
Message Passing-Based Inference for Time-Varying Autoregressive Models


Abstract
:1. Introduction
2. Model Specification and Problem Definition
2.1. Model Specification
2.2. Problem Definition
3. Inference in TVAR Models
3.1. Bayesian Evidence as a Model Performance Criterion
3.2. Inference as a Prediction-Correction Process
4. Factor Graphs and Message Passing-Based Inference
4.1. Forney-Style Factor Graphs
4.2. Free Energy and Variational Message Passing
5. Variational Message Passing for TVAR Models
5.1. Message Passing-Based Inference in the TVAR Model
5.2. Intractable Messages and the Composite AR Node
5.3. VMP Update Rules for the Composite AR Node
6. Experiments
6.1. Verification on a Synthetic Data Set
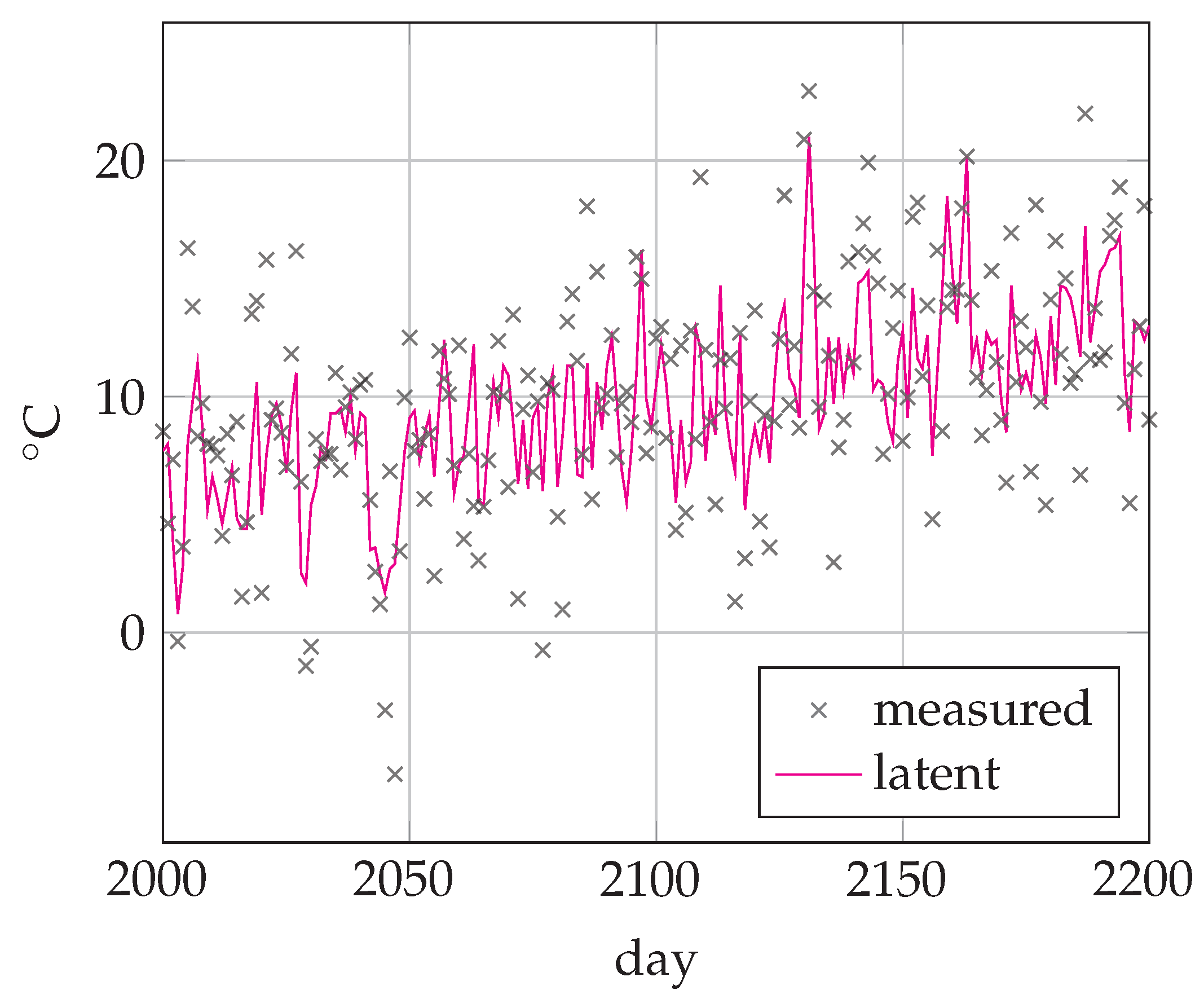
6.2. Temperature Modeling
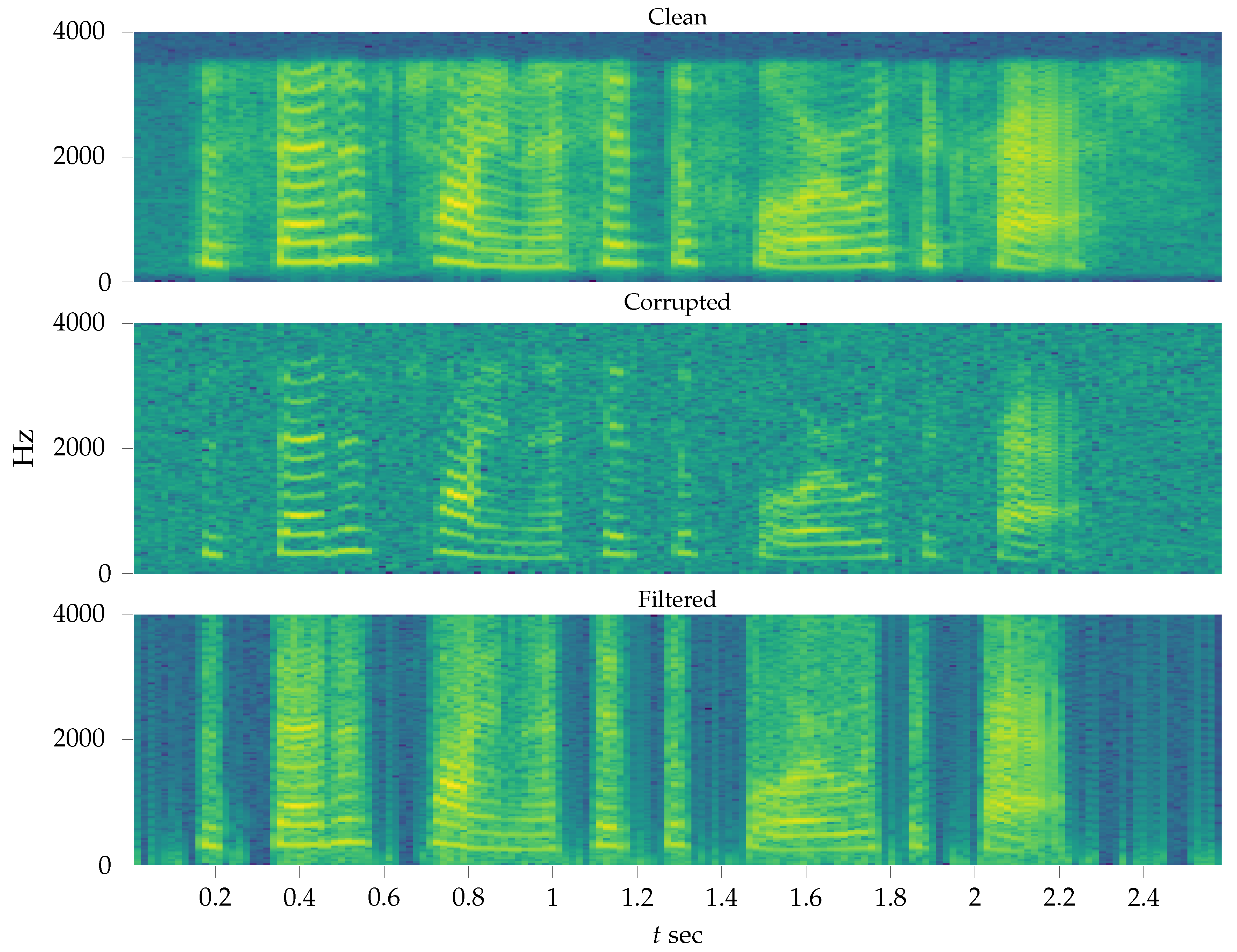
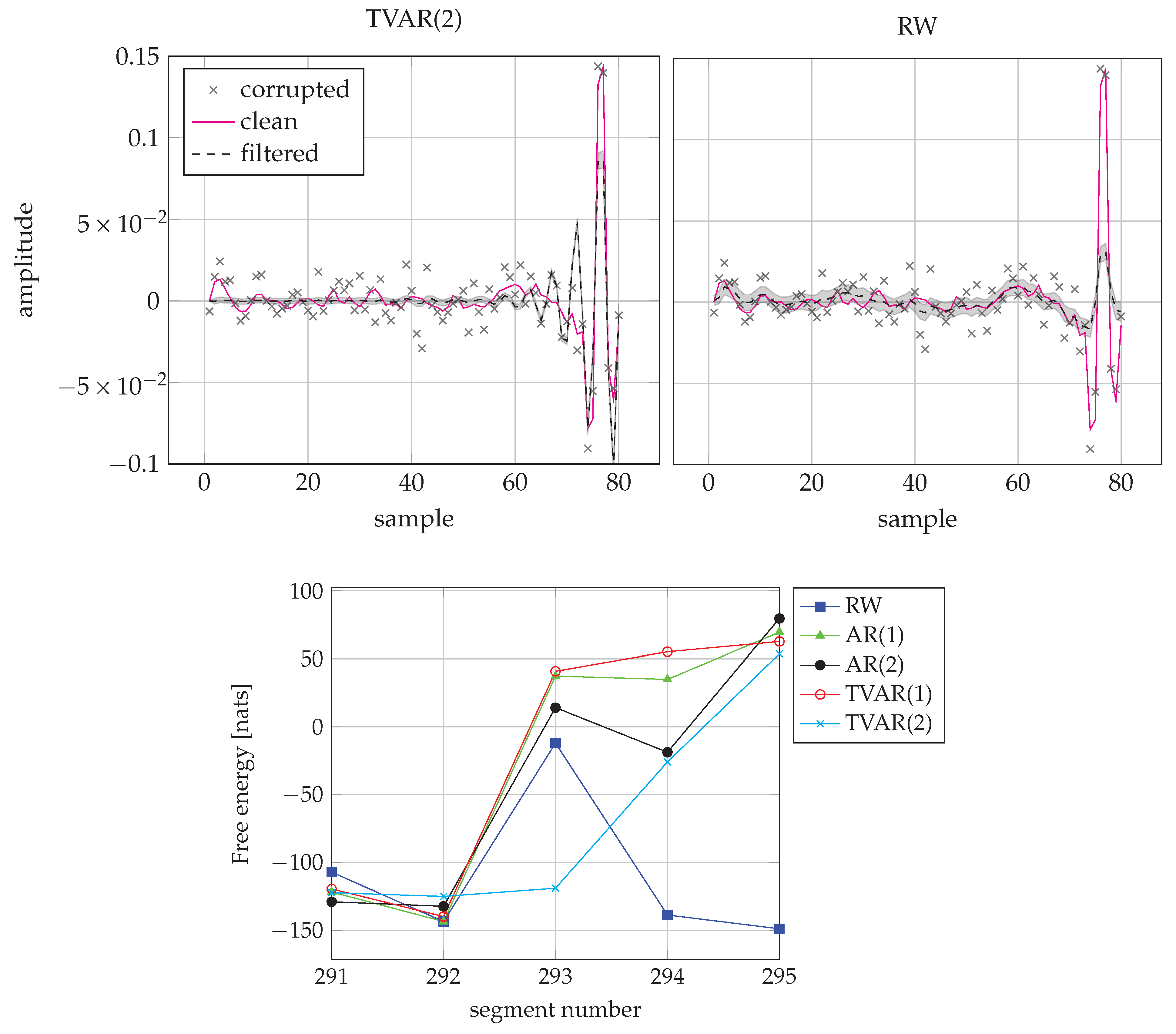
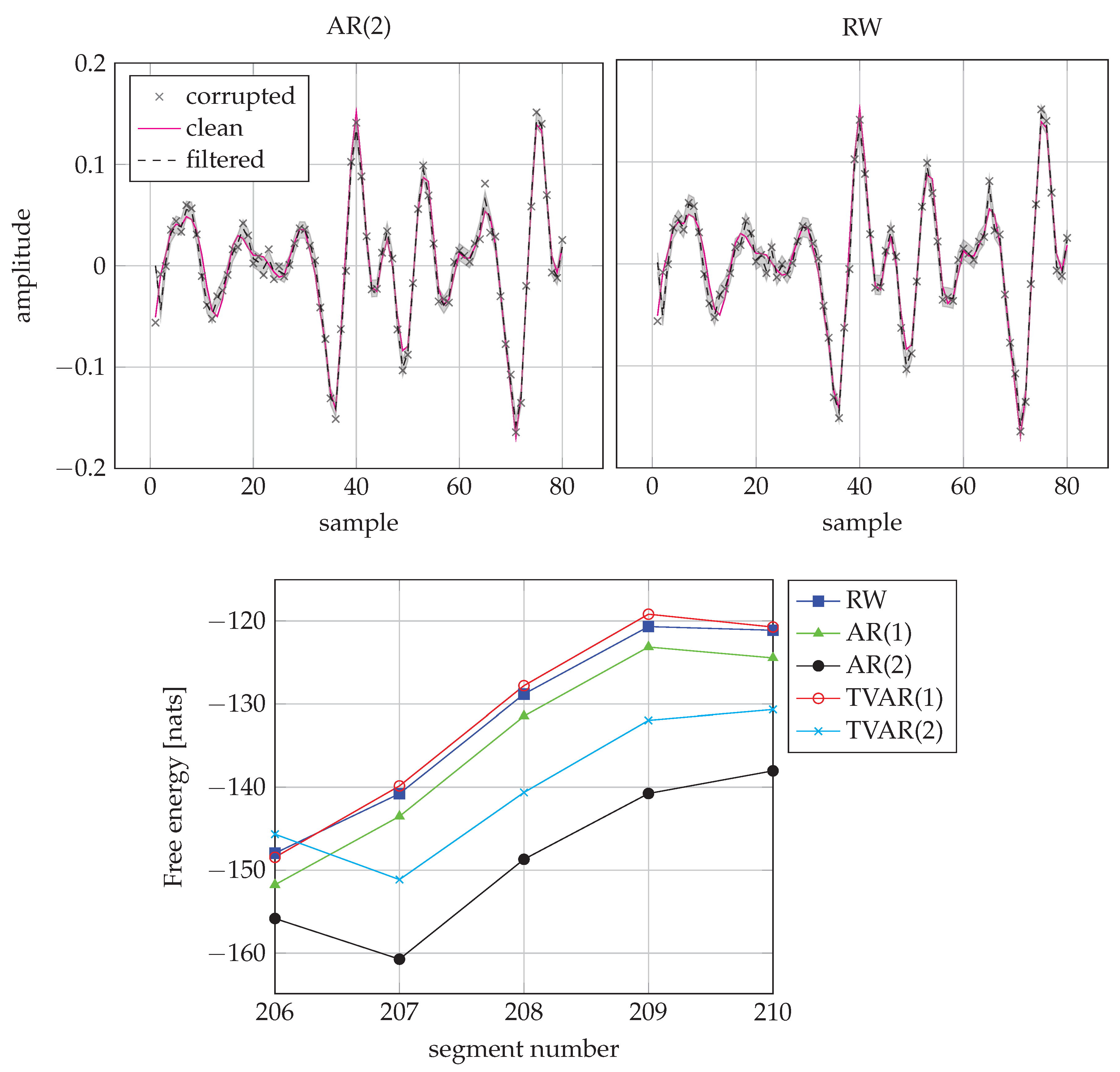
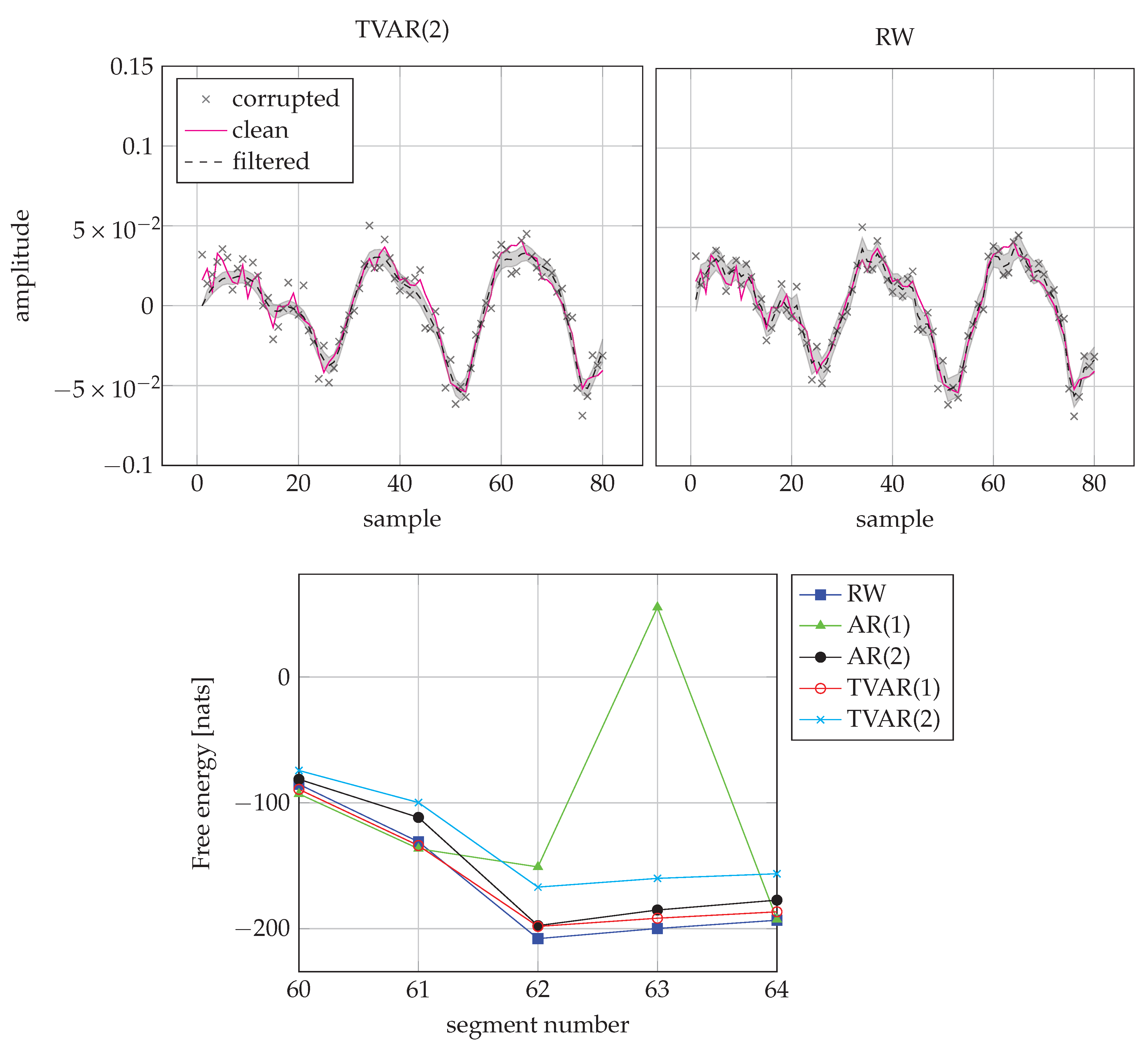
6.3. Single-Channel Speech Enhancement
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Derivations

Appendix A.1. Structural Variational Message Passing

- (1)
- compute outgoing messages , :
- (2)
- update joint posterior :
- (3)
- compute the outgoing message :
- (4)
- update posterior :
Appendix A.2. Auxiliary Node Function
Appendix A.3. Update of Message to y
Appendix A.4. Update of Message to x
Appendix A.5. Update of Message to θ
Appendix A.6. Update of Message to γ
- I:
- II:
