Abstract
In the process of bridge management, large amounts of domain information are accumulated, such as basic attributes, structural defects, technical conditions, etc. However, the valuable information is not fully utilized, resulting in insufficient knowledge service in the field of bridge management. To tackle these problems, this paper proposes a complex knowledge base question answering (C-KBQA) framework for intelligent bridge management based on multi-task learning (MTL) and cross-task constraints (CTC). First, with C-KBQA as the main task, part-of-speech (POS) tagging, topic entity extraction (TEE), and question classification (QC) as auxiliary tasks, an MTL framework is built by sharing encoders and parameters, thereby effectively avoiding the error propagation problem of the pipeline model. Second, cross-task semantic constraints are provided for different subtasks via POS embeddings, entity embeddings, and question-type embeddings. Finally, using template matching, relevant query statements are generated and interaction with the knowledge base is established. The experimental results show that the proposed model outperforms compared mainstream models in terms of TEE and QC on bridge management datasets, and its performance in C-KBQA is outstanding.
1. Introduction
In contrast to general search engines, question answering (QA) systems can simply and quickly provide queries with accurate and clear answers rather than a series of documents related to natural language questions [1]. The QA system mainly includes three parts: Question analysis, information retrieval, and answer processing. As the main tasks of question parsing, topic entity extraction (TEE) and question classification (QC) play important roles in information retrieval and answer processing [2]. With the continuous development in big data knowledge engineering, data have realized the transformation and upgrading from information to knowledge, and further deepened the research on knowledge base QA (KBQA) [3]. According to the difficulty of the question, it can be mainly divided into simple KBQA and complex KBQA (C-KBQA) [4].
Bridge management is essential to ensure bridges are always in safe condition [5]. In addition to direct measures, such as detection, monitoring, evaluation, maintenance, and reinforcement, bridge management includes some indirect measures, such as data management, emergency plans, and auxiliary decision-making [6]. At present, most of the bridge management data are stored in the form of electronic documents, e.g., inspection reports, which contain large amounts of valuable information to be further excavated and integrated. Taking full advantage of the data can help bridge engineers in analyzing bridge defects and assisting in their judgment and decision-making [7]. Therefore, an intelligent system is urgently needed to realize the structured storage of management data and further realize the effective interaction between bridge engineers and the databases. For the urgent need in intelligent bridge management, the KBQA technology is undoubtedly the best solution.
The KBQA system can be used as a portable intelligent terminal to meet the requirements of fine-grained domain information interaction in bridge management scenarios in real time, thereby supporting knowledge sharing in specific domains and improving work efficiency. For example, bridge engineers can use the KBQA system to query the structural attributes of bridges and the defect information of bridge members, quickly grasp the similar characteristics of bridges in the area, and achieve the purpose of assisting in decision-making. However, the KBQA research that is fully applicable to the bridge engineering field is still in the preliminary exploratory stage [8], and some research in related fields can provide insight [9,10,11], but there are still three main challenges:
- (1)
- Due to the privacy policy, bridge management data have not been fully disclosed, and the industry lacks ready-made knowledge base and question answering corpus, resulting in insufficient data support for research in this field. In addition, important information, such as basic attributes, defect damage, and technical conditions are not fully utilized, leading to insufficient knowledge services in the field of bridge management.
- (2)
- Bridge management information has great domain characteristics in data storage, term description, expression, etc. For example, the topic entity boundary is not clear with a significant amount of specialized words, and the question types are not evenly distributed. Existing methods cannot directly solve these problems.
- (3)
- The bridge management questions are relatively complex, involving multiple-hops, judgment, constraints, numerical calculation, aggregation operation, etc.
To solve the above-mentioned problems, this paper proposes a cross-task constraint-enhanced multi-task learning (MTL) framework to solve the C-KBQA of bridge management. Figure 1 shows the overall process of C-KBQA for bridge management.

Figure 1.
The overall process of C-KBQA for bridge management. For the natural language question (NLQ) given by the user, the purpose of C-KBQA for bridge management is to generate the corresponding Cypher query. Then, the Neo4j graph database is searched to return the answer “3类” (Level 3) to the user. The process of transforming questions into structured queries involves some key technologies, including TEE, POS, and QC.
The proposed framework classifies fine-grained domain C-KBQA as the main task, TEE and QC as two key auxiliary tasks, and part-of-speech (POS) tagging as a secondary auxiliary task. First, we jointly train model embeddings for multiple auxiliary tasks by sharing similar pretrained language encoder models and sharing parameters. Second, POS information, question types, and topic entities are introduced into different subtasks as external knowledge to enhance cross-task semantic constraints. Finally, according to the bridge management domain characteristics of TEE and QC, model improvement and innovation are carried out at the feature fusion layer. The main contributions of this paper are as follows:
- (1)
- We constructed a bridge management domain knowledge base and question answering corpus, realized the integration and utilization of data, and laid the data foundation for the question answering task in this field.
- (2)
- Cross-task constraints (CTC) make the semantics of subtasks interrelated, enrich the expression of contextual semantic features of domain questions, and can effectively solve problems, such as unclear entity boundaries and inaccurate professional vocabulary recognition. MTL strategy can reduce the error propagation of TEE and QC tasks. The template matching method combines semantic analysis and neural network technology to convert natural language questions into answer templates, which can answer more complex questions and maximize the accuracy of QA, meeting the complex application scenarios of bridge management.
- (3)
- This research compensates for the shortage of fine-grained knowledge service in the bridge management field and realizes the fine-grained information interaction between bridge management users and domain knowledge base.
