Abstract
In this work, we present a rigorous application of the Expectation Maximization algorithm to determine the marginal distributions and the dependence structure in a Gaussian copula model with missing data. We further show how to circumvent a priori assumptions on the marginals with semiparametric modeling. Further, we outline how expert knowledge on the marginals and the dependency structure can be included. A simulation study shows that the distribution learned through this algorithm is closer to the true distribution than that obtained with existing methods and that the incorporation of domain knowledge provides benefits.
1. Introduction
Even though the amount of data is increasing due to new technologies, big data are by no means good data. For example, missing values are ubiquitous in various fields, from the social sciences [1] to manufacturing [2]. For explanatory analysis or decision making, one is often interested in the joint distribution of a multivariate dataset, and its estimation is a central topic in statistics [3]. At the same time, there exists background knowledge in many domains that can help to compensate for the potential shortcomings of datasets. For instance, domain experts have an understanding of the causal relationships in the data generation process [4]. It is the scope of this paper to unify expert knowledge and datasets with missing data to derive approximations of the underlying joint distribution.
To estimate the multivariate distribution, we use copulas, where the dependence structure is assumed to belong to a parametric family, while the marginals are estimated nonparametrically. Genest et al. [5] showed that for complete datasets, a two-step approach consisting of the estimation of the marginals with an empirical cumulative distribution function (ecdf) and subsequent derivation of the dependence structure is consistent. This idea is even transferable to high dimensions [6].
In the case of missing values, the situation becomes more complex. Here, nonparametric methods do not scale well with the number of dimensions [7]. On the other hand, assuming that the distribution belongs to a parametric family, it can often be derived by using the EM algorithm [8]. However, this assumption is, in general, restrictive. Due to the encouraging results for complete datasets, there have been several works that have investigated the estimation of the joint distribution under a copula model. The authors of [9,10] even discussed the estimation in a missing-not-at-random (MNAR) setting. While MNAR is less restrictive than missing at random (MAR), it demands the explicit modeling of the missing mechanism [11]. On the contrary, the authors of [12,13] provided results in cases in which data were missing completely at random (MCAR). This strong assumption is rarely fulfilled in practice. Therefore, we assume an MAR mechanism in what follows [11].
Another interesting contribution [14] assumed external covariates, such that the probability of a missing value depended exclusively on them and not on the variables under investigation. They applied inverse probability weighting (IPW) and the two-step approach of [5]. While they proved a consistent result, it is unclear how this approach can be adapted to a setting without those covariates. IPW for general missing patterns is computationally demanding, and no software exists [15,16]. Thus, IPW is mostly applied with monotone missing patterns that appear, for example, in longitudinal studies [17]. The popular work of [18] proposed an EM algorithm in order to derive the joint distribution in a Gaussian copula model with data MAR [11]. However, their approach had weaknesses:
- If there was no a priori knowledge of the parametric family of all marginals, Ref. [18] proposed using the ecdf of the observed data points. Afterwards, they exclusively derived the parameters of the copula. This estimator of the marginals was biased [19,20], which is often overlooked in the copula literature, e.g., [21] (Section 4.3), [22] (Section 3), [23] (Section 3), or [24] (Section 3).
- The description of the simulation study was incomplete and the results were not reproducible.
The aim of this paper is to close these gaps, and our contributions are the following:
- We give a rigorous derivation of the EM algorithm under a Gaussian copula model. Similarly to [5], it consists of two separate steps, which estimate the marginals and the copula, respectively. However, these two steps alternate.
- We show how prior knowledge about the marginals and the dependency structure can be utilized in order to achieve better results.
- We propose a flexible parametrization of the marginals when a priori knowledge is absent. This allows us to learn the underlying marginal distributions; see Figure 1.
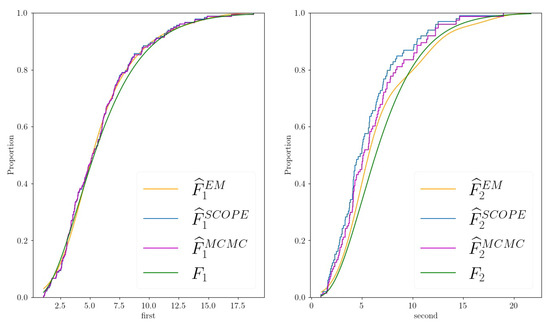 Figure 1. Estimates of the proposed EM algorithm (, orange line), the Standard Copula Estimator (, blue line, corresponds to ecdf), the Markov chain–Monte Carlo approach (, purple line) for the marginals , , and the truth (, green line) of a two-dimensional example dataset generated as described in Section 4.2 with , , and .
Figure 1. Estimates of the proposed EM algorithm (, orange line), the Standard Copula Estimator (, blue line, corresponds to ecdf), the Markov chain–Monte Carlo approach (, purple line) for the marginals , , and the truth (, green line) of a two-dimensional example dataset generated as described in Section 4.2 with , , and . - We provide a Python library that implements the proposed algorithm.
The structure of this paper is as follows. In Section 2, we review some background information about the Gaussian copula. We proceed by presenting the method (Section 3). In Section 4, we investigate its performance and the effect of domain knowledge in simulation studies. We conclude in Section 5. All technical aspects and proofs in this paper are given in Appendix A and Appendix B.
