


Distributed Support Vector Ordinal Regression over Networks



Abstract
:1. Introduction
- 1.
- Existing work on distributed ordinal regression [14] uses a linear model; therefore, it cannot deal with the problems of linearly inseparable data. We extended the SVOR method to distributed scenarios to solve distributed ordinal regression problems with linearly inseparable data.
- 2.
- We developed a decentralized implementation of SVOR, and propose a dSVOR algorithm. In the proposed algorithm, the kernel feature map is approximated by random feature maps to avoid transmitting the original data, and sparse regularization is added to avoid excessively high approximation dimensions.
- 3.
- The consensus and convergence of the proposed algorithm are theoretically analyzed.
2. Related Works
3. Preliminaries
3.1. Ordinal Regression Problem
3.2. Support Vector Ordinal Regression with Implicit Constraints
4. Distributed Support Vector Ordinal Regression Algorithm
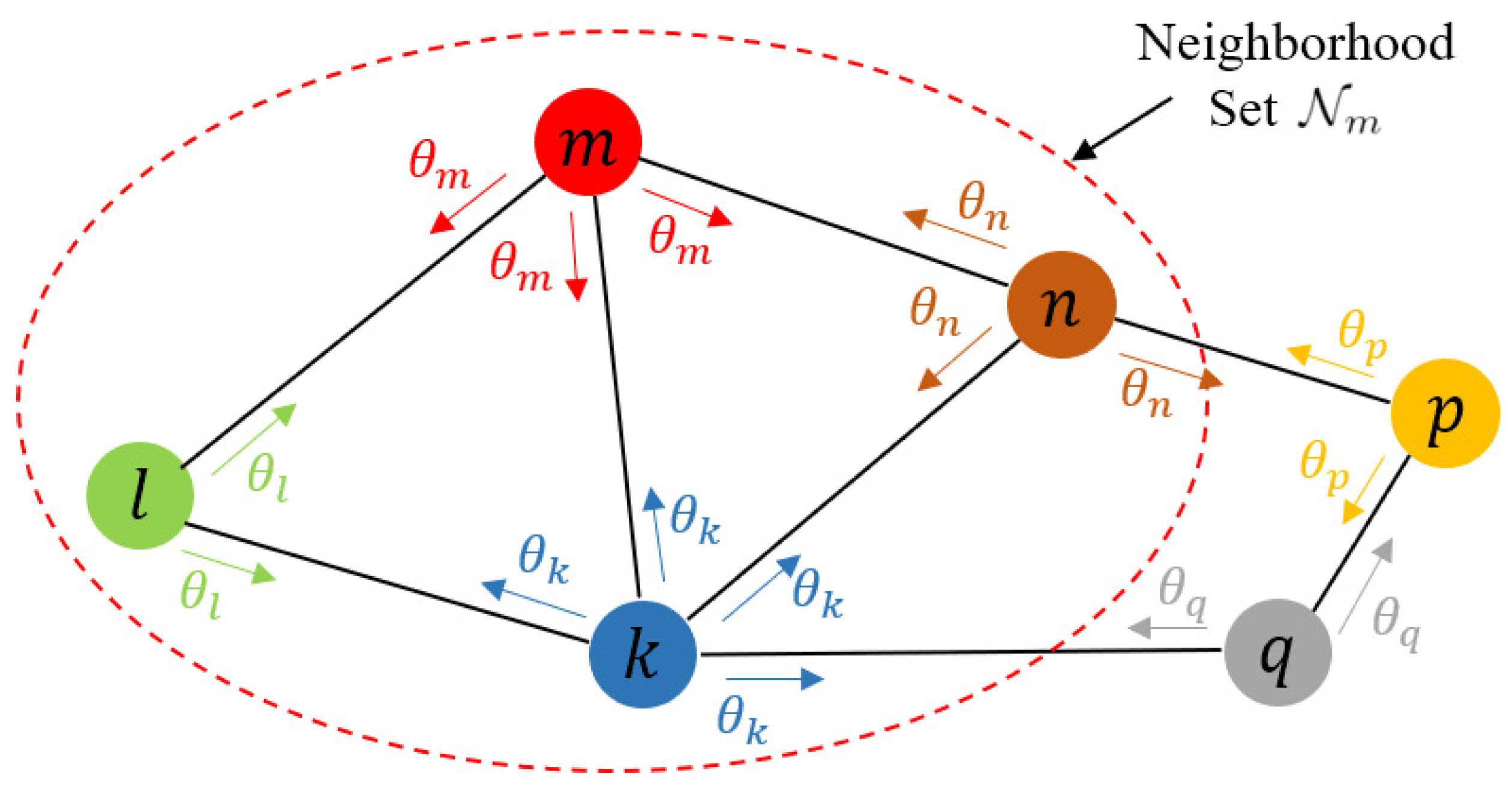
4.1. Network and Data Model
4.2. Problem Formulation
4.3. Problem Transformation
- 1.
