1. Introduction
The idea of preorders over channels goes back a long way in the history of information theory. For instance, in [
1], Shannon introduced the “
inclusion” preorder to compare the capacities of discrete memoryless channels. Several authors, such as El Gamal [
2], Korner and Marton [
3], and many more, made further significant contributions to the study of channel preorders.
Such preorders are of practical importance in information theory. For example, the “
more capable” preorder [
3] is used in calculating the capacity region of broadcast channels [
2], or in deciding whether a system is more secure than another [
4,
5]. As discussed in the book by Cohen, Kempermann, and Zbaganu [
6], the applications of preorders over stochastic matrices goes beyond the field of information theory, for instance, to statistics, economics, and population sciences.
In this work, which is an extension of the results in our previous work [
7], we introduce a new preorder over channels. To illustrate the key idea, consider the following channel:
Now build a new channel from it as follows: take the first two columns, and for each row, rearrange their pairwise entries such that the larger element is moved to the first column, and the smaller element is in the second column. This yields:
We will refer to this pairwise operation on columns as a
Join-Meet operation. We prove that, for most commonly used entropy measures, a
Join-Meet operation always increases the posterior entropy. More precisely, the posterior entropy of the derived channel is never less than the posterior entropy of the original channel, for any probability distribution on the input. That is, the original channel is
more capable [
3] than the derived channel. We name the entropies respecting this property
channel-supermodular, and prove they entail Arimoto–Rényi entropies (including Shannon and min-entropy), and the guessing entropy, as well as some other entropies that are motivated from security and privacy contexts.
We define the
supermodular preorder (
) based on the Join-Meet operator. In particular, given channels
and
, we say
iff
can be obtained from
via a finite sequence of Join-Meet operations. We establish that the supermodular preorder is neither included nor does it include the
degradedness [
8] or
inclusion (Shannon) [
1] preorders. Motivated by this, we define two other channel preorders (
and
) that strictly include the aforementioned ones, respectively. The relation
implies that
is “more capable” than
. Moreover, whenever
, then the capacity of
is higher than that of
. Several such new channel ordering results are proven in this paper based on channel-supermodularity.
Next, we will consider the applications of channel-supermodularity in the context of security and privacy. The starting point will be the channel design problem, which is the problem of designing a channel that leaks the least amount of confidential information while respecting a set of operational constraints. This kind of problem arises in many security systems, such as authentication systems [
9], operating systems functions [
10], scheduling protocols [
11], bucketing schemes in cryptography [
12], anonymity (
Section 6.2), and so on. In the context of these applications, the problem is particularly interesting for deterministic systems and deterministic solutions. Solutions which are unique across many measures of leakage are also of interest because they are robust against how the knowledge or abilities of the attackers are modeled. In this work, we present a robust anonymity mechanism. The algorithm is based on a result from [
13], which uses the properties of channel-supermodularity presented in this paper to derive a greedy channel design algorithm that is provably optimal and unique for all channel-supermodular measures of leakage. We apply our robust anonymity mechanism to query anonymization: we consider the problem in which the real query itself is the secret, and we also consider the scenario where a related attribute is the secret. We provide optimal solutions for these two problems based on channel-supermodularity.
1.1. Related Literature
In the “information theory” literature, the degradedness order was introduced by Cover [
8] in the study of broadcasting channels. Cover conjectured a solution for the capacity region of broadcast channels that satisfy the degradedness ordering, which was proved by Bergmans [
14,
15] and Gallager [
16]. The problem of determining the capacity region of broadcast channels also motivated Korner and Marton to introduce the
-less noisy and
-more capable orderings [
3]. In the same paper, Korner and Marton established the capacity region for broadcast channels that respect the
-less noisy ordering. A similar result for broadcast channels respecting the
-more capable ordering was later established by El Gamal [
2].
Those orderings also play an important role in the field of
quantitative information flow (QIF), which is concerned with quantifying information leakage in computational systems (we refer to [
17] for a review of QIF). Malacaria [
18] makes use of degradedness ordering to reason about the security of deterministic programs, proving it is equivalent to the
,
, and
-more capable orderings for deterministic channels. This ordering also appears in the work of Alvim et al. [
19], in which it is shown to imply the more capable ordering for the
g-entropy family, a generalizing framework for information measures used in QIF. In the same paper, they conjectured that if two channels satisfy the more capable ordering for all members of the
g-entropy family, they satisfy the degradedness order. This conjecture, which was proven by McIver et al. [
20], turns out to be equivalent to Blackwell’s theorem in the finite setting [
21]. The less noisy ordering also appears recently in QIF literature, especially the
-less noisy ordering, in the study of
Dalenius leakage by Bordenabe and Smith [
22]. This last work is also closely related to the classical implications of the work by Buscemi [
23], which is mainly focused on the
-less noisy ordering in quantum information theory.
