
Brain Inspired Cortical Coding Method for Fast Clustering and Codebook Generation


Abstract
:Highlights
- A cortical coding method is developed inspired by the network formation in the brain, where the information entropy is maximized while dissipated energy is minimized.
- The execution time in the cortical coding model is far superior, seconds versus minutes or hours, compared to those of the frequently used current algorithms, while retaining comparable distortion rate.
- The significant attribute of the methodology is its generalization performance, i.e., learning rather than memorizing data.
- Although only vector quantization property was demonstrated herein, the cortical coding algorithm has a real potential in a wide variety of real-time machine learning implementations such as , temporal clustering, data compression, audio and video encoding, anomaly detection, and recognition, to list a few.
Abstract
1. Introduction
- (a)
- Neurons minimize dissipated energy in time by increasing the most common features of the probabilistic distribution of the received signal pattern properties [16];
- (b)
- Neurons develop connections along the electric field gradient mostly selected by spine directions [17];
- (c)
- A signal may be received by multiple neurons through their dendritic inputs while absorbing the relevant features in a parallel manner that specifies their selectivity [18];
- (d)
- New connections between axon terminals and the dendritic inputs of the neurons are made for higher transferability of the electric charge until maximum entropy, or equal thermal dissipation, is reached within the cortex [19];
- (e)
- (f)
- The overall entropy tends to increase by developing and adapting the cortical networks with respect to the received signal within a given environment [22].
