
Learning to Classify DWDM Optical Channels from Tiny and Imbalanced Data


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Machine Learning Challenges
1.2. Related Work
1.3. Article organization
2. Materials and Methods
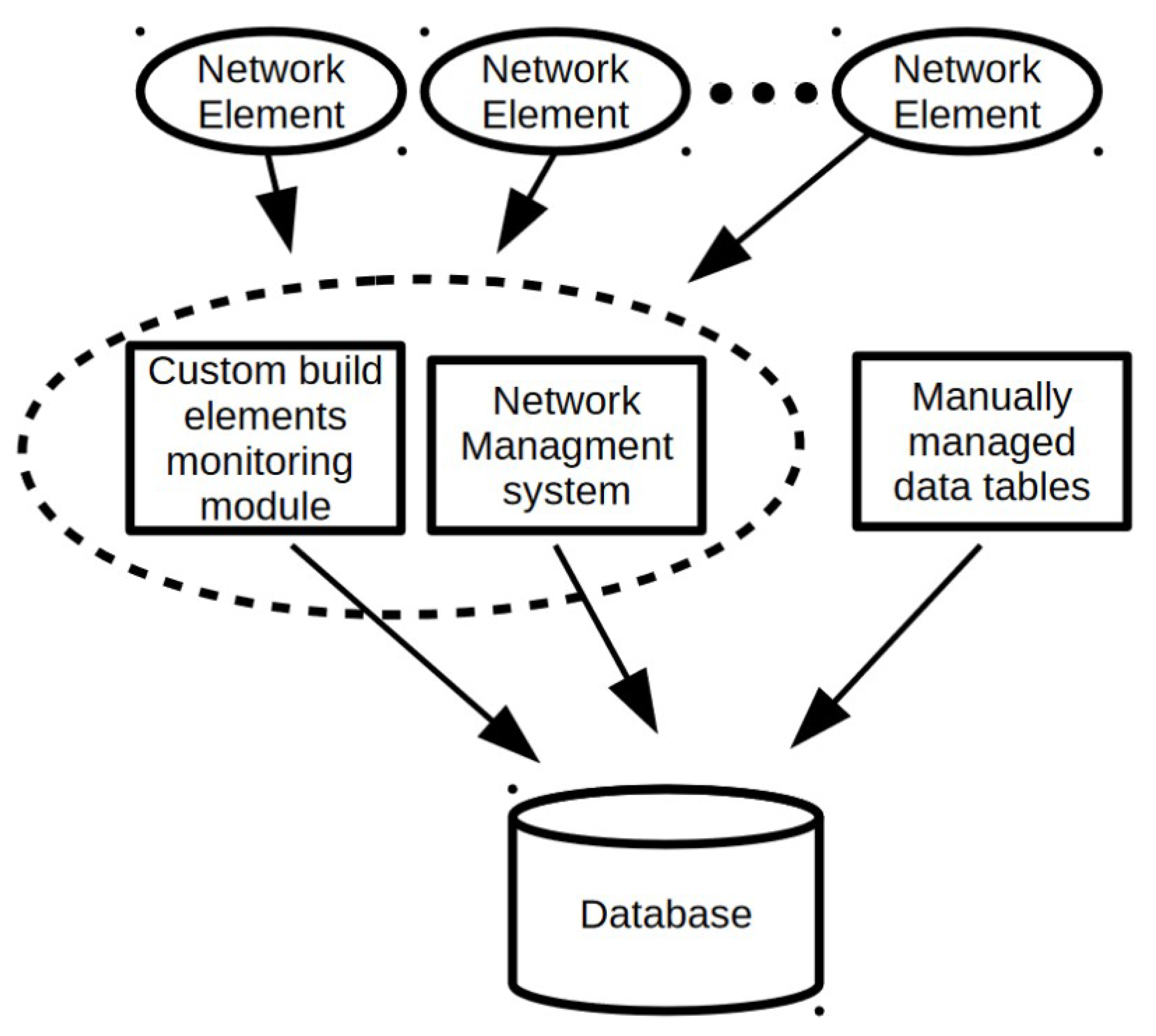
2.1. Data
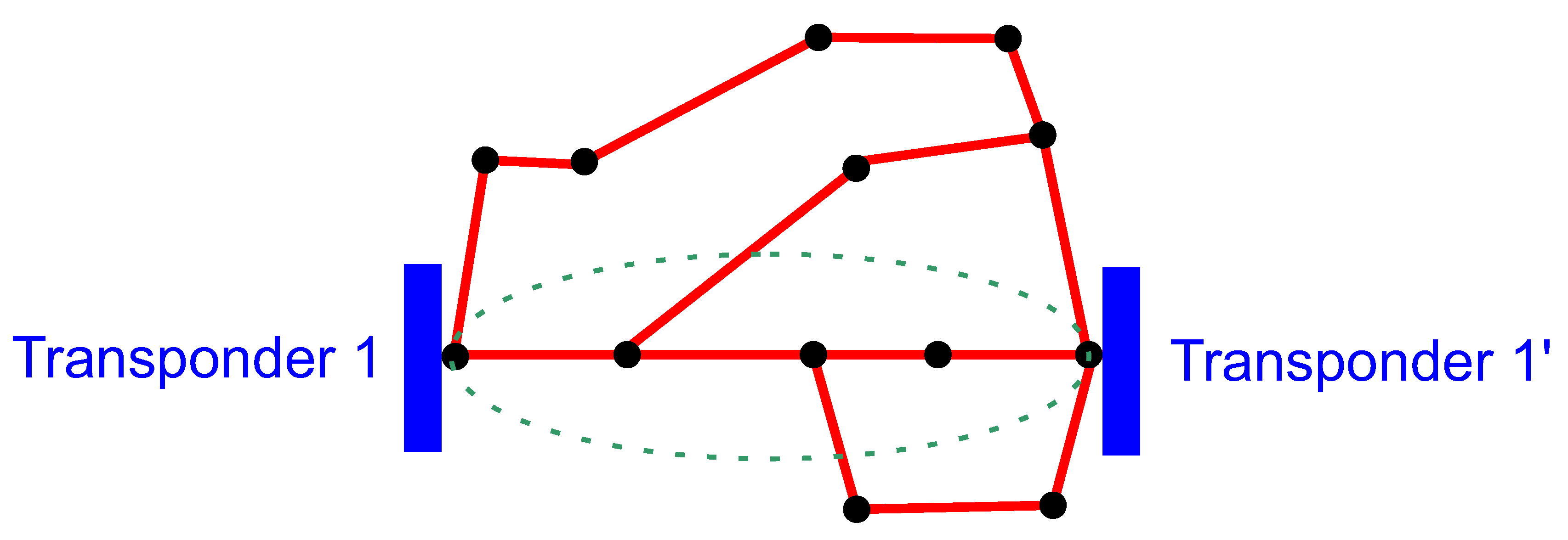
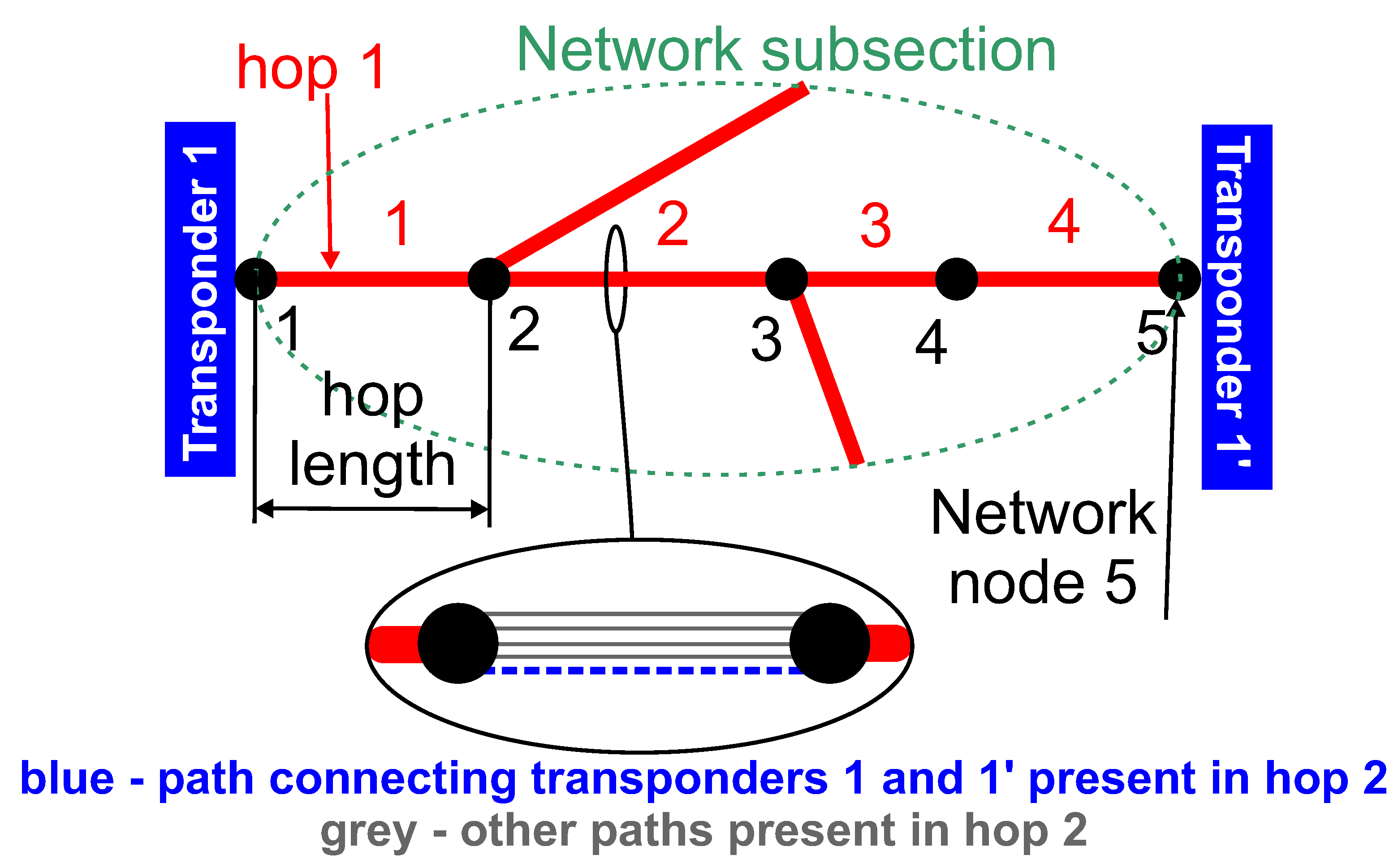
2.1.1. Path Description
2.1.2. Vector Representation
2.2. Binary Classification
2.2.1. Random Forest
- large maximally fitted trees are grown (with splitting continued until reaching a uniform class, exhausting the set of instances, or exhausting the set of possible splits),
- whenever a split has to be selected for a tree node, a small subset of available attributes is selected randomly and only those attributes are considered for candidate splits.
2.2.2. Extreme Gradient Boosting
2.2.3. Handling Class Imbalance
- internal compensation by the learning algorithm, controlled by its parameter settings,
- compensation by data resampling,
- compensation by synthetic minority class data generation.
2.3. One-Class Classification
- the training contains only instances of a single class,
- the learned model is supposed to predict for any instance whether it belongs to the single class represented in the training set.
2.3.1. One-Class SVM
2.3.2. One-Class Naive Bayes Classifier
2.3.3. Isolation Forest
2.3.4. Maximum Entropy Modeling
2.4. Model Evaluation
