

A Fault Detection Method Based on an Oil Temperature Forecasting Model Using an Improved Deep Deterministic Policy Gradient Algorithm in the Helicopter Gearbox

Abstract
:1. Introduction
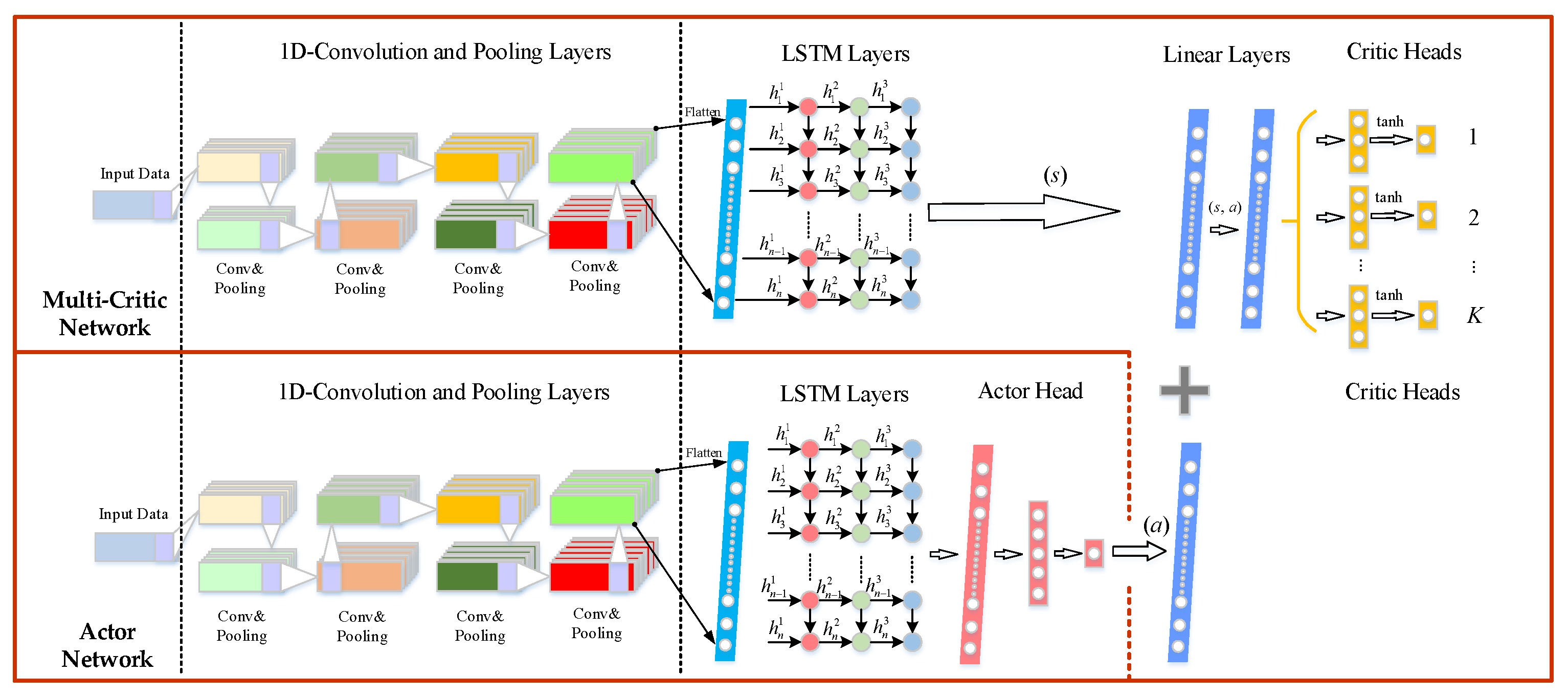
- An improved DDPG framework is proposed, namely multi-CRDPG, in which CNN–LSTM is used as a basic learner to sense the input working condition information of HMGB; thereby, the strong feature extraction ability of CNN and the advantage of LSTM in dealing with time series prediction are combined. DDPG is introduced as an RL framework for training the basic learner, which enhances the prediction ability to deal with the complex oil temperature series of the basic learner.
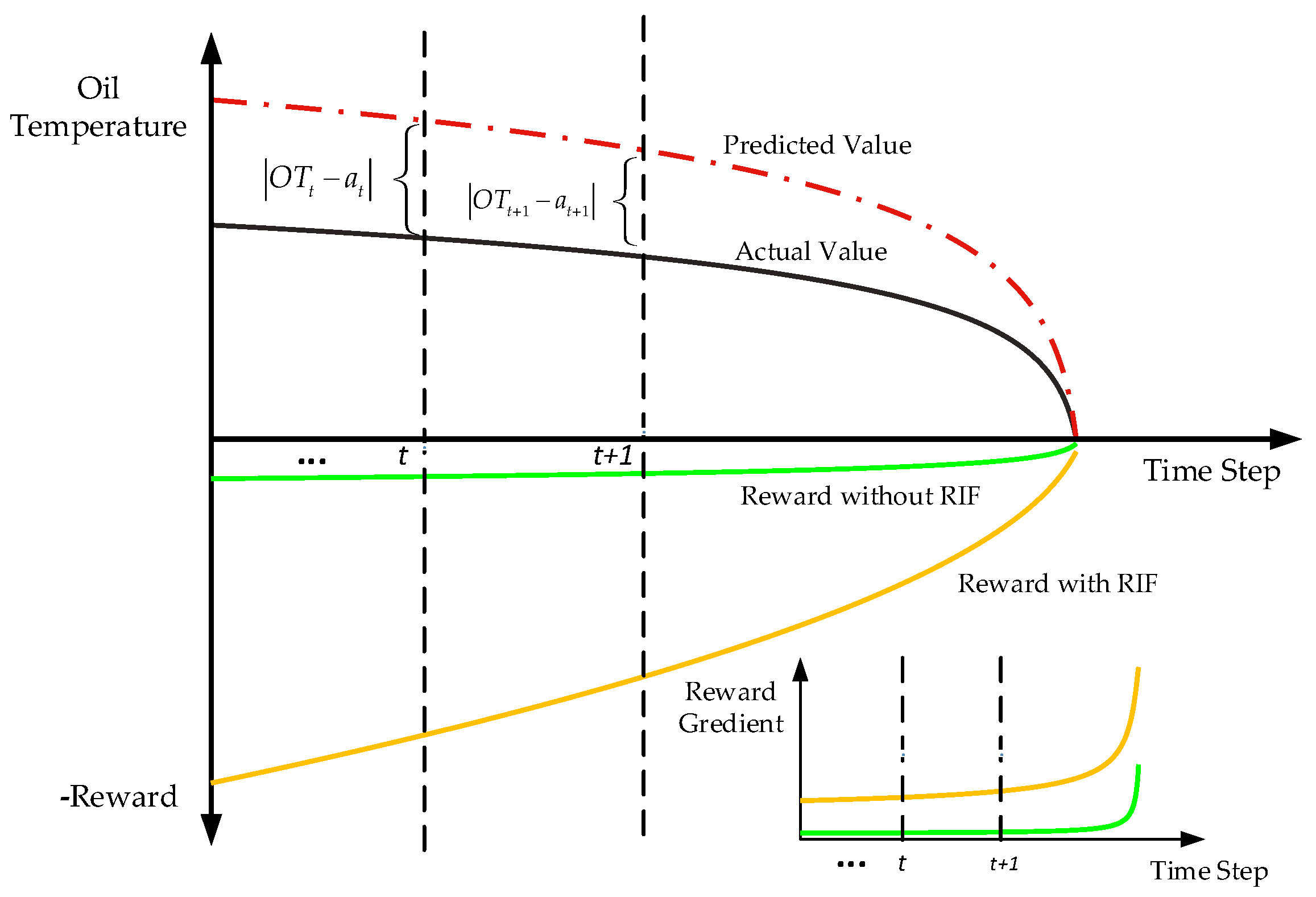
- A novel reward function is designed for educating the agent to output the predicted action as accurately as possible.
- An explore strategy is presented, in which agent are encouraged to actively explore the unknown space in the early stage of training and use the learned experience to gradually converge on the ideal output action in the later stage of training.
- In order to avoid the inaccurate estimation of the current state by a singer critic network and the inability to find the optimal strategy, a multi-critics network structure is advanced. A minimum and truncated mean processing method for a multi-critics network is conducive to reducing the deviation and variance of the estimated Q-value.
