Abstract
Count datasets are traditionally analyzed using the ordinary Poisson distribution. However, said model has its applicability limited, as it can be somewhat restrictive to handling specific data structures. In this case, the need arises for obtaining alternative models that accommodate, for example, overdispersion and zero modification (inflation/deflation at the frequency of zeros). In practical terms, these are the most prevalent structures ruling the nature of discrete phenomena nowadays. Hence, this paper’s primary goal was to jointly address these issues by deriving a fixed-effects regression model based on the hurdle version of the Poisson–Sujatha distribution. In this framework, the zero modification is incorporated by considering that a binary probability model determines which outcomes are zero-valued, and a zero-truncated process is responsible for generating positive observations. Posterior inferences for the model parameters were obtained from a fully Bayesian approach based on the g-prior method. Intensive Monte Carlo simulation studies were performed to assess the Bayesian estimators’ empirical properties, and the obtained results have been discussed. The proposed model was considered for analyzing a real dataset, and its competitiveness regarding some well-established fixed-effects models for count data was evaluated. A sensitivity analysis to detect observations that may impact parameter estimates was performed based on standard divergence measures. The Bayesian p-value and the randomized quantile residuals were considered for the task of model validation.
Keywords:
Bayesian inference; hurdle model; Monte Carlo simulation; overdispersion; Poisson–Sujatha distribution; zero-modified data PACS:
02.50.-r
MSC:
62E15; 62J20; 62F15
1. Introduction
The ordinary Poisson distribution is often adopted for the analysis of count data, mainly due to its simplicity and having computational implementations available for most of the standard statistical packages. However, it is well-known that such a model is not suitable to describe over/underdispersed counts. Apart from data transformation, the most popular approach to circumvent such an issue is based on using hierarchical models that can accommodate different overdispersion levels [1].
The negative binomial distribution (that may arise as a mixture model by using a gamma distribution for the continuous part) is undoubtedly the most popular alternative to model extra- variability. There is extensive literature regarding other discrete mixed distributions that can accommodate different levels of overdispersion, for example, the Poisson–Lindley [2], the Poisson–lognormal [3], the Poisson–inverse Gaussian [4], the negative binomial–Lindley [5], the Poisson–Janardan [6], the two-parameter Poisson–Lindley [7], the Poisson–Amarendra [8], the Poisson–Shanker [9], the Poisson–Sujatha [10], the quasi-Poisson–Lindley [11], the weighted negative binomial–Lindley [12] the Poisson-weighted Lindley [13], the binomial-discrete Lindley [14], and the two-parameter Poisson–Sujatha [15], among many others.
Unfortunately, there is a significant drawback regarding such mixture models: they do not fit well when data present a modification in the frequency of zeros (typically underestimates the data dispersion and the frequency of zero-valued outcomes). The most common case in practice is the presence of an excessive number of zero-valued observations and a skewed distribution of positive values. In this way, developing -based two-part models (zero-inflated/hurdle models) became necessary. Prominent works addressing this task are [16,17,18,19,20,21,22].
Several authors have considered these approaches to analyze real data, and here we point out a few. Ref. [23] have sought to deal with the excess of zeros on data from recreational trips. Ref. [24] have shown that the modeling of migration frequency data can be improved using zero-inflated Poisson models. Ref. [25] have exploited the apple shoot propagation data, and they have addressed the modeling task by using several zero-inflated regression models. In the social sciences, ref. [26] have considered the hurdle version of the model for the number of homicides in Chicago (State of Illinois, US). Ref. [27] provided an application to private health insurance count data using ordinary and zero-inflated Poisson regression models. Further applications of these models were considered in quantitative studies about HIV-risk reduction [28,29], for the modeling of some occupational allergic diseases in France [30], for the analysis of DNA sequencing data [31], and for the modeling of several datasets on chromosomal aberrations induced by radiation [32]. A Bayesian approach for the zero-inflated Poisson distribution was considered by [33], and by [34] in a regression framework with fixed-effects.
Noticeably, most developed works are focused on the modeling of zero inflation, but zero-deflated data are also frequently observed in practice. However, there are still very few studies addressing this case [35], but this situation is often referred to in works handling zero inflation. In this context, a more comprehensive approach is provided by zero-modified models, which are flexible tools to handle count data with inflation/deflation at zero when there is no information about the nature of such a phenomenon.
Some of the most relevant works about zero-modified and hurdle models are cited in the following. Ref. [35] have introduced the zero-modified Poisson regression model, and ref. [36] have considered such a model as an alternative for the analysis of Brazilian leptospirosis notification data. The possible loss due to the specification of a model for analyzing samples without zero modification was studied by [37] using the Kullback–Leibler divergence. The hurdle version of the power series distribution was presented and well discussed by [38], and ref. [39] have adopted a Bayesian approach for the zero-modified Poisson model to predict match outcomes of the Spanish La Liga (2012–2013). Besides, ref. [40] have proposed the zero-modified Poisson–Shanker regression model, whose usefulness was illustrated through its application to fetal death notification data, and ref. [41] have introduced the zero-modified Poisson–Lindley regression model with fixed-effects under a fully Bayesian approach.
Accordingly, this paper aims to extend the works of [42,43] in the sense of developing a new fixed-effects regression model for count data based on the zero-modified Poisson–Sujatha distribution . Ref. [42] have introduced and exploited the theoretical distribution’s main statistical properties. On the other hand, ref. [43] have proposed a new class of zero-modified models, whose baseline distributions are Poisson mixtures, including the . The present paper also extends the works of [40,41] since the model differentiates from the zero-modified Poisson–Lindley and Poisson–Shanker by the ability, for example, to describe better (by adjusting its shape parameter) those discrete phenomena in which the probabilities of observing 0 s and 1 s are low (see [43], Figure 2).
Formally, a discrete random variable Y defined into is said to follow a distribution if its probability mass function (pmf) can be written as
where p is the zero-modification parameter and is an indicator function, so that if and otherwise. Additionally, is the expected value of the ordinary distribution, whose reparameterized pmf is given by
where
with
and for (shape parameter). This parameterization is particularly useful since our primary goal is to derive a regression model, in which the influence of fixed-effects can be evaluated directly over the mean of a zero-modified response variable. Unlike in zero-inflated models, here parameter p is defined on the interval , and so the model is not a mixture distribution since p may assume values greater than 1. The expected value and variance of Y are given, respectively, by and , where is the variance of the distribution (see [43], Table 4).
The hurdle version of the distribution can be obtained by taking , and so rewriting Equation (1) as
for and where is the pmf of the zero-truncated Poisson–Sujatha distribution [44]. Noticeably, Equation (3) is only a reparameterization of the standard , and so one can conclude that these models are interchangeable. For ease of notation and understanding, the acronym will be used when we refer to the hurdle version of the distribution.
The corresponding cumulative distribution function (cdf) of Y is given by
Comparatively, the proposed model can be considered more flexible than zero-inflated models as it allows for zero-deflation, which is a structure often encountered when handling count data (see, for example, [45,46]). Besides, it can incorporate overdispersion that does not come only from inflation/deflation of zeros, as one of its parts is dedicated to describing the positive values’ behavior. In the regression framework that we have developed, discrepant points (outliers) can be identified, and through a careful sensitivity analysis, it is possible to quantify the influences of such observations. However, since the distribution accounts for different levels of overdispersion, its zero-modified version is naturally a robust alternative, as it may accommodate discrepant points that would significantly impact the parameter estimates of the model.