3. Results
3.1. Algorithm Implementations and Setup
- random forest (RF): the implementation provided by the ranger R package [49],
- extreme gradient boosting (XGB): The implementation provided by the xgboost R package [50],
- SMOTE: The implementation provided by the smotefamily R package [51],
- ROSE: The implementation provided by the ROSE R package [52],
- one-class SVM (OCSVM): The implementation provided by the e1071 R package [53],
- one-class naive Bayes classifier (OCNB): The implementation provided by the e1071 R package [53], with a custom prediction method to handle the one-class classification mode specifically implemented for this work,
- isolation forest (IF): The implementation provided by the isotree R package [54],
- maximum entropy modeling (ME): The implementation provided by the MIAmaxent R package [55], with background data generation by random sampling of attribute value ranges specifically implemented for this work.
- random forest: A forest of 500 trees is grown, with the number of attributes drawn at random for split selection set to the square root of the number of all available attributes,
- extreme gradient boosting: 50 boosting iterations are performed, growing trees with a maximum depth of 6 and scaling the contribution of each tree by a learning rate factor of , and applying regularization on leaf values with a regularization coefficient of 1,
- SMOTE: The number of nearest neighbors of minority class instances is set to 1 (which is the only available choice given the fact there are just three minority class instances in the data two of which are available for model creation in each cross-validation fold),
- ROSE: The generated dataset size and the probability of the minority class are set so as to approximately preserve the number of majority class instances and increase the number of minority class instances,
- one-class SVM: The radial kernel function is used, with the kernel parameter set to the reciprocal of the input dimensionality, and the parameter specifying an upper bound on the share of training instances that may be considered outlying is equal ,
- isolation forest: The extended version of the algorithm is used [40], with multivariate splits based on three attributes, a forest of 500 isolation trees is grown, and for each of them the data sample size is equal the training set size (which is a reasonable setup for a small dataset), and the maximum three depth is the ceiling of the base-2 logarithm thereof,
- maximum entropy modeling: All available attribute transformations [42] are applied to derive environmental features (linear, monotone, deviation, forward hinge, reverse hinge, threshold, and binary one-hot encoding), a significance threshold used for internal feature selection is set to , and the generated background data size is 1000.
