to the specific structure of our problem and is not valid for any classification problem. Thus, the idea of providing informed priors remains an interesting tool for most cases.
4. PAC Bayesian Bounds with Smoothed Estimator
We now move on to control the right-hand side term in Theorem 3 when K is not constant. A first step is to consider a transformed estimate of the risk, inspired by the truncated estimator from [20], also used in [21], and more recently in [13]. The following is inspired by the results of [13], which we summarise in Section 6.
The idea is to modify the estimator for any h by introducing a threshold t and a function which will attenuate the influence of the empirical losses that exceed t.
Definition 2.
-risks. For every , , for any , we define the empirical ψ-risk and the theoretical ψ-risk as follows:
where . Notice that .
We now focus on what we call softening functions, i.e., functions that will temper high values of the loss function ℓ.
Definition 3.
(Softening function). We say that is a softening function if:
- ,
- ψ is non-decreasing,
- .
We let denote the set of all softening functions.
Remark 5.
Notice that those three assumptions ensure that ψ is continuous at 1. For instance, the functions and are in . In Section 6 we compare these softening functions and those used by Holland [13].
Using , for a fixed threshold , the softened loss function verifies for any , :
because is non-decreasing. In this way, the exponential moment in Theorem 3 can be far more controllable. The trade-off lies in the fact that softening ℓ (instead of taking directly ℓ) will deteriorate our ability to distinguish between two bad predictions when both of them are greater than t. For instance, if we choose such as on and , if for a certain pair , then we cannot tell how far is from t and we only can affirm that .
We now move on to the following lemma, which controls the shortfall between and for all , for a given and . To do that, we assume that K admits a finite moment under any posterior distribution:
For instance, in the case of identified with a weight space , and if K is polynomial in (where denotes the Euclidean norm), then this assumption holds if we consider Gaussian priors and posteriors.
Lemma 2.
Assume that Equation (3) holds, and let , . We have:
Proof.
Let , . We have, for :
and using that ,
while using that ,
and continuing:
Finally, by crudely bounding the probability by 1, we get:
Hence the result by integrating over with respect to Q. □
Finally we present the following theorem, which provides a PAC-Bayesian inequality bounding the theoretical risk by the empirical -risk for .
Theorem 4.
Let ℓ be HYPE(K) compliant, and assume K satisfies Equation (3). Then for any with no data dependency, for any , for any and for any , with probability of at least over size-m random samples S, simultaneously for all Q such that we have:
Proof.
Let , we define the -loss:
Since is non decreasing, we have for all :
Thus, we apply Theorem 3 to the learning problem defined with : for any and , with probability at least over size-m random samples S, simultaneously for all Q such that we have:
We then add on both sides of the latter inequality and apply Lemma 2. □
Remark 6.
Notice that the function is such that for any given prior P we have . So the exponential moment can be controlled with a good choice of ψ. Thus the strength of Theorem 4 is to provide a PAC-Bayesian bound valid for any set of posterior measures verifying Equation (3). The choice of ψ minimising the bound is still an open problem.
5. The Linear Regression Problem
5.1. Theoretical Result
We now focus on the celebrated linear regression problem and see how our theory translates to that particular learning problem. We assume that the data is a size-m random sample where the are i.i.d. drawn from the distribution , and with , .
Our goal here is to find the most accurate predictor (with ), with respect to the loss function , where . We will make the following mild assumption: there exists such that for all drawn under :
where is the norm associated to the classical inner product of . Under this assumption we note that for all drawn according to , we have:
Thus we define for . If we first restrict ourselves to the framework of Section 2, we want to use Theorem 3 and doing so, our goal is to bound . The shape of K invites us to consider a Gaussian prior. Indeed, we notice that if with , then . Notice that we cannot take just any Gaussian prior, however with a small , the condition may become quite loose. Thus, we have the following:
Theorem 5.
Let and . Assume that the loss ℓ is HYPE(K) compliant with , with . For a prior distribution, consider any Gaussian with , . Then, for any , with probability of at least over size-m random samples S, simultaneously for all such that we have:
where .
The proof is deferred to Section 7.2. To compare our result with those found in the literature, we can fix . Doing so, we lose the dependency in m for the choice of the variance of the prior (which now only depends on B), but we recover the classic decreasing factor .
Remark 7.
Notice that for now we did not use Section 4, even if we could (because K is polynomial in and we consider Gaussian priors and posteriors, so Equation (3) is satisfied). Doing so, we obtained a bound which appears to depend linearly on the dimension N. In practice, N may be too big, and in this case, introducing an adapted softening function ψ (one can think for instance of ) is a powerful tool to attenuate the weight of the exponential moment. This also extends the class of authorised Gaussian priors by avoidance, to stick with a variance , .
