1. Introduction
With the continuous development of the Internet, the number of users on the network has grown extremely fast, and the scale of the inter-domain routing systems has continued to increase. An inter-domain routing system is a dynamic system composed of multiple autonomous systems (AS). It usually has four kinds of business relationships: customer-to-provider, provider-to-customer, peer-to-peer, and sibling-to-sibling [
1]. AS generally refers to a collection of routers that belong to a management organization, and they can make their routing strategy. The routing information is exchanged between AS through the inter-domain routing protocol. Here it refers to the border gateway protocol (BGP). As the Internet’s only inter-domain routing protocol, BGP is the postal service of the Internet. AS plays the role of a branch of the post office. When users’ data requests were sent across the Internet, all of the data transmissions’ available paths were charged by BGP. It chooses the best route, making a hop between autonomous systems.
The BGP protocol greatly facilitates the transmission of information over the Internet. However, the inter-domain routing systems face many security threats because of the security defects of BGP [
2,
3,
4,
5,
6]. The local failure caused by an intentional attack or self-failure of critical nodes in the network may continue to spread rapidly and wildly and eventually cause the whole network to be paralyzed on a large scale. This phenomenon is called a cascading failure. Some researchers have proposed a series of attacks that can cause the cascading failure of inter-domain routing systems, such as coordinated cross plane session termination (CXPST) [
7] attacks, BGP stress attacks [
8], and distributed network paralyzing (DNP) attacks [
9]. This kind of attack mainly causes cascading failures of inter-domain routing systems by attacking key nodes and leading to colossal inter-domain routing system losses. Therefore, finding critical nodes in the inter-domain routing systems and implementing security policies in advance is of great significance to protect the inter-domain routing systems.
In previous studies, the importance of nodes was defined mainly by a single indicator, such as degree [
10], betweenness [
11], the clustering coefficient [
12], and so on. In ordinary complex networks, this kind of method usually has better results. As for the inter-domain routing systems, due to its business relationships and dynamic characteristics, a single indicator cannot reflect the impact of node failure on the network. Then, some researchers added some indicators closely related to nodes based on a single indicator to assist in evaluating the importance of nodes, such as the substitutability of nodes [
13], the connection ability of edges [
14], the weak connection property of nodes [
15], and so on. However, when multiple indicators are applied, the weight of each indicator is not considered, and the default value is the same. It is unreasonable. In addition, the importance value of nodes is obtained by simply adding multiple indicators or adding reciprocal sums, which cannot reflect the advantages of each indicator. In summary, the deficiencies of existing research are as follows:
- (1)
The indicator proposed by the researchers does not take into account cascading-failure processes in inter-domain routing systems.
- (2)
There is no reasonable method to calculate the weight of each indicator.
- (3)
Simple addition does not reflect the advantages of each indicator.
In order to better solve the existing problems in existing research, this study proposed a method for identifying key nodes in inter-domain routing systems based on cascading failures (IKN-CF). IKN-CF considers the cascading-failure characteristics of inter-domain routing systems and the business relationships, proposes two cascading indicators, and calculates the importance of nodes through improved the entropy weight TOPSIS (EWT) model. The results verify that the work in this study is meaningful. In general, the contributions of this study are as follows:
- (1)
We analyzed the topology of inter-domain routing networks and proposed an optimal valid path discovery algorithm considering business relationships.
- (2)
We analyzed the cause and propagation mechanism of cascading failures in the inter-domain routing network and proposed two cascading indicators, which can approximate the impact of node failure on the network.
- (3)
We established a key node identification model based on improved entropy weight TOPSIS, and the sequence of key nodes in the network can be obtained through model calculations.
The remainder of this article is arranged as follows:
Section 2 introduces the preliminaries and related work. In
Section 3, we analyze the topology of inter-domain routing systems and describe business relationships. Based on business relationships, an optimal routing path discovery algorithm is proposed.
Section 4 introduces the implementation process of the IKN-CF method in detail. Experiments and analyses are described in
Section 5. The last section summarizes the study and provides our conclusions.
