Abstract
Regression analysis using line equations has been broadly applied in studying the evolutionary relationship between the response trait and its covariates. However, the characteristics among closely related species in nature present abundant diversities where the nonlinear relationship between traits have been frequently observed. By treating the evolution of quantitative traits along a phylogenetic tree as a set of continuous stochastic variables, statistical models for describing the dynamics of the optimum of the response trait and its covariates are built herein. Analytical representations for the response trait variables, as well as their optima among a group of related species, are derived. Due to the models’ lack of tractable likelihood, a procedure that implements the Approximate Bayesian Computation (ABC) technique is applied for statistical inference. Simulation results show that the new models perform well where the posterior means of the parameters are close to the true parameters. Empirical analysis supports the new models when analyzing the trait relationship among kangaroo species.
1. Introduction
Species evolve across generations. For quantitative-trait evolution, scientists apply phylogenetic comparative methods (PCMs) to study the evolutionary relationship of a group of related species where a phylogenetic tree is incorporated for describing affinity among species [1,2,3,4,5,6,7,8]. Most current regression models in PCMs assume that the response trait variable y is linear with its covariates xs where the estimated line equation (e.g., ) is used to predict the response trait [8,9,10]. However, the allometric relationship between body mass and other organisms is also often observed in nonlinear form (i.e., ). Logarithm transformation () is usually considered as a regular procedure prior to analysis [11]. From a statistical perspective, log transformation on the data reduces skewness, decreasing the variability, conforming data close to the normal distribution, and placing dependent variable and covariates in a linear-like relationship [12,13,14]. From an evolutionary perspective, because most traits of particular species fall within a certain range, interpreting trait changes using raw scales may produce unreasonable results. Hence, convex transformation by the logarithm function is often applied to convert the raw data of the interval type into the ratio type. This has particular advantages, for example, a change in body mass of kg might not be important for a male red kangaroo with a weight from 55 to 90 kg, but probably matters substantially for a wallaby with a weight of about kg; a % change in body mass for both species is interpretable under log-transformed data.
Nevertheless, even the log transformation helps to convert the trait relationship from nonlinear into a moderate linear type, and there exists a nonlinear relationship among some log-transformed data [15]. The trait relationship shown in Figure 1 provides two examples in which nonlinear exponential regressions could provide a better fit with less predicted errors than those obtained when using linear regression. The left panel in Figure 1 displays the bivariate relationship between the body mass (x) and the maintenance nitrogen requirement (y) in the log scale of the marsupial species [16,17]. The exponential equation has a root mean square deviation with a value of , while the linear regression model has a root mean square deviation .
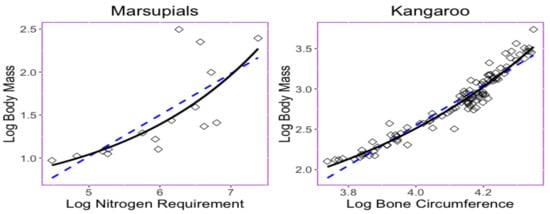
Figure 1.
Scatter plots and the relationship of the bivariate trait dataset described by the least squares regression lines or curves. (left) Relationship between maintenance nitrogen requirement and body mass in marsupials [16,17]. Exponential curve (RMSD ) and line equation (RMSD ) shown. (right) Relationship between bone circumference and the body mass in kangaroos [18]. Exponential curve (RMSD ) and line (RMSD ) shown.
The right panel in Figure 1 displays relationship between the thigh-bone (femoral) circumference (x) and body mass (y) of the kangaroo species [18] is shown Figure 1. The exponential equation has a root mean square deviation with a value of , while the linear regression model has a root mean square deviation of . Parameters in the exponential curve were estimated under a least-squares method performed using the following step. Since adds to the complexity of the model, an estimate of is established by using the half value of the minimum of the responses; then, traits are subtracted from this value, which yields the model . Parameters and are estimated through the least-squares method for the model .
In the marsupial and kangaroo datasets, exponential regression models yield to smaller RMSD than those in linear regression models. Conceiving that the potential use of exponential regression models to study phylogenetic-traits relationships, the empirical datasets in Figure 1 call for novel phylogenetic comparative methods. In this framework, we developed models for adaptive trait evolution where the optimum of the trait undergoes stabilizing selection and has an exponential relationship with the predictor trait. Our work is distinguished from the work in [19], which mainly makes use of multiple linear regression. Our ultimate goal was to provide feasible models for scientists to analyze their valuable data for research.
Prior to developing new models, the background of phylogenetic adaptive trait evolution was introduced follows. Hansen et al. [20] developed a popular model (OUBM model) for phylogenetic adaptive trait evolution where the response trait variable is assumed following an Ornstein–Uhlenbeck (OU) process dynamic where the optimum of the response trait is assumed with a linear relationship with Brownian motion (BM) covariates. Later, various scientists made further efforts to expand the OUBM model of Hansen et al. via considering an Ornstein–Uhlenbeck process covariates (OUOU model) [21,22], a Cox–Ingersoll–Ross process for rate evolution [19], or extending the OUBM model to the multivariate case [23,24,25].
In general, the generalized model for phylogenetic adaptive trait evolution assumes that trait variable solves stochastic differential equation (SDE) in Equation (1):
where parameter is the force that pulled the trait back to its optimum , parameter is called the evolutionary rate for the trait variable , and is a Wiener process with independent Gaussian increment, with mean 0 and variance t. Let and be constants. By multiplying the integrating factor and then integrating on both sides of Equation (1), can be expressed explicitly, as shown in Equation (2)
where is a deterministic term with initial condition at , and term is a stochastic integral with respect to , and is, again, a Gaussian variable with mean 0 and variance (obtained by applying Itô isometry [26]) and
is an integral with respect to time.