- III:
- and
- IV:
Appendix A.7. Derivation of q(x,y)
Appendix A.8. Free Energy Derivations
- I:
- II:
References
- Akaike, H. Fitting autoregressive models for prediction. Ann. Inst. Stat. Math. 1969, 21, 243–247. [Google Scholar] [CrossRef]
- Charbonnier, R.; Barlaud, M.; Alengrin, G.; Menez, J. Results on AR-modelling of nonstationary signals. Signal Process. 1987, 12, 143–151. [Google Scholar] [CrossRef]
- Tahir, S.M.; Shaameri, A.Z.; Salleh, S.H.S. Time-varying autoregressive modeling approach for speech segmentation. In Proceedings of the Sixth International Symposium on Signal Processing and its Applications (Cat.No.01EX467), Kuala Lumpur, Malaysia, 13–16 August 2001; Volume 2, pp. 715–718. [Google Scholar] [CrossRef]
- Rudoy, D.; Quatieri, T.F.; Wolfe, P.J. Time-Varying Autoregressions in Speech: Detection Theory and Applications. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 977–989. [Google Scholar] [CrossRef] [Green Version]
- Chu, Y.J.; Chan, S.C.; Zhang, Z.G.; Tsui, K.M. A new regularized TVAR-based algorithm for recursive detection of nonstationarity and its application to speech signals. In Proceedings of the 2012 IEEE Statistical Signal Processing Workshop (SSP), Ann Arbor, MI, USA, 5–8 August 2012; pp. 361–364. [Google Scholar] [CrossRef] [Green Version]
- Paulik, M.J.; Mohankrishnan, N.; Nikiforuk, M. A time varying vector autoregressive model for signature verification. In Proceedings of the 1994 37th Midwest Symposium on Circuits and Systems, Lafayette, LA, USA, 3–5 August 1994; Volume 2, pp. 1395–1398. [Google Scholar] [CrossRef]