- For nonlinear kernel functions, the dimension of the RKHS is unknown, and we can only calculate the inner product of and rather than them. Because the data are distributed in various nodes of the network, the kernel function requiring data from different nodes is difficult to calculate without transmitting the original data.
- 2.
- The dual variables of samples should satisfy constraints in (2). In the distributed scenarios, the dual variables of the first constraint in (2) are usually from different nodes. Since each node is only allowed to exchange information with its neighbors, it is difficult to optimize these dual variables.
4.4. Sparse Regularization
4.5. Distributed SVOR Algorithm
| Algorithm 1 Distributed SVOR algorithm |
Initialization: initialize hinge loss function weight C, sparsity regularization weight , random approximate dimension D, and total iteration number T. Each node m initializes . for for Communication Step: communicate parameters with neighbors . end for for Combination Step: compute intermediate estimate via (21). Adaption Step: update via (22). end for end for |
4.6. Theoretical Analysis
5. Experiments
- proposed dSVOR algorithm (dSVOR);
- centralized SVOR (cSVOR), which relies on all the data available in a central node;
- distributed SVOR with a noncooperative strategy (ncSVOR). In ncSVOR, each node uses only its own data to train a model without any information exchanged with other nodes.
- 1.
- The centralized method needs data in a central node. For comparison, we artificially collected all the data distributed in the nodes of the network together to render it applicable, which is impractical in reality.
- 2.
- 3.
- The distributed algorithms were subject to additional constraints, so a distributed algorithm is generally satisfactory if it can achieve comparable performance to the corresponding centralized algorithm.
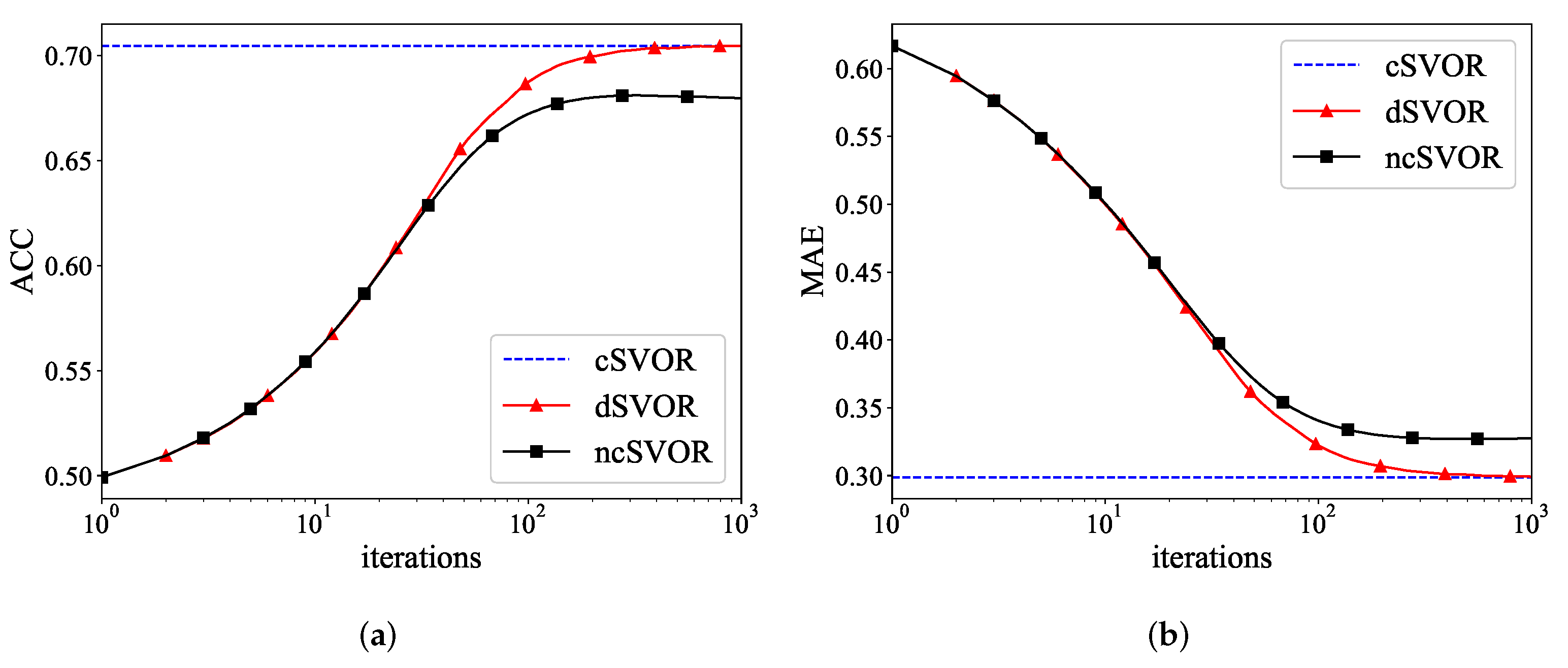
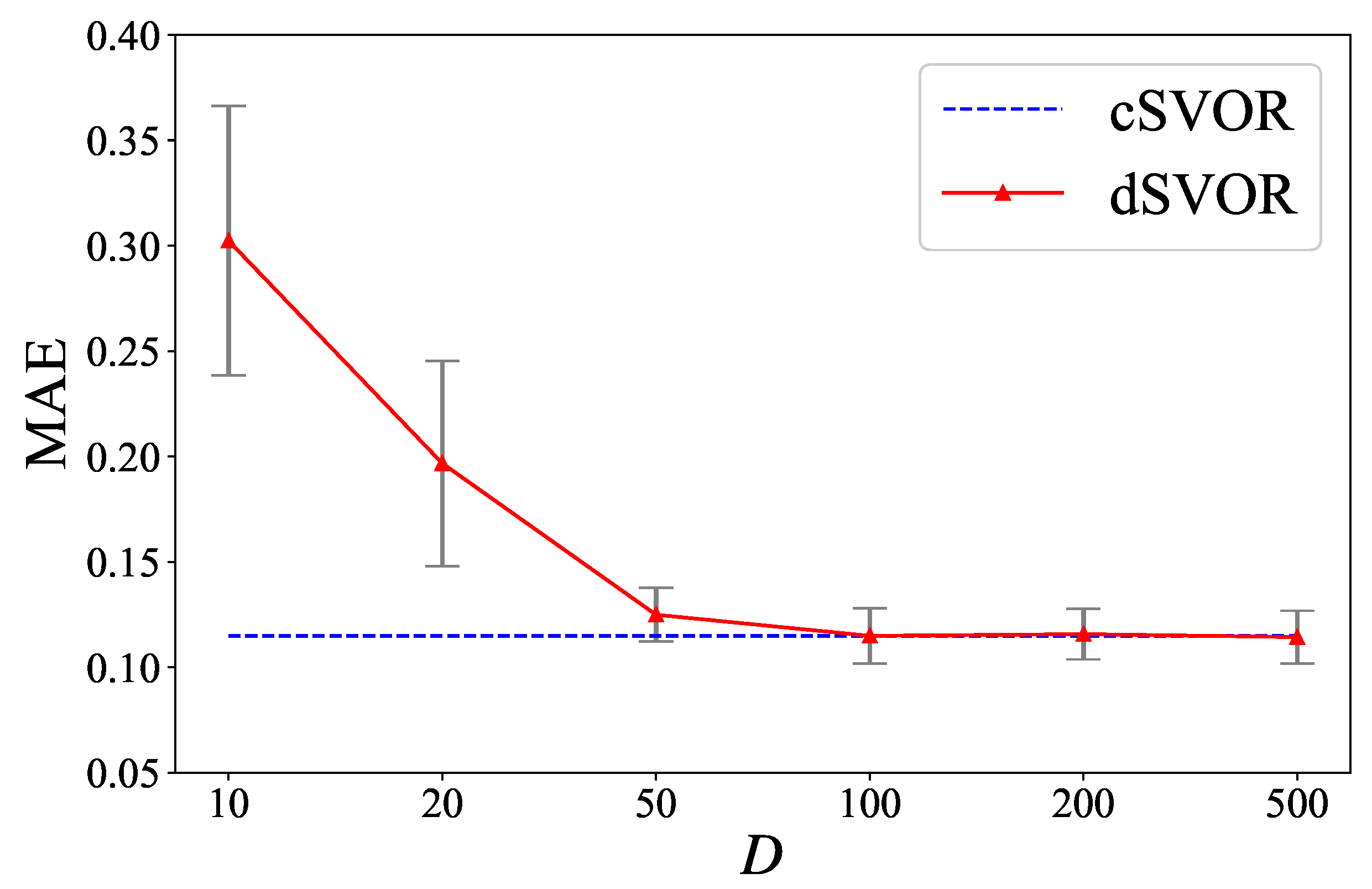
5.1. Synthetic Data
5.2. A Real-World Example
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
