2.1. Reservoir Computing with Output Layer Expansion
In this section, we cover the reservoir computing basics in terms of operation and training and discuss the principle of output layer expansion. A reservoir computer consists of
N internal states, also called neurons, here captured in a column vector
as a function of discrete time
n. The system is operated by coupling input data
to these neurons using different weights. The neurons are randomly interconnected to form a recurrent neural network. A state update equation describes how the neural states evolve, i.e., how their (typically nonlinear) activation function
acts (element-wise) on both past states and newly injected data as
Standard reservoir outputs are constructed through linear combinations of neural responses with a set of readout weights
. In practice, the act of accessing these neural responses often involves measuring and recording them. The measured responses
, with subscript
m, are then obtained by parsing the neural responses with a (possibly nonlinear) readout function
acting element-wise; we note
. In our work, we will be measuring the optical power of the neural states encoded in the optical field strength, such that
. For a standard reservoir output, then, the measured responses form the set of output features
that are combined with output weights
to construct reservoir outputs:
Below, we will generalize Equation (
2) to a scenario where the output features
are not restricted to equal the measured responses
. The number of output features is denoted
(in the case of Equation (
2) we have
).
Multiple parallel reservoir outputs can be created from these output features. Since all outputs are created in the same way, we focus here on a single scalar output
. This output is constructed by optimizing a row vector of
readout weights
:
By combining
T timesteps, we construct row vector
with
as its
element and state matrix
with
as its
column to rewrite Equation (
3) as
The readout weights
are optimized to minimize the square error with respect to a target output
by finding the pseudo inverse
of the state matrix
as
Typically, the readout weights are optimized over a set of training samples, and the residual output error is evaluated over a disjunct set of testing samples.
In this work, we consider an adapted readout layer which expands the number of output features
using polynomials of the measured states
. In general, such an adaptation to the readout layer can be described by an output function:
which maps the
N dimensional vector
of (measured) neural responses to an
dimensional vector of output features
. Any readout adaptation of this form has the advantage that the standard procedure for constructing and training reservoir outputs given by Equations (
3)–(
5) remains applicable.
2.2. Output Expansion with First and Second Degree Polynomials
Here, we present an illustrative example of an output feature expansion. This example will be used below to improve the performance of an experimental photonic reservoir computing system. It is important, however, to keep in mind that the proposed scheme can be generalized in many ways (there are many other nonlinear expansions possible). With this example expansion, we pay special attention to the number of output features. This is because it allows us to probe the trade-off between system complexity and computational performance, a trade-off which is of great interest to experimental reservoir computing systems in general.
We have chosen to expand the reservoir’s set of output features with polynomial functions, limited to first and second degree, of the recorded neural responses. The first degree contributions correspond with the original recorded responses . The second degree contributions are obtained by mixing the recorded responses with auxiliary features. These auxiliary features are signals constructed as linear combinations of the recorded responses . This process is identical for standard reservoir outputs, which is why we label these auxiliary features as Y, and we will add a subscript to refer to the method used to obtain them. In general, the auxiliary features can be constructed through supervised training or unsupervised training, determined by the availability of a target signal. Here we focus on an unsupervised method to obtain the auxiliary features because we want to avoid the need to measure, estimate or even identify all drifting parameters, and consequently, no target signals are available.
Since parameter drifts and variations are expected to occur slowly with respect to the input sample spacing, we have tried using slow feature analysis [
26] to find linear combinations of the neural responses that vary slowly. Our efforts are outlined in
Appendix B. This method yields useful slow features, i.e., signals that correlate strongly with the slowest perturbations of the system, which are the parameter drifts. However, we also found that constructing random auxiliary features
as linear combinations of the recorded neural responses
with random weights
is much easier than constructing slow features and gives the same performance gains and robustness to parameter drifts. For this reason, we focus on the latter approach.
In general the practical implementation determines the bounds of the distribution from which the random weights are sampled. Since we evaluate the proposed scheme by post-processing the recorded experimental data, we have complete liberty. Here, we choose to sample weights uniformly from
as this could be implemented passively (i.e., without amplification).
To obtain
P random features, the
column vector
is thus constructed with the
matrix
as
We now write the explicit form of the corresponding output expansion
to clarify how we obtain the full set of output features
. Combining
T timesteps, we construct the
matrix of output features
with
where the
column
is constructed as follows: the first
N elements correspond with the measured neural responses
, the next
N elements correspond with
multiplied by the first element of
, the next
N elements are
multiplied by the second element of
and so on. Using the Kronecker product, this can be written as
The output features thus consist of the recorded neural responses directly and these responses mixed with the random features. The extended set of
readout weights
can then be obtained following the standard training procedure of Equation (
5). Note that
, as otherwise there will be output features
which are linearly dependent on other output features.