Optimal , has a functional relationship with the covariate represented in Equation (4)
where is the vector of regression parameters.
In Equation (4), when optimum and covariate trait variable are in a linear relationship (i.e., where are identical independently distributed continuous stochastic random variables), the dynamics of can be characterized through identifying the dynamics of the linear combination of identical independent distributed covariates . For Gaussian process covariates s, optimal follows a Brownian motion if covariates s follows Brownian motion (i.e., ), called the OUBM model [20]. On the other hand, is an OU process if s are OU processes (i.e., ), called the OUOU model [21].
In this work, we assumed that an exponential relationship existed between trait optimum and its covariate . The development of the new models is described as follows. When assuming an exponential relationship between the optimum and a Brownian motion covariate , the optimum follows a well known geometric Brownian motion [27]. By assuming an exponential relationship between optimum and its Ornstein–Uhlenbeck process-type covariate , the optimum follows a geometric Ornstein–Uhlenbeck process [28].
We assumed that the covariate trait variable evolved under Gaussian processes (e.g., Brownian motion or Ornstein–Uhlenbeck process); hence, the analytic expression of Ⓐ in Equation (3) depends on the expression between and its covariate . Both evolutionary rate () and force in Equation (1) are assumed to be positive constants throughout this work (i.e., ). Hence, we focused on developing of models by implementing the curved relationship between optimum and its covariate . The new model is named OUGBM (see Section 2.1.1) when trait represented in Equation (2) admits a generalized OU process dynamic, and its optimum has an exponential relationship with Brownian motion covariates . The new model is named OUGOU (see Section 2.1.2) if admits a generalized OU process, and has an exponential relationship with OU process covariates . We also implemented the OUBM (see Section 2.2.1) and OUOU (see Section 2.2.2) models for comparison with the new models. Since species are evolutionarily related, the models were developed with the assumption that evolutionary dependency among a group of species is along a given root phylogenetic tree (see Section 2.3). Due to those new models’ lack of model likelihood, we propose the use of the approximate Bayesian computation procedure for model inference (see Section 2.4).
2. Materials and Methods
2.1. Optimal Exponential Regression
Consider an exponential relationship between the optimum and its covariate as follows
The relationship in Equation (5) is commonly applied in growth/decay studies with representing the value of maximal growth (if ) or minimal decay (if ). By using Equation (5), two models (OUGBM and OUGOU) were developed, as reported in Section 2.1.1 and Section 2.1.2, respectively.
2.1.1. OUGBM Model
Let be a Brownian motion random variable that solves the SDE (i.e., and in the SDE . Suppose the optimum of the response trait has an exponential relationship with , as shown in Equation (5). The first step is to express in terms of model parameters in . By taking a derivative in Equation (5) with respect to t, one has . Let with partial derivative and . By applying Itô’s lemma [26] , one has
which is known as the SDE for a geometric Brownian motion random variable with constant of percentage drift parameter and a constant of percentage volatility parameter . The analytical solution is
Plugging into Equation (5) and then simplifying the equation yields to an explicit representation for the optimum as follows.
To draw a sample for trait considering the expression of in Equation (2), it suffices to recognize the dynamics of Ⓐ in Equation (3), where . This can be performed by replacing with in Equation (6), which yields to
where is a definite integral with respect to time, and the integrand is a geometric Brownian motion variable [29,30,31].
Currently there is no analytical expression for . The authors in [31,32] extensively studied the problem and provided a numerical solution through the Laplace transform. In particular, when t approaches to ∞, and the reciprocal of has a limit distribution of gamma type with shape parameter and scale parameter for at (see Prop. 4.4.4 in [30]). In our modeling framework, since t represented evolutionary time and was of finite value (i.e., after scaling tree in the models), samples of were drawn from the definite integral of a geometric Brownian motion variable with respect to time on time domain using Simpson’s rule [33]. Hence, given , samples of trait variables and were accordingly drawn with the aid of R package pracma [34] to compute the stochastic integral.
2.1.2. OUGOU Model
Let be the Ornstein–Uhlenbeck process variable that solves the SDE.
Given the exponential relationship between and as , by taking differentials with respect to t on both sides yields to . Let , again by Itô’s lemma and use Equation (7), one has
which implies that is a geometric Ornstein–Uhlenbeck process [28]. can be expressed as
Hence, can be expressed as
To draw a sample for trait , considering the expression of in Equation (2), it suffices to recognize the dynamics of Ⓐ in Equation (3) where By using Equation (8) for , one has
where
is a definite integral of geometric OU process with respect to time. Currently, there is no analytical expression for , so we used R package pracma [34] to draw samples of where the definite integral was computed over a finite grid by Simpson’s rule. On each grid sample of were generated by a normal variable with mean 0 and variance .
Section 2.1.1 and Section 2.1.2 provide the fundamental framework for phylogenetic exponential optimal regression for adaptive trait evolution. Once Ⓐ
in Equation (3) was fully recognized, samples of trait variable could be drawn accordingly by using the expressed in Equation (2). Trajectories for optimal response and the covariate for the OUGBM and OUGOU models are shown in Figure 2.