Shannon ordering (or inclusion), which generalizes degradedness ordering, was first introduced by Shannon when studying channels that could be perfectly simulated by other channels [
1]. In the same paper, Shannon established that inclusion implies
-capacity ordering. This ordering has been the object of study of several recent works. Inspired by Le Cam’s concept of deficiency [
24], which is itself related to the degradedness order and Blackwell’s theorem, Raginsky [
25] defines
Shannon deficiency, which may be seen as a measure of how far two channels are from satisfying the inclusion order. Techniques to verify Shannon ordering, both algebraic and computational, were studied by Zhang and Tepedelenlioǧlu [
26], and Nasser [
27] gave two different characterizations of the Shannon ordering.
The abstract problem of designing a system that leaks the least amount of information under some generalized form of operational constraints has been the objective of recent exploration in the literature [
28,
29,
30]. The problem of optimal system design in security settings has been studied within specific contexts, including secure multi-party computation systems [
31] and countermeasures against timing attacks [
12,
32]. The general channel design problem is of particular significance in QIF, as it represents a paradigm shift from the earlier foundational research in the area, which focuses mostly on measuring information leakage for existing channels or systems [
4,
5,
19,
33,
34].
Query obfuscation and anonymity have been investigated by several authors and even implemented in commercial products. Related to our work are algorithms presented in [
35,
36,
37]. Compared to those works, our approach follows an order-theoretical methodology and is based on a more general notion of entropy.
All the results in this paper rely on the concept of core-concave entropies, a generalizing framework that has been recently developed and can be shown to generalize the most commonly used conditional entropy measures in the literature [
28]. Core-concavity is a generalization of concavity, which has also been considered as a defining or desirable property for generalized information measures in QIF [
38] and in information theory [
39,
40,
41,
42].
1.2. Notational Conventions
Throughout the paper, represent discrete random variables with (nonempty, finite) alphabets . We assume that the elements of each alphabet are ordered, denoting by the elements of , by the elements of , and so on. Given , we write or to mean , and use p to refer to the (categorical) distribution (as a vector). We may specify the r.v. with a subscript, for example, writing , if it is not clear from the context.
We denote by the -dimensional probability simplex. Given a probability distribution p over , we overload the notation and use p to refer to its probability vector . We write for the nonincreasing rearrangement of —that is, denotes largest element of p, the second largest, and so forth. Given a vector , we denote by its -norm (note that this is a slight abuse of nomenclature, since it is not a norm when ).
Given a function F over and a random variable X with distribution , we use , and interchangeably.
A channel
K is a row stochastic matrix with rows indexed by
and columns indexed by
. The value
is equal to
, that is, the conditional probability that
y is produced by the channel
K when
x is the input value. The notation
means that the channel
K has
and
as input and output alphabets, respectively.
Channels are represented in a table format, or simply in the matrix notation, for example:
with the understanding that the
ith row corresponds to
, and the
jth column to
.
3. Channel-Supermodular Entropies
Note that any specific core-concave entropy H induces a H-more capable preorder over channels. However, this preorder might not be preserved for a different choice of conditional entropy. Theorem 3 characterizes a channel preorder that is “consistent” for all core-concave entropies. As strong as this result is, it still leaves the question whether there exists a preorder that is consistent for a class of entropies of interest. This is motivated by the fact that the class of core-concave entropies include far more entropies than the conventionally used ones, so it may include some eccentric ones that can be excluded for a stronger result. Moreover, the degradedness relation between channels seems very restrictive: there are many channels that cannot be compared with respect to degradedness, but have consistent ordering with respect to all typically used entropies.
With these motivations in mind, we introduce
channel-supermodular entropies. Channel-supermodularity is a property satisfied by a significant portion of commonly used entropies, being a helpful tool in optimization problems (as shown in
Section 6.1).
