
Learning in Convolutional Neural Networks Accelerated by Transfer Entropy


Abstract
:1. Introduction
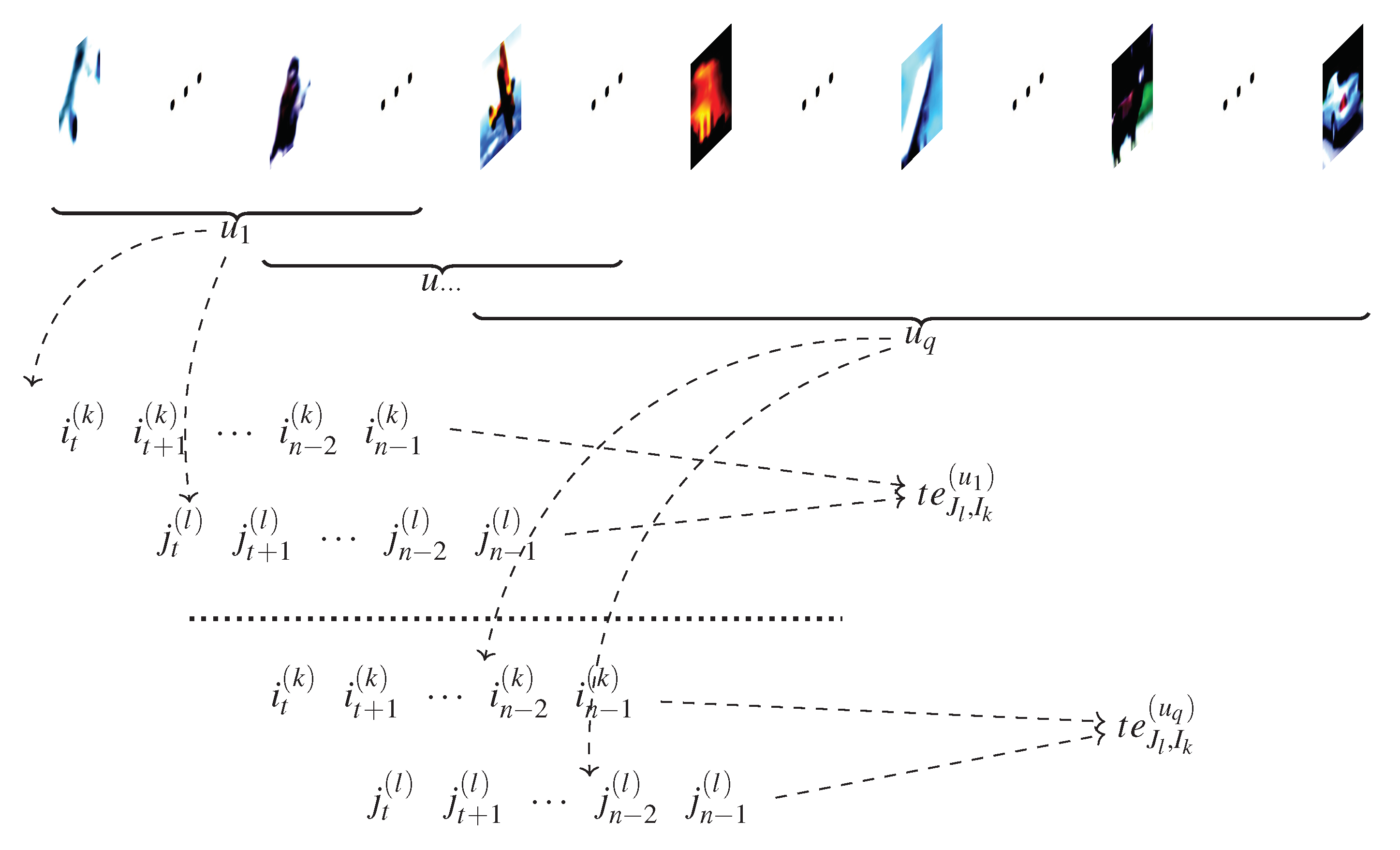
2. Transfer Entropy Notations
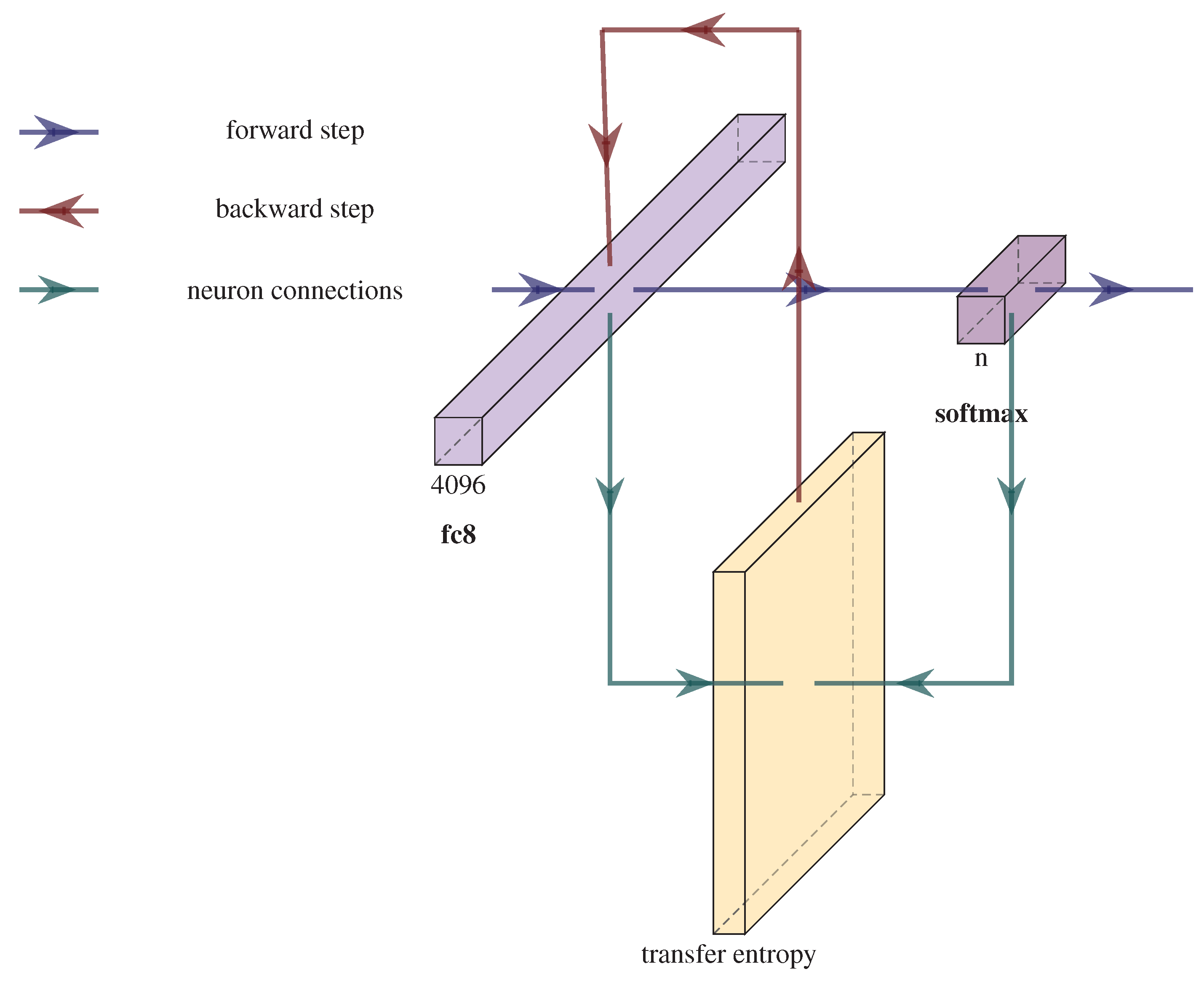
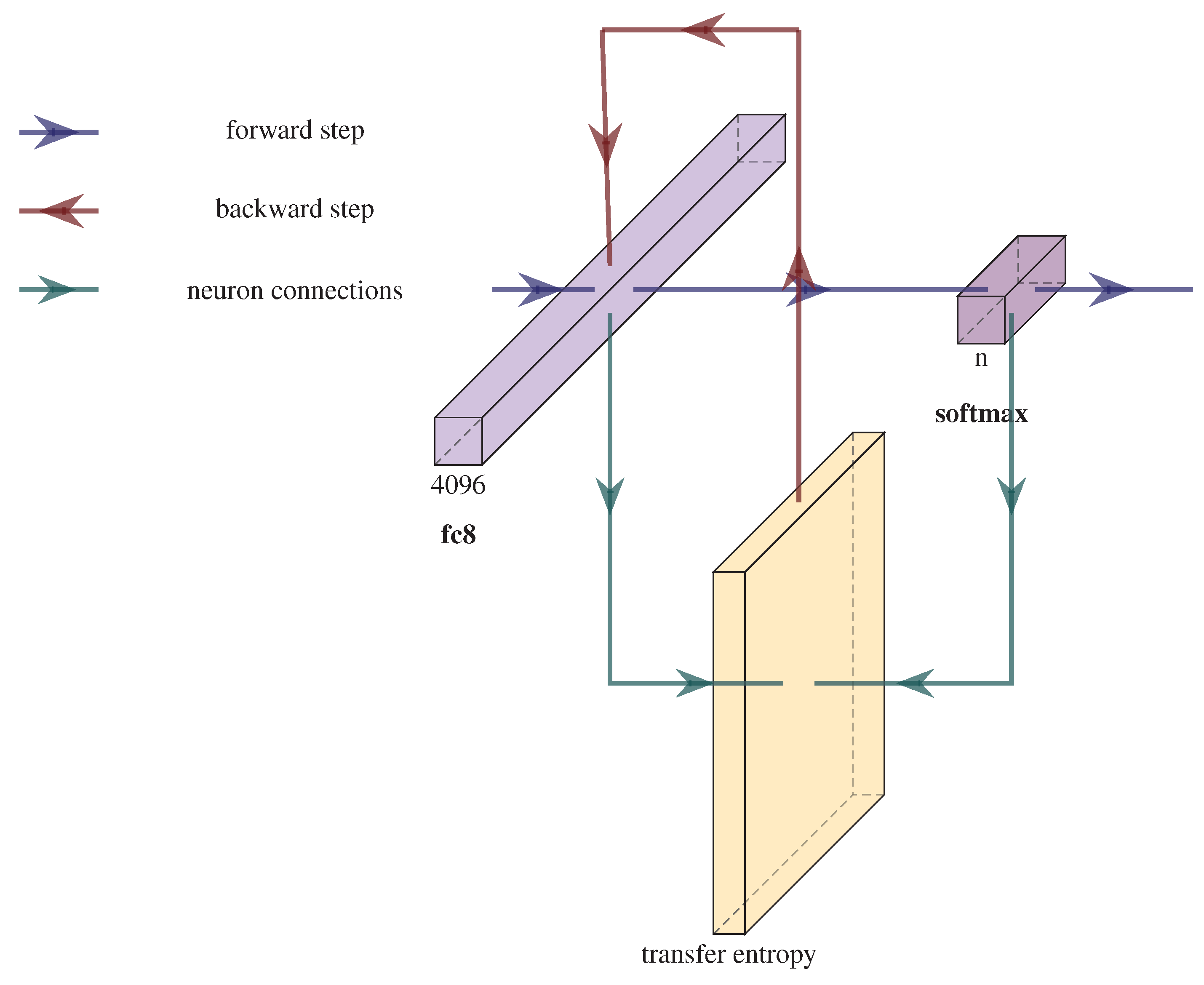
3. Computing the TE Feedback in a CNN
4. TE Feedback Integration in CNN Training
| Algorithm 1: Backpropagation using TE for a single step and a single mini-batch. Mini-batches are obtained by equally dividing the training set by a fixed number. This algorithm is repeated for all the available mini-batches and for a number of epochs. Bold items denote matrices and vectors. is the derivative of the activation function . The k and l indices are the same as the ones in Equation (1). |
 |
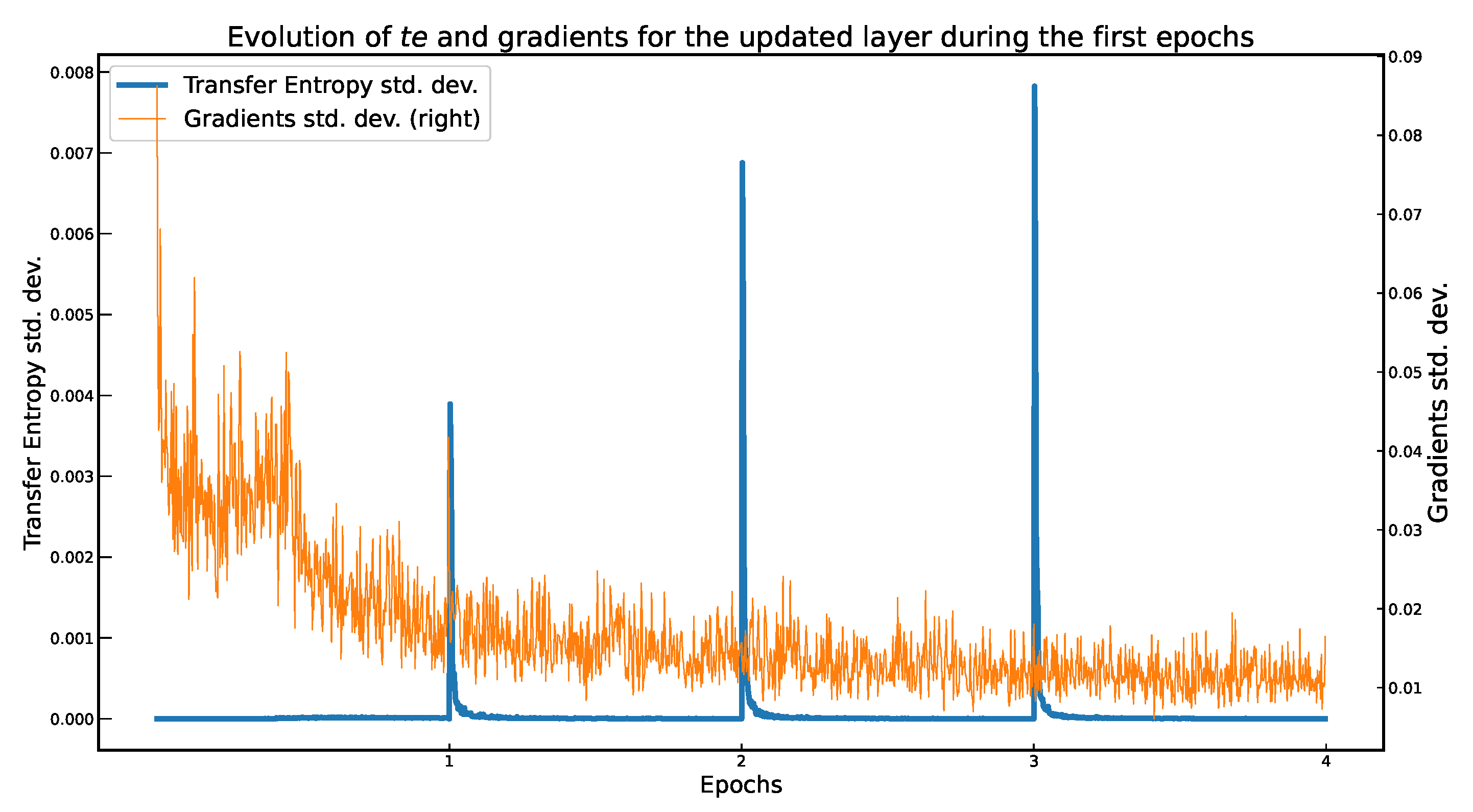
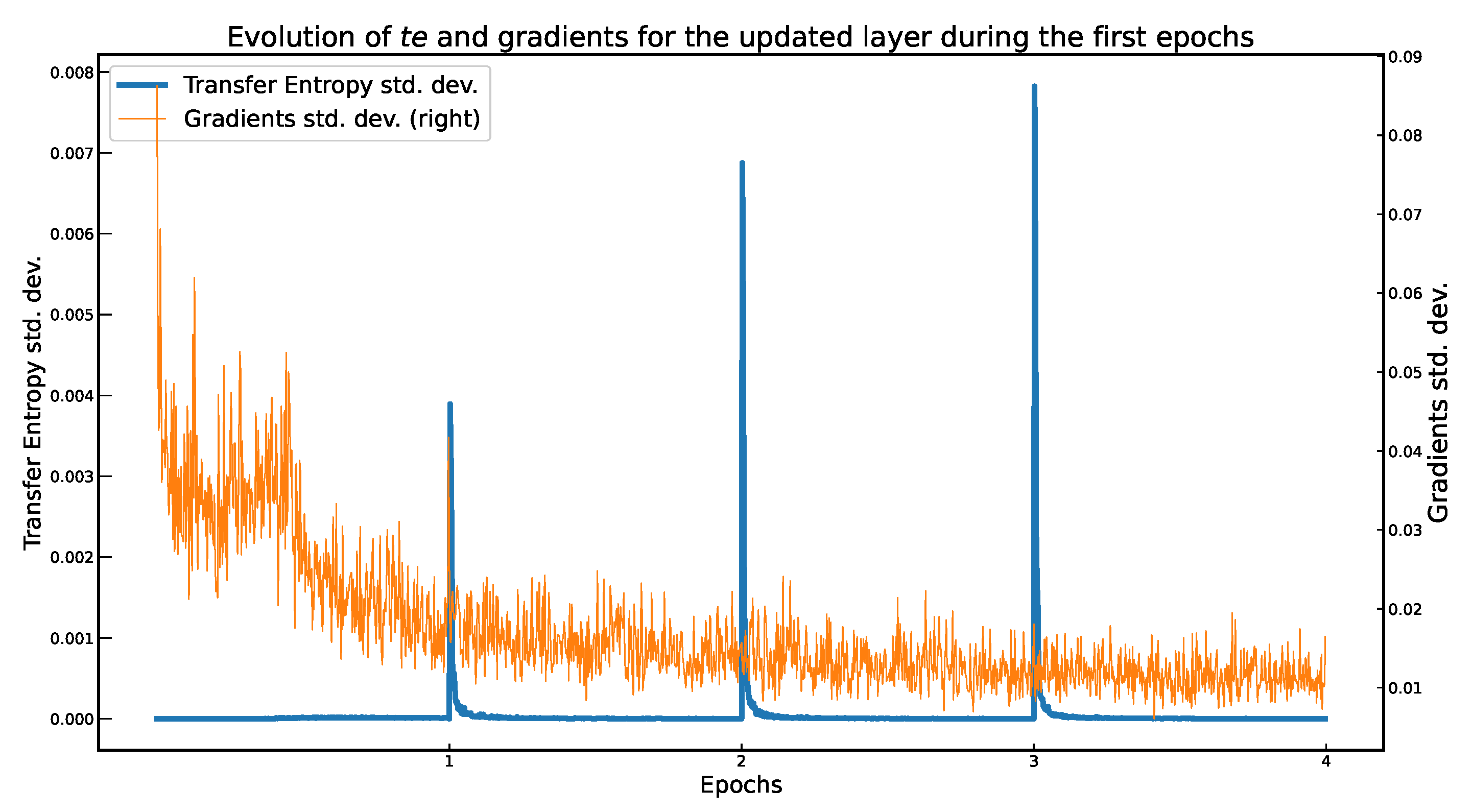
5. Experimental Results
6. Conclusions and Open Problems
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| transfer entropy value | |
| TE | Transfer Entropy |
| g | the binarization threshold |
| u | window of time series used to calculate TE |
| weights matrix | |
| C | loss function |
| CNN | Convolutional Neural Network |
| SGD | Stochastic Gradient Descent |
| CNN+TE | CNN + Transfer Entropy—our proposed method |
| MLP | Multi-layer perceptron |
