Abstract
There is no generally accepted definition for conditional Tsallis entropy. The standard definition of (unconditional) Tsallis entropy depends on a parameter that converges to the Shannon entropy as approaches 1. In this paper, we describe three proposed definitions of conditional Tsallis entropy suggested in the literature—their properties are studied and their values, as a function of , are compared. We also consider another natural proposal for conditional Tsallis entropy and compare it with the existing ones. Lastly, we present an online tool to compute the four conditional Tsallis entropies, given the probability distributions and the value of the parameter .
1. Introduction
Tsallis entropy [1], (The name Tsallis entropy used in this paper, to identify the quantity presented in Equation (3), is not consensual in the community, given that before Tsallis presented it in 1988, and as he himself acknowledges, other authors had already introduced it [2,3,4].) a generalization of Shannon entropy [5,6], was extensively studied by Constantino Tsallis in 1988, and provides an alternative way of dealing with several characteristics of nonextensive physical systems, given that the information about the intrinsic fluctuations in the physical system can be characterized by the nonextensivity parameter . It can be applied to many scientific fields, such as physics [7], economics [8], computer science [9,10], and biology [11]. We refer the reader to Reference [12] for a more extensive bibliography on applications of Tsallis entropy. Furthermore, we refer the reader to Reference [13] for a survey on the most significant areas of application of the most usual entropy measures, including Shannon [6], Rényi [14], and Tsallis entropies [1,2,3,4].
It is known that, as the parameter approaches 1, the Tsallis entropy corresponds to the Shannon entropy. Unlike for Shannon entropy, but similar to Rényi entropy (yet another generalization of Shannon entropy developed by Alfréd Rényi in 1961 [14], which also depends on a parameter and converges to Shannon entropy when approaches 1), there is no commonly accepted definition for the conditional Tsallis entropy: several versions have been proposed and used in the literature [15,16]. In this work, we revisit the notion of conditional Tsallis entropy by studying some natural and desirable properties in the existing proposals (see for instance References [15,16]): when , the usual conditional Shannon entropy should be recovered, the conditional Tsallis entropy should not exceed the unconditional Tsallis entropy, and the conditional Tsallis entropy should have values between 0 and the maximum value of the unconditional version.
The use of entropies in different fields, especially in the field of information theory and its connection to communication, allowed the development of several useful information measures, such as mutual information, symmetry of information, and information distances. See, for example, References [17,18,19] for some recent work related to the aforementioned information measures.
Depending on the entropy measure used, all of these have been applied in many different areas of knowledge, such as physics [20], information theory [21,22], complexity theory [23,24,25], security [26,27,28], biology [29,30,31,32], finances [33], and medicine [34,35,36], among others. The conditional Tsallis entropy, as suggested in Reference [37], can be directly applied to information theory, especially coding theory. Furthermore, since Tsallis entropy can be applied in many areas (see, for example, Reference [12]), the study of conditional Tsallis entropies is quite promising. This paper analyzes several definitions of conditional Tsallis entropy, with the intent of providing the reader with a description of the properties that each approach satisfies.
Continuing from previous works [37,38], we introduce a new natural definition for conditional Tsallis entropy as a possible alternative to the existing ones. Our new proposal does not intend to be the ultimate version of conditional Tsallis entropy, but an alternative to the existing ones, with its own properties that, in settings, such as biomedical applications, might be useful for defining information distances or other significant measurements. None of the known definitions contain all of the desired properties for a conditional version. In particular, the one presented here (as it takes the maximum over the marginal distributions) does not converge to the Shannon entropy when —it behaves similar to a parameterized entropy, and is akin to the one proposed in Reference [38] as an alternative to Rényi’s conditional entropy, another generalization of Shannon entropy.