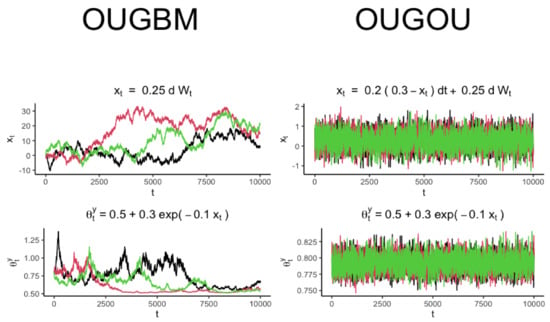
Figure 2.
Trajectory simulation for the OUGBM and the OUGOU models. Each plot contains three realizations generated from the corresponding model. Trajectories of optimum were generated by evaluating the exponential relationship from the realization of covariate .
2.2. Optimal Linear Regression
Optimal of response trait and its covariate has a linear relationship, as follows:
Two optimal linear regression models, OUBM [20] using a BM covariate, and OUOU [21] using an OU process covariate were developed in the literature. We included both models in this study for comparison with the optimal exponential regression model.
2.2.1. OUBM Model
When the dynamic of optimum was assumed with a linear relationship with the BM covariate , then
2.2.2. OUOU Model
Let where is a random OU process variable. By replacing in terms of to Equation (9), one has
2.3. Optimal Adaptive-Trait Evolution along Phylogenetic Tree
A phylogenetic tree provides evidence of the summary of evolutionary history of living species [35]. For a mutation occurring in an individual identified on a lineage of the tree where the mutation changed the phenotype of the organism such as kangaroos, that mutation may change the moving style from bipedal walking to bipedal hopping. Such a mutation may need many generations to be achieved. However, the trait may be difficult to predict when a lineage is fixed for a derived trait; descendants would inherit the trait until a subsequent evolution change occurs. For a clade that contains marsupials such as kangaroos, wallabies, koalas, and possums, their differences are the results of changes after their common ancestor begins to diversify. Here, a phylogenetic tree provides information to organize this biological diversity where internal nodes depict a common ancestry and contain the formation of the degree of relatedness that is relative to the entire evolutionary history. As adopting tree thinking that living species share a common ancestor is broadly accepted in evolutionary biology, the tree provides evidence in how to conceptualize the broad sweep of biological diversity.
For trait evolution, a group of currently observed species has beautifully expressed affinity by the evolutionary tree. From the mathematical side, changes in trait value among a group of species along a phylogenetic tree can be realized by the relevant stochastic process. One realization of using a BM predictor in the OUBM and OUGBM models, and one realization of trajectories for the OU process-based predictor in the OUOU and OUGOU models using a 3-species phylogenetic tree are shown in Figure 3. Box plots of 100 simulated optimal-trait and response trait samples under the tree in Figure 3 using the tree traversal algorithm can be accessed in Figure S1 in the online Supplemental Material, displaying the spread of traits across models.
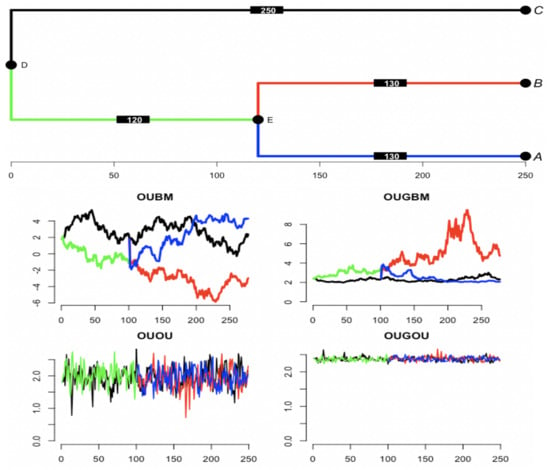
Figure 3.
Simulation of optimal trajectories along the tree using Gaussian process covariates. (top) Tree of 3 taxa is simulated from coalescent process using R package’s ape function rcoal [36]. Original tree has branch of length 250 from root node D to tip C, 120 from node D to node E, and 130 from E to B and from E to A. Edge length is increased by multiplying a constant, and trajectories are simulated at each unit under relevant processes. Trajectories of predictor assume Brownian motion with rate first simulated along the tree with at root . For the covariate under an Ornstein–Uhlenbeck process dynamics with parameters , optimum , and rate . Trait is first simulated along the tree with starting point at the root . Optimum as a function of is computed under each model using the regression parameters . For linear model , and for exponential model .
2.4. Approximate Bayesian Computation
Due to the exponential relationship between and its covariate , the stochastic variable shown in Equation (2) includes a definite integral of stochastic variable with respect to time t. The distribution for the definite integral of the geometric OU process with respect to time is currently not known. Hence, the OUGOU model lack of closed-form likelihood as stochastic variable in Equation (3) embedded in is intractable. Approximate Bayesian computation (ABC) was used for statistical inference herein. The ABC procedure is a likelihood free based method used for model inference. To start an ABC algorithm, data are first simulated from the model using parameters drawn from prior distributions. Then, a set of the summary statistics for samples and raw data are calculated. For the ABC rejection method, a distance function and a threshold are used to determine posterior samples by comparing summary statistics of observed data and simulated data [37].