3. Topology Analysis of Inter-Domain Routing Systems
The topology of inter-domain routing systems conforms to the general rules of complex network, such as scale-free characteristics and small-world characteristics. However, the inter-domain routing systems has business relationships that are not available in general complex networks, resulting in the path of the inter-domain routing network being divided into two types, namely, valid paths and invalid paths.
3.1. Business Relationships
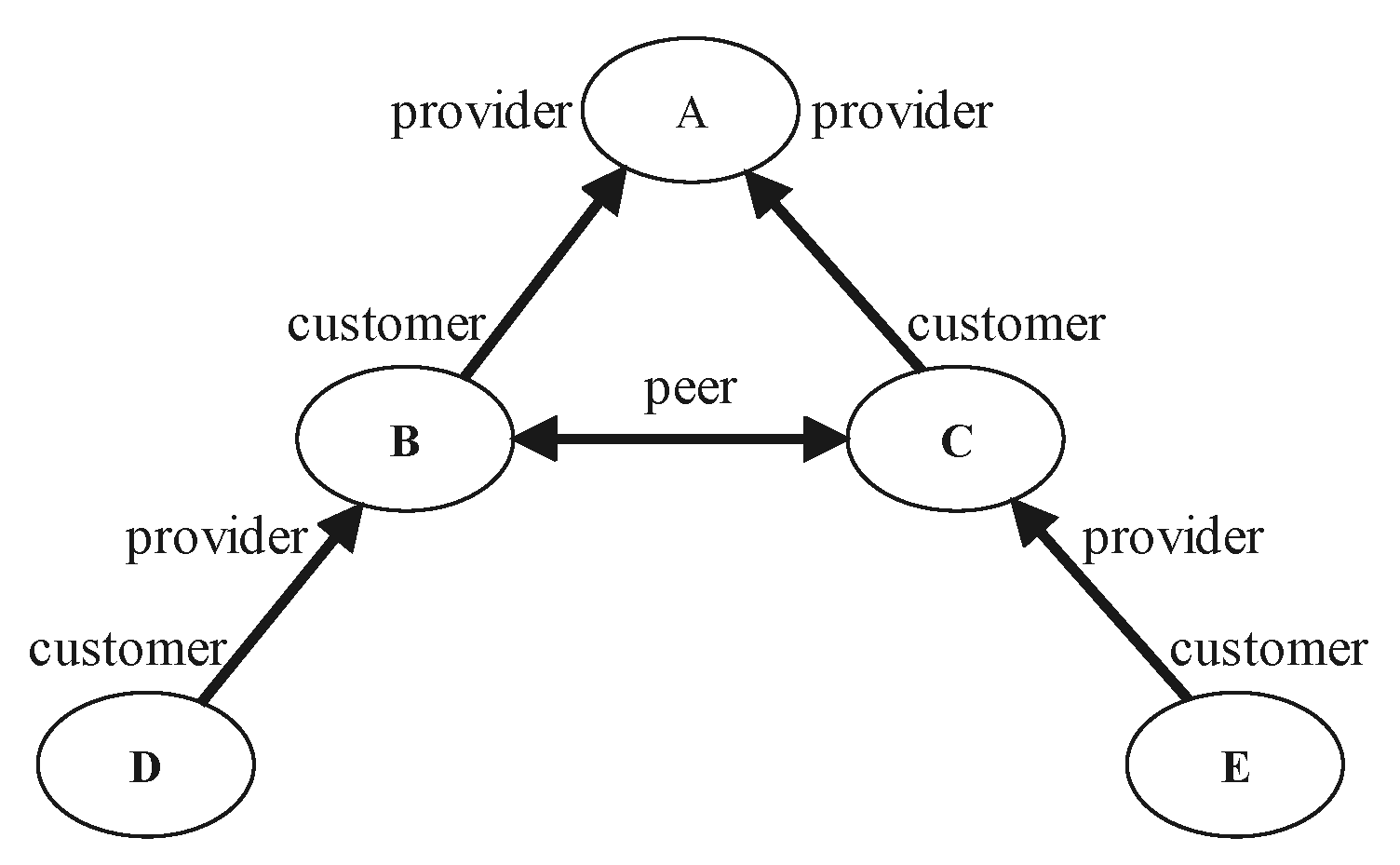
A business relationship is a paid relationship in which customers can exchange traffic with the service provider only if they pay the service provider. There are complex business relationships in the inter-domain routing systems. For the inter-domain routing network, even if two nodes have a connection relationships but no business relationships, then the information cannot be transmitted.