3.2. Classification Performance
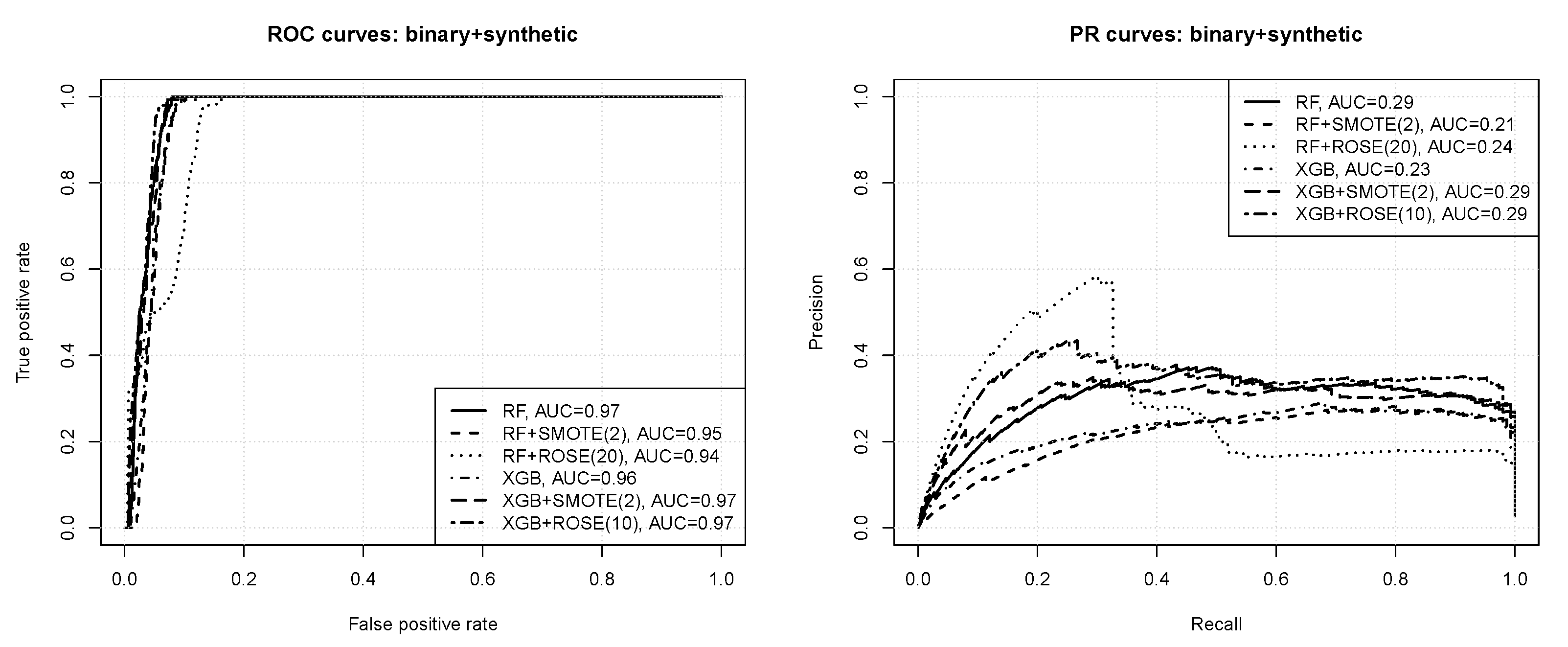
3.2.1. Binary Classification
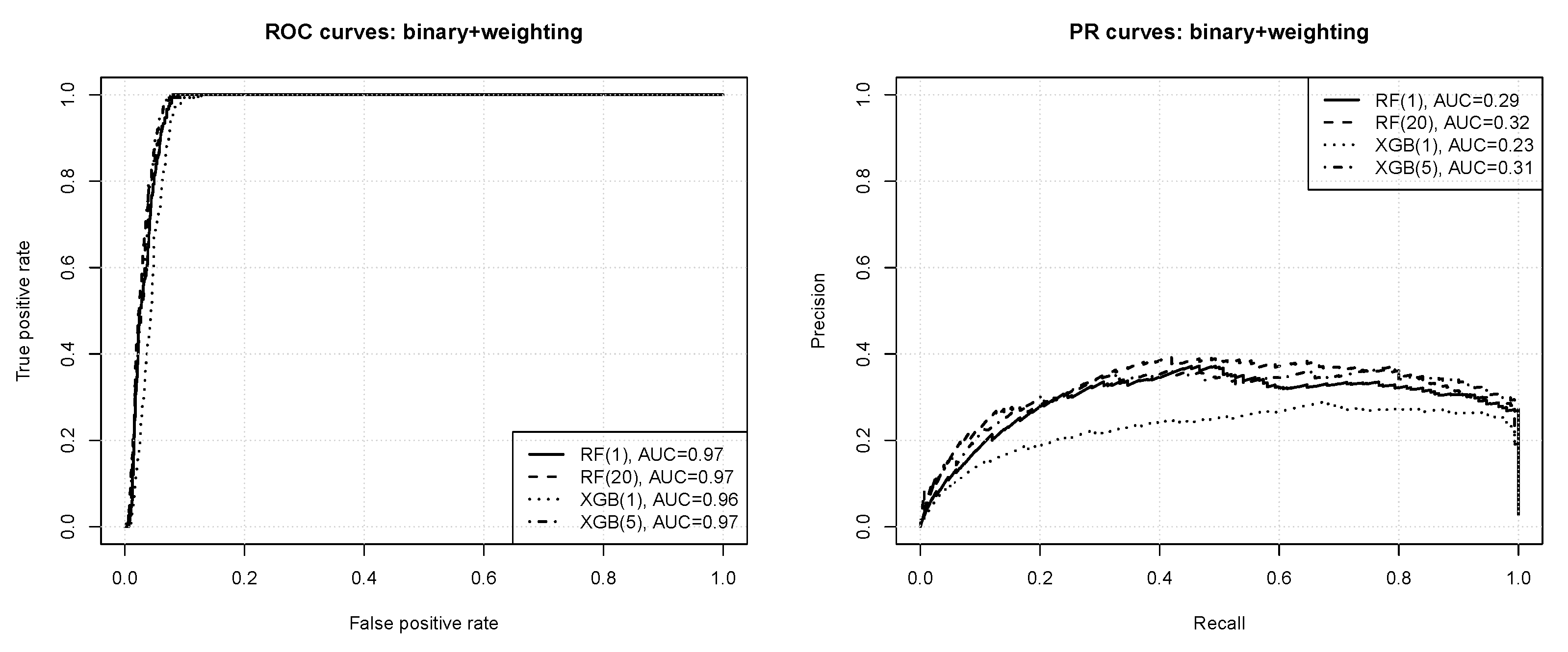
- according to the ROC curves the prediction quality appears very good, with AUC values of ,
- nearly perfect ROC operating points are possible, with the true positive rate of 1 and the false positive rate of or less,
- the precision-recall curves reveal that the prediction quality is not actually perfect, with the average precision just above at best,
- without instance weighting the random forest algorithm outperforms xgboost, but with instance weighting they both perform on roughly the same level,
- imbalance compensation with instance weighting improves the predictive performance of both the algorithms, with the effect more pronounced for extreme gradient boosting.
- synthetic instance generation reduces the prediction quality of the random forest algorithm, but provides an improvement for extreme gradient boosting,
- the effects of SMOTE and ROSE for xgboost are similar except for the fact that the latter works better with bigger minority class multiplication coefficients,
- the results for both SMOTE and ROSE are worse than those obtained with instance weighting.