2. Methods
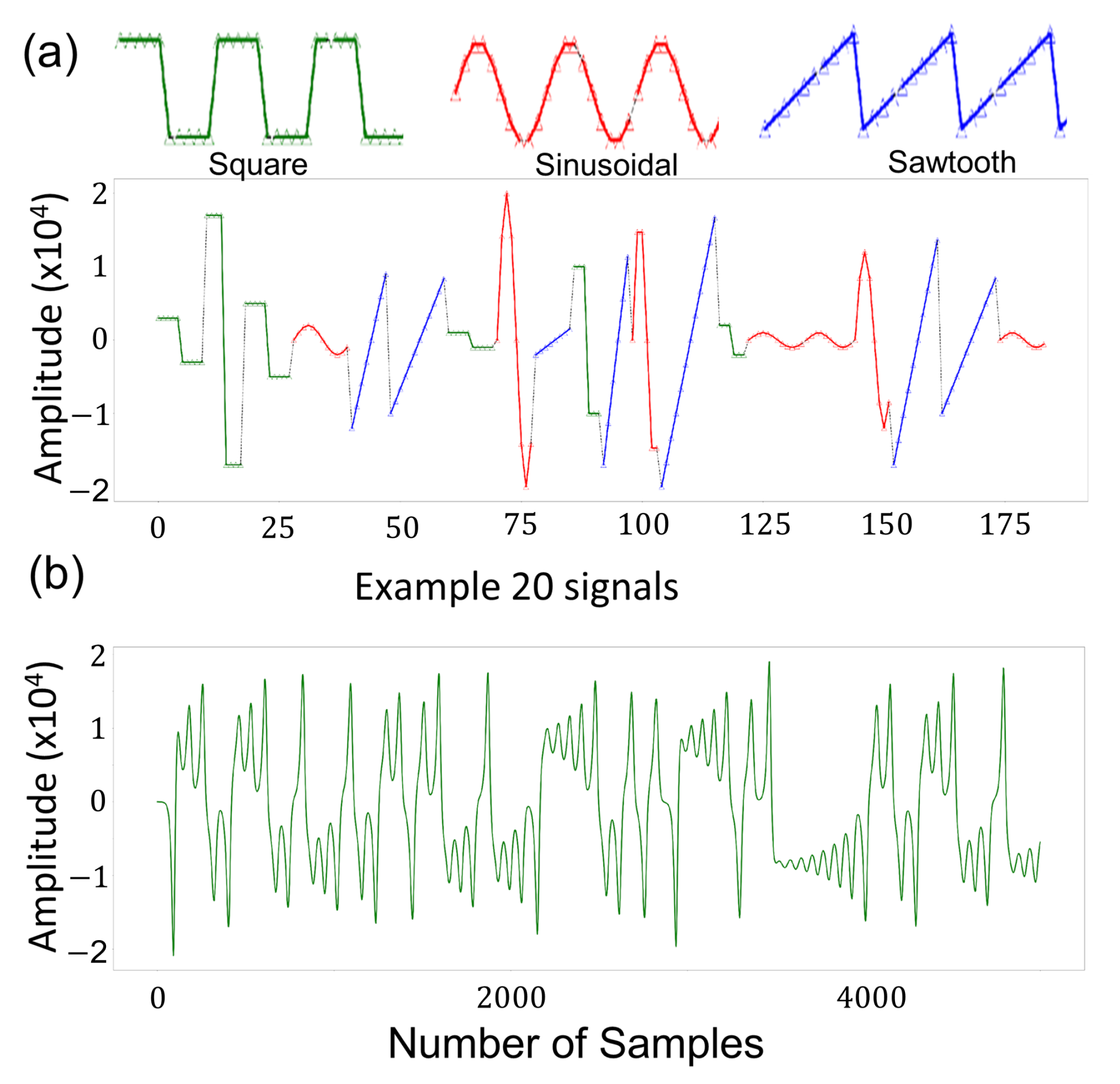
2.1. Datasets Used in Testing the Algorithms
2.1.1. Datasets with Basic Periodic Waves Form
2.1.2. Generation of the Lorenz Chaotic Dataset
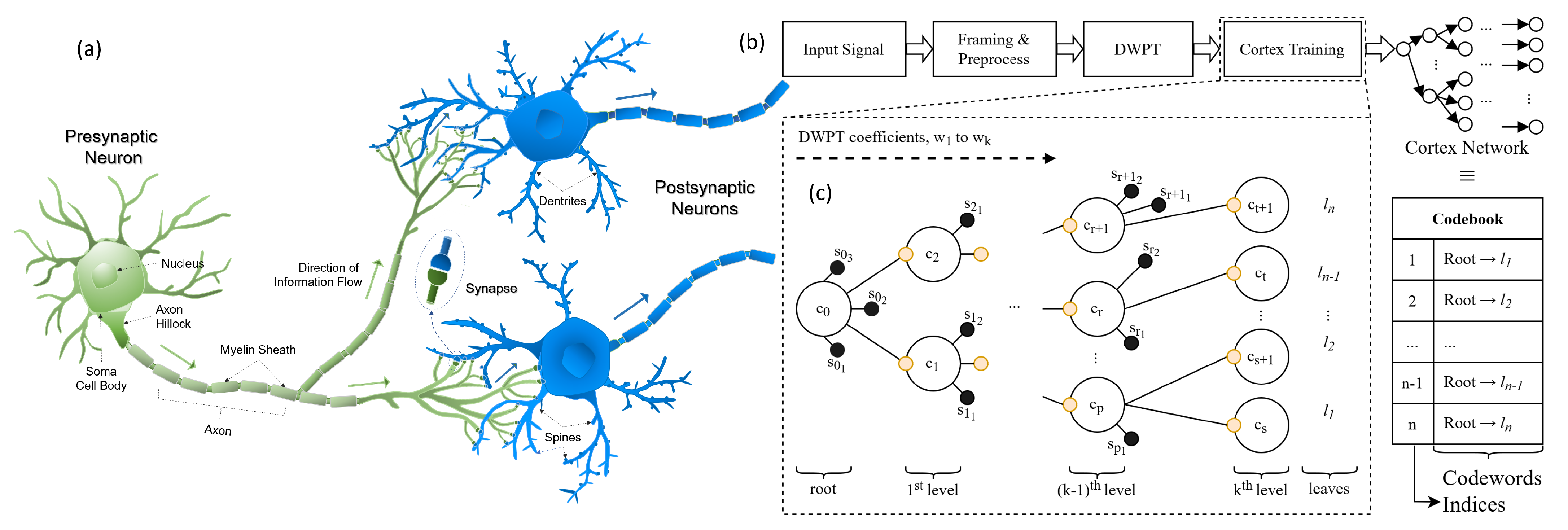
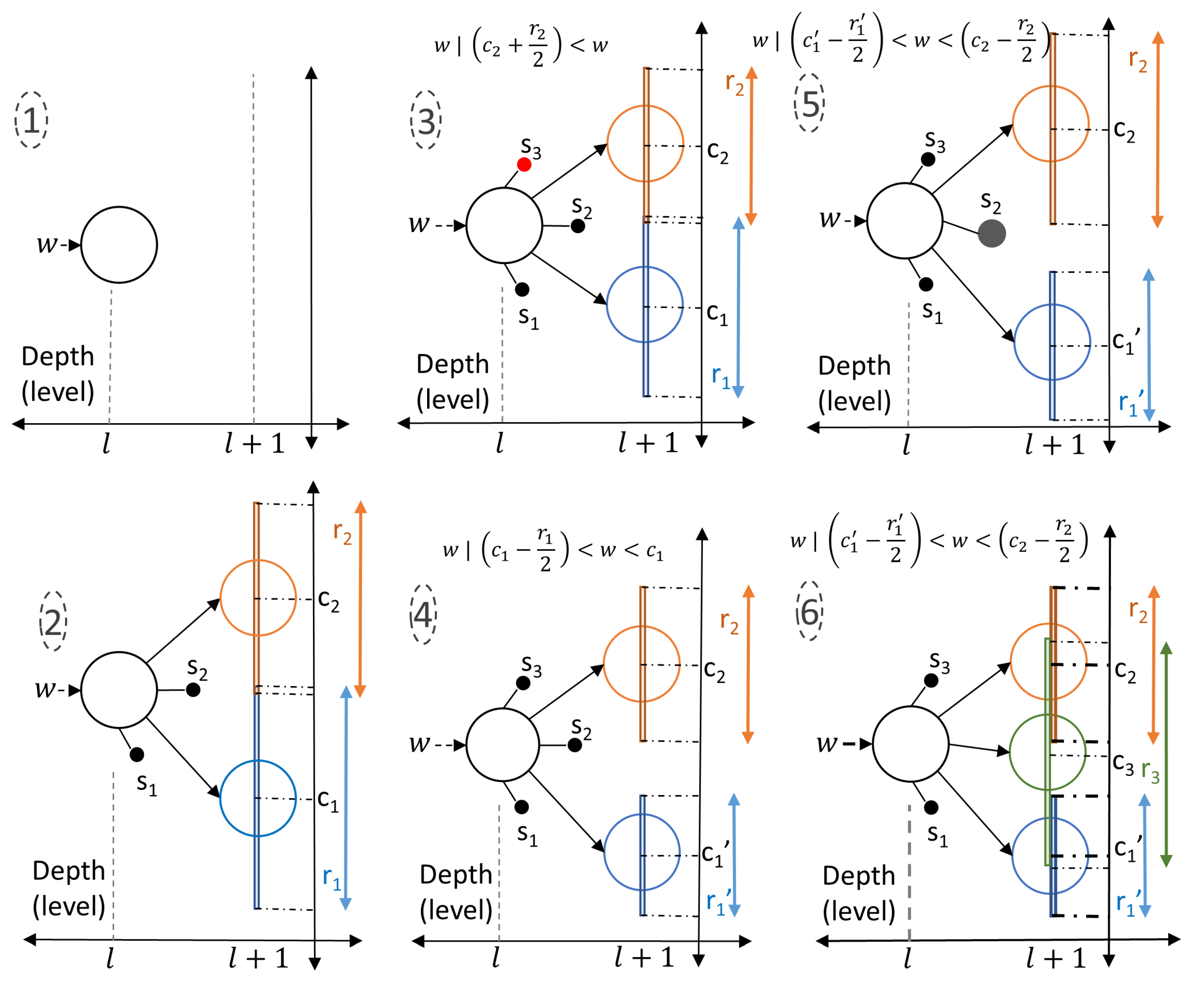
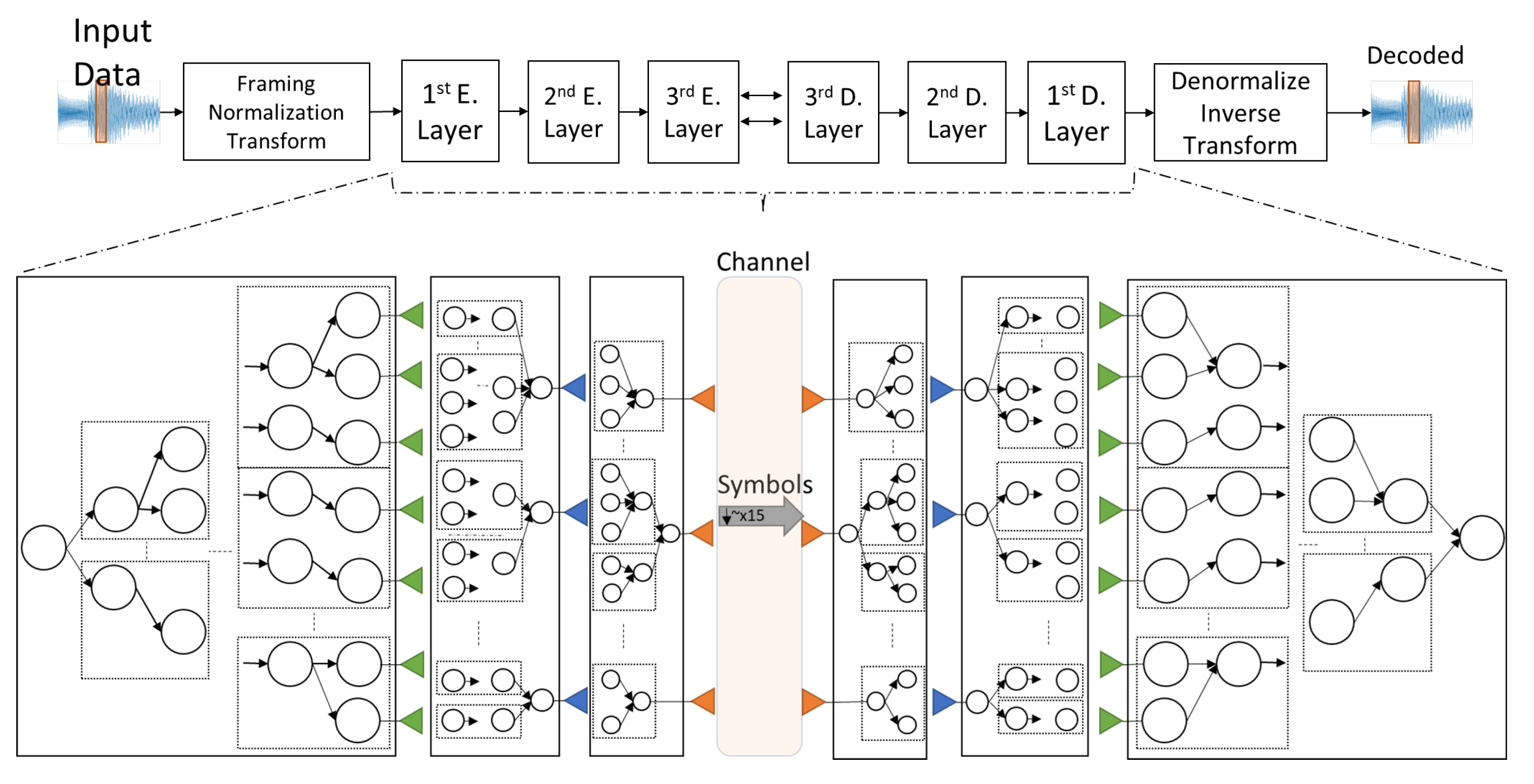
2.2. Components of Cortical Coding Network
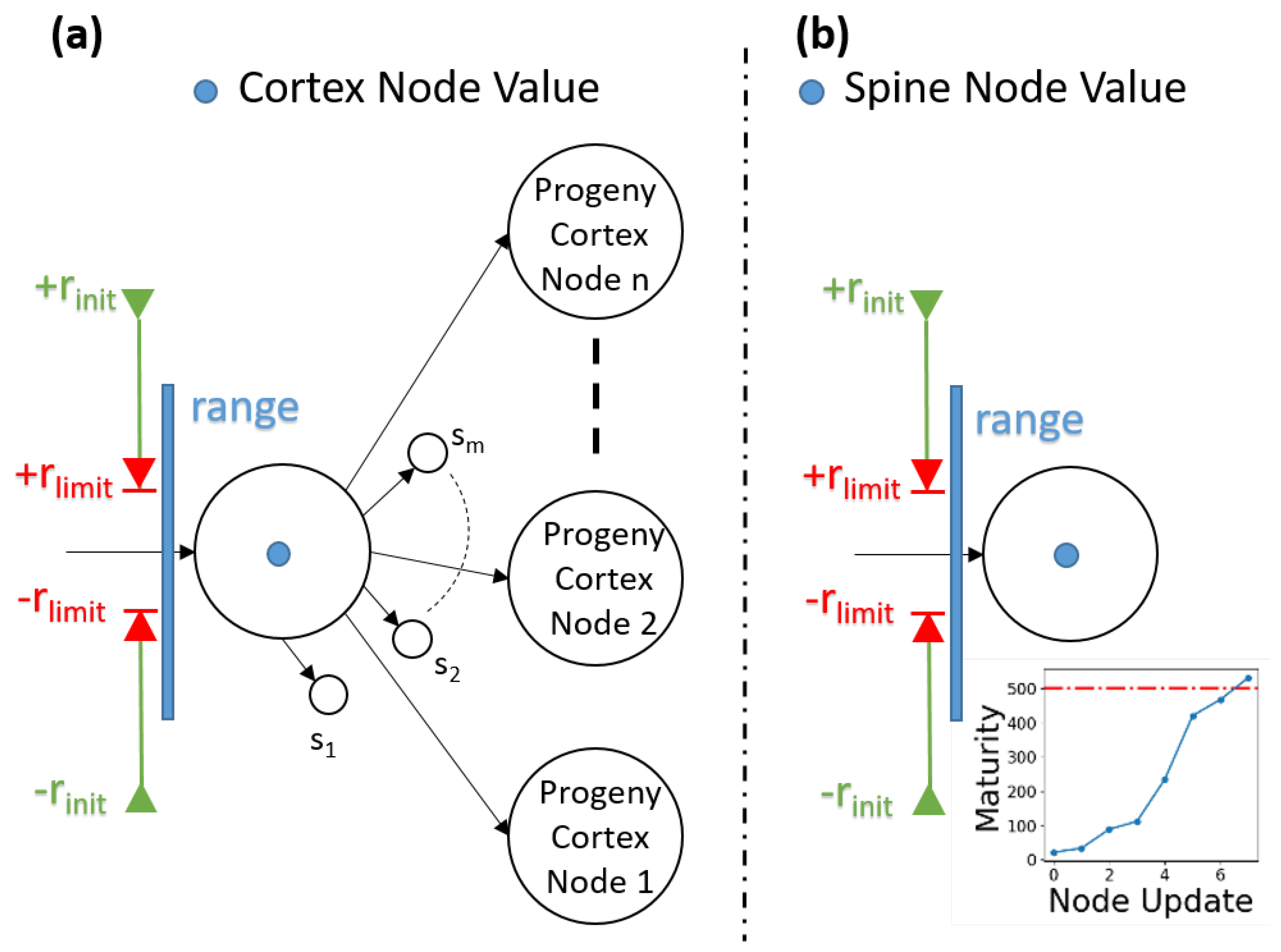
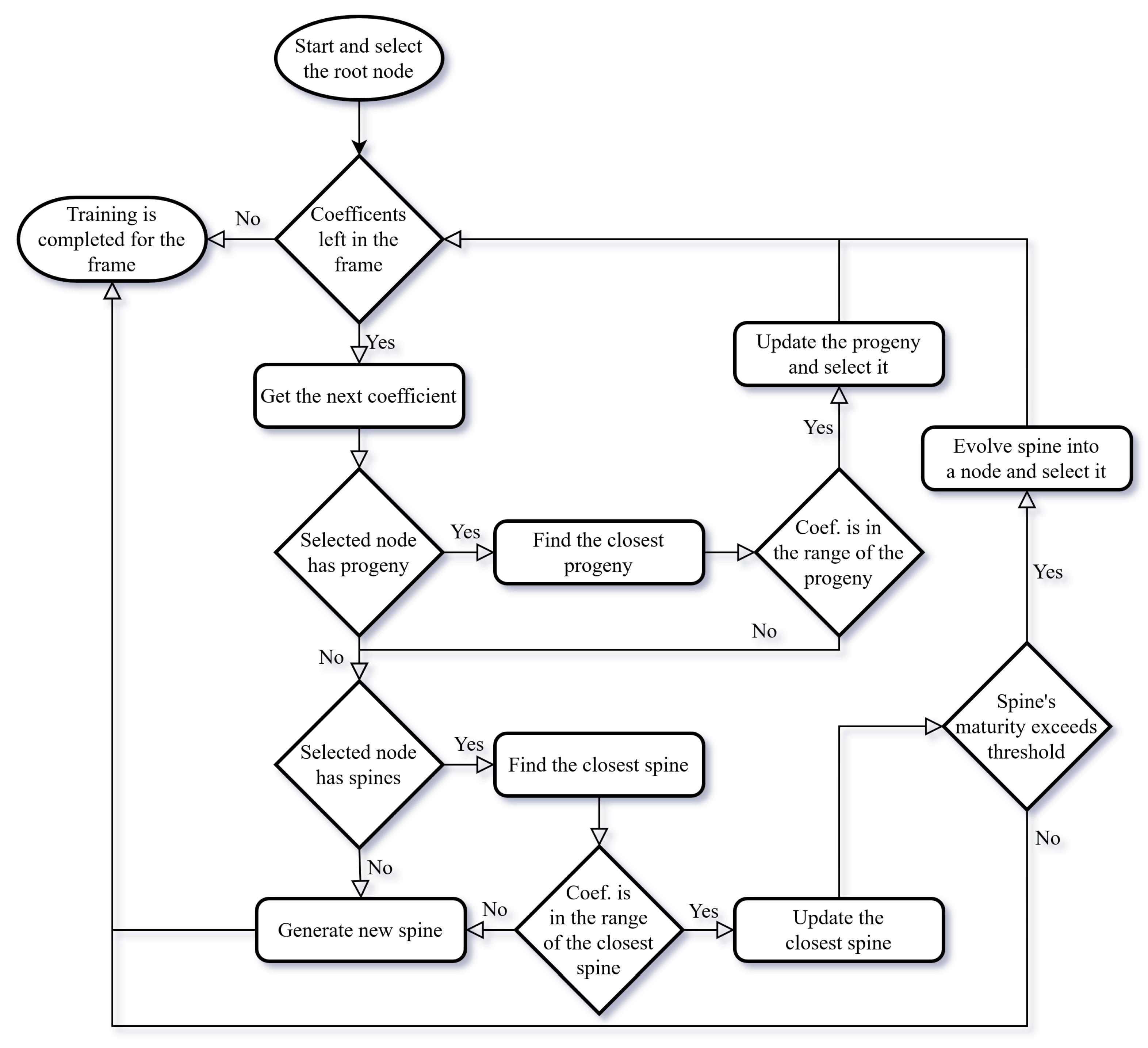
2.3. Cortical Coding Network Training Algorithm—Formation of Spines and Generation of the Network
| Algorithm 1 Cortical Coding Network Training (for one frame) |
|
Input input wavelet coefficients vectors, procedure Cortical Coding Network (Cortex) Training for each coefficient () in the input data frame do if node has progeny cortex node then closest_node ← FindClosestNode(node, coefficient) if coefficient is in the range of the closest cortex node then node ← UpdateClosestNode(closest_node, coefficient) continue end if end if if node has spines then closest_spine ← FindClosestSpine(node, coefficient) if coefficient is in the range of the closest spine node then UpdateClosestSpine(closest_spine, coefficient) if closest_spine’s maturity > threshold then node ← EvolveSpineToNode(closest_spine) continue else break end if end if end if GenerateSpine(node, coefficient) break end for end procedure |
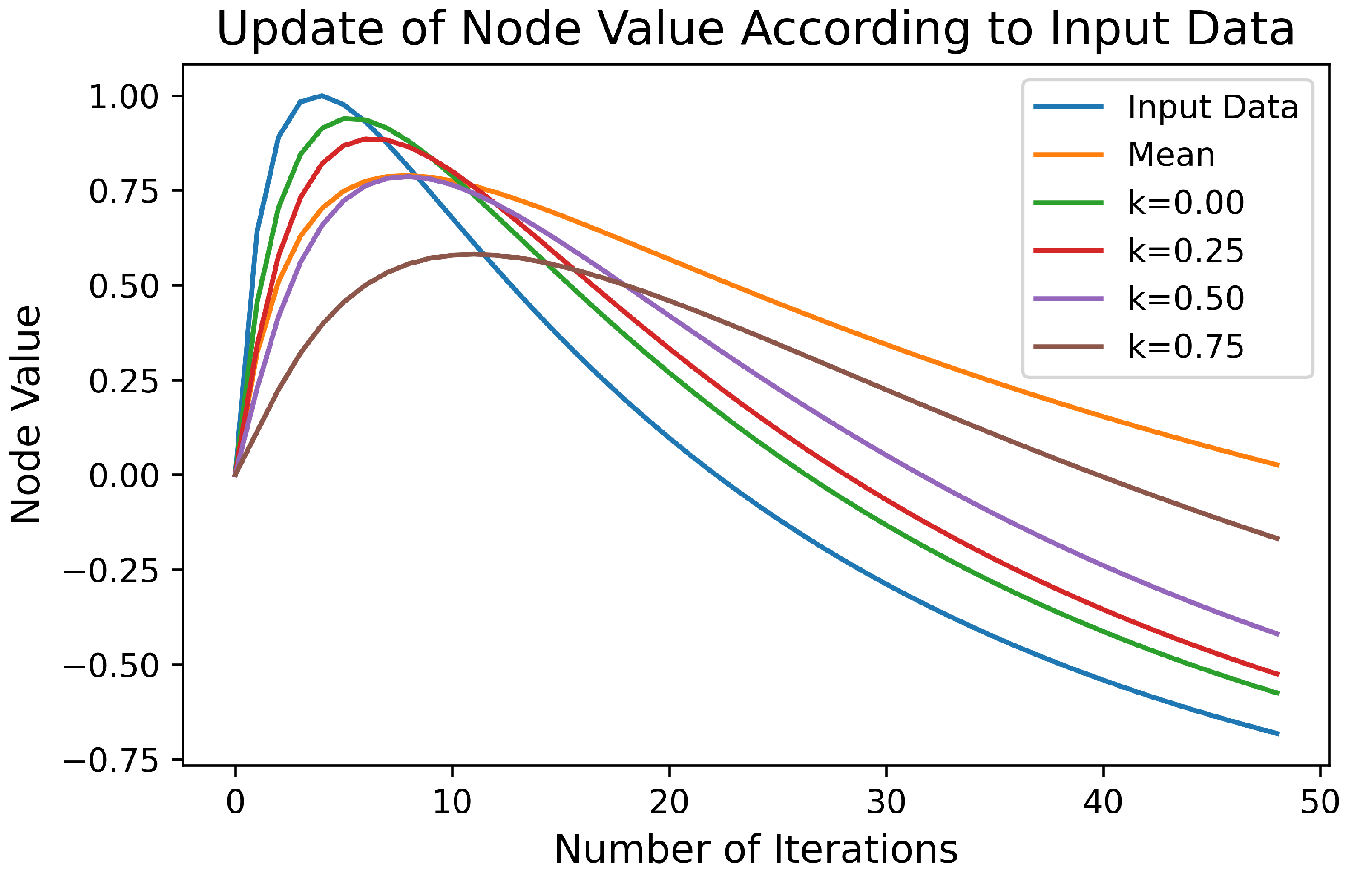
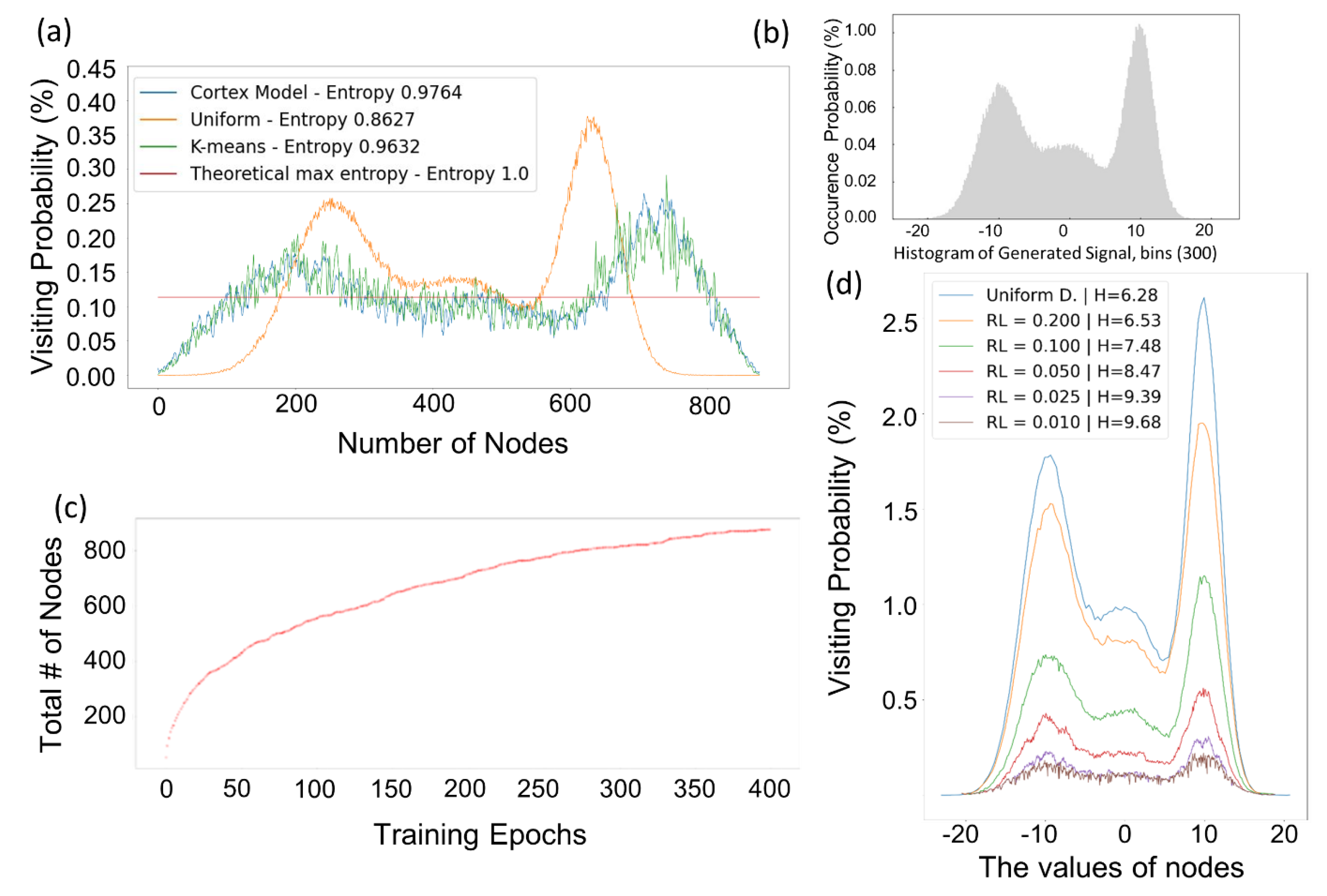
2.4. Entropy Maximization
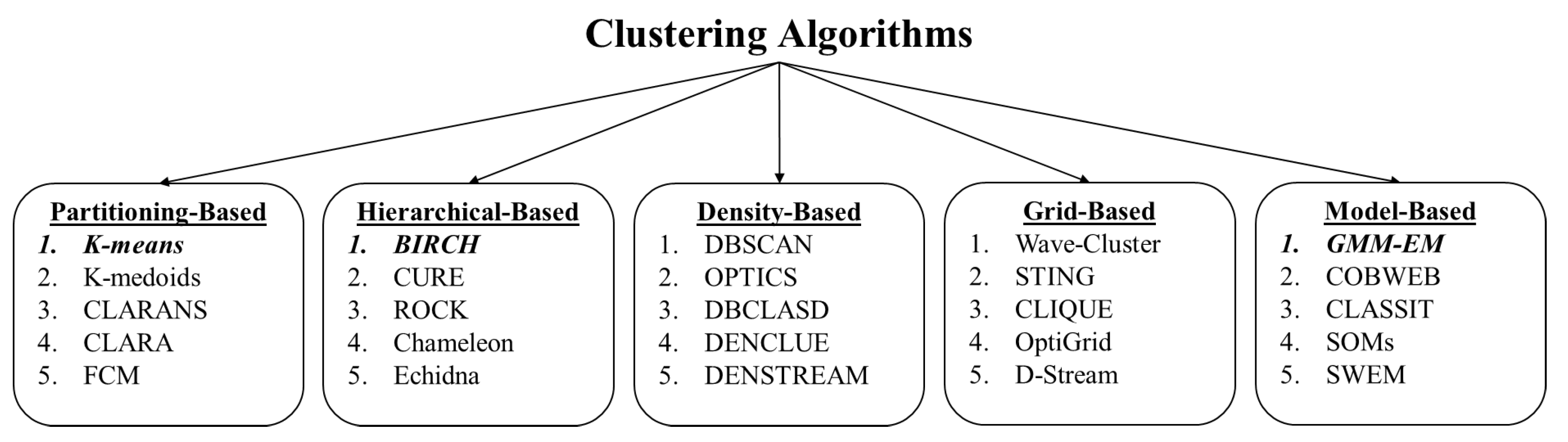
2.5. Comparison of Algorithms for Codebook Generation
| Algorithm 2 k-means |
|
Input X input vectors, k number of clusters Output C centroids, procedure K-means for do Random vector from X end for while not converged do Assign each vector in X to the closest centroid c for each do mean of vectors assigned to c end for end while end procedure |