Service providers play an important role in the Internet, providing new users with access to the Internet services. Business relationships can be summarized into three types: provider-to-customer (P2C) or C2P, peer-to-peer (P2P), and sibling-to-sibling (S2S) [
28]. S2S only occurs in a few cases, and in order to make the study more general, S2S was not considered in this study.
The business relationships is shown in the
Figure 1, with the arrow of the line in the direction of payment. For example,
means that customer B pays provider A, and B is a customer of A, that is, a C2P. A is the provider of B, that is, the P2C. At this time, customer B can exchange information with A to obtain resources. Similarly, customer D has to pay B to access resources. For
, it is a peer relationship, that is, a P2P. The relationship between the two ends of the connection is equal, and information can usually be exchanged for free. Therefore, to exchange information between nodes of an inter-domain routing systems, links and business relationships are required. Otherwise, the path may be invalid. The following examples illustrate valid and invalid paths.
Article [
28] gives the definitions of a valid path and an invalid path in inter-domain routing systems. In the path from the source AS node to the target AS node, each relay AS node has a customer connected to it. Such a path is called a valid path. Contrary to the valid path, at least one relay AS node does not pay customers to it. Such a path is called an invalid path. Therefore, the key to determining whether it is a valid path is to find all relay AS nodes and determine whether there are customers connected to them.
Figure 2 shows several common path modes, with the bold line being the current path. The path in
Figure 2a is (D,B,A,C,E). Among them, B, A, and C are relay AS nodes, and their customers are D, B and C, and E, respectively. Therefore, (D,B,A,C,E) are valid paths. Similarly, (D,B,C,E) in
Figure 2b are valid paths. In
Figure 2c, the relay node in the path (F,B,A) is B, while node B in the path has no customers connected to it, so (F,B,A) is an invalid path. Similarly, (F,B,C,E) in
Figure 2d are also invalid paths. The general pattern of valid paths can be summarized from the examples: first, there are zero or more C2P, followed by zero or one P2P, and finally zero or more P2C.
3.2. Optimal Valid Path Discovery Algorithm Considering Business Relationships
When calculating the routing path, the general shortest path algorithm is not suitable for inter-domain routing networks.Therefore, calculating the routing path considering the business relationships needs a new algorithm to solve it.
Based on the two-way Dijkstra algorithm, this study proposed an optimal valid path discovery algorithm (DBR) that considers business relationships. The main process of the DBR is shown in Algorithm 1. The idea is that on the basis of two-way Dijkstra algorithm, the judgment of whether the path is connected is added to it, so that the overall complexity of the algorithm will not increase. DBR can finally determine whether there is a valid path between two nodes, and if so, output the optimal valid path.
| Algorithm 1 DBR |
Input: Predecessor , successors , complex network G, , , forward business relationships , reverse business relationships
Output: The between the source node and the target node.
- 1:
- 2:
- 3:
whiledo - 4:
if then - 5:
←, - 6:
for v∈ do - 7:
for w ∈ do - 8:
if w∉ then - 9:
k← - 10:
if () or ( ) or ( ) then - 11:
- 12:
← v - 13:
← k - 14:
else - 15:
- 16:
end if - 17:
end if - 18:
if then - 19:
if () or ( ) or ( ) then - 20:
- 21:
end if - 22:
end if - 23:
end for - 24:
end for - 25:
else - 26:
, - 27:
for do - 28:
for do - 29:
if then - 30:
- 31:
if () or ( ) or ( ) then - 32:
- 33:
- 34:
- 35:
else - 36:
- 37:
end if - 38:
end if - 39:
if then - 40:
if () or ( ) or ( ) then - 41:
- 42:
end if - 43:
end if - 44:
end for - 45:
end for - 46:
end if - 47:
end while
|
In order to illustrate the effectiveness of the DBR algorithm, it was compared with the commonly used shortest path discovery algorithm [
29] (Dijkstra) in a simple network.
