
Reservoir Dynamic Interpretability for Time Series Prediction: A Permutation Entropy View
 ,
,
Abstract
:1. Introduction
- We develop two reservoir dynamic analysis methods based on PE from the instantaneous and global modeling perspectives. This is the first attempt to use PE and its multiscale modeling tools to reveal the relationship between reservoir richness and projection capacity.
- We investigate the sensitivity of ISE and GSE on hyperparameters affecting reservoir richness.
- We use multiscale complexity–entropy to analyze the global reservoir and neuron-level states to verify the single-scale and input-driven properties of reservoirs.
- We reveal the multistep and multiscale relationships between ESN performance and reservoir dynamic, which is achieved by measuring the Pearson correlations between nonlinear approximation/memory capacity and global PE of neurons’ states.
2. Preliminary
2.1. Motivation
2.2. Esn Architecture
3. Methodologies
3.1. Permutation Entropy Measure of Reservoir Dynamics
| Algorithm 1 PE analysis on reservoir states |
Input: Datasets Output:,
|
3.2. Multiscale Complexity-Entropy Analysis
4. Experiments
4.1. Dataset
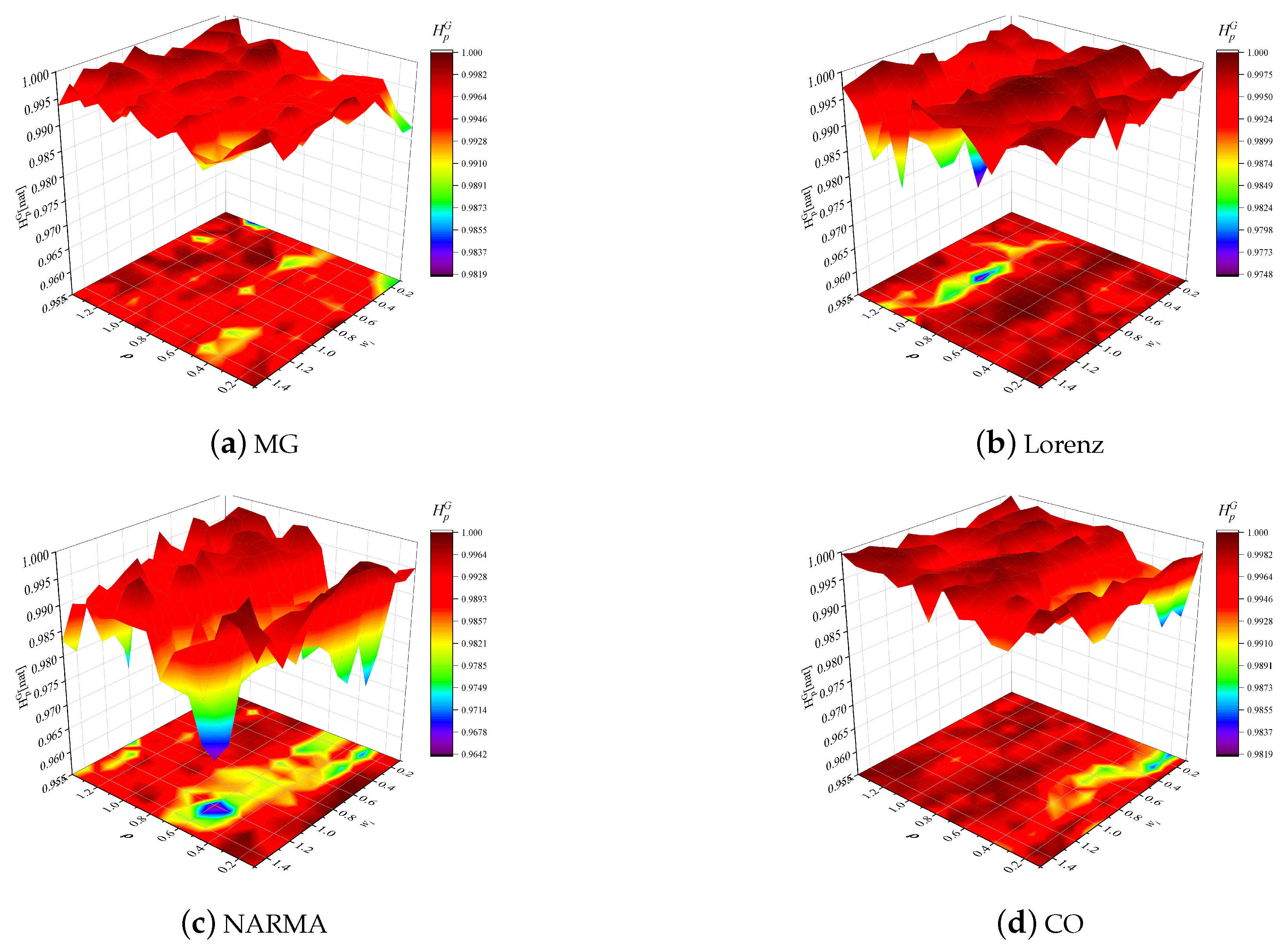
4.2. ISE Analysis
4.3. GSE Analysis
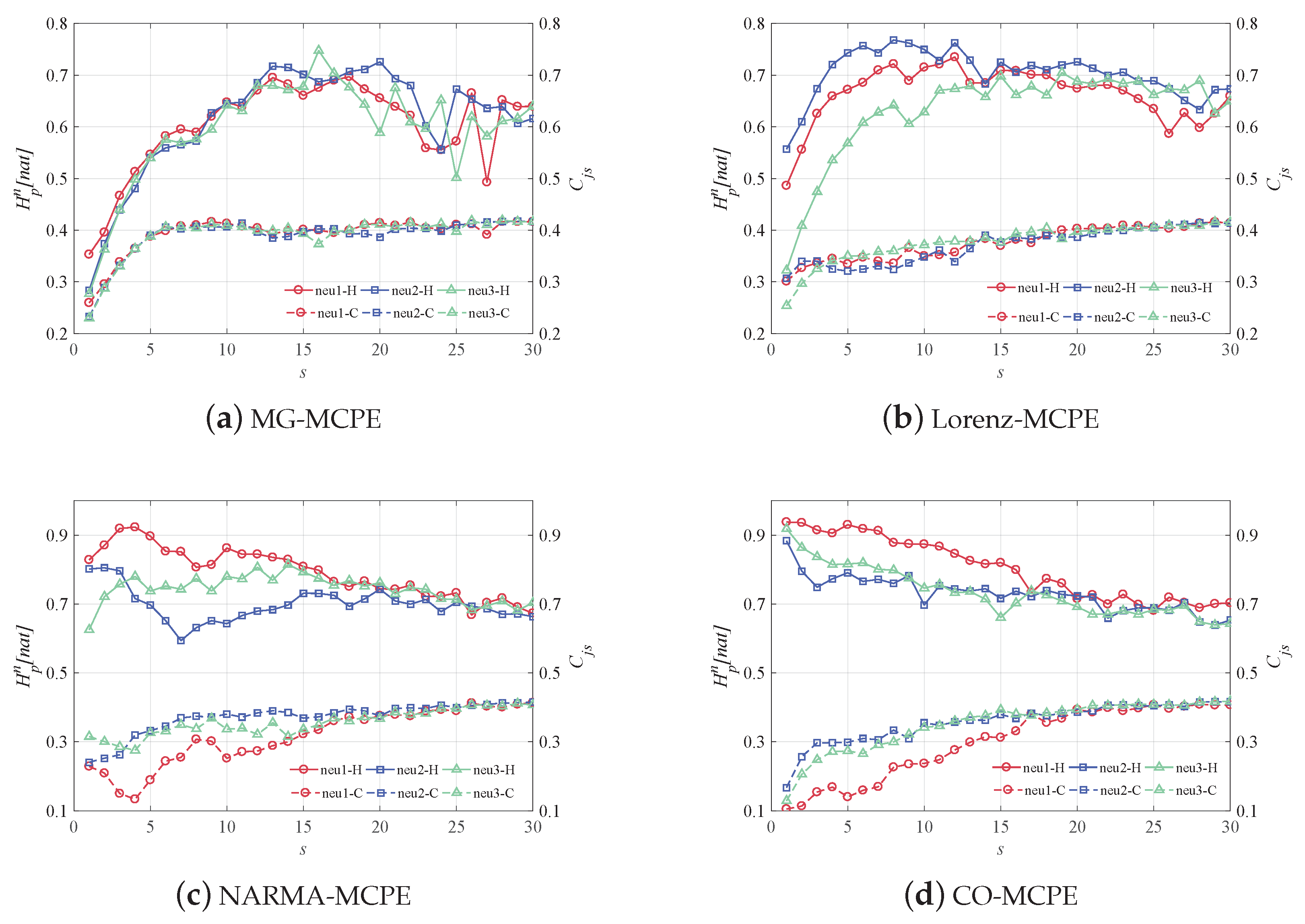
4.4. Multiscale Reservoir Dynamics
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviations | Description |
| ESN | Echo state network |
| PE | Permutation entropy |
| ISE | Instantaneous state entropy |
| GSE | Global state entropy |
| RC | Reservoir computing |
| RP | Recurrence plots |
| ASE | Average state entropy |
| SCM | Statistical complexity measure |
| MCPE | Multiscale complexity permutation entropy |
| MPE | Multiscale permutation entropy |
| CECP | Complexity–entropy causal plane |
| MG | Mackey–Glass |
| NARMA | Nonlinear autoregressive moving average |
| CO | Crude oil |
| MSE | Mean square error |
| MC | Memory capacity |
| Notation | Description |
| The state of RC at time t | |
| The nth neuron of RC | |
| W | Internal weight matrix of ESN |
| N, n | The number of RC neurons |
| T, t | Time |
| X | Internal state matrix of the reservoir |