| Algorithm 3 Birch |
|
Input X input vectors, T Threshold value for CF Tree Output C set of clusters procedure BIRCH for each do find the leaf node for insertion if leaf node is within the threshold condition then add to cluster update CF triples else if there is space for insertion then insert as a single cluster update CF triples else split leaf node redistribute CF features end if end if end for end procedure |
| Algorithm 4 Pairwise Nearest Neighbor. |
|
Input X input vectors, k number of clusters Output C centroids, procedure PNN while do FindNearestClusterPair() MergeClusters . end while end procedure |
| Algorithm 5 GMM |
|
Input X input vectors, k number of clusters Output C centroids, , procedure GMM for do Random vector from X Sample covariance end for while not converged do for do end for for do . end for end while end procedure |
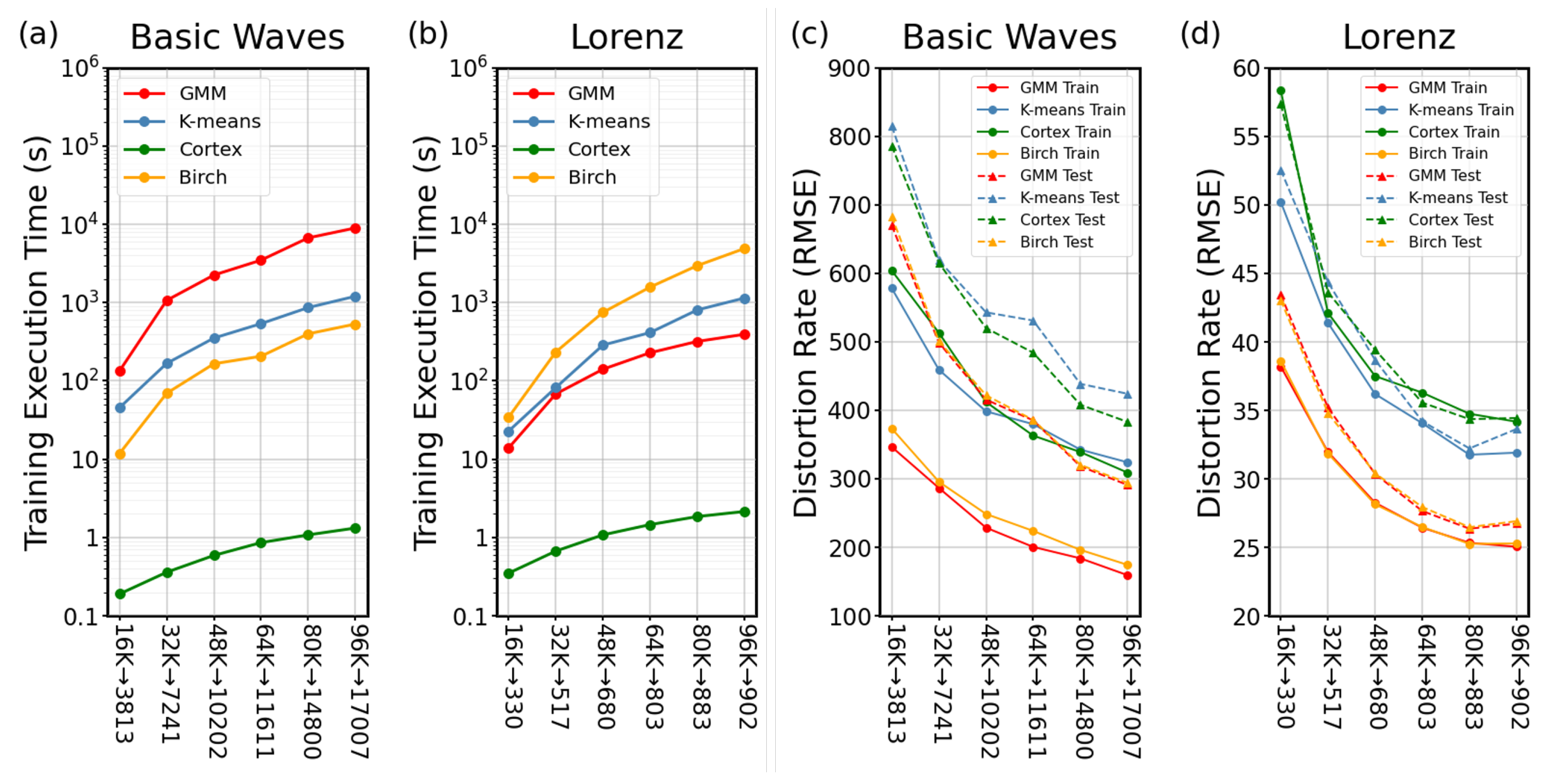
3. Results
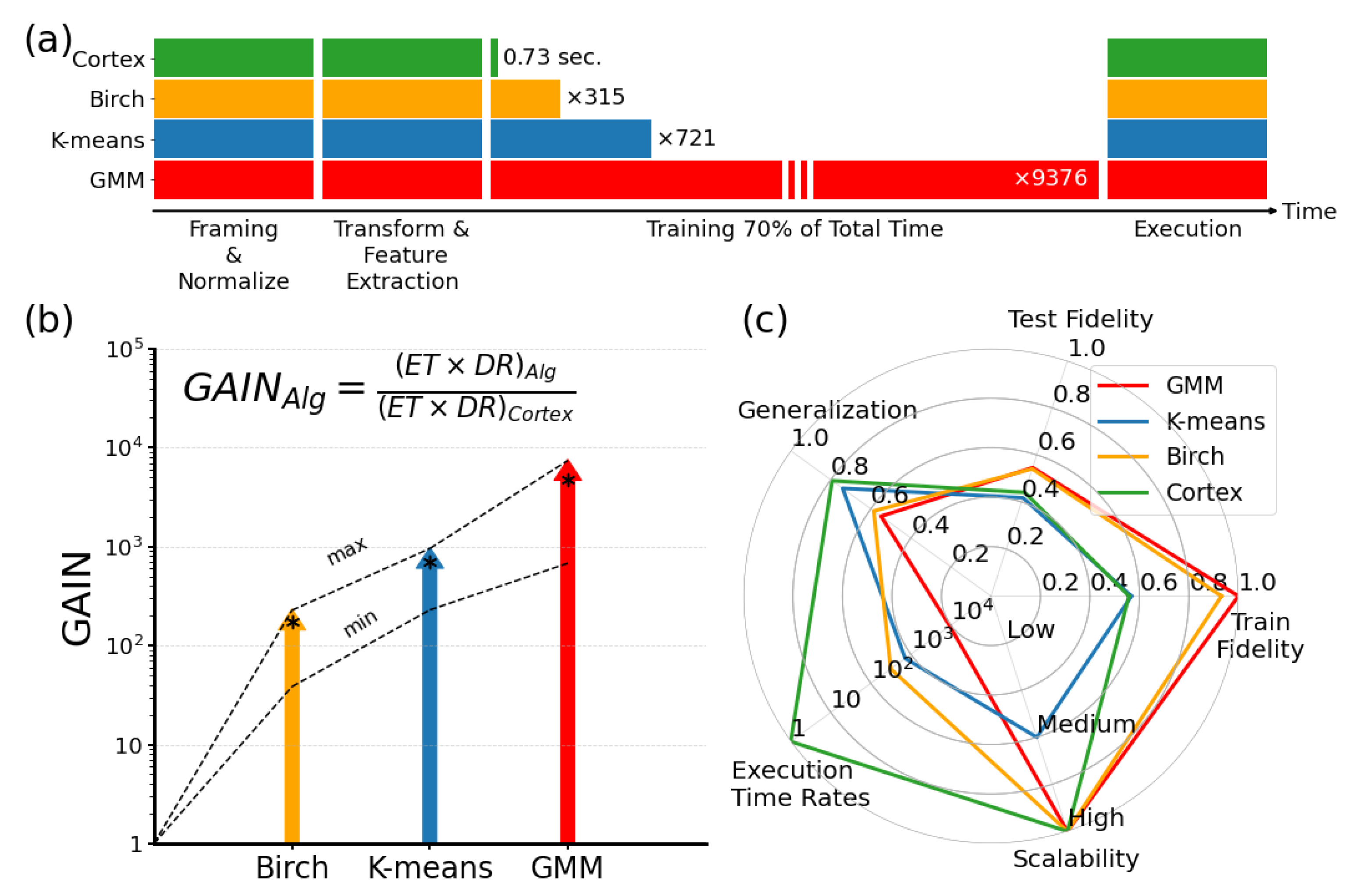
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
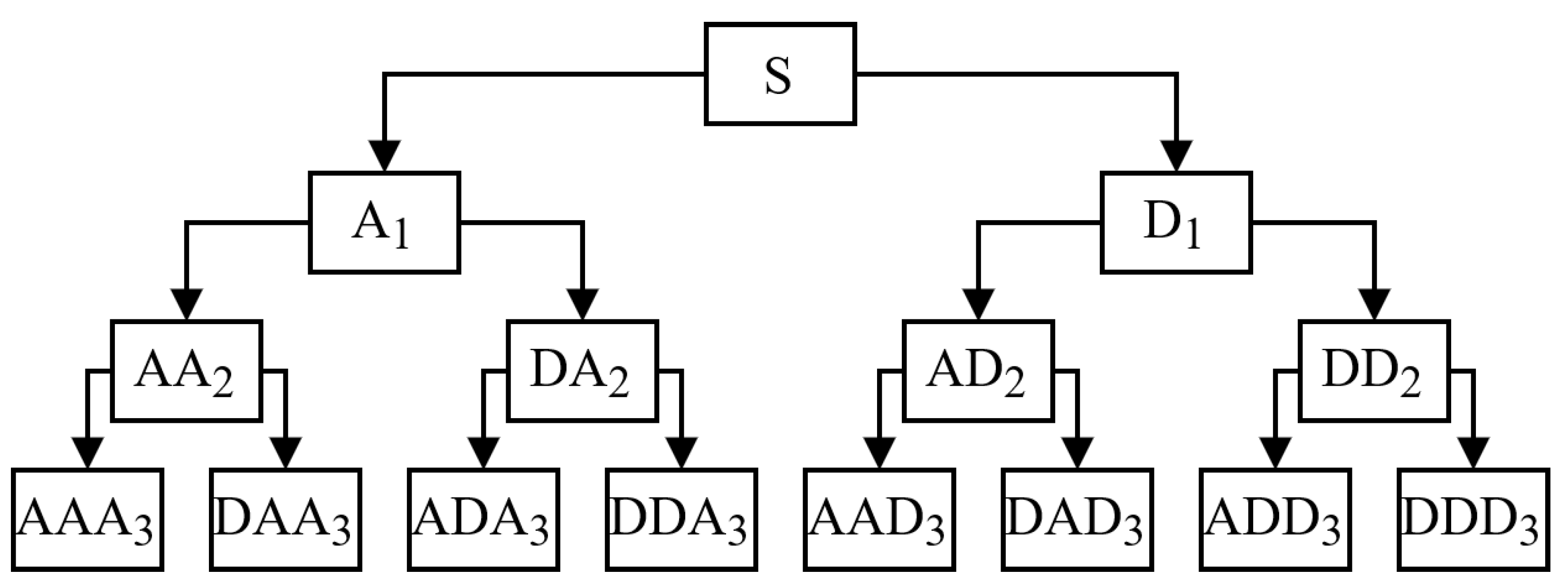
Appendix A. Wavelet Packet Transform

Appendix B. Justification for Using Hyperparameter Tuning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Random Initialize | K-Means Initialize | ||
|---|---|---|---|
| Tolerance | 0.01 | 0.001 | 0.01 |
| Distortion (Train) | 2559 | 234 | 234 |
| Distortion (Test) | 2611 | 430 | 430 |
| Execution Time (sec) | 12,909 | 10,880 | 6875 |
Appendix C. Cortical Coding Network Training: Minimizing Dissipation Energy and Maximizing Entropy
Appendix D. Numerical Presentation of Compared Algorithms in Figure 10c
| Train Fidelity | Test Fidelity | Execution Time Rates | Scalability | Generalization | |
|---|---|---|---|---|---|