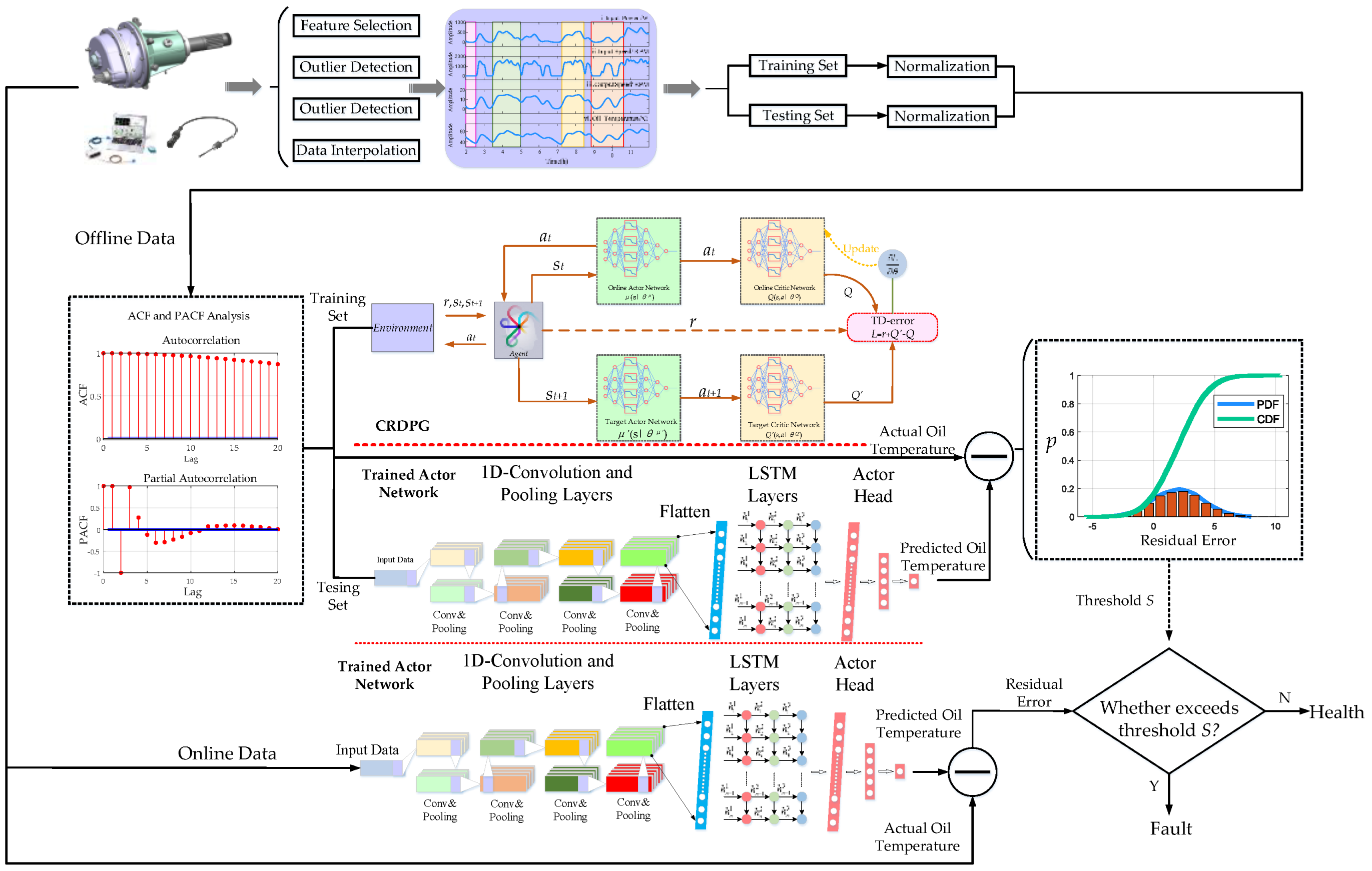
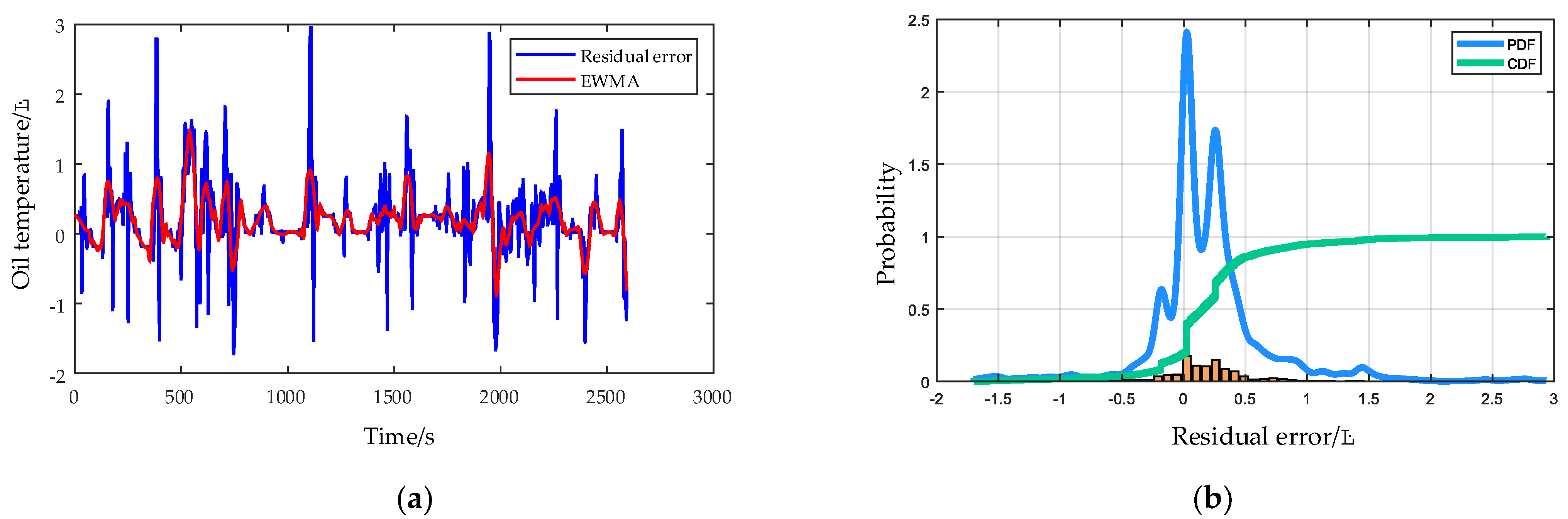
- KDE is used to calculate the probability density function of the prediction residual errors in the healthy state of a HMGB to determine the failure threshold, and the trend of residual errors generated by EWMA control chart is to judge the HMGB health degree in the monitoring process.
- The rest of this paper is organized as follows. Section 2 introduces the basic theories of the fault mechanism, RL, DDPG and CNN–LSTM algorithm. Section 3 provides the proposed multi-CRDPG algorithm. Section 4 describes the implementation details and experimental results ofthe mMulti-CRDPG in actual testing. Section 5 outlines conclusions and future works.
2. Basic Theories Involved
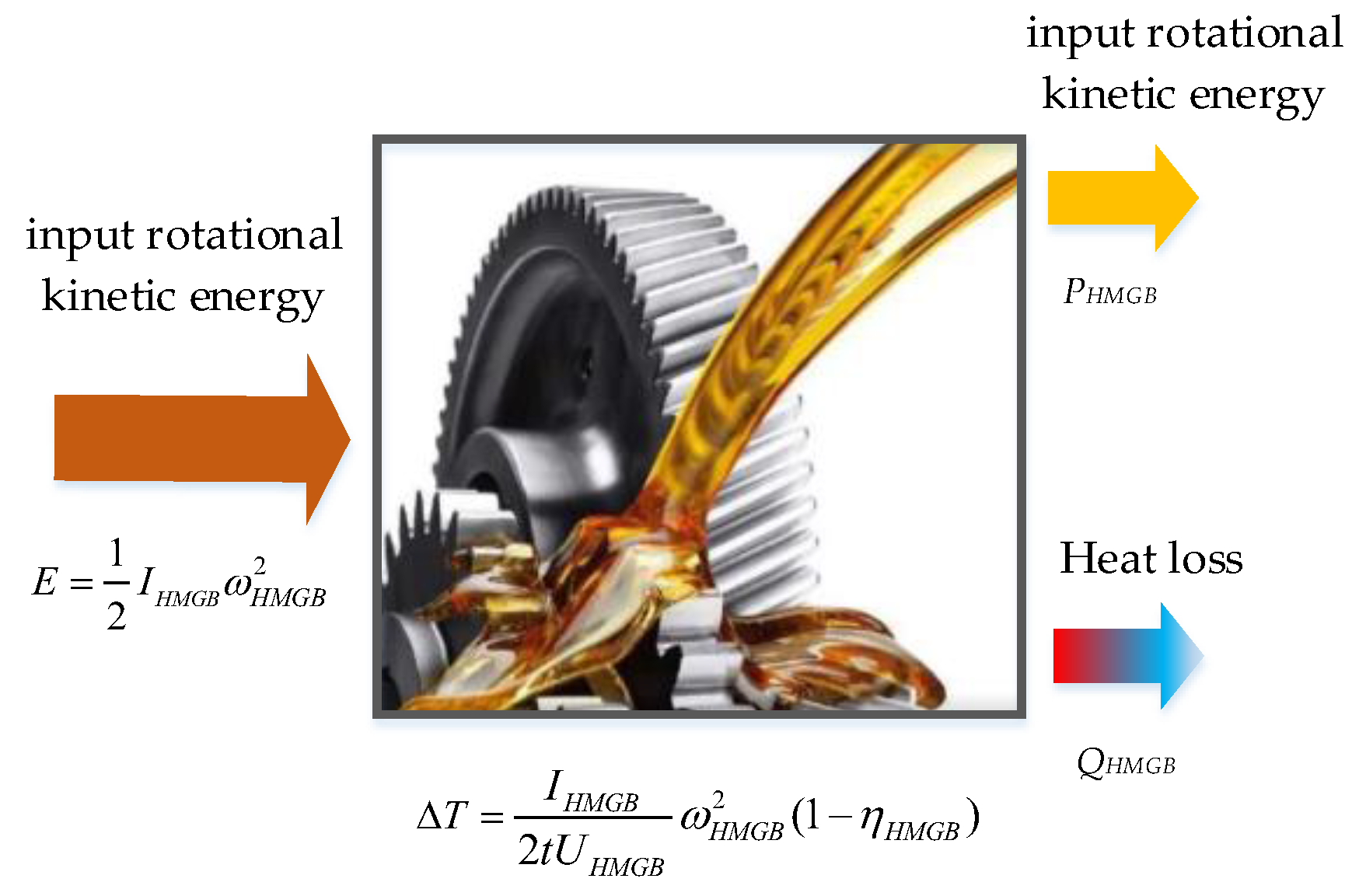
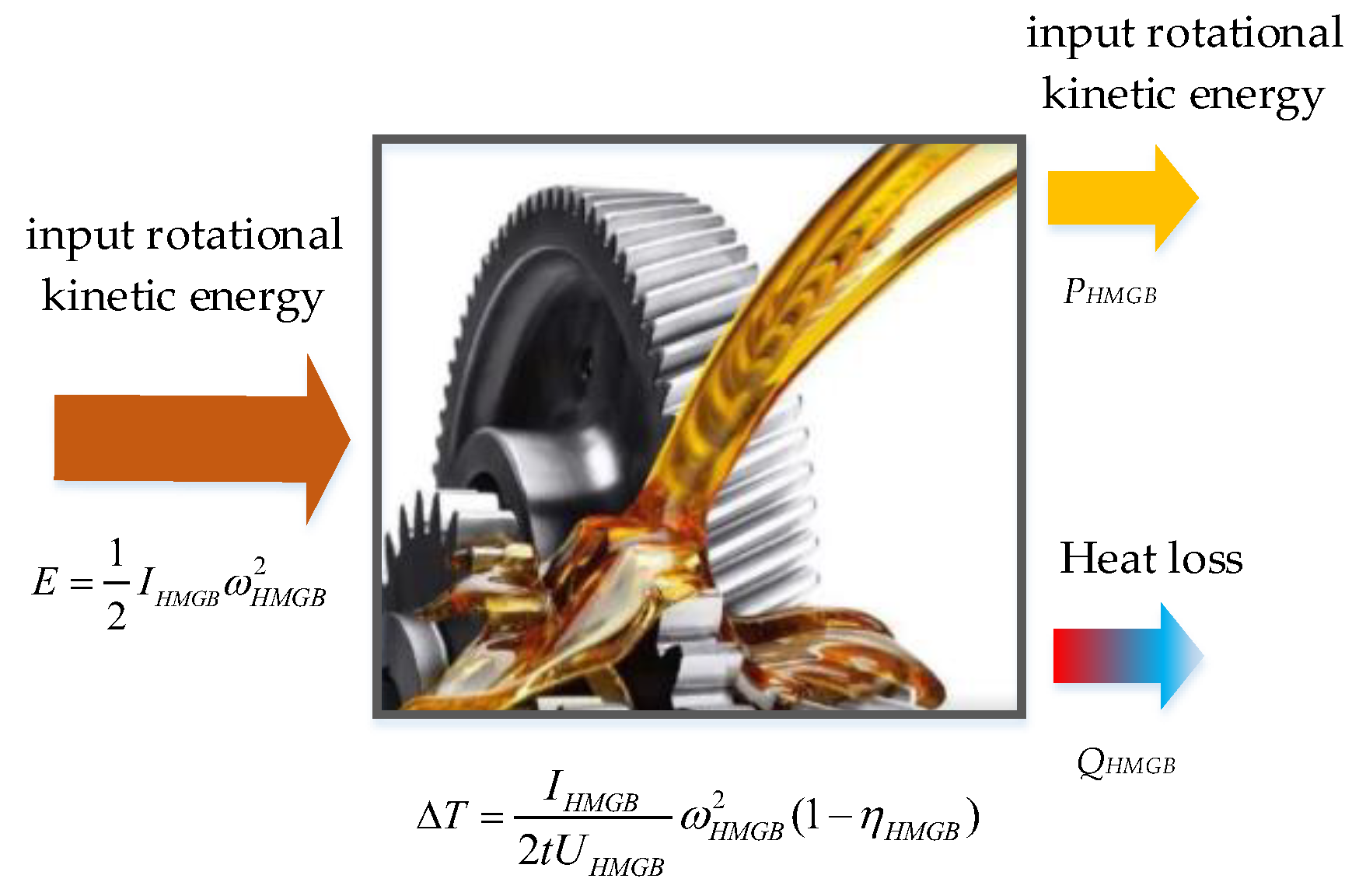
2.1. The Mechanism That Oil Temperature Can Reflect HMGB Health Degree
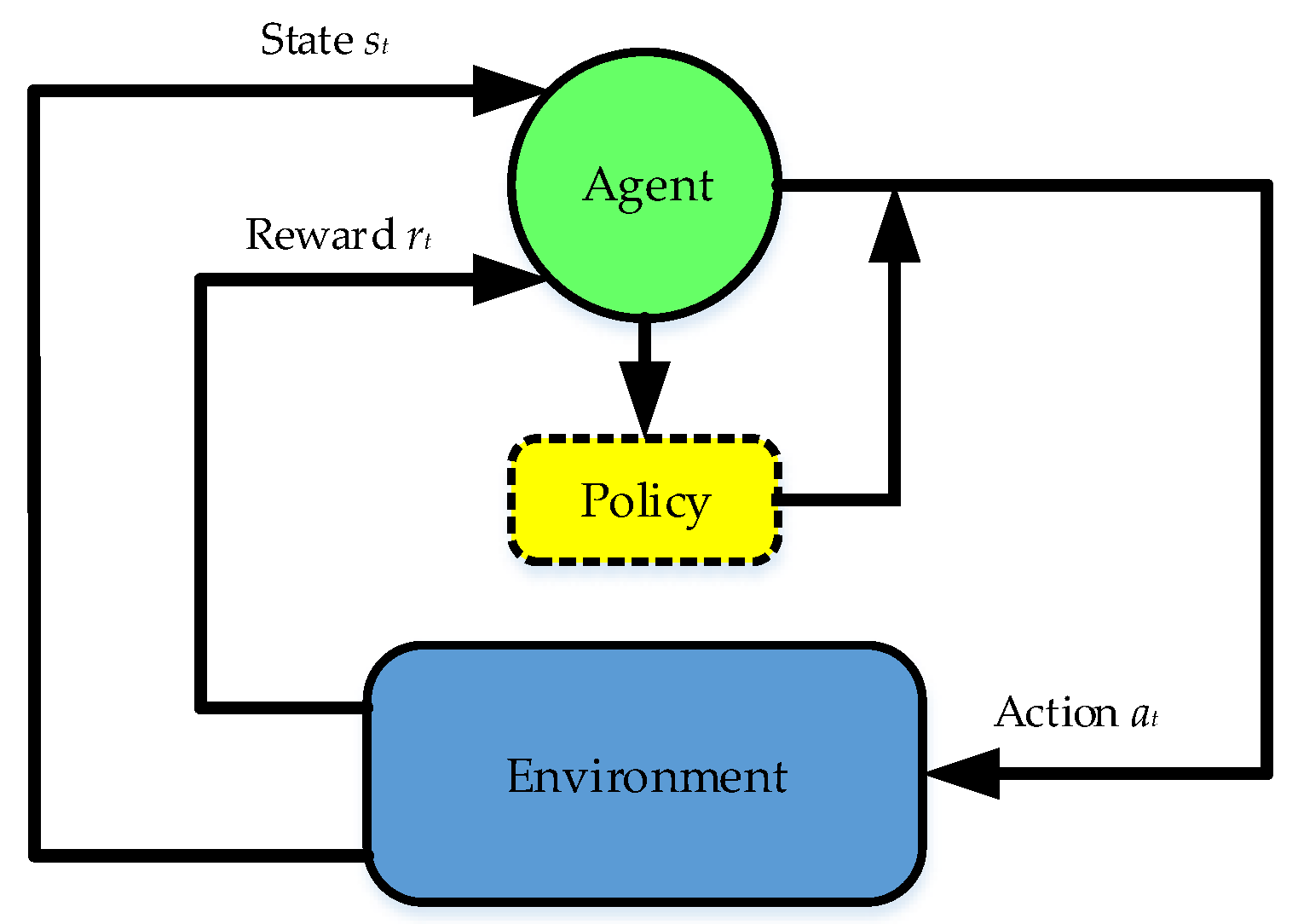