| Y | Output matrix of ESN |
| m | Embedding dimension |
| Delay time | |
| The state entropy of all neurons in the reservoir at time t | |
| The time-varying state entropy of nth neuron | |
| The value of ISE | |
| The value of GSE | |
| s | The scale factor |
| The spectral radius of reservoir | |
| The value of SCM |
References
- Gauthier, D.J.; Bollt, E.; Griffith, A.; Barbosa, W.A. Next generation reservoir computing. Nat. Commun. 2021, 12, 5564. [Google Scholar] [CrossRef]
- Wang, L.; Su, Z.; Qiao, J.; Deng, F. A pseudo-inverse decomposition-based self-organizing modular echo state network for time series prediction. Appl. Soft Comput. 2022, 116, 108317. [Google Scholar] [CrossRef]
- Na, X.; Han, M.; Ren, W.; Zhong, K. Modified BBO-Based Multivariate Time-Series Prediction System With Feature Subset Selection and Model Parameter Optimization. IEEE Trans. Cybern. 2022, 52, 2163–2173. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, Y.R.; Wang, S.; Wang, L. Optimizing echo state network with backtracking search optimization algorithm for time series forecasting. Eng. Appl. Artif. Intell. 2019, 81, 117–132. [Google Scholar] [CrossRef]
- Xu, M.; Yang, Y.; Han, M.; Qiu, T.; Lin, H. Spatio-Temporal Interpolated Echo State Network for Meteorological Series Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1621–1634. [Google Scholar] [CrossRef]
- Jalalvand, A.; Demuynck, K.; De Neve, W.; Martens, J.P. On the application of reservoir computing networks for noisy image recognition. Neurocomputing 2018, 277, 237–248. [Google Scholar] [CrossRef] [Green Version]
- Tong, Z.; Tanaka, G. Reservoir Computing with Untrained Convolutional Neural Networks for Image Recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1289–1294. [Google Scholar]
- Sun, L.; Jin, B.; Yang, H.; Tong, J.; Liu, C.; Xiong, H. Unsupervised EEG feature extraction based on echo state network. Inf. Sci. 2019, 475, 1–17. [Google Scholar] [CrossRef]
- He, Q.; Pang, Y.; Jiang, G.; Xie, P. A Spatio-Temporal Multiscale Neural Network Approach for Wind Turbine Fault Diagnosis with Imbalanced SCADA Data. IEEE Trans. Ind. Inform. 2021, 17, 6875–6884. [Google Scholar] [CrossRef]