| K-means | 0.566 | 0.417 | 721 | Medium | 0.737 |
| BIRCH | 0.929 | 0.539 | 315 | High | 0.580 |
| GMM/EM | 1 | 0.545 | 9376 | High | 0.545 |
| Cortical Coding | 0.557 | 0.440 | 1 | High | 0.790 |
References
- Gray, R. Vector quantization. IEEE Assp. Mag. 1984, 1, 4–29. [Google Scholar] [CrossRef]
- Pagès, G. Introduction to vector quantization and its applications for numerics. ESAIM Proc. Surv. 2015, 48, 29–79. [Google Scholar] [CrossRef] [Green Version]
- Kekre, H.; Sarode, T.K. Speech data compression using vector quantization. WASET Int. J. Comput. Inf. Sci. Eng. (IJCISE) 2008, 2, 251–254. [Google Scholar]
- Zou, Q.; Lin, G.; Jiang, X.; Liu, X.; Zeng, X. Sequence clustering in bioinformatics: An empirical study. Brief. Bioinform. 2020, 21, 1–10. [Google Scholar] [CrossRef]
- Gersho, A.; Gray, R.M. Vector Quantization and Signal Compression; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 159. [Google Scholar]
- Lu, T.C.; Chang, C.C. A Survey of VQ Codebook Generation. J. Inf. Hiding Multim. Signal Process. 2010, 1, 190–203. [Google Scholar]
- Equitz, W.H. A new vector quantization clustering algorithm. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1568–1575. [Google Scholar] [CrossRef]
- Shannon, C.E. Coding theorems for a discrete source with a fidelity criterion. IRE Nat. Conv. Rec 1959, 4, 1. [Google Scholar]
- Ezugwu, A.E.; Ikotun, A.M.; Oyelade, O.O.; Abualigah, L.; Agushaka, J.O.; Eke, C.I.; Akinyelu, A.A. A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Eng. Appl. Artif. Intell. 2022, 110, 104743. [Google Scholar] [CrossRef]
- Selim, S.Z.; Ismail, M.A. K-Means-Type Algorithms: A Generalized Convergence Theorem and Characterization of Local Optimality. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 81–87. [Google Scholar] [CrossRef]