In this paper, the inferential procedures are conducted under a fully Bayesian perspective—an adaptation of the g-prior method [47] for the fixed-effects parameters is considered. The random-walk metropolis algorithm was used to draw pseudo-random samples from the posterior distribution of the model parameters. Local influence measures based on some well-known divergences were considered for the task of detecting influential points. Model validation metrics such as the Bayesian p-value and the randomized quantile residuals are presented. Intensive Monte Carlo simulation studies were performed to assess Bayesian estimators’ empirical properties; the obtained results are discussed, and the overall performance of the adopted methodology was evaluated. Additionally, an application using a real dataset is presented to assess the proposed model’s usefulness and competitivity.
This paper is organized as follows. In Section 2, we present the fixed-effects regression model based on the hurdle version of the distribution. In Section 3, we describe all the Bayesian methodologies and associated numerical procedures considered for inferential purposes. In Section 4, we discuss the results of an intensive simulation study, and in Section 5, a real data application using the proposed model is exhibited. General comments and concluding remarks are addressed in Section 6.
2. The ZMPS Regression Model
Suppose that a random experiment (designed or observational) is conducted with n subjects. The primary response for such an experiment is described by a discrete random variable denoting the outcome for the i-th subject. The full response vector is given by , and we assume that the observed vector is obtained conditionally to fixed-effects, here denoted by . Assuming that holds for all i, a general fixed-effects regression model for count data based on the distribution can be derived by rewriting Equation (3) as
where and are parameterized nonlinear functions. In this framework, we have related to , where is a vector of covariates that may include, for example, dummy variables, cross-level interactions, and polynomials. The quantity denotes the number of covariates considered in the systematic component of a linear predictor for parameter . The full regression matrices of model (5) can be written as , where is the intercept column and the submatrix is defined in such a way that its i-th row contains the vector . The overall dimension of is .
Now, we have to specify two monotonic, invertible, and twice differentiable link functions, say and , in which and are well defined on and , respectively. For this purpose, one may choose any suitable mappings and such that and . The logarithm link function, , is the natural choice for . For , the popular choice is the logit link function,
The probit link function,
is also appropriate for the requested purpose. Another possible choice for is
which corresponds to the complementary log–log link function. One can notice that these link functions exclude the limit cases and . The link Function (8) is usually preferable when the occurrence probability of a specific outcome is considerably high/low as it accommodates asymmetric behaviors on the unit interval, which is not the case for link Functions (6) and (7). Besides, a more sophisticated approach considering power and reversal power link functions was proposed by [48], and can also be used to add even more flexibility when modeling parameter .
We may refer to the proposed model as a “semi-compatible” regression model. The term “compatible” alludes to “zero-altered,” which defines the class proposed by [49], and extended by [50] in a setting including semiparametric zero-altered models that accommodate over/underdispersion. Zero-altered models are similar to zero-modified ones, but the compatibility arises from the linear predictors of and being the same. In our case, specifically, it is worthwhile to mention that identifiability problems may occur if one considers a fixed-effects regression model derived directly from (3), with parameters and p sharing covariates, even if . Therefore, the adopted structure allows for more flexibility and robustness as and may share covariates not necessarily with , and so the only requirement for ensuring model identifiability is the linear independence between covariates within linear predictors.
Given a set of covariates, the probability of a zero-valued count being observed for the i-th subject is given by . Under the logistic regression model (6), represents the direct change in the log-odds of , it being positive per 1-unit change in , while holding the other covariates at fixed values. On the other hand, the same not apply if one adopts the link Function (8) since is not the odds ratio for the l-th covariate effect, and so does not have a straightforward interpretation in terms of contribution to log-odds. Likewise, it is not possible to interpret the coefficients of the probit model (7) directly, but one can evaluate the marginal effect of by analyzing how much the conditional probability of being positive is affected when the value of is changed. The exact interpretation of is not direct in terms of the mean of the hurdle model since the positive counts are modeled by a zero-truncated distribution , and therefore, represents the overall effect of on the expected value when , while holding the other covariates at fixed values.
The proposed model has unknown quantities to be estimated. A fully Bayesian approach will be considered for parameter estimation and associated inference. The next section is dedicated to present details of such an approach.
3. Inference
In this section, we address the problem of estimating and making inferences about the proposed model from a fully Bayesian perspective. Firstly, we derive the model likelihood function, and then, a suitable set of prior distributions is considered to obtain a computationally tractable posterior density for the vector . Beyond the primary distributional assumption that holds for all i, here we also assume that the outcomes for different subjects are unconditionally independent.
Let Y be a discrete random variable assuming values on . Suppose that a random experiment is carried out n times independently and, subject to for each i, a vector of observed values from Y is obtained. Considering model Formulation (5), the likelihood function of can be written as
and so the corresponding log-likelihood function is given by
In this work, we will consider a log-linear model for parameter , that is, . The choice of is left open and the notation will be used when necessary. From Equation (9), one can easily notice that the vectors and are orthogonal and that depends only on the positive values of . In this way, the log-likelihood function of takes the form
where is the finite set of indexes regarding the positive observations of . Adopting this setup is equivalent to assuming that each positive element of comes from a distribution. Here, we are extending the fact that estimating the parameter using the zero-truncated Poisson distribution results in a loss of efficiency in the inference if there is no zero modification [35,37]. Now, the log-likelihood function of can be written as
where is the finite set of indexes regarding the zero-valued observations of .
3.1. Prior Distributions
The g-prior [47] is a popular choice among Bayesian users of the multiple linear regression model, mainly due to the fact of providing a closed-form posterior distribution for the regression coefficients. The g-prior is classified as an objective prior method which uses the inverse of the Fisher information matrix up to a scalar variance factor to obtain the prior correlation structure of the multivariate normal distribution. Such specification is quite attractive since the Fisher information plays a major role in determining large-sample covariance in both Bayesian and classical inference.
The problem of eliciting conjugate priors for a GLM was addressed by [51]. Their approach can be considered as a generalization of the original g-prior method. Still, its application is restricted for the class of GLMs since the proposed prior does not have closed-form for non-normal exponential families. Alternatively, ref. [52] have proposed the information matrix prior as a way to assess the prior correlation structure between the coefficients, not including the intercept since the regression matrix is centered as to ensure that is orthogonal to the other coefficients. This method uses the Fisher information similarly to a precision matrix whose elements are shrunken by a fixed variance factor. However, the authors have pointed out that such class of priors can only be considered Gaussian priors if the Fisher information matrix does not depend on the vector . In this way, ref. [53] had considered a similar approach when they proposed a class of hyper-g priors for GLMs, where the precision matrix is evaluated at the prior mode, hence obtaining an information matrix that is free.
The formal concept behind the information matrix prior is closely related to the unit information prior [54], whose main idea is that the amount of information provided by a prior distribution must be the same as the amount of information contained in a single observation. Such an idea can be applied in the previously mentioned approaches by simply considering the total sample size as the variance factor. Ref. [52] have also considered fixed values for the scalar variance factor. On the other hand, some works, including [53,55,56] do consider prior elicitation and inference procedures for the variance scale factor. Here, we will adopt a methodology based on the unit information prior idea combined with the “noninformative g-prior” proposed by [57] for binary regression models. Based on such an approach, it is possible to obtain a quite simple prior distribution for the fixed-effects of the proposed model as , where .
It is worthwhile to mention that, in cases where is rank deficient or contains collinear covariates, it is highly advisable to compute the generalized inverse of otherwise the prior covariance matrix of may not be defined.