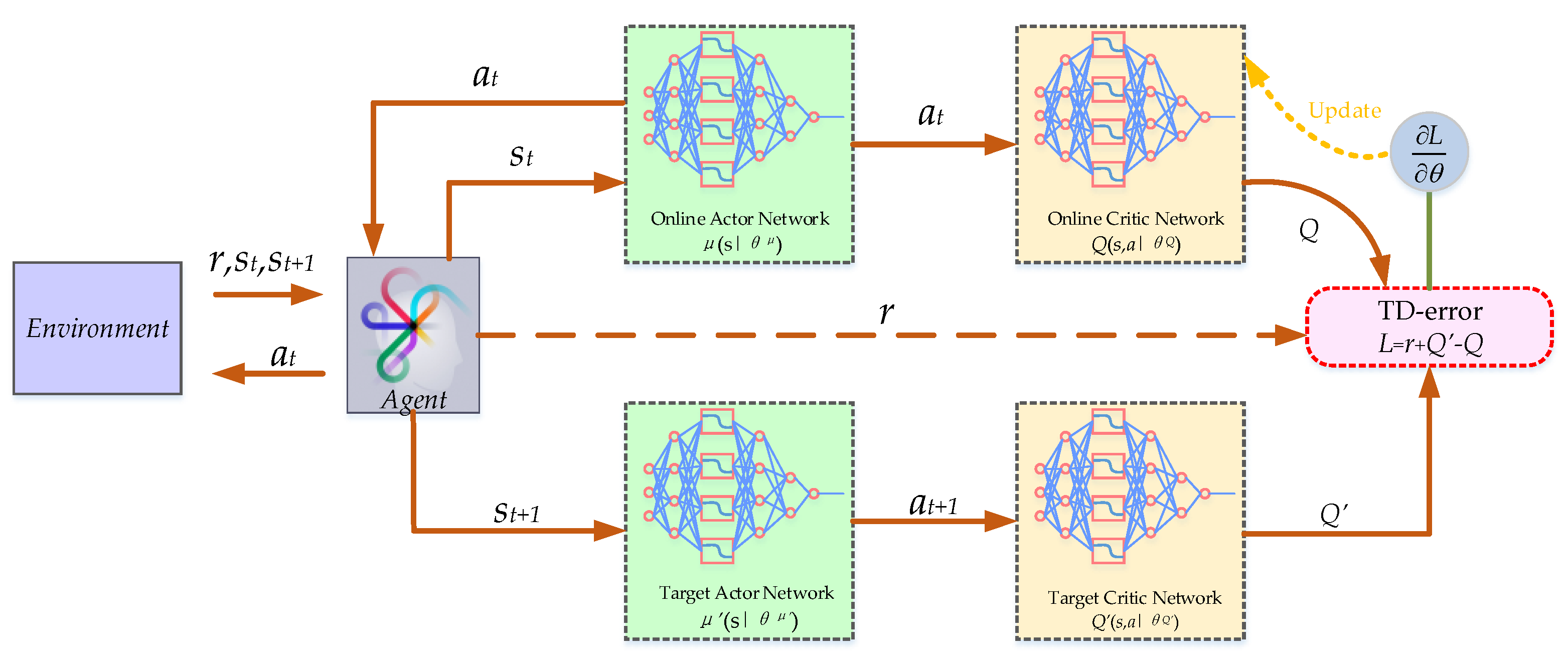
2.2. The Concept of the Deep Deterministic Policy Gradient Algorithm
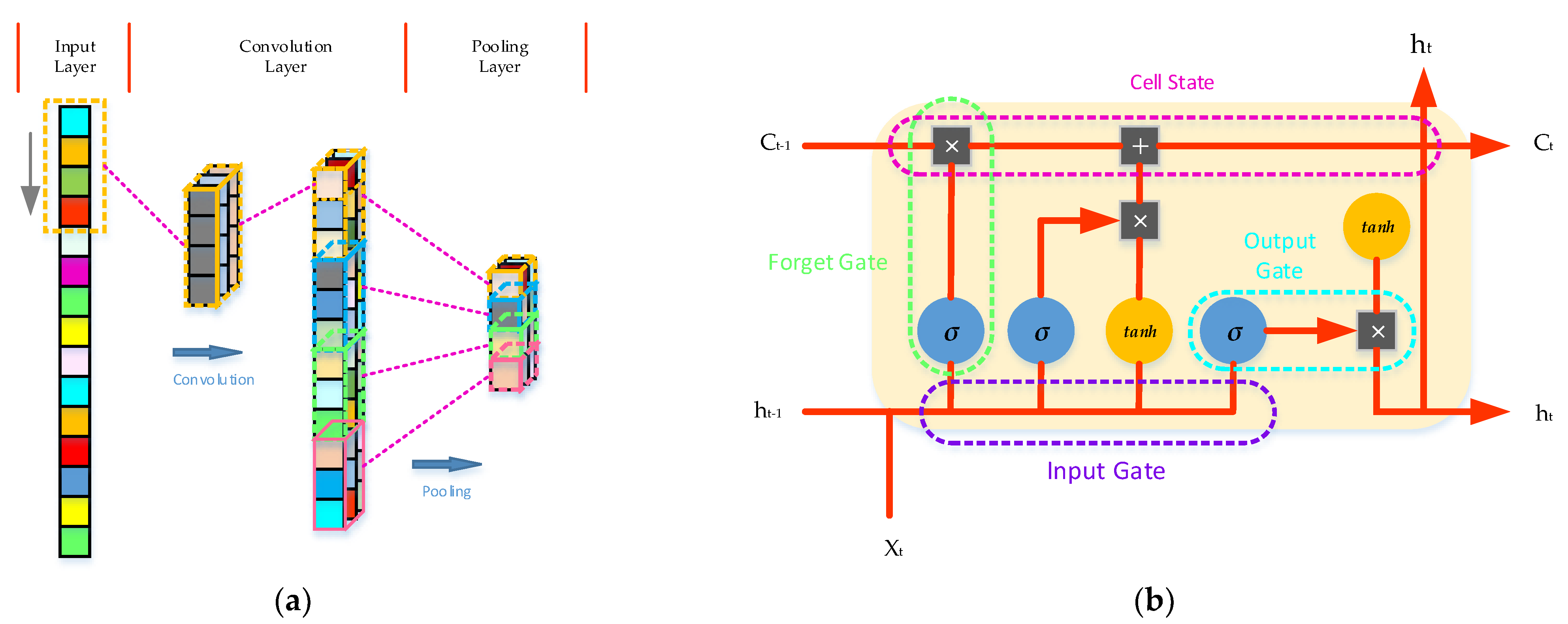
2.3. The Convolutional Long-Short Time Memory Neural Network
3. Improving DDPG for HMGB Condition Monitoring and Fault Detection
3.1. The Deign of Reward Incentive Function
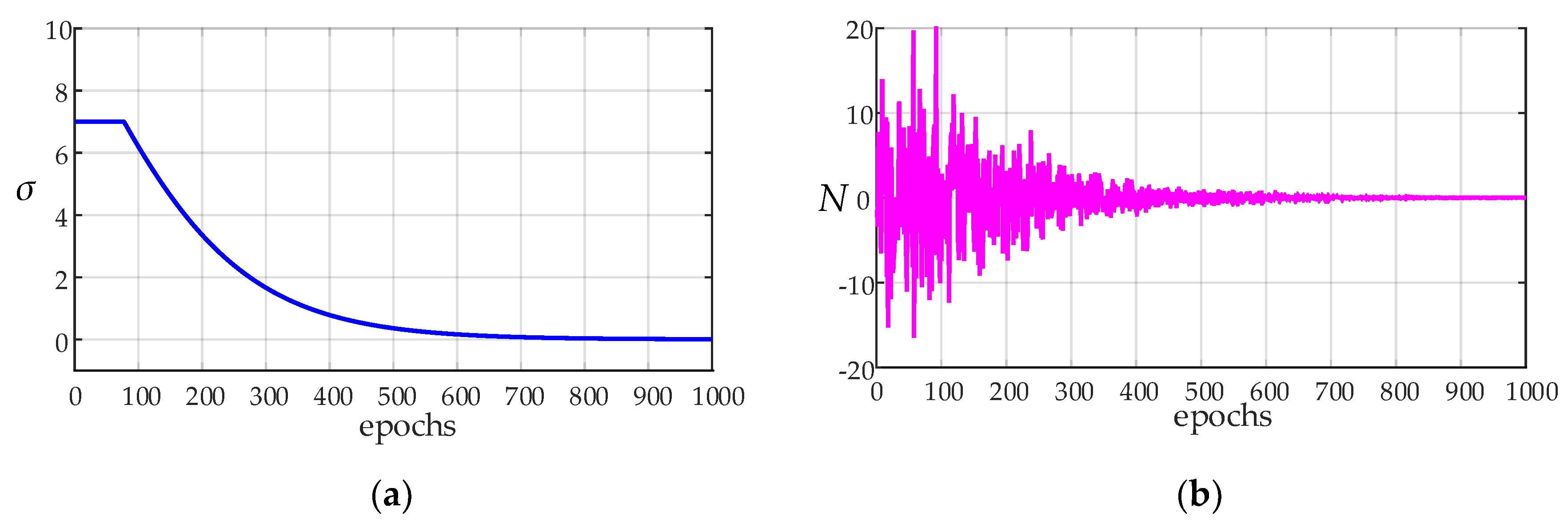
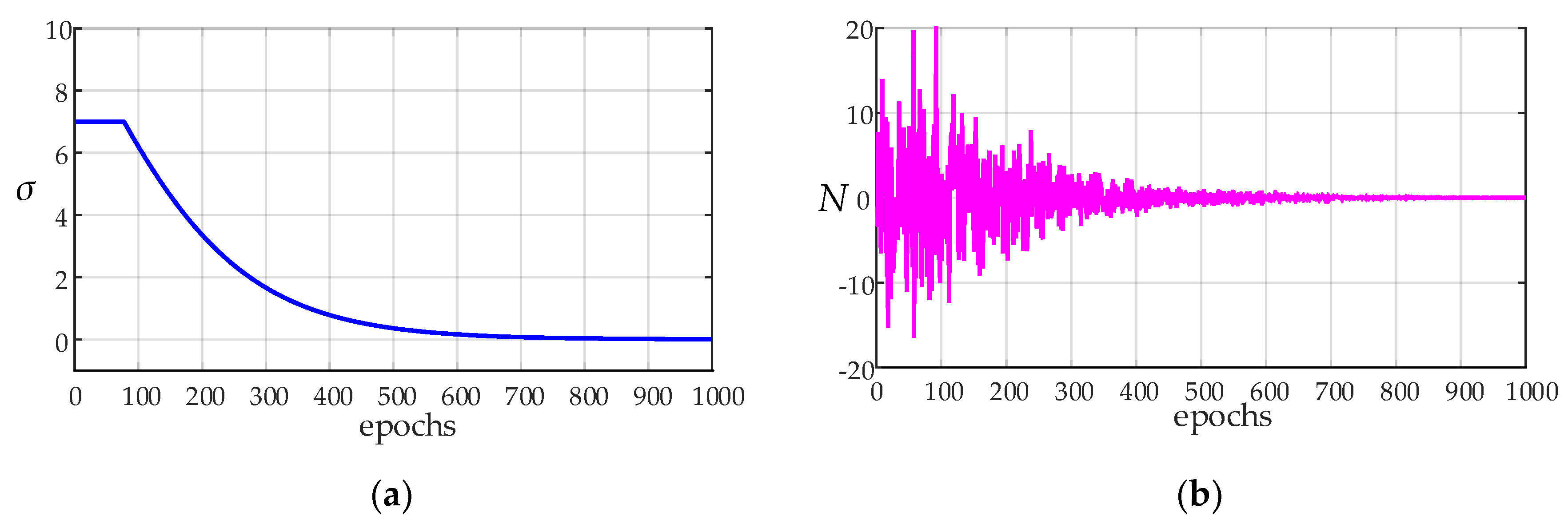
3.2. Variable Exploration Variance
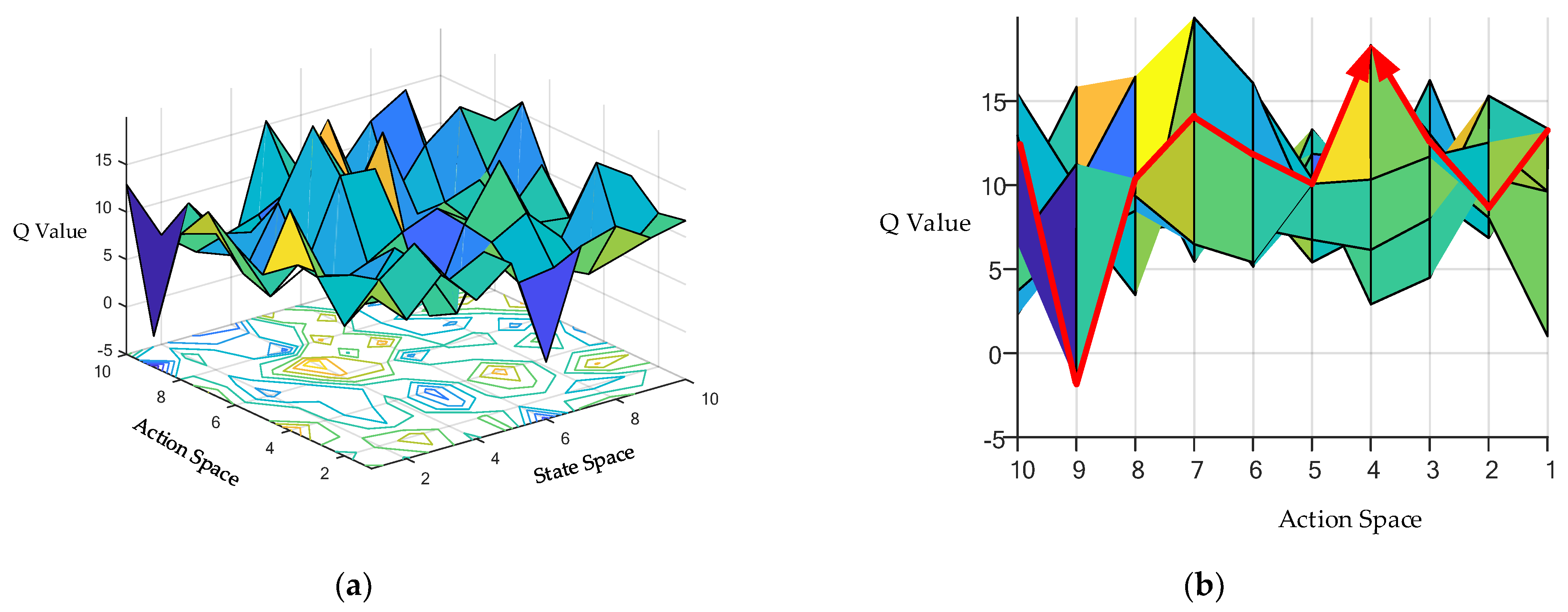
3.3. Multi-Critics Networks Structure
3.4. The Condition Monitoring and Fault Detection for HMGBs Based on Multi-CRDPG and EWMA
4. Experimental Verification and Results Analysis
4.1. The Establishment of an Oil Temperature Forecasting Model
4.1.1. Generation of Datasets
4.1.2. Performance Evaluation of the Model
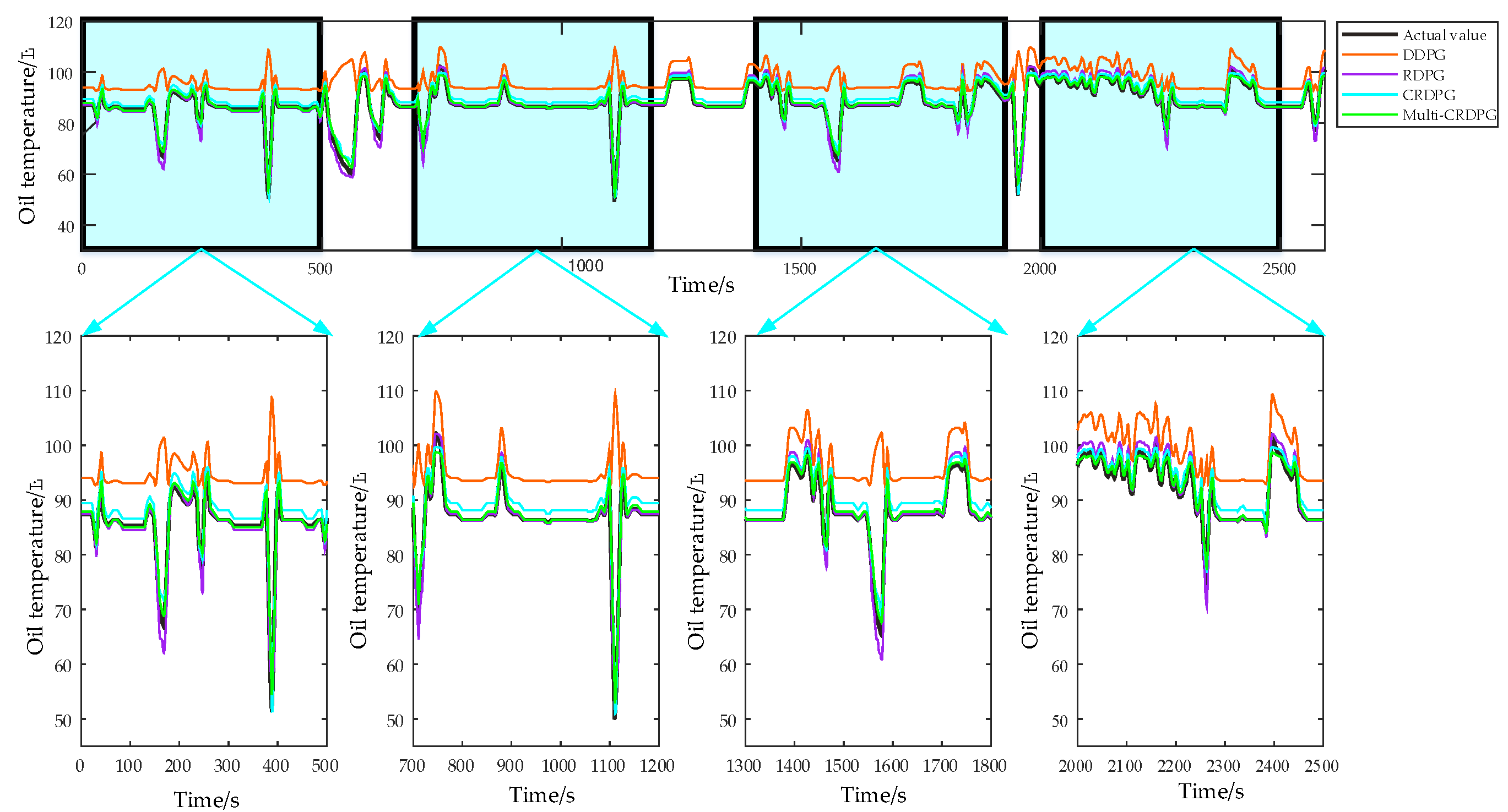
4.1.3. Performance Comparison of Different Models
- (1)
- LS-SVM: Penalty coefficient (C), kernel coefficient (gamma);