The remainder of the paper is organized as follows. Section 2 provides an overview of related works. Section 3 presents the overall architecture of the proposed model and introduces its key components in detail. Section 4 presents the experimental and evaluation results of the proposed model. Section 5 demonstrates an example of the C-KBQA system platform of bridge management. Finally, Section 6 concludes the paper and outlines future work directions.
2. Related Work
With the rapid development in natural language processing (NLP) and neural networks, the research on KBQA has gradually shifted from general domains to specific domains. However, the research related to the field of bridge engineering is still in its infancy. In this section, we reviewed the relevant topics of KBQA.
2.1. Complex Knowledge Base Question Answering
Complex questions contain multiple entities and relationships; therefore, C-KBQA involves multiple knowledge triples [12], including operations, such as multi-hop, aggregation, logical operations, and reasoning [13]. At present, the mainstream methods of C-KBQA include semantic parsing, information retrieval, and template matching [14].
Semantic parsing converts natural language questions into logical symbols which can be used on the knowledge base to obtain answers [15]. For example, Sun et al. [16] proposed a multi-strategy method based on semantic parsing that combines sentence-lexical level semantics to represent high-level semantics of complex questions. Zhang et al. [17] proposed a KBQA semantic parsing model based on structural information constraints (SIR). Guo et al. [18] introduced dialogue memory management to manipulate historical entities, predicates, and logical forms, in order to infer the logical form of the current utterance. The method based on semantic parsing can achieve a more interpretable reasoning process by generating a logical form. However, these methods depend heavily on the design of the logical form and the quality of the parser algorithm [19]. It is difficult for existing semantic parsers to cover a variety of complex queries [20].
Information retrieval-based methods extract the relevant information of the questions from the knowledge base, and then rank all the extracted entities and relationships [21]. For instance, Zhou et al. [22] proposed the use of information retrieval to update reasoning instructions in the reasoning stage, in order to improve the reasoning ability of complex problems. Jin et al. [23] decomposed complex questions into multiple triplet patterns, and then retrieved the matching candidate subgraphs from the knowledge base to find answers through a semantic similarity evaluation. Answer ranking is applicable to a small search space [24], while complex questions contain more relationships and subject entities, which increases the difficulty in searching and ranking for candidate answers.
Template matching-based approaches aim to generate structured query statements using predefined templates [25]. In order to perform the question resolution process of C-KBQA, Gomes et al. [26] proposed a hereditary attentive template-based approach for C-KBQA. This method uses the combination of semantic analysis and neural network technology to classify natural language questions into answer templates. However, the limited number of templates and insufficient coverage have become a bottleneck hindering performance improvement [27].
The above-mentioned methods all involve some key subtasks, including TEE, QC, semantic matching, etc. [28]. A popular method of subtask composition is the pipeline model [29]. For example, Chen et al. [30] constructed a KBQA pipeline system to identify the knowledge base relationship corresponding to the question. However, the pipeline model consists of concatenated subtasks, and the prediction results of the previous task will affect the subsequent tasks, thus causing serious error propagation. To solve this problem, MTL has been applied to complex question answering [31,32]. For example, Yang et al. [33] proposed a new multi-tasking and knowledge-enhanced multi-head interactive attention network, which classifies questions as auxiliary tasks and conducts community question answering through multi-tasking learning. In addition, multi-tasking joint learning can enhance the generalization ability of the model [34].
2.2. Domain-Specific KBQA Approaches
In recent years, KBQA technologies have begun to be applied in specific fields, e.g., biomedicine [35], finance [36], and education [37]. With the deepening of KBQA research in specific domains, some basic works have been carried out in bridge engineering related fields. For example, Wu et al. [38] discussed the role and challenges of NLP in intelligent construction, providing a reference for the application of NLP technology in the industrial field. In the QA system of building regulations proposed by Zhong et al. [39], the BERT pretraining model is used for feature extraction questions. Li et al. [40] used narrative descriptions in bridge inspection reports as data sources and proposed a data-driven framework to support automatic condition recommendation and real-time quality control. Xia et al. [41] proposed a data-driven bridge condition assessment framework to effectively predict the future condition of bridges. Although the research in related fields can provide reference for the field of bridge management, the existing methods cannot be directly applied to the question answering task of bridge management due to the strong field characteristics.
Furthermore, our previous research laid the foundation for bridge management C-KBQA. For example, the previous work [42] constructed bridge structure and health monitoring ontology using Semantic Web technology, and realized multi-angle fine-grained modeling of bridge structure, SHM system, sensor, and perception data, which lays a foundation for the semantic ontology construction of bridge maintenance. With the in-depth research, Li et al. [43] proposed a dictionary-enhanced machine reading comprehension NER neural model for identifying planes and nested entities from Chinese bridge detection texts. In the previous work [44], a new entity related attention neural network model was proposed for joint extraction of entities and relationships in bridge inspection. The research on domain text information extraction provides technical support for the construction of bridge management knowledge graph. Yang et al. [45] proposed a novel BigKE-based intelligent bridge management and maintenance framework according to the big data knowledge engineering paradigm, pointing out the direction for bridge management knowledge services. However, the above-mentioned work is partial to theoretical research and technical preparation. The core work of bridge management QA task has not been carried out, and the problems, such as insufficient utilization of bridge management data and insufficient domain knowledge service, have not been effectively solved.
2.3. Gaps and Challenges
Research status shows that the existing methods cannot be directly applied to the field of bridge management, and bridge management C-KBQA faces many challenges. Therefore, combined with the existing theories and methods, as well as the characteristics of the field, a reasonable solution for bridge management C-KBQA is briefly presented.
