
S2A: Scale-Attention-Aware Networks for Video Super-Resolution


Abstract
:1. Introduction
- We propose a Scale-and-Attention Aware network (SAA) for video SR. Experiments on several public datasets demonstrate the effectiveness of our SAA networks.
- We propose Scale-and-Attention Aware Module (SAAM) to fuse and extract features in multi-frame streams. This module design methodology not only extracts multi-scale feature information but also obtains feature correlations explicitly and effectively, thanks to the center-oriented fusion manner and the spatial–channel attention extraction mechanism in .
- We propose the Criss-Cross Channel Attention Module () to extract spatial and channel attention information inherent in multi-frame stream features. With the aid of criss-cross non-local implementation, spatial correlations can be obtained both efficiently and effectively. The channel attention mechanism further helps the module to acquire attention weights in the channel dimension for even better feature representations. Both criss-cross non-local and channel attention mechanisms help extract feature correlations effectively with negligible computation overhead and extra parameters compared to vanilla non-local implementation.
2. Related Works
2.1. Deep Single Image SR
2.2. Deep Video SR
2.3. Attention Mechanism
3. Scale-and-Attention Aware Networks (SAA)
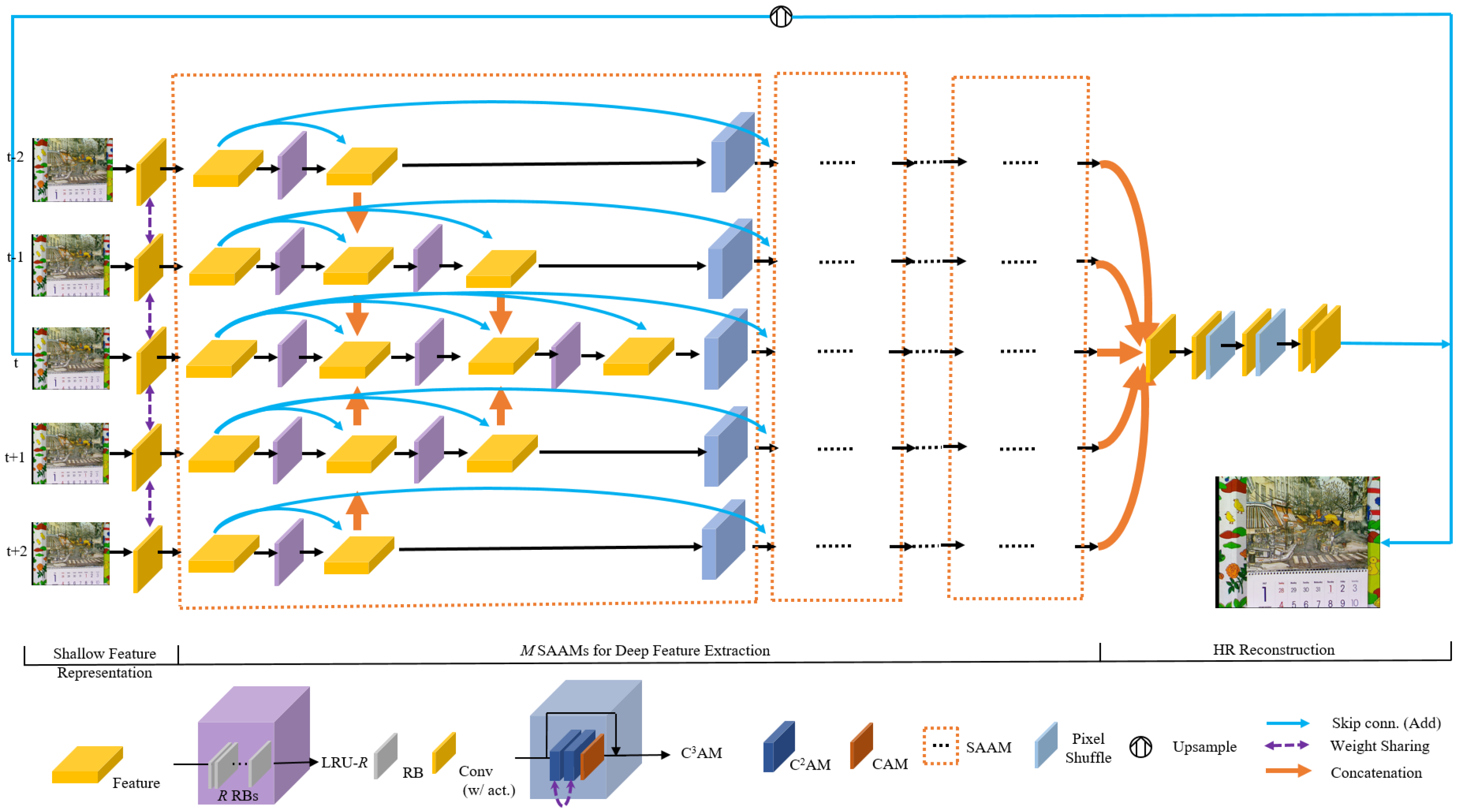
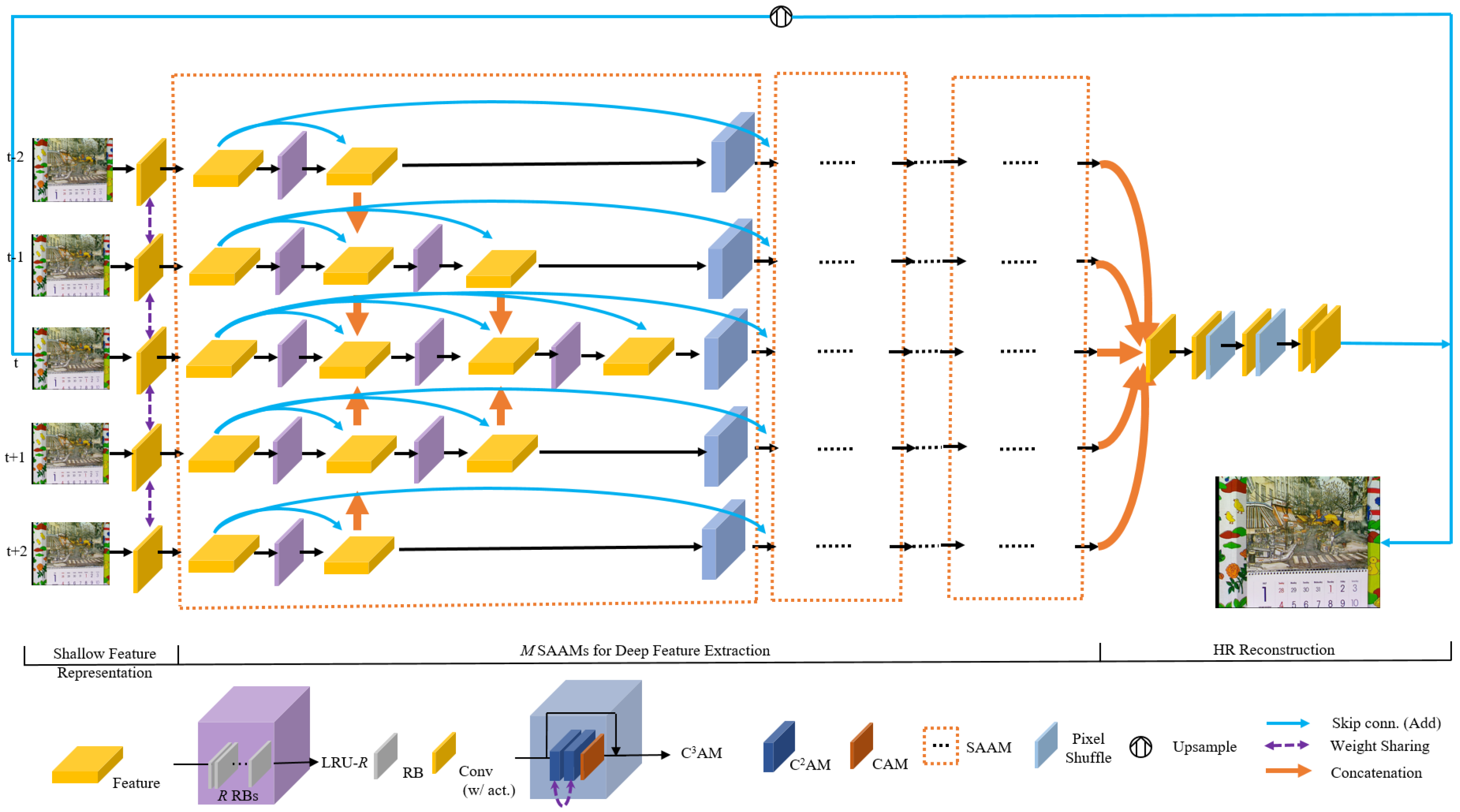
3.1. Overall Network Architecture
3.2. Scale-and-Attention Aware Module (SAAM)
3.3. Criss-Cross Channel Attention Module ()
3.4. Implementation Details
3.5. Discussions
4. Experiments
4.1. Datasets
4.2. Configurations
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Study
4.4.1. Multi-Scale Feature Extraction and Center-oriented Fusion (MFE-CF) and Criss-Cross Channel Attention Module ()