- (2)
- NARX: Input felays (ID), feedback delays (FD), hidden size (N);
- (3)
- ARIMA: AR/auto-regressive(p), MA/moving average (q), integrated(d)
- (a)
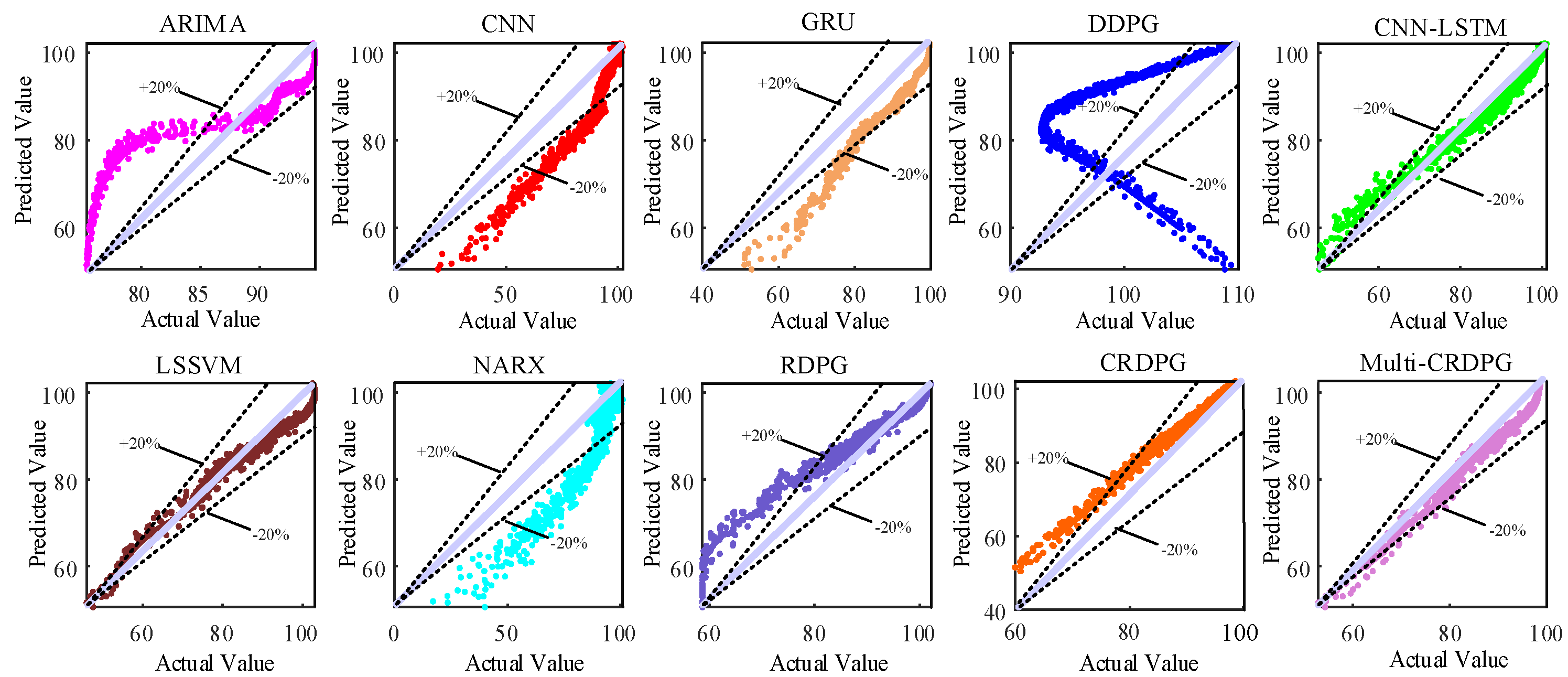
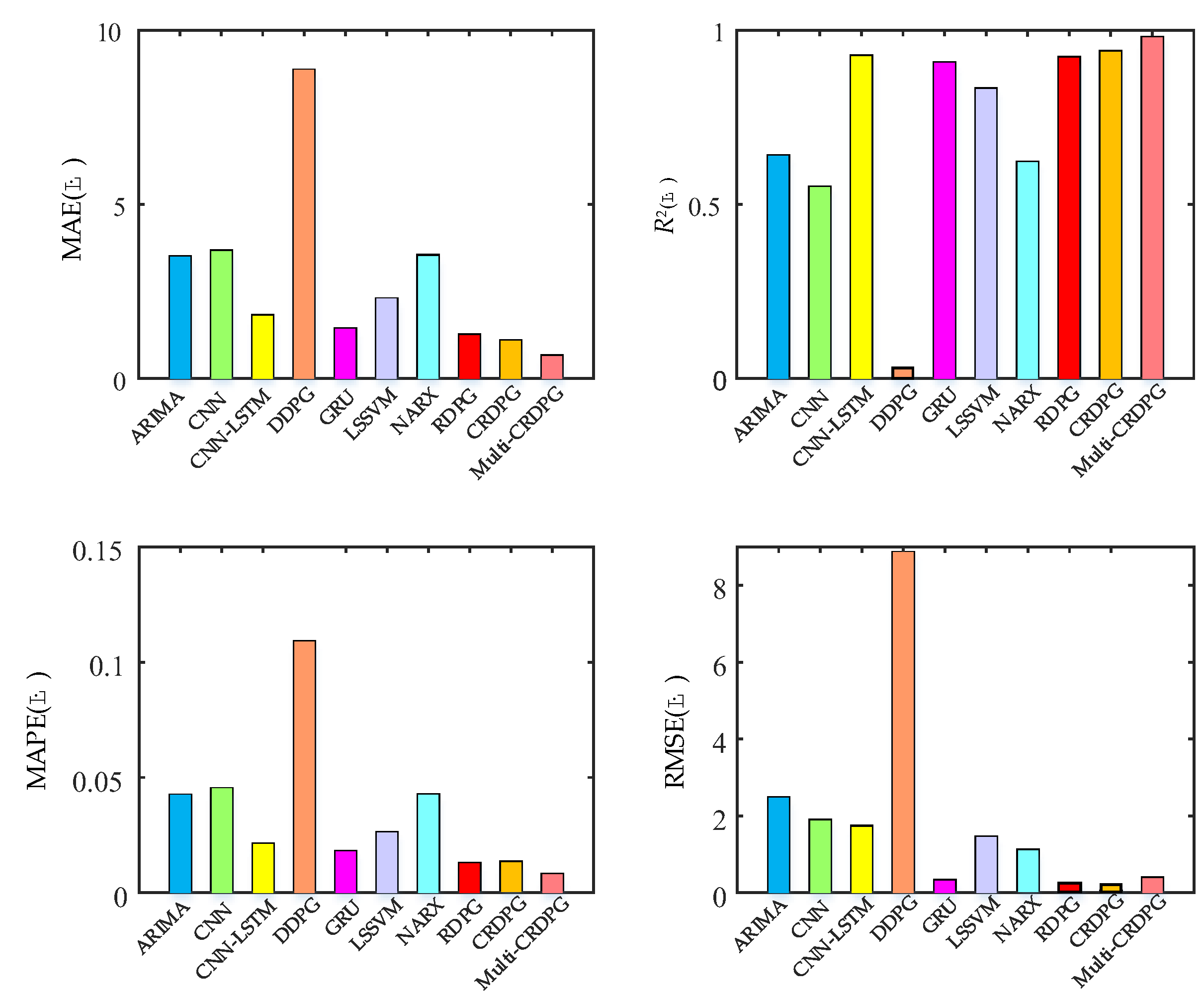
- Some conventional time series prediction models, including LSSVM, NARX, ARIMA and GRU, can predict the change trend in oil temperature to a certain extent, but in the face of complex working condition data, the ability of the above models to improve the prediction accuracy is very limited. As a classical feature extraction algorithm, CNN is good at data classification, but it is not good at excavating the transformation rules of time series, so its prediction performance is unsatisfactory. Of three DRL models, DDPG performs the worst among these models, even worse than conventional DL, because the structure of the BP neural network is too simple.
- (b)
- The key to the successful application of the DRL algorithm is to choose a model with excellent performance as the basic learner. After extracting the feature of the time series, the prediction accuracy is higher than directly forecasting from the original data, and the training time of the model is shorter due to the simplification of the sequence information. By observing four evaluation indicies of LSSVM, NARX, ARIMA, CNN, GRU and CNN–LSTM, CNN–LSTM performed better than other models, which implies it has more potential as a basic learner of DRL and obtains optimal predicted accuracy.
- (c)
- When comparing GRU and CNN–LSTM with their corresponding RL algorithms RDPG and CRDPG, it was fully proven that the performance of the basic learner guided by the reinforcement learning framework has been greatly improved. The possible reason is that the decision-making ability of the reinforcement learning framework is stronger than that of the traditional deep learning method for directly fitting data.
