
Subjective and Objective Quality Assessments of Display Products †


Abstract
:1. Introduction
2. Subjective Quality Assessment of Display Products
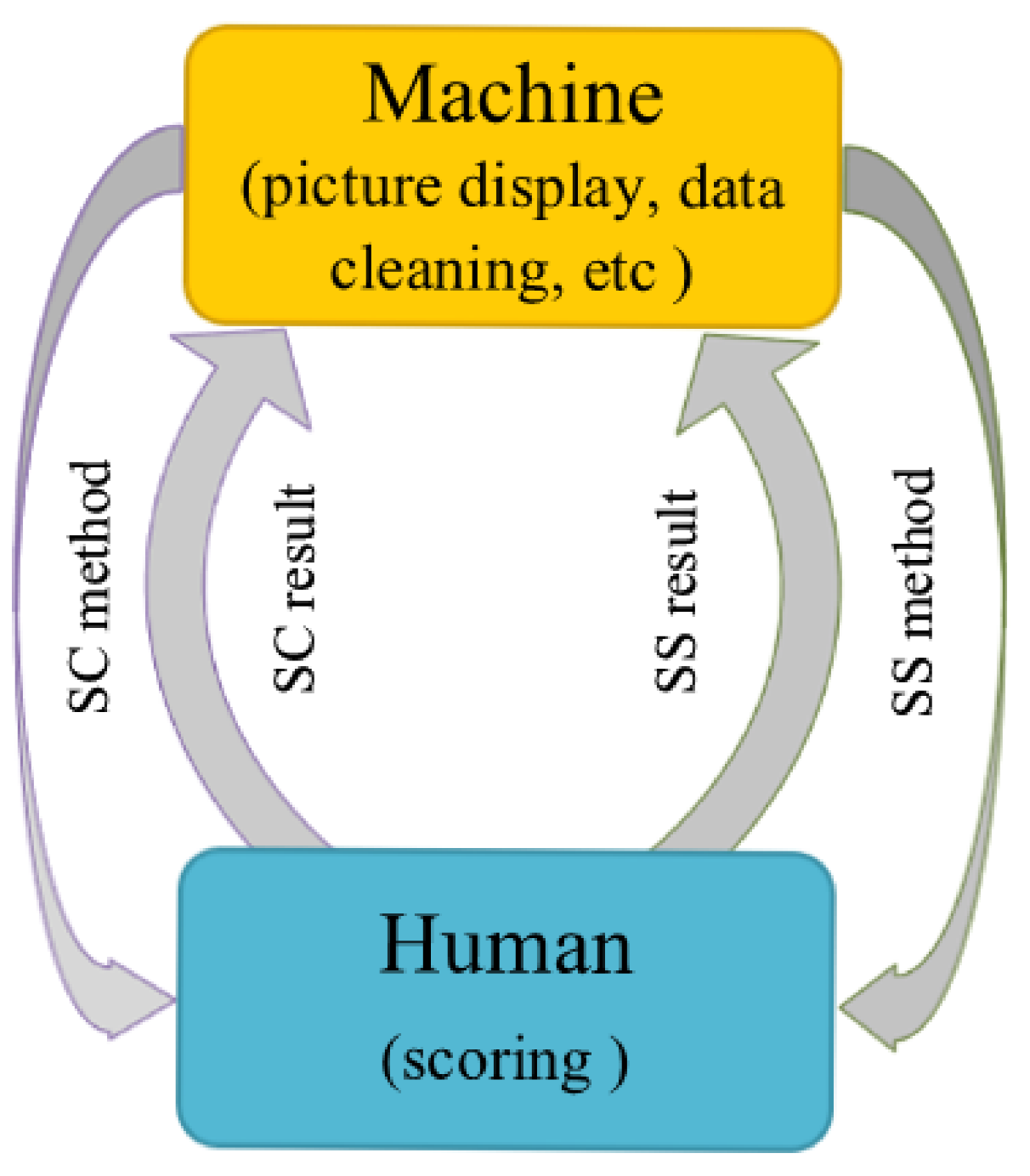
2.1. Mutually Supervised Subjective Evaluation
2.2. Protocol of Subjective Quality Assessment Experiment
- We fix the two mobile phone screens to the background cardboard and keep them as the same as possible, as shown in Figure 2;
- During this test, the ambient light condition is sufficient and steady. The light condition is kept the same in the whole screen, for avoiding the impacts caused by the environment;
- Under the condition that the backlight current is set to 30 mA and the power consumption of the two products is kept the same, we adjust the color temperature of RGBW to be close to that of RGB;
- The participants are kept at a distance of 30 cm from the phone screen and located in front of the screen to prevent the results from being affected by side-looking.