- Huang, C.M.; Harris, R. A comparison of several vector quantization codebook generation approaches. IEEE Trans. Image Process. 1993, 2, 108–112. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian mixture models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Nasrabadi, N.; King, R. Image coding using vector quantization: A review. IEEE Trans. Commun. 1988, 36, 957–971. [Google Scholar] [CrossRef] [Green Version]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. Wavecluster: A multi-resolution clustering approach for very large spatial databases. In Proceedings of the 24rd International Conference on Very Large Data Bases—VLDB, New York, NY, USA, 24–27 August 1998; Volume 98, pp. 428–439. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Van Aerde, K.I.; Feldmeyer, D. Morphological and physiological characterization of pyramidal neuron subtypes in rat medial prefrontal cortex. Cereb. Cortex 2015, 25, 788–805. [Google Scholar] [CrossRef] [PubMed]
- Heida, T.; Rutten, W.; Marani, E. Understanding dielectrophoretic trapping of neuronal cells: Modelling electric field, electrode-liquid interface and fluid flow. J. Phys. D Appl. Phys. 2002, 35, 1592. [Google Scholar] [CrossRef]
- Varga, Z.; Jia, H.; Sakmann, B.; Konnerth, A. Dendritic coding of multiple sensory inputs in single cortical neurons in vivo. Proc. Natl. Acad. Sci. USA 2011, 108, 15420–15425. [Google Scholar] [CrossRef] [Green Version]
- Yuste, R. Dendritic spines and distributed circuits. Neuron 2011, 71, 772–781. [Google Scholar] [CrossRef] [Green Version]
- Kempermann, G. New neurons for ‘survival of the fittest’. Nat. Rev. Neurosci. 2012, 13, 727–736. [Google Scholar] [CrossRef]
- Lindvall, O.; Kokaia, Z. Stem cells for the treatment of neurological disorders. Nature 2006, 441, 1094–1096. [Google Scholar] [CrossRef]