- Kostoglou, K.; Robertson, A.D.; MacIntosh, B.J.; Mitsis, G.D. A Novel Framework for Estimating Time-Varying Multivariate Autoregressive Models and Application to Cardiovascular Responses to Acute Exercise. IEEE Trans. Biomed. Eng. 2019, 66, 3257–3266. [Google Scholar] [CrossRef]
- Eom, K.B. Analysis of Acoustic Signatures from Moving Vehicles Using Time-Varying Autoregressive Models. Multidimens. Syst. Signal Process. 1999, 10, 357–378. [Google Scholar] [CrossRef]
- Abramovich, Y.I.; Spencer, N.K.; Turley, M.D.E. Time-Varying Autoregressive (TVAR) Models for Multiple Radar Observations. IEEE Trans. Signal Process. 2007, 55, 1298–1311. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.G.; Hung, Y.S.; Chan, S.C. Local Polynomial Modeling of Time-Varying Autoregressive Models With Application to Time–Frequency Analysis of Event-Related EEG. IEEE Trans. Biomed. Eng. 2011, 58, 557–566. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Bai, L.; Xu, J.; Fei, W. EEG recognition through Time-varying Vector Autoregressive Model. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 292–296. [Google Scholar] [CrossRef]
- Sharman, K.; Friedlander, B. Time-varying autoregressive modeling of a class of nonstationary signals. In Proceedings of the ICASSP’84—IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, CA, USA, 19–21 March 1984; Volume 9, pp. 227–230. [Google Scholar] [CrossRef]