Analogously to Marin and Robert’s approach, we do not consider centered regression matrices in the prior specification. Hence, we are able to include in the proposed g-prior but, in this case, the intercept is a priori correlated with the other coefficients . The same applies for and the vector .
3.2. Posterior Distributions and Estimation
Considering the outlined structure for the regression model, the unnormalized joint posterior distribution of the unknown vector is given by
However, since and are orthogonal, we have that
where and are given by (10) and (11), respectively. Naturally, in the discrete setting, the use of proper (Gaussian) priors prevents and from being improper.
From the Bayesian point of view, inferences for the elements of can be obtained from their marginal posterior distributions. However, deriving analytical expressions for these densities is infeasible, mainly due to the associated log-likelihood function’s complexity. In this case, to make inferences for , we must resort to a suitable iterative procedure to drawn pseudo-random samples from their posterior densities. Hence, aiming to generate N chains for , we will adopt the well-known random-walk metropolis (RwM) algorithm [58,59]. For the posterior densities in (13), we consider a multivariate normal distributions for the proposal (candidate-generating) densities in the algorithm. These distributions will be used as the main terms in the transition kernels when computing the acceptance probabilities. Hence, at any state , the MCMC simulation are performed by proposing a candidate for as
where . One can notice that transitions depend on the acceptance of pseudo-random vectors generated with mean given by the actual state of the chain, which is shrunken by the factor . Besides, at any state , the covariance matrix of the candidate vector can be approximated numerically by evaluating at , where
The procedure to generate pseudo-random samples from the approximate posterior distribution of is summarized in Algorithm A1 (see Appendix A). To run it, one has to specify the size of chains to be generated and the initial state vectors and beforehand. For a specific asymptotic Gaussian environment, [59] have shown that the optimal acceptance rate should be around for 1-dimensional problems and asymptotically approaches to in higher-dimensional problems. We consider acceptance rates varying between and as quite reasonable since the proposed model will generally have at least four parameters to be estimated. Indeed, the higher the value of n, the lower the acceptance rate in the RwM algorithm, which results in lower variability of estimates.
The convergence of the simulated sequences can be monitored by using trace and autocorrelation plots, and the run-length control method with a half-width test [60], the Geweke z-score diagnostic [61], and the Brooks-Gelman-Rubin scale-reduction statistic [62]. After diagnosing convergence, some samples can be discarded as burn-in. The strategy to decrease the correlation between and within generated chains is based on getting thinned steps, and so the final sample is supposed to have size for each parameter. A full descriptive summary of the posterior distribution (12) can be obtained through Monte Carlo (MC) estimators using the sequence . We choose the posterior expected value as the Bayesian point estimator for , that is,
which is also known as the minimum mean square error estimator.
In the next section, we discuss the results of the Monte Carlo simulation studies performed to assess the proposed Bayesian methodology’s performance. In Section 5, the proposed model’s usefulness and competitivity are illustrated by using a real dataset. All computations were performed using the R environment [63]. The executable scripts were made available at the publisher’s website.
3.3. Posterior Predictive Distribution
In a Bayesian context, the posterior predictive distribution (ppd) is defined as the distribution of possible future (unobserved) values conditioned on the observed ones. Under the distribution, the pmf of any observation (subject to the vectors and of covariates) is given by
where if and otherwise. Noticeably, the ppd has no closed-form available, and therefore, an MC estimator for this quantity is given by
where
From Equation (15), one can easily estimate, for example, the posterior probability of (subject to and ) as
4. Simulation Study
The empirical properties of an estimator can be accessed through Monte Carlo simulations. In this way, we have performed an intensive simulation study aiming to validade the Bayesian approach in some specific situations. The simulation process was carried out by generating 500 pseudo-random samples of sizes of a variable Y following a distribution under the regression framework presented in Section 2. For the whole process, it was considered a regression matrix in which is a vector containing n generated values from a Uniform distribution on the unit interval. Here, we have fixed . Moreover, we have assigned different values for the vectors and in order to generate both zero-inflated and zero-deflated artificial samples. The logarithm link function was considered for . For , we have considered the link Functions (6)–(8) as a way to evaluate how these different specifications affect the estimation of .
Algorithm A2 (see Appendix A) can be used to generate a single pseudo-random realization from the distribution in the regression framework with covariate for and . The extension for the use of more covariates is straightforward. The process to generate a pseudo-random sample of size n consists of running the algorithm as often as necessary, say times . The sequential search is a black-box algorithm and works with any computable probability vector. The main advantage of such a procedure is its simplicity. On the other hand, sequential search algorithms may be slow as the while-loop may have to be repeated very often. More details about this algorithm can be found at [64].
Under the distribution, the expected number of iterations (NI), that is, the expected number of comparisons in the while condition, is given by
where is given by Equation (2).
We have considered four scenarios for each kind of zero-modification. Table 1 presents the true parameter values that were considered in our study. For the zero-inflated (zero-deflated) case, the samples were generated from the distribution by considering that for all i. Here, the regression coefficients were chosen by taking into account that zero-inflated (zero-deflated) samples have, naturally, proportion of zeros greater (lower) than expected under an ordinary count distribution and therefore, the variable was generated with mean far from zero (close to zero). Table 1 also presents the range of parameters and in each scenario. The bounds were obtained by evaluating the linear predictors and at and (limit values of the adopted covariate). Scenarios 1 and 2 of the zero-inflated case were considered to illustrate the Bayesian estimators’ behavior when the proposed model is used to fit (right) long-tailed count data.

Table 1.
Actual parameter values for simulation of zero-modified artificial datasets.
To apply the proposed Bayesian approach to each scenario, we have considered the RwM algorithm for MCMC sampling. For each generated sample, a chain with 50,000 values was generated for each parameter, considering a burn-in period of of the chain size. To obtain pseudo-independent samples from the posterior distributions given in (13), one out every 10 generated values were kept, resulting in chains of size for each parameter. Using trace plots and Geweke’s z-score diagnostic, the remaining chains’ stationarity was revealed. When running the simulations, the acceptance rates were ranging between and . The posterior mean (14) was considered as the Bayesian point estimator, and its performance was studied by assessing its bias (B), its mean squared error (MSE), and its mean absolute percentage error (MAPE). Besides, the coverage probability (CP) of the highest posterior density intervals (HPDIs) was also estimated.
Using the generated samples and letting , the MC estimators for these measures are given by
The variance of was estimated as the difference between the MSE and the square of the bias. Moreover, the CP of the HPDIs was estimated by
where assumes 1 if the j-th HPDI contains the true value and 0 otherwise. We have also estimated the below noncoverage probability (BNCP) and the above noncoverage probability (ANCP) of the HPDIs. These measures are computed analogously to CP. The BNCP and ANCP may be useful measures to determine asymmetrical behaviors as they provide the probabilities of finding the actual value of on the tails of its posterior distribution.
Due to the massive amount of results, the obtained results were made available on the publisher’s website as supplementary material. In our study, we have noticed that, as expected, the parameter estimates became more accurate with increasing sample sizes since the estimated biases and mean squared errors have decreased considerably as n increased. The squared ratio between the mean squared error and the estimated variance approaches 1 as n increases. Although high MAPE values were obtained for some parameters (when using small sample sizes), this does not compromise the overall estimation accuracy. For example, when , we have obtained a estimated MAPE value of approximately for (see Table S25, Scenario S1, Supplementary Material). Taking into account the true value of such parameter , we have that the estimates for were ranging mostly between and , which do not represent a significant impact on the estimated mean . When (right) long-tailed count data are available, the CP of the HPDI for is considerably lower than the adopted nominal level (for small sample sizes) as its posterior distribution tends to be more asymmetric towards higher values on the parameter space. However, we have observed that the estimated CP of the HPDIs is converging to in both zero-modified cases, and the posterior distributions became more symmetric with increasing sample sizes.