- Conducting the SS method by asking the observers to score the pictures displayed on screen A and B. The time during assessing each picture is 20 s. The range of score is from 1 to 5;
- Conducting the SC method by asking the observers to compare the same picture displayed on two different screens (A and B). The observers are requested to decide which screen has better display effect or whether the two screens have equivalent display effect. The time during assessing each picture is 20 s as well;
- Each participant observes the same number of pictures at the same time before gives their subjective scores.
- Cross-test-based data cleaning: Abnormal data were cleaned based on the comparison of SS’s results and SC’s results. If the score of SS method is opposite to that of SC method, the relevant data will be discarded.
- Cross-content-based data cleaning: Considering the different contents of pictures, this paper independently analyzes each picture and cleans the outliers in each picture. According to the results of SS method, the average score and 95% confidence interval of each picture are derived. Unreasonable scores outside the interval are deleted according to the method in [24].
- Cross-evaluator-based data cleaning: After completing the above two data cleaning methods, it is required to exclude the subjective scores of special testers. When more than 20% of data provided by a single participant are discarded, that participant is considered to be “careless” during the test or his/her hobbies deviate from the public. If so, all of the data of the participant are deleted.
2.3. Subjective Assessment Experimental Results
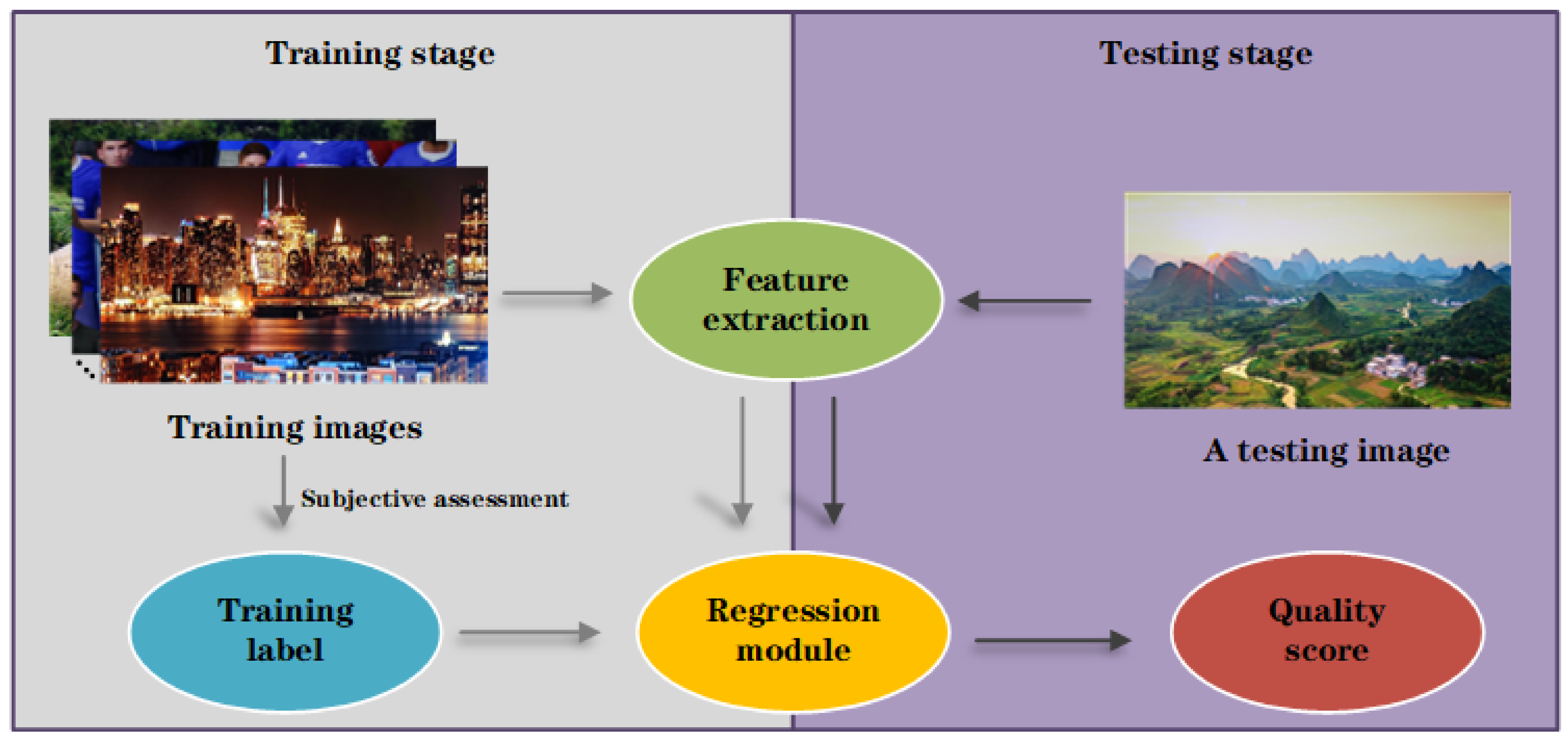
3. Objective Quality Assessment of Display Products
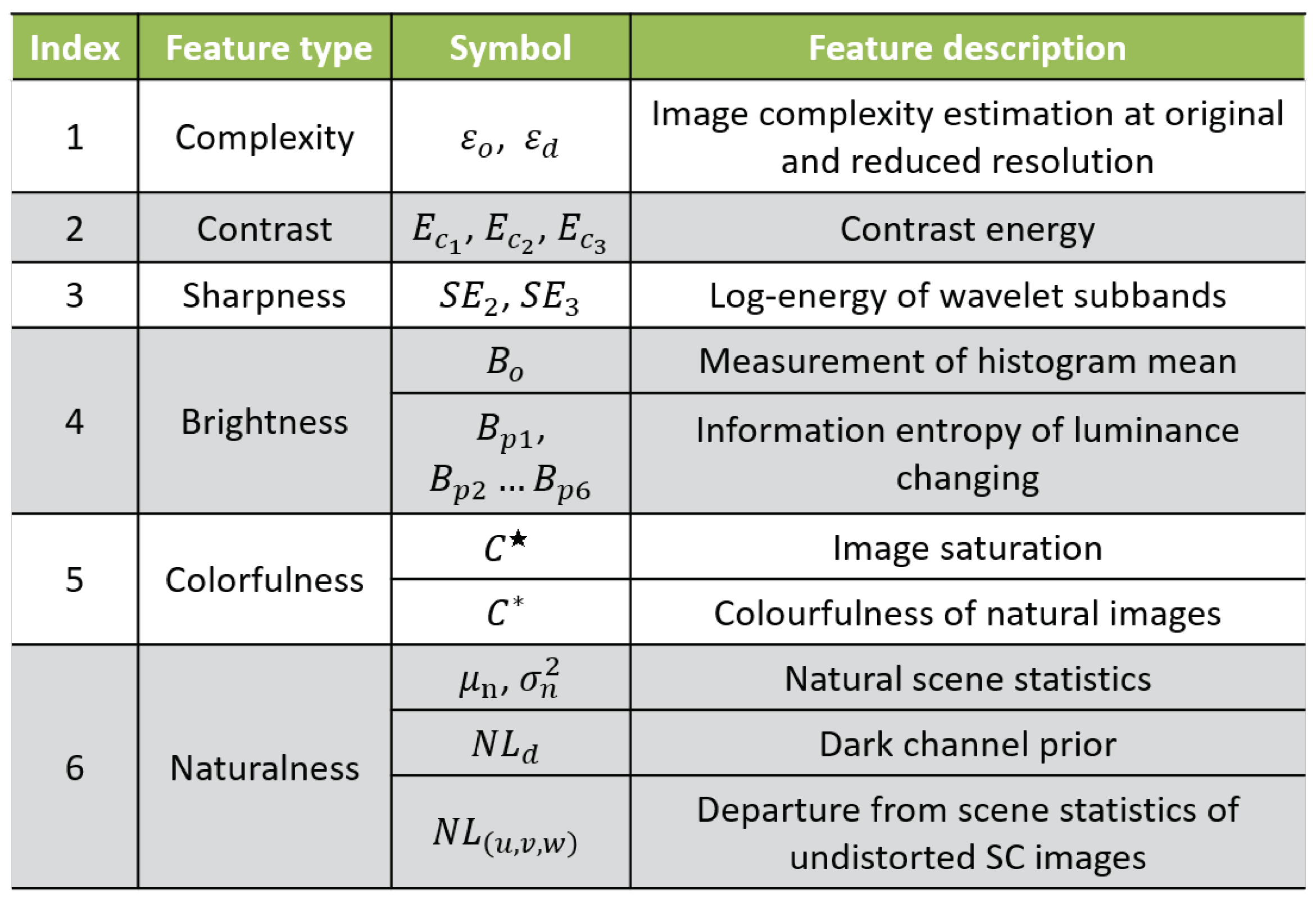
3.1. Feature Extraction
3.2. Regression Module
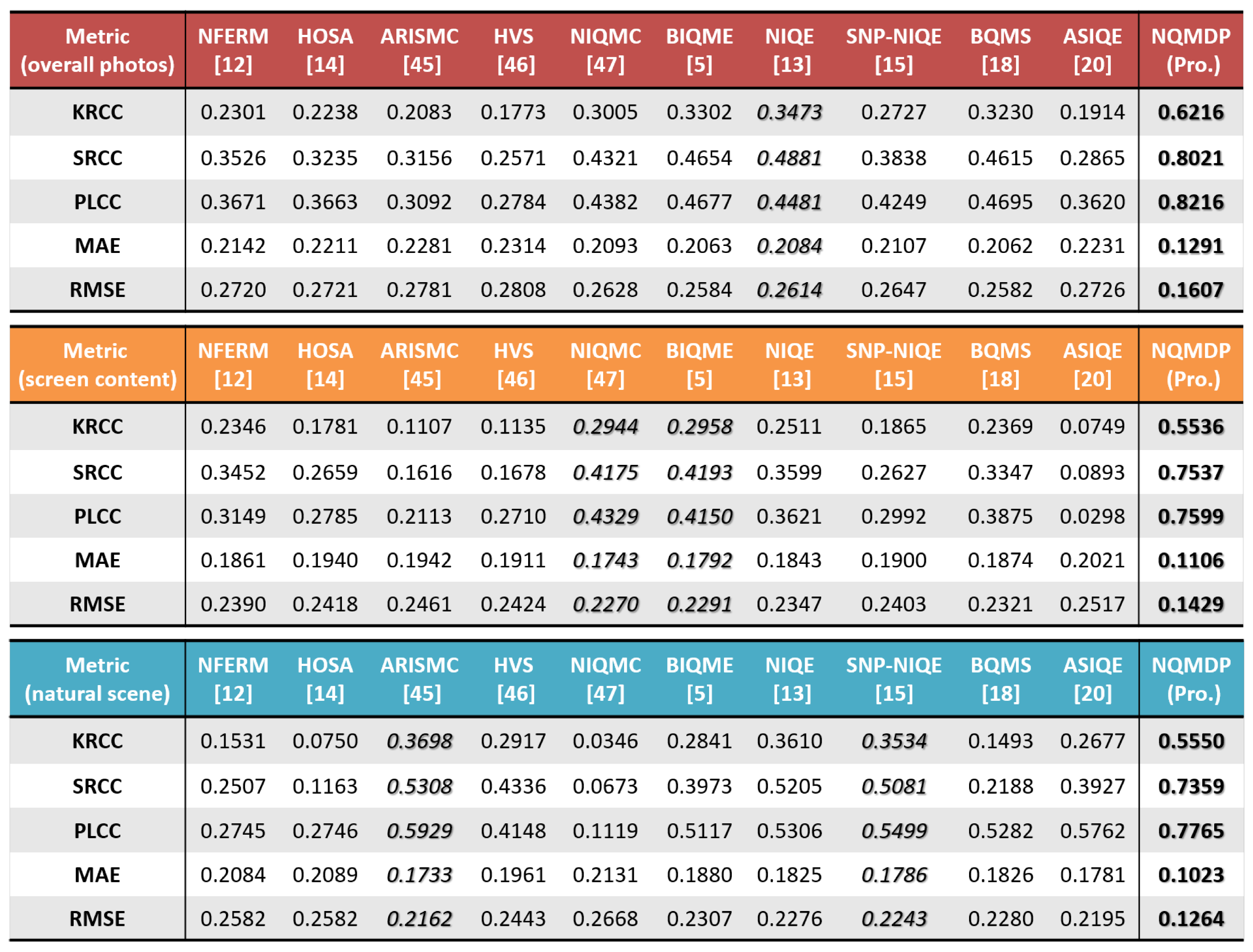
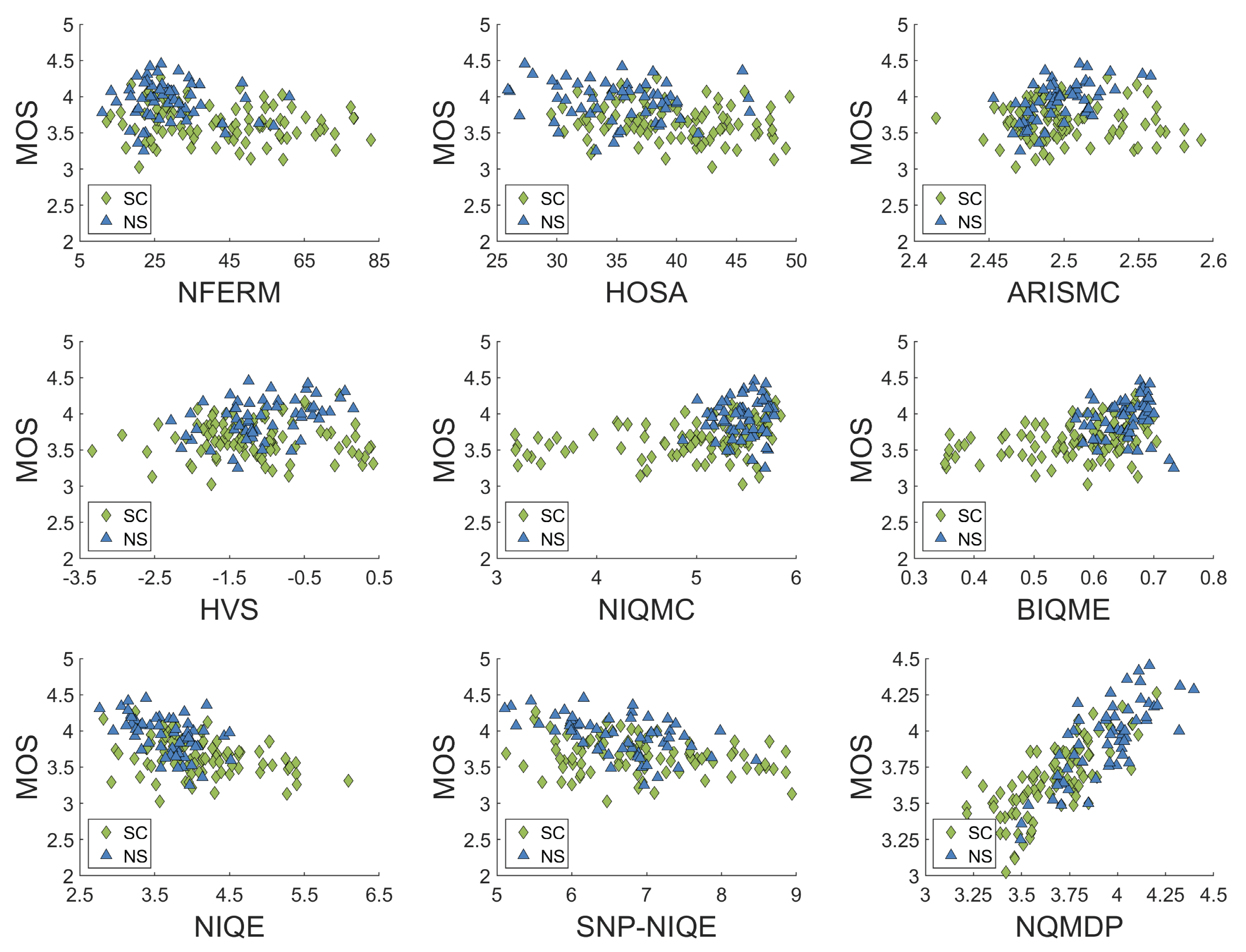
4. Experiments and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saupe, D.; Hahn, F.; Hosu, V.; Zingman, I.; Rana, M.; Li, S. Crowd workers proven useful: A comparative study of subjective video quality assessment. In Proceedings of the QoMEX 2016: 8th International Conference on Quality of Multimedia Experience, Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Liu, A.; Lin, W.; Narwaria, M. Image quality assessment based on gradient similarity. IEEE Trans. Image Process. 2012, 21, 1500–1512. [Google Scholar] [PubMed]
- Yue, G.; Hou, C.; Gu, K. Biologically inspired blind quality assessment of tone-mapped images. IEEE Trans. Ind. Electron. 2018, 65, 2525–2536. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W. Using free energy principle for blind image quality assessment. IEEE Trans. Multimed. 2015, 17, 50–63. [Google Scholar] [CrossRef]
- Zhai, G.; Wu, X.; Yang, X.; Lin, X.; Lin, W.; Zhang, W. A psychovisual quality metric in free-energy principle. IEEE Trans. Image Process. 2012, 21, 41–52. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Lin, W.; Liu, M. The analysis of image contrast:from quality assessment to automatic enhancement. IEEE Trans. Cybern. 2016, 46, 284–297. [Google Scholar] [CrossRef]