- Reddy, G.R.S.; Rao, R. Non stationary signal prediction using TVAR model. In Proceedings of the 2014 International Conference on Communication and Signal Processing, Bangkok, Thailand, 10–12 October 2014; pp. 1692–1697. [Google Scholar] [CrossRef]
- Souza, D.B.d.; Kuhn, E.V.; Seara, R. A Time-Varying Autoregressive Model for Characterizing Nonstationary Processes. IEEE Signal Process. Lett. 2019, 26, 134–138. [Google Scholar] [CrossRef]
- Zheng, Y.; Lin, Z. Time-varying autoregressive system identification using wavelets. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing (Cat. No.00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 1, pp. 572–575. [Google Scholar] [CrossRef]
- Moon, T.K.; Gunther, J.H. Estimation of Autoregressive Parameters from Noisy Observations Using Iterated Covariance Updates. Entropy 2020, 22, 572. [Google Scholar] [CrossRef]
- Rajan, J.J.; Rayner, P.J.W.; Godsill, S.J. Bayesian approach to parameter estimation and interpolation of time-varying autoregressive processes using the Gibbs sampler. IEE Proc. Vis. Image Signal Process. 1997, 144, 249–256. [Google Scholar] [CrossRef] [Green Version]
- Prado, R.; Huerta, G.; West, M. Bayesian tIme-Varying Autoregressions: Theory, Methods and Applications; University of Sao Paolo: Sao Paulo, Brazil, 2000; p. 2000. [Google Scholar]