4.4.2. Share-Source Residuals in SAAMs and Residuals between Adjacent SAAMs
4.5. Model Analyses Experiments
4.5.1. Influence of Number of SAAMs (M)
4.5.2. Influence of Number of Temporal Branches (F)
4.5.3. Influence of Number of Channels (C)
4.5.4. Influence of Number of Residual Blocks (R) in Local Residual Unit (LRU)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Y.; Wang, W.; Wang, L. Bidirectional recurrent convolutional networks for multi-frame super-resolution. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 235–243. [Google Scholar]
- Tao, X.; Gao, H.; Liao, R.; Wang, J.; Jia, J. Detail-revealing deep video super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4472–4480. [Google Scholar]
- Sajjadi, M.S.; Vemulapalli, R.; Brown, M. Frame-recurrent video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6626–6634. [Google Scholar]
- Yi, P.; Wang, Z.; Jiang, K.; Jiang, J.; Ma, J. Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 29 October–3 November 2019; pp. 3106–3115. [Google Scholar]
- Isobe, T.; Li, S.; Jia, X.; Yuan, S.; Slabaugh, G.; Xu, C.; Li, Y.L.; Wang, S.; Tian, Q. Video super-resolution with temporal group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 8008–8017. [Google Scholar]
- Xiao, Z.; Fu, X.; Huang, J.; Cheng, Z.; Xiong, Z. Space-time distillation for video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 16–25 June 2021; pp. 2113–2122. [Google Scholar]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video super-resolution with convolutional neural networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4778–4787. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Recurrent Back-Projection Network for Video Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3897–3906. [Google Scholar]