The relation between the task-solving reservoir output
and the expanded set of output features
is still given by Equation (
3). Additionally, for the specific output expansion discussed here, we can express
in terms of the recorded neural responses
directly as
where the
is the subset of readout weights in
used for first order polynomials terms in
, and the matrix product
is the subset used for second order terms. More formally, vectorizing weights matrix
and appending it to weights vector
yields
as
Note that the
matrix resulting from the product of
and
is not necessarily of full rank, depending on the (number of) features used. In an explicit nonlinear expansion of this degree, this matrix product would be replaced by a single
matrix of full rank. Our approach allows for choosing how many auxiliary features are used, which offers a trade-off between performance gains and system complexity, as will be shown in the Results section. This output-expansion scheme is illustrated in
Figure 1, showing 3 neural responses and 1 random feature resulting in 6 output features.
2.3. Slow Noise and Feature Dependent Weights
In this section, we discuss slow uncontrolled parameter variations which can affect the internal dynamics of a reservoir computer in operation and can thus negatively impact its performance. We also touch on the concept of feature-dependent weights and how it relates to the previously discussed nonlinear output expansion.
Denote by
the set all parameters and operators describing a reservoir computer’s operation in Equation (
1). Following the spirit of reservoir computing, we avoid micromanaging the reservoir’s response to changes in
and instead focus on the optimization of the readout weights
. If
changes over time due to environmental fluctuations (which are slow with regard to the input data rate), then the system’s computational capacity can be negatively affected. The standard reservoir training scheme will automatically try to capture the reservoir’s dynamics for the range of values
encountered during training. This provides a natural robustness during testing, provided that only similar values of
occur. However, this robustness obviously comes at a price, since a reservoir trained and tested on a fixed parameter set
would work better. Furthermore, even without parameter drifts or variations, reservoir computing systems can exhibit different performance levels at different operating points. So even if the system is, in principle, not affected by the dynamics of the parameter fluctuations, performance variations could still occur due to the suitability of the instantaneous parameter values.
In [
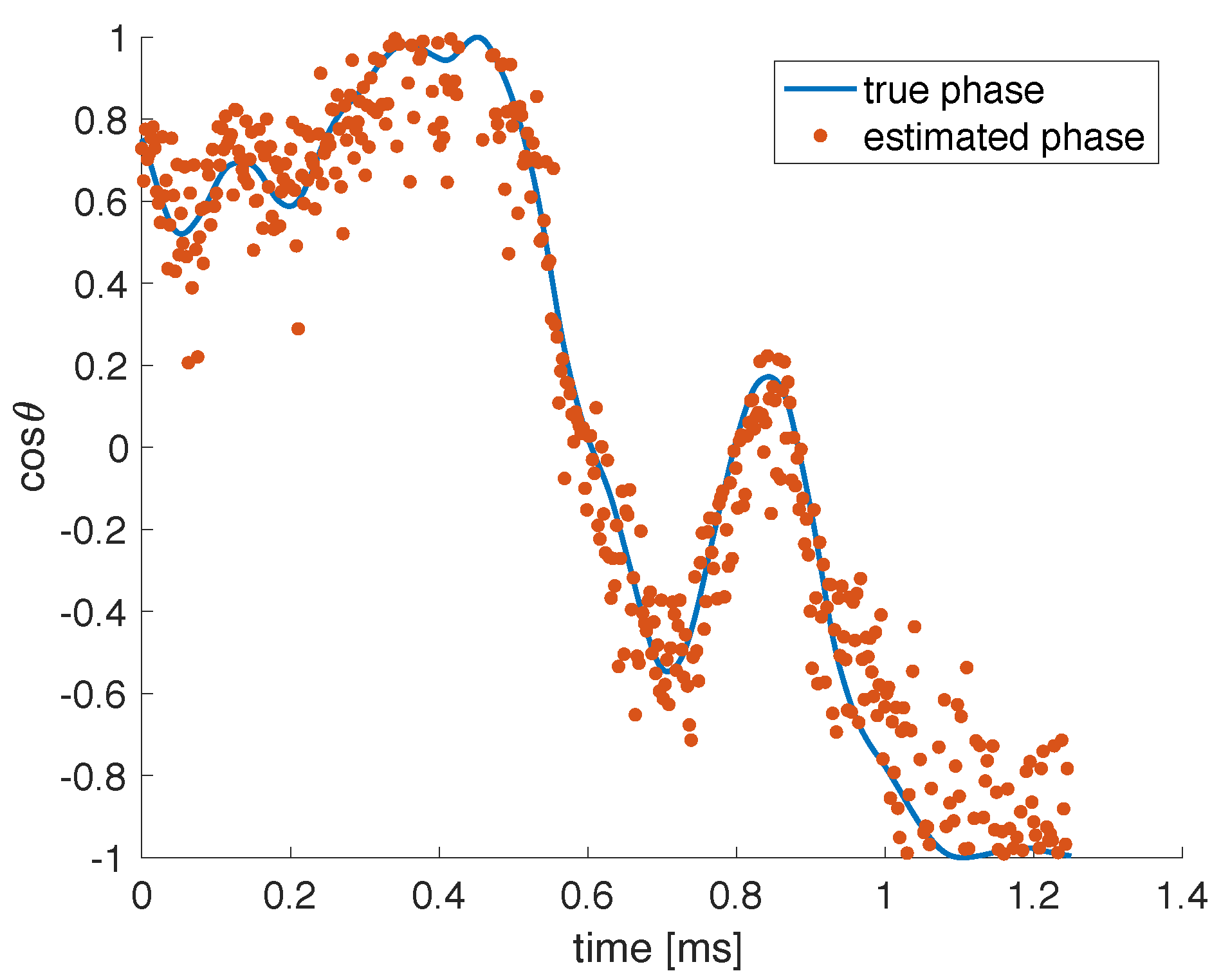
25], several approaches are presented to counter the negative impact of such variations on the performance of a photonic reservoir computer. There, a simulated coherent reservoir is perturbed by the variations of a single parameter
(one-dimensional), namely the detuning of an optical cavity. An estimation of any uncontrolled variations in
is extracted from the reservoir using 2 auxiliary features,
and
. As their names suggest, these features are trained to estimate
and
to account for the periodic nature of the system’s response to changes in
. These two auxiliary features are constructed as standard reservoir outputs, i.e., as linear combinations of the neural responses with readout weights