The characterization of channel-supermodular entropies is linked to
supermodular functions over the real lattice. These functions and some basic properties are introduced next. For details about supermodular functions please refer to [
49] and [
50] (Chapter 6.D).
Consider the set
of all
n-dimensional vectors with no negative entries (i.e., the non-negative orthant of
). Let ⪯ represent the element-wise inequality, that is, given
and
,
iff
for all
i. ⪯ is a partial order on
. In fact ⪯ defines a lattice over
, whose join ∨ and meet ∧ operations are defined as:
Recall that:
Definition 4. A function is supermodular
(over a lattice) if, for all , Next, we introduce some fundamental definitions for this work:
Definition 5. Let be a core-concave entropy. Define the function asif is not the null vector, and . (Notice that, as F is continuous over a compact set, .) Definition 6. An entropy is said to be channel-supermodular if is supermodular. The set of channel-supermodular entropies is noted by .
The motivation for defining channel-supermodularity in terms of
might seem arbitrary, but it is justified for its relationship with conditional entropies, given by
Together with (
2), the supermodularity of
can be a powerful tool for deriving results regarding conditional entropy and mutual information for entropies in
.
3.1. Examples of Channel-Supermodular and Non-Channel-Supermodular Entropies
In the next sections, we will study the implications of channel-supermodularity. The inequality in Definition 4 implies interesting behaviors regarding
H-mutual information, as will be seen in
Section 4. This property has immediate consequences for channel ordering and channel design, as will be explored in
Section 5 and
Section 6.
One appealing aspect of channel-supermodularity is that some of the most commonly used entropies in the literature belong to
, including Shannon and min-entropy, and more generally the Arimoto–Rényi entropies. In this section, we prove that these (and other entropies) indeed belong to
, and provide examples of entropies that do not. First, we state a useful characterization of supermodular functions, which is an immediate consequence of Corollary 2.6.1 in [
49].
Let
and let
denote the canonical basis of
. The function
is supermodular if and only if, for all
, all
and all
with
,
Moreover, if
has second partial derivatives,
is supermodular if and only if, for all
and all
with
,
The property characterized by Equations (
3) and (
4) is known in the economics literature as
increasing differences [
49]. This name is due to the effect an increase on a coordinate has on the value of
being monotonically increasing with regard to the other coordinates. This is readily noticeable if we rearrange the terms of (
3):
That is, the change of
prompted by an increase of
in coordinate
i is greater the greater the value of coordinate
j. Equation (
3) is thus just the statement that on the lattice
increasing differences and supermodularity are equivalent concepts ([
49] Corollary 2.6.1).
Using this result, as well as appealing directly to Definition 4, we now prove channel-supermodularity for a number of commonly used entropies. Throughout, given , we denote by its ith coordinate.
Proposition 2. - 1.
Shannon entropy is channel-supermodular.
- 2.
Arimoto–Rényi entropies are channel-supermodular for all .
- 3.
For any k, the k-tries entropy is channel-supermodular. In particular, min-entropy is channel-supermodular.
- 4.
Guessing entropy is channel-supermodular.
Items 3 and 4 of Proposition 2 are of particular interest to security applications, as guessing entropy and k-tries entropies have found interesting applications in the field of quantitative information flow.
Guessing entropy is especially useful in scenarios modelling brute-force attacks, as it models the expected number of attempts necessary for an adversary to obtain the value of a secret when trying one by one. On the other hand,
k-tries entropy reflects the probability of guessing a value correctly when
k guesses are allowed (see e.g., [
19] (Section III.C)). It is defined as
and can be readily seen to be core-concave by taking
and
. Notice that min entropy is equal to
when
.
The results in Proposition 2 justify our interest in channel-supermodularity, as any property derived for entropies in will also hold for this set of commonly used entropy measures. However, not all entropies are channel-supermodular.
This includes another interesting entropy family useful in security, the
partition entropies [
19]. Let
be a partition of the set
. The partition entropy with regard to
is given by
It is easy to see that is core-concave, by taking and . The partition entropy is useful for capturing the uncertainty of an adversary that is interested in knowing only to which subset the realization of X pertains. This is an appropriate model for adversaries that are interested in obtaining some specific partial knowledge about some sensitive information (e.g., obtaining the home town or the DOB of a user).
Proposition 3. - 1.
Hayashi–Rényi, Tsallis and Sharma–Mittal entropies (with conditional forms as in Table 1) are not channel-supermodular for all whenever the input set is of size greater than 2. Moreover, they are also not channel-supermodular for all for some size of input set. - 2.