To determine posterior samples, we adopted the 12 summary statistics from [19], and used the mean, median, standard deviation, skewness, kurtosis, and the phylogenetic tree based statistics: the contrast mean, the contrast standard deviation, the contrast skewness, the contrast kurtosis [1], and two phylogenetics-related statistics: (i) the Bloomberg’s statistic (measures the relatedness of species in a clade when compared to randomly selected species from the same tree ) [38] and (ii) the Pagel’s statistic (measures the strength of trait heritability from the ancestor) [39]. For where is the mean square root of the observed tip data measured from phylogenetic correct mean and MSE is the mean squared error of the observed data calculated using the variance covariance matrix derived from the candidate tree. For trait vector following a Brownian motion model (i.e., ), one has
where is the phylogenetic corrected mean, and is the transformed vector obtained from the generalized least-square procedure. Matrix satisfies equation , where is the variance covariance matrix and is the identity matrix. Relatively small occurs when there is little covariance within the tip data that is explained by the candidate tree, and it leads to a smaller value of the ratio of (weaker phylogenetic signal). Conversely, while if the candidate tree precisely demonstrate the variance-covariance pattern observed in the data, then there is a small MSE, which results in large value of (stronger phylogenetic signal) [38]. Pagel’s statistic parameter is calculated by optimizing the likelihood function of the model, assuming that observed trait vector follows multivariate normal distribution where is vector of 1s, and is an identity matrix, is phylogentic affinity matrix transformed from the given phylogenetic tree [40]. Since both the MLE for mean and variance can be written as a function of ,
can be estimated by optimizing the likelihood function over its domain . Those statistics resulted in a great interest in evolutionary-biology research [19,41,42]. Euclidean distance measure corresponds to those statistics S, where and are computed from observed and simulated-trait data, respectively. The procedure for parameter estimation under the ABC rejection method is shown in Algorithm 1.
| Algorithm 1: Approximate Bayesian computation for the models of adaptive trait evolution. |
|
2.5. Interpretation of Change of Optimum by Its Covariate
As traits are logarithm-transformed prior to analysis, the change in response traits is measured on a ratio scale under two types of regression methods: (i) optimal linear regression or (ii) optimal exponential regression. Below, we briefly describe the change in optimum by its covariate.
(i) In optimal linear regression: First, given and , the two equations in log scale are written as and . The difference between the two equations is which implies that . Hence, depends on values of , and . Let , and , then , which means that a 10% increase in the covariate x results in 4.88% increase in the optimum of response .
(ii) In optimal exponential regression: First, given and , the two equations in log scale are written as and . The difference between the two equations is , which implies that . Hence, depends on covariate . Let and , then . Set , then . So, a 10% increase in covariate x would result in a 5.13% increase in optimal response .
3. Results
3.1. Simulation
3.1.1. Parameter Estimation
To validate the new models, their performance was assessed through extensive simulations. Prior parameter distributions were assumed to be independent. Some appropriate priors were selected because of the models’ lack of tractable likelihood without a conjugate prior. A balanced tree of 16, 32, 64 and 128 with a height of 1, and Grafen branch length simulated by R: ape was used for the simulation. To obtain reliable estimates, 2000 (=500 × 4) posterior samples were obtained from four runs, in each run, 50,000 samples were generated, and a tolerance rate () was used to obtain 500 posterior samples. Two sets of true parameters and priors were used for simulation. For the first set, all priors used uniform distribution. For the second set, priors were set to a specific distribution by intuitive beliefs about the true values of the parameters [43,44]. For the nonuniform prior, was assumed to be normal, as it was reasonable to assumed that the optimum remained at the peaks. An example of using the normal prior comes from a study of coral polyp evolution [19], where a suitable prior for the adaptive optimum of polyp thickness used the normal distribution of polyp thickness across all corals. The exponential prior was used for force parameters and , and the inverse gamma was used for the rate parameters and . The setup of hyperparameters for priors is listed in Table 1.

Table 1.
Simulation setup for true parameter values and prior distributions. , uniform distribution; , exponential distribution; inverse gamma distribution; and , normal distribution. In inverse gamma distribution, sh = shape and sc = scale.
Root state was set to a trivial value of 0 for all models. For each taxon size, one trait was simulated under each model from the simulation.
The results for uniform priors from this simulation of model parameters are shown in Table 2. The results for the second set using informative priors from this simulation of model parameters are shown in Tables S2 and S3 in the online Supplemental Material.
Table 2.
Simulation results of validating models through model parameter estimation using uniform prior. Four different taxon sizes of 16, 32, 64, and 128 were used for the four models (OUGBM, OUGOU, OUBM and OUOU). Means and 95% credible intervals using 2000 posterior samples from 4 individual runs on each model are reported for each model parameter on each column.
Overall, parameters could be estimated reasonably well with acceptable accuracy. The posterior mean of each parameter was close to the true parameter value under uniform priors. Results for the uniform priors from this simulation of regression parameters are shown in Table 3. On each taxon, most models showed reasonable mean estimates for (true 0), (true 1), (true ). Results guaranteed that Algorithm 1 provided a reliable procedure for estimating parameters.
Table 3.
Simulation results of validating models through regression parameter estimation using uniform prior. Four different taxon sizes of 16, 32, 64, and 128 were used for four models (OUGBM, OUGOU, OUBM and OUOU). Means and 95% credible intervals using 2000 posterior samples from 4 individual runs on each model were reported for each regression parameter on each column.
3.1.2. Cross-Validation
Cross-validation is used to investigate how many taxa are needed and whether the correct model can be chosen from a candidate set. Leave-one-out cross-validation was performed under ABC using the R: abc package [37]. The balanced trees of taxon sizes 64, 128, 256, and 512 taxa were simulated using R: ape package, while 10,000 birth–death trees of taxon sizes 50, 100, 200, and 500 with birth rate 2, death rate 0.5, the time since origin 2, and probability of 0.5 for each tip were included in the final tree and simulated using the R: TreeSim package [45]. One trait datum was simulated along a given tree using parameters with values set up in Table 1 using uniform distribution. To assess if ABC could distinguish between the models, the 12 summary statistics were calculated in each model. For each model, the size of the cross-validation samples was set to 100.