2. The Gaussian Copula Model
2.1. Notation and Assumptions
In the following, we consider a p-dimensional dataset of size N, where are i.i.d. samples from a p-dimensional random vector with a joint distribution function F and marginal distribution functions . We denote the entries of by . The parameters of the marginals are represented by , where is the parameter of , so we write , where can be a vector itself.
For , we define as the index set of the observed and as the index set of the missing columns of . Hence, and . is a random vector for which if is missing and if can be observed. Further, we define to be the density function and to be the distribution function of the one-dimensional standard normal distribution. stands for the distribution function of a p-variate normal distribution with covariance and mean . To simplify the notation, we define . For a matrix , the entry of the i-th row and the j-th column is denoted by , while for index sets , is the submatrix of A with the row number in and column number in . For a (random) vector (), () is the subvector containing entries with the index in .
Throughout, we assume F to be strictly increasing and continuous in every component. Therefore, is strictly increasing and continuous for all , and so is the existing inverse function . For , we define by
This work assumes that data are Missing at Random (MAR), as defined by [11], i.e.,
where are the observed and are the missing entries of .
2.2. Properties
Sklar’s theorem [25] decomposes F into its marginals and its dependency structure C with
Here, C is a copula, which means it is a p-dimensional distribution function with support whose marginal distributions are uniform. In this paper, we focus on Gaussian copulas, where
and is a covariance matrix with . Beyond all multivariate normal distributions, there are distributions with non-normal marginals whose copula is Gaussian. Hence, the Gaussian copula model provides an extension of the normality assumption. Consider a random vector whose copula is . Under the transformation
it holds that
and hence, is normally distributed with mean 0 and covariance . The two-step approaches given in [5,6] use this property and apply the following scheme:
- Find consistent estimates for the marginal distributions .
- Find by estimating the covariance of the random vector
From now on, we assume that the marginals of have existing density functions . Then, by using Equation (4) and a change of variables, we can derive the joint density function
where . As for the multivariate normal distribution, we can identify the conditional independencies ([6]) from the inverse of the covariance matrix by using the property
K is called the precision matrix. In order to slim down the notation, we define
and similarly
The former function transforms the data of a Gaussian copula distribution to be normally distributed. The latter mapping takes multivariate normally distributed data and returns data following a Gaussian copula distribution with marginals . The conditional density functions have a closed form.
Proposition 1
(Conditional Distribution of Gaussian Copula). Let and be such that .
- The conditional density of is given bywhere , , and
- is normally distributed with mean μ and covariance .
- The expectation of with respect to the density can be expressed by
Proposition 1 shows that the conditional distribution’s copula is Gaussian as well. More importantly, we can derive an algorithm for sampling from the conditional distribution.
| Algorithm 1:Sampling from the conditional distribution of a Gaussian copula |
Input: Result: m samples of Calculate Calculate and as in Proposition 1 using and Draw samples from return { |
The very last step follows with Proposition 1, as it holds for any measurable :
3. The EM Algorithm in the Gaussian Copula Model
3.1. The EM Algorithm
Let be a dataset following a distribution with parameter and corresponding density function , where observations are MAR. The EM algorithm [8] finds a local optimum of the log-likelihood function
After choosing a start value , it does so by iterating the following two steps.
- E-Step: Calculate
- M-Step: Setand .
For our purposes, there are two extensions of interest:
- If there is no closed formula for the right-hand side of Equation (7), one can apply Monte Carlo integration [26] as an approximation. This is called the Monte Carlo EM algorithm.
3.2. Applying the ECM Algorithm on the Gaussian Copula Model
As we need a full parametrization of the Gaussian copula model for the EM algorithm, we assume parametric marginal distributions with densities . According to Equation (5), the joint density with respect to the parameters and has the form
where . Section 3.3 will describe how we can keep the flexibility for the marginals despite the parametrization. However, first, we outline the EM algorithm for general parametric marginal distributions.
3.2.1. E-Step
Set and . For simplicity, we pick one summand in Equation (7). By Equation (7) and (9), it holds with and taking the role of :
The first and last summand depend only on and , respectively. Thus, of special interest is the second summand, for which we obtain the following with Proposition 1:
where
Here,
and
At this point, the authors of [18] neglected that, in general,
holds, and hence, (11) depends not only on , but also on . This let us reconsider their approach, as we describe below.
3.2.2. M-Step
The joint optimization with respect to and is difficult, as there is no closed form for Equation (10). We circumvent this problem by sequentially optimizing with respect to and by applying the ECM algorithm. The maximization routine is the following.
- Set .
- Set .
This is a two-step approach consisting of estimating the copula first and the marginals second. However, both steps are executed iteratively, which is typical for the EM algorithm.
Estimating
As we are maximizing Equation (10) with respect to with a fixed , the last summand can be neglected. By a change-of-variables argument, we show the following in Theorem A1:
where depends on and . Thus, considering all observations, we search for
which only depends on the statistic . Generally, this maximization can be formalized as a convex optimization problem that can be solved by a gradient descent. However, the properties of this estimator are not understood (for example, a scaling of S by leads to a different solution; see Appendix A.3). To overcome this issue, we instead approximate the solution with the correlation matrix
where is the diagonal matrix with entries . This was also proposed in [28] (Section 2.2).
In cases in which there is expert knowledge on the dependency structure of the underlying distribution, one can adapt Equation (12) accordingly. We discuss this in more detail in Section 4.4.