- Li, S.; He, F.; Du, B.; Zhang, L.; Xu, Y.; Tao, D. Fast Spatio-Temporal Residual Network for Video Super-Resolution. arXiv 2019, arXiv:1904.02870. [Google Scholar]
- Liu, H.; Ruan, Z.; Zhao, P.; Dong, C.; Shang, F.; Liu, Y.; Yang, L. Video super resolution based on deep learning: A comprehensive survey. arXiv 2020, arXiv:2007.12928. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order Attention Network for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11065–11074. [Google Scholar]
- Soh, J.W.; Park, G.Y.; Jo, J.; Cho, N.I. Natural and Realistic Single Image Super-Resolution with Explicit Natural Manifold Discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8122–8131. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 4799–4807. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep Back-Projection Networks for Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lv, Y.; Dai, T.; Chen, B.; Lu, J.; Xia, S.T.; Cao, J. HOCA: Higher-Order Channel Attention for Single Image Super-Resolution. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Paris, France, 18–19 November 2021; pp. 1605–1609. [Google Scholar]
- Liao, R.; Tao, X.; Li, R.; Ma, Z.; Jia, J. Video super-resolution via deep draft-ensemble learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 531–539. [Google Scholar]
- Liu, D.; Wang, Z.; Fan, Y.; Liu, X.; Wang, Z.; Chang, S.; Huang, T. Robust video super-resolution with learned temporal dynamics. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2507–2515. [Google Scholar]
- Chan, K.C.; Wang, X.; Yu, K.; Dong, C.; Loy, C.C. BasicVSR: The search for essential components in video super-resolution and beyond. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 16–25 June 2021; pp. 4947–4956. [Google Scholar]
- Liu, S.; Zheng, C.; Lu, K.; Gao, S.; Wang, N.; Wang, B.; Zhang, D.; Zhang, X.; Xu, T. Evsrnet: Efficient video super-resolution with neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 16–25 June 2021; pp. 2480–2485. [Google Scholar]