- Gupta, D.S.; Bahmer, A. Increase in mutual information during interaction with the environment contributes to perception. Entropy 2019, 21, 365. [Google Scholar] [CrossRef] [Green Version]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Sparrow, C. The Lorenz Equations: Bifurcations, Chaos, and Strange Attractors; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 41. [Google Scholar]
- Sprott, J.C. Chaos and Time-Series Analysis; Oxford University Press: Oxford, UK, 2003; Volume 69. [Google Scholar]
- Cody, M.A. The wavelet packet transform: Extending the wavelet transform. Dr. Dobb’s J. 1994, 19, 44–46. [Google Scholar]
- Graps, A. An introduction to wavelets. IEEE Comput. Sci. Eng. 1995, 2, 50–61. [Google Scholar] [CrossRef]
- Litwin, L. FIR and IIR digital filters. IEEE Potentials 2000, 19, 28–31. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef] [Green Version]
- Rai, P.; Singh, S. A survey of clustering techniques. Int. J. Comput. Appl. 2010, 7, 1–5. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Olukanmi, P.O.; Twala, B. K-means-sharp: Modified centroid update for outlier-robust k-means clustering. In Proceedings of the 2017 Pattern Recognition Association of South Africa and Robotics and Mechatronics (PRASA-RobMech), Bloemfontein, South Africa, 29 November–1 December 2017; pp. 14–19. [Google Scholar]
- Zeebaree, D.Q.; Haron, H.; Abdulazeez, A.M.; Zeebaree, S.R. Combination of K-means clustering with Genetic Algorithm: A review. Int. J. Appl. Eng. Res. 2017, 12, 14238–14245. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Mahajan, M.; Nimbhorkar, P.; Varadarajan, K. The planar k-means problem is NP-hard. Theor. Comput. Sci. 2012, 442, 13–21. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Karczmarek, P.; Kiersztyn, A.; Pedrycz, W.; Al, E. K-Means-based isolation forest. Knowl.