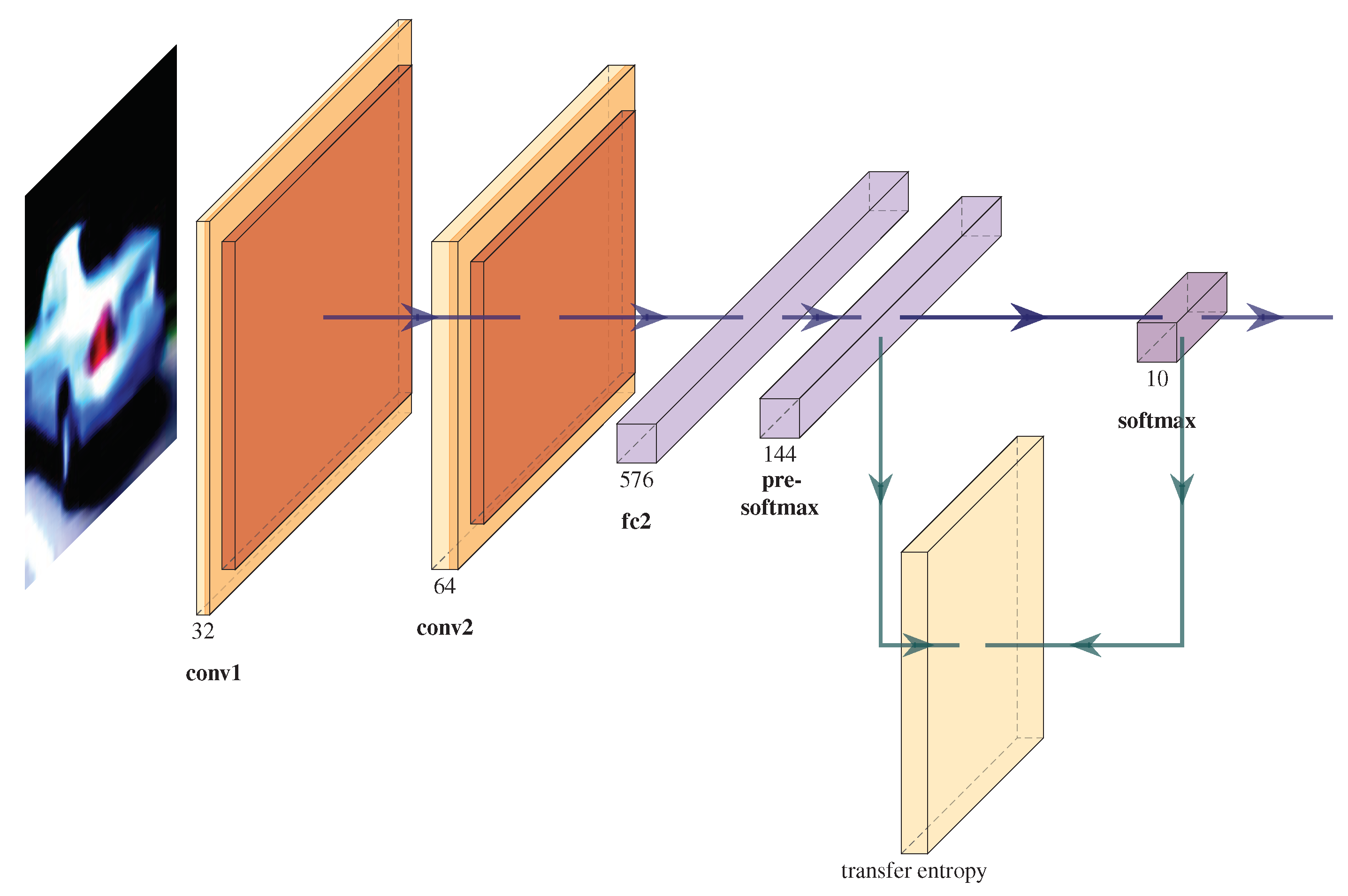
Appendix A. CNN Architectures
Appendix A.1. FashionMNIST
Appendix A.2. CIFAR-10
Appendix A.3. STL-10
Appendix A.4. SVHN
Appendix A.5. USPS
References
- Shadish, W.; Cook, T.; Campbell, D. Experimental and Quasi-Experimental Designs for Generalized Causal Inference; Houghton Mifflin: Boston, MA, USA, 2001. [Google Scholar]
- Marwala, T. Causality, Correlation and Artificial Intelligence for Rational Decision Making; World Scientific: Singapore, 2015. [Google Scholar] [CrossRef]
- Zaremba, A.; Aste, T. Measures of Causality in Complex Datasets with Application to Financial Data. Entropy 2014, 16, 2309–2349. [Google Scholar] [CrossRef] [Green Version]
- Lizier, J.T.; Prokopenko, M. Differentiating information transfer and causal effect. Eur. Phys. J. B 2010, 73, 605–615. [Google Scholar] [CrossRef] [Green Version]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger Causality and Transfer Entropy Are Equivalent for Gaussian Variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef] [Green Version]
- Hlaváčková-Schindler, K. Equivalence of Granger Causality and Transfer Entropy: A Generalization. Appl. Math. Sci. 2011, 5, 3637–3648. [Google Scholar]