- Nakajima, J.; Kasuya, M.; Watanabe, T. Bayesian analysis of time-varying parameter vector autoregressive model for the Japanese economy and monetary policy. J. Jpn. Int. Econ. 2011, 25, 225–245. [Google Scholar] [CrossRef] [Green Version]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Zhong, X.; Song, S.; Pei, C. ime-varying Parameters Estimation based on Kalman Particle Filter with Forgetting Factors. In Proceedings of the EUROCON 2005—The International Conference on “Computer as a Tool”, Belgrade, Serbia, 21–24 November 2005; Volume 2, pp. 1558–1561. [Google Scholar] [CrossRef]
- Winn, J.; Bishop, C.M.; Jaakkola, T. Variational Message Passing. J. Mach. Learn. Res. 2005, 6, 661–694. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Korl, S. A Factor Graph Approach to Signal Modelling, System Identification and Filtering. Ph.D. Thesis, Swiss Federal Institute of Technology, Zurich, Switzerland, 2005. [Google Scholar]
- Penny, W.D.; Roberts, S.J. Bayesian multivariate autoregressive models with structured priors. IEE Proc. Vis. Image Signal Process. 2002, 149, 33–41. [Google Scholar] [CrossRef]
- Loeliger, H.A.; Dauwels, J.; Hu, J.; Korl, S.; Ping, L.; Kschischang, F.R. The Factor Graph Approach to Model-Based Signal Processing. Proc. IEEE 2007, 95, 1295–1322. [Google Scholar] [CrossRef] [Green Version]
- Dauwels, J.; Korl, S.; Loeliger, H.A. Expectation maximization as message passing. Int. Symp. Inf. Theory 2005, 583–586. [Google Scholar] [CrossRef] [Green Version]