and
, respectively. These weights are obtained through the regular (supervised) reservoir training procedure, Equation (
5), since the target signals (
and
) are known. These features are obtained as
and thus, omitting the additional filtering that was applied in [
25] to clean up these auxiliary features, this constitutes an example of auxiliary features such as presented previously, albeit with non-random weights.
Furthermore, in [
25], recognizing that fixed readout weights yield suboptimal solutions under varying
, a weight-tuning scheme is then implemented, changing the output relation Equation (
3) to
with time-dependent readout weights
This results in an extended set of weights that is optimized during supervised training, using the target output specified for the computational task at hand. It has successfully been shown that this weight-tuning scheme improves the robustness to phase fluctuations of the simulated photonic reservoir computer and provides good performance over a wide range of operational settings. In fact, it does so without taxing the reservoir’s computational capacity as it is no longer the reservoir’s internal dynamics which provide the robustness to parameter variations, but rather the readout weight-tuning.
We have identified this weight-tuning scheme to be an alternative perspective on the nonlinear output expansion with polynomials of first and second degree, as discussed above, a perspective which is also useful for the optimization of the extended set of readout weights, as discussed in the next paragraph. In this work we effectively build on this idea, switching to an unsupervised method (in the form of random features as discussed above) to demonstrate the concept experimentally. We consider a different coherent photonic reservoir computer but with the same one-dimensional
, i.e., the detuning of the optical cavity that makes up the reservoir. This system allows us to compare simulation results directly with experiments. We employ the same readout layer adaptation, but instead of constructing estimates of
and
through supervised training, we explore the applicability of the proposed adapted readout scheme to drifting parameters which cannot readily be measured. Lacking (and preventing the need for) a measurement of
, we do not train the additional outputs with the standard procedure Equation (
5). Instead, as discussed above, we construct random features following Equation (
8).
The specific example of a nonlinear output expansion that we presented is, in fact, equivalent to the same weight-tuning scheme presented in [
25]. In our case, the weight-tuning scheme is expressed as
which, when combined with the output relation Equation (
14), yields
One can verify that Equations (
8) and (
17) indeed combine to yield Equation (
10), which confirms the equivalence. The weight-tuning scheme is illustrated in
Figure 2, showing 3 measured neural responses
which are combined with 3 time-dependent readout weights
to form 1 task-solving output
. It also shows 1 auxiliary random feature
which is obtained with random weights
and used to tune the time-dependent readout weights
, and it can be compared with
Figure 1 to verify that it is an example of a nonlinear output expansion.
