2.1. Model
We provide details and mathematical description of the joint model below. Let
and
denote the MEG and EEG, respectively, at time
t,
; where
and
denote the number of MEG and EEG sensors, the model assumes:
where
and
denote
and
forward operators, respectively computed based on Maxwell’s equations under the quasi-static assumption [
33] for EEG and MEG;
and
are known
and
matrices, respectively, which can be obtained from baseline data providing information on the covariance structure of EEG and MEG sensor noise; and
represents the magnitude and polarity of neural currents sources over a fine grid covering the cortical surface. In this case,
P represents a large number of point sources of potential neural activity within the brain covering the cortical surface. It is assumed that the
P cortical locations are embedded in a 3D regular grid composed of
voxels to allow efficient computational implementation. Given this grid of voxels, a mapping
is defined such that
is the index of the voxel containing the
th cortical location. We assume a latent Gaussian mixture with allocations at the level of voxels:
; where
is a labeling process defined over the grid of voxels such that for each
,
with
and
;
, where
denotes the mean of the “active” states over different components of activity and
, so that the first component corresponds to an “inactive” state. The variability of the
mixture component about its mean
is represented by
.
The labeling process assigns each voxel to a latent state and is assumed to follow a Potts model:
where
is the normalizing constant for this probability mass function,
is a hyper-parameter that governs the strength of spatial cohesion, and
indicates that voxels
i and
j are neighbors, with a first-order neighborhood structure over the 3D regular grid. The mean temporal dynamics for active components is assumed to follow a first-order vector autoregressive process:
,
, with
fixed and known, but
unknown and assigned an inverse-Gamma (
) hyper-prior. Although in [
13] a pseudo-likelihood approximation is adopted to the normalizing constant of the Potts model and then assigned a uniform prior to the spatial parameter to control the degree of spatial correlation, we fixed the inverse temperature parameter and vary it as part of a sensitivity analysis.
For model selection, the number of mixture components, the value of
K, in Equation (
1) will not be known prior and so it is estimated simultaneously with model parameters. Thus this approach achieves simultaneous point estimation and model selection. We can obtain a simple estimate for the number of mixture components based on the estimated allocation variables
when the algorithm is run with a sufficiently large value of
K. This is achieved by running the algorithm with a value of
K that is larger than the expected number of mixture components. For example, the value of
K can be set as
when running the algorithm. The
location on the cortex is allocated to one of the mixture components based on the estimated value of
, where
and
if location
j is allocated to component
. When the algorithm is run with a value of
K that is large, there will result empty mixture components that have not been assigned any voxel locations under
. In a sense these empty components have been automatically pruned out as redundant. The estimated number of mixture components can be obtained by counting the number of non-empty mixture components as follows:
This estimator requires us to run our algorithm only once for a single value of K and then the resulting number of mixture components assigned a location in is determined and
2.2. Ant Colony System
Ant Colony System (ACS) is a population-based optimization algorithm introduced in [
14]. The basic structure of this algorithm is designed to solve the traveling salesman problem in which the aim is to find the shortest path to cover a given set of cities without revisiting any one of them. The inspiring source and development of this algorithm is the observation of the foraging behavior of real ants in their colony. This behavior is exploited in artificial ant colonies for the search of approximate solutions to discrete optimization problems, for continuous optimization problems, and for important problems in telecommunications, such as routing and load balancing, telecommunication network design, or problems in bioinformatics [
34,
35]. At the core of this algorithm is the communication between the ants by means of chemical pheromone trails, which enables them to collectively find short paths between their nest and food source. The framework of this algorithm can be categorized into four main parts: (1) construction of an agent ant solution, (2) local pheromone update of the solution, (3) improving solution by local search, and (4) global pheromone update of the best solution.