Results of the confusion matrix are reported with birth-death tree cases by bar plots in Figure 4. In the lower right panel (taxon size 500) in Figure 4, the bar plots in the OUGOU categories shows that for ABC model choice will identify the OUOU model 1 time, the OUGOU model 93 times, the OUGBM model 1 time, the OUBM model 5 times, which yielded to the misclassification proportion for the OUGOU model of (1 − 93/100) × 100% = 7%; in the upper left panel (taxon size 50), the rightmost bar plots in the OUOU categories shows that the ABC model identified the OUOU model (purple) 90 times, the OUGOU model (blue) 4 times, the OUGBM model (orange) 1 time and the OUBM model (pink) 3 times among the 100 samples, which yielded to the misclassification proportion for the OUOU model of (1 − 90/100) × 100% = 10%.
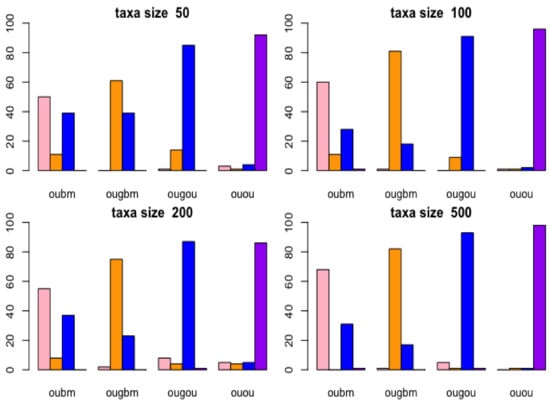
Figure 4.
Cross-validation of models using birth-death tree. Bar plots show results of confusion matrices from cross-validation analysis under Approximate Bayesian Computatin (ABC) multinomial logistic-regression method for models of adaptive trait evolution. Four taxon sizes of 50, 100, 200, and 500 of birth-death trees were considered. The actual model is shown in the horizontal label for each bar plot on each panel, and the frequency of correctly identifying the models is represented by the height of the bar plots.
From this analysis, models are distinguishable at each taxon size. When taxa increase, ABC can more frequently identify the correct models. There are other factors, such as the choices of parameters and number of models in the candidates set, which may impact the power of correctly identifying the correct models. Here, we used constant factors. Results of the confusion matrix for each model reported with the balanced tree cases were similar to those of the case with the birth-death tree cases, and can be accessed in Figure S2 in the online Supplemental Material.
3.2. Empirical Analysis
Kangaroos are bipedal, and using their femoral midshaft circumference is especially suitable for predicting body mass. We used the trait datasets in [18] and applied our models by treating femoral bone circumference as the covariate to explore its impact on the optimum of body mass. The phylogeny of kangaroos is shown in Figure 5 and trait values corresponding to the species can be accessed in Table S3 in the Supplemental Material. Prior to log transformation, data were scaled by the feature-scaling method [46], while the curved relationship remains unchanged under this scaling. Our ABC algorithm worked properly for the dataset where traits were simulated within a reasonable range.
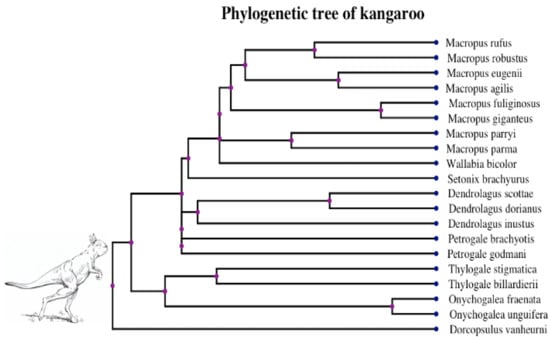
Figure 5.
Phylogenetic tree of 20 giant kangaroo species in [18]. Image at the root of the tree is a reconstruction of Sthenurus stirlingi [47], an extinct giant kangaroo in walking pose.
Posterior means for the parameters of each model is shown in Table 4.
Table 4.
Posterior means of parameters for kangaroo dataset.
For the kangaroo dataset, all models reported relatively small estimates of force parameters and , which indicated that relative weak force was detected to pull the trait back to its optimum during evolution. For rate parameter, , the OU*OU models reported a smaller value than that of OU*BM models, while for the response trait in all model was between 0.5 and 0.8. For optimum parameter for the covariate trait, , both exponential model (OUGOU) and linear model reported negative values. For regression parameters, linear models (OUBM and OUOU) reported a positive regression slope which was consistent with [18], where positive correlation among traits was reported. Regression parameters reported relatively closed values across the same class of models. Overall, our results predicted that bone circumference has a positive effect on the optimum body mass, which is consistent with the result in [18] when using phylogenetic independent contrast as the response trait.
We used Bayes factors(BF) to compare the models. The posterior probability of a model given data is given by Bayes’ theorem: We adopted the method in [19] and computed the BF, defined as the ratio of the posterior model probabilities of two different models and , parameterized by model parameter vectors and . This is performed by using function postpr in the R package abc [37], where posterior model probabilities are estimated using the rejection method.