Figure 3 shows a simple network with business relationships. On the right is the business relationships between nodes, which is illustrated by (A,B,X). A and B are nodes, and X is the business relationships between A and B. If X = 1, then A and B are in a C2P relationship; if X = 0, then A and B are in a P2P relationship; and if X = −1, then A and B are in a P2C relationship. A total of 36 routing paths were found through the Dijkstra algorithm, and a total of 25 routing paths were found through the DBR algorithm. The extra 11 paths were confirmed to be invalid after a check. All the 11 extra paths were invalid. For example, there was no routing path for the node pair (1,7) and (1,9), and the path calculated by the Dijkstra algorithm was an invalid path. Therefore, it can be explained that the DBR algorithm can correctly identify the routing path in inter-domain routing systems.
4. IKN-CF
As shown in
Figure 4, IKN-CF mainly consists of four steps. The first step is to obtain basic network data, including business relationships and connection relationships. Then, the network topology is constructed to facilitate the calculation of the indicator. The second step is to select the cascading indicator that reflects the importance of the node, which is used to approximate the impact on the network after the node fails. The third step is to construct a key node identification model, including calculating the weight of the index and applying the TOPSIS method to obtain the importance value of the node. Finally, the ranking of importance of nodes is obtained. The important steps are described in detail below.
4.1. Selection of Cascading Indicators
4.1.1. Analysis of Cascading Indicators
In inter-domain routing systems, it is generally considered that the cascading impact of node failure on the network determines the importance of node in the network. The importance of nodes increases as this influence increases. Therefore, the primary problem of identifying key nodes is how to approximate the influence of the cascading-failures process on nodes and links in the network after node failure. It can be seen from the analysis of cascading failures in our previous work [
30], due to the cascading failures, that the failure of nodes in the inter-domain routing systems will have two effects on the network. On the one hand, the load of other nodes increases due to the propagation of UPDATE messages. If the load exceeds the capacity, the node fails. On the other hand, the load traffic of the failed node selects a new path to transmit information, and the load traffic of the selected link will increase. If it is greater than the capacity of the link, the link will also fail. The UPDATE messages propagation process corresponds to the change of control plane traffic, and the load redistribution process corresponds to the change of data plane traffic.
Figure 5 is used to illustrate the effect of node and link failure. The heavier colors of nodes or links in the figure are caused by increased loads. In
Figure 5a, after node G fails, neighbor nodes A and B will generate UPDATE messages, and reachable nodes C, D, E, and F of node G will receive UPDATE messages to increase the load. Afterwards, it is judged whether the number of UPDATE messages arriving at the same time is overloaded, and the overload becomes invalid. In
Figure 5b, after node G fails, link AG and BG through node G are disconnected, and the traffic load that originally passed through node G will be rerouted to link AC and BC. In this case, the load of link AC and BC increases. The overload state also becomes invalid. Therefore, how to select reference indicators to approximate the impact of these two aspects on the network is the primary problem to be solved in evaluating the importance of nodes.
In addition to the changes in the node or link status during the cascading-failures process, the greatest change is the change in the traffic in the network. It is precisely because of changes in flow that failure will be caused. It can be seen from the above examples that the more reachable nodes of a failed node, the more UPDATE messages generated by neighbor nodes after the failure. When the number of reachable nodes of a node’s neighbor reaches a certain scale, it can cause traffic congestion on the control plane, which is more likely to cause cascading failures. Therefore, the number of reachable nodes of the neighboring node was selected to indicate the impact of the node failure on the control plane. For the load redistribution process, data plane traffic overload is the direct cause of load redistribution. The heavier the link load is, the more data traffic the node forwards. When the node fails, a large number of loads are rerouted to other links, which may lead to load redistribution and cascading failures. Therefore, the number of link loads was selected to indicate the impact on the data plane after the node fails.
The number of reachable nodes (NR) and the number of link loads (NL) are called cascading indicators, which can approximate the impact of node failure on the network. These two indicators are both positive indicators, which are positively related to the importance of nodes.