References
- Doyle, O.M.; Westman, E.; Marqu, A.F.; Mecocci, P.; Vellas, B.; Tsolaki, M.; Kłoszewska, I.; Soininen, H.; Lovestone, S.; Williams, S.C.; et al. Predicting progression of alzheimer’s disease using ordinal regression. PLoS ONE 2014, 9, e105542. [Google Scholar] [CrossRef]
- Allen, J.; Eboli, L.; Mazzulla, G.; Ortúzar, J.D. Effect of critical incidents on public transport satisfaction and loyalty: An Ordinal Probit SEM-MIMIC approach. Transportation 2020, 47, 827–863. [Google Scholar] [CrossRef]
- Gutiérrez, P.A.; Salcedo-Sanz, S.; Hervás-Martínez, C.; Carro-Calvo, L.; Sánchez-Monedero, J.; Prieto, L. Ordinal and nominal classification of wind speed from synoptic pressurepatterns. Eng. Appl. Artif. Intell. 2013, 26, 1008–1015. [Google Scholar] [CrossRef]
- Cao, W.; Mirjalili, V.; Raschka, S. Rank consistent ordinal regression for neural networks with application to age estimation. Pattern Recognit. Lett. 2020, 140, 325–331. [Google Scholar] [CrossRef]
- Hirk, R.; Hornik, K.; Vana, L. Multivariate ordinal regression models: An analysis of corporate credit ratings. Stat. Method. Appl. 2019, 28, 507–539. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Zuo, M.J.; Liu, Z.; Hoseini, M.R. Diagnosis of artificially created surface damage levels of planet gear teeth using ordinal ranking. Measurement 2013, 46, 132–144. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Pintelas, P.E. A cost sensitive technique for ordinal classification problems. In Proceedings of the 3rd Hellenic Conference on Artificial Intelligence, Samos, Greece, 5–8 May 2004; pp. 220–229. [Google Scholar]
- Tu, H.-H.; Lin, H.-T. One-sided support vector regression for multiclass cost-sensitive classification. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 49–56. [Google Scholar]
- Harrington, E.F. Online ranking/collaborative filtering using the perceptron algorithm. In Proceedings of the 20th International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 250–257. [Google Scholar]