The model comparison under the Bayes factor is shown in Table 5. For the kangaroo data in [18], the best model was the OUGBM model, followed by the OUGOU, OUBM, and OUOU models. Their pairwise Bayes factors are shown in Table 5. The best model (Rank = 1st) was the OUGBM model. This dataset provides relative equal support for all the exponential OUG** models, a result which was slightly higher than the linear OU** models with the Bayes factor 1.5000 for OUGBM model over OUBM, and 2.1132 for OUGBM over OUOU model. This indicates that the evolution of the optimum was also more appropriately described by the geometric BM process predictor than that described by a linear predictor.
Table 5.
Bayes factor table for kangaroo dataset. Posterior probability for each model is shown in the first row; and models shown in second row. Bayes factor for model vs. model shown in ith row and jth column. Acceptance rate was set to 1% () for the kangaroo dataset.
Regression curves are shown in Figure 6. Overall, the exponential models (EXP, OUGBM, and OUGOU) returned smaller RMSD values than those of the linear models (LS, OUBM, and OUOU) suggesting the utility of the new models. To interpret the impact on the optimal by its covariate x, we again used the two transformation methods described in Section 2.5 and the posterior mean of parameters in Table 4.
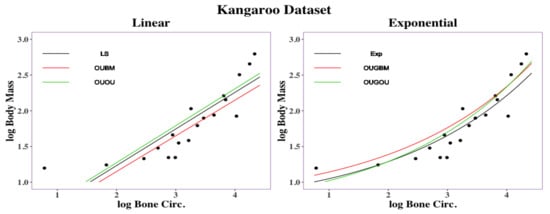
Figure 6.
Regression curves for kangaroo traits: femoral bone circumference vs. body mass. Linear regression had an RMSD under the LS method, RMSD under the OUBM model, and RMSD under the OUOU model. Exponential regression had an RMSD under the exponential method, RMSD under the OUGBM model, and RMSD under the OUGOU model.
For a 1% decrement of the covariate bone circumference across kangaroos, it was expected that there would be a 0.13% decrement of the body mass under the EXP model, 0.13% decrement under the OUGBM model, 0.14% decrement under the OUGOU model, 0.51% decrement under the LS model, 0.50% decrement under the OUBM model and 0.52% decrement under the OUOU model. For a 5% increment of the covariate bone circumference across the kangaroos, it was expected that there would be a 0.62% increment of the body mass under the EXP model, 0.63% increment under the OUGBM model, 0.69% decrement under the OUGOU model, 2.53% increment under the LS model, 2.47% decrement under the OUBM model, and 2.56% increment under the OUOU model. Overall, the exponential models predicted smaller optimum changes of the optima than the linear models did for this dataset. A list of optimum changes corresponding to the covariate under those models can be seen in Table S4 in online Supplemental Material.
4. Discussion
Two phylogenetic optimal exponential regression models, OUGBM and OUGOU, for adaptive trait evolution under stabilizing selection were developed. Simulations showed that the new models were validated where posterior means of parameters were close to their true parameter values. The utility of the new regression models in phylogenetic comparative analysis is accessed by analyzing the kangaroo dataset, and results showed that the new models could be appropriately used and are more competitive than the linear models.
Parameter estimation for regression parameters in the ABC procedure depends on several factors. While appropriate priors are required for simulating samples, the choice of the hyperparameters is also important. In this study, uniform distribution with bounds of regression estimates ±5 times their standard deviations was used. As results showed the fit of the model, the choice of the parameters for ABC inference provides a reasonable range to cover the true parameters.
The OU process is applied to model stabilizing selection, but is currently criticised for simply being a trait-tracking movement process [48]. Our models assumed that the optimum was tracked by its covariates in a nonlinear functional manner. While our approach provides options for analyzing trait data from the aspect of adaptive trait evolution, it remains to be seen whether models can accurately estimate the adaptive optima from the stabilizing selection, as described in the literature [48]. Undoubtedly, it would be very interesting to investigate this open question for all OU process-based PCMs [8].
Phylogenetic comparative methods are very useful statistical methods to answer evolutionary questions. Those methods, which were developed on the basis of the property of stochastic process remains, require more improvement so that they are able to face the challenges of an intrinsic evolutionary process, which merely a simple Brownian motion model or an OU process model can solve [40,49]. Our models provide feasible options to users in the community to account for nonlinearity in the relationship between the trait optima undergoing stabilizing selection and predictor traits. The models and procedures included in this study were implemented into the R package ouxy [50].
Supplementary Materials
The following are available at https://www.mdpi.com/1099-4300/23/2/218/s1, Figure S1: Box plots of simulated trait values, Figure S2: Cross-validation of models using balanced tree, Table S1: Simulation results of validating models through model parameter estimation using informative priors, Table S2: Simulation results of validating models through regression parameter estimation using informative priors, Table S3: Body mass and bone circumference for Kangaroo species, Table S4: Percentage change of the optimal trait impacted by its covariate.
