
Conflict Data Fusion in a Multi-Agent System Premised on the Base Basic Probability Assignment and Evidence Distance


Abstract
:1. Introduction
1.1. Motivation
1.2. Contributions
- It is feasible and extensible to integrate evidence theory into the MAIF system. However, D-S theory may result in counterintuitive results in highly conflicting situations. In order to address D-S conflicting information fusion in MAIF, the method based on nbBPA and evidence distance is proposed.
- In the improved MAIF method, nbBPA provides a kind of prior information to preprocess the data. The evidence distance is used to judge the difference between the bodies of evidence. The weight of each belief function is calculated according to the evidence distance so as to recalculate the revised BPA.
1.3. Organization
2. Related Work
3. Background
3.1. Dempster–Shafer Evidence Theory
3.1.1. Framework of Discernment
3.1.2. Basic Probability Assignment
3.1.3. D-S Combination Rule
3.2. Base Basic Probability Assignment
3.2.1. Base Basic Probability Assignment
3.2.2. Use the bBPA to Modify Initial BPA
3.3. Evidence Distance
3.3.1. Jousselme Evidence Distance
3.3.2. Combined Belief Function Based on Evidence Distance
3.4. Reconstructed BPA
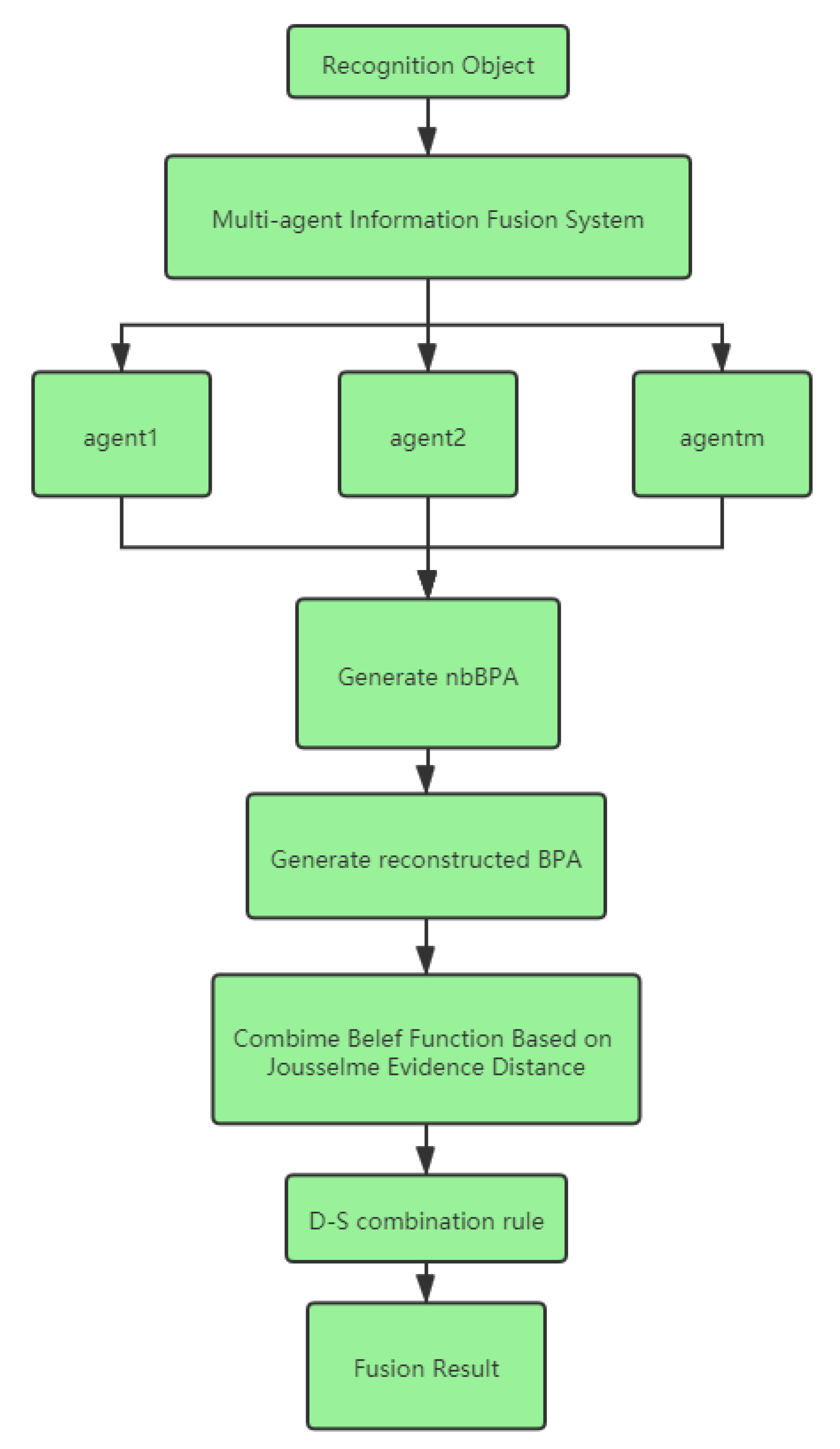
4. Multi-Agent Information Fusion
4.1. New Base BPA Definitions
- In ,, and , at least one single element is a focal element, so n = 4.