- (1)
- The bridge management process is concerned with numerical values, such as technical condition level and score, as well as textual information, such as structural defect and maintenance advice. Therefore, the Neo4j attribute graph structure can be used for storing bridge management knowledge. In addition, the question types in the field of bridge management are relatively fixed; therefore, template matching can give full scope to its advantages, which can better ensure the QA effect in the practical application scenarios of bridge management.
- (2)
- Bridge management questions often contain multiple topic entities with ill-defined boundaries. For example, the question “A桥桥面系的技术状况等级是多少?” (“What is the technical condition level of the bridge deck system of Bridge A?”) contains two topic entities “A桥” (“Bridge A”) and “桥面系” (“Deck System”). The same character “桥” (“bridge”) exists between topic entities, but without any separators. In addition, the short text of bridge management questions lacks contextual semantics, which increases the difficulty in professional vocabulary recognition. Moreover, bridge management questions can be classified according to two levels: Coarse-grained and fine-grained. For example, the coarse-grained type for the question “A桥和B桥有哪些共同缺陷?” (“What common defects do Bridge A and Bridge B have?”) is “损伤缺陷” (“damage defects”), and its fine-grained type is “共同缺陷” (“common defects”). Therefore, it is necessary to clarify the entity boundary and assist in the fine classification of questions through POS tagging. To improve the contextual comprehension ability of questions, the semantic correlation between subtasks should be strengthened to form CTC. (Due to the privacy property of bridge management information, letters are used rather than real bridge names in this paper).
- (3)
- There is no strict execution order between the TEE and QC tasks. Therefore, the multiple subtasks of bridge management C-KBQA can be jointly trained to avoid error propagation and save computational resources.
3. Methodology
Aiming at the domain characteristics of the bridge management C-KBQA, we propose an MTL model that joints POS tagging, TEE, and QC. First, we analyze each subtask module and then elaborate on the constraint strategy. As shown in Figure 2, the model adopts BERT as a shared character-grained embedding model for TEE and QC. In order to make full use of the correlation information between different tasks and achieve CTC, question-type embeddings, BERT character embeddings, and POS embeddings are used as joint encodings for TEE. Similarly, BERT character embeddings, POS embeddings, and entity embeddings are used as joint encodings for QC. Bi-directional long short-term memory (BiLSTM) network is shared for feature extraction, conditional random field (CRF) is used as a decoder for TEE, and question types are obtained by max pooling. According to the output of the multi-task module, the template is matched and the semantic map is constructed. Under the constraints of POS and entity type combinations, the query path is locked, and finally a query is generated according to the extracted topic entities. In contrast to the end-to-end deep learning framework, the proposed model framework is a combination of semantic analysis and deep learning. For specific domain question answering tasks with relatively fixed question types, template matching can ensure the interpretability of the model and maximize the accuracy of question answering. At the same time, it can also avoid the problems of over fitting, gradient explosion, and waste of computing power caused by deep neural network stacking. Therefore, the template matching question answering method is more suitable for the actual application scenario of bridge management.

Figure 2.
Model architecture of C-KBQA for bridge management. The multi-task learning module (left part) consists of four key components: Coding layer, part-of-speech (POS) tagging, topic entity extraction (TEE), and question classification (QC). POS is used for obtaining domain POS features. The encoder layer is composed of question-type embeddings, BERT embeddings, POS embeddings, and entity embeddings, and forms cross-task semantic constraints. Shared BiLSTM is used for extracting features; CRF and maximum pooling are used for decoding TEE and QC tasks. The query generation module (right part) matches the template based on the QC result, replaces the concepts in the template based on the TEE result, and aligns with the POS.
3.1. Encoder
The model classifies the complex questions of bridge management as input, and obtains BERT embeddings, POS embeddings, entity embeddings, and question-type embeddings from character-level, POS-level, word-level, and sentence-level, respectively.
BERT contains three embeddings: Token embeddings, segment embeddings, and position embeddings. The three embeddings are added element-wise to obtain the synthesized embedding. The BERT model encodes embedded features through a transformer component with a multi-head attention mechanism. The encoded character-level distributed representation is expressed as follows:
where represents the text embedding of the characters in the question, represents the character-level feature embedding encoded by the BERT model, and represents the BERT model encoding component.
POS is the basic grammatical attribute of vocabulary, which contains rich semantic information. The domain POS embedding lookup table is trained by one-hot encoding, and the POS embedding is expressed as follows:
where represent the POS set, and represents the encoding of the POS in the lookup table.
The entity embedding matrix uses the domain specialized vocabulary as the database, and uses Glove for entity embedding. The topic entity embedding will be used as the embedding constraint for the QC task, which is expressed as follows:
Similarly, the question-type embedding is also obtained by one-hot encoding that will be used as the embedding constraint of the TEE task, which is expressed as follows:
3.2. Multi-Task Learning
The MTL module includes three key subtasks: POS tagging, TEE, and QC. Character-grained embedding of subtasks and feature extraction are achieved by sharing the BERT encoder and BiLSTM feature extractor.
Part-of-speech tagging: POS tagging includes word segmentation and POS judgment. POS tagging can effectively distinguish entity boundaries. The combination of different POS in questions will also affect the judgment of QC. Formally, the question can be divided into multiple word combinations {} and then given the POS list {} in the word combination. POS tagging is used for generating POS embeddings and providing POS combination constraints during the query generation stage. As shown in Table 1, we build a professional vocabulary library for bridge management and define the vocabulary attributes of domain vocabulary to improve the performance of Jieba. Figure 3 shows the two POS tagging results of bridge management questions by Jieba tool. The former lacks the domain POS, resulting in incorrect word segmentation. Clearly, the latter POS tagging results contain more domain semantic information.