- Massey, J.L. Causality, feedback and directed information. In Proceedings of the 1990 International Symposium on Information Theory and its applications and Its Applications, Honolulu, HI, USA, 27–30 November 1990; pp. 303–305. [Google Scholar]
- Cațaron, A.; Andonie, R. Transfer Information Energy: A Quantitative Causality Indicator Between Time Series. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2017—26th International Conference on Artificial Neural Networks, Alghero, Italy, 11–14 September 2017; pp. 512–519. [Google Scholar] [CrossRef]
- Caţaron, A.; Andonie, R. Transfer Information Energy: A Quantitative Indicator of Information Transfer between Time Series. Entropy 2018, 20, 323. [Google Scholar] [CrossRef] [Green Version]
- Lizier, J.T.; Heinzle, J.; Horstmann, A.; Haynes, J.D.; Prokopenko, M. Multivariate information-theoretic measures reveal directed information structure and task relevant changes in fMRI connectivity. J. Comput. Neurosci. 2011, 30, 85–107. [Google Scholar] [CrossRef]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—A model-free measure of effective connectivity for the neurosciences. J. Comput. Neurosci. 2011, 30, 45–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shimono, M.; Beggs, J.M. Functional Clusters, Hubs, and Communities in the Cortical Microconnectome. Cereb. Cortex 2015, 25, 3743–3757. [Google Scholar] [CrossRef] [Green Version]