- Cox, M.; van de Laar, T.; de Vries, B. A factor graph approach to automated design of Bayesian signal processing algorithms. Int. J. Approx. Reason. 2019, 104, 185–204. [Google Scholar] [CrossRef] [Green Version]
- De Vries, B.; Friston, K.J. A Factor Graph Description of Deep Temporal Active Inference. Front. Comput. Neurosci. 2017, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beck, J. Bayesian system identification based on probability logic. Struct. Control. Health Monit. 2010. [Google Scholar] [CrossRef]
- Zhang, D.; Song, X.; Wang, W.; Fettweis, G.; Gao, X. Unifying Message Passing Algorithms Under the Framework of Constrained Bethe Free Energy Minimization. arXiv 2019, arXiv:1703.10932v3. [Google Scholar]
- Dauwels, J. On Variational Message Passing on Factor Graphs. In Proceedings of the IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 2546–2550. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Wang, W.; Fettweis, G.; Gao, X. Unifying Message Passing Algorithms Under the Framework of Constrained Bethe Free Energy Minimization. arXiv 2017, arXiv:1703.10932. [Google Scholar]
- Cui, G.; Yu, X.; Iommelli, S.; Kong, L. Exact Distribution for the Product of Two Correlated Gaussian Random Variables. IEEE Signal Process. Lett. 2016, 23, 1662–1666. [Google Scholar] [CrossRef]
- Wu, W.-R.; Chen, P.-C. Subband Kalman filtering for speech enhancement. IEEE Trans. Circuits Syst. Analog. Digit. Process. 1998, 45, 1072–1083. [Google Scholar] [CrossRef]