- In , and , a is the highest in the single-element subsets, so Mx(a) = 3.
- In , b is the highest in the single-element subsets, so Mx(b) = 1.
- Thus, (a) = 0.75, (b) = 0.25.
- (c) = (a,b) = (b,c) = (a,c) = (a,b,c) = 0.
4.2. Steps for Multi-Agent Information Fusion
5. Numerical Examples
5.1. Example of Disturbed Agents
5.2. Example of Real-Time Processing
5.3. Example of Setaria
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weiss, G. Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Catano, V.; Gauger, J. Information Fusion: Intelligence Centers and Intelligence Analysis; Springer: Cham, Germany, 2017. [Google Scholar]
- Xiao, F. Multi-sensor data fusion based on the belief divergence measure of evidences and the belief entropy. Inf. Fusion 2018, 46, 23–32. [Google Scholar] [CrossRef]
- Han, Y.; Deng, Y. An Evidential Fractal Analytic Hierarchy Process Target Recognition Method. Def. Sci. J. 2018, 68, 367–373. [Google Scholar] [CrossRef] [Green Version]
- Ding, B.; Wen, G.; Huang, X.; Ma, C.; Yang, X. Target Recognition in Synthetic Aperture Radar Images via Matching of Attributed Scattering Centers. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Wu, D.; Tang, Y. An improved failure mode and effects analysis method based on uncertainty measure in the evidence theory. Qual. Reliab. Eng. Int. 2020, 36, 1786–1807. [Google Scholar] [CrossRef]
- Liu, Z.G.; Pan, Q.; Dezert, J.; Martin, A. Combination of classifiers with optimal weight based on evidential reasoning. IEEE Trans. Fuzzy Syst. 2017, 26, 1217–1230. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Wu, D.; Liu, Z. A new approach for generation of generalized basic probability assignment in the evidence theory. Pattern Anal. Appl. 2021, 1–17. [Google Scholar] [CrossRef]
- Wu, D.; Liu, Z.; Tang, Y. A new classification method based on the negation of a basic probability assignment in the evidence theory. Eng. Appl. Artif. Intell. 2020, 96, 103985. [Google Scholar] [CrossRef]
- Fu, C.; Hou, B.; Chang, W.; Feng, N.; Yang, S. Comparison of evidential reasoning algorithm with linear combination in decision making. Int. J. Fuzzy Syst. 2020, 22, 686–711. [Google Scholar] [CrossRef]
- Fu, C.; Wang, Y. An interval difference based evidential reasoning approach with unknown attribute weights and utilities of assessment grades. Comput. Ind. Eng. 2015, 81, 109–117. [Google Scholar] [CrossRef]
- Xiao, F. A Multiple-Criteria Decision-Making Method Based on D Numbers and Belief Entropy. Int. J. Fuzzy Syst. 2019, 21, 1144–1153. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Najafi, S.E.; Khalaj, M. A risk-based fuzzy evidential framework for FMEA analysis under uncertainty: An interval-valued DS approach. J. Intell. Fuzzy Syst. 2018, 35, 1–12. [Google Scholar] [CrossRef]
- Xu, X.; Li, S.; Song, X.; Wen, C.; Xu, D. The optimal design of industrial alarm systems based on evidence theory. Control Eng. Pract. 2016, 46, 142–156. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, T.; Hu, G.; He, W.; Zhao, F.; Li, G. Fault-alarm-threshold optimization method based on interval evidence reasoning. Sci. China Inf. Sci. 2019, 62, 89202. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.J.; Hu, G.Y.; Zhang, B.C.; Hu, C.H.; Zhou, Z.G.; Qiao, P.L. A Model for Hidden Behavior Prediction of Complex Systems Based on Belief Rule Base and Power Set. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1649–1655. [Google Scholar] [CrossRef]