- Gutiérrez, P.A.; Perez-Ortiz, M.; Sanchez-Monedero, J.; Fernez-Navarro, F.; Hervas-Martinez, C. Ordinal regression methods: Survey and experimental study. IEEE Trans. Knowl. Data Eng. 2015, 28, 127–146. [Google Scholar] [CrossRef] [Green Version]
- Chu, W.; Keerthi, S.S. New approaches to support vector ordinal regression. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 145–152. [Google Scholar]
- Chu, W.; Keerthi, S.S. Support vector ordinal regression. Neural Comput. 2007, 19, 792–815. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Liu, H.; Tu, J.; Li, C. Distributed Ordinal Regression Over Networks. IEEE Access 2021, 9, 62493–62504. [Google Scholar] [CrossRef]
- McCullagh, P. Regression models for ordinal data. J. Royal Stat. Soc. Ser. B Methodol. 1980, 42, 109–142. [Google Scholar] [CrossRef]
- Williams, R. Understanding and interpreting generalized ordered logit models. J. Math. Sociol. 2016, 40, 7–20. [Google Scholar] [CrossRef]
- Wang, H.; Shi, Y.; Niu, L.; Tian, Y. Nonparallel Support Vector Ordinal Regression. IEEE Trans. Cybern. 2017, 47, 3306–3317. [Google Scholar] [CrossRef]
- Jiang, H.; Yang, Z.; Li, Z. Non-parallel hyperplanes ordinal regression machine. Knowl.-Based Syst. 2021, 216, 106593. [Google Scholar] [CrossRef]
- Li, L.; Lin, H.-T. Ordinal regression by extended binary classification. Adv. Neural Inf. Process. Syst. 2006, 19, 865–872. [Google Scholar]
- Liu, X.; Fan, F.; Kong, L.; Diao, Z.; Xie, W.; Lu, J.; You, J. Unimodal regularized neuron stick-breaking for ordinal classification. Neurocomputing 2020, 388, 34–44. [Google Scholar] [CrossRef]
- Cattivelli, F.S.; Sayed, A.H. Diffusion LMS strategies for distributed estimation. IEEE Trans. Signal Process. 2009, 58, 1035–1048. [Google Scholar] [CrossRef]
- Li, C.; Shen, P.; Liu, Y.; Zhang, Z. Diffusion information theoretic learning for distributed estimation over network. IEEE Trans. Signal Process. 2013, 61, 4011–4024. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Yang, T.; Yi, X.; Wu, J.; Yuan, Y.; Wu, D.; Meng, Z.; Hong, Y.; Wang, H.; Lin, Z.; Johansson, K.H. A survey of distributed optimization. Annu. Rev. Control 2019, 47, 278–305. [Google Scholar] [CrossRef]