4.2. Fault Detection Analysis
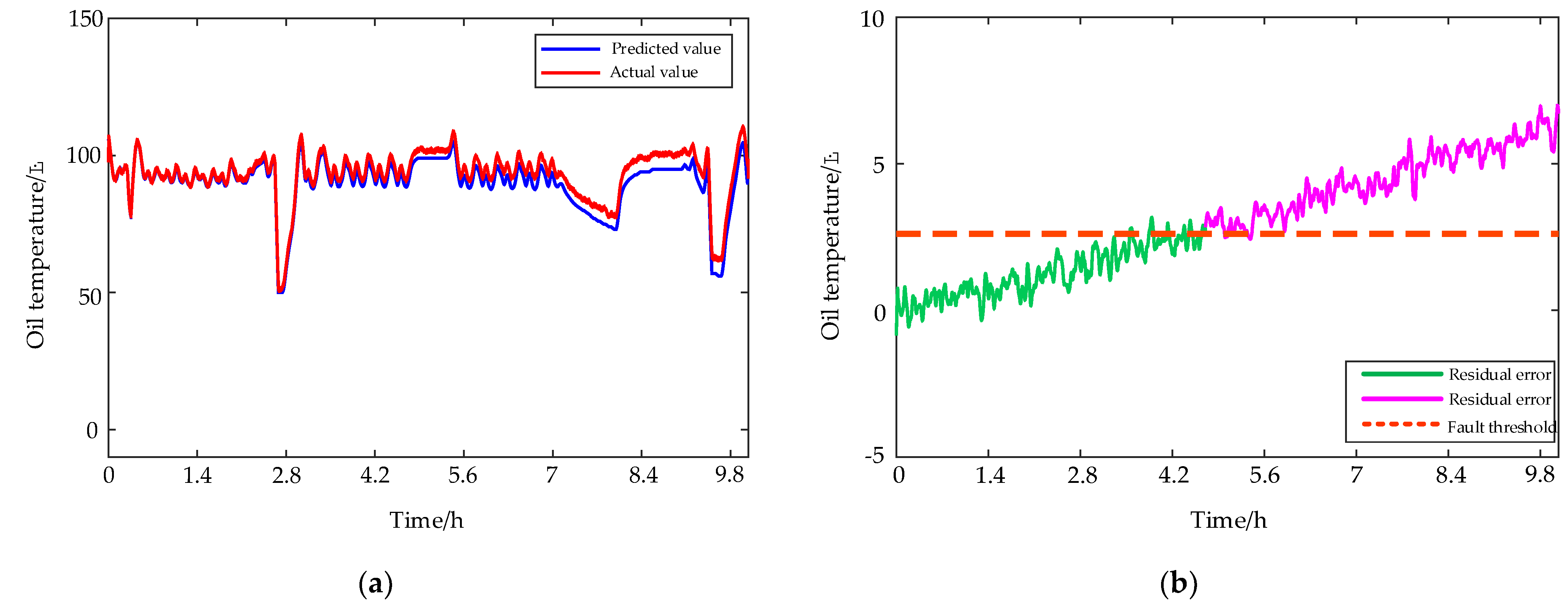
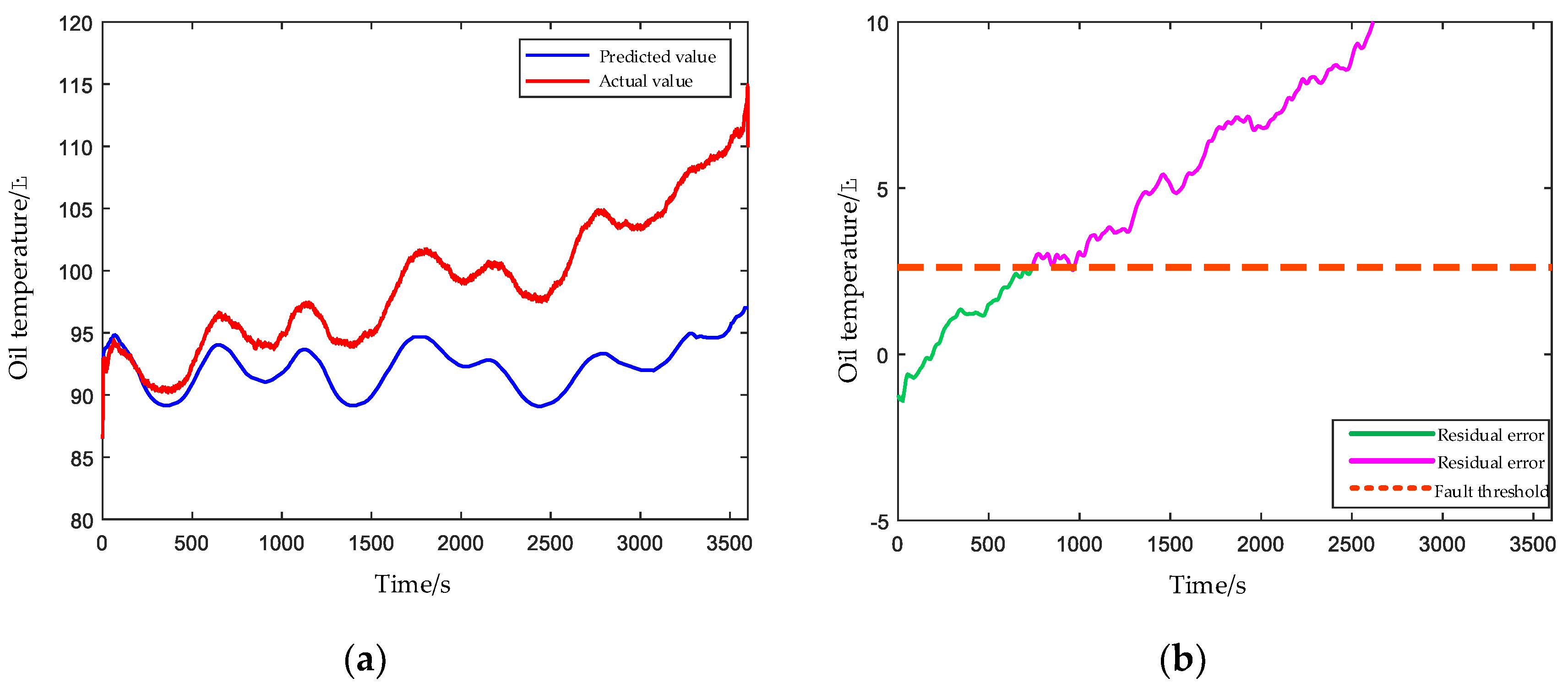
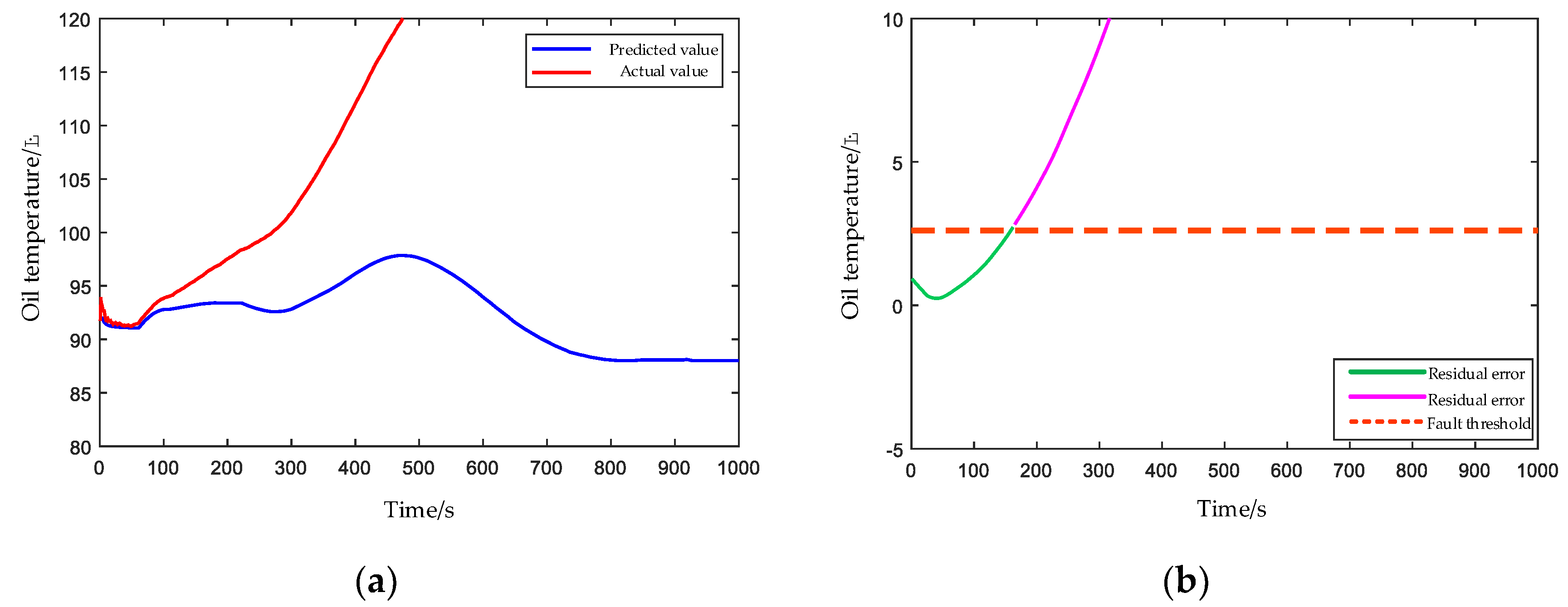
4.2.1. Planet Gear Broken Teeth
4.2.2. Damaged Bearing Cage and Rolling Elements
4.2.3. Clogged Oil Filter Element
5. Conclusions and Future Works
- (1)
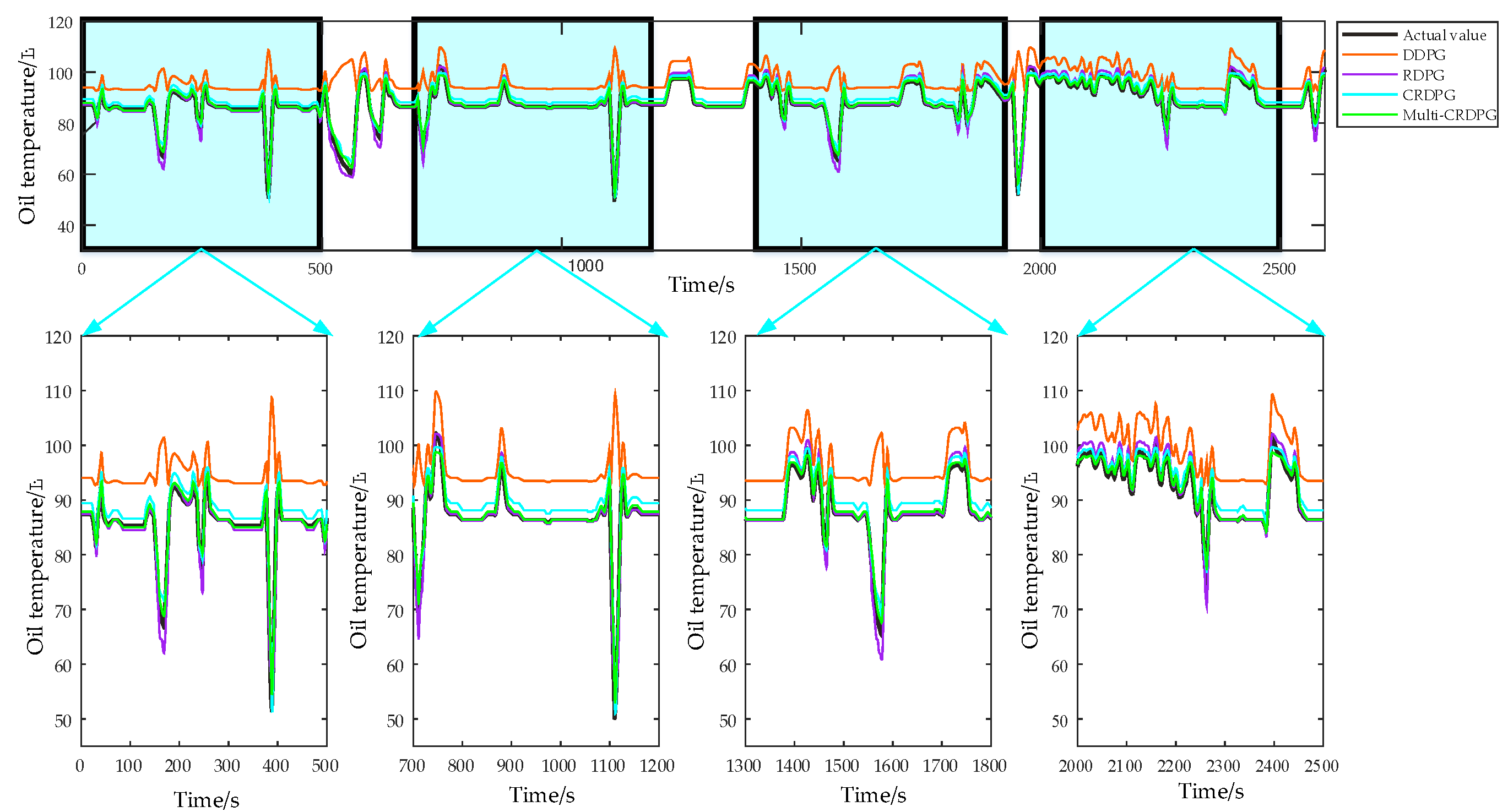
- The proposed model has the advantages of higher prediction accuracy and more stable convergence than other baseline models. The results of comparison experiments in the datasets of each working condition demonstrate that an accurate oil temperature prediction model is successfully established. Meanwhile, the robustness of the model is verified, which can ensure the reliability of the prediction and detection results.