Estimating
We now focus on finding , which is the maximizer of
with respect to . As there is, in general, no closed formula for the right-hand side, we use Monte Carlo integration. Again, we start by considering a single observation to simplify terms. Employing Algorithm 1, we receive M samples from the distribution of given the parameters and . We set . Then, by Equation (9),
Hence, considering all observations, we set
Note that we only use the Monte Carlo samples to update the parameters of the marginal distributions . We would also like to point out some interesting aspects about Equations (13) and (14):
- The summand describes how well the marginal distributions fit the (one-dimensional) data.
- The estimations of the marginals are interdependent. Hence, in order to maximize with respect to , we have to take into account all other components of .
- The first summand adjusts for the dependence structure in the data. If all observations at step are assumed to be independent, then , and this term is 0.
- More generally, the derivative depends on if and only if . This means that if implies the conditional independence of column j and k given all other columns (Equation (6)), the optimal can be found without considering . This, e.g., is the case if we set entries of the precision matrix to 0. Thus, the incorporation of prior knowledge reduces the complexity of the identification of the marginal distributions.
The intuition behind the derived EM algorithm is simple. Given a dataset with missing values, we estimate the dependency structure. With the identified dependency structure, we can derive likely locations of the missing values. Again, these locations help us to find a better dependency structure. This leads to the proposed cyclic approach. The framework of the EM algorithm guarantees the convergence of this procedure to a local maximum for in Equation (14).
3.3. Modelling with Semiparametric Marginals
In the case in which the missing mechanism is MAR, the estimation of the marginal distribution using only complete observations is biased. Even worse, any moment of the distribution can be distorted. Thus, one needs a priori knowledge in order to identify the parametric family of the marginals [19,20]. If their family is known, one can directly apply the algorithm of Section 3.2. If this is not the case, we propose the use of a mixture model parametrization of the form
where is a hyperparameter and the ordering of the ensures the identifiability.
Using mixture models for density estimation is a well-known idea (e.g., [29,30,31]). As the authors of [31] noted, mixture models vary between being parametric and being non-parametric, where flexibility increases with g. It is reasonable to choose Gaussian mixture models, as their density functions are dense in the set of all density functions with respect to the -norm [29] (Section 3.2). This flexibility and the provided parametrization make the mixture models a natural choice.
3.4. A Blueprint of the Algorithm
The complete algorithm is summarized in Algorithm 2. For the Monte Carlo EM algorithm, Ref. [26] proposed the stabilization of the parameters with a rather small number of samples M and to increase this number substantially in the latter steps of the algorithm. This seems to be reasonable for line 2 of Algorithm 2 as well.
If there is no a priori knowledge about the marginals, we propose that we follow Section 3.3. We choose the initial such that the cumulative distribution function of the mixture model fits the ecdf of the observed data points. For an empirical analysis of the role of g, see Section 4.3.3. For , we use a rule of thumb inspired by [3] and set
where is the standard deviation of the observed data points in the j-th component.
| Algorithm 2:Blueprint for the EM algorithm for the Gaussian copula model |
 |
4. Simulation Study
We analyze the performance of the proposed estimator in two studies. First, we consider scenarios for two-dimensional datasets and check the potential of the algorithm. In the second part, we explore how expert knowledge can be incorporated and how this affects the behavior and performance. The proposed procedure, which is indexed with EM in the figures below, is compared with:
- Standard COPula Estimator (SCOPE): The marginal distributions are estimated by the ecdf of the observed data points. This was proposed by [18] if the parametric family is unknown, and it is the state-of-the art approach. Thus, we apply an EM algorithm to determine the correlation structure on the mapped data pointswhere is the ecdf of the observed data points in column j. Its corresponding results are indexed with SCOPE in the figures and tables.
- Known marginals: The distribution of the marginals is completely known. The idea is to eliminate the difficulty of finding them. Here, we apply the EM algorithm for the correlation structure onwhere is the real marginal distribution function. Its corresponding results are indexed with a 0 in the figures and tables.
- Markov chain–Monte Carlo (MCMC) approach [21]: The author proposed an MCMC scheme to estimate the copula in a Bayesian fashion. Therefore, Ref. [21] derived the distribution of the multivariate ranks. The marginals are treated as nuisance parameters. We employed the R package sbgcop, which is available on CRAN, as it provides not only a posterior distribution of the correlation matrix , but also imputations for missing values. In order to compare the approach with the likelihood-based methods, we setwhere are samples of the posterior distribution of the correlation matrix. For the marginals, we definedwhere is the m-th of the total of M imputations for and if can be observed. The samples were drawn from the posterior distribution. The corresponding results were indexed with the MCMC approach in the figures and tables.
Sklar’s theorem shows that the joint distribution can be decomposed into the marginals and the copula. Thus, we analyze them separately.
4.1. Adapting the EM Algorithm
In Section 4.3 and Section 4.4, we chose , for which we saw a sufficient flexibility. A sensitivity analysis of the procedure with respect to g can be found in Section 4.3.3. The initial was chosen by fitting the marginals to the existing observations, and was the identity matrix. For the number of Monte Carlo samples M, we observed that with , stabilized after around 10 steps. Cautiously, we ran 20 steps before we increased M to 1000, for which we run another five steps. We stopped the algorithm when the condition was fulfilled.
4.2. Data Generation
We considered a two-dimensional dataset (we would have liked to include the setup of the simulation study of [18]; however, neither could the missing mechanism be extracted from the paper nor did the authors provide it on request) with a priori unknown marginals and , whose copula was Gaussian with the correlation parameter . The marginals were chosen to be with six and seven degrees of freedom. The data matrix kept N (complete) observations of the random vector. We enforced the following MAR mechanism:
- Remove every entry in D with probability . We denote the resulting data matrix (with missing entries) as .
