1. Introduction
Non-orthogonal multiple access (NOMA) is a key enabler in the design of future overloaded beyond-5G communication systems with many more designated users than available physical resources, precluding the conventional orthogonal multiple access (OMA) paradigm [
1,
2,
3,
4] (see also [
5] for a very recent technology review). The main potential appeal of NOMA over OMA stems from either supporting more simultaneous users or, in lieu, facilitating higher user throughputs when orthogonality is practically unsustainable. NOMA technologies generally comprise two main manifestations, power-domain NOMA and code-domain NOMA. Power-domain NOMA essentially relies on direct superposition of the transmitted signals, successive interference cancellation (SIC) at the receivers and appropriate power allocation to different users in order to achieve desired performance objectives [
1,
2,
6,
7]. Under the code-domain NOMA paradigm, the users’ signals are distinguished by different spreading signatures chosen to facilitate efficient multiuser detection (MUD) at the receivers (see, e.g., [
2,
8]). In particular, sparse NOMA, or low-density code-domain (LDCD) NOMA, has gained considerable interest in recent years due to its appealing attributes. Relying on sparse spreading signatures, sparse NOMA potentially facilitates enhanced spectral efficiency with practical receiver implementation based on sparsity exploiting iterative message passing algorithms (MPAs), similarly to the ones empowering the efficient decoding of low-density parity-check (LDPC) codes. The interested reader is referred to the insightful surveys [
1,
2] for details about the utilization of MPAs in NOMA, along with their concrete application for sparse NOMA [
9,
10,
11], including sparse-code multiple access (SCMA) [
12]. Different designs of sparse spreading signatures and their impact on MUD error-rate performance are discussed, e.g., in [
11,
13,
14] and references therein.
Transmission schemes
combining power-domain NOMA and SCMA were also recently proposed, e.g., in [
15,
16] for the cellular downlink channel and in [
17,
18,
19,
20,
21] for the uplink channel. Therein, the main objective is to identify efficient centralized algorithms for joint resource and power allocation, that attempt to maximize the SCMA achievable throughput under independent Rayleigh fading and certain simplifying assumptions (viz., independent Gaussian signaling over each utilized physical resource, full synchronization and perfect channel state information). Fairness and quality-of-service constraints may also be incorporated into the optimization algorithm (e.g., [
19,
20,
21]). The performance of the proposed algorithms is then evaluated by means of numerical simulations. More involved network configurations have also been considered recently, e.g., system models encompassing relays (see [
22] and references therein for an exhaustive literature survey). Relaying may either appear in the form of dedicated network elements, e.g., [
22,
23] or, alternatively, by means of user cooperation, e.g., [
24,
25,
26,
27]. In this framework, focusing on power-domain NOMA with SIC, the notion of virtual full-duplex (VFD) relaying [
28] has gained particular interest as means to circumvent the implementation challenges of true full-duplex operation; see, e.g., [
22,
25,
26,
27]. The impact of imperfect SIC and residual inter-relay interference in this framework was also recently considered in [
26].
Notwithstanding their great practical promise and potential, sparse NOMA techniques often pose serious analytical challenges and their information-theoretic performance limits are not easily tractable even in the simplest settings. Typically, tools from random matrix theory or statistical physics are harnessed for their analysis [
29,
30,
31,
32], while considering the asymptotic large-system limit, where both the number of users and the number of available resources grow large, while retaining a fixed ratio (see, e.g., [
33,
34,
35]). The obtained results typically yield
excellent approximations for the expected performance with finite (and quite moderate) system dimensions [
29,
30].
Sparse NOMA is dubbed:
regular when a
fixed (and finite) number of orthogonal resources is allocated to any designated user and each resource is used by a fixed number of users;
irregular when the respective numbers are random and only kept fixed on average [
33]. In the literature, one can also find a
partly regular version of the sparse NOMA setup where each user occupies a fixed number of resources and each resource is used by a random, yet fixed on average, number of users (or vice versa) [
34,
36].