At each step of this constructive algorithm a decision is made concerning which solution component to add to the sequence of solution components already built. These decisions are dependent on the pheromone information, which represents the learned experience of adding a particular solution component given the current state of the solution under construction. The accumulated amount of pheromone mirrors the quality of the solution constructed based on the value of the objective function. The pheromone update aims to concentrate the search in regions of the search space containing high quality solutions while there is a stochastic component facilitating random exploration of the search space. In particular, the reinforcement of solution components depending on the solution quality is an important ingredient of ACS algorithms. To learn which components contribute to good solutions can help assembling them into better solutions. In general, the ACS approach attempts to solve an optimization problem by iterating the following two steps: (1) candidate solutions are constructed using a pheromone model, that is, a parameterized probability distribution over the solution space; (2) the candidate solutions are used to modify the pheromone values in a way that is deemed to bias future sampling toward high quality solutions.
The posterior distribution of the dynamic model takes the form
=
, where:
where
denotes the density of the
-dimensional multivariate normal distribution with mean
and covariance
evaluated at
;
denotes the density of the inverse gamma distribution with parameters
a and
b evaluated at
x;
denotes the density of the normal distribution with mean
and variance
evaluated at
x;
is the joint probability mass function of the Potts model with parameter
evaluated at
. Equation (
2) represents the objective function to be maximized over
. The goal is to optimize over
maximizing the posterior (
2).
ACS is based on set of agents, each representing artificial ants that construct solutions as sequences of solution components. Agent ant
k builds a solution by allocating label
ℓ from a set of voxel labels
to the voxel
based on a probabilistic transition rule
. The transition rule quantifies the probability of ant
k, assigning voxel
s to label
ℓ. This transition rule depends on the pheromone information
of the coupling
representing the quality of assigning voxel
s to label
ℓ based on experience gathered by ants in the previous iteration. We let:
where
ℓ is a label for voxel
s selected according to the transition rule above;
;
is a tuning parameter. An artificial ant chooses, with probability
, the solution component that maximizes the pheromone function
or it performs, with probability
, a probabilistic construction step according to (
3). The ACS pheromone system consists of two update rules; one rule is applied whilst constructing solutions (local pheromone update rule) and the other rule is applied after all ants have finished constructing a solution (global pheromone update rule). After assigning a label to a voxel, an ant modifies the amount of pheromone of the chosen couples
by applying a local pheromone update (
4):
where
is a tuning parameter that controls evaporation of the pheromone and
is the initial pheromone value. This operation simulates the natural process of pheromone evaporation preventing the algorithm from converging too quickly (all ants constructing the same solution) and getting trapped into a poor solution. In practice, the effect of this local pheromone update is to decrease the pheromone values via evaporation
on the visited solution components, making these components less desirable for the subsequents ants. The value of the evaporation rate indicates the relative importance of the pheromone values from one iteration to the following one. If
takes a value near 1, then the pheromone trail will not have a lasting effect, and this mechanism increases the random exploration of the search space within each iteration and helps avoid a too rapid convergence of the algorithm toward a sub-optimal region of the parameter space, whereas a small value will increase the importance of the pheromone, favoring the exploitation of the search space near the current solution.
To improve all solutions constructed and also update the other model parameters, we considered incorporating ICM as a local search method. Here, the ICM algorithm is used for both updating the model parameters and also for a local search over the mixture allocation variables. Thus, the update steps corresponding to ACS are combined with running ICM to convergence at each iteration. Finally, after all solutions have been constructed by combined ACS and ICM steps, the quality of all solutions is evaluated using the objective function where the corresponding best solution is selected. We use a global update rule, where pheromone evaporation is again applied on the best solution chosen. Assuming voxel
j is assigned to label
v for the best solution, the global update is given as:
The steps described are performed repeatedly until a change in the objective function becomes negligible and the model parameters from the best solution are returned as the final parameter estimates. The optimal values for the tuning parameters
used in our ACS-ICM algorithm depend on the data. The strategy we adopt for choosing the tuning parameters is by using an outer level optimization on top of the ACS-ICM algorithm to optimize over tuning parameters
within updates at the outer level based on the Nelder–Mead algorithm [
36] applied to optimize over tuning parameters.