-Based Syst. 2020, 195, 105659. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Lorbeer, B.; Kosareva, A.; Deva, B.; Softić, D.; Ruppel, P.; Küpper, A. Variations on the clustering algorithm BIRCH. Big Data Res. 2018, 11, 44–53. [Google Scholar] [CrossRef]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Rasmussen, C. The infinite Gaussian mixture model. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1999; Volume 12, pp. 554–560. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Povey, D.; Burget, L.; Agarwal, M.; Akyazi, P.; Kai, F.; Ghoshal, A.; Glembek, O.; Goel, N.; Karafiát, M.; Rastrow, A.; et al. The subspace Gaussian mixture model—A structured model for speech recognition. Comput. Speech Lang. 2011, 25, 404–439. [Google Scholar] [CrossRef] [Green Version]
- Curtin, R.R.; Edel, M.; Lozhnikov, M.; Mentekidis, Y.; Ghaisas, S.; Zhang, S. mlpack 3: A fast, flexible machine learning library. J. Open Source Softw. 2018, 3, 726. [Google Scholar] [CrossRef] [Green Version]
- Novikov, A. PyClustering: Data Mining Library. J. Open Source Softw. 2019, 4, 1230. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Novak, R.; Bahri, Y.; Abolafia, D.A.; Pennington, J.; Sohl-Dickstein, J. Sensitivity and generalization in neural networks: An empirical study. arXiv 2018, arXiv:1802.08760. [Google Scholar]
- Coleman, C.; Kang, D.; Narayanan, D.; Nardi, L.; Zhao, T.; Zhang, J.; Bailis, P.; Olukotun, K.; Ré, C.; Zaharia, M. Analysis of dawnbench, a time-to-accuracy machine learning performance benchmark. ACM SIGOPS Oper. Syst. Rev. 2019, 53, 14–25. [Google Scholar] [CrossRef] [Green Version]
- Yucel, M.; Eryilmaz, S.E.; Ozgur, H. Data & Code of Compared Algorithms. 2021. Available online: https://zenodo.org/record/7180368#.Y28NWORBxPY (accessed on 1 November 2022).