- Gu, K.; Lin, W.; Zhai, G.; Yang, X.; Zhang, W.; Chen, C.W. No-Reference Quality Metric of Contrast-Distorted Images Based on Information Maximization. IEEE Trans. Cybern. 2017, 47, 4559–4565. [Google Scholar] [CrossRef]
- Gu, K.; Zhou, J.; Qiao, J.-F.; Zhai, G.; Lin, W.; Bovik, A.C. No-Reference Quality Assessment of Screen Content Pictures. IEEE Trans. Image Process. 2017, 26, 4005–4018. [Google Scholar] [CrossRef]
- Yang, H.; Fang, Y.; Lin, W. Perceptual quality assessment of screen content images. IEEE Trans. Image Process. 2015, 24, 4408–4421. [Google Scholar] [CrossRef]
- Gu, K.; Wang, S.; Yang, H.; Lin, W.; Zhai, G.; Yang, X.; Zhang, W. Saliency-Guided Quality Assessment of Screen Content Images. IEEE Trans. Multimed. 2016, 18, 1098–1110. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Xu, J.; Ye, P.; Li, Q.; Du, H.; Liu, Y.; Doermann, D. Blind image quality assessment based on high order statistics aggregation. IEEE Trans. Image Process. 2016, 25, 4444–4457. [Google Scholar] [CrossRef]
- Xu, J.; Ye, P.; Li, Q.; Du, H.; Liu, Y.; Doermann, D. Unsupervised blind image quality evaluation via statistical measurements of structure, naturalness, and perception. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 929–943. [Google Scholar]
- Gu, K.; Qiao, J.; Min, X.; Yue, G.; Lin, W.; Thalmann, D. Evaluating quality of screen content images via structural variation analysis. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2689–2701. [Google Scholar] [CrossRef] [PubMed]