The paper is organized as follows. In the next section, we present the definitions necessary for the rest of the paper, namely Shannon entropy and Tsallis entropy. In Section 3, we provide several definitions for the conditional Tsallis entropy in both existing literature and our proposal. In Section 4, we establish several results, comparing the definitions presented previously. In Section 5, we explore some features of each variant for the conditional Tsallis entropy. Finally, in Section 6, we present the conclusions and future work.
2. Preliminaries
In the remainder of the paper, we use the standard notation for entropies and for probability distributions according to Reference [5]. For the sake of simplicity of notation, we use the notation log for the logarithm in base 2. We call the reader’s attention to the fact that, whenever we say that one entropy converges to another, it is always up to logarithmic factor that depends only on the choice of cardinality of the alphabet.
The Shannon entropy of X is the expectation of the surprise of an occurrence,
The conditional Shannon entropy, , is the expectation over x of the entropy of the distribution ,
It is easy to derive the chain rule : to get the average information contained in , we may first get the average information contained in X, and add to it the average information of Y, given X.
The Tsallis entropy [1] was firstly introduced in [2,3] and is defined for a random variable X by:
It is straightforward to show that, when the parameter converges to 1, the value of the entropy converges to the Shannon entropy.
3. Conditional Tsallis Entropy: Four Definitions
We consider three definitions for conditional Tsallis entropy that already exist in the literature and introduce a new proposal. All definitions consider a positive parameter .
Definition 1.
Let be a random vector. One can define the following variants of conditional Tsallis entropy:
- 1.
- Definition of from Reference [15]One can easily verify that and, therefore, it satisfies the chain rule.
- 2.
- Definition of from [16] (Definition 2.8)
- 3.
- Definition of from [16] (Definition 2.10)
The first definition presented proposes that the conditional Tsallis entropy should be weighed by the probability of sampling with parameter , while the second one proposes that one uniformly weighs only the probability of sampling . Therefore, notice that for the first definition presented, the value of largely affects the value of the conditional Tsallis entropy. The idea for the third proposal is to distribute evenly the influence of the parameter by the entire joint distribution.
Next, we present another possible definition of the conditional Tsallis entropy. This definition is based on Definition III.6 of [38] and captures the intuitive notion of defining the conditional entropy, by taking the maximum over all possible marginal distributions. Note that this definition is analogous to an existing one for the Rényi entropy; however, as we will show later, this proposal does not satisfy some of the expected basic properties.
Definition 2
(Definition of ).
We opted to use different notations for the variants of the conditional Tsallis entropy in the last definition, to better distinguish them in the rest of the paper. In particular, we follow the same approach as in Reference [38].
The following expressions will be useful later.
Theorem 1.
Let be a random vector. The following identities are true:
4. Comparison of the Definitions
We now compare the above four definitions of the conditional Tsallis entropy by comparing whether or not the definition satisfies some common properties of an entropy measure. In the next theorem, we report two simple facts with straightforward proofs. We leave the details for the interested reader to check.
Theorem 2.
For any fixed joint probability distribution ,
- (i)
- , and , as functions of α, are continuous and differentiable;
- (ii)
- , as a function of α, is continuous for all .
The following results provide the possible comparisons (in terms of values) between the proposed definitions. For the sake of organization, we split the comparison by types of entropy.
First we compare with .
Theorem 3.
For all joint probability distributions and for every ,
Proof.
Consider first the case . In this case, we have that . Thus,
For the case , see the proof of Theorem 8.
The case is similar to the previous one, but this time, the conclusion follows, since for , . □
In the next theorem we provide the comparison between and .
Theorem 4.
For all joint probability distributions and for every ,
Proof.
Consider first the case . In this case, we have that . So,
The proof of the case is similar to the previous one but this time, the conclusion follows from the fact that, for , . □
As a consequence of the two previous results and the definitions, we can derive the relation between and .
Corollary 1.
For all joint probability distributions and for every ,
The proof follows directly from Theorems 3 and 4. Now, we derive the relation between and .
Theorem 5.
For all joint probability distributions and for every ,
Proof.