4.1.2. Calculation of Cascading Indicators
From the above analysis, NR is used to represent the impact of node failure on the network data plane. The NR can be defined as:
where
is the neighbor node set of
, and
represents the reachable node of
, which can be obtained by the DBR algorithm presented in
Section 3.2. The larger the NR of a node is, the more important the node is.
NL was used to represent the influence of node failure on the network control plane. NL can be defined as:
where
is mainly related to the number of valid paths
calculated by the DBR algorithm and the unit traffic
on the link.
can be denoted as:
4.2. The Identifying Key Nodes Model
The weights for NR and NL cannot be obtained empirically. To be more objective and accurate, this study used entropy to calculate the weight of the indicator. The indicator that can reflect the importance of nodes is regarded as the scheme’s attributes, and the importance of each scheme is quantified by calculating the proximity to the best scheme of each attribute by TOPSIS. Finally, we can obtain the ranking of node importance.
is the set of nodes, and is the indicator set of nodes. The j-th indicator of the is denoted as . Then, the indicator matrix of the node can be expressed as .
4.2.1. Using Entropy to Calculate the Weight of Indicators
Generally, the information entropy of a certain indicator is smaller, and the variation of the indicator is greater. Therefore, the more information it can provide the greater its role in the TOPSIS and the greater its weight. In order to eliminate the impact of different orders of magnitude and units, we first needed to standardize the indicator matrix E, and then a normalized
was obtained. The process can be denoted as:
where
,
is the normalized value of the
j-th indicator of
.
is the maximum value of the
j-th indicator.
is the minimum value of the
j-th indicator.
Then, we calculated the information entropy
of the
j-th indicator in the
U, and
can be denoted as:
where
. When
,
,
can be denoted as:
The weight of the
j-th indicator can be denoted as:
where
.
Finally, the weight vector indicator was determined as , and .
4.2.2. Using TOPSIS to Calculate the Importance of Nodes
Firstly, the weighted normalized indicator matrix
was constructed from
W and
U. The calculation process can be denoted as:
where
is the element of the weighted normalized evaluation matrix
E, and
is the weight corresponding to the attribute.
is the element of the normalized evaluation matrix
U.
Secondly, to find out the positive ideal solution
and the negative ideal solution
for each indicator, the calculation process can be denoted as:
where
, and
is the maximum value of the
j-th indicator.
is the minimum value of the
j-th indicator.
Then, the weighted distance between each attribute and its positive ideal point
and negative ideal point
in the weighted normalized evaluation matrix is solved. The calculation process can be denoted as:
Finally, the importance value of each node is calculated, that is, the degree of closeness to the ideal point
. The calculation process can be denoted as:
where
is the proximity of
to the ideal point. The
is larger, the closer the evaluation attribute of
is to the positive ideal point, and its importance is higher. On the other hand, the
is smaller, the farther the evaluation attribute of
is from the positive ideal point, and its importance is lower.
6. Conclusions
For the shortcomings of traditional identification methods for important nodes in inter-domain routing systems, this study proposed a method for identifying key nodes in inter-domain routing systems based on cascading failures. In addition, based on the existing business relationships of inter-domain routing systems, this study proposed an optimal valid path discovery algorithm, which provides convenience for the calculation of cascading indicators. In the two inter-domain routing systems (India and the UK), we compared the top 100 in the ranking obtained by the IKN-CF, AIPR, SD-KNI, and degree. The experimental results show that the IKN-CF performed best, and the failure rate basically decreased with the increase in the importance-ranking number. Then, the KT was introduced. In the Indian network, the between IKN-CF and LOR. In the UK network, the between IKN-CF and LOR. Compared with the other three methods, IKN-CF had the highest KT with LOR, with an average increase of at least 12.8%. In addition, the KT of IKN-CF in the two networks was almost the same, which indicates that the IKN-CF is stable and widely applicable.
In future work, under the premise of considering the cost, we plan to analyze the damage strategy that the attacker may apply to provide a basis for defending the inter-domain routing systems. The IKN-CF can provide significant support for this.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}