- If and are observed, remove with probabilityWe call the resulting data matrix .
The missing patterns were non-monotone. Aside from , the parameters and controlled how many entries were absent in the final dataset. Assuming that , , and was not too large, the ecdf of the observed values of was shifted to the left compared to the true distribution function (changing the signs of and/or may change the direction of the shift, but the situation is analogous). This can be seen in Figure 1, where we chose , , . The marginal distribution of could be estimated well by the ecdf of the observed data.
4.3. Results
This subsection explores how different specifications of the data-generating process presented in Section 4.2 influenced the estimation of the joint distribution. First, we investigate the influence of the share of missing values (controlled via ) and the dependency (controlled via ) by fixing the number of observations (denoted by N) to 100. Then, we vary N to study the behavior of the algorithms for larger sample sizes. Afterwards, we carry out a sensitivity analysis of the EM algorithm with respect to g, the number of mixtures. Finally, we study the computational demands of the algorithms.
4.3.1. The Effects of Dependency and Share of Missing Values
We investigate two different choices for the setup in Section 4.2 by setting the parameters to , and , . For both, we draw 1000 datasets with each and apply the estimators. To evaluate the methods, we look at two different aspects.
First, we compare the estimators for with respect to bias and standard deviations. The results are depicted in the corresponding third columns of Table 1 and are summarized as boxplots in Figure A1 in Appendix B.3. We see that no method is clearly superior. While the EM algorithm has a stronger bias for than that of SCOPE, it also has a smaller standard deviation. The MCMC approach shows the largest bias. As even known marginals () do not lead to substantially better estimators compared to SCOPE () or the proposed () approach, we deduce that (at least in this setting) the estimators for the marginals are almost negligible. MCMC performs notably worse.

Table 1.
Comparison of the algorithms with respect to the Cramer–von Mises distance between the estimated and the true first () and true second marginal distributions (), as well as the correlation (). Shown are the mean and standard deviation of the proposed EM algorithm (EM), the method based on known marginals (0), the Standard Copula Estimator (SCOPE), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.3.1.
Second, we investigate the Cramer–von Mises statistics between the estimated and the true marginal distribution ( statistic for the first marginal, statistic for the second marginal). The results are shown in Table 1 (corresponding first two columns) and are summarized as boxplots in Figure A2 in Appendix B.3. While for , the proposed estimator behaves only slightly better than SCOPE, we see that the benefit becomes larger in the case of high correlation and more missing values, especially when estimating the second marginal. This is in line with the intuition that if the correlation is vanishing, the two random variables and become independent. Thus, , the missing value indicator, and become independent. (Note that there is a difference from the case in which , and hence, the missingness probability isconditionally independent from given .) In that case, we can estimate the marginal of using the ecdf of the observed data points. Hence, SCOPE’s estimates of the marginals should be good for small values of . An illustration can be found in Figure 2. Again, the MCMC approach performs the worst.

Figure 2.
Dependency graph for , and . is independent of if either and are independent () or if and are independent ().
4.3.2. Varying the Sample Size N
To investigate the behavior of the methods for larger sample sizes, we repeat the experiment from Section 4.2 with for the sample sizes . The results are depicted in Table 2 and Figure A3, Figure A4 and Figure A5 in Appendix B.3. The bias of SCOPE and EM algorithm for seem to vanish for large N, while the MCMC approach remains biased. Studying the estimation of the true marginals, the approximation of the second marginal via MCMC and SCOPE improves only slowly and is still poor for the largest sample sizes . In contrast, the EM algorithm performs best in small sample sizes, and the mean (of and ) and standard deviations (of all three values) move towards 0 for increasing N.
Table 2.
Comparison of the algorithms with respect to the Cramer–von Mises distance between the estimated and the true first () and true second marginal distributions (), as well as the correlation (). Shown are the mean and standard deviation of the proposed EM algorithm (EM), the method based on known marginals (0), the Standard Copula Estimator (SCOPE), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and varying sample sizes .
4.3.3. The Impacts of Varying the Number of Mixtures g
The proposed EM algorithm relies on the hyperparameter g, the number of mixtures in Equation (15). To analyze the behavior of the EM algorithm with respect to g, we additionally run the EM algorithm with and on the 1000 datasets of Section 4.2 for , , and . We did not adjust the number of steps in the EM algorithm to keep the results comparable. The results can be found in Table 3. We see that the choice of g does not have a large effect on the estimation of . However, an increased g leads to better estimates for . This is in line with the intuition that the ecdf of the first components is an unbiased estimate for the distribution function of , and setting g to the number of samples corresponds to the kernel density estimator. On the other hand, the estimator for benefits slightly from , as has a lower mean and standard deviation compared to the choice . However, this effect is small and almost non-existent when we compare with . As the choice leads to better estimates of the first marginal compared to , we see this choice as a good compromise for our setting. For applications without prior knowledge, we recommend considering g as additional tuning parameter (via cross-validation).
Table 3.
Comparison of the proposed EM algorithm with respect to the Cramer–von Mises distance between the estimated and the true first () and true second marginal distributions (), as well as the correlation (), for different numbers of mixtures g in Equation (15). Shown are the mean and standard deviation for and for 1000 datasets generated as described in Section 4.2 with and .