Table 1.
The examples of entity and POS labels. There are six types of entity and POS labels. Although the label symbols are different, the corresponding entity instances are the same.
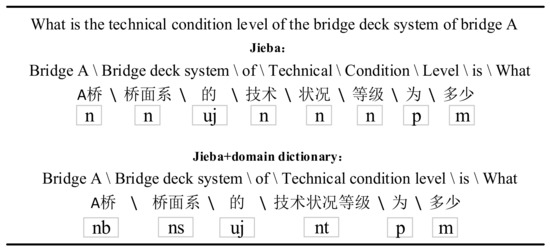
Figure 3.
Comparative example of POS tagging in bridge management questions. The former is the POS tagging result of Jieba tool, and the latter is the POS tagging result after adding the domain dictionary.
Topic entity extraction: The primary purpose of TEE is to extract key substrings from question string , where . Then, determine the entity type of , where belongs to the list of entity labels {BRI, BST, BSE, BSL, BSD, BTC}. An example of TEE is shown in Figure 4. The meaning and examples of entity labels are shown in Table 1.

Figure 4.
Example of topic entity extraction. The topic entities of the question are “A桥” (“Bridge A”, “桥面系” (“Deck System”), and “技术状况等级” (“Technical conditions level”). The corresponding entity labels are “BRI”, “BST”, and “BTC”, respectively.
The features of question-type embeddings, BERT embeddings, and POS embeddings are fused to obtain the final encoding for TEE task. The embedding vector is expressed as follows:
Taking as the input of BiLSTM to capture long-range dependencies and extract features, the BiLSTM model consists of forget gate , input gate , temporary cell state , cell state , output gate , and bidirectional hidden state . The status at each time step is expressed as follows:
where , , , , , , , and are the weight parameters that need to be learned during the training process, and is the question embedding word vector at the current moment. The forward hidden vectors and backward hidden vectors are spliced to obtain the final hidden layer state as follows:
The CRF layer classifies the emission score of BiLSTM as input and outputs the maximum possible predicted annotation sequence that meets the annotation transfer constraints. The model loss function is defined as follows:
where and represent the emission score and transition score of in the labeling sequence , respectively. The maximum log-likelihood function during model training is expressed as follows:
Question classification: QC aims to determine the type of the question and establish the mapping relation . For example, the coarse-grained type of the question in Figure 4 is “技术状况” (“technical condition”) and the fine-grained type is “结构技术状况” (“structural technical condition”). The features of BERT embeddings, POS embeddings, and entity embeddings are fused to obtain the final encoding for the QC task. The embedding vector is expressed as follows:
Taking as the input of the text recurrent convolutional neural network (TextRCNN), the recurrent neural network (RNN) adopts BiLSTM to guarantee model similarity for MTL. BiLSTM is used for capturing the semantic features of the word itself and the left and right context in the question. The left and right context vectors are calculated as follows:
where , , , and are the weight parameters that need to be learned, and are the left context embeddings of the current word and the previous word, respectively, and are the right context embeddings of the current word and the previous word, respectively, and is the sigmoid activation function. The vector representation of the current word after feature fusion is expressed as follows:
Perform linear transformation and activation on to obtain a latent semantic vector . After maximum pooling, the maximum value of the vector elements in is obtained. The formula is expressed as follows:
where and are hyperparameters that need to be learned during training, and the model output and probability are expressed as follows:
Objective function: The main training tasks of the MTL module are TEE and QC. Two key subtasks are jointly trained. The objective functions are expressed as follows:
where and are the loss function for TEE and QC, and are the hyperparameters that need to be learned to control the importance of each subtask.
3.3. Cross-Task Constraints
The proposed model adopts different CTC in the MTL and query generation stages to improve the model performance. Semantic constraints are used in the MTL stage to enrich the embedded features of subtasks. Conditional constraints are used in the query generation stage to further prune query paths. The key to query generation is template matching and concept replacement. The question template is matched by QC, and the concepts in the template are replaced by TEE, thereby transforming the question into a structured query. Formally, there is a mapping relationship between question types and query templates . Templates are structured representations at the conceptual level, replacing conceptual descriptions in with instances of topic entities to obtain the Cypher query . Semantic constraints are embodied in the encoding layer of the model, while conditional constraints include three steps and two limitations.
Step 1: Narrow down templates based on coarse-grained question types and determine query templates based on fine-grained question types.
Limitation 1: , where indicates the matched correct template and indicates the locked template range.
Step 2: Add potential constraints to query templates and prune query paths based on POS and entity-type combinations. Correct the TEE result according to POS information.
Limitation 2: Ensure the POS combination is consistent with the entity-type combination (entity and POS tags are detailed in Table 1).
Step 3: The Cypher query is generated by replacing the concept description in the query template with an instance of the topic entity.
4. Experiments
Utilizing the constructed knowledge base and C-KBQA corpus for bridge management as domain data sources, we evaluate the performance of the proposed model and conduct experimental comparisons.
4.1. Neo4j Knowledge Base
Combined with the practical application scenarios of bridge management and the characteristics of domain data, the Neo4j graph database is used for storing bridge management knowledge. Data are obtained from an unstructured text, semi-structured tables, and relational data. Based on the previous research work [8], the extracted triple knowledge is stored in the Neo4j graph database. As shown in Figure 5, the bridge maintenance knowledge base is composed of various types of bridge entities and relation edges, and the entity nodes contain basic attributes. The constructed bridge maintenance knowledge base contains 9352 entities, 19,556 relationships, and 5674 attribute values.