Author Contributions
The authors’ individual contributions are provided as the following: Conceptualization, D.-C.J.; methodology, C.-P.W. and D.-C.J.; software, D.-C.J.; validation, D.-C.J.; formal analysis, C.-P.W. and DCJ; investigation, C.-P.W. and D.-C.J.; resources, D.-C.J.; data curation, C.-P.W. and D.-C.J.; writing—original draft preparation, D.-C.J.; writing—review and editing, D.-C.J.; visualization, C.-P.W. and D.-C.J.; supervision, D.-C.J.; project administration, D.-C.J.; funding acquisition, D.-C.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Ministry of Science and Technology, Taiwan (grant no. MOST-109- 2118-M-035-003), and was assisted by attendance as a Short-Term Visitor at the National Institute for Mathematical and Biological Synthesis, an Institute supported by the National Science Foundation through NSF Award # DBI-1300426, with additional support from The University of Tennessee, Knoxville.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors thank the editors and two anonymous reviewers for their constructive suggestions for improving the early version of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Felsenstein, J. Phylogenies and the comparative method. Am. Nat. 1985, 125, 1–15. [Google Scholar] [CrossRef]
- Lynch, M. Methods for the analysis of comparative data in evolutionary biology. Evolution 1991, 45, 1065–1080. [Google Scholar] [CrossRef]
- Harvey, P.H.; Pagel, M.D. The Comparative Method in Evolutionary Biology; Oxford University Press: Oxford, UK, 1991; Volume 239. [Google Scholar]
- Felsenstein, J. Inferring Phylogenies; Sinauer Associates: Sunderland, MA, USA, 2004; Volume 2. [Google Scholar]
- O’Meara, B.C. Evolutionary inferences from phylogenies: A review of methods. Annu. Rev. Ecol. Evol. Syst. 2012, 43, 267–285. [Google Scholar] [CrossRef]
- Hernández, C.E.; Rodríguez-Serrano, E.; Avaria-Llautureo, J.; Inostroza-Michael, O.; Morales-Pallero, B.; Boric-Bargetto, D.; Canales-Aguirre, C.B.; Marquet, P.A.; Meade, A. Using phylogenetic information and the comparative method to evaluate hypotheses in macroecology. Methods Ecol. Evol. 2013, 4, 401–415. [Google Scholar] [CrossRef]
- Pennell, M.W.; Harmon, L.J. An integrative view of phylogenetic comparative methods: Connections to population genetics, community ecology, and paleobiology. Ann. N. Y. Acad. Sci. 2013, 1289, 90–105. [Google Scholar] [CrossRef]
- Garamszegi, L.Z. Modern Phylogenetic Comparative Methods and Their Application in Evolutionary Biology. Concepts and Practice; Springer: London, UK, 2014. [Google Scholar]
- Grafen, A. The phylogenetic regression. Philos. Trans. R. Soc. Lond. B Biol. Sci. 1989, 326, 119–157. [Google Scholar] [PubMed]
- Freckleton, R.P.; Harvey, P.H.; Pagel, M. Phylogenetic analysis and comparative data: A test and review of evidence. Am. Nat. 2002, 160, 712–726. [Google Scholar] [CrossRef]
- Xiao, X.; White, E.; Hooten, M.; Durham, S. On the use of log-transform vs. nonlinear regression for analyzing biological power laws. Ecology 2011, 92, 1887–1894. [Google Scholar] [CrossRef] [PubMed]
- Harmon, L. Phylogenetic Comparative Methods: Learning from Trees; CreateSpace Independent Publishing Platform: Charleston, SC, USA, 2018. [Google Scholar]
- Ives, A.R.; Garland, T., Jr. Phylogenetic logistic regression for binary dependent variables. Syst. Biol. 2009, 59, 9–26. [Google Scholar] [CrossRef] [PubMed]
- Maddison, W.P.; Midford, P.E.; Otto, S.P. Estimating a binary character’s effect on speciation and extinction. Syst. Biol. 2007, 56, 701–710. [Google Scholar] [CrossRef] [PubMed]
- Packard, G.C. On the use of log-transformation versus nonlinear regression for analyzing biological power laws. Biol. J. Linn. Soc. 2014, 113, 1167–1178. [Google Scholar] [CrossRef]
- Klaassen, M.; Nolet, B.A. Stoichiometry of endothermy: Shifting the quest from nitrogen to carbon. Ecol. Lett. 2008, 11, 785–792. [Google Scholar] [CrossRef]
- Hume, I.D. Marsupial Nutrition; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Helgen, K.M.; Wells, R.T.; Kear, B.P.; Gerdtz, W.R.; Flannery, T.F. Ecological and evolutionary significance of sizes of giant extinct kangaroos. Aust. J. Zool. 2006, 54, 293–303. [Google Scholar] [CrossRef]
- Jhwueng, D.C. Modeling rate of adaptive trait evolution using Cox–Ingersoll–Ross process: An Approximate Bayesian Computation approach. Comput. Stat. Data Anal. 2020, 145, 106924. [Google Scholar] [CrossRef]
- Hansen, T.F.; Pienaar, J.; Orzack, S.H. A comparative method for studying adaptation to a randomly evolving environment. Evolution 2008, 62, 1965–1977. [Google Scholar] [CrossRef] [PubMed]
- Jhwueng, D.C.; Maroulas, V. Phylogenetic ornstein–uhlenbeck regression curves. Stat. Probab. Lett. 2014, 89, 110–117. [Google Scholar] [CrossRef][Green Version]
- Jhwueng, D.C.; Maroulas, V. Adaptive trait evolution in random environment. J. Appl. Stat. 2016, 43, 2310–2324. [Google Scholar] [CrossRef]