- Shen, P.; Li, C. Distributed information theoretic clustering. IEEE Trans. Signal Process. 2014, 62, 3442–3453. [Google Scholar] [CrossRef]
- Olfati-Saber, R. Distributed Kalman filtering for sensor networks. In Proceedings of the 46th Conference on Decision and Control, New Orleans, LA, USA, 12–14 December 2007; pp. 5492–5498. [Google Scholar]
- Miao, X.; Liu, Y.; Zhao, H.; Li, C. Distributed online one-class support vector machine for anomaly detection over networks. IEEE Trans. Cybern. 2018, 49, 1475–1488. [Google Scholar] [CrossRef]
- Rahimi, A.; Recht, B. Random features for large-scale kernel machines. Adv. Neural Inf. Process. Syst. 2007, 20, 1177–1184. [Google Scholar]
- Cover, T.M. Geometrical and Statistical Properties of Systems of Linear Inequalities with Applications in Pattern Recognition. IEEE Trans. Electron. Comput. 1965, 14, 326–334. [Google Scholar] [CrossRef] [Green Version]
- Vedaldi, A.; Zisserman, A. Efficient additive kernels via explicit feature maps. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 480–492. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. Royal Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Bertsekas, D. Convex Optimization Algorithms; Athena Scientific: Belmont, MA, USA, 2015. [Google Scholar]
- Xiao, L.; Boyd, S. Fast linear iterations for distributed averaging. Syst. Control Lett. 2004, 53, 65–78. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Cerrada, M.; Sánchez, R.V.; Li, C.; Pacheco, F.; Cabrera, D.; de Oliveira, J.V.; Vásquez, R.E. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64, 100–131. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, Y.; Zhou, J. A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM. Measurement 2015, 69, 164–179. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Type | Load | cSVOR | ncSVOR | dSVOR | |||
|---|---|---|---|---|---|---|---|
| ACC | MAE | ACC | MAE | ACC | MAE | ||