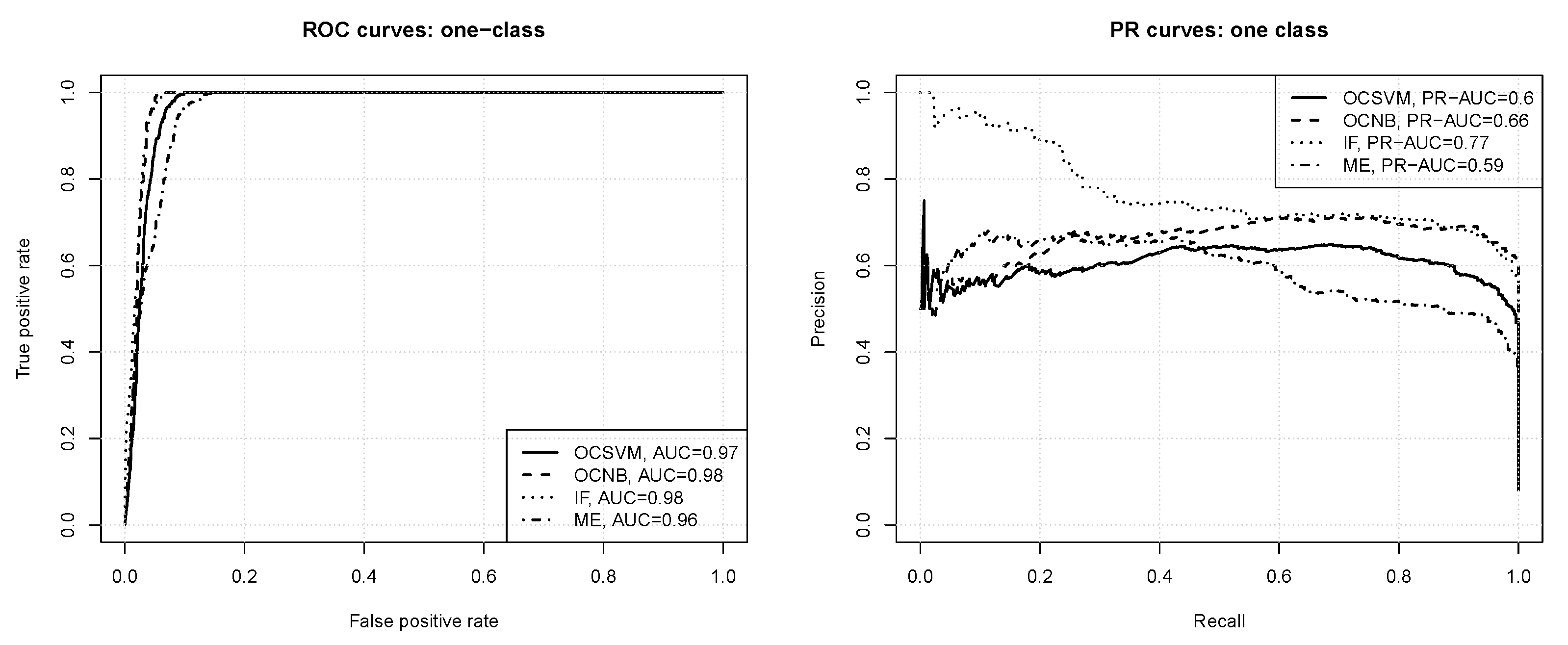
3.2.2. One-Class Classification
- all the algorithms produce models capable of successfully detecting out-of-class instances (“bad” paths), with AUC values between and ,
- the one-class naive Bayes and isolation forest algorithms achieve the maximum true positive rate value for a slightly less false positive rate value than the one-class SVM and maxent algorithms,
- the algorithms differ more substantially with respect to the average precision achieved, which is about for one-class SVM and maxent, for the one-class naive Bayes classifier, and for the isolation forest algorithm,
- the isolation forest and one-class naive Bayes models maintain a high precision of or above for a wide range of recall values (up to about ), whereas the one-class SVM and maxent models can only maintain a precision level of and , respectively, in the same range of recall values,
- all the one-class algorithms produce better models than those obtained by binary classification.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kozdrowski, S.; Żotkiewicz, M.; Sujecki, S. Ultra-Wideband WDM Optical Network Optimization. Photonics 2020, 7, 16. [Google Scholar] [CrossRef] [Green Version]
- Klinkowski, M.; Żotkiewicz, M.; Walkowiak, K.; Pióro, M.; Ruiz, M.; Velasco, L. Solving large instances of the RSA problem in flexgrid elastic optical networks. IEEE/OSA J. Opt. Commun. Netw. 2016, 8, 320–330. [Google Scholar] [CrossRef] [Green Version]
- Ruiz, M.; Pióro, M.; Żotkiewicz, M.; Klinkowski, M.; Velasco, L. Column generation algorithm for RSA problems in flexgrid optical networks. Photonic Netw. Commun. 2013, 26, 53–64. [Google Scholar] [CrossRef]
- Dallaglio, M.; Giorgetti, A.; Sambo, N.; Velasco, L.; Castoldi, P. Routing, Spectrum, and Transponder Assignment in Elastic Optical Networks. J. Lightw. Technol. 2015, 33, 4648–4658. [Google Scholar] [CrossRef]
- Kozdrowski, S.; Żotkiewicz, M.; Sujecki, S. Resource optimization in fully flexible optical node architectures. In Proceedings of the 20th International Conference on Transparent Optical Networks (ICTON), Bucharest, Romania, 1–5 July 2018. [Google Scholar]
- Panayiotou, T.; Manousakis, K.; Chatzis, S.P.; Ellinas, G. A Data-Driven Bandwidth Allocation Framework With QoS Considerations for EONs. J. Lightw. Technol. 2019, 37, 1853–1864. [Google Scholar] [CrossRef]
- Morais, R.M.; Pedro, J. Machine learning models for estimating quality of transmission in DWDM networks. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, D84–D99. [Google Scholar] [CrossRef]
- Kozdrowski, S.; Żotkiewicz, M.; Sujecki, S. Optimization of Optical Networks Based on CDC-ROADM Tech. Appl. Sci. 2019, 9, 399. [Google Scholar] [CrossRef] [Green Version]
- Mestres, A.; Rodríguez-Natal, A.; Carner, J.; Barlet-Ros, P.; Alarcón, E.; Solé, M.; Muntés, V.; Meyer, D.; Barkai, S.; Hibbett, M.J.; et al. Knowledge-Defined Networking. arXiv 2016, arXiv:1606.06222. [Google Scholar] [CrossRef] [Green Version]
- Musumeci, F.; Rottondi, C.; Nag, A.; Macaluso, I.; Zibar, D.; Ruffini, M.; Tornatore, M. An Overview on Application of Machine Learning Techniques in Optical Networks. IEEE Commun. Surv. Tutor. 2019, 21, 1383–1408. [Google Scholar] [CrossRef] [Green Version]
- Żotkiewicz, M.; Szałyga, W.; Domaszewicz, J.; Bąk, A.; Kopertowski, Z.; Kozdrowski, S. Artificial Intelligence Control Logic in Next-Generation Programmable Networks. Appl. Sci. 2021, 11, 9163. [Google Scholar] [CrossRef]