Consider first the case . Proving that , by definition, is the same to prove:
As , we have that . Thus, proving Equation (27) is the same, proves that:
Now, the result follows by observing that the last inequality is true, since, for and for every x, we have that
The case is proved in a similar manner. □
Now, we derive the relation between and .
Theorem 6.
For all joint probability distributions and for every ,
Proof.
Consider first the case . Thus,
The result follows by observing that the last inequality is true, since for , we have that:
and consequently,
The proof of the case is similar to the previous one. □
Finally, we show that the values of and are incomparable in the sense that there are probability distributions for which is greater than and there are probability distributions for which is greater than .
Theorem 7.
The values of and of are incomparable, i.e., for each and
Proof.
For Statement (32) and , consider the following joint probability distribution:
For Statement (32) and , consider the following joint probability distribution:
For Statement (33) and , consider the following joint probability distribution:
Finally, for Statement (33) and , consider the following joint probability distribution:
□
5. Properties of the Conditional Tsallis Entropies
In this section, we investigate some properties of the proposals considered. In particular, we show that there are probability distributions and for which the conditional Tsallis entropies are bigger than the unconditional Tsallis entropy.
Theorem 8.
For any fixed joint probability distribution ,
where is the conditional Shannon entropy. In general, it is not true that .
Proof.
The second equation is easy to derive directly from the definition of conditional probability and from Equation (2). Furthermore, using Equation (6) we can also easily obtain (using the previous derivation) that Equation (42) is also true.
The third equation was proven in Reference [16].
Now, it is only left to prove the last statement of the theorem, i.e., in general
From Equations (6) and (11) it is easy to check that is the expectation over x of , while is the maximum over x of .
The function depends on the conditional probabilities . Therefore, there are joint probability distributions , such that:
□
Contrary to the Shannon entropy, the value of any conditional Tsallis entropy may exceed the corresponding unconditional Tsallis entropy for all proposals.
Theorem 9.
There are probability distributions and values of α, such that:
Proof.
Consider the following joint probability distribution:
For this distribution we have:
□
Bounds on Conditional Tsallis Entropy
As mentioned in the Introduction, one of the properties of the (conditional) Shannon entropy for discrete variables is to be bounded by the number of elements of the support of the distribution. Furthermore, it is well known that the unconditional Tsallis entropy is always between 0 and , where m is the number of elements in the support of the distribution. In this subsection, we derive bounds for the conditional Tsallis entropies based on the number of elements in the support of each distribution.
Theorem 10.
Let be any joint random vector defined over sets of size m each. Then,
Moreover all of these lower and upper bounds may be reached by suitable probability distributions .
Proof.
The Inequalities (57) follow from the fact that is the expectation of the unconditional Tsallis entropy.
For Inequalities (58), recall that Equation (10) can be written, for , as Equation (12). Note that, for all x, the values are the (unconditional) Tsallis entropies of the marginal distribution, and are all defined in a set of cardinality m.
So, by definition of , for some particular x, we have . The case is similar. So, independently of , for every probability distributions and defined over set with m elements, we have , since the same bound applies for the unconditional version or any its marginal distributions. □
Theorem 11.
Let be any joint random vector defined over sets of size m each. Then,
For , in general, the inequality does not hold.
Proof.
In order to prove that the inequality does not hold for all , consider and the following joint probability distribution:
Notice that and . For any other , one can construct similarly a joint probability distribution for which the inequality is also violated. □
Theorem 12.
Let be any joint random vector defined over sets of size m each. Then,
We conjecture that the above theorem also holds for . For example, the inequality is true for all uniform probability distribution over n variables.
We now show that, for any fixed joint probability distribution , three of the forms of conditional Tsallis entropy studied in this paper are non-increasing functions of . First, we state a simple theorem.
Lemma 1.
If ,…, are non-increasing real functions, then the function is also a non-increasing function.
Theorem 13.
For every probability distribution ,
- 1.