Considering the predefined scenarios, we conclude that our simulation study provides favorable indications about the adopted Bayesian methodology’s suitability to estimate the parameters of the proposed model. We believe that in a similar procedure with a different set of actual values, the estimators’ overall behavior should resemble the results that we have described here. Besides, the adopted methodology would also be reliable if one or more than one covariates (possibly of other nature) were included in the linear predictors of and .
5. Chromosomal Aberration Data Analysis
In this section, the regression model is considered for analyzing a real dataset obtained from a cytogenetic dosimetry experiment that was first presented by [65]. In this study, the response variable is the number of cytogenetic chromosomal aberrations after the DNA molecule is treated with induced radiation. The dataset was obtained by irradiating five blood samples from a healthy donor with different doses ranging between and Gy with MeV neutrons in three different culture times (48 h, 56 h, and 72 h), considering partial-body exposure-densely ionizing radiation. In the following, cells were examined in each irradiated sample and the number of dicentrics and centric ring aberrations was recorded.
While [65] have used a t-test to analyze whether the averages of the relative number of dicentrics plus centric ring aberration frequencies differed significantly between the three different culture times, we are primarily interested in evaluating if the averages of the number of dicentrics plus centric ring aberration differ significantly between doses of ionizing radiation, considering data from culture times of 72 h.
The frequency distribution of the collected data is available in Table 2, along with some descriptive statistics. From the observed dataset, there exist evidences that the response variable is slightly overdispersed since and . Additionally, the number of aberrations appears to be heavily zero-inflated, as shown in the left-panel of Figure 1. On the other hand, one can notice that, as the dose of ionizing radiation increases, the number of observed zeros decreases. Still, the distribution becomes more overdispersed since it naturally increases the number of aberrations.
Table 2.
Descriptive summary of the numbers of dicentrics and centric ring aberrations.
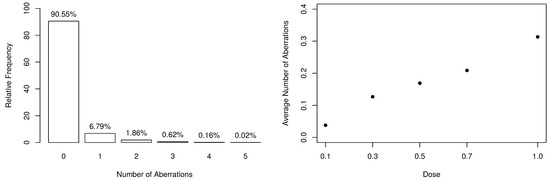
Figure 1.
Summary of the numbers of dicentrics and centric ring aberrations.
According to [32], when considering higher linear energy transfer radiations, the incidence of chromosomal aberrations becomes a linear function of the dose because the more densely ionizing nature of the radiation leads to an “one track” distribution of damage. Such an aspect can be seen in the right-panel of Figure 1, which highlights the linear behavior between the average number of aberrations and the doses. In this way, our assumption is that , where parameters and are specified as linear dose models, that is,
To fit the regression model with dose as the only covariate, we have adopted the same procedure used in the previous section. The link Function (7) was chosen to relate with the linear predictor and so we have the probit hurdle regression model. In this framework, the coefficient represents the effect of the dose of ionizing radiation on the expected count when , and indicates the effect of the dose on the probability of aberrations to occur. We have considered the RwM for MCMC sampling, generating a chain of size 50,000 for each parameter whereby the first 10,000 values were discarded as burn-in. The stationarity of the chains was revealed using the Geweke z-score diagnostic of convergence. To obtain the pseudo-independent samples from the posterior distributions given in (13), we have considered one value out of every 10 generated ones, resulting in chains of size for each parameter.
Table 3 presents the posterior parameter estimates and 95% HPDIs from fitted model. When obtaining the MCMC samples, the acceptance rate in the RwM algorithm was approximately . Besides, we have computed the number of effectively pseudo-independent draws, that is, the Effective Sample Size (ESS) for each parameter. Figure 2 and Figure 3 depict the chains’ history (trace plots) and the marginal posterior distributions of the regression coefficients. The normality assumption of the generated chains is quite reasonable, even with slight tails on the estimated densities. Additionally, there exists evidence of symmetry since the posterior means and medians are very close to each other. For each parameter, the ESS was estimated at approximately half of M, indicating a good mixing of the generated chains without computational waste.
Table 3.
Posterior parameter estimates and highest posterior density intervals (HPDIs) from fitted model.
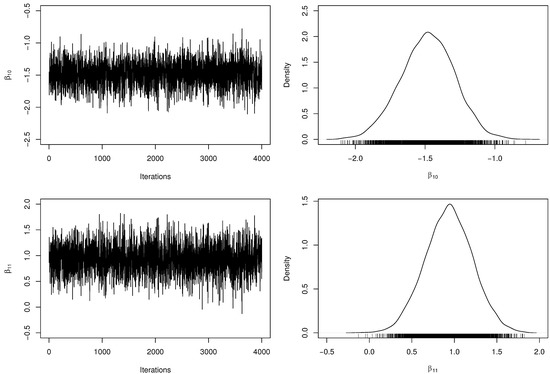
Figure 2.
Trace plots and marginal posterior distributions of parameters and from the regression model.
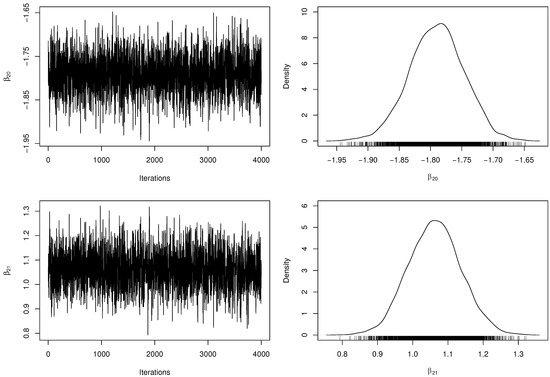
Figure 3.
Trace plots and marginal posterior distributions of parameters and from the regression model.
A sensitivity analysis to verify the existence of influential points is presented in Figure 4. We have estimated all divergence measures presented in Table A1 but, since the obtained results led to the same conclusions, we are only reporting the KL and H divergences and their calibration for each observation. Even being very conservative by considering an observation whose distance has a calibration exceeding as an influential point, we do not have found evidence that any observation has influenced the estimation of any coefficient of the regression model significantly.
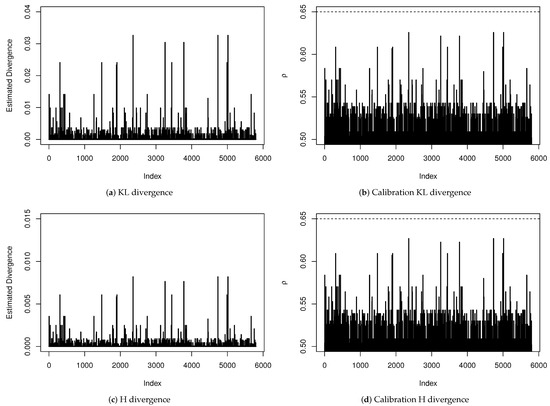
Figure 4.
Sensitivity analysis for diagnosis of influential points.