- Fang, H.; Wang, V.; Yamaguchi, M. Dissecting Deep Learning Networks—Visualizing Mutual Information. Entropy 2018, 20, 823. [Google Scholar] [CrossRef] [Green Version]
- Obst, O.; Boedecker, J.; Asada, M. Improving Recurrent Neural Network Performance Using Transfer Entropy. In Proceedings of the 17th International Conference on Neural Information Processing: Models and Applications—Volume Part II; Springer: Berlin/Heidelberg, Germany, 2010; pp. 193–200. [Google Scholar]
- Féraud, R.; Clérot, F. A methodology to explain neural network classification. Neural Netw. 2002, 15, 237–246. [Google Scholar] [CrossRef]
- Herzog, S.; Tetzlaff, C.; Wörgötter, F. Transfer entropy-based feedback improves performance in artificial neural networks. arXiv 2017, arXiv:1706.04265. [Google Scholar]
- Herzog, S.; Tetzlaff, C.; Wörgötter, F. Evolving artificial neural networks with feedback. Neural Netw. 2020, 123, 153–162. [Google Scholar] [CrossRef]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Moldovan, A.; Caţaron, A.; Andonie, R. Learning in Feedforward Neural Networks Accelerated by Transfer Entropy. Entropy 2020, 22, 102. [Google Scholar] [CrossRef] [Green Version]