In order to reduce the dimension of parameter space and computing time, we apply clustering to the estimated neural sources. This is achieved by implementing a K-means algorithm to cluster the
P locations on the cortex into a smaller number of
clusters, assuming that
for cortical locations
belonging to the same cluster. We investigated different values of
in our simulation studies. Within the ICM algorithm, the labeling process
is updated using an efficient chequerboard updating scheme [
13]. The update scheme starts with partitioning
into two blocks
based on a three-dimensional chequerboard arrangement, where
corresponds to “white” voxels and
corresponds to “black” voxels. Under the Markov random field prior with a first-order neighborhood structure, the elements of
are conditionally independent given
, the remaining parameters, and the data
,
. This allows us to update
in a single step, which involves simultaneously updating its elements from their full conditional distributions. The variables
are updated in the same way.
It is well-known that the ICM algorithm is sensitive to initial values and the authors of [
13] found this to be the case with the ICM algorithm developed for the spatiotemporal mixture model. The solution obtained, and even the convergence of the algorithm depend rather heavily on the starting values chosen. In the case of ACS-ICM, regardless of the initial values, the algorithm finds a better solution with the optimal tuning parameters and this solution tends to be quite stable. This is because ACS-ICM is a stochastic search procedure in which the pheromone update concentrates the search in regions of the search space containing high quality solutions to reach an optimum. When considering a stochastic optimization algorithm, there are at least two possible types of convergence that can be considered: convergence in value and convergence in solution. With convergence in value, we are interested in evaluating the probability that the algorithm will generate an optimal solution at least once. On the contrary, with convergence in solution we are interested in evaluating the probability that the algorithm reaches a state that keeps generating the same optimal solution. The convergence proofs are presented in [
37,
38]. The authors of [
37] proved convergence with a probability of
for the optimal solution and more in general for any optimal solution in [
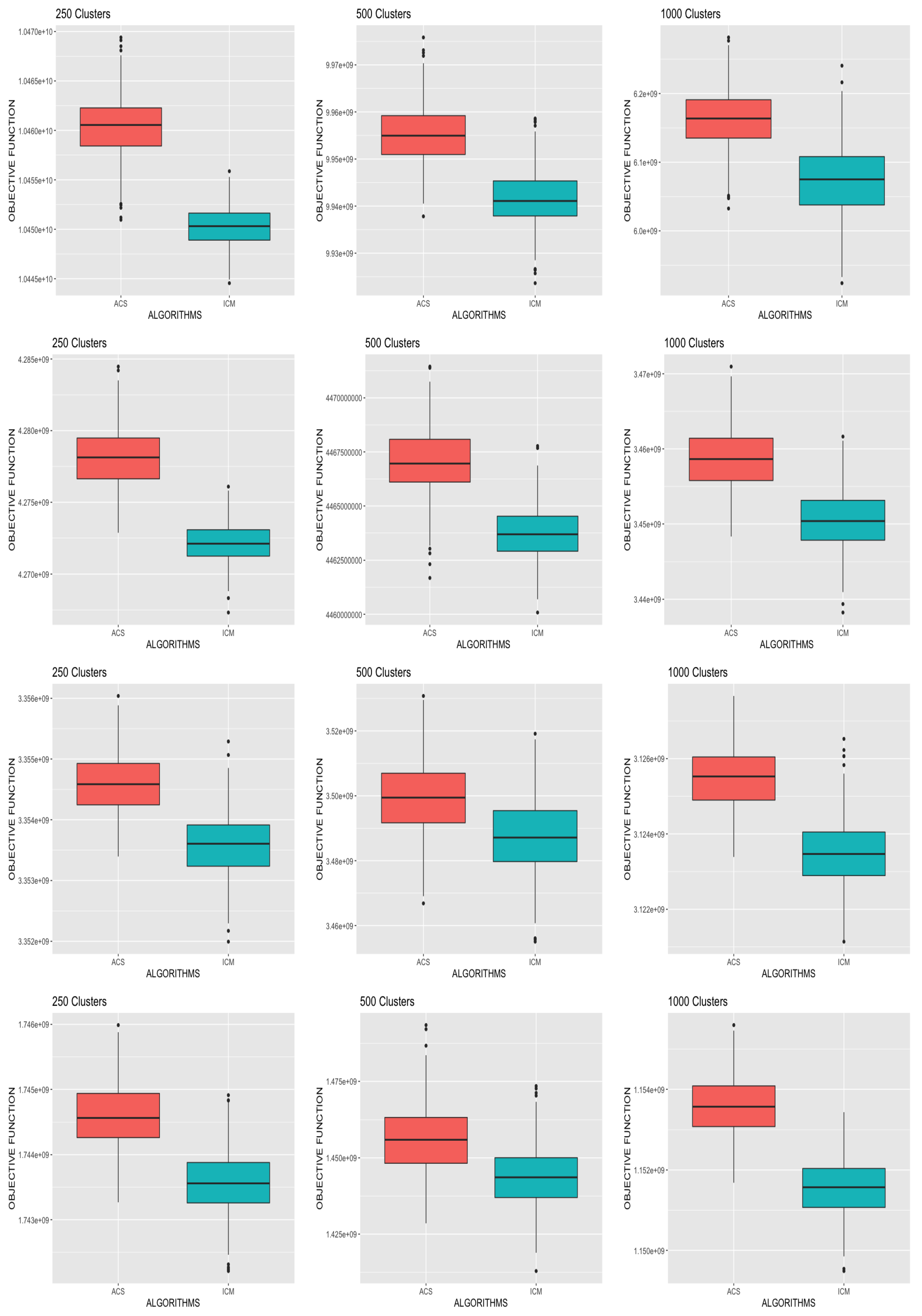
38] of the ACS algorithm. This supports the argument that theoretically the application of ACS-ICM to source reconstruction should improve ICM.