The partition entropy is not, in general, channel-supermodular.
Notice that, for some choices of , is channel-supermodular. In particular, if , coincides with min-entropy.
A generalization of partition entropy is the
weighted partition entropies,
where
is a set of weights. Being a generalization of partition entropies, weighted partition entropies are also not channel-supermodular in general.
4. The Join-Meet Operator and a New Structural Order
In this section we address the claim made in
Section 1, proving that the
Join-Meet operation is monotonic with regard to conditional entropy for all channel-supermodular entropies.
Let
be a channel, with
, and let
be the column of
K corresponding to output
. Define, for
, the
Join-Meet operator
as follows:
The next result proves that the Join-Meet operator is monotonic with if .
Theorem 4. For all channels and all , .
Proof. Let
and define
as in Definition 5. Let
, and denote by
,
the outputs of
,
. Notice that, for any distribution on the input, we have
, and, similarly,
. Thus,
where the inequality follows from
being supermodular. From Equation (
2) and
being increasing, it follows that
, which is equivalent to
. □
In light of Theorem 4, one might wonder if the Join-Meet operator completely defines —that is, whether whenever for all channels K and all . In fact, an even stronger statement can be made by only considering a subset of channels.
Definition 7. Let denote the channel with input alphabet and output alphabet , given by Theorem 5. Let . If for all , and all , , then .
Proof. We prove the contrapositive. Suppose that
. Then, from (
3), there are
,
with
and
such that
Let
and define a probability distribution over
X by
Let
and
, and let
,
. Then,
and thus, as
is strictly increasing,
, which concludes the proof. □
An immediate consequence of Theorems 4 and 5 is that the Join-Meet operator completely characterizes .
Corollary 1. Let . if, and only if, for all channels K and all .
A New Structural Ordering
Theorem 4 yields some immediate new results for reasoning about channel ordering, as, whenever
, the Join-Meet operator is not, in general, captured by the degradedness ordering. Consider, for instance, the following channels
,
(notice that
).
Then, we have that
, but clearly
. To see this, fix a channel
. Because
R is a channel, there are
such that
Therefore, for any choice of .
We formalize this observation in the next result.
Proposition 4. - 1.
If , then, for all and all , .
- 2.
If , then there are and such that .
Proof. We first prove (1). As it is possible to reorder columns by degrading a channel, without loss of generality let and . Fix . Let , and suppose, again without loss of generality, that and .
If
or
, then
is obtainable by permutating columns of
K, and therefore
. Otherwise, we have
, and
where
R is the following channel:
For the proof of (2), it suffices to notice that, whenever
,
. The proof for general
is along the same lines of the argument after (
5). □
Next we define the channel-supermodularity preorder over channels, which is based on the Join-Meet operators .
Definition 8. if there is a finite collection of tuples such that An induced preorder can be then defined by combining and as follows:
Definition 9. if there are channels such that , where each stands for or .
5. Relations between Preorders for Channel-Supermodular Entropies
Throughout this section, let and . First, note that Proposition 1 and Theorem 2 are still meaningful under . The next proposition summarizes the relationship between and the other preorders.
Proposition 5. - 1.
and ,
- 2.
,
- 3.
,
- 4.
,
- 5.
,
- 7.
,
- 8.
,
- 8.
,
- 9.
.
Proposition 5.7 can be used to decide whether
, for
, by only using structural properties of the channel. Consider, for example, the following channels
,
.
In [
19], the authors claimed to have no proof that
. By Proposition 5 (7),
can be proven as follows:
Notice that if is substituted for , Theorem 3 does not hold:
Proposition 6. and .
Proof. From Proposition 5 (2), there are channels , such that and . For such channels, Proposition 5 (7) implies , and the first result follows. The second result then follows by noting that Proposition 1 and Theorem 2 imply . □
Proposition 7. .
Results on Channel Capacity
In [
1], Shannon proved that
. We can use Theorem 4 to prove similar results for the preorder
, which is an extension of
with
.
Definition 10. if there are channels such that where each stands for or .
We have:
Proposition 8. For all channels ,
- 1.
,
- 2.
,
- 3.
,
- 4.
.