4.3.4. Run Time
We analyze the computational demands of the different algorithms by comparing their run times in the study of Section 4.3.1 with and (the settings and lead to similar results and are omitted). The run times of all presented algorithms depend not only on the dataset, but also on the parameters (e.g., convergence criterion and for SCOPE). Thus, we do not aim for an extensive study, but focus on the magnitudes. We compare the proposed EM algorithm with a varying number of mixtures () with MCMC and SCOPE. The results are shown in Table 4. We see that the EM algorithm has the longest run time, which depends on the number of mixtures g. The MCMC approach and the proposed EM algorithm have a higher computational demand than SCOPE, as they are trying to model the interaction between the copula and the marginals. As mentioned in the onset, we could reduce the run time of the EM algorithm by going down to only 10 steps instead of 20.
Table 4.
Comparison of the algorithms with respect to the run time in seconds. Shown are the mean and standard deviation of the proposed EM algorithm (EM) with the number of mixtures g set to , the Standard Copula Estimator (SCOPE), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and .
4.4. Inclusion of Expert Knowledge
In the presence of prior knowledge on the dependency structure, the presented EM algorithm is highly flexible. While information on the marginals can be used to parametrize the copula model, expert knowledge on the dependency structure can be incorporated by adapting Equation (12). In the case of soft constraints on the covariance or precision matrix, one can replace Equation (12) with a penalized covariance estimation, where the penalty reflects the expert assessment [32,33]. Similarly, one can define a prior distribution on the covariance matrices and set as the mode of the posterior distribution (the MAP estimate) of given the statistic S of Equation (12).
Another possibility could be that we are aware of conditional independencies in the data-generating process. This is, for example, the case when causal relationships are known [4]. To exemplify the latter, we consider a three-dimensional dataset with the Gaussian copula and marginals , which are distributed with six, seven, and five degrees of freedom. The precision is set to
where is a diagonal matrix, which ensures that the diagonal elements of are 1. We see that and are conditionally independent given . The missing mechanism is similar to the one in Section 4.2. The missingness of depends on and , while the probability of a missing or is independent of the others. The mechanism is, again, MAR. Details can be found in Appendix B.2. We compare the proposed method with prior knowledge on the zeros in the precision matrix (indexed by KP, EM in the figures) with the EM, SCOPE, and MCMC algorithms without background knowledge. We again sample 1000 datasets with 50 observations each from the real distribution. The background knowledge on the precision is used by restricting the non-zero elements in Equation (12). Therefore, we apply the procedure presented in [34] (Chapter 17.3.1) to find . The means and standard deviations of the estimates are presented in Table 5.
Table 5.
Comparison of the algorithms with respect to the Cramer–von Mises distance between the estimated and the true first marginal distribution (), true second marginal distribution (), and true third marginal distribution (), as well as the correlation (). Shown are the mean and standard deviation of the proposed EM algorithm (EM), the proposed EM algorithm with prior knowledge on the conditional independencies (KP, EM), the method based on known marginals (0), the Standard Copula Estimator (SCOPE), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.4.
First, we evaluate the estimated dependency structures by calculating the Frobenius norm of the estimation error . The EM algorithm with background knowledge (KP, EM) performs best and is more stable than its competitors. Apart from MCMC, the other procedures behave similarly, which indicates again that the exact knowledge of the marginal distributions is not too relevant for identifying the dependency structure. MCMC performs the worst.
Second, we see that the proposed EM estimators return marginal distributions that are closer to the truth, while the estimate with background knowledge (KP, EM) performs the best. Thus, the background knowledge on the copula also transfers into better estimates for the marginal distribution—in particular, for . This is due to Equation (14) and the comments thereafter. The zeros in the precision structure indicate which other marginals are relevant in order to identify the parameter of a marginal. In our case, provides no additional information for . This information is provided to the EM algorithm through the restriction of the precision matrix.
Finally, we compare the EM estimates of the joint distribution. The relative entropy or Kullback–Leibler divergence is a popular tool for estimating the difference between two distributions [35,36], where one of them is absolutely continuous with respect to the other. A lower number indicates a higher similarity. Due to the discrete structure of the marginals of SCOPE and MCMC, we cannot calculate their relative entropy with respect to the truth. However, we would like to analyze how the estimate of the proposed procedure improves if we include expert knowledge. The results are depicted in Table 6. Again, we observe that the incorporation of extra knowledge improves the estimates. This is in line with Table 5, as the estimation of all components in the joint distribution of Equation (3) is improved by the domain knowledge.
Table 6.
Comparison of the algorithms with respect to the Kullback–Leibler divergence () between the true joint distribution (F) and the estimates. Shown are the mean and standard deviation of the proposed EM algorithm (EM) and the proposed EM algorithm with prior knowledge on the conditional independencies (KP, EM) for 1000 datasets generated as described in Section 4.4.
5. Discussion
In this paper, we investigated the estimation of the Gaussian copula and the marginals with an incomplete dataset, for which we derived a rigorous EM algorithm. The procedure iteratively searches for the marginal distributions and the copula. It is, hence, similar to known methods for complete datasets. We saw that if the data are missing at random, a consistent estimate of a marginal distribution depends on the copula and other marginals.