Figure 5.
The example of Neo4j knowledge base for bridge management. Neo4j is an attribute graph. The entity node contains some basic attributes. For example, the value of the attribute “中心桩号” (“Center Station”) of the bridge entity “K桥” (“Bridge K”) is “K253+465”. Different entities are connected by relational edges to form a graph structure. For example, there is a “结构” (“Structure”) relationship between “K桥” (“Bridge K”) and “桥墩” (“Bridge Pier”).
4.2. Experimental Dataset
Aiming at the multi-task strategy of domain C-KBQA, the QA, TEE, and QC datasets are constructed, respectively. The annotated corpus consists of 26,798 questions with information about 126 bridges, which contain 513,631 characters. The corpus is divided into training, validation, and test sets according to 8:1:1. For the TEE task, Table 2 shows the distribution of entities in its training, validation, and test sets. Figure 6 shows the number of characters for various entities.
Table 2.
The number of entities in the training, validation, and test sets.
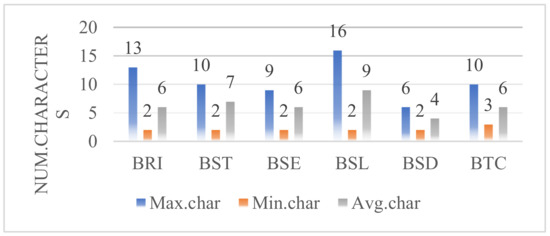
Figure 6.
The number of characters for various entities. Max.char, Min.char, and Avg.char, respectively represent the maximum, minimum, and average characters of different types of entities.
The bridge management questions are divided into coarse-grained and fine-grained. There are three types of coarse-grained questions and ten types of fine-grained questions. Table 3 shows the number of various bridge management questions.
Table 3.
Number of different types of bridge management questions.
The 2680 questions in the test set were selected to construct QA pairs to verify the C-KBQA effect of bridge management. Complex questions are often characterized by multiple-hops, numerical calculations, aggregation, etc. Combining the question characteristics in the bridge management domain, Table 4 lists some examples of complexity in bridge management QA pairs. In the table, the multi-hop questions indicate that the questions involve multiple knowledge triples. Numerical calculation questions are mainly in regrad to the types of defects and the number of components. The questions of judgment, constraint, and aggregation operation have certain inference properties, which are difficult questions in bridge management C-KBQA.
Table 4.
The examples of complexity in bridge management QA pairs. Bridge management questions mainly include the following five complex types: Multi-hops, numerical calculation, judgment, constraint, and aggregation operation. Examples of QA pairs for each complex type are provided in the table, where Q stands for “question” and A stands for “answer”.
4.3. Baselines and Configurations
The precision, recall, and F1 score are used for evaluating the performance of TEE tasks. Accuracy and F1 score are used as evaluation metrics for QC tasks. The calculation formulas of these evaluation metrics are expressed as follows:
where is true positive, is true negative, is false positive, and is false negative. represents the ratio of the number of correctly classified samples to the total number of samples. represents the ratio of the number of correctly retrieved samples to the total number of retrieved samples. represents the ratio of the number of samples that were correctly retrieved to the number of samples that should have been retrieved. is the weighted harmonic mean of and . The baseline models for the TEE task include CNN-CRF, BiLSTM-CRF, and BERT-CRF. The baseline models for the QC task include TextRNN_Att, TextRCNN, ERNIE, BERT, BERT_CNN, and BERT_RNN.
All experiments were conducted on a server with Intel Xeon Gold 6338 CPU, NVIDIA A40 GPU, 32 GB DDR3 RAM, and 512 GB disk space. For the MTL of C-KBQA, the parameter settings on the two key subtasks of TEE and QC are shown in Table 5. The parameter settings of the pretrained model mainly use the native embedding dimension and hyperparameters of Bert_base_Chinese.
Table 5.
Parameter settings for TEE and QC.
4.4. Experimental Results
The performance comparison of TEE task is shown in Table 6, BiLSTM outperforms CNN, and its F1 score is improved by 1.01%. The BERT pretraining model is effective, and its F1 score is 2.04% higher than BiLSTM. Based on BERT, our proposed model improves the domain adaptability and achieves the expected effect. Its F1 score is 94.76%, which is better than the above baselines.
Table 6.
The comparative experimental results of TEE task. The bold numbers represent the best experimental results.
The model performance comparison for the QC task is shown in Table 7. For the text classification series model, TextRCNN performed best with an F1 score of 96.79%. The F1 score of the BERT model is 1.87% higher than the TextRCNN model. The BERT series model is significantly better than the text classification model. Our proposed model introduces MTL and CTC on BERT, and the F1 score is 98.84%, which has well model performance.
Table 7.
The comparative experimental results of QC task. The bold numbers represent the best experimental results.
For the bridge management C-KBQA task, this paper conducts question answering experiments on 2680 complex questions in the test set. The trained multi-task model is used for QC and TEE, and structured queries are generated according to template matching principles and concept replacement rules. A total of 10 overall experiments were conducted on 2680 questions, and the average test scores and standard deviations of the 10 results were used as comprehensive evaluation indicators. The experimental results shown in Table 8 demonstrate that the model effect of basic information question and technical condition question is remarkable, and the comprehensive F1 score of bridge management C-KBQA also reaches more than 90%, which initially meets the needs of specific scenarios. However, the accuracy of damage defects needs to be improved, and it will be the work of continuous optimization and improvement in this paper. This is due to the fact that the damage defect question involves multi-hop retrieval calculation, and the question scenario is more complicated.