Proof. (1) and (2) follow immediately from the definitions of and , and from observing that . (3) and (4) follow from (2) and Propositions 5 (3) and 5 (8). □
In the remainder of this section, we prove that is a sufficient condition for establishing that both the Shannon and min-capacity of are at least as large as that of .
Lemma 1. Let . If , then .
Proof. Let . From Propositions 1, 5 (1), and 5 (7), . The result then follows from Definition 10. □
Proposition 9. - 1.
,
- 2.
,
- 3.
and .
Figure 1 summarizes the implications between orderings. As can be seen, there are some open questions that need to be established, designated by dotted lines with a question mark. Note that the absence of an arrow means that the implication is known to be false.
6. Channel Design
Core-concavity was originally introduced in [
51] in the context of universally optimal channel design—that is, the problem of finding, given some operational constraints, a channel leaking the minimum amount of confidential information (optimality), for all entropy-based measures of leakage (universality). This section shows how core-concavity and channel-supermodularity can be used in this context.
If X and Y are the input and output of a channel and H is a core-concave entropy, then the leakage about X through Y as measured by H is defined to be the H-mutual information , as in Definition 3.
The concept of leakage is relevant in security/privacy contexts where X is some confidential data, K is modelling a system (e.g., a cryptographic computation or a database query system), and Y some observable generated by the system (e.g., the computation time or the result of a statistical query). Different H corresponds to different attackers’ models, and universal channel solutions identify countermeasures to leakage which are robust with regard to all attackers in that universe.
Minimizing leakage of sensitive information is usually a desirable goal. However, when designing systems, it is often the case that some leakage is unavoidable. With that in mind, some recent works in QIF aimed at obtaining channels that leak the least amount of information subject to some operational constraints [
13,
28,
29]. From Definition 3, the problem can be rephrased as finding the channel which, subject to some operational constraints, maximizes
— or, as
is increasing, maximizes
. In a recent work [
29], which considered a generalizing framework for these operational constraints, it was shown that this problem can be solved by convex optimization techniques, for a given core-concave
H. However, it was also proven that the solution to the problem is in general not
universal—that is, the optimal channel given a set of constraints may vary with the choice of
H.
Despite this negative result, it was shown in [
29] that some classes of problems admit a universal solution. As different entropies model different attackers, these results provide a very strong security guarantee—namely, that the optimal system in these situations is the most secure possible regardless of the attacker model. In the next few sections, we show how channel-supermodularity can be a useful tool in obtaining solutions that, while not universally optimal for all core-concave entropies, are the most secure for all symmetric entropies in
.
6.1. Deterministic Channel Design Problem: A Universal Solution by Channel-Supermodularity
In many applications, such as repeated queries, it is either undesirable or impractical to consider a “probabilistic” system. This motivates the study of the channel design problem restricted to
deterministic channels, which has been recently investigated in [
13].
It was proven in [
13] that, similarly to the general channel design problem, the deterministic version does not in general accept a universal solution. Moreover, the problem was also shown to be, in general, NP-hard. However, it was also proven in this work that a specific class of problems, called the
deterministic complete k-hypergraph design problem, admit a solution that is optimal for all symmetric channel-supermodular entropies. This problem can be defined as follows.
Definition 11. Let , and let be finite sets with
The deterministic complete k-hypergraph design problem (CKDP) is to find a channel that maximizes , subject to the following constraints:
, and
.
That is, the deterministic CKDP is the problem of finding the most secure deterministic channel, subject to the constraint that each output can only be generated by at most k inputs.
For the remainder of this section, let , and fix a distribution such that, without loss of generality, whenever .
The greedy solution proposed by [
13] is described in Algorithm 1. The algorithm is straightforward: it associates the
k most likely secrets with the first observable; it then associates the
k most likely secrets among the remaining secrets with the second observable, and so on. The solution for
and
is depicted in
Figure 2.
| Algorithm 1 Greedy algorithm for the k-complete hypergraph problem |
Input: Input set , prior and integer
Output: Matrix of optimal deterministic channel |
| 1: initialize: as a matrix of 0s, with rows and columns. |
| 2: for do |
| 3: |
| 4:return |
Theorem 6 ([
13]).
