
Threshold-Based Hierarchical Clustering for Person Re-Identification


Abstract
1. Introduction
- We propose a threshold-based hierarchical clustering method which combines advantages of hierarchical clustering and DBSCAN. It regards outliers as single-sample clusters to participate in training and generates more reliable pseudo labels for training.
- We propose to use nonparametric memory with contrastive loss to optimize model. We make full use of all valuable information including source-class centroids, target-cluster centroids and single-sample clusters, so we get better performance.
- We evaluate different distance measurements in threshold-based hierarchical clustering. Results show minimum distance criterion has the best performance. We also evaluate our method on three datasets: Market-1501, DukeMTMC-reID and MSMT17. Results show we achieve state of the art.
2. Related Work
2.1. Unsupervised Domain Adaptation re-ID
2.2. Noise Label Learning
2.3. Memory Module
3. Our Method
3.1. Threshold-Based Hierarchical Clustering
3.1.1. Distance Metric
3.1.2. Hierarchical Cluster Merging
3.1.3. Distance Measurement
3.2. Nonparametric Memory
3.2.1. Memory Initialization
3.2.2. Memory Update
| Algorithm 1 THC Algorithm |
| Require: |
| Labeled source dataset ; |
| Unlabeled target dataset ; |
| Epoch t; |
| Threshold m; |
| Update rate ,. |
| Ensure: |
| Best model M. |
|
3.3. Loss Function
4. Experiment
4.1. Datasets
4.2. Evaluation Protocol
4.3. Implementation Details
4.4. Comparison with State-of-the-Arts
5. Ablation Study
5.1. Comparison with Different Distance Measurements and Threshold Values
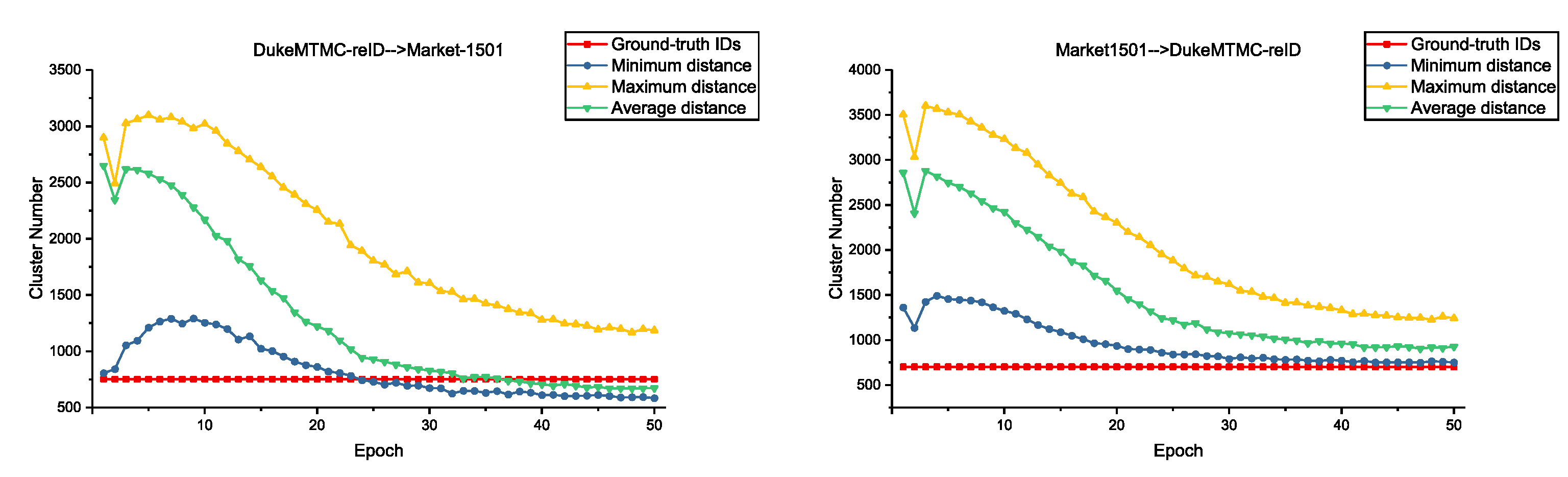
5.2. Comparison with Clusters Number during Training
5.3. Qualitative Analysis of T-SNE Visualization
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fan, H.; Zheng, L.; Yan, C.; Yang, Y. Unsupervised person re-identification: Clustering and fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–18. [Google Scholar] [CrossRef]
- Ning, M.; Zeng, K.; Guo, Y.; Wang, Y. Deviation based Clustering for Unsupervised Person Re-identification. Pattern Recognit. Lett. 2020, 135, 237–243. [Google Scholar] [CrossRef]
- Zeng, K.; Ning, M.; Wang, Y.; Guo, Y. Energy clustering for unsupervised person re-identification. Image Vis. Comput. 2020, 98, 103913. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 274–282. [Google Scholar]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A bottom-up clustering approach to unsupervised person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Nanjing, China, 27 January–1 February 2019; Volume 33, pp. 8738–8745. [Google Scholar]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised Domain Adaptive Re-Identification: Theory and Practice. arXiv 2018, arXiv:1807.11334. [Google Scholar] [CrossRef]
- Wu, Z.; Efros, A.A.; Yu, S.X. Improving generalization via scalable neighborhood component analysis. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 685–701. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 791–808. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Available online: https://www.aaai.org/Papers/KDD/1996/KDD96-037.pdf (accessed on 24 April 2021).