| >OR | 0 | 0.9585 ± 0.0057 | 0.0415 ± 0.0057 | 0.7977 ± 0.0211 | 0.2069 ± 0.0230 | 0.9553 ± 0.0064 | 0.0447 ± 0.0064 |
| 1 | 0.9317 ± 0.0147 | 0.0683 ± 0.0147 | 0.7376 ± 0.0228 | 0.2726 ± 0.0264 | 0.9278 ± 0.0136 | 0.0727 ± 0.0138 | |
| 2 | 0.9547 ± 0.0091 | 0.0457 ± 0.0096 | 0.7901 ± 0.0136 | 0.2172 ± 0.0153 | 0.9517 ± 0.0094 | 0.0492 ± 0.0099 | |
| 3 | 0.9253 ± 0.0099 | 0.0747 ± 0.0099 | 0.7599 ± 0.0158 | 0.2489 ± 0.0173 | 0.9243 ± 0.0095 | 0.0758 ± 0.0096 | |
| >IR | 0 | 0.8853 ± 0.0133 | 0.1149 ± 0.0133 | 0.7472 ± 0.0087 | 0.2589 ± 0.0091 | 0.8844 ± 0.0120 | 0.1157 ± 0.0120 |
| 1 | 0.8624 ± 0.0112 | 0.1376 ± 0.0112 | 0.7288 ± 0.0103 | 0.2781 ± 0.0110 | 0.8556 ± 0.0137 | 0.1444 ± 0.0137 | |
| 2 | 0.8435 ± 0.0109 | 0.1565 ± 0.0109 | 0.7071 ± 0.0116 | 0.3000 ± 0.0133 | 0.8391 ± 0.0113 | 0.1611 ± 0.0113 | |
| 3 | 0.8726 ± 0.0095 | 0.1291 ± 0.0091 | 0.7238 ± 0.0110 | 0.2918 ± 0.0122 | 0.8632 ± 0.0094 | 0.1392 ± 0.0091 | |
| B | 0 | 0.7768 ± 0.0110 | 0.2586 ± 0.0129 | 0.5440 ± 0.0184 | 0.5975 ± 0.0311 | 0.7594 ± 0.0221 | 0.2771 ± 0.0245 |
| 1 | 0.7836 ± 0.0105 | 0.2419 ± 0.0099 | 0.5770 ± 0.0124 | 0.5284 ± 0.0195 | 0.7710 ± 0.0067 | 0.2540 ± 0.0106 | |
| 2 | 0.8256 ± 0.0088 | 0.1886 ± 0.0088 | 0.5820 ± 0.0156 | 0.5341 ± 0.0264 | 0.8177 ± 0.0147 | 0.1980 ± 0.0150 | |
| 3 | 0.8627 ± 0.0167 | 0.1541 ± 0.0193 | 0.6345 ± 0.0138 | 0.4648 ± 0.0253 | 0.8485 ± 0.0169 | 0.1710 ± 0.0204 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Tu, J.; Li, C. Distributed Support Vector Ordinal Regression over Networks. Entropy 2022, 24, 1567. https://doi.org/10.3390/e24111567
Liu H, Tu J, Li C. Distributed Support Vector Ordinal Regression over Networks. Entropy. 2022; 24(11):1567. https://doi.org/10.3390/e24111567
Chicago/Turabian StyleLiu, Huan, Jiankai Tu, and Chunguang Li. 2022. "Distributed Support Vector Ordinal Regression over Networks" Entropy 24, no. 11: 1567. https://doi.org/10.3390/e24111567
APA StyleLiu, H., Tu, J., & Li, C. (2022). Distributed Support Vector Ordinal Regression over Networks. Entropy, 24(11), 1567. https://doi.org/10.3390/e24111567