Given a complete k-hypergraph channel design problem, the solution given by Algorithm 1 is optimal for any symmetric channel-supermodular entropy. Proof. We reproduce the proof of this theorem from [
13], as it provides an interesting application of channel-supermodularity. Let us consider the following joint matrix
obtained by Algorithm 1 and the prior:
We now prove that any matrix J satisfying the constraints can be transformed into by a sequence of steps each increasing (or keeping equal) any supermodular entropy. Each step consists of the following three sub-steps:
Select two columns and align the non-zero coefficients in ;
Perform operations on the aligned columns and replace with ;
Disalign the two columns .
The following example illustrates one step (i.e., the three sub-steps above):
from left to right we have:
selected , which are the two columns containing the two most likely priors (i.e., 0.4 and 0.3) and aligned so that 0.4, 0.3 appear in different rows;
replaced with ;
disaligned columns 2 and 3, that is, position values in , so that each row has the same probability it had before the step.
Notice that aligning (and disaligning) is a permutation of a column; hence, they do not change the value of the posterior of symmetric channel-supermodular entropies because for any permutation of the column .
Next, for the remaining sub-step, where we replace with , by supermodularity of G we have ; hence, that sub-step increases (or keeps equal) the posterior entropy. Notice also that the matrix at the end of the step has in each row the same probabilities as it had before that step; hence, it is still a joint matrix that respects the complete k-hypergraph constraints for the same prior.
The selection and alignment of columns is as follows: at the initial step select such that contains the first r elements with the highest probabilities, say ; if , then select as the column containing ; align so that is not on the same row as any of the (and has no more than k non-zero terms). Then, will contain . Repeat until . Then repeat the process considering the probabilities .
By repeating these steps, we will reach a matrix with columns such that each element of column has higher probability than all elements of column . This is exactly the solution given by the greedy algorithm (modulo column permutations), that is, . □
If
H is not channel-supermodular, the greedy solution may not be optimal. Consider, for example, the Hayashi–Rényi entropies, which are not channel-supermodular. Let
,
and
, and consider the channels
with outputs
below.
Then,
is the greedy solution. However, for Hayashi–Rényi entropies, the following limit holds [
52]:
Thus, for large enough , and the greedy solution is not optimal.
Another example of core-concave functions for which Algorithm 1 is not optimal is provided by “partition” entropies. For example, if
B is a partition of the possible values of
X then
is a core-concave entropy which is not channel-supermodular.
6.2. An Application to Query Anonymity
Let us consider the following anonymity mechanism problem: we want to design an anonymity mechanism where in order to conceal a secret query from an eavesdropper, the user sends to a server a set of k queries which includes the secret query. Then, once received from the server the response to all the k queries, the user retrieves the response to the secret query. In our setting, this corresponds to each observable having a pre-image of size exactly k.
As an illustrative example consider a Twitter user who wants to visit some other Twitter user page but wants to keep this query secret. To solve this problem, he decides to use the following protocol: whenever he visits the desired user page, he also sends other queries to the pages of other Twitter users. Suppose further that this user frequently visits this user’s page, meaning that a random choice of the other queries is not a wise strategy, since multiple observations would end up revealing more and more information about the query, eventually completely revealing the secret query. The problem is then: which set of k Twitter pages will leak the least information about the user secret query?
We assume the attacker has no background information about the user, and hence we set the probability of a Twitter query for that user as the probability that a general member of the public requests that Twitter page (a good proxy to this measure can be derived by the number of followers of that Twitter page). Let n be the number of possible queries (i.e., the input set). Considering the scenario that n is divisible by k, we can use Algorithm 1 to solve this problem.
Notice that for
n secrets, there are
possible ways to satisfy these anonymity constraints. For example, there are about
possible solutions when
and
, and about
for
10,000 and
. We will now compare the greedy algorithm in
Section 6 against other possible anonymity solutions, and we will measure the goodness of the solutions using min and Shannon posterior entropies. Let us consider the three anonymity solutions below:
the solution from the greedy algorithm (Algorithm 1) (i.e., pick the queries closest in probability to the real query);
a random solution (i.e., pick k random queries);
a non-optimal solution where the secrets with the highest probabilities, instead of being grouped in the first bin, are distributed in the other bins.
For example, for 6 secrets and , the greedy solution would be , whereas the non-optimal solution (3) would be .
The difference between these solutions can be very substantial.
Figure 3 shows the values when the distribution over the input set is a binomial distribution, with parameter
: in this scenario, supposing that there is a universe of 350 Twitter pages and that the user sends 19 queries selected using the greedy algorithm, the probability of an attacker guessing the secret query correctly would be over 7 times smaller than if the user had opted instead for the non-optimal solution (using
as the conversion formula from posterior min entropy to probability of guessing). In fact, it is easy to define an input probability distribution such that the leakage gap between the non-optimal solution and the optimal solution given by the greedy algorithm is arbitrarily large.