- Cabessa, J.; Hernault, H.; Kim, H.; Lamonato, Y.; Levy, Y.Z. Efficient Text Classification with Echo State Networks. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Fan, F.L.; Xiong, J.; Li, M.; Wang, G. On Interpretability of Artificial Neural Networks: A Survey. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 741–760. [Google Scholar] [CrossRef]
- Bianchi, F.M.; Livi, L.; Alippi, C. Investigating Echo-State Networks Dynamics by Means of Recurrence Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 427–439. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.C.; Loo, C.K. On the Post Hoc Explainability of Optimized Self-Organizing Reservoir Network for Action Recognition. Sensors 2022, 22, 1905. [Google Scholar] [CrossRef]
- Bianchi, F.M.; Livi, L.; Alippi, C.; Jenssen, R. Multiplex visibility graphs to investigate recurrent neural network dynamics. Sci. Rep. 2017, 7, 44037. [Google Scholar] [CrossRef] [Green Version]
- Ceni, A.; Ashwin, P.; Livi, L. Interpreting Recurrent Neural Networks Behaviour via Excitable Network Attractors. Cogn. Comput. 2020, 12, 330–356. [Google Scholar] [CrossRef] [Green Version]
- Variengien, A.; Hinaut, X. A journey in ESN and LSTM visualisations on a language task. arXiv 2020, arXiv:2012.01748. [Google Scholar]
- Armentia, U.; Barrio, I.; Ser, J.D. Performance and Explainability of Reservoir Computing Models for Industrial Prognosis. In Proceedings of the 16th International Conference on Soft Computing Models in Industrial and Environmental Applications (SOCO 2021), Bilbao, Spain, 22–24 September 2022; pp. 24–36. [Google Scholar]
- Barredo Arrieta, A.; Gil-Lopez, S.; Laña, I.; Bilbao, M.N.; Del Ser, J. On the post-hoc explainability of deep echo state networks for time series forecasting, image and video classification. Neural Comput. Appl. 2022, 34, 10257–10277. [Google Scholar] [CrossRef]
- Alao, O.; Lu, P.Y.; Soljacic, M. Discovering Dynamical Parameters by Interpreting Echo State Networks. Present. Neurips Sci. Workshop Dec. 2021. Available online: https://openreview.net/forum?id=coaSxusdBLX (accessed on 4 September 2022).