For comparison purposes, identical Bayesian procedures were adopted to fit the , the , the , the and the regression models. To estimate the fixed dispersion parameter of and models, we have considered a noninformative inverse-gamma prior distribution with hyperparameters . For each fitted model, we have estimated the measures presented in Appendix C. The model comparison procedure is summarized in Table 4. One can notice that the zero-modified models have performed considerably better with outperforming all. These results are highlighting that the proposed model is highly competitive with well-established models in the literature. This feature can be considered one of the most relevant achievements of the model since it has to deal with the positive observations using fewer parameters than, for example, the model.
Table 4.
Comparison criteria and adequacy measures for the fitted models.
In Table 4, we have also reported the Bayesian p-values as a way to evaluate the adequacy of the fitted models. As expected, the model is unsuitable to describe the considered dataset, and the fit provided by the regression model is also highly questionable. For the zero-modified models, there is no indication of overall lack-of-fit, since the posterior values of were estimated close to . Figure 5 depicts additional evidence based on the RQRs for validating the fitted regression. This residual metric was computed as discussed in Appendix D, using Equation (4). One can notice that the normality assumption of the residuals is easily verified by the behavior of its frequency distribution (left-panel). Additionally, the half-normal probability plot indicates that the fit of the model was very satisfactory since all estimated residuals are lying within the simulated envelope (right-panel).
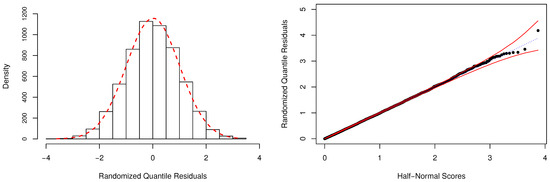
Figure 5.
Frequency distribution and half-normal plot with simulated envelope for the randomized quantile residuals (RQRs).
From the results displayed in Table 3, one can make some conclusions. Firstly, we have observed that the HPDIs of parameters and do not contain the value zero, which constitutes the dose of ionizing radiation as a relevant covariate to describe the average number of chromosomal aberrations as well the probability of not observing at least one aberration . For example, the expected number of dicentrics and centric rings in a cell that was exposed to Gy is , and the probability of such aberrations not to occur is . Therefore, based on the posterior estimates, the components of the fitted model can be expressed by
where is the dose of ionizing radiation.
Figure 6 present the Bayesian estimates, by dose, for the probability of not observing at least one aberration (left-panel) and for parameter p (right-panel). Noticeably, inferences about parameter p confirm the initial assumption that the analyzed sample has an excessive amount of zeros.
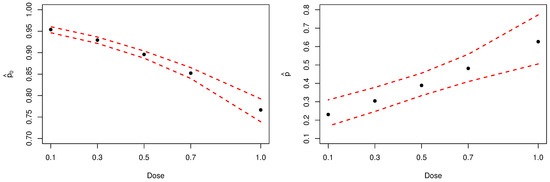
Figure 6.
Posterior estimates of parameters and p. The dashed red lines represent the HPDIs.
Table 5 presents a general posterior summary of the models that were fitted to the chromosomal aberration data. Here, parameter as estimated as and was estimated analogously. One can notice that the expected number of zeros obtained by the , the and the models are slightly lower than the observed , while those provided by the zero-modified models are very close (or exactly equal) to 5252. Through these measures, one can better understand how the fitted models are adhering to the data since the nature of the observed counts should be well described regarding its overdispersion level and the frequency and the average number of nonzero observations.
Table 5.
Posterior parameter estimates and goodness-of-fit evaluation.
The goodness-of-fit of the fitted models can be evaluated by the statistic obtained from the observed and expected frequencies. To compute such measure, we have grouped cells with frequencies lower or equal than 5, resulting in 4 degrees of freedom. The obtained statistics are also presented in Table 5. Figure 7 depict the positive expected frequencies (left-panel) and the dose-response curves (right-panel) that were estimated by the zero-modified models. Noticeably, the zero-modified models describe much better the data’s behavior, especially the and the distributions.
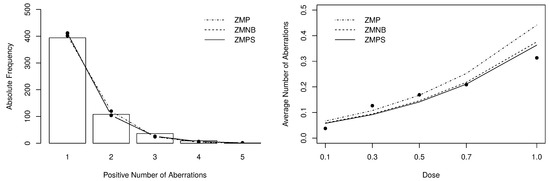
Figure 7.
Posterior expected frequencies and dose-response curve fitted by the zero-modified models.
From the obtained results, one can conclude that despite the suitable fit provided by the regression model, the proposed model have adhered better to the chromosomal aberration data. This achievement can be regarded as extremely relevant since the model has an additional (dispersion) parameter to handle the non-zero observations. In contrast, the proposed model was proved highly competitive by its ability to accommodate the data overdispersion and zero modification using fewer parameters.
6. Concluding Remarks
This work aimed to introduce the regression model as an alternative for the analysis of overdispersed datasets exhibiting zero-modification in the presence of covariates. Intensive Monte Carlo simulation studies were performed, and the obtained results have allowed us to assess the empirical properties of the Bayesian estimators and then conclude about the suitability of the adopted methodology to the predefined scenarios. The proposed model was considered for analyzing a real dataset on the number of cytogenetic chromosomal aberrations, considering the dose of ionizing radiation as the covariate for both model components. The response variable was identified as overdispersed and heavily zero-inflated, which justified using the regression model. The main conclusion one can make from the fitted models is that the dose is statistically relevant to describe either the probability of occurrence and the average incidence of aberrations. Besides, when looking at the statistic and the posterior-based comparison criteria, we have noticed that the proposed model has presented a better fit when compared to its competitors and therefore, it can be considered an excellent addition to the set of models that can be used for the analysis of overdispersed and zero-modified count data.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/e23060646/s1.
Author Contributions
All authors equally contributed to developing this work. All authors have read and agreed to the published version of the manuscript.
Funding
The research of Wesley Bertoli is supported by the Federal University of Technology—Paraná. The research of Francisco Louzada is supported by the National Council for Scientific and Technological Development (CNPq— Grant: 301976/2017-1) and by the São Paulo Research Foundation (FAPESP—Grant: 2013/07375-0). The research of Katiane S. Conceição and Marinho G. Andrade is supported by FAPESP (Grants: 2019/22412-5 and 2019/21766-8). This work was supported by FAPESP (Grant: 2021/00407-0).
Data Availability Statement
The dataset analyzed in this work was made available in the Supplementary Material.
Acknowledgments
We would like to thank the associate editor and the four anonymous referees for their careful reading and thoughtful suggestions, which certainly improved this work’s content.
Conflicts of Interest
The authors declare that they have no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ANCP | Above noncoverage probability |
| B | Bias |
| BNCP | Below noncoverage probability |
| CDF | Cumulative distribution function |
| CP | Coverage probability |
| CPO | Conditional predictive ordinate |
| CS | Chi-square |
| DIC | Deviance information criterion |
| EAIC | Expected Akaike information criterion |
| EBIC | Expected Bayesian information criterion |
| ESS | Effective sample size |
| GLM | Generalized linear model |
| H | Hellinger |
| HPDI | Highest posterior density interval |
| J | Jeffrey |
| KL | Kullback–Leibler |
| L | Variational divergence |
| LMPL | Log-marginal pseudo-likelihood |
| MAPE | Mean absolute percentage error |
| MC | Monte Carlo |
| MCMC | Markov chain Monte Carlo |
| MSE | Mean squared error |
| Negative binomial | |
| NI | Number of iterations |
| Poisson | |
| PMF | Probability mass function |
| Poisson–Sujatha | |
| RQR | Randomized quantile residuals |
| RwM | Random-walk metropolis |
| Zero-inflated Poisson | |
| Zero-modified Poisson | |
| Zero-modified Poisson–Sujatha | |
| Zero-truncated Poisson | |
| Zero-truncated Poisson–Sujatha |
Appendix A. Algorithms
Appendix A.1. Random-Walk Metropolis
| Algorithm A1 Random-walk metropolis. |
|
Appendix A.2. Sequential Search
| Algorithm A2 Sequential search. |
|
Appendix B. Influential Points
Identifying influential observations is a crucial step in any statistical analysis. Usually, the presence of influential points impacts the inferential procedures and the subsequent conclusions considerably. In this way, this subsection is dedicated to present some case deletion Bayesian diagnostic measures that can be used to quantify the influence of observations from each subject in a given dataset.