- is a non-increasing function of α.
- 2.
- is a non-increasing function of α.
- 3.
- is a non-increasing function of α.
Proof.
- 1.
- First consider the case , and consider the function , the derivative of the function in order to :It is easy to see that, since , . Therefore, the function is a non-increasing function of .
Consider now the case and assume that are such that . In order to prove that is non-increasing we have to show that , i.e.,:
Notice that, since , Then and, therefore, . So, the last inequality is true.
□
It is easy to show that does not fulfill the property of the last theorem.
Theorem 14.
There exists probability distributions and for which .
Proof.
Consider the following joint probability distribution:
We have:
□
We developed a small application that, given two probability distributions, computes the values of all conditional Tsallis entropies considered in the paper. The application is self-contained and its use is extremely simple. There are two use case examples that the reader can use in order to try the calculator. The interested reader can find it in the following link: http://gloss.di.fc.ul.pt/tryit/Tsallis (accessed on 28 October 2021).
6. Conclusions
In this paper, we studied the definitions for the conditional Tsallis entropy existing in the literature. We also considered a possible alternative definition for it. This new proposal is a natural approach to consider as a possible definition. It defines the conditional value as the maximum value of all marginal distributions. Due to this fact, and similar to what happens with the Rényi entropy, this definition was also analyzed, although it was never considered in the literature before. The relationships between the four definitions, described in this work, are summarized in Figure 1.
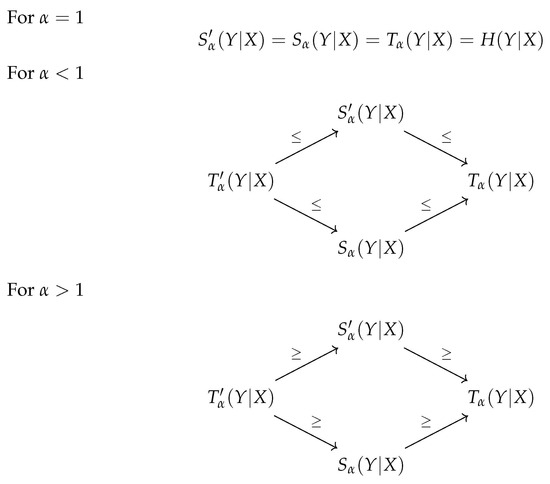
Figure 1.
Summary of the relations between the several proposals for the definition of conditional Tsallis entropy.
As we understand, it would be expectable that a proposal for conditional Tsallis entropy would satisfy the following properties:
- Chain Rule;
- Convergence to Shannon entropy as the parameter tended to 1;
- Its value would be between 0 and the upper bound of the unconditional version.
In Table 1, we summarize the properties that the four proposals have (we also added the property of being a non-increasing function with ). To conclude, we can say that none of the proposals fulfill all of the properties. The definition is the candidate that fulfills more properties.

Table 1.
Summary of the proved properties of all proposed conditional entropies. The question mark indicates that the property is not known to be fulfilled.
For future work, since all definitions focus on possible different aspects of the entropy, it would be important to consider a deeper study in this area and its possible applications, aiming to develop a theory that would emphasize the best proposal for each area, or eventually present an ultimate version for the conditional Tsallis entropy that would satisfy all of the desirable properties.