- Bossomaier, T.; Barnett, L.; Harré, M.; Lizier, J.T. An Introduction to Transfer Entropy. Information Flow in Complex Systems; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Baghli, M. A model-free characterization of causality. Econ. Lett. 2006, 91, 380–388. [Google Scholar] [CrossRef]
- Hlaváčková-Schindler, K.; Paluš, M.; Vejmelka, M.; Bhattacharya, J. Causality detection based on information-theoretic approaches in time series analysis. Phys. Rep. 2007, 441, 1–46. [Google Scholar] [CrossRef]
- Kaiser, A.; Schreiber, T. Information transfer in continuous processes. Phys. D Nonlinear Phenom. 2002, 166, 43–62. [Google Scholar] [CrossRef]
- Gencaga, D.; Knuth, K.H.; Rossow, W.B. A Recipe for the Estimation of Information Flow in a Dynamical System. Entropy 2015, 17, 438–470. [Google Scholar] [CrossRef] [Green Version]
- Hlaváčková-Schindler, K. Causality in Time Series: Its Detection and Quantification by Means of Information Theory. In Information Theory and Statistical Learning; Emmert-Streib, F., Dehmer, M., Eds.; Springer: Boston, MA, USA, 2009; pp. 183–207. [Google Scholar] [CrossRef]
- Zhu, J.; Bellanger, J.J.; Shu, H.; Le Bouquin Jeannès, R. Contribution to Transfer Entropy Estimation via the k-Nearest-Neighbors Approach. Entropy 2015, 17, 4173–4201. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: R ethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Muşat, B.; Andonie, R. Semiotic Aggregation in Deep Learning. Entropy 2020, 22, 1365. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 318–362. [Google Scholar]