The local search ICM algorithm procedure is presented in Algorithm 1 and the ACS-ICM algorithm is presented in Algorithm 2. Convergence of the ICM algorithms is monitored by examining the relative change of the Frobenius norm of the estimated neural sources on consecutive iterations.
Algorithm 1 presents a detailed description of the ICM algorithm. The ICM algorithm requires full conditional distributions of each model parameter where the mode of the distribution is taken as the update step for the parameter. The full conditional distribution are described and presented in [
13]. This ICM algorithm is embedded in our ACS-ICM algorithm.
| Algorithm 1 Iterated Conditional Modes (ICM) Algorithm. |
- 1:
- 2:
- 3:
whiledo - 4:
- 5:
- 6:
- 7:
, where , and - 8:
for do - 9:
- 10:
end for - 11:
, where - 12:
for do - 13:
where - 14:
end for - 15:
where - 16:
for do - 17:
▹ , where denote the column of and - 18:
end for - 19:
Let denote the indices for “black” voxels and denote the indices for “white” voxels. - 20:
for do - 21:
and where , and - 22:
where is the number of cortical locations contained in voxel . - 23:
end for - 24:
for do - 25:
and where , and - 26:
where is the number of cortical locations contained in voxel . - 27:
end for - 28:
Check for convergence. Set Converged = 1 if so. - 29:
end while
|
| Algorithm 2 Ant Colony System (ACS)-ICM Algorithm. |
- 1:
Initial Value; set tuning parameters , , and . - 2:
Initialize pheromone information , for each representing information gathered by ants. - 3:
Construct candidate solutions for each of ants. For ant j, we find a candidate voxel labeling This is done sequentially for each ant j. Construct candidate by assigning label l to voxel s using the transition probability rule:
where if the label for voxel s is drawn randomly from with probability
and where . Assuming voxel s is assigned label ℓ set:
and for all
where is a tuning parameter in (0,1), which represents evaporation of the pheromone trails and .
- 4:
For all ants, improve candidate solutions by running ICM to convergence (this also allows an update to the other model parameters) - 5:
For all solutions, evaluate the quality of each ant’s solution using objective function: . Keep track of the best value. The current solution for each ant serves as the starting value for the next iteration. - 6:
Apply global updating of the pheromone function. For the best solution, update the pheromone as follows: Assuming voxel s is assigned label ℓ set:
and for all :
Check for convergence via increase in . Go back to step 3 - 7:
Return all voxel labeling and model parameters from the best solution.
|






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}