- Jo, Y.; Wug Oh, S.; Kang, J.; Joo Kim, S. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3224–3232. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video enhancement with task-oriented flow. Int. J. Comput. Vis. 2019, 127, 1106–1125. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Sun, D. A Bayesian approach to adaptive video super resolution. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 209–216. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, C.; Sun, D. On Bayesian adaptive video super resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 346–360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, Y.; Zhang, Y.; Fu, Y.; Xu, C. Tdan: Temporally deformable alignment network for video super-resolution. arXiv 2018, arXiv:1812.02898. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR (dB)/SSIM (RGB) | PSNR (dB)/SSIM (Y) |
|---|---|---|
| Bicubic | 29.79/0.8483 | 31.32/0.8684 |
| RCAN [18] | 33.61/0.9101 | 35.35/0.9251 |
| DeepSR [29] | 25.55/0.8498 | -/- |
| BayesSR [43] | 24.64/0.8205 | -/- |
| TOFlow [39] | 33.08/0.9054 | 34.83/0.9220 |
| DUF [33] | 34.33/0.9227 | 36.37/0.9387 |
| RBPN [9] | -/- | 37.07/0.9435 |
| SAA (Ours) | 35.22/0.9310 | 37.00/0.9432 |
| SAA+ (Ours) | 35.44/0.9329 | 37.24/0.9448 |
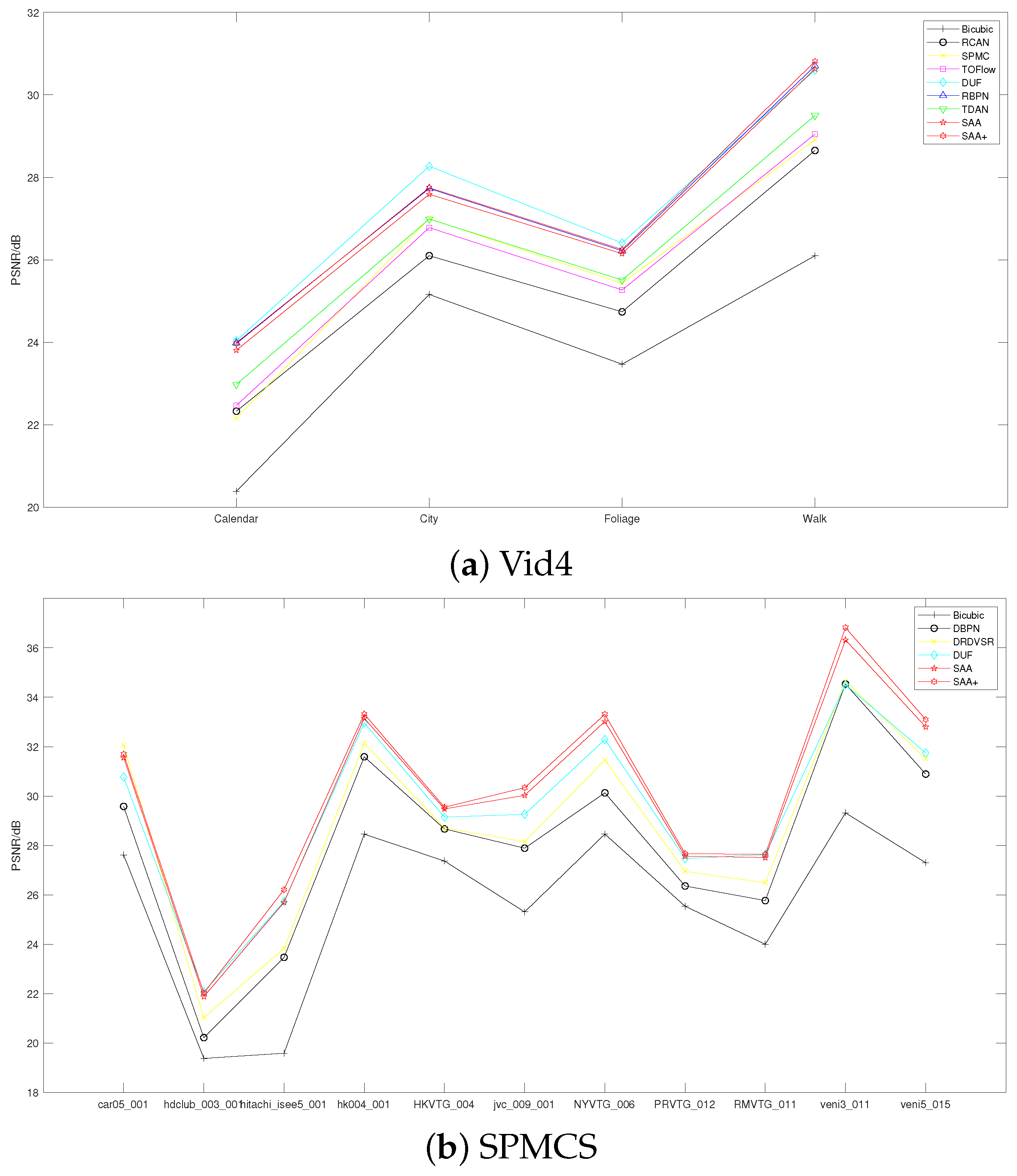
| Methods | Calendar (Y) | City (Y) | Foliage (Y) | Walk (Y) | Average (Y) |
|---|---|---|---|---|---|
| Bicubic | 20.39/0.5720 | 25.16/0.6028 | 23.47/0.5666 | 26.10/0.7974 | 23.78/0.6347 |
| RCAN [18] | 22.33/0.7254 | 26.10/0.6960 | 24.74/0.6647 | 28.65/0.8719 | 25.46/0.7395 |
| VESPCN [8] | -/- | -/- | -/- | -/- | 25.35/0.7557 |
| SPMC [2] | 22.16/0.7465 | 27.00/0.7573 | 25.43/0.7208 | 28.91/0.8761 | 25.88/0.7752 |
| TOFlow [39] | 22.47/0.7318 | 26.78/0.7403 | 25.27/0.7092 | 29.05/0.8790 | 25.89/0.7651 |