- Fei, L.; Xia, J.; Feng, Y.; Liu, L. An ELECTRE-based multiple criteria decision making method for supplier selection using Dempster-Shafer theory. IEEE Access 2019, 7, 84701–84716. [Google Scholar] [CrossRef]
- Su, X.; Li, L.; Shi, F.; Qian, H. Research on the Fusion of Dependent Evidence Based on Mutual Information. IEEE Access 2019, 6, 71839–71845. [Google Scholar] [CrossRef]
- Fu, C.; Xu, D.L.; Yang, S.L. Distributed preference relations for multiple attribute decision analysis. J. Oper. Res. Soc. 2016, 67, 457–473. [Google Scholar] [CrossRef]
- Song, Y.; Wang, X.; Wu, W.; Quan, W.; Huang, W. Evidence combination based on credibility and non-specificity. Pattern Anal. Appl. 2018, 21, 167–180. [Google Scholar] [CrossRef]
- Liu, Z.; Pan, Q.; Dezert, J.; Han, J.W.; He, Y. Classifier Fusion With Contextual Reliability Evaluation. IEEE Trans. Cybern. 2017, 48, 1605–1618. [Google Scholar] [CrossRef]
- Su, X.; Li, L.; Qian, H.; Mahadevan, S.; Deng, Y. A new rule to combine dependent bodies of evidence. Soft Comput. 2019, 23, 9793–9799. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, K.; Deng, Y. Base belief function: An efficient method of conflict management. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3427–3437. [Google Scholar] [CrossRef]
- Jing, M.; Tang, Y. A new base basic probability assignment approach for conflict data fusion in the evidence theory. Appl. Intell. 2021, 51, 1056–1068. [Google Scholar] [CrossRef]
- Weng, J.; Xiao, F.; Cao, Z. Uncertainty Modelling in Multi-agent Information Fusion Systems. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, Auckland, New Zealand, 9–13 May 2020; pp. 1494–1502. [Google Scholar]
- Dempster, A.P. Upper and Lower Probabilities Induced by a Multivalued Mapping. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; pp. 57–72. [Google Scholar]
- Shafer, G.A. A Mathematical Theory of Evidence. Technometrics 1978, 20, 106. [Google Scholar]
- Guan, X.; He, Y.; Yi, X. Radar emitter recognition of gray correlation based on D-S reasoning. Editor. Board Geomat. Inf. Ence Wuhan Univ. 2005, 30, 274–277. [Google Scholar]
- You, H.E.; Lifang, H.U.; Xin, G. A new method of measuring the degree of conflict among general basic probability assignments. Sci. Sin. Inform. 2011, 41, 989–997. [Google Scholar]
- Pchon, F.; Destercke, S.; Burger, T. A consistency-specificity trade-off to select source behavior in information fusion. IEEE Trans. Cybern. 2015, 45, 598–609. [Google Scholar] [CrossRef]
- Deng, Y. Generalized evidence theory. Appl. Intell. 2015, 43, 530–543. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 2017, 46, 630–640. [Google Scholar] [CrossRef]
- Martin, A. Conflict Management in Information Fusion with Belief Functions; Springer: Zurich, Switzerland, 2019. [Google Scholar]
- Weiquan, Z.; Yong, D. Combining conflicting evidence using the DEMATEL method. Soft Comput. 2018, 23, 8207–8216. [Google Scholar]
- Smets, P. The concept of distinct evidence. In IPMU 92 Proceedings; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Yager, R.R. On the fusion of non-independent belief structures. Int. J. Gen. Syst. 2009, 38, 505–531. [Google Scholar] [CrossRef]