- Shalev-Shwartz, S.; Singer, Y.; Srebro, N.; Cotter, A. Pegasos: Primal estimated sub-gradient solver for SVM. Math. Program. 2011, 127, 3–30. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An Analysis of Single-Layer Networks in Unsupervised Feature Learning. J. Mach. Learn. Res. Proc. Track 2011, 15, 215–223. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A. Reading Digits in Natural Images with Unsupervised Feature Learning. NIPS 2011, 1–9. [Google Scholar]
- Hull, J.J. A database for handwritten text recognition research. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 550–554. [Google Scholar] [CrossRef]
- Lecun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object Recognition with Gradient-Based Learning. In Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Gilbert, C.D.; Li, W. Top-down influences on visual processing. Nat. Rev. Neurosci. 2013, 14, 350–363. [Google Scholar] [CrossRef] [PubMed]
- Spillmann, L.; Dresp-Langley, B.; Tseng, C.H. Beyond the classical receptive field: The effect of contextual stimuli. J. Vis. 2015, 15, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ke, N.R.; Bilaniuk, O.; Goyal, A.; Bauer, S.; Larochelle, H.; Pal, C.; Bengio, Y. Learning Neural Causal Models from Unknown Interventions. arXiv 2019, arXiv:1910.01075. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CIFAR-10+TE | FashionMNIST+TE | STL-10+TE | SVHN+TE | USPS+TE | |
|---|---|---|---|---|---|
| learning rate () | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
| momentum | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 |
| dropout | 0 | 0.25 | 0. | 0.3 | 0.25 |
| threshold rate 1 () | 2.0 | 2.0 | 2.0 | 2.0 | 5.0 |
| threshold rate 2 () | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| window length | 100 | 100 | 4000 | 200 | 90 |
| batch size | 500 | 100 | 200 | 200 | 60 |
| CIFAR-10+TE | CIFAR-10 | |
|---|---|---|
| Target 98% accuracy in epoch | 5 | 6 |
| Top 1 accuracy at epoch 5 | 98.02% | 97.58% |
| Average epoch duration | 2110 s | 81 s |
| Total training duration | 10,550 s | 492 s |
| FashionMNIST+TE | FashionMNIST | |
|---|---|---|
| Target 97% accuracy in epoch | 23 | 28 |
| Top 1 accuracy at epoch 23 | 97.0% | 97.02% |
| Average epoch duration | 71 s | 41 s |
| Total training duration | 1720 s | 1162 s |
| STL-10+TE | STL-10 | |
|---|---|---|
| Target 98% accuracy in epoch | 5 | 7 |
| Top 1 accuracy at epoch 5 | 98.33% | 78.63% |