5.2. Numerical Experiment
5.2.1. Setting
In this section we apply Theorem 5 on a concrete linear regression problem. The situation is as follows: we want to approximate the function , where . We assume that so that lies in an hypercube centred at 0 of half-side , i.e., the set . Doing so we have .
Furthermore, we assume that input data are drawn inside a hypercube of half-side , i.e., . Doing so we have for any data .
For any data , we define . As before, we identify the hypothesis set with the weight space . As described in Section 5.1, we set . We then remark that for any :
Then we can define and to apply Theorem 5. We restrict (as before) the class of distributions over to be d-dimensional Gaussians:
which is the set of candidate distributions for this learning problem. Recall that in practice, given a fixed , we are only allowed to consider priors such that their variance . We want to learn an optimised predictor (posterior) given a random dataset . To do so, we consider synthetic data.
5.2.2. Synthetic Data
We draw under a Gaussian (with mean 0 and standard deviation equal to 5) truncated to the hypercube centered at 0 of the half-side . We generate synthetic data according to the following process: for a fixed sample size m, we draw under a Gaussian (with mean 0 and standard deviation equal to 5) truncated to the hypercube centered at 0 of the half-side .
5.2.3. Experiment
First, we fix . Our goal here is to obtain a generalisation bound on our problem. We fix arbitrarily, for a fixed , and and we define our naive prior as . For a given dataset S, we define our posterior as , with (), such that it is minimising the bound among candidates. Note that all the previously defined parameters are dependent on , which is why we choose for step a fixed integer (in practice step = 8 or 16) and we take the value of minimising the bound among the candidates as well. Figure 2 contains two figures, one with , the other with . On each figure are computed the right-hand side term in 5 with an optimised for each step.
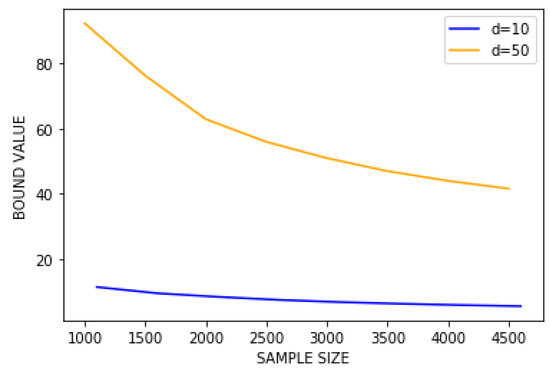
Figure 2.
Evaluation of the right hand side in Theorem 5 with and .
5.2.4. Discussion
To the the best of our knowledge, this is the first attempt to numerically compute PAC-Bayes bounds for unbounded problems, making it impossible to compare to other results. We stress, however, that obtaining numerical values for the bound without assuming a bounded loss is a significant first step. Furthermore, we consider a rather hard problem: f is not linear, so we cannot rely on a linear approximation fitting perfectly data, and the larger the dimension, the larger the error, as illustrated by Figure 2. Thus, for any posterior Q, the quantity is potentially large in practice and our bound might not be tight. Finally, notice that optimising (instead of taking to recover a classic convergence rate) leads to a significantly better bound. A numerical example of this assertion is presented in Section 3.2. We aim to conduct further studies to consider the convergence rate as an hyperparameter to optimise, rather than selecting the same rate for all terms in the bound.
6. Existing Work
6.1. Germain et al., 2016
In Germain et al. [11] (Section 4), a PAC-Bayesian bound has been provided for all sub-gamma losses with a variance and scale parameter , under a data distribution and a prior P, i.e., losses such that for every the following is satisfied:
Note that a sub-gamma loss (with regards to and P) is potentially unbounded. Germain et al. then propose the following PAC-Bayesian bound:
Theorem 6.
Ref. [11]. If the loss ℓ is sub-gamma with a variance and scale parameter c, under the data distribution μ and a fixed prior , then for any , with probability over size-m random samples, simultaneously for all we have:
Theorem 6 will be quoted several times in this paper given that it is a concrete PAC Bayesian bound provided with the will to overcome the constraint of a bounded loss. It is also one of the only one found in the literature.
Can we apply this theorem to the bounded case? The answer is yes: we remark that thanks to Hoeffding’s lemma, if ℓ is bounded by , then for any it holds that almost surely. So, . Therefore, for any prior P, we have:
Thus, ℓ is sub-gamma with variance and scale parameter 0. Then, Theorem 6 can be applied with , .
Comparison with Proposition 1. We remark that by taking and in Proposition 1, we are recovering Theorem 6. However, our approach allows us to say that if we can obtain a more precise form of K such that , and K is non-constant, 3, will ensure that:
Thus, having precise information on the behavior of the loss function ℓ, with regards to the predictor h, allows us to obtain a tighter control of the exponential moment, and hence a tighter bound.