- (2)
- The proposed deep deterministic policy gradient method is based on a CNN–LSTM network, which can extract complex time series features, eliminate redundant information, reduce noise influence and excavate the change rules of time series. Moreover, CNN–LSTM educated by a deep deterministic policy gradient framework can obtain better performance than the original CNN–LSTM.
- (3)
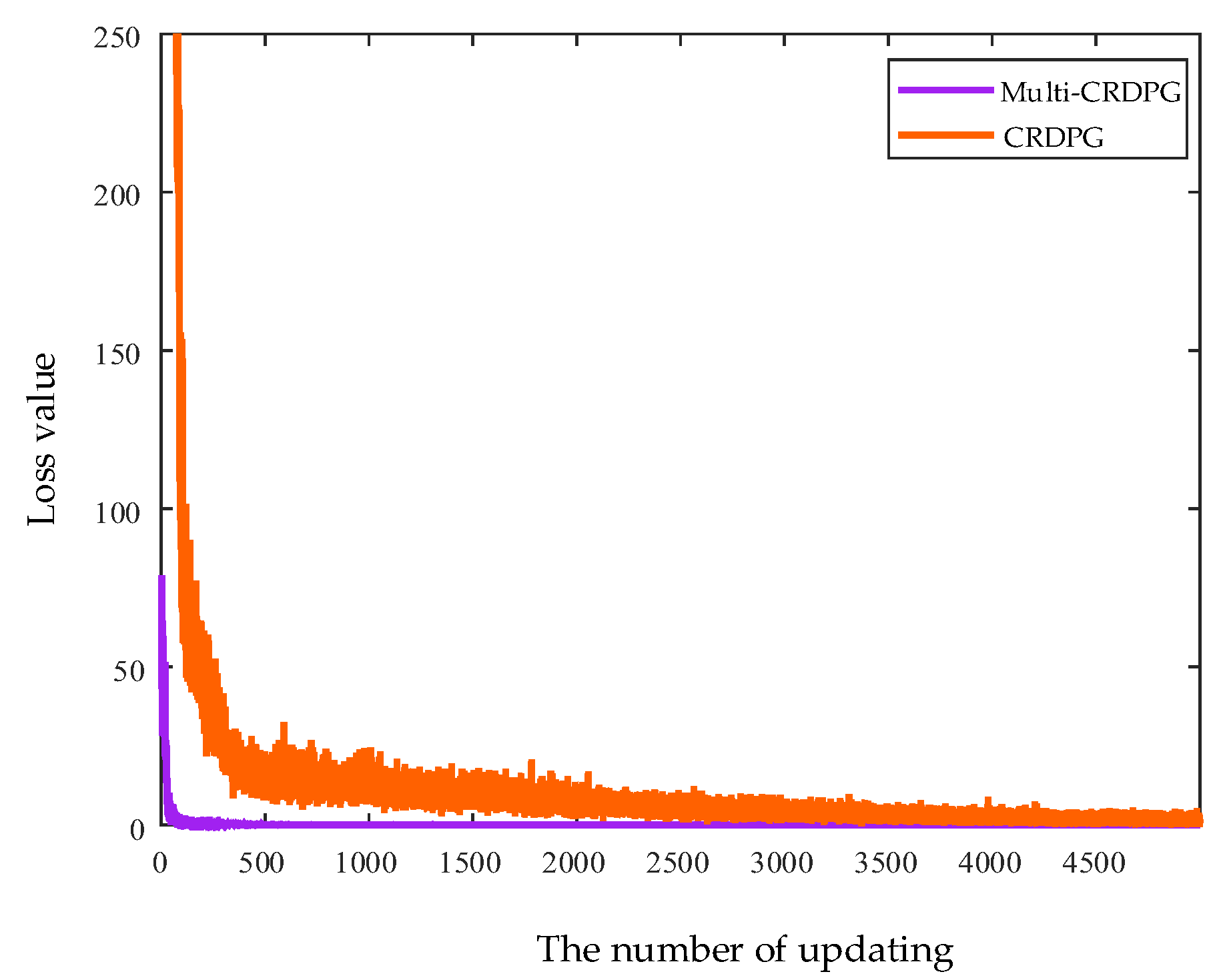
- The proposed reward incentive function can accelerate and stabilize the convergence of model training by exciting the agent, which is worth being rewarded at different time steps.
- (4)
- The proposed variable exploration variance is beneficial for the agent to fully explore the state space and correctly evaluate each state value in the initial training stage. Reduce the noise variance at the later training stage to make the model converge gradually.
- (5)
- The proposed multi-critic network structure and a state-action value estimation strategy can reduce the overestimation and underestimation of the state-action values of the agent to improve the forecasting accuracy of the basic learner, which is a key step to further improve the prediction accuracy of the model.
Author Contributions
Funding
Conflicts of Interest
References
- Hu, J.; Hu, N.; Yang, Y.; Zhang, L.; Shen, G. Nonlinear dynamic modeling and analysis of a helicopter planetary gear set for tooth crack diagnosis. Measurement 2022, 198, 111347. [Google Scholar] [CrossRef]
- Sun, C.; Wang, Y.; Sun, G. A multi-criteria fusion feature selection algorithm for fault diagnosis of helicopter planetary gear train. Chin. J. Aeronaut. 2020, 33, 1549–1561. [Google Scholar] [CrossRef]
- Bolvashenkov, I.; Kammermann, J.; Herzog, H.G. Electrification of Helicopter: Actual Feasibility and Prospects. In Proceedings of the 2017 IEEE Vehicle Power and Propulsion Conference (VPPC), Belfort, France, 11–14 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Kamble, S.B.; Desai, V.; Jeppu, Y.V.; Prajna. System Identification for Helicopter Longitudinal Dynamics Model—Best Practices. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; pp. 496–501. [Google Scholar]
- Bayoumi, A.; Ranson, W.; Eisner, L.; Grant, L.E. Cost and effectiveness analysis of the AH-64 and UH-60 on-board vibrations monitoring system. In Proceedings of the 2005 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2005; Volume 1–4, pp. 3921–3940. [Google Scholar]
- Song, J.H.; Yang, J.W.; Rim, M.S.; Kim, Y.Y.; Kim, J.H.; Park, H.; Seok, J.N.; Kim, C.G.; Lee, H.C.; Choi, S.W.; et al. Implementation of Sensor-embedded Main Wing Model of Ultra Light Airplane for Health and Usage Monitoring System (HUMS) Test-bed. In Proceedings of the 2012 12th International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 17–21 October 2012; pp. 1247–1249. [Google Scholar]
- Wu, J.Y.; Sun, C.; Zhang, C.; Chen, X.F.; Yan, R.Q. Deep clustering variational network for helicopter regime recognition in HUMS. Aerosp. Sci. Technol. 2022, 124, 107553. [Google Scholar] [CrossRef]
- Li, T.F.; Zhao, Z.B.; Sun, C.; Yan, R.Q.; Chen, X.F. Adaptive Channel Weighted CNN With Multisensor Fusion for Condition Monitoring of Helicopter Transmission System. IEEE Sens. J. 2020, 20, 8364–8373. [Google Scholar] [CrossRef]
- Marple, S.L.; Marino, C.; Strange, S. Large dynamic range time-frequency signal analysis with application to helicopter Doppler radar data. In Proceedings of the Sixth International Symposium on Signal Processing and its Applications, Kuala Lumpur, Malaysia, 13–16 August 2001; Volume 1, pp. 260–263. [Google Scholar]
- He, D.; Bechhoefer, E. Development and validation of bearing diagnostic and prognostic tools using HUMS condition indicators. In Proceedings of the 2008 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008; Volume 1–9, pp. 1–8. [Google Scholar]
- Rashid, H.S.J.; Place, C.S.; Mba, D.; Keong, R.L.C.; Healey, A.; Kleine-Beek, W.; Romano, M. Reliability model for helicopter main gearbox lubrication system using influence diagrams. Reliab. Eng. Syst. Safe 2015, 139, 50–57. [Google Scholar] [CrossRef]
- Modaresahmadi, S.; Khalesi, J.; Li, K.; Bird, J.Z.; Williams, W.B. Convective heat transfer analysis of a laminated flux focusing magnetic gearbox. Therm. Sci. Eng. Prog. 2020, 18, 100552. [Google Scholar] [CrossRef]
- Rashid, H.; Khalaji, E.; Rasheed, J.; Batunlu, C. Fault Prediction of Wind Turbine Gearbox Based on SCADA Data and Machine Learning. In Proceedings of the 2020 10th International Conference on Advanced Computer Information Technologies (ACIT), Deggendorf, Germany, 16–18 September 2020; pp. 391–395. [Google Scholar]
- Feng, Y.H.; Qiu, Y.N.; Crabtree, C.J.; Long, H.; Tavner, P.J. Monitoring wind turbine gearboxes. Wind Energy 2013, 16, 728–740. [Google Scholar] [CrossRef]
- Liu, Y.R.; Wu, Z.D.; Wang, X.L. Research on Fault Diagnosis of Wind Turbine Based on SCADA Data. IEEE Access 2020, 8, 185557–185569. [Google Scholar] [CrossRef]
- Zeng, X.J.; Yang, M.; Bo, Y.F. Gearbox oil temperature anomaly detection for wind turbine based on sparse Bayesian probability estimation. Int. J. Electr. Power Energy Syst. 2020, 123, 106233. [Google Scholar] [CrossRef]
- Dhiman, H.; Deb, D.; Muyeen, S.M.; Kamwa, I. Wind Turbine Gearbox Anomaly Detection Based on Adaptive Threshold and Twin Support Vector Machines. IEEE Trans. Energy Convers. 2021, 36, 3462–3469. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.J.; Long, H.; Xu, J.; Liu, R.H. Wind Turbine Gearbox Failure Identification with Deep Neural Networks. IEEE Trans. Ind. Inform. 2017, 13, 1360–1368. [Google Scholar] [CrossRef]
- Guo, R.J.; Zhang, G.B.; Zhang, Q.; Zhou, L. Early Fault Detection of Wind Turbine Gearbox Based on Adam-Trained LSTM. In Proceedings of the 2021 The 6th International Conference on Power and Renewable Energy, Shanghai, China, 17–20 September 2021. [Google Scholar]
- Yang, S.Y.; Zheng, X.X. Prediction of Gearbox Oil Temperature of Wind Turbine Based on GRNN-LSTM Combined Model. In Proceedings of the 2021 The 6th International Conference on Power and Renewable Energy, Shanghai, China, 17–20 September 2021. [Google Scholar]
- Jia, X.J.; Han, Y.; Li, Y.J.; Sang, Y.C.; Zhang, G.L. Condition monitoring and performance forecasting of wind turbines based on denoising autoencoder and novel convolutional neural networks. Energy Rep. 2021, 7, 6354–6365. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- You, C.X.; Lu, J.B.; Filev, D.; Tsiotras, P. Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning. Robot. Auton. Syst. 2019, 114, 1–18. [Google Scholar] [CrossRef]
- Dogru, O.; Velswamy, K.; Huang, B. Actor-Critic Reinforcement Learning and Application in Developing Computer-Vision-Based Interface Tracking. Engineering 2021, 7, 1248–1261. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, L.; Ma, J.; Suo, M.L.; Tao, L.F.; Cheng, Y.J.; Lu, C. Intelligent fault diagnosis for rotating machinery using deep Q-network based health state classification: A deep reinforcement learning approach. Adv. Eng. Inform. 2019, 42, 100977. [Google Scholar] [CrossRef]
- Liu, H.; Yu, C.Q.; Yu, C.M. A new hybrid model based on secondary decomposition, reinforcement learning and SRU network for wind turbine gearbox oil temperature forecasting. Measurement 2021, 178, 109347. [Google Scholar] [CrossRef]
- Guo, M.Z.; Liu, Y.; Malec, J. A new Q-learning algorithm based on the Metropolis criterion. IEEE Trans. Syst. Man Cybern. Part B 2004, 34, 2140–2143. [Google Scholar] [CrossRef] [PubMed]
- Luo, F.; Zhou, Q.; Fuentes, J.; Ding, W.C.; Gu, C.H. A Soar-Based Space Exploration Algorithm for Mobile Robots. Entropy 2022, 24, 426. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.P.; Zhu, W.; Benton, M.G.; Romagnoli, J.A. Continuous Control of a Polymerization System with Deep Reinforcement Learning. J. Process Control 2019, 75, 40–47. [Google Scholar] [CrossRef]