- Bartoszek, K.; Pienaar, J.; Mostad, P.; Andersson, S.; Hansen, T.F. A phylogenetic comparative method for studying multivariate adaptation. J. Theor. Biol. 2012, 314, 204–215. [Google Scholar] [CrossRef]
- Cressler, C.E.; Butler, M.A.; King, A.A. Detecting adaptive evolution in phylogenetic comparative analysis using the Ornstein–Uhlenbeck model. Syst. Biol. 2015, 64, 953–968. [Google Scholar] [CrossRef]
- Marass, F.; Mouliere, F.; Yuan, K.; Rosenfeld, N.; Markowetz, F. A phylogenetic latent feature model for clonal deconvolution. Ann. Appl. Stat. 2016, 10, 2377–2404. [Google Scholar] [CrossRef]
- Oksendal, B. Stochastic Differential Equations: An Introduction with Applications; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Ksendal, B. Stochastic differential equations. In Stochastic Differential Equations; Springer: Berlin, Germany, 2003; pp. 65–84. [Google Scholar]
- Vega, C.A.M. Calibration of the exponential Ornstein–Uhlenbeck process when spot prices are visible through the maximum log-likelihood method. Example with gold prices. Adv. Differ. Equations 2018, 2018, 269. [Google Scholar] [CrossRef]
- Lyasoff, A. Another look at the integral of exponential Brownian motion and the pricing of Asian options. Financ. Stochastics 2016, 20, 1061–1096. [Google Scholar] [CrossRef]
- Dufresne, D. The distribution of a perpetuity, with applications to risk theory and pension funding. Scand. Actuar. J. 1990, 1990, 39–79. [Google Scholar] [CrossRef]
- Dufresne, D. The integral of geometric Brownian motion. Adv. Appl. Probab. 2001, 33, 223–241. [Google Scholar] [CrossRef]
- Yor, M. On some exponential functionals of Brownian motion. Adv. Appl. Probab. 1992, 24, 509–531. [Google Scholar] [CrossRef]
- Burden, R.L.; Faires, J.D. Numerical Analysis, 9th ed.; Brooks Cole Publishing: Monterey, CA, USA, 2010. [Google Scholar]
- Borchers, H.W. Pracma: Practical Numerical Math Functions. R Package Version 2.2.9. 2019. Available online: https://CRAN.R-project.org/package=pracma (accessed on 12 September 2020).
- Baum, D. Trait evolution on a phylogenetic tree: Relatedness. Nat. Educ. 2008, 1, 191. [Google Scholar]
- Paradis, E.; Schliep, K. ape 5.0: An environment for modern phylogenetics and evolutionary analyses in R. Bioinformatics 2019, 35, 526–528. [Google Scholar] [CrossRef] [PubMed]
- Csillery, K.; Francois, O.; Blum, M.G.B. abc: An R package for approximate Bayesian computation (ABC). Methods Ecol. Evol. 2012. [Google Scholar] [CrossRef]
- Blomberg, S.P.; Garland, T., Jr.; Ives, A.R. Testing for phylogenetic signal in comparative data: Behavioral traits are more labile. Evolution 2003, 57, 717–745. [Google Scholar] [CrossRef] [PubMed]
- Pagel, M. Inferring thetheirtorical patterns of biological evolution. Nature 1999, 401, 877–884. [Google Scholar] [CrossRef]
- Adams, D.C.; Felice, R.N. Assessing trait covariation and morphological integration on phylogenies using evolutionary covariance matrices. PLoS ONE 2014, 9, e94335. [Google Scholar] [CrossRef]
- Bartoszek, K.; Liò, P. Modelling trait dependent speciation with Approximate Bayesian Computation. arXiv 2018, arXiv:1812.03715. [Google Scholar] [CrossRef]
- Lepers, C.; Billiard, S.; Porte, M.; Méléard, S.; Tran, V.C. Inference with selection, varying population size and evolving population structure: Application of ABC to a forward-backward coalescent process with interactions. arXiv 2019, arXiv:1910.10201. [Google Scholar] [CrossRef] [PubMed]
- Uyeda, J.C.; Harmon, L.J. A novel Bayesian method for inferring and interpreting the dynamics of adaptive landscapes from phylogenetic comparative data. Syst. Biol. 2014, 63, 902–918. [Google Scholar] [CrossRef]
- Bastide, P.; Ho, L.S.T.; Baele, G.; Lemey, P.; Suchard, M.A. Efficient Bayesian Inference of General Gaussian Models on Large Phylogenetic Trees. arXiv 2020, arXiv:2003.10336. [Google Scholar]
- Stadler, T. TreeSim: Simulating Phylogenetic Trees. R package version 2.4. 2019. Available online: https://CRAN.R-project.org/package=TreeSim (accessed on 28 August 2020).
- Bo, L.; Wang, L.; Jiao, L. Feature scaling for kernel fisher discriminant analysis using leave-one-out cross validation. Neural Comput. 2006, 18, 961–978. [Google Scholar] [CrossRef] [PubMed]
- Janis, C.M.; Buttrill, K.; Figueirido, B. Locomotion in extinct giant kangaroos: Were sthenurines hop-less monsters? PLoS ONE 2014, 9, e109888. [Google Scholar] [CrossRef] [PubMed]
- Cooper, N.; Thomas, G.H.; Venditti, C.; Meade, A.; Freckleton, R.P. A cautionary note on the use of Ornstein Uhlenbeck models in macroevolutionary studies. Biol. J. Linn. Soc. 2016, 118, 64–77. [Google Scholar] [CrossRef] [PubMed]
- Cornwell, W.; Nakagawa, S. Phylogenetic comparative methods. Curr. Biol. 2017, 27, R333–R336. [Google Scholar] [CrossRef] [PubMed]
- Jhwueng, D.C. Building an adaptive trait simulator package to infer parametric diffusion model along phylogenetic tree. MethodsX 2020, 7, 100978. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).