- So, S.; Paliwal, K.K. Modulation-domain Kalman filtering for single-channel speech enhancement. Speech Commun. 2011, 53, 818–829. [Google Scholar] [CrossRef]
- Nossier, S.A.; Wall, J.; Moniri, M.; Glackin, C.; Cannings, N. An Experimental Analysis of Deep Learning Architectures for Supervised Speech Enhancement. Electronics 2021, 10, 17. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun. 2007, 49, 588–601. [Google Scholar] [CrossRef] [Green Version]
- Paliwal, K.; Basu, A. A speech enhancement method based on Kalman filtering. In Proceedings of the ICASSP’87—IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 6–9 April 1987; Volume 12, pp. 177–180. [Google Scholar] [CrossRef]
- You, C.H.; Rahardja, S.; Koh, S.N. Autoregressive Parameter Estimation for Kalman Filtering Speech Enhancement. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV-913–IV-916. [Google Scholar] [CrossRef]
- Grenier, Y. Time-dependent ARMA modeling of nonstationary signals. IEEE Trans. Acoust. Speech Signal Process. 1983, 31, 899–911. [Google Scholar] [CrossRef]
- Kamary, K.; Mengersen, K.; Robert, C.P.; Rousseau, J. Testing hypotheses via a mixture estimation model. arXiv 2014, arXiv:1412.2044. [Google Scholar]
- Friston, K.; Parr, T.; Zeidman, P. Bayesian model reduction. arXiv 2019, arXiv:1805.07092. [Google Scholar]