- Baptista, M.L.; Goebel, K.; Henriques, E.M. Relation between prognostics predictor evaluation metrics and local interpretability SHAP values. Artif. Intell. 2022, 306, 103667. [Google Scholar] [CrossRef]
- Han, X.; Zhao, Y. Reservoir computing dissection and visualization based on directed network embedding. Neurocomputing 2021, 445, 134–148. [Google Scholar] [CrossRef]
- Miao, W.; Narayanan, V.; Li, J.S. Interpretable Design of Reservoir Computing Networks Using Realization Theory. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Z.; Lu, C. Self-adaptive bearing fault diagnosis based on permutation entropy and manifold-based dynamic time warping. Mech. Syst. Signal Process. 2019, 114, 658–673. [Google Scholar] [CrossRef]
- Zunino, L.; Soriano, M.C.; Rosso, O.A. Distinguishing chaotic and stochastic dynamics from time series by using a multiscale symbolic approach. Phys. Rev. E 2012, 86, 046210. [Google Scholar] [CrossRef]
- Ma, F.; Fan, Q.; Ling, G. Complexity-Entropy Causality Plane Analysis of Air Pollution Series. Fluct. Noise Lett. 2022, 21, 2250011. [Google Scholar] [CrossRef]
- Zheng, J.; Pan, H.; Yang, S.; Cheng, J. Generalized composite multiscale permutation entropy and Laplacian score based rolling bearing fault diagnosis. Mech. Syst. Signal Process. 2018, 99, 229–243. [Google Scholar] [CrossRef]
- à Mougoufan, J.B.B.; Fouda, J.A.E.; Tchuente, M.; Koepf, W. Adaptive ECG beat classification by ordinal pattern based entropies. Commun. Nonlinear Sci. Numer. Simul. 2020, 84, 105156. [Google Scholar] [CrossRef]
- Yin, Y.; Shang, P.; Ahn, A.C.; Peng, C.K. Multiscale joint permutation entropy for complex time series. Phys. Stat. Mech. Its Appl. 2019, 515, 388–402. [Google Scholar] [CrossRef]
- Ozturk, M.C.; Xu, D.; Principe, J.C. Analysis and Design of Echo State Networks. Neural Comput. 2007, 19, 111–138. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A. Architectural richness in deep reservoir computing. Neural Comput. Appl. 2022, 1–18. [Google Scholar] [CrossRef]
- Silva, A.S.A.; Menezes, R.S.C.; Rosso, O.A.; Stosic, B.; Stosic, T. Complexity entropy-analysis of monthly rainfall time series in northeastern Brazil. Chaos Solitons Fractals 2021, 143, 110623. [Google Scholar] [CrossRef]
- Zhang, B.; Shang, P.; Zhou, Q. The identification of fractional order systems by multiscale multivariate analysis. Chaos Solitons Fractals 2021, 144, 110735. [Google Scholar] [CrossRef]
- Pessa, A.A.; Ribeiro, H.V. Ordpy: A Python package for data analysis with permutation entropy and ordinal network methods. Chaos 2021, 31, 063110. [Google Scholar] [CrossRef]
- Herteux, J.; Räth, C. Breaking symmetries of the reservoir equations in echo state networks. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 123142. [Google Scholar] [CrossRef]
- Mastroeni, L.; Vellucci, P. Replication in Energy Markets: Use and Misuse of Chaos Tools. Entropy 2022, 24, 701. [Google Scholar] [CrossRef]