- Ni, Z.; Ma, L.; Zeng, H.; Chen, J.; Cai, C.; Ma, K.K. ESIM: Edge similarity for screen content image quality assessment. IEEE Trans. Image Process. 2017, 26, 4818–4831. [Google Scholar] [CrossRef] [PubMed]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. Learning a blind quality evaluation engine of screen content images. Neurocomputing 2016, 196, 140–149. [Google Scholar] [CrossRef] [Green Version]
- Min, X.; Ma, K.; Guangtao, Z.; Zhai, G.; Wang, Z.; Lin, W. Unified Blind Quality Assessment of Compressed Natural, Graphic, and Screen Content Images. IEEE Trans. Image Process. 2017, 26, 5462–5474. [Google Scholar] [CrossRef]
- Gu, K.; Tao, D.; Qiao, J.F.; Lin, W. Learning a No-Reference Quality Assessment Model of Enhanced Images With Big Data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1301–1313. [Google Scholar] [CrossRef] [Green Version]
- Series, B.T. Methodology for the subjective assessment of the quality of television pictures. Recomm. ITU-R BT 2012, 2012, 500–513. [Google Scholar]
- Chen, K.T.; Wu, C.C.; Chang, Y.C.; Lei, C.L. A crowdsourceable QoE evaluation framework for multimedia content. In Proceedings of the 17th ACM International Conference on Multimedia, Nice, France, 21–25 October 2009; pp. 491–500. [Google Scholar]
- Zhang, J.-J.; Li, S.-M.; Wei, J.-J.; Za, Y.-J. Subjective quality evaluation method of stereo image. Acta Photonica Sin. 2012, 41, 602–607. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A. A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef] [PubMed]
- Varga, D. No-Reference Image Quality Assessment with Global Statistical Features. J. Imaging 2021, 7, 29. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features. J. Imaging 2020, 6, 75. [Google Scholar] [CrossRef]