The EM algorithm relies on a complete parametrization of the marginals. The parametric family of the marginals is, in general, a priori unknown and cannot be identified through the observed data points. For this case, we presented a novel idea of employing mixture models. Although this is practically always a misspecification, our simulation study revealed that the combination of our EM algorithm and marginal mixture models delivers better estimates for the joint distribution than currently used procedures do. In principle, uncertainty quantification of the parameters derived by the proposed EM algorithm can be achieved by bootstrapping [37].
There are different possibilities for incorporating expert knowledge. Information on the parametric family of the marginals can be used for their parametrization. However, causal and structural understandings of the data-generating process can also be utilized [4,38,39]. For example, this can be achieved by restricting the correlation matrix or its inverse, the precision matrix. We presented how one can restrict the non-zero elements of the precision, which enforces conditional independencies. Our simulation study showed that this leads not only to an improved estimate for the dependency structure, but also to better estimates for the marginals. This translates into a lower relative entropy between the real distribution and the estimate. We also discussed how soft constraints on the dependency structure can be included.
We note that the focus of this paper is on estimating the joint distribution without precise specification of its subsequent use. Therefore, we did not discuss imputation methods (see, e.g., [40,41,42,43]). However, Gaussian copula models were employed as a device for multiple imputation (MI) with some success [22,24,44]. The resulting complete datasets can be used for inference. All approaches that we are aware of estimate the marginals by using the ecdf of the observed data points. The findings in Section 4 translate into better draws for the missing values.
Additionally, the joint distribution can be utilized for regressing a potentially multivariate on even if data are missing. By applying the EM algorithm on and by Proposition 1, one even obtains the whole conditional distribution of given .
We have shown how to incorporate a causal understanding of the data-generating process. However, in the potential outcome framework of [45], the derivation of a causal relationship can also be interpreted as a missing data problem in which the missing patterns are “misaligned” [46]. Our algorithm is applicable for this.
figuresection tablesection
Author Contributions
Conceptualization, M.K.; methodology, M.K.; software, M.K.; validation, M.P. and M.K.; formal analysis, M.K.; investigation, M.K.; resources, M.P. and M.K.; data curation, M.K.; writing—original draft preparation, M.K.; writing—review and editing, M.P. and M.K; visualization, M.K.; supervision, M.P.; project administration, M.P. All authors have read and agreed to the published version of the manuscript.
Funding
Maximilian Kertel’s work is funded by the BMW Group.
Data Availability Statement
The data generation procedures of the simulation studies and the proposed algorithm are availabe at https://github.com/mkrtl/misscop, accessed on 26 October 2022.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Technical Results
Appendix A.1. Proof of Conditional Distribution
Proof of Proposition 1.
We prove in the order of the proposition, which is a multivariate generalization of [47].
- 1.
- We inspect the conditional density function:Using well-known factorization lemmas and using the Schur complement (see, for example, [48] (Section 4.3.4)) applied on , we encounter
- 2.
- The distribution offollows with a change-of-variable argument. Using Equation (A1), we observe for any measurable set A thatwhere, in the second equation, we used the transformation and the fact that
- 3.
- This proof is analogous to the one above, and we finally obtain
The result can be generalized to the case in which . □
Appendix A.2. Closed-Form Solution of the E-Step for θ = θ t
Theorem A1.
We assume w.l.o.g. that and set
Then, it holds that
where and .
Proof.
We define . Then,
We now apply Proposition 1 and encounter
The last integral is understood element-wise. By the first and second moment of , it follows that
□
Appendix A.3. Maximizer of argmax Σ,Σ jj =1∀j=1,…,p λ(θ t, Σ|θ t, Σ t )
We are interested in
where are positive definite matrices. Clearly,
Using the Lagrangian, we obtain the following function to optimize
Applying the identities , , and , we obtain the derivative with respect to :
This is equivalent to
where is the diagonal matrix with entries and . We see that the scaling of S by leads, in general, to a different solution K, and hence, the estimator is not invariant under strictly monotone linear transformations of S.
We can also formulate the task as a convex optimization problem:
Appendix B. Details of the Simulation Studies
Appendix B.1. Drawing Samples from the Joint Distributions
Appendix B.1.1. Estimators of the Percentile Function
- In the case of SCOPE, consider the marginal observed data points, which we assume to be ordered . We use the following linearly interpolated estimator for the percentile function:
- To estimate the percentile function for the mixture models, we choose with equal probability (all Gaussians have equal weight) one component of the mixture and then draw a random number with its mean and standard deviation , . In this manner, we generate samples . The estimator for the percentile function is then chosen to be analogous to the one above. A higher leads to a more exact result. We choose to be 10,000.
Appendix B.1.2. Sampling
Given an estimator and estimators for the percentile functions , we obtain M samples from the learned joint distribution with
where are draws from a bivariate normal distribution with mean 0 and covariance . In the case of the gold standard, we set . We obtain samples of the real underlying distribution by using the correct percentile functions, as in the gold standard, and, additionally, . The procedure for three dimensions is analogous.
Appendix B.2. Missing Mechanism for Section 4.4
The missing mechanism is similar to the two-dimensional case. The marginals are chosen to be with six, seven, and five degrees of freedom. The data matrix keeps N (complete) observations of the random vector. We enforce the following missing data mechanism:
- Again, we remove every entry in the data matrix D with probability . The resulting data matrix (with missing entries) is denoted as
- If , , and are observed, we remove with probabilitywhereand .
We call the resulting data matrix . Its missing patterns are, again, non-monotone, and the data are MAR, but not MCAR. In Section 4.4, we set .
Appendix B.3. Complementary Figures

Figure A1.