Note that, by Theorem 6, the greedy solution is in fact optimal for all channel-supermodular entropies. Hence, the user knows that the greedy solution is optimal against an attacker trying to guess his secret query in a fixed number of guesses, or using guesswork or guessing using a twenty-questions-style guesswork (reflecting Shannon entropy), and so on.
6.3. Query Anonymity for Related Secrets
Consider the scenario where a user who wants to query the Twitter page of some political commentators is at the same time interested in hiding his own political affiliation, which could be leaked by his queries. In this scenario, the solution from Algorithm 1 might be sub-optimal. To see this, suppose that the k queries in the real query’s cover end up being all affiliated to the same party. This would thus reveal the user’s political party to the attacker with certainty even though the real intended query is still uncertain. This is not a contradiction to the optimality of the algorithm. As such, an adversary would be better modeled by a partition entropy—with political commentators (the queried users) grouped by party affiliation—and, as established in Proposition 3, this type of entropy is not channel-supermodular in general.
Motivated by this scenario, we now give an optimal solution for all channel supermodular entropies (even if not symmetric) to deal with this kind of problem. Suppose there are k political parties, and l commentators aligned with each party. Suppose, further, that the user is affiliated to one of the parties, and would like to check the profiles of his party’s commentators without revealing his own affiliation.
To achieve this aim, the user decides to group the political commentators in covers of size
k, each cover containing exactly one commentator from each party, and then proceed to use these covers similarly to the mechanism described in
Section 6.2, by querying the entire cover (fetching the pages of all the commentators in the cover). The question is: what is the set of covers that reveal the least amount of information about the user’s political affiliation?
Let
be the set of parties,
be the set of commentators, wherein
is the
jth commentator of the
ith party, and let
be the set of covers. Let
be the channel giving the conditional probability of a user choosing to query a commentator given the user’s party inclination. We assume that the user only chooses commentators that share the same affiliation as his, that is,
whenever
. For simplicity, we assume that the commentators are organized decreasingly with regard to this probability—that is,
We claim that the optimal mechanism, for all channel-supermodular entropies (with regards to the political parties, not the commentators), is to group the most popular commentators for each party in the first cover, then the second-most popular commentators for each party on the second, and so on. That is, the covers would be: , , …, .
Let
be the channel mapping each commentator to their cover, modelling the optimal solution described above. The matrix of this channel can be seen as a vertical concatenation of identity matrices:
The channel above is then obtained by postprocessing K by R.
The claim of optimally can be more formally stated as follows: given any channel-supermodular
H, any distribution
over the parties, and any other deterministic covering
in which there is exactly one commentator from each party per cover, the resulting channel
will never leak less information than the channel
in (
7). That is,
The proof that the covering
R above is indeed optimal for all channel-supermodular entropies is similar to the proof of Theorem 6, but even simpler. Suppose the channel
is any covering that satisfies the restriction that each cover has exactly one commentator from each party. Now, consider the channel
, and proceed as follows: first, do the Join-Meet operation of the first column with all the other columns (that is, obtaining the channel
). Now, disregarding the first column, the process is repeated for the second column with all the remaining ones. It is easy to see that the resulting channel will be exactly
in (
7).
As an example, let
,
, and suppose the non-zero values of
K are:
and suppose that the covers that are defined by
are
,
, and
. We have
By doing the Join-Meet operations on the first column with the others, we obtain
Finally, by doing the Join-Meet of the second column with the remaining one, we have
which is exactly the optimal solution given by (
7).
7. Conclusions
In this work, we introduced the notion of channel-supermodular entropies, as a subset of core-concave entropies, which include guessing and Arimoto–Rényi entropies. We demonstrated that, for this new classification of entropies, the Join-Meet operator on channel columns decreases the H-mutual information. This property prompted us to define structural preorders of channels (), providing novel sufficient conditions for establishing whether two channels are in the H-more capable any channel-supermodular H or in the -capacity ordering. Moreover, this work establishes some relationships of these new structural preorders with other existing preorders from the literature.
As an example application, we used channel-supermodularity to prove an optimality result of a greedy query anonymization algorithm.