- Su, X.; Mahadevan, S.; Xu, P.; Deng, Y. Handling of Dependence in Dempster–Shafer Theory. Int. J. Intell. Syst. 2015, 30, 441–467. [Google Scholar] [CrossRef]
- Tessem, B. Approximations for efficient computation in the theory of evidence. Artif. Intell. 1993, 61, 315–329. [Google Scholar] [CrossRef]
- Bauer, M. Approximation Algorithms and Decision Making in the Dempster-Shafer Theory of Evidence—An Empirical Study. Int. J. Approx. Reason. 1997, 17, 217–237. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Dezert, J.; Pan, Q.; Mercier, G. Combination of sources of evidence with different discounting factors based on a new dissimilarity measure. Decis. Support Syst. 2012, 52, 133–141. [Google Scholar] [CrossRef]
- Cuzzolin, F. A geometric approach to the theory of evidence. IEEE Trans. Syst. Man Cybern. Part C 2008, 38, 522–534. [Google Scholar] [CrossRef] [Green Version]
- Jousselme, A.L.; Grenier, D.; Bossé, É. A new distance between two bodies of evidence. Inf. Fusion 2001, 2, 91–101. [Google Scholar] [CrossRef]
- Han, D.; Deng, Y.; Liu, Q. Combining belief functions based on distance of evidence. Decis. Support Syst. 2005, 38, 489–493. [Google Scholar]
- Liu, W. Analyzing the degree of conflict among belief functions. Artif. Intell. 2006, 170, 909–924. [Google Scholar] [CrossRef] [Green Version]
- Ristic, B.; Smets, P. The TBM global distance measure for the association of uncertain combat ID declarations. Inf. Fusion 2014, 7, 276–284. [Google Scholar] [CrossRef]
- Zouhal, L.M.; Denoeux, T. An evidence-theoretic k-NN rule with parameter optimization. Syst. Man Cybern. Part C Appl. Rev. IEEE Trans. 1998, 28, 263–271. [Google Scholar] [CrossRef]
- Schubert, J. Clustering decomposed belief functions using generalized weights of conflict. Int. J. Approx. Reason. 2008, 48, 466–480. [Google Scholar] [CrossRef] [Green Version]
- Deng, X.; Jiang, W. Evaluating Green Supply Chain Management Practices Under Fuzzy Environment: A Novel Method Based on D Number Theory. Int. J. Fuzzy Syst. 2019, 21, 1389–1402. [Google Scholar] [CrossRef]
- Xiao, F.; Zhang, Z.; Abawajy, J. Workflow scheduling in distributed systems under fuzzy environment. J. Intell. Fuzzy Syst. 2019, 37, 1–11. [Google Scholar] [CrossRef]
- Xu, X.; Weng, X.; Xu, D.; Xu, H.; Hu, Y.; Li, J. Evidence updating with static and dynamical performance analyses for industrial alarm system design. ISA Trans. 2020, 99, 110–122. [Google Scholar] [CrossRef] [PubMed]
- Liao, H.; Mi, X.; Xu, Z. A survey of decision-making methods with probabilistic linguistic information: Bibliometrics, preliminaries, methodologies, applications and future directions. Fuzzy Optim. Decis. Mak. 2020, 19, 81–134. [Google Scholar] [CrossRef]
- Zhou, M.; Liu, X.; Yang, J. Evidential reasoning approach for MADM based on incomplete interval value. J. Intell. Fuzzy Syst. 2017, 33, 3707–3721. [Google Scholar] [CrossRef] [Green Version]
- He, Z.; Jiang, W. An evidential dynamical model to predict the interference effect of categorization on decision making results. Knowl. Based Syst. 2018, 150, 139–149. [Google Scholar] [CrossRef]
- Barrière, A.; Maubert, B.; Murano, A.; Rubin, S. Reasoning about Changes of Observational Power in Logics of Knowledge and Time. In AAMAS 2019: International Conference on Autonomous Agents and Multiagent Systems, Montreal, QC, Canada, 13–17 May 2019; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2019; pp. 971–979. [Google Scholar]