Author Contributions
Conceptualization, A.T., A.S. and L.A.; methodology, A.T., A.S. and L.A.; validation, A.T., A.S. and L.A.; formal analysis, A.T. and A.S.; investigation, A.T., A.S. and L.A.; writing—original draft preparation, A.T. and A.S.; writing—review and editing A.T., A.S. and L.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by FCT—Fundação para a Ciência e a Tecnologia, within CINTESIS, R&D Unit (reference UIDB/4255/2020), within Instituto de Telecomunicações (IT) Research Unit ref. UIDB/EEA/50008/2020 and within LASIGE Research Unit, ref. UIDB/00408/2020 and ref. UIDP/00408/2020. It was also supported by the projects Predict PTDC/CCI-CIF/29877/2017, QuantumMining POCI-01-0145-FEDER-031826 funded by FCT through national funds, by the European Regional Development Fund (FEDER), through the Competitiveness and Internationalization Operational Programme (COMPETE 2020), from EU H2020-SU-ICT-03-2018 project no. 830929 CyberSec4Europe (cybersec4europe.eu), and also the project “Safe Cities”, reference POCI-01-0247-FEDER-041435, financed by Fundo Europeu de Desenvolvimento Regional (FEDER),through COMPETE 2020 and Portugal 2020.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Daróczy, Z. Generalized information functions. Inf. Control 1970, 16, 36–51. [Google Scholar] [CrossRef] [Green Version]
- Havrda, J.; Charvat, F. Quantification method of classification processes. concept of structural α-entropy. IEEE Trans. Inf. Theory 1967, 3, 30–35. [Google Scholar]
- Wehrl, A. General properties of entropy. Rev. Mod. Phys. 1978, 50, 221–260. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef] [Green Version]
- Tsallis, C. The Nonadditive Entropy Sq and Its Applications in Physics and Elsewhere: Some Remarks. Entropy 2011, 13, 1765–1804. [Google Scholar] [CrossRef]
- Borland, R.O.L.; Tsallis, C. Distributions of high-frequency stock-market observables. In Nonextensive Entropy—Interdisciplinary Applications; Gell-Mann, M., Tsallis, C., Eds.; Oxford University Press: New York, NY, USA, 2004. [Google Scholar]
- Ibrahim, R.W.; Darus, M. Analytic Study of Complex Fractional Tsallis’ Entropy with Applications in CNNs. Entropy 2018, 20, 722. [Google Scholar] [CrossRef] [Green Version]
- Mohanalin, B.; Kalra, P.K.; Kumar, N. A novel automatic microcalcification detection technique using Tsallis entropy and a type II fuzzy index. Comput. Math. Appl. 2010, 60, 2426–2432. [Google Scholar]
- Tamarit, F.A.; Cannas, S.A.; Tsallis, C. Sensitivity to initial conditions in the Bak-Sneppen model of biological evolution. Eur. Phys. J. B 1998, 1, 545–548. [Google Scholar] [CrossRef]
- Group of Statistical Physics. Available online: http://tsallis.cat.cbpf.br/biblio.htm (accessed on 8 November 2018).
- Ribeiro, M.; Henriques, T.; Castro, L.; Souto, A.; Antunes, L.; Costa-Santos, C.; Teixeira, A. The Entropy Universe. Entropy 2021, 23, 222. [Google Scholar] [CrossRef]
- Rényi, A. On measures of information and entropy. Berkeley Symp. Math. Statist. Prob. 1961, 1, 547–561. [Google Scholar]
- Furuichi, S. Information theoretical properties of Tsallis entropies. J. Math. Phys. 2006, 47, 023302. [Google Scholar] [CrossRef] [Green Version]
- Manije, S.; Gholamreza, M.; Mohammad, A. Conditional Tsallis Entropy. Cyb. Inf. Technol. 2013, 13, 37–42. [Google Scholar] [CrossRef]
- Heinrich, F.; Ramzan, F.; Rajavel, F.A.; Schmitt, A.O.; Gültas, M. MIDESP: Mutual Information-Based Detection of Epistatic SNP Pairs for Qualitative and Quantitative Phenotypes. Biology 2021, 10, 921. [Google Scholar] [CrossRef] [PubMed]