Table 8.
The experimental results of bridge management C-KBQA. The symbol “±” indicates that the results of each experiment fluctuate within the positive and negative range.
In addition, we compare the proposed model framework with the latest general framework, as shown in Table 9. Comparison models are some general domain models based on information retrieval ideas. They are mainly encoded by pretraining models, and then some deep neural networks can be accessed for feature extraction. Finally, answers are matched by semantic similarity calculation. However, the comparison model does not improve the model according to the characteristics of the domain, nor does it introduce the domain rules, which is quite different from the template matching method. The experimental results show that the indexes of the proposed model are clearly better than the comparison models, which proves the superior performance of the proposed model based on template matching in the C-KBQA task of bridge management. It is further proved that the existing deep learning techniques cannot be directly applied to the C-KBQA scene with the knowledge inference property in a specific domain.
Table 9.
Comparison of C-KBQA models for bridge management. “Similarity” indicates semantic similarity calculation.
4.5. Ablation Study
Furthermore, we evaluate the MTL model performance and cross-task constraint effect of bridge management C-KBQA. As shown in Table 10, the single-task experiments are equivalent to the use of the BERT-BiLSTM-CRF and BERT-RCNN models independently for TEE and QC, respectively. Subsequently, the semantic embedding constraints of each subtask are sequentially added to other tasks, and the BERT and model parameters are shared, thereby proving the effectiveness of each key component in the model. The experimental results show that the performance of the MTL model is significantly better than the single-task model.
Table 10.
Ablation results of the proposed model. The bold numbers represent the best experimental results.
5. System Prototype
To evaluate the effect of the proposed C-KBQA method in bridge management scenarios, we developed a bridge management C-KBQA prototype system. As shown in Figure 7, when logging in to the system interface, bridge management users can query bridge management-related information in natural language, and the system will directly return the processed answer. The question answer module includes the retrieval function of fact triple knowledge, the enumeration function of various bridge defects, the inference function of bridge common defects, and the calculation function of bridge defect types. In this way, information retrieval, structural state evolution trend, technical condition assessment, and damage safety warning among multiple bridges with similar structure types and similar operating environments are realized, and the bridge management unit can make corresponding decisions.
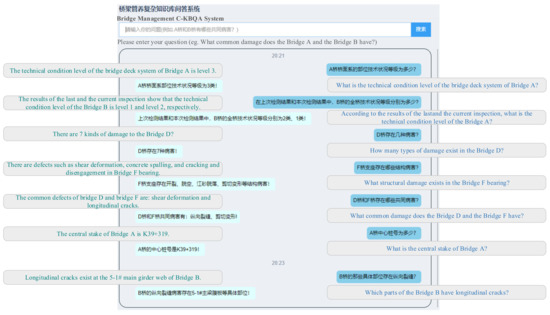
Figure 7.
C-KBQA prototype system for bridge management. The system takes the proposed model as the back-end technical support. The right part consists of the natural language questions in the field of bridge management input by domain users, and the left part consists of the answers returned by the system after analysis and processing. In addition, the answer is in a natural language and contains the context, which makes the human-computer interaction more friendly.
6. Conclusions
The informatization in the field of bridge engineering has developed rapidly. Large amounts of data have been accumulated in the process of bridge management, which has laid the foundation for the digital development in bridge management. This paper proposes an MTL framework based on CTC, with POS tagging, TEE, and QC as auxiliary tasks, to improve the performance of bridge management C-KBQA task by sharing BERT and jointly setting model parameters. The proposed model combines BERT embeddings, POS embeddings, entity embeddings, and question-type embeddings to enhance the contextual representation of short-text questions and achieve cross-task semantic constraints. Moreover, the proposed model is experimentally evaluated on the bridge management dataset and compared with the baseline. The results demonstrate that the model outperforms the baseline model on both TEE and QC tasks. Furthermore, the proposed MTL framework achieves good performance in solving the main task of bridge management C-KBQA. The research provides knowledge-based services and intelligent decisions for bridge management users, which has important significance and far-reaching influence on accelerating the information construction of bridge engineering, and provides a new application scenario for the interdisciplinary research of computer science and bridge engineering.
However, the proposed model has certain limitations. Some future work should be carried out as follows:
- (1)
- The template still needs to be designed manually and is closely related to the storage form of the knowledge base; therefore, it cannot be flexibly improved. As a result, the automatic generation of query templates will be the focus of future research. The following work will carry out syntactic dependency analysis and part of speech analysis on natural language questions to obtain the core sentence pattern of the questions. The QA pairs are used as training data, and feature extraction is carried out through the deep neural network to automatically construct question templates.
- (2)
- The bridge management knowledge base contains large numbers of entities and relationships; therefore, the follow-up work can build a domain knowledge graph embedding model to integrate prior knowledge into the model in advance. In order to retain the structural and semantic features between entities and relations at the same time, the graph neural network and attention mechanism will be combined to generate the knowledge graph embedding to capture the deep interaction information between entities and relationships.
- (3)
- With the advancement in deep learning, end-to-end C-KBQA models have been extensively studied in the general domain; therefore, researching C-KBQA end-to-end models for bridge management is another important and challenging task. The future work will be based on the semantic support of knowledge graph embedding, and automatically construct structured queries through the automatic generation of templates, in an attempt to obtain an automatic question answering solution for complex knowledge bases with enhanced domain knowledge semantics.