- Oszust, M. No-Reference Image Quality Assessment Using Image Statistics and Robust Feature Descriptors. IEEE Signal Process. Lett. 2017, 24, 1656–1660. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. Visual Saliency Detection with Free Energy Theory. IEEE Signal Process. Lett. 2015, 22, 1552–1555. [Google Scholar] [CrossRef]
- Wu, J.; Lin, W.; Shi, G.; Wang, X.; Li, F. Pattern Masking Estimation in Image with Structural Uncertainty. IEEE Trans. Image Process. 2013, 22, 4892–4904. [Google Scholar] [CrossRef]
- Stromeyer, C.F.; Julesz, B.; Iii, C.F.S. Spatial-Frequency Masking in Vision: Critical Bands and Spread of Masking*. J. Opt. Soc. Am. 1972, 62, 1221–1232. [Google Scholar] [CrossRef]
- De Valois, R.L.; Albrecht, D.G.; Thorell, L. Spatial frequency selectivity of cells in macaque visual cortex. Vis. Res. 1982, 22, 545–559. [Google Scholar] [CrossRef]
- Heeger, D.J. Normalization of cell responses in cat striate cortex. Vis. Neurosci. 1992, 9, 181–197. [Google Scholar] [CrossRef]
- Vu, P.V.; Chandler, D.M. A Fast Wavelet-Based Algorithm for Global and Local Image Sharpness Estimation. IEEE Signal Process. Lett. 2012, 19, 423–426. [Google Scholar] [CrossRef]
- Gu, K.; Wang, S.; Zhai, G.; Ma, S.; Yang, X.; Lin, W.; Zhang, W.; Gao, W. Blind Quality Assessment of Tone-Mapped Images Via Analysis of Information, Naturalness, and Structure. IEEE Trans. Multimed. 2016, 18, 432–443. [Google Scholar] [CrossRef]