- Oggier, F.; Datta, A.A. Renyi entropy driven hierarchical graph clustering. PeerJ Comput. Sci. 2021, 7, e366. [Google Scholar] [CrossRef]
- Tao, M.; Wang, S.; Chen, H.; Wang, X. Information space of multi-sensor networks. Inf. Sci. 2021, 565, 128–245. [Google Scholar] [CrossRef]
- Jozsa, R.; Schlienz, J. Distinguishability of states and von Neumann entropy. Phys. Rev. A 2000, 62, 012301. [Google Scholar] [CrossRef] [Green Version]
- Hassani, H.; Unger, S.; Entezarian, M. Information content measurement of esg factors via entropy and its impact on society and security. Information 2021, 12, 391. [Google Scholar] [CrossRef]
- Shannon, C.E. Communication theory of secrecy systems. Bell Syst. Tech. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Bhotto, M.Z.A.; Antoniou, A. A new normalized minimum-error entropy algorithm with reduced computational complexity. In Proceedings of the 2009 IEEE International Symposium on Circuits and Systems, Taipei, Taiwan, 24–27 May 2009; pp. 2561–2564. [Google Scholar] [CrossRef]
- Teixeira, A.; Matos, A.; Souto, A.; Antunes, L. Entropy measures vs. Kolmogorov complexity. Entropy 2011, 13, 595–611. [Google Scholar] [CrossRef]
- Teixeira, A.; Souto, A.; Matos, A.; Antunes, L. Entropy measures vs. algorithmic information. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 1413–1417. [Google Scholar] [CrossRef] [Green Version]
- Edgar, T.; Manz, D. Chapter 2-Science and Cyber Security. In Research Methods for Cyber Security; Syngress: Amsterdam, The Netherlands, 2017; pp. 33–62. [Google Scholar]
- Huang, L.; Shen, Y.; Zhang, G.; Luo, H. Information system security risk assessment based on multidimensional cloud model and the entropy theory. In Proceedings of the 2015 IEEE 5th International Conference on Electronics Information and Emergency Communication, Beijing, China, 14–16 May 2015; pp. 11–15. [Google Scholar]
- Lu, R.; Shen, H.; Feng, Z.; Li, H.; Zhao, W.; Li, X. HTDet: A clustering method using information entropy for hardware Trojan detection. Tsinghua Sci. Technol. 2021, 26, 48–61. [Google Scholar] [CrossRef]
- Firman, T.; Balázsi, G.; Ghosh, K. Building Predictive Models of Genetic Circuits Using the Principle of Maximum Caliber. Biophys J. 2017, 113, 2121–2130. [Google Scholar] [CrossRef]
- Jost, L. Entropy and diversity. Oikos 2006, 113, 363–375. [Google Scholar] [CrossRef]
- Roach TNF. Use and Abuse of Entropy in Biology: A Case for Caliber. Entropy 2020, 22, 1335. [Google Scholar] [CrossRef] [PubMed]
- Simpson, E. Measurement of diversity. Nature 1949, 163, 688. [Google Scholar] [CrossRef]
- Yin, Y.; Shang, P. Weighted permutation entropy based on different symbolic approaches for financial time series. Phys. A Stat. Mech. Its Appl. 2016, 443, 137–148. [Google Scholar] [CrossRef]
- Castiglioni, P.; Parati, G.; Faini, A. Information-Domain Analysis of Cardiovascular Complexity: Night and Day Modulations of Entropy and the Effects of Hypertension. Entropy 2019, 21, 550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Polizzotto, N.R.; Takahashi, T.; Walker, C.P.; Cho, R.Y. Wide Range Multiscale Entropy Changes through Development. Entropy 2016, 18, 12. [Google Scholar] [CrossRef] [Green Version]
- Prabhu, K.P.; Martis, R.J. Diagnosis of Schizophrenia using Kolmogorov Complexity and Sample Entropy. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Fehr, S.; Berens, S. On the Conditional Rényi Entropy. IEEE Trans. Inf. Theory 2014, 60, 6801–6810. [Google Scholar] [CrossRef]
- Teixeira, A.; Matos, A.; Antunes, L. Conditional Rényi Entropies. IEEE Trans. Inf. Theory 2012, 58, 4273–4277. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).