Comparison of the algorithms with respect to the correlation . Shown are the boxplots for the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), the method based on known marginals (0), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2, where are depicted in the left canvas and are depicted in the right canvas. The true correlations are indicated by the dashed line.
Figure A1.
Comparison of the algorithms with respect to the correlation . Shown are the boxplots for the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), the method based on known marginals (0), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2, where are depicted in the left canvas and are depicted in the right canvas. The true correlations are indicated by the dashed line.


Figure A2.
Comparison of the algorithms with respect to the Cramer–von Mises distance between the estimated and the true first () and true second marginal distributions (). Shown are the boxplots on a logarithmic scale for the proposed EM algorithm (EM), the Standard Copula Estimator (SCOPE), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2, where are depicted in the left canvas and are depicted in the right canvas.
Figure A2.
Comparison of the algorithms with respect to the Cramer–von Mises distance between the estimated and the true first () and true second marginal distributions (). Shown are the boxplots on a logarithmic scale for the proposed EM algorithm (EM), the Standard Copula Estimator (SCOPE), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2, where are depicted in the left canvas and are depicted in the right canvas.


Figure A3.
Comparison of the algorithms with respect to the correlation (). Shown are the mean (upper canvas) and standard deviation (lower canvas) of the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and for varying sample sizes , where the true is (dashed line in the upper canvas).
Figure A3.
Comparison of the algorithms with respect to the correlation (). Shown are the mean (upper canvas) and standard deviation (lower canvas) of the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and for varying sample sizes , where the true is (dashed line in the upper canvas).


Figure A4.
Comparison of the algorithms with respect to the Cramer–von Mises statistic between the estimated and the true first marginal distribution. Shown are the mean (upper canvas) and standard deviation (lower canvas) of the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and for varying sample sizes of .
Figure A4.
Comparison of the algorithms with respect to the Cramer–von Mises statistic between the estimated and the true first marginal distribution. Shown are the mean (upper canvas) and standard deviation (lower canvas) of the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and for varying sample sizes of .


Figure A5.
Comparison of the algorithms with respect to the Cramer–von Mises statistic between the estimated and the true second marginal distribution. Shown are the mean (upper canvas) and standard deviation (lower canvas) of the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and for varying sample sizes of N = 100, 200, 500, 1000.
Figure A5.
Comparison of the algorithms with respect to the Cramer–von Mises statistic between the estimated and the true second marginal distribution. Shown are the mean (upper canvas) and standard deviation (lower canvas) of the Standard Copula Estimator (SCOPE), the proposed EM algorithm (EM), and the Markov chain–Monte Carlo approach (MCMC) for 1000 datasets generated as described in Section 4.2 with and and for varying sample sizes of N = 100, 200, 500, 1000.

References
- Thurow, M.; Dumpert, F.; Ramosaj, B.; Pauly, M. Imputing missings in official statistics for general tasks–our vote for distributional accuracy. Stat. J. IAOS 2021, 37, 1379–1390. [Google Scholar] [CrossRef]
- Liu, Y.; Dillon, T.; Yu, W.; Rahayu, W.; Mostafa, F. Missing value imputation for industrial IoT sensor data with large gaps. IEEE Internet Things J. 2020, 7, 6855–6867. [Google Scholar] [CrossRef]
- Silverman, B. Density Estimation for Statistics and Data Analysis; Routledge: London, UK, 2018. [Google Scholar]
- Kertel, M.; Harmeling, S.; Pauly, M. Learning causal graphs in manufacturing domains using structural equation models. arXiv 2022, arXiv:2210.14573. [Google Scholar] [CrossRef]
- Genest, C.; Ghoudi, K.; Rivest, L.P. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika 1995, 82, 543–552. [Google Scholar] [CrossRef]
- Liu, H.; Han, F.; Yuan, M.; Lafferty, J.; Wasserman, L. High-dimensional semiparametric gaussian copula graphical models. Ann. Stat. 2012, 40, 2293–2326. [Google Scholar] [CrossRef]
- Titterington, D.; Mill, G. Kernel-based density estimates from incomplete data. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 258–266. [Google Scholar] [CrossRef]
- Dempster, A.; Laird, N.; Rubin, D. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–22. [Google Scholar]
- Shen, C.; Weissfeld, L. A copula model for repeated measurements with non-ignorable non-monotone missing outcome. Stat. Med. 2006, 25, 2427–2440. [Google Scholar] [CrossRef]
- Gomes, M.; Radice, R.; Camarena Brenes, J.; Marra, G. Copula selection models for non-Gaussian outcomes that are missing not at random. Stat. Med. 2019, 38, 480–496. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Cui, R.; Groot, P.; Heskes, T. Learning causal structure from mixed data with missing values using Gaussian copula models. Stat. Comput. 2019, 29, 311–333. [Google Scholar] [CrossRef]