| Average epoch duration | 28 s | 7 s |
| Total training duration | 128 s | 53 s |
| SVHN+TE | SVHN | |
|---|---|---|
| Target 94% accuracy in epoch | 9 | 11 |
| Top 1 accuracy at epoch 9 | 94.05% | 91.67% |
| Average epoch duration | 512 s | 491 s |
| Total training duration | 4587 s | 5369 s |
| USPS+TE | USPS | |
|---|---|---|
| Target 99% accuracy in epoch | 3 | 3 |
| Top 1 accuracy at epoch 3 | 99.32% | 99.05% |
| Average epoch duration | 376 s | 33 s |
| Total training duration | 1138 s | 102 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moldovan, A.; Caţaron, A.; Andonie, R. Learning in Convolutional Neural Networks Accelerated by Transfer Entropy. Entropy 2021, 23, 1218. https://doi.org/10.3390/e23091218
Moldovan A, Caţaron A, Andonie R. Learning in Convolutional Neural Networks Accelerated by Transfer Entropy. Entropy. 2021; 23(9):1218. https://doi.org/10.3390/e23091218
Chicago/Turabian StyleMoldovan, Adrian, Angel Caţaron, and Răzvan Andonie. 2021. "Learning in Convolutional Neural Networks Accelerated by Transfer Entropy" Entropy 23, no. 9: 1218. https://doi.org/10.3390/e23091218
APA StyleMoldovan, A., Caţaron, A., & Andonie, R. (2021). Learning in Convolutional Neural Networks Accelerated by Transfer Entropy. Entropy, 23(9), 1218. https://doi.org/10.3390/e23091218