- Yucel, M. Release Version of Cortical Coding Method. 2021. Available online: https://zenodo.org/record/7185297#.Y28NeuRBxPY (accessed on 1 November 2022).
- Walczak, B.; Massart, D. Noise suppression and signal compression using the wavelet packet transform. Chemom. Intell. Lab. Syst. 1997, 36, 81–94. [Google Scholar] [CrossRef]
- Hilton, M.L. Wavelet and wavelet packet compression of electrocardiograms. IEEE Trans. Biomed. Eng. 1997, 44, 394–402. [Google Scholar] [CrossRef]
- Shensa, M.J. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Sundararajan, D. Discrete Wavelet Transform: A Signal Processing Approach; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Fan, X.; Zuo, M.J. Gearbox fault detection using Hilbert and wavelet packet transform. Mech. Syst. Signal Process. 2006, 20, 966–982. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yucel, M.; Bagis, S.; Sertbas, A.; Sarikaya, M.; Ustundag, B.B. Brain Inspired Cortical Coding Method for Fast Clustering and Codebook Generation. Entropy 2022, 24, 1678. https://doi.org/10.3390/e24111678
Yucel M, Bagis S, Sertbas A, Sarikaya M, Ustundag BB. Brain Inspired Cortical Coding Method for Fast Clustering and Codebook Generation. Entropy. 2022; 24(11):1678. https://doi.org/10.3390/e24111678
Chicago/Turabian StyleYucel, Meric, Serdar Bagis, Ahmet Sertbas, Mehmet Sarikaya, and Burak Berk Ustundag. 2022. "Brain Inspired Cortical Coding Method for Fast Clustering and Codebook Generation" Entropy 24, no. 11: 1678. https://doi.org/10.3390/e24111678
APA StyleYucel, M., Bagis, S., Sertbas, A., Sarikaya, M., & Ustundag, B. B. (2022). Brain Inspired Cortical Coding Method for Fast Clustering and Codebook Generation. Entropy, 24(11), 1678. https://doi.org/10.3390/e24111678