- Wang, Z.J.; Cui, J.; Cai, W.A.; Li, Y.F. Partial Transfer Learning of Multidiscriminator Deep Weighted Adversarial Network in Cross-Mechine Fault Diagnosis. IEEE Trans. Instrum. Measurement 2022, 71, 1–10. [Google Scholar] [CrossRef]
- He, X.X.; Wang, Z.J.; Li, Y.F.; Svetlana, K.; Du, W.H.; Wang, J.Y.; Wang, W.Z. Joint decision-making of parallel machine scheduling restricted in job-machine release time and preventive maintenance with remaining useful life constrains. Reliab. Eng. Syst. Saf. 2022, 222, 108429. [Google Scholar] [CrossRef]
- Liu, T.; Xu, C.L.; Guo, Y.B.; Chen, H.X. A novel deep reinforcement learning based methodology for short-term HVAC system energy consumption prediction. Int. J. Refrig. 2019, 107, 39–51. [Google Scholar] [CrossRef]
- Liu, T.; Tan, Z.H.; Xu, C.L.; Chen, H.X.; Li, Z.F. Study on deep reinforcement learning techniques for building energy consumption forecasting. Energy Build. 2020, 208, 109675. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Chen, Q.; Yan, J.Y.; Zhang, S.; Xu, J.Y. A novel asynchronous deep reinforcement learning model with adaptive early forecasting method and reward incentive mechanism for short-term load forecasting. Energy 2021, 236, 121492. [Google Scholar] [CrossRef]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. Int. Conf. Mach. Learn. 2018, 80, 1587–1596. [Google Scholar] [CrossRef]
- Fan, J.J.; Chen, J.P.; Fu, Q.M.; Lu, Y.; Wu, H.J. DDPG algorithm based on multiple exponential moving average evaluation. Comput. Eng. Design 2021, 42, 3084–3090. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Detailed Definition |
|---|---|
| HMGB | Helicopter main gearbox |
| HTS | Helicopter transmission system |
| HUMS | Health and usage monitoring system |
| DRL | Deep reinforcement learning |
| RL | Reinforcement learning |
| DL | Deep learning |
| CNN–LSTM | Convolutional long-short time memory |
| LSTM | Long short-term memory |
| CNN | Convolutional neural network |
| DDPG | Deep deterministic policy gradient |
| RDPG | Recurrent deterministic policy gradient |
| GRU | Gate recurrent unit |
| KDE | Kernel density estimation |
| EWMA | Exponentially weighted moving average |
| HPGB | Helical gear pair-two-stage planetary gearbox |
| MDP | Markov decision process |
| Multi-CRDPG |
| 1: Initialize the parameters θμ, θμ’ of online actor network μ(s|θμ) and online critic networks Q(s,a|θQ), and their target network μ’(s|θμ’), Q’(s,a|θQ’) is set to θμ ’= θμ, θQ’ = θQ. 2: Initialize the experience replay buffer B, the batch size H and the number of critic output K 3: Set the learning parameters α, β, τ, nepo_total and weight coefficient a, b, c. 4: for episode nepo = 1, …, nepo_total do: 5: for t = 1,2,…, training size do: 6: Receive initial state s1 7: Calculate the current noise variance σepo according to equation (20) 8: Select action at = μ(s|θμ) + N(0, σepo) from the actor network μ(s|θμ) 9: Execute action at, get reward rt and receive the next state st+1 10: Store transition (st, at, rt, st+1) in B 11: Sample random batch size of H transitions from B 12: Calculate the loss function Lcritic and the estimated Q value: Calculate the estimated state-action of the target critic network using Equation (21) Minimize the loss Lcritic using Equation (24) Update the parameters of the online critic network: 13: Calculate the gradient of the for the online actor network by using Equation (12) Update the parameters of the online actor network: 14: Update the parameters of the target actor network and target critic network using soft updating θμ’ = (1 − τ)θμ , θQ’ = (1 − τ)θQ’ 15: end for 15: end for |
| Acquisition Variables | Unit | Mean | Std | Max Normalized CCF |
|---|---|---|---|---|
| Motor speed | rpm | 1114.1 | 620.0 | 0.8897 |
| Load | N.m | 36.6 | 34.0 | 0.7381 |
| Gearbox oil pressure | Kpa | 214. 8 | 114.5 | 0.8965 |
| Gearbox inlet oil temperature | °C | 69.2 | 20.1 | 0.9915 |
| Ambient temperature | °C | 25.0 | 0.98 | 0.4123 |
| Gearbox oil temperature | °C | 88.7 | 20.8 | 1 |
| Modules | Layers | Types | Parameters | Input/Output Channel |
|---|---|---|---|---|
| Critic Network | 1 | Convolution | KS:11 S:1 P:5 | 4/16 |
| 2 | Pooling layer | PS:4 | 16/16 | |
| 3 | Convolution | KS:3 S:1 P:1 | 16/32 | |
| 4 | Pooling layer | PS:4 | 32/32 | |
| 5 | LSTM | N:512 HN: 5 | 32/4 | |
| 6 | Linear layer | N: 512 | 512/128 | |
| 7 | Linear layer | N: 128 | 128/64 | |
| 8 | Linear layer | N: 64 | 64/1 | |
| … | … | … | … | |
| 27 | Linear layer | N: 512 | 512/128 | |
| 28 | Linear layer | N: 128 | 128/64 | |
| 29 | Linear layer | N: 64 | 64/1 | |
| Actor Network | 1 | Convolution | KS:11 S:1 P:5 | 4/16 |
| 2 | Pooling layer | PS:4 | 16/16 | |
| 3 | Convolution | KS:3 S:1 P:1 | 16/32 | |
| 4 | Pooling layer | PS:4 | 32/32 | |
| 5 | LSTM | N:512 HN: 5 | 32/4 | |
| 6 | Linear layer | N: 512 | 512/128 | |
| 7 | Linear layer | N: 128 | 128/64 | |
| 8 | Linear layer | N: 64 | 64/1 | |
| Parameters: α = 0.00005, β = 0.00005, τ = 0.05, B = 1000, H = 32, K = 8, nepo_total = 10, a = 0.5, b = 0.5, c = 0.1, λ = 0.9, kp = 2.2, ki = 1.8, kd = 0.5.Hardware and software: CPU: Intel Core i5-11400F K, GPU: GeForce RTX 1650s, Programing language: python, Deep learning framework: pytorch. | ||||
| Models | Detailed Parameters |
|---|---|
| LS-SVM | C = 8, gamma = 0.02 |
| NARX | ID = 35, FD = 1, N = 512 |
| ARIMA | P = 16, q = 10, d = 1 |
| Projection | Duration Time | Number of Tests | Ambient Temperature |
|---|---|---|---|
| Fault 1 | 36,000s | 30 | 23~28 °C |
| Fault 2 | 3600s | 50 | 23~28 °C |
| Fault 3 | 1000s | 70 | 23~28 °C |
| Models | Fault 1 | Fault 2 | Fault 3 |
|---|---|---|---|
| Multi-CRDPG | 18,002 ± 40.3 s | 900 ± 20.7 s | 159 ± 10.4 s |
| CRDPG | 18,502 ± 34.2 s | 933 ± 19.5 s | 172 ± 13.9 s |
| RDPG | 18,937 ± 40.5 s | 1012 ± 21.2 s | 200 ± 9.9 s |
| DDPG | 24,557 ± 64.2 s | 2321 ± 50.3 s | 323 ± 33.2 s |
| LS-SVM | 19,423 ± 44.8 s | 1134 ± 24.3 s | 235 ± 11.3 s |
| NARX | 20,032 ± 23.2 s | 1342 ± 23.2 s | 283 ± 23.2 s |
| ARIMA | 19,623 ± 37.1 s | 1216 ± 23.4 s | 252 ± 16.6 s |
| CNN | 20,144 ± 53.8 s | 1385 ± 42.2 s | 299 ± 27.4 s |
| GRU | 19,002 ± 37.1 s | 1022 ± 26.7 s | 211± 14.6 s |
| CNN–LSTM | 18,722 ± 37.2 s | 961 ± 23.5 s | 184 ± 20.2 s |
| Models | Fault 1 | Fault 2 | Fault 3 |
|---|---|---|---|
| Multi-CRDPG | 0.0% | 0.0% | 0.0% |
| CRDPG | 0.0% | 0.0% | 0.0% |
| RDPG | 3.3% | 2.0% | 0.0% |
| DDPG | 26.7% | 16.7% | 5.7% |
| LS-SVM | 6.6% | 6.0% | 2.9% |
| NARX | 6.6% | 6.0% | 2.9% |
| ARIMA | 6.6% | 6.0% | 2.9% |
| CNN | 26.7% | 8.0% | 4.3% |
| GRU | 13.3% | 2.0% | 1.4% |
| CNN–LSTM | 6.6% | 2.0% | 0.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Cheng, Z.; Cheng, J.; Hu, N.; Yang, Y. A Fault Detection Method Based on an Oil Temperature Forecasting Model Using an Improved Deep Deterministic Policy Gradient Algorithm in the Helicopter Gearbox. Entropy 2022, 24, 1394. https://doi.org/10.3390/e24101394
Wei L, Cheng Z, Cheng J, Hu N, Yang Y. A Fault Detection Method Based on an Oil Temperature Forecasting Model Using an Improved Deep Deterministic Policy Gradient Algorithm in the Helicopter Gearbox. Entropy. 2022; 24(10):1394. https://doi.org/10.3390/e24101394
Chicago/Turabian StyleWei, Lei, Zhe Cheng, Junsheng Cheng, Niaoqing Hu, and Yi Yang. 2022. "A Fault Detection Method Based on an Oil Temperature Forecasting Model Using an Improved Deep Deterministic Policy Gradient Algorithm in the Helicopter Gearbox" Entropy 24, no. 10: 1394. https://doi.org/10.3390/e24101394
APA StyleWei, L., Cheng, Z., Cheng, J., Hu, N., & Yang, Y. (2022). A Fault Detection Method Based on an Oil Temperature Forecasting Model Using an Improved Deep Deterministic Policy Gradient Algorithm in the Helicopter Gearbox. Entropy, 24(10), 1394. https://doi.org/10.3390/e24101394