- Wang, H.; Fazayeli, F.; Chatterjee, S.; Banerjee, A. Gaussian copula precision estimation with missing values. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, Reykjavik, Iceland, 22–25 April 2014; PMLR: Reykjavik, Iceland, 2014; Volume 33, pp. 978–986. [Google Scholar]
- Hamori, S.; Motegi, K.; Zhang, Z. Calibration estimation of semiparametric copula models with data missing at random. J. Multivar. Anal. 2019, 173, 85–109. [Google Scholar] [CrossRef]
- Robins, J.M.; Gill, R.D. Non-response models for the analysis of non-monotone ignorable missing data. Stat. Med. 1997, 16, 39–56. [Google Scholar] [CrossRef]
- Sun, B.; Tchetgen, E.J.T. On inverse probability weighting for nonmonotone missing at random data. J. Am. Stat. Assoc. 2018, 113, 369–379. [Google Scholar] [CrossRef] [PubMed]
- Seaman, S.R.; White, I.R. Review of inverse probability weighting for dealing with missing data. Stat. Methods Med. Res. 2013, 22, 278–295. [Google Scholar] [CrossRef]
- Ding, W.; Song, P. EM algorithm in gaussian copula with missing data. Comput. Stat. Data Anal. 2016, 101, 1–11. [Google Scholar] [CrossRef]
- Efromovich, S. Adaptive nonparametric density estimation with missing observations. J. Stat. Plan. Inference 2013, 143, 637–650. [Google Scholar] [CrossRef]
- Dubnicka, S.R. Kernel density estimation with missing data and auxiliary variables. Aust. N. Z. J. Stat. 2009, 51, 247–270. [Google Scholar] [CrossRef]
- Hoff, P. Extending the rank likelihood for semiparametric copula estimation. Ann. Appl. Stat. 2007, 1, 265–283. [Google Scholar] [CrossRef]
- Hollenbach, F.; Bojinov, I.; Minhas, S.; Metternich, N.; Ward, M.; Volfovsky, A. Multiple imputation using gaussian copulas. Sociol. Methods Res. 2021, 50, 1259–1283. [Google Scholar] [CrossRef]
- Di Lascio, F.; Giannerini, S.; Reale, A. Exploring copulas for the imputation of complex dependent data. Stat. Methods Appl. 2015, 24, 159–175. [Google Scholar] [CrossRef]
- Houari, R.; Bounceur, A.; Kechadi, T.; Tari, A.; Euler, R. A new method for estimation of missing data based on sampling methods for data mining. Adv. Intell. Syst. Comput. 2013, 225, 89–100. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Wei, G.; Tanner, M. A monte carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. J. Am. Stat. Assoc. 1990, 85, 699–704. [Google Scholar] [CrossRef]
- Meng, X.L.; Rubin, D. Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika 1993, 80, 267–278. [Google Scholar] [CrossRef]
- Guo, J.; Levina, E.; Michailidis, G.; Zhu, J. Graphical models for ordinal data. J. Comput. Graph. Stat. 2015, 24, 183–204. [Google Scholar] [CrossRef]
- McLachlan, G.; Lee, S.; Rathnayake, S. Finite mixture models. Annu. Rev. Stat. Its Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Hwang, J.; Lay, S.; Lippman, A. Nonparametric multivariate density estimation: A comparative study. IEEE Trans. Signal Process. 1994, 42, 2795–2810. [Google Scholar] [CrossRef]
- Scott, D.; Sain, S. Multidimensional density estimation. Handb. Stat. 2005, 24, 229–261. [Google Scholar]
- Zuo, Y.; Cui, Y.; Yu, G.; Li, R.; Ressom, H. Incorporating prior biological knowledge for network-based differential gene expression analysis using differentially weighted graphical LASSO. BMC Bioinform. 2017, 18, 99. [Google Scholar] [CrossRef]
- Li, Y.; Jackson, S.A. Gene network reconstruction by integration of prior biological knowledge. G3 Genes Genomes Genet. 2015, 5, 1075–1079. [Google Scholar] [CrossRef] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Joyce, J.M. Kullback-Leibler divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar]
- Contreras-Reyes, J.E.; Arellano-Valle, R.B. Kullback–Leibler divergence measure for multivariate skew-normal distributions. Entropy 2012, 14, 1606–1626. [Google Scholar] [CrossRef]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. WIREs Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed]
- Dinu, V.; Zhao, H.; Miller, P.L. Integrating domain knowledge with statistical and data mining methods for high-density genomic SNP disease association analysis. J. Biomed. Inform. 2007, 40, 750–760. [Google Scholar] [CrossRef]
- Rubin, D. Multiple imputation after 18+ years. J. Am. Stat. Assoc. 1996, 91, 473–489. [Google Scholar] [CrossRef]
- Van Buuren, S. Flexible Imputation of Missing Data; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ramosaj, B.; Pauly, M. Predicting missing values: A comparative study on non-parametric approaches for imputation. Comput. Stat. 2019, 34, 1741–1764. [Google Scholar] [CrossRef]
- Ramosaj, B.; Amro, L.; Pauly, M. A cautionary tale on using imputation methods for inference in matched-pairs design. Bioinformatics 2020, 36, 3099–3106. [Google Scholar] [CrossRef]
- Zhao, Y.; Udell, M. Missing value imputation for mixed data via gaussian copula. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 636–646. [Google Scholar] [CrossRef]
- Rubin, D.B. Causal Inference Using Potential Outcomes: Design, Modeling, Decisions. J. Am. Stat. Assoc. 2005, 100, 322–331. [Google Scholar] [CrossRef]
- Ding, P.; Li, F. Causal inference: A missing data perspective. Stat. Sci. 2017, 33. [Google Scholar] [CrossRef]
- Käärik, E.; Käärik, M. Modeling dropouts by conditional distribution, a copula-based approach. J. Stat. Plan. Inference 2009, 139, 3830–3835. [Google Scholar] [CrossRef]
- Murphy, K. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).