The computation of divergence measures between posterior distributions is a useful way to quantify influence. According [66], the -divergence measure between two densities f and g for is defined by
where is a smooth convex, lower semicontinuous function such that . Some popular divergence measures can be obtained by choosing specific functions for . The well-known Kullback–Leibler (KL) divergence is obtained by considering . A symmetric version of the KL divergence, the Jeffrey (J) divergence, can be obtained by specifying and the variational divergence ( norm) is obtained when . In addition, the Chi-square (CS) divergence is obtained by considering and the Hellinger (H) distance arises when . We refer to [67] for a detailed study on several types of -divergence.
Let be the joint posterior distribution of based only on the i-th observation and let , where is the response vector without the i-th observation. After some algebra (see [68] for the KL divergence case), one can verify that the -divergence corresponds to
where is the conditional predictive ordinate (CPO) statistic [69] for the i-th observation. Here, we are also not able to compute the inner expectation over analytically and so, an MC estimator for the is given by
According to [70], the harmonic mean estimator (A1) is stable when most of the individual log-likelihood values exceed -10. Using the estimated CPO, one can approximate the local influence of a particular on the joint posterior distribution (12) as
One can notice that, if , then there is no divergence caused by observation . In practice, however, it may not be elementary to define a threshold value for the divergence to decide about the magnitude of the influence [71]. A measure of calibration for the KL divergence was proposed by [72]. The idea is based on the typical toy binary example of tossing a coin once and observing its upper face. This experiment can be described by , , where is the probability of success. Regardless of what success means, if the coin is unbiased, then . Thus, the -divergence between a (possibly) biased and an unbiased coin is given by
from which one can conclude that the divergence between two posteriors distributions can be associated with the biasedness of a coin [67]. By analogy, this implies that predict unobserved responses using instead of is equivalent to describe an unobserved event as having probability , when the correct probability is 0.50. Considering some specific choices for , in Table A1 we present MC estimators that can be used to compute the local influence of each . Besides, we also present the expression of for each . For ease of notation, we assume .
Table A1.
MC estimators for some -divergence measures and their calibration.
Table A1.
MC estimators for some -divergence measures and their calibration.
| no closed-form | |||
KL: K; J: Jeffrey; : Variational; CS: Chi-Square; and H: Hellinger.
The function is symmetric about 0.50 and increases as moves away from 0.50. In addition, , which is attained at since . Therefore, a general measure of calibration based on the -divergence can be obtained by solving
An estimator for the calibration measure associated with each -divergence type is also presented in Table A1. Clearly, depending on the form of , such an equation may not have a closed-form, which is the case of the J divergence. Besides, one can notice that and so, for , the i-th observation may be considered an influential point. For example, if is considered a significative bias, then will be classified as influential if under the KL divergence or yet if under the H divergence.
Appendix C. Model Comparison and Adequacy
There are several techniques for Bayesian model selection that are useful to compare competing models. The most popular method is the deviance information criterion (DIC), which was proposed to work simultaneously to measure fit and complexity of the model. The DIC criterion is defined as
where is the deviance function and is the effective number of model parameters, with given by (14). A negative value for may suggest that the log-likelihood function is non-concave, the prior distribution is misspecified, or the posterior expected value is not a good estimator for . On the other hand, when , then there is an indication of overfitting with estimate .
Noticeably, we are not able to compute the expectation of over analytically. In this case, an MC estimator for such a measure is given by
and so the DIC can be estimated by .
The expected Akaike (EAIC) and the expected Bayesian (EBIC) information criteria can also be used when comparing Bayesian models [73,74]. Using the approximation for the expected value of , these measures can be estimated by
Another widely used criterion is derived from the CPO statistic, which is based on the cross-validation criterion to compare models. For the i-th observation, the CPO can be estimated through Equation (A1). A summary statistic of the estimated CPO’s is the log-marginal pseudo-likelihood (LMPL) given by the sum of the logarithms of ’s. Regarding model comparison, we have that the lower the values of DIC, EAIC, EBIC, and NLMPL (negative LMPL), the better the fit.
In addition to comparing, researchers are often interested in verifying the adequacy of the fitted models. An effective way to evaluate model suitability is based on the use of measures derived from the ppd. For instance, if any observation is extremely unlikely relative to the ppd, the obtained fit’s adequacy might be questionable. Ref. [75] proposed a widespread discrepancy measure between model and data. In our case, we need a slightly adapted version of such a measure, which is given by
The Bayesian p-value (posterior predictive p-value), proposed by [76], is defined as
where denotes the response vector that might have been observed if the conditions generating were reproduced. This predictive measure can be empirically estimated as the relative number of times that exceeds out of B simulations. In general, the model fit becomes suspect if the discrepancy is of practical relevance, and the associated Bayesian p-value is close either to 0 or 1 [75]. A large (small) value of , say greater than 0.95 (lower than 0.05), indicates model misspecification (lack-of-fit), that is, the observed behavior would be unlikely to be seen if we replicate the response vector using the fitted model.
Appendix D. Residual Analysis
The residual analysis plays an essential role in the task of validating the results obtained from a regression model. In general, residual metrics are responsible for indicating departures from the underlying model assumptions by quantifying the portion of data variability that the fitted model is not explaining. Assessing a regression model’s adequacy using residual metrics is a common practice nowadays due to the availability of statistical packages providing diagnostic tools for well-established models. However, deriving appropriate residuals is not always an easy task for non-normal models that accommodate overdispersion. In this way, we will consider a popular residual metric proposed by [77], the randomized quantile residuals (RQRs), which can be straightforwardly used in our context to assess the appropriateness of the proposed model when fitted to real data.
For obvious reasons, we focus on the definition of RQRs for discrete random variables. In this case, the RQR associated with the i-th observation is defined as , where denotes the cdf of the standard normal distribution and is a Uniform random variable defined on , with and , where is the cdf of the current model. In our case, we may obtain an MC estimator for the RQR as , with . Here, is an estimate for the probability of using cdf (4), where and depend on the fitted model as and .
The primary assumption for this metric is that must hold, whichever the variability degree of and . In this case, after model fitting, one has to evaluate if these residuals are normally distributed around zero, which can be made through adherence tests and by using graphical techniques as histograms and half-normal probability plots. An excellent alternative for checking whether RQRs are consistent with the fitted model is the inclusion of simulated envelopes in their half-normal plot. Thus, if a significant subset of estimated residuals falls outside the envelope bands, then the fitted model’s adequacy must be questioned, and further investigation on the corresponding observations is necessary. Ref. [78] provides an algorithm for obtaining simulated envelopes for a half-normal plot.