| FRVSR [3] | -/- | -/- | -/- | -/- | 26.69/0.8220 |
| DUF [33] | 24.04/0.8110 | 28.27/0.8313 | 26.41/0.7709 | 30.60/0.9141 | 27.33/0.8318 |
| RBPN [9] | 23.99/0.807 | 27.73/0.803 | 26.22/0.757 | 30.70/0.909 | 27.12/0.818 |
| TDAN [44] | 22.98/0.756 | 26.99/0.757 | 25.51/0.717 | 29.50/0.890 | 26.24/0.780 |
| SAA (Ours) | 23.81/0.8005 | 27.59/0.7962 | 26.15/0.7530 | 30.63/0.9077 | 27.05/0.8144 |
| SAA+ (Ours) | 23.97/0.8055 | 27.75/0.8031 | 26.25/0.7564 | 30.81/0.9099 | 27.20/0.8187 |
| Clips | Bicubic | DBPN [27] | DRDVSR [2] | DUF [33] | SAA (Ours) | SAA+ (Ours) |
|---|---|---|---|---|---|---|
| car05_001 | 27.62 | 29.58 | 32.07 | 30.77 | 31.56 | 31.70 |
| hdclub_003_001 | 19.38 | 20.22 | 21.03 | 22.07 | 21.88 | 22.03 |
| hitachi_isee5_001 | 19.59 | 23.47 | 23.83 | 25.73 | 25.70 | 26.21 |
| hk004_001 | 28.46 | 31.59 | 32.14 | 32.96 | 33.15 | 33.32 |
| HKVTG_004 | 27.37 | 28.67 | 28.71 | 29.15 | 29.48 | 29.55 |
| jvc_009_001 | 25.31 | 27.89 | 28.15 | 29.26 | 30.03 | 30.34 |
| NYVTG_006 | 28.46 | 30.13 | 31.46 | 32.29 | 33.02 | 33.31 |
| PRVTG_012 | 25.54 | 26.36 | 26.95 | 27.47 | 27.57 | 27.67 |
| RMVTG_011 | 24.00 | 25.77 | 26.49 | 27.63 | 27.51 | 27.64 |
| veni3_011 | 29.32 | 34.54 | 34.66 | 34.51 | 36.32 | 36.82 |
| veni5_015 | 27.30 | 30.89 | 31.51 | 31.75 | 32.80 | 33.10 |
| Average | 25.67/0.726 | 28.10/0.820 | 28.82/0.841 | 29.42/0.867 | 29.91/.8708 | 30.15/.8744 |
| Methods | ||||
|---|---|---|---|---|
| MFE-CF? | × | ✓ | × | ✓ |
| ? | × | × | ✓ | ✓ |
| PSNR (dB)/SSIM (Y) | 35.08/0.9192 | 35.31/0.9246 | 35.37/0.9251 | 35.44/0.9264 |
| PSNR (dB)/SSIM (RGB) | 33.35/0.9040 | 33.54/0.9093 | 33.57/0.9095 | 33.66/0.9113 |
| Methods | ||||
|---|---|---|---|---|
| Skips between SAAMs? | × | ✓ | × | ✓ |
| SSR inside each SAAM? | × | × | ✓ | ✓ |