It is our belief that the connection between supermodular functions and some commonly used entropy measures, made in
Section 3.1, will prove useful for posterior investigations in information theory (for example, given the vast literature of supermodular functions over Euclidean space [
50] (Chapter 6.D) and [
49]). Further directions of work include investigating other useful properties of channel-supermodular entropies, and further applications of channel-supermodularity to anonymity.


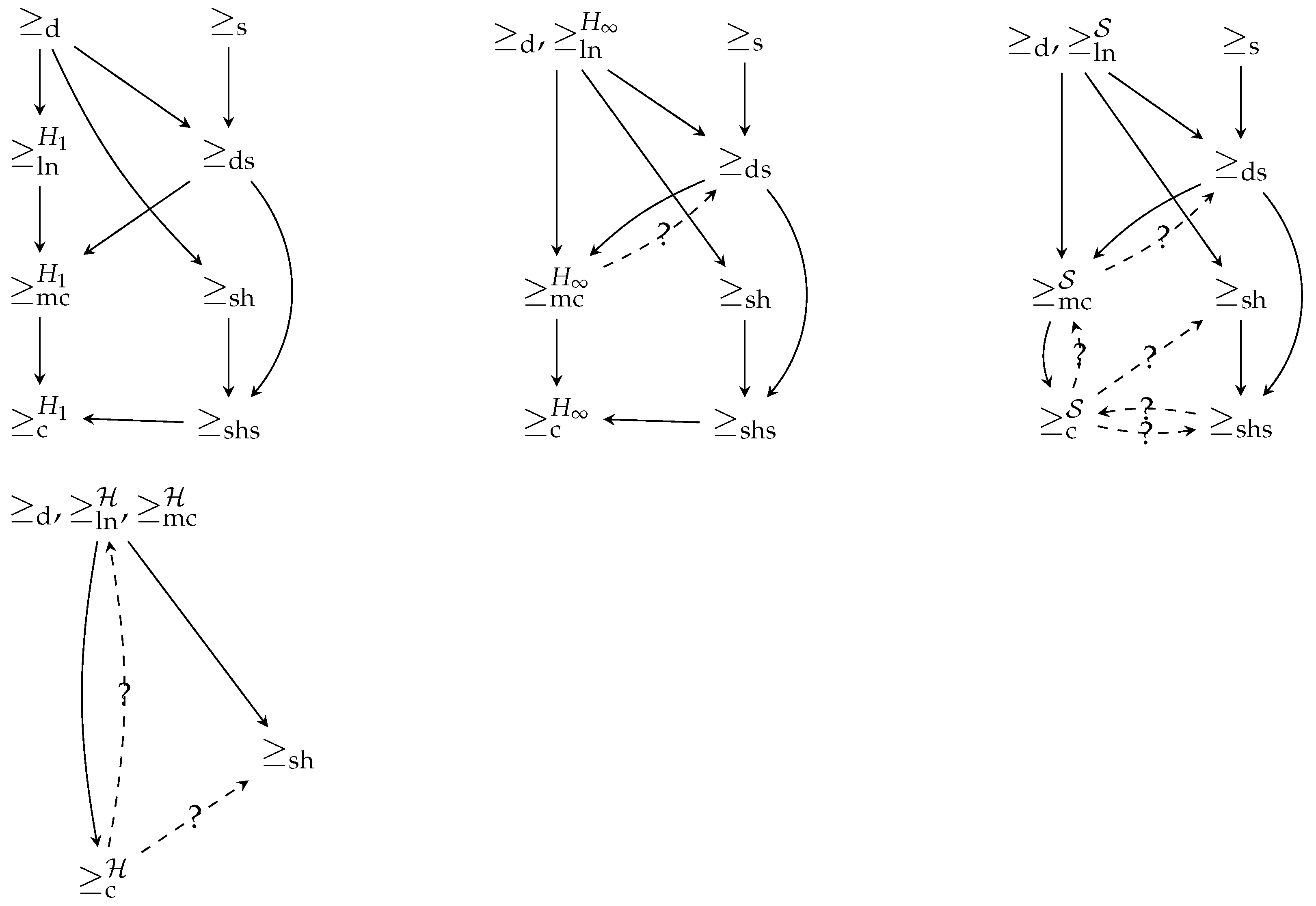



{kind=link}
{kind=link}
{kind=link}