Author Contributions
Conceptualization, J.Y. and R.L.; methodology, X.Y. and R.L.; software, X.Y. and H.L.; validation, X.Y. and H.L.; formal analysis, X.Y.; investigation, H.Z. and Y.Z.; resources, J.Y. and R.L.; data curation, X.Y., H.Z. and Y.Z.; writing—original draft preparation, X.Y.; writing—review and editing, R.L., H.Z. and Y.Z.; visualization, X.Y.; supervision, R.L.; project administration, J.Y.; funding acquisition, J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant 62103068, the Natural Science Foundation of Chongqing, China under Grant cstc2020jcyj-msxmX0047, and the Science and Technology Research Program of Chongqing Municipal Education Commission of China under Grant KJQN202200720.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
The authors would like to thank all anonymous reviewers for their comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Soares, M.A.C.; Parreiras, F.S. A literature review on question answering techniques, paradigms and systems. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 635–646. [Google Scholar]
- Razzaghnoori, M.; Sajedi, H.; Jazani, I.K. Question classification in Persian using word vectors and frequencies. Cogn. Syst. Res. 2018, 47, 16–27. [Google Scholar] [CrossRef]
- Lu, R.; Jin, X.; Zhang, S.; Qiu, M.; Wu, X. A study on big knowledge and its engineering issues. IEEE Trans. Knowl. Data Eng. 2018, 31, 1630–1644. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Pregnolato, M. Bridge safety is not for granted-A novel approach to bridge management. Eng. Struct. 2019, 196, 109193. [Google Scholar] [CrossRef]
- Gui, C.; Zhang, J.; Lei, J.; Hou, Y.; Zhang, Y.; Qian, Z. A comprehensive evaluation algorithm for project-level bridge maintenance decision-making. J. Clean. Prod. 2021, 289, 125713. [Google Scholar] [CrossRef]
- Wu, C.; Wu, P.; Wang, J.; Jiang, R.; Chen, M.; Wang, X. Critical review of data-driven decision-making in bridge operation and maintenance. Struct. Infrastruct. Eng. 2021, 18, 47–70. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Li, R.; Luo, M.; Jiang, S.; Wang, G.; Yang, Y. Knowledge graph construction and knowledge question answering method for bridge inspection domain. J. Comput. Appl. 2022, 42, 28–36. [Google Scholar]
- Pan, Z.; Su, C.; Deng, Y.; Cheng, J. Video2Entities: A computer vision-based entity extraction framework for updating the architecture, engineering and construction industry knowledge graphs. Autom. Constr. 2021, 125, 103617. [Google Scholar] [CrossRef]
- Sarazin, A.; Bascans, J.; Sciau, J.B.; Song, J.; Supiot, B.; Montarnal, A.; Lorca, X.; Truptil, S. Expert system dedicated to condition-based maintenance based on a knowledge graph approach: Application to an aeronautic system. Expert Syst. Appl. 2021, 186, 115767. [Google Scholar] [CrossRef]
- Wan, C.; Zhou, Z.; Li, S.; Ding, Y.; Xu, Z.; Yang, Z.; Xia, Y.; Yin, F. Development of a bridge management system based on the building information modeling technology. Sustainability 2019, 11, 4583. [Google Scholar] [CrossRef]
- Diefenbach, D.; Lopez, V.; Singh, K.; Maret, P. Core techniques of question answering systems over knowledge bases: A survey. Knowl. Inf. Syst. 2018, 55, 529–569. [Google Scholar] [CrossRef]
- Hu, S.; Zou, L.; Zhang, X. A state-transition framework to answer complex questions over knowledge base. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2098–2108. [Google Scholar]
- Hua, Y.; Li, Y.F.; Qi, G.; Wu, W.; Zhang, J.; Qi, D. Less is more: Data-efficient complex question answering over knowledge bases. J. Web Semant. 2020, 65, 100612. [Google Scholar] [CrossRef]
- Cai, Q.; Yates, A. Large-scale semantic parsing via schema matching and lexicon extension. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 423–433. [Google Scholar]
- Sun, Y.; Li, P.; Cheng, G.; Qu, Y. Skeleton parsing for complex question answering over knowledge bases. J. Web Semant. 2022, 72, 100698. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, L.; Hui, B.; Tian, L. Improving complex knowledge base question answering via structural information learning. Knowl. -Based Syst. 2022, 242, 108252. [Google Scholar] [CrossRef]
- Guo, D.; Tang, D.; Duan, N.; Zhou, M.; Yin, J. Dialog-to-action: Conversational question answering over a large-scale knowledge base. In Proceedings of the 2018 Neural Information Processing Systems Conference, Montreal, Canada, 3–8 December 2018; pp. 2942–2951. [Google Scholar]
- Wu, W.; Zhu, Z.; Zhang, G.; Kang, S.; Liu, P. A reasoning enhance network for muti-relation question answering. Appl. Intell. 2021, 51, 4515–4524. [Google Scholar] [CrossRef]
- Höffner, K.; Walter, S.; Marx, E.; Usbeck, R.; Lehmann, J.; Ngonga, N.; Axel, C. Survey on challenges of question answering in the semantic web. Semant. Web 2017, 8, 895–920. [Google Scholar] [CrossRef]
- Yang, M.C.; Lee, D.G.; Park, S.Y.; Rim, H.C. Knowledge-based question answering using the semantic embedding space. Expert Syst. Appl. 2015, 42, 9086–9104. [Google Scholar] [CrossRef]