2.4. Setup
In this section we discuss the dynamical system on which our reservoir computing simulations and experiments is based. The reservoir itself is implemented in the all-optical fiber-ring cavity shown in
Figure 3, using standard single-mode fiber. A polarization controller is used to ensure that the input field
excites a polarization eigenmode of the fiber-ring cavity. A fiber coupler, characterized by its power transmission coefficient
, couples light in and out of the cavity. Ignoring dispersion, the fiber-ring is characterized by the roundtrip length
(or roundtrip time
ns), the propagation loss
(taken here
), the fiber nonlinear coefficient
and the cavity detuning
, i.e., the difference between the roundtrip phase and the nearest resonance (multiple of
). Without active stabilization, the cavity detuning is an uncontrolled parameter susceptible to slow (sub-MHz) variations. This low-finesse cavity is operated off-resonance, with a maximal input power of 50
(17
). A network of time-multiplexed virtual neurons is encoded in the cavity field envelope, with neuron spacing
.
We use the physical model constructed in [
12]. In this mean-field model, the temporal evolution of the electric field envelope is described by
, which represents the cavity field envelope measured at position
z from the coupler at time
during the
n-th roundtrip. The longitudinal coordinate of the fiber ring cavity is bound by the cavity length
, and similarly, the time variable is bound by the cavity roundtrip time
, since other values are covered by the expressions of other roundtrips (with different
n). A nonlinear propagation model is combined with the cavity boundary conditions to transform the input field
into the output field
, following the equations
where the effective cavity length that describes the accumulation of nonlinear Kerr phase is
. In this model, the cavity phase is the only drifting/noisy parameter and is therefore denoted
. Variations in
are caused by drift in the frequency of the pump laser and mechanical/thermal fluctuations affecting the cavity.
The input field
is generated by using a Mach–Zehnder modulator (MZM) to modulate a CW optical pump following [
7]. Here the input signal
(
) is first mixed with the input masks
and
(with neuron index
k):
and then used to drive the MZM. The input coupled to the
k-th neuron is thus expressed as
where
represents the pump power,
represents the setpoint and
represents the modulation range. The bias mask values
allow the masked input values
to exploit the full modulation range and affect the reservoir’s ability to recover phase information from its neural responses. These inputs then couple to all neurons through time-multiplexing, as the amplitude-modulated input field becomes
The neuron spacing
is set with respect to the cavity roundtrip time
and the number of neurons
N as
This deviation from the synchronized scenario (
) yields a ring-like coupling topology between the neurons, following [
9].
The output field
is sent to the readout layer where the neural responses are demultiplexed. In the readout layer, a photodetector (PD) measures the optical power of the neural responses
. More specifically, the measured value of the
k-th neuron is
The expansion of the reservoir’s output layer will be achieved by digitally post-processing the experimentally recorded neural responses.
It is known that the MZM and PD can act nonlinearly on the input and output signals and can thus affect the RC system’s performance [
9]. The implications for a coherent nonlinear reservoir have been investigated in [
12].
With high optical power levels and small neuron spacing (meaning fast modulation of the input signal), dynamical and nonlinear effects other than the Kerr nonlinearity may appear, such as photon–phonon interactions causing Brillouin and Raman scattering and bandwidth limitations caused by the driving and readout equipment. These effects are not included in our numerical model, and our experiments are designed to avoid them. Combined with the memory limitations of the oscilloscope, we therefore limit our reservoir to 20 neurons, with a maximal input power of 50 .
We remark a particular symmetry to this system. The Equations (
18)–(
20) admit a solution of the form
for some function
F which can be computed iteratively. With a real-valued input signal
, the complex conjugate of
is given by the same function, with opposite signs for
and
. Thus, neglecting the relatively weak influence of
and following Equation (
25), the recorded neural responses
are an even function of
.
In
Appendix A, we consider a discrete time version of a linearized system model, and we investigate how
affects the recorded neural responses (and linear combinations thereof, such as our random features). When averaged over times which are long compared to the cavity roundtrip time
but short compared to the time over which
varies and when the input bias
is non-zero, the system response depends on
and its powers. These are even functions of
, as expected on account of the mentioned symmetry.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}