Remark 8.
We can see that Theorem 6 cannot control the factor . However, Ref. [11] remarked on this apparent weakness and partially corrected this issue [11] (Section 4, Equations (13) and (14)). Indeed, they proposed to balance the influence of m between the different terms of the PAC-Bayes bound by providing the same convergence rate in to all terms.
We can then see Proposition 1 as a proper generalisation of Germain et al. [11] (Section 4, Equations (13) and (14)). Indeed, our bound exhibits properly the influence of the parameter α. Thus, we understand (and Lemma 1 proves it) that the choice of α deserves a study in itself in the way it is now a parameter of our optimisation problem. This fact has already been highlighted in Alquier et al. [10] (Theorem 4.1) (where ).
6.2. Holland, 2019
In [13], Holland proposed a PAC Bayesian inequality with unbounded loss. For that, he introduced a function verifying a few specific conditions, different to those used in Section 4 to define our set of softening functions. Indeed, he considered a function such that:
- is bounded,
- is non decreasing,
- it exists such that for all :
We remark that, as Holland did, we supposed that our softening functions are non-decreasing. We chose softening functions to be equal to the identity function () on , which is quite restrictive. However, we are imposing softening functions to be lesser than the identity on ; whereas, Holland supposed to be bounded and satisfy Equation (4). A concrete example of such a function , lies in the piecewise polynomial function of Catoni and Giulini [21], defined by:
As in Section 4, we are considering the -empirical risk for any . Holland provided his theorem given the fact the following assumptions are realised:
- Bounds on lower-order moments. For all , we have and .
- Bounds on the risk. For all , we suppose .
- Large enough confidence, we require .
Now we can state Holland’s theorem.
Theorem 7.
Ref. [13]. Let P be a prior distribution on model . Let the three assumptions listed above hold. Setting , then for any , with probability of at least over the random draw of the size-m sample S, simultaneously for all Q it holds that:
where:
7. Proofs
7.1. Proof of Theorem 1
Proof.
Let be a convex function, P a fixed prior, and . Since is a nonnegative random variable, we know that, by Markov’s inequality, for any :
So with probability of at least , we have:
Applying the log function on each side of this inequality gives us with probability of at least over samples S:
We now rename .
Furthermore, if we denote by the Radon-Nikodym derivative of Q with respect to P when , we then have, for all Q such that :
and by concavity of log and Jensen’s inequality,
while by convexity of F with Jensen’s inequality,
Hence, for Q such that ,
So with probability , for Q such that ,
This completes the proof of Theorem 1. □
7.2. Proof of Theorem 5
We first provide a technical property. Recall that:
Proposition 3.
Let . Suppose the loss ℓ is HYPE(K) compliant with , with , . Then, for any Gaussian prior with , and we have:
with .
Proof.
We recall that . By expliciting the expectation and we thus obtain:
We will use the spherical coordinates in N-dimensional Euclidean space given in [22]:
where especially and also the Jacobian of is given by:
Let us also precise that as given in Blumenson [22] (page 66), we have that the surface of the sphere of radius 1 in N-dimensional space is:
where is the Gamma function defined as:
Then, if we set:
we obtain by a change of variable:
We fix a random variable X such that:
We then have for any k positive integer, if k is even:
And if k is odd:
So we have:
As precised in [23], we have for any k:
So finally:
Lemma 3.
If , then:
Proof.
As precised in the introduction of Srinivasan and Zvengrowski [24], Gauss [25] (page 147) proved that on the interval where , is a monotonic increasing function. So, for . And because , we have:
Because , and is monotone and increasing on , we have . Hence the result. □
Using Lemma 3 allows us to write:
We recall that and . Then we can write:
We now conclude with the final bound on :
This completes the proof of Proposition 3. □
Proof of Theorem 5.