References
- Karlis, D.; Xekalaki, E. Mixed Poisson distributions. Int. Stat. Rev. 2005, 73, 35–58. [Google Scholar] [CrossRef]
- Sankaran, M. The discrete Poisson-Lindley distribution. Biometrics 1970, 26, 145–149. [Google Scholar] [CrossRef]
- Bulmer, M.G. On fitting the Poisson-Lognormal distribution to species-abundance data. Biometrics 1974, 30, 101–110. [Google Scholar] [CrossRef]
- Shaban, S.A. On the discrete Poisson-Inverse Gaussian distribution. Biom. J. 1981, 23, 297–303. [Google Scholar] [CrossRef]
- Zamani, H.; Ismail, N. Negative Binomial-Lindley distribution and its application. J. Math. Stat. 2010, 6, 4–9. [Google Scholar] [CrossRef]
- Shanker, R.; Sharma, S.; Shanker, U.; Shanker, R.; Leonida, T.A. The discrete Poisson-Janardan distribution with applications. Int. J. Soft Comput. Eng. 2014, 4, 31–33. [Google Scholar]
- Shanker, R.; Mishra, A. A two parameter Poisson-Lindley distribution. Int. J. Stat. Syst. 2014, 9, 79–85. [Google Scholar]
- Shanker, R. The discrete Poisson-Amarendra distribution. Int. J. Stat. Distrib. Appl. 2016, 2, 14–21. [Google Scholar] [CrossRef][Green Version]
- Shanker, R. The discrete Poisson-Shanker distribution. Jacobs J. Biostat. 2016, 1, 1–7. [Google Scholar]
- Shanker, R. The discrete Poisson-Sujatha distribution. Int. J. Probab. Stat. 2016, 5, 1–9. [Google Scholar]
- Shanker, R.; Mishra, A. A quasi Poisson-Lindley distribution. J. Indian Stat. Assoc. 2016, 54, 113–125. [Google Scholar]
- Bakouch, H.S. A Weighted Negative Binomial-Lindley distribution with applications to dispersed data. An. Acad. Bras. Ciências 2018, 90, 2617–2642. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K. On Poisson-weighted Lindley distribution and its applications. J. Sci. Res. 2018, 11, 1–13. [Google Scholar] [CrossRef]
- Kuş, C.; Akdoğan, Y.; Asgharzadeh, A.; Kınacı, İ.; Karakaya, K. Binomial-discrete Lindley distribution. Commun. Fac. Sci. Univ. Ank. Ser. A1 Math. Stat. 2019, 10, 401–411. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K.; Leonida, T.A. A two-parameter Poisson-Sujatha distribution. Am. J. Math. Stat. 2020, 68, 70–78. [Google Scholar]
- Mullahy, J. Specification and testing of some modified count data models. J. Econom. 1986, 91, 841–853. [Google Scholar] [CrossRef]
- Lambert, D. Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics 1992, 34, 1–14. [Google Scholar] [CrossRef]
- Zorn, C.J.W. Evaluating zero-inflated and hurdle Poisson specifications. Midwest Political Sci. Assoc. 1996, 18, 1–16. [Google Scholar]
- Deb, P.; Trivedi, P.K. The structure of demand for health care: Latent class versus two-part models. J. Health Econ. 2002, 21, 601–625. [Google Scholar] [CrossRef]
- Angers, J.F.; Biswas, A. A Bayesian analysis of zero-inflated generalized Poisson model. Comput. Stat. Data Anal. 2003, 42, 37–46. [Google Scholar] [CrossRef]
- McDowell, A. From the help desk: Hurdle models. Stata J. 2003, 3, 178–184. [Google Scholar] [CrossRef]
- Wagh, Y.S.; Kamalja, K.K. Zero-inflated models and estimation in zero-inflated Poisson distribution. Commun. Stat. Simul. Comput. 2018, 47, 1–18. [Google Scholar] [CrossRef]
- Gurmu, S.; Trivedi, P.K. Excess zeros in count models for recreational trips. J. Bus. Econ. Stat. 1996, 14, 469–477. [Google Scholar]
- Bohara, A.K.; Krieg, R.G. A zero-inflated Poisson model of migration frequency. Int. Reg. Sci. Rev. 1996, 19, 211–222. [Google Scholar] [CrossRef]
- Ridout, M.; Demétrio, C.G.B.; Hinde, J. Models for count data with many zeros. In Proceedings of the XIXth International Biometric Conference, Cape Town, South Africa, 13–18 December 1998; Volume 19, pp. 179–192. [Google Scholar]
- Bahn, G.D.; Massenburg, R. Deal with excess zeros in the discrete dependent variable, the number of homicide in Chicago census tract. In Proceedings of the Joint Statistical Meetings of the American Statistical Association, Denver, CO, USA, 3–7 August 2008; pp. 3905–3912. [Google Scholar]
- Mouatassim, Y.; Ezzahid, E.H. Poisson regression and zero-inflated Poisson regression: Application to private health insurance data. Eur. Actuar. J. 2012, 2, 187–204. [Google Scholar] [CrossRef]
- Heilbron, D.C.; Gibson, D.R. Shared needle use and health beliefs concerning AIDS: Regression modeling of zero-heavy count data. Poster session. In Proceedings of the Sixth International Conference on AIDS, San Francisco, CA, USA, 20–24 June 1990. [Google Scholar]
- Hu, M.C.; Pavlicova, M.; Nunes, E.V. Zero-inflated and hurdle models of count data with extra zeros: Examples from an HIV-risk reduction intervention trial. Am. J. Drug Alcohol Abus. 2011, 37, 367–375. [Google Scholar] [CrossRef]
- Ngatchou-Wandji, J.; Paris, C. On the zero-inflated count models with application to modelling annual trends in incidences of some occupational allergic diseases in France. J. Data Sci. 2011, 9, 639–659. [Google Scholar]
- Beuf, K.D.; Schrijver, J.D.; Thas, O.; Criekinge, W.V.; Irizarry, R.A.; Clement, L. Improved base-calling and quality scores for 454 sequencings based on a hurdle Poisson model. BMC Bioinform. 2012, 13, 303. [Google Scholar] [CrossRef]
- Oliveira, M.; Einbeck, J.; Higueras, M.; Ainsbury, E.; Puig, P.; Rothkamm, K. Zero-inflated regression models for radiation-induced chromosome aberration data: A comparative study. Biom. J. 2016, 58, 259–279. [Google Scholar] [CrossRef]
- Rodrigues, J. Bayesian analysis of zero-inflated distributions. Commun. Stat. Theory Methods 2003, 32, 281–289. [Google Scholar] [CrossRef]
- Ghosh, S.K.; Mukhopadhyay, P.; Lu, J.C. Bayesian analysis of zero-inflated regression models. J. Stat. Plan. Inference 2006, 136, 1360–1375. [Google Scholar] [CrossRef]
- Dietz, E.; Böhning, D. On estimation of the Poisson parameter in zero-modified Poisson models. Comput. Stat. Data Anal. 2000, 34, 441–459. [Google Scholar] [CrossRef]
- Conceição, K.S.; Andrade, M.G.; Louzada, F. Zero-modified Poisson model: Bayesian approach, influence diagnostics, and an application to a Brazilian leptospirosis notification data. Biom. J. 2013, 55, 661–678. [Google Scholar] [CrossRef] [PubMed]
- Conceição, K.S.; Andrade, M.G.; Louzada, F. On the zero-modified Poisson model: Bayesian analysis and posterior divergence measure. Comput. Stat. 2014, 29, 959–980. [Google Scholar] [CrossRef]
- Conceição, K.S.; Louzada, F.; Andrade, M.G.; Helou, E.S. Zero-modified Power Series distribution and its hurdle distribution version. J. Stat. Comput. Simul. 2017, 87, 1842–1862. [Google Scholar] [CrossRef]