- Podusenko, A.; Kouw, W.M.; de Vries, B. Online variational message passing in hierarchical autoregressive models. In Proceedings of the 2020 IEEE International Symposium on Information Theory, Los Angeles, CA, USA, 21–26 June 2020; pp. 1337–1342. [Google Scholar]













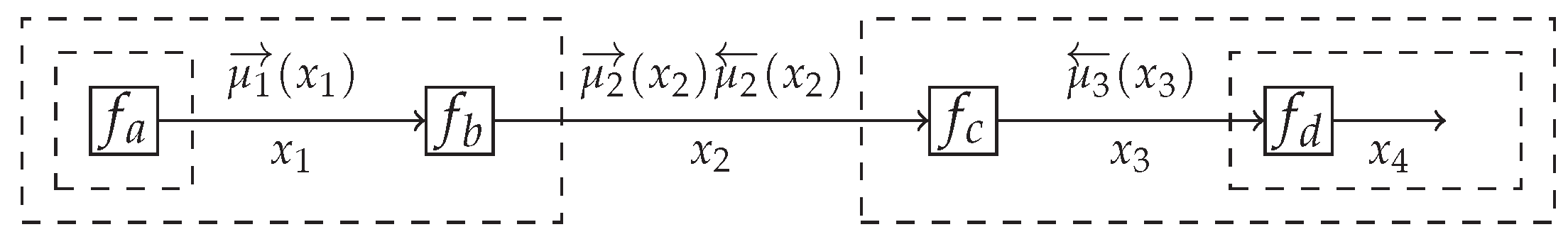{kind=link}
{kind=link}
{kind=link}
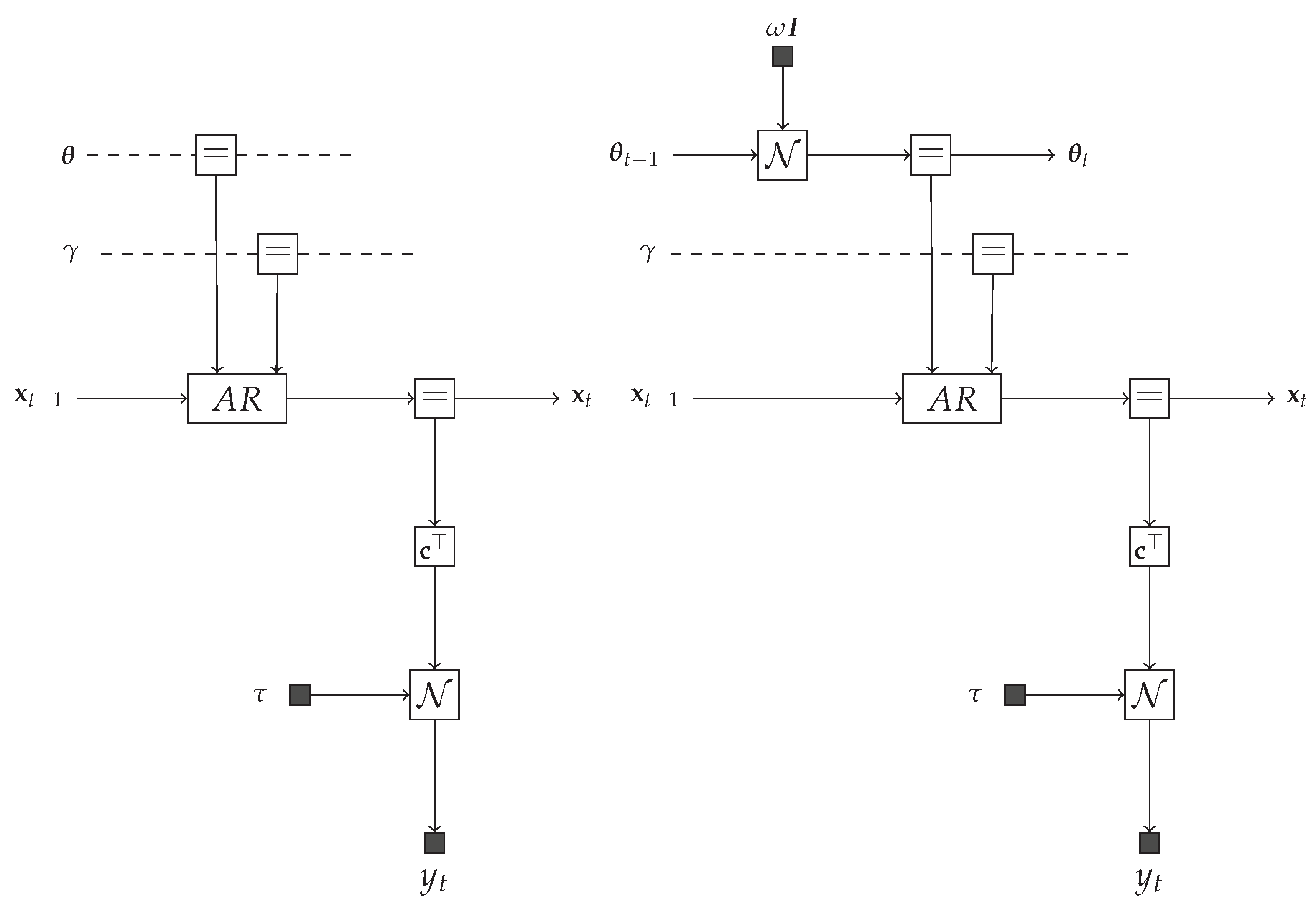{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VMP for the Composite AR Node | |
|---|---|
 | |
| Outgoing messages | Incoming messages |
| Joint marginal | |
| (Appendix A.7) | |
| Free energy | |
| Auxiliary variables | |
| RW | AR(1) | AR(2) | TVAR(1) | TVAR(2) | |
|---|---|---|---|---|---|
| Ratio | % | % | % | % | % |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Podusenko, A.; Kouw, W.M.; de Vries, B. Message Passing-Based Inference for Time-Varying Autoregressive Models. Entropy 2021, 23, 683. https://doi.org/10.3390/e23060683
Podusenko A, Kouw WM, de Vries B. Message Passing-Based Inference for Time-Varying Autoregressive Models. Entropy. 2021; 23(6):683. https://doi.org/10.3390/e23060683
Chicago/Turabian StylePodusenko, Albert, Wouter M. Kouw, and Bert de Vries. 2021. "Message Passing-Based Inference for Time-Varying Autoregressive Models" Entropy 23, no. 6: 683. https://doi.org/10.3390/e23060683
APA StylePodusenko, A., Kouw, W. M., & de Vries, B. (2021). Message Passing-Based Inference for Time-Varying Autoregressive Models. Entropy, 23(6), 683. https://doi.org/10.3390/e23060683