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance matters: Exemplar memory for domain adaptive person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Huang, T.S. Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6112–6121. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Bing, X.; Bengio, Y. Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint detection and identification feature learning for person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3415–3424. [Google Scholar]
- Zhong, Z.; Zheng, L.; Li, S.; Yang, Y. Generalizing a person retrieval model hetero-and homogeneously. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–188. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Deep association learning for unsupervised video person re-identification. arXiv 2018, arXiv:1808.07301. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Available online: https://papers.nips.cc/paper/2016/hash/90e1357833654983612fb05e3ec9148c-Abstract.html (accessed on 24 April 2021).
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. arXiv 2018, arXiv:1805.07836. [Google Scholar]
- Patrini, G.; Rozza, A.; Krishna Menon, A.; Nock, R.; Qu, L. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1944–1952. [Google Scholar]
- Lee, K.H.; He, X.; Zhang, L.; Yang, L. Cleannet: Transfer learning for scalable image classifier training with label noise. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5447–5456. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. arXiv 2018, arXiv:1804.06872. [Google Scholar]
- Yang, F.; Li, K.; Zhong, Z.; Luo, Z.; Sun, X.; Cheng, H.; Guo, X.; Huang, F.; Ji, R.; Li, S. Asymmetric Co-Teaching for Unsupervised Cross-Domain Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12597–12604. [Google Scholar]
- Ge, Y.; Chen, D.; Li, H. Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification. arXiv 2020, arXiv:2001.01526. [Google Scholar]
- Ge, Y.; Chen, D.; Zhu, F.; Zhao, R.; Li, H. Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID. arXiv 2018, arXiv:2006.02713. [Google Scholar]
- Sukhbaatar, S.; Weston, J.; Fergus, R. End-to-end memory networks. arXiv 2015, arXiv:1503.08895. [Google Scholar]
- Weston, J.; Chopra, S.; Bordes, A. Memory networks. arXiv 2014, arXiv:1410.3916. [Google Scholar]
- Wu, C.Y.; Feichtenhofer, C.; Fan, H.; He, K.; Krahenbuhl, P.; Girshick, R. Long-term feature banks for detailed video understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 284–293. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Learning to adapt invariance in memory for person re-identification. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Ding, Y.; Fan, H.; Xu, M.; Yang, Y. Adaptive exploration for unsupervised person re-identification. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–19. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1318–1327. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 17–35. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar]