We combine Theorem 3 with Proposition 3. We also upper-bound by N. □
Author Contributions
Conceptualization, M.H., B.G. and J.S.-T.; Formal analysis, M.H., B.G. and O.R.; Project administration, B.G.; Supervision, B.G.; Writing—original draft, M.H., B.G. and O.R.; Writing—review and editing, M.H., B.G., O.R. and J.S.-T. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the U.S. Army Research Laboratory and the U. S. Army Research Office, and by the U.K. Ministry of Defence and the U.K. Engineering and Physical Sciences Research Council (EPSRC) under grant number EP/R013616/1. BG acknowledges partial support from the French National Agency for Research, grants ANR-18-CE40-0016-01 and ANR-18-CE23-0015-02.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shawe-Taylor, J.; Williamson, R.C. A PAC analysis of a Bayes estimator. In Proceedings of the 10th Annual Conference on Computational Learning Theory, Nashville, TN, USA, 6–9 July 1997; ACM: New York, NY, USA, 1997; pp. 2–9. [Google Scholar]
- McAllester, D.A. Some PAC-Bayesian theorems. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; ACM: New York, NY, USA, 1998; pp. 230–234. [Google Scholar]
- McAllester, D.A. PAC-Bayesian model averaging. In Proceedings of the Twelfth Annual Conference on Computational Learning Theory, Santa Cruz, CA, USA, 7–9 July 1999; ACM: New York, NY, USA, 1999; pp. 164–170. [Google Scholar]
- Guedj, B. A Primer on PAC-Bayesian Learning. arXiv 2019, arXiv:stat.ML/1901.05353. [Google Scholar]
- Rivasplata, O.; Kuzborskij, I.; Szepesvári, C.; Shawe-Taylor, J. PAC-Bayes Analysis Beyond the Usual Bounds. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, Online, 6–12 December 2020. [Google Scholar]
- Seeger, M. PAC-Bayesian Generalization Error Bounds for Gaussian Process Classification. J. Mach. Learn. Res. 2002, 3, 233–269. [Google Scholar]
- Langford, J. Tutorial on practical prediction theory for classification. J. Mach. Learn. Res. 2005, 6, 273–306. [Google Scholar]
- Catoni, O. PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning; Institute of Mathematical Statistics: Waite Hill, OH, USA, 2007. [Google Scholar]
- Germain, P.; Lacasse, A.; Laviolette, F.; Marchand, M. PAC-Bayesian Learning of Linear Classifiers. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 353–360. [Google Scholar]
- Alquier, P.; Ridgway, J.; Chopin, N. On the properties of variational approximations of Gibbs posteriors. J. Mach. Learn. Res. 2016, 17, 1–41. [Google Scholar]
- Germain, P.; Bach, F.; Lacoste, A.; Lacoste-Julien, S. PAC-Bayesian Theory Meets Bayesian Inference. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; pp. 1884–1892. [Google Scholar]
- Alquier, P.; Guedj, B. Simpler PAC-Bayesian bounds for hostile data. Mach. Learn. 2018, 107, 887–902. [Google Scholar] [CrossRef] [Green Version]
- Holland, M. PAC-Bayes under potentially heavy tails. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 2715–2724. [Google Scholar]
- Kuzborskij, I.; Szepesvári, C. Efron-Stein PAC-Bayesian Inequalities. arXiv 2019, arXiv:1909.01931. [Google Scholar]
- Shalaeva, V.; Fakhrizadeh Esfahani, A.; Germain, P.; Petreczky, M. Improved PAC-Bayesian Bounds for Linear Regression. In Proceedings of the AAAI 2020—Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Lever, G.; Laviolette, F.; Shawe-Taylor, J. Distribution-Dependent PAC-Bayes Priors. In Algorithmic Learning Theory; Hutter, M., Stephan, F., Vovk, V., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 119–133. [Google Scholar]
- Lever, G.; Laviolette, F.; Shawe-Taylor, J. Tighter PAC-Bayes Bounds through Distribution-Dependent Priors. Theor. Comput. Sci. 2013, 473, 4–28. [Google Scholar] [CrossRef]
- Mhammedi, Z.; Grünwald, P.; Guedj, B. PAC-Bayes Un-Expected Bernstein Inequality. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 12202–12213. [Google Scholar]
- Parrado-Hernández, E.; Ambroladze, A.; Shawe-Taylor, J.; Sun, S. PAC-Bayes bounds with data dependent priors. J. Mach. Learn. Res. 2012, 13, 3507–3531. [Google Scholar]
- Catoni, O. Challenging the empirical mean and empirical variance: A deviation study. Ann. Inst. H. Poincaré Probab. Statist. 2012, 48, 1148–1185. [Google Scholar] [CrossRef]
- Catoni, O.; Giulini, I. Dimension-free PAC-Bayesian bounds for matrices, vectors, and linear least squares regression. arXiv 2017, arXiv:math.ST/1712.02747. [Google Scholar]
- Blumenson, L.E. A Derivation of n-Dimensional Spherical Coordinates. Am. Math. Mon. 1960, 67, 63–66. [Google Scholar] [CrossRef] [Green Version]
- Winkelbauer, A. Moments and Absolute Moments of the Normal Distribution. arXiv 2012, arXiv:math.ST/1209.4340. [Google Scholar]
- Srinivasan, G.K.; Zvengrowski, P. On the Horizontal Monotonicity of |Γ(s)|. Can. Math. Bull. 2011, 54, 538–543. [Google Scholar] [CrossRef]
- Gauss, C.F. Disquisitiones Generales Circa Seriem Infinitam (reprint). In Werke; Cambridge University Press: Cambridge, UK, 2011; Volume 3. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).