- Conceição, K.S.; Suzuki, A.K.; Andrade, M.G.; Louzada, F. A Bayesian approach for a zero modified Poisson model to predict match outcomes applied to the 2012-13 La Liga season. Braz. J. Probab. Stat. 2017, 31, 746–764. [Google Scholar] [CrossRef]
- Bertoli, W.; Conceição, K.S.; Andrade, M.G.; Louzada, F. On the zero-modified Poisson-Shanker regression model and its application to fetal deaths notification data. Comput. Stat. 2018, 33, 807–836. [Google Scholar] [CrossRef]
- Bertoli, W.; Conceição, K.S.; Andrade, M.G.; Louzada, F. Bayesian approach for the zero-modified Poisson-Lindley regression model. Braz. J. Probab. Stat. 2019, 33, 826–860. [Google Scholar] [CrossRef]
- Bertoli, W.; Ribeiro, A.M.T.; Conceição, K.S.; Andrade, M.G.; Louzada, F. On zero-modified Poisson-Sujatha distribution to model overdispersed count data. Austrian J. Stat. 2018, 47, 1–19. [Google Scholar]
- Bertoli, W.; Conceição, K.S.; Andrade, M.G.; Louzada, F. A Bayesian approach for some zero-modified Poisson mixture models. Stat. Model. 2020, 20, 467–501. [Google Scholar] [CrossRef]
- Shanker, R.; Fesshaye, H. On zero-truncation of Poisson, Poisson-Lindley and Poisson-Sujatha distributions and their applications. Biom. Biostat. Int. J. 2016, 3, 1–13. [Google Scholar] [CrossRef]
- Fernández-Fontelo, A.; Puig, P.; Ainsbury, E.A.; Higueras, M. An exact goodness-of-fit test based on the occupancy problems to study zero-inflation and zero-deflation in biological dosimetry data. Radiat. Prot. Dosim. 2018, 179, 317–326. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wang, D.; Sun, J. Control charts based on dependent count data with deflation or inflation of zeros. J. Stat. Comput. Simul. 2019, 89, 3273–3289. [Google Scholar] [CrossRef]
- Zellner, A. On assessing prior distributions and Bayesian regression analysis with g-prior distributions. Bayesian Inference Decis. Tech. Essays Honor Bruno De Finetti 1986, 6, 233–243. [Google Scholar]
- Bazán, J.L.; Torres-Avilés, F.; Suzuki, A.K.; Louzada, F. Power and reversal power links for binary regressions: An application for motor insurance policyholders. Appl. Stoch. Model. Bus. Ind. 2017, 33, 22–34. [Google Scholar] [CrossRef]
- Heilbron, D.C. Zero-altered and other regression models for count data with added zeros. Biom. J. 1994, 36, 531–547. [Google Scholar] [CrossRef]
- Ghosh, S.K.; Kim, H. Semiparametric inference based on a class of zero-altered distributions. Stat. Methodol. 2007, 4, 371–383. [Google Scholar] [CrossRef][Green Version]
- Chen, M.H.; Ibrahim, J.G. Conjugate priors for generalized linear models. Stat. Sin. 2003, 30, 461–476. [Google Scholar]
- Gupta, M.; Ibrahim, J.G. An information matrix prior for Bayesian analysis in generalized linear models with high dimensional data. Stat. Sin. 2009, 19, 1641–1663. [Google Scholar]
- Bové, D.S.; Held, L. Hyper-g priors for generalized linear models. Bayesian Anal. 2011, 6, 387–410. [Google Scholar]
- Kass, R.E.; Wasserman, L. A reference Bayesian test for nested hypotheses and its relationship to the Schwarz criterion. J. Am. Stat. Assoc. 1995, 90, 928–934. [Google Scholar] [CrossRef]
- Hansen, M.H.; Yu, B. Minimum description length model selection criteria for generalized linear models. Lect. Notes Monogr. Ser. 2003, 40, 145–163. [Google Scholar]
- Wang, X.; George, E.I. Adaptive Bayesian criteria in variable selection for generalized linear models. Stat. Sin. 2007, 17, 667–690. [Google Scholar]
- Marin, J.M.; Robert, C. Bayesian Core: A Practical Approach to Computational Bayesian Statistics; Springer Texts in Statistics: New York, NY, USA, 2007. [Google Scholar]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Roberts, G.O.; Gelman, A.; Gilks, W.R. Weak convergence and optimal scaling of random walk Metropolis algorithms. Ann. Appl. Probab. 1997, 7, 110–120. [Google Scholar] [CrossRef]
- Heidelberger, P.; Welch, P.D. Simulation run length control in the presence of an initial transient. Oper. Res. 1983, 31, 1109–1144. [Google Scholar] [CrossRef]
- Geweke, J. Evaluating the accuracy of sampling-based approaches to the calculation of posterior moments. Bayesian Stat. 1992, 4, 641–649. [Google Scholar]
- Brooks, S.P.; Gelman, A. General methods for monitoring convergence of iterative simulations. J. Comput. Graph. Stat. 1998, 7, 434–455. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Hörmann, W.; Leydold, J.; Derflinger, G. Automatic Nonuniform Random Variate Generation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Heimers, A.; Brede, H.J.; Giesen, U.; Hoffmann, W. Chromosome aberration analysis and the influence of mitotic delay after simulated partial-body exposure with high doses of sparsely and densely ionising radiation. Radiat. Environ. Biophys. 2006, 45, 45–54. [Google Scholar] [CrossRef]
- Csiszár, I. Information-type measures of difference of probability distributions and indirect observations. Stud. Sci. Math. Hung. 1967, 2, 299–318. [Google Scholar]
- Peng, F.; Dey, D.K. Bayesian analysis of outlier problems using divergence measures. Can. J. Stat. 1995, 23, 199–213. [Google Scholar] [CrossRef]
- Cho, H.; Ibrahim, J.G.; Sinha, D.; Zhu, H. Bayesian case influence diagnostics for survival models. Biometrics 2009, 65, 116–124. [Google Scholar] [CrossRef] [PubMed]
- Geisser, S.; Eddy, W.F. A predictive approach to model selection. J. Am. Stat. Assoc. 1979, 74, 153–160. [Google Scholar] [CrossRef]
- Congdon, P. Bayesian Models for Categorical Data; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Weiss, R. An approach to Bayesian sensitivity analysis. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 739–750. [Google Scholar] [CrossRef]
- McCulloch, R.E. Local model influence. J. Am. Stat. Assoc. 1989, 84, 473–478. [Google Scholar] [CrossRef]
- Brooks, S.P. Discussion on the paper by Spiegelhalter, Best, Carlin, and van der Linde. J. R. Stat. Soc. Ser. B Stat. Methodol. 2002, 64, 616–639. [Google Scholar]
- Carlin, B.P.; Louis, T.A. Bayes and Empirical Bayes Methods for Data Analysis; Chapman & Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman & Hall/CRC Texts in Statistical Science; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Rubin, D.B. Bayesianly justifiable and relevant frequency calculations for the applied statistician. Ann. Stat. 1984, 12, 1151–1172. [Google Scholar] [CrossRef]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Moral, R.A.; Hinde, J.; Demétrio, C.G.B. Half-Normal plots and overdispersed models in R: The hnp package. J. Stat. Softw. 2017, 81, 1–23. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).