- Yuan, K.; Deng, Y. Conflict evidence management in fault diagnosis. Int. J. Mach. Learn. Cybern. 2019, 10, 121–130. [Google Scholar] [CrossRef]


{kind=link}
| A | 0.65 | 0 | 0.7788 | 0.7788 | 0.7895 |
| B | 0.2 | 0.9167 | 0.1593 | 0.1593 | 0.1579 |
| C | 0.15 | 0.0833 | 0 | 0 | 0 |
| A,C | 0 | 0 | 0.0619 | 0.0619 | 0.0526 |
| Method | m(A) | m(B) | m(C) |
|---|---|---|---|
| D-S combination rule | 0 | 0.1228 | 0.8772 |
| Modified average combination rule of Deng et al. [43] | 0.8909 | 0.0086 | 0.1005 |
| Original method [25] | 0.9966 | 0.0028 | 0.0005 |
| Proposed method | 0.9974 | 0.0026 | 0.00002 |
| m(A) = 0.3666 | m(H) = 0.8176 | m(H) = 0.6229 | |
| m(H) = 0.4563 | m(F) = 0.0003 | m() = 0.3771 | |
| m(A,H) = 0.1185 | m(A,H) = 0.1553 | ||
| m(() = 0.0586 | m(() = 0.0268 | ||
| m(A) = 0.2793 | m(H) = 0.5658 | m(H) = 0.7660 | |
| m(H) = 0.4151 | m(F) = 0.0009 | m((Θ) = 0.2340 | |
| m(A,H) = 0.2652 | m(A,H) = 0.0646 | ||
| m(() = 0.0404 | m(() = 0.3687 | ||
| m(A) = 0.2897 | m(H) = 0.2403 | m(H) = 0.8598 | |
| m(H) = 0.4331 | m(F) = 0.0004 | m((Θ) = 0.1402 | |
| m(A,H) = 0.2470 | m(A,H) = 0.0141 | ||
| m(() = 0.0302 | m(() = 0.7452 |
| D-S combination rule | m(A) = 0.3376 | m(H) = 0.9399 | m(H) = 0.9876 |
| m(H) = 0.6317 | m(F) = 0.0001 | m() = 0.0124 | |
| m(A,H) = 0.0305 | m(A,H) = 0.0526 | ||
| m() = 0.0001 | m() = 0.0074 | ||
| Modified average combination rule of Deng et al. | m(A) = 0.3347 | m(H) = 0.9065 | m(H) = 0.9845 |
| m(H) = 0.6319 | m(F) = 0.0002 | m() = 0.0155 | |
| m(A,H) = 0.0332 | m(A,H) = 0.0403 | ||
| m() = 0.0002 | m() = 0.0530 | ||
| original method | m(A) = 0.3786 | m(H) = 0.9451 | m(H) = 0.9979 |
| m(H) = 0.6094 | m(F) = 0.0189 | m() = 0.0021 | |
| m(A,H) = 0.0120 | m(A,H) = 0.0298 | ||
| m() = 0.0062 | |||
| proposed method | m(A) = 0.0250 | m(H) = 0.9992 | m(H) = 0.999992 |
| m(H) = 0.9749 | m(F) = 0.0002 | m() = 0.000008 | |
| m(A,H) = 0.0018 | m(A,H) = 0.0005 | ||
| m() = 0.00000006 | m() = 0.00003 |
| Attribute | |||||
|---|---|---|---|---|---|
| SL | 0.2712 | 0 | 0 | 0 | 0.7288 |
| SW | 0 | 0.9 | 0 | 0.1 | 0 |
| PL | 0.6486 | 0 | 0 | 0 | 0.3514 |
| PW | 0.7477 | 0 | 0 | 0 | 0.2523 |
| Attribute | |||||
|---|---|---|---|---|---|
| D-S combination rule | 0 | 0.9 | 0 | 0.1 | 0 |
| Modified average combination rule of Deng et al. | 0.9133 | 0.0489 | 0 | 0.0037 | 0.0341 |
| Original method | 0.9997 | 0.0002 | 0 | 0 | 0.0001 |
| Proposed method | 0.999985 | 0.00001 | 0 | 0 | 0.000005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Tang, Y. Conflict Data Fusion in a Multi-Agent System Premised on the Base Basic Probability Assignment and Evidence Distance. Entropy 2021, 23, 820. https://doi.org/10.3390/e23070820
Liu J, Tang Y. Conflict Data Fusion in a Multi-Agent System Premised on the Base Basic Probability Assignment and Evidence Distance. Entropy. 2021; 23(7):820. https://doi.org/10.3390/e23070820
Chicago/Turabian StyleLiu, Jingyu, and Yongchuan Tang. 2021. "Conflict Data Fusion in a Multi-Agent System Premised on the Base Basic Probability Assignment and Evidence Distance" Entropy 23, no. 7: 820. https://doi.org/10.3390/e23070820
APA StyleLiu, J., & Tang, Y. (2021). Conflict Data Fusion in a Multi-Agent System Premised on the Base Basic Probability Assignment and Evidence Distance. Entropy, 23(7), 820. https://doi.org/10.3390/e23070820