- Hasler, D.; Suesstrunk, S.E. Measuring colorfulness in natural images. In Human Vision and Electronic Imaging VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2003; Volume 5007, pp. 87–96. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Gu, K.; Zeng, K.; Wang, Z.; Lin, W. Objective Quality Assessment and Perceptual Compression of Screen Content Images. IEEE Eng. Med. Boil. Mag. 2016, 38, 47–58. [Google Scholar] [CrossRef] [PubMed]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W.; Liang, L. No-reference image quality assessment metric by combining free energy theory and structural degradation model. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Saad, M.A.; Bovik, A.; Charrier, C. Blind Image Quality Assessment: A Natural Scene Statistics Approach in the DCT Domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef]
- Zhang, Y.; Moorthy, A.K.; Chandler, D.M.; Bovik, A. C-DIIVINE: No-reference image quality assessment based on local magnitude and phase statistics of natural scenes. Signal Process. Image Commun. 2014, 29, 725–747. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. No-reference image sharpness assessment in autoregressive parameter space. IEEE Trans. Image Process. 2015, 24, 3218–3231. [Google Scholar]
- Hosseini, M.S.; Zhang, Y.; Plataniotis, K. Encoding Visual Sensitivity by MaxPol Convolution Filters for Image Sharpness Assessment. IEEE Trans. Image Process. 2019, 28, 4510–4525. [Google Scholar] [CrossRef] [Green Version]
- VQEG: Final Report from the Video Quality Experts Group on the Validation of Objective Models of Video Quality Assessment, [EB/OL]. 2006. Available online: https://www.its.bldrdoc.gov/vqeg/vqeg-home.aspx (accessed on 25 June 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Score | Quality | Impairment |