- Li, J.; Shang, P.; Zhang, X. Financial time series analysis based on fractional and multiscale permutation entropy. Commun. Nonlinear Sci. Numer. Simul. 2019, 78, 104880. [Google Scholar] [CrossRef]
- Xu, M.; Han, M. Adaptive Elastic Echo State Network for Multivariate Time Series Prediction. IEEE Trans. Cybern. 2016, 46, 2173–2183. [Google Scholar] [CrossRef]
- Yusoff, M.H.; Chrol-Cannon, J.; Jin, Y. Modeling neural plasticity in echo state networks for classification and regression. Inf. Sci. 2016, 364, 184–196. [Google Scholar] [CrossRef]
- Li, D.; Liu, F.; Qiao, J.; Li, R. Structure optimization for echo state network based on contribution. Tsinghua Sci. Technol. 2018, 24, 97–105. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | MG | Lorenz | NARMA | CO |
|---|---|---|---|---|
| PE | 0.55409 | 0.75621 | 0.97349 | 0.96773 |
| Step | Parameter Space | Correlation | MG | Lorenz | NARMA | CO |
|---|---|---|---|---|---|---|
| 1 | vs. MSE | −0.96069 | −0.95188 | −0.85053 | −0.69467 | |
| vs. MC | 0.928394 | 0.971848 | 0.791282 | 0.931725 | ||
| vs. MSE | −0.47532 | −0.41578 | −0.52174 | −0.39389 | ||
| vs. MC | 0.588914 | 0.189191 | 0.376211 | 0.689503 | ||
| 3 | vs. MSE | −0.91901 | −0.89865 | −0.8507 | −0.79467 | |
| vs. MC | 0.939181 | 0.921805 | 0.841936 | 0.92253 | ||
| vs. MSE | −0.56666 | −0.348145 | −0.56681 | −0.41327 | ||
| vs. MC | 0.466588 | 0.27456 | 0.59542 | 0.35036 | ||
| 5 | vs. MSE | −0.92581 | −0.93273 | −0.94301 | −0.86987 | |
| vs. MC | 0.927302 | 0.920522 | 0.921338 | 0.91253 | ||
| vs. MSE | −0.635644 | −0.45148 | −0.18493 | −0.23585 | ||
| vs. MC | 0.53558 | 0.554063 | 0.231826 | 0.666532 |
| s | MG | Lorenz | NARMA | CO | ||||
|---|---|---|---|---|---|---|---|---|
| MSE | MSE | MSE | MSE | |||||
| 1 | 6.33 × 10 | 0.973 | 3.53 × 10 | 0.968 | 6.22 × 10 | 0.975 | 2.73 × 10 | 0.973 |
| 2 | 1.14 × 10 | 0.945 | 6.59 × 10 | 0.93 | 6.44 × 10 | 0.945 | 2.77 × 10 | 0.944 |
| 3 | 1.20 × 10 | 0.933 | 6.52 × 10 | 0.902 | 6.68 × 10 | 0.89 | 2.96 × 10 | 0.906 |
| 4 | 1.26 × 10 | 0.892 | 7.77 × 10 | 0.901 | 6.76 × 10 | 0.888 | 3.04 × 10 | 0.889 |
| 5 | 1.30 × 10 | 0.872 | 8.82 × 10 | 0.871 | 6.78 × 10 | 0.863 | 3.15 × 10 | 0.835 |
| 6 | 1.36 × 10 | 0.827 | 1.06 × 10 | 0.813 | 6.79 × 10 | 0.827 | 3.26 × 10 | 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Hao, M.; Wang, Y.; Wang, Y.; Li, Z.; Li, Y. Reservoir Dynamic Interpretability for Time Series Prediction: A Permutation Entropy View. Entropy 2022, 24, 1709. https://doi.org/10.3390/e24121709
Sun X, Hao M, Wang Y, Wang Y, Li Z, Li Y. Reservoir Dynamic Interpretability for Time Series Prediction: A Permutation Entropy View. Entropy. 2022; 24(12):1709. https://doi.org/10.3390/e24121709
Chicago/Turabian StyleSun, Xiaochuan, Mingxiang Hao, Yutong Wang, Yu Wang, Zhigang Li, and Yingqi Li. 2022. "Reservoir Dynamic Interpretability for Time Series Prediction: A Permutation Entropy View" Entropy 24, no. 12: 1709. https://doi.org/10.3390/e24121709