- Zhou, M.; Huang, M.; Zhu, X. An interpretable reasoning network for multi-relation question answering. arXiv 2018, arXiv:1801.04726. [Google Scholar]
- Jin, H.; Luo, Y.; Gao, C.; Tang, X.; Yuan, P. ComQA: Question answering over knowledge base via semantic matching. IEEE Access 2019, 7, 75235–75246. [Google Scholar] [CrossRef]
- Esteva, A.; Kale, A.; Paulus, R.; Hashimoto, K.; Yin, W.; Radev, D.; Socher, R. COVID-19 information retrieval with deep-learning based semantic search, question answering, and abstractive summarization. NPJ Digit. Med. 2021, 4, 68. [Google Scholar] [CrossRef] [PubMed]
- Unger, C.; Bühmann, L.; Lehmann, J.; Ngonga Ngomo, A.C.; Gerber, D.; Cimiano, P. Template-based question answering over RDF data. In Proceedings of the 21st international conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 639–648. [Google Scholar]
- Gomes, J.J.; de Mello, R.C.; Ströele, V.; de Souza, J.F. A hereditary attentive template-based approach for complex Knowledge Base Question Answering systems. Expert Syst. Appl. 2022, 205, 117725. [Google Scholar] [CrossRef]
- Ojokoh, B.; Adebisi, E. A review of question answering systems. J. Web Eng. 2018, 17, 717–758. [Google Scholar] [CrossRef]
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J. A survey on complex knowledge base question answering: Methods, challenges and solutions. arXiv 2021, arXiv:2105.11644. [Google Scholar]
- Pereira, A.; Trifan, A.; Lopes, R.P.; Oliveira, J.L. Systematic review of question answering over knowledge bases. IET Softw. 2022, 16, 1–13. [Google Scholar] [CrossRef]
- Chen, Y.; Li, H. DAM: Transformer-based relation detection for Question Answering over Knowledge Base. Knowl. Based Syst. 2020, 201, 106077. [Google Scholar] [CrossRef]
- Wu, H.; Cheng, S.; Wang, Z.; Zhang, S.; Yuan, F. Multi-task learning based on question-answering style reviews for aspect category classification and aspect term extraction on GPU clusters. Clust. Comput. 2020, 23, 1973–1986. [Google Scholar] [CrossRef]
- Wu, C.; Luo, G.; Guo, C.; Ren, Y.; Zheng, A.; Yang, C. An attention-based multi-task model for named entity recognition and intent analysis of Chinese online medical questions. J. Biomed. Inform. 2020, 108, 103511. [Google Scholar] [CrossRef]
- Yang, M.; Tu, W.; Qu, Q.; Zhou, W.; Liu, Q.; Zhu, J. Advanced community question answering by leveraging external knowledge and multi-task learning. Knowl. Based Syst. 2019, 171, 106–119. [Google Scholar] [CrossRef]
- Cheng, L.; Xie, F.; Ren, J. KB-QA based on multi-task learning and negative sample generation. Inf. Sci. 2021, 574, 349–362. [Google Scholar] [CrossRef]
- Hamon, T.; Grabar, N.; Mougin, F. Querying biomedical linked data with natural language questions. Semant. Web 2017, 8, 581–599. [Google Scholar] [CrossRef]
- Demner-Fushman, D.; Mrabet, Y.; Ben Abacha, A. Consumer health information and question answering: Helping consumers find answers to their health-related information needs. J. Am. Med. Inform. Assoc. 2020, 27, 194–201. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, J. Application of Knowledge Map Based on BiLSTM-CRF Algorithm Model in Ideological and Political Education Question Answering System. Mob. Inf. Syst. 2022, 2022, 4139323. [Google Scholar] [CrossRef]
- Wu, C.; Li, X.; Guo, Y.; Wang, J.; Ren, Z.; Wang, M.; Yang, Z. Natural language processing for smart construction: Current status and future directions. Autom. Constr. 2022, 134, 104059. [Google Scholar] [CrossRef]
- Zhong, B.; He, W.; Huang, Z.; Love, P.E.D.; Tang, J.; Luo, H. A building regulation question answering system: A deep learning methodology. Adv. Eng. Inform. 2020, 46, 101195. [Google Scholar] [CrossRef]
- Li, T.; Alipour, M.; Harris, D.K. Mapping textual descriptions to condition ratings to assist bridge inspection and condition assessment using hierarchical attention. Autom. Constr. 2021, 129, 103801. [Google Scholar] [CrossRef]
- Xia, Y.; Lei, X.; Wang, P.; Sun, L. A data-driven approach for regional bridge condition assessment using inspection reports. Struct. Control. Health Monit. 2022, 29, e2915. [Google Scholar] [CrossRef]
- Li, R.; Mo, T.; Yang, J.; Jiang, S.; Li, T.; Liu, Y. Ontologies-based domain knowledge modeling and heterogeneous sensor data integration for bridge health monitoring systems. IEEE Trans. Ind. Inform. 2020, 17, 321–332. [Google Scholar] [CrossRef]
- Li, R.; Mo, T.; Yang, J.; Li, D.; Jiang, S.; Wang, D. Bridge inspection named entity recognition via BERT and lexicon augmented machine reading comprehension neural model. Adv. Eng. Inform. 2021, 50, 101416. [Google Scholar] [CrossRef]
- Li, R.; Li, D.; Yang, J.; Xiang, F.; Ren, H.; Jiang, S.; Zhang, L. Joint extraction of entities and relations via an entity correlated attention neural model. Inf. Sci. 2021, 581, 179–193. [Google Scholar] [CrossRef]
- Yang, J.; Xiang, F.; Li, R.; Zhang, L.; Yang, X.; Jiang, S.; Zhang, H.; Wang, D.; Liu, X. Intelligent bridge management via big data knowledge engineering. Autom. Constr. 2022, 135, 104118. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).