|---|---|---|
| 5 | Excellent | Imperceptible |
| 4 | Good | Perceptible, but not annoying |
| 3 | Fair | Slightly annoying |
| 2 | Poor | Annoying |
| 1 | Bad | Very annoying |
| Score | Condition | Explanation |
|---|---|---|
| +1 | A > B | A is better than B |
| 0 | A = B | A is equivalent to B |
| −1 | A < B | A is worse than B |
| Resolution | Luminance Peak | Contrast | Flicker | Color Temperature | Gamma | |
|---|---|---|---|---|---|---|
| BOE RGBW screen | 1080*2244 | 625.3 | 1125.4 | 0.5 | 7688.9 | 2.12 |
| BOE RGBW screen | 1080*2244 | 708.8 | 1228.4 | 0.3 | 6503.1 | 2.17 |
| Real RGB screen | 1080*1920 | 341.8 | 1393.9 | 0.5 | 7581.2 | 2.14 |
| Index | RGB | RGBW | ||
|---|---|---|---|---|
| SS | BMS | SS | BMS | |
| LCC | 0.9835 | 0.9866 | 0.9888 | 0.9933 |
| RMSE | 0.0381 | 0.0320 | 0.0311 | 0.0234 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Li, D.; Yu, Y.; Guo, N. Subjective and Objective Quality Assessments of Display Products. Entropy 2021, 23, 814. https://doi.org/10.3390/e23070814
Zhang H, Li D, Yu Y, Guo N. Subjective and Objective Quality Assessments of Display Products. Entropy. 2021; 23(7):814. https://doi.org/10.3390/e23070814
Chicago/Turabian StyleZhang, Huiqing, Donghao Li, Yibing Yu, and Nan Guo. 2021. "Subjective and Objective Quality Assessments of Display Products" Entropy 23, no. 7: 814. https://doi.org/10.3390/e23070814
APA StyleZhang, H., Li, D., Yu, Y., & Guo, N. (2021). Subjective and Objective Quality Assessments of Display Products. Entropy, 23(7), 814. https://doi.org/10.3390/e23070814