- Rottondi, C.; Barletta, L.; Giusti, A.; Tornatore, M. Machine-learning method for quality of transmission prediction of unestablished lightpaths. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, A286–A297. [Google Scholar] [CrossRef] [Green Version]
- Diaz-Montiel, A.A.; Aladin, S.; Tremblay, C.; Ruffini, M. Active Wavelength Load as a Feature for QoT Estimation Based on Support Vector Machine. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Kozdrowski, S.; Cichosz, P.; Paziewski, P.; Sujecki, S. Machine Learning Algorithms for Prediction of the Quality of Transmission in Optical Networks. Entropy 2021, 23, 7. [Google Scholar] [CrossRef] [PubMed]
- Cichosz, P.; Kozdrowski, S.; Sujecki, S. Application of ML Algorithms for Prediction of the QoT in Optical Networks with Imbalanced and Incomplete Data. In Proceedings of the 2021 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 23–25 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Panayiotou, T.; Savva, G.; Tomkos, I.; Ellinas, G. Decentralizing machine-learning-based QoT estimation for sliceable optical networks. J. Opt. Commun. Netw. 2020, 12, 146–162. [Google Scholar] [CrossRef] [Green Version]
- Mata, J.; de Miguel, I.; Durán, R.J.; Aguado, J.C.; Merayo, N.; Ruiz, L.; Fernández, P.; Lorenzo, R.M.; Abril, E.J. A SVM approach for lightpath QoT estimation in optical transport networks. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4795–4797. [Google Scholar]
- Barletta, L.; Giusti, A.; Rottondi, C.; Tornatore, M. QoT estimation for unestablished lighpaths using machine learning. In Proceedings of the 2017 Optical Fiber Communications Conference and Exhibition (OFC), Los Angeles, CA, USA, 19–23 March 2017; pp. 1–3. [Google Scholar]
- Japkowicz, N. Learning from Imbalanced Data Sets: A Comparison of Various Strategies. In Proceedings of the AAAI Workshop on Learning from Imbalanced Data Sets, Austin, TX, USA, 31 July 2000; AAAI Press: Menlo Park, CA, USA, 2000. [Google Scholar]
- Lee, H.; Cho, S. The Novelty Detection Approach for Different Degrees of Class Imbalance. In Proceedings of the Thirteenth International Conference on Neural Information Processing Systems, Hong Kong, China, 3–6 October 2006; Springer: Berlin, Germany, 2006. [Google Scholar]
- Bellinger, C.; Sharma, S.; Zaïane, O.R.; Japkowicz, N. Sampling a Longer Life: Binary versus One-Class Classification Revisited. Proc. Mach. Learn. Res. 2017, 74, 64–78. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman and Hall/CRC: Boca Raton, FL, USA, 1984. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the First International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; Springer: Berlin, Germany, 2000. [Google Scholar]
- Schapire, R.E. The Strength of Weak Learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and Algorithms; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the Twenty-Second ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM Press: New York, NY, USA, 2016. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W. Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Menardi, G.; Torelli, N. Training and Assessing Classification Rules with Imbalanced Data. Data Min. Knowl. Discov. 2014, 28, 92–122. [Google Scholar] [CrossRef]
- Moya, M.; Hush, D. Network Constraints and Multi-Objective Optimization for One-Class Classification. Neural Netw. 1996, 9, 463–474. [Google Scholar] [CrossRef]