| PSNR (dB)/SSIM (Y) | 35.20/0.9238 | 35.42/0.9261 | 35.42/0.9262 | 35.44/0.9264 |
| PSNR (dB)/SSIM (RGB) | 33.26/0.9064 | 33.57/0.9103 | 33.64/0.9110 | 33.66/0.9113 |
| M | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| PSNR (dB)/SSIM (Y) | 35.05/0.9213 | 35.29/0.9244 | 35.46/0.9265 | 35.60/0.9282 | 35.61/0.9284 |
| PSNR (dB)/SSIM (RGB) | 33.29/0.9056 | 33.52/0.9091 | 33.67/0.9114 | 33.81/0.9132 | 33.84/0.9137 |
| F | 1 | 3 | 5 | 7 |
|---|---|---|---|---|
| PSNR (dB)/SSIM (Y) | 34.31/0.9099 | 34.69/0.9151 | 35.17/0.9225 | 35.44/0.9264 |
| PSNR (dB)/SSIM (RGB) | 32.60/0.8933 | 32.97/0.8993 | 33.40/0.9071 | 33.66/0.9113 |
| C | 16 | 32 | 64 | 128 |
|---|---|---|---|---|
| PSNR (dB)/SSIM (Y) | 35.05/0.9213 | 35.53/0.9273 | 35.95/0.9323 | 36.20/0.9351 |
| PSNR (dB)/SSIM (RGB) | 33.29/0.9056 | 33.76/0.9125 | 34.18/0.9183 | 34.42/0.9216 |
| R | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| PSNR (dB)/SSIM (Y) | 35.44/0.9264 | 35.60/0.9282 | 35.82/0.9309 | 35.88/0.9314 | 35.91/0.9318 |
| PSNR (dB)/SSIM (RGB) | 33.66/0.9113 | 33.81/0.9133 | 34.01/0.9161 | 34.07/0.9168 | 34.10/0.9173 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, T.; Dai, T.; Liu, L.; Zhu, Z.; Xia, S.-T. S2A: Scale-Attention-Aware Networks for Video Super-Resolution. Entropy 2021, 23, 1398. https://doi.org/10.3390/e23111398
Guo T, Dai T, Liu L, Zhu Z, Xia S-T. S2A: Scale-Attention-Aware Networks for Video Super-Resolution. Entropy. 2021; 23(11):1398. https://doi.org/10.3390/e23111398
Chicago/Turabian StyleGuo, Taian, Tao Dai, Ling Liu, Zexuan Zhu, and Shu-Tao Xia. 2021. "S2A: Scale-Attention-Aware Networks for Video Super-Resolution" Entropy 23, no. 11: 1398. https://doi.org/10.3390/e23111398
APA StyleGuo, T., Dai, T., Liu, L., Zhu, Z., & Xia, S.-T. (2021). S2A: Scale-Attention-Aware Networks for Video Super-Resolution. Entropy, 23(11), 1398. https://doi.org/10.3390/e23111398