- Chang, W.G.; You, T.; Seo, S.; Kwak, S.; Han, B. Domain-specific batch normalization for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7354–7362. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhai, Y.; Ye, Q.; Lu, S.; Jia, M.; Ji, R.; Tian, Y. Multiple expert brainstorming for domain adaptive person re-identification. arXiv 2020, arXiv:2007.01546. [Google Scholar]
- Li, Y.J.; Yang, F.E.; Liu, Y.C.; Yeh, Y.Y.; Du, X.; Frank Wang, Y.C. Adaptation and re-identification network: An unsupervised deep transfer learning approach to person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–178. [Google Scholar]
- Yu, H.X.; Zheng, W.S.; Wu, A.; Guo, X.; Gong, S.; Lai, J.H. Unsupervised Person Re-identification by Soft Multilabel Learning. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huang, H.; Yang, W.; Chen, X.; Zhao, X.; Huang, K.; Lin, J.; Huang, G.; Du, D. EANet: Enhancing alignment for cross-domain person re-identification. arXiv 2018, arXiv:1812.11369. [Google Scholar]
- Zhang, X.; Cao, J.; Shen, C.; You, M. Self-training with progressive augmentation for unsupervised cross-domain person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8222–8231. [Google Scholar]
- Wang, D.; Zhang, S. Unsupervised Person Re-identification via Multi-label Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10981–10990. [Google Scholar]
- Zou, Y.; Yang, X.; Yu, Z.; Kumar, B.; Kautz, J. Joint Disentangling and Adaptation for Cross-Domain Person Re-Identification. arXiv 2020, arXiv:2007.10315. [Google Scholar]
- Zeng, K.; Ning, M.; Wang, Y.; Guo, Y. Hierarchical Clustering With Hard-Batch Triplet Loss for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13657–13665. [Google Scholar]
- Lin, Y.; Xie, L.; Wu, Y.; Yan, C.; Tian, Q. Unsupervised person re-identification via softened similarity learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3390–3399. [Google Scholar]
- Ma, L.; Deng, Z. Real-Time Hierarchical Facial Performance Capture. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, I3D ‘19, Montreal, QC, Canada, 21–23 May 2019. [Google Scholar]
- Mousas, C.; Anagnostopoulos, C.N. Real-time performance-driven finger motion synthesis. Comput. Graph. 2017, 65, 1–11. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, Q.; Liu, J.; Luo, B. Efficient synthetical clustering validity indexes for hierarchical clustering. Expert Syst. Appl. 2020, 151, 113367. [Google Scholar] [CrossRef]
- Xiang, Z.; Xiang, C.; Li, T.; Guo, Y. A self-adapting hierarchical actions and structures joint optimization framework for automatic design of robotic and animation skeletons. Soft Comput. 2020, 25, 263–276. [Google Scholar] [CrossRef]
- Tan, X.; Zhang, L.; Xiong, D.; Zhou, G. Hierarchical Modeling of Global Context for Document-Level Neural Machine Translation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1576–1585. [Google Scholar]
- Angelin, B.; Geetha, A. Outlier Detection using Clustering Techniques – K-means and K-median. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | DukeMTMC-reID → Market-1501 | Market-1501 → DukeMTMC-reID | ||||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP | |
| PUL [1] | 44.7 | 59.1 | 65.6 | 20.1 | 30.4 | 44.5 | 50.7 | 16.4 |
| SPGAN [12] | 51.5 | 70.1 | 76.8 | 22.8 | 41.1 | 56.6 | 63.0 | 22.3 |
| HHL [19] | 62.2 | 78.8 | 84.0 | 31.4 | 46.9 | 61.0 | 66.7 | 27.2 |
| ARN [44] | 70.3 | 80.4 | 86.3 | 39.4 | 60.2 | 73.9 | 79.5 | 33.4 |
| MAR [45] | 67.7 | 81.9 | - | 40.0 | 67.1 | 79.8 | - | 48.0 |
| ECN [13] | 75.1 | 87.6 | 91.6 | 43.0 | 63.3 | 75.8 | 80.4 | 40.4 |
| EANet [46] | 78.0 | - | - | 51.6 | 67.7 | - | - | 48.0 |
| Theory [7] | 75.8 | 89.5 | 93.2 | 53.7 | 68.4 | 80.1 | 83.5 | 49.0 |
| PAST [47] | 78.4 | - | - | 54.6 | 72.4 | - | - | 54.3 |
| SSG [14] | 80.0 | 90.0 | 92.4 | 58.3 | 73.0 | 80.6 | 83.2 | 53.4 |
| MMCL [48] | 84.4 | 92.8 | 95.0 | 60.4 | 72.4 | 82.9 | 85.0 | 51.4 |
| ACT [27] | 80.5 | - | - | 60.6 | 72.4 | - | - | 54.5 |
| ECN++ [33] | 84.1 | 92.8 | 95.4 | 63.8 | 74.0 | 83.7 | 87.4 | 54.4 |
| DG-Net++ [49] | 82.1 | 90.2 | 92.7 | 61.7 | 78.9 | 87.8 | 90.4 | 63.8 |
| MMT [28] | 87.7 | 94.9 | 96.9 | 71.2 | 78.0 | 88.8 | 92.5 | 65.1 |
| MEB-Net [43] | 89.9 | 96.0 | 97.5 | 76.0 | 79.6 | 88.3 | 92.2 | 66.1 |
| THC | 91.2 | 96.4 | 97.7 | 78.5 | 83.0 | 90.1 | 92.7 | 68.8 |
| Methods | Market-1501 → MSMT17 | DukeMTMC-reID → MSMT17 | ||||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP | |
| PTGAN [15] | 10.2 | - | 24.4 | 2.9 | 11.8 | - | 27.4 | 3.3 |
| ECN [13] | 25.3 | 36.3 | 42.1 | 8.5 | 30.2 | 41.5 | 46.8 | 10.2 |
| SSG [14] | 31.6 | - | 49.6 | 13.2 | 32.2 | - | 51.2 | 13.3 |
| MMCL [48] | 40.8 | 51.8 | 56.7 | 15.1 | 43.6 | 54.3 | 58.9 | 16.2 |
| ECN++ [33] | 40.4 | 53.1 | 58.7 | 15.2 | 42.5 | 55.9 | 61.5 | 16.0 |
| DG-Net++ [49] | 48.4 | 60.9 | 66.1 | 22.1 | 48.8 | 60.9 | 65.9 | 22.1 |
| MMT [28] | 49.2 | 63.1 | 68.8 | 22.9 | 50.1 | 63.9 | 69.8 | 23.3 |
| THC | 48.2 | 59.7 | 64.5 | 23.7 | 50.0 | 61.5 | 66.7 | 24.9 |
| Methods | Market-1501 | DukeMTMC-reID | ||||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP | |
| BOW [37] | 35.8 | 52.4 | 60.3 | 14.8 | 17.1 | 28.8 | 34.9 | 8.3 |
| OIM [18] | 38.0 | 58.0 | 66.3 | 14.0 | 24.5 | 38.8 | 46.0 | 11.3 |
| BUC [6] | 66.2 | 79.6 | 84.5 | 38.3 | 47.4 | 62.6 | 68.4 | 27.5 |
| SSL [51] | 71.7 | 83.8 | 87.4 | 37.8 | 52.5 | 63.5 | 68.9 | 28.6 |
| MMCL [48] | 80.3 | 89.4 | 92.3 | 45.4 | 65.2 | 75.9 | 80.0 | 40.9 |
| HCT [50] | 80.0 | 91.6 | 95.2 | 56.4 | 69.6 | 83.4 | 87.4 | 50.7 |
| THC | 89.5 | 95.8 | 97.5 | 75.2 | 81.9 | 89.9 | 92.5 | 66.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, M.; Zeng, K.; Wang, Y.; Guo, Y. Threshold-Based Hierarchical Clustering for Person Re-Identification. Entropy 2021, 23, 522. https://doi.org/10.3390/e23050522
Hu M, Zeng K, Wang Y, Guo Y. Threshold-Based Hierarchical Clustering for Person Re-Identification. Entropy. 2021; 23(5):522. https://doi.org/10.3390/e23050522
Chicago/Turabian StyleHu, Minhui, Kaiwei Zeng, Yaohua Wang, and Yang Guo. 2021. "Threshold-Based Hierarchical Clustering for Person Re-Identification" Entropy 23, no. 5: 522. https://doi.org/10.3390/e23050522
APA StyleHu, M., Zeng, K., Wang, Y., & Guo, Y. (2021). Threshold-Based Hierarchical Clustering for Person Re-Identification. Entropy, 23(5), 522. https://doi.org/10.3390/e23050522