- Khan, S.S.; Madden, M.G. One-Class Classification: Taxonomy of Study and Review of Techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Datta, P. Characteristic Concept Representations. Ph.D. Thesis, University of California, Irvine, CA, USA, 1997. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-Based Anomaly Detection. Acm Trans. Knowl. Discov. Data 2012, 6, 3. [Google Scholar] [CrossRef]
- Hariri, S.; Kind, M.C.; Brunner, R.J. Extended Isolation Forest. arXiv 2018, arXiv:1811.02141. [Google Scholar] [CrossRef] [Green Version]
- Phillips, S.J.; Anderson, R.P.; Schapire, R.E. Maximum Entropy Modeling of Species Geographic Distributions. Ecol. Nodelling 2006, 190, 231–259. [Google Scholar] [CrossRef] [Green Version]
- Halvorsen, R.; Mazzoni, S.; Bryn, A.; Bakkestuen, V. Opportunities for Improved Distribution Modelling Practice via a strict maximum likelihood interpretation of MaxEnt. Ecography 2015, 38, 172–183. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Li, W.; Guo, O. A Maximum Entropy Approach to One-Class Classification of Remote Sensing Imagery. Int. J. Remote Sens. 2010, 31, 2227–2235. [Google Scholar] [CrossRef]
- Liu, X.; Liu, H.; Gong, H.; Lin, Z.; Lv, S. Appling the One-Class Classification Method of Maxent to Detect an Invasive Plant Spartina alterniflora with Time-Series Analysis. Remote Sens. 2017, 9, 1120. [Google Scholar] [CrossRef] [Green Version]
- Egan, J.P. Signal Detection Theory and ROC Analysis; Academic Press: Cambridge, MA, USA, 1975. [Google Scholar]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A Survey of Cross-Validation Procedures for Model Selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. xgboost: Extreme Gradient Boosting, R Package Version 1.1.1.1; 2020. Available online: https://CRAN.R-project.org/package=xgboost (accessed on 5 January 2021).
- Siriseriwan, W. smotefamily: A Collection of Oversampling Techniques for Class Imbalance Problem Based on SMOTE, R Package Version 1.3.1; 2019. Available online: https://CRAN.R-project.org/package=smotefamily (accessed on 5 January 2021).
- Lunardon, N.; Menardi, G.; Torelli, N. ROSE: A Package for Binary Imbalanced Learning. R J. 2014, 6, 82–92. [Google Scholar] [CrossRef] [Green Version]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien, R Package Version 1.7-4; 2020. Available online: https://CRAN.R-project.org/package=e1071 (accessed on 5 January 2021).
- Cortes, D. isotree: Isolation-Based Outlier Detection, R Package Version 0.1.20; 2020. Available online: https://CRAN.R-project.org/package=isotree (accessed on 5 January 2021).
- Vollering, J.; Halvorsen, R.; Mazzoni, S. The MIAmaxent R package: Variable Transformation and Model Selection for Species Distribution Models. Ecol. Evol. 2019, 9, 12051–12068. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cichosz, P.; Kozdrowski, S.; Sujecki, S. Learning to Classify DWDM Optical Channels from Tiny and Imbalanced Data. Entropy 2021, 23, 1504. https://doi.org/10.3390/e23111504
Cichosz P, Kozdrowski S, Sujecki S. Learning to Classify DWDM Optical Channels from Tiny and Imbalanced Data. Entropy. 2021; 23(11):1504. https://doi.org/10.3390/e23111504
Chicago/Turabian StyleCichosz, Paweł, Stanisław Kozdrowski, and Sławomir Sujecki. 2021. "Learning to Classify DWDM Optical Channels from Tiny and Imbalanced Data" Entropy 23, no. 11: 1504. https://doi.org/10.3390/e23111504
APA StyleCichosz, P., Kozdrowski, S., & Sujecki, S. (2021). Learning to Classify DWDM Optical Channels from Tiny and Imbalanced Data. Entropy, 23(11), 1504. https://doi.org/10.3390/e23111504