In a recent line of works by the authors [
37,
38,
39], the particular manifestation of code-domain NOMA known as
regular sparse NOMA has been investigated and its asymptotic spectral efficiency has been derived in
closed form [
38,
39] (see
Section 2 for a precise characterization of the underlying asymptotic large-system limit and [
38,
39] for a discussion on what distinguishes this particular setting from previous analyses). Therein, a generic setup of a (non-fading) Gaussian vector multiple-access channel (MAC) with equal-power users was considered, representing the case of a single-cell uplink model with fully coordinated grant-based access, and the scheme was analytically proven to substantially decrease the gap to the ultimate capacity limit of overloaded systems. Furthermore, regular sparse NOMA was proven by the authors to outperform the dense code-domain NOMA alternative [
40,
41], along with its irregular and partly regular sparse counterparts [
33,
34]. Hence, regular sparse NOMA seems to exhibit a rare combination of information-theoretic superiority and
computational feasibility (dense code-domain NOMA is operationally equivalent to randomly spread code-division multiple access (RS-CDMA) [
40,
41], for which achieving the optimal spectral efficiency becomes
prohibitively complex in large systems [
42]). However, analyzing the merits of regular sparse NOMA beyond the generic equal-power Gaussian vector MAC setting is still a challenging, yet of utmost importance, open problem, which does not seem to lend itself to closed-form characterization, as in [
38,
39].
Motivated by this noteworthy challenge, the current paper takes a step further towards a generalization of the fundamental result of [
38,
39]. To this end, the focus remains on regular sparse NOMA within a single-cell Gaussian uplink (MAC) model, but the single-class information-theoretic analysis of [
37,
38,
39] is extended to a looser, yet more realistic, setting comprising
two user classes distinguished by their received powers. Again, the large-system limit is considered and our main contribution is the derivation of
closed-form bounds on the achievable class-rate (total throughput) region, which are both insightful and analytically tractable. An inner bound is first derived based on the standard conditional vector entropy power inequality (EPI) [
43]. A derivation of an outer bound follows, while relying on a recent strengthened version of the EPI by Courtade [
44,
45]. Both bounds are
tight with respect to the individual achievable class-throughput constraints and only differ in the achievable sum-rate (total throughput) constraint. The key tool in the derivations is a noise-split “trick”, that, when combined with the EPI, induces closed-form bounds expressed in terms of single-class achievable throughputs [
38,
39]. A simplified outer bound, which does not rely on the EPI, is then presented for load-symmetric settings (under some mild technical assumptions). This bound turns out to be tighter in certain cases. An in-depth elucidative investigation of the corresponding lower and upper bounds on the achievable sum rate in extreme-SNR regimes is also provided, which, by means of appropriate approximations [
41], identifies conditions under which the bounds are useful and a superior performance over dense code-domain NOMA is guaranteed. Conditions for attaining a relatively small gap to the ultimate performance limits are also discussed.
Our contribution provides valuable insights into the potential performance gains of regular sparse NOMA in several timely use cases of interest. One particular example represents a 5G-and-beyond scenario, where the two user classes respectively correspond, say, to low-complexity devices with stringent power constraints (e.g., Internet-of-Things applications) and to broadband users with higher transmit power capabilities. Another applicable use case is a single cell with users located at the extremes of either the cell center or the cell edge. Our analysis is also applicable to a compelling combination of power-domain NOMA [
2,
6] and code-domain NOMA, which has only recently started to attract attention in the literature [
15,
16,
17,
18,
19,
20,
21], as discussed above. Accordingly, the corner points of the achievable region bounds correspond to a SIC scheme between the two user classes, while incorporating near-optimal joint iterative decoding (MPA) within each class. In fact, by this interpretation, our analysis provides, in a sense, an
analytical benchmark for the setting considered in [
20] (see also [
18]), under the simplifying assumptions of non-fading channels and full symmetry among the users in each user class. Note that, in the
absence of fading, the corresponding regular SCMA achievable sum rate, while assuming independent Gaussian signaling over each utilized resource, trivially coincides with the Cover–Wyner sum capacity (see, e.g., [
43] and
Section 3.3). Hence, our analytical bounds quantify the gap from the ultimate performance limit induced by employing regular sparse spreading signatures and may serve as reference for practical schemes that aim to approach the sum-capacity limit using the SCMA paradigm, e.g., [
17,
18,
19,
20,
21]. Note that, in the presence of fading, characterizing the achievable rate region of the two-user-class system considered in this paper is still a formidable open problem yet to be explored; hence, a direct and explicit comparison with practical achievable sum rates reported in works, such as [
20], cannot be performed at this stage. Yet another applicable model is a two-cell interference network, where the two user classes represent, respectively, the local cell users and the users operating in the adjacent interfering cell. This may be further extended, e.g., to Wyner-type cellular models with single-cell processing [
46,
47,
48,
49].
This paper is organized as follows:
Section 2 describes the underlying system model and the random graph models employed to construct the regular sparse spreading signatures.
Section 3 presents a general statement of the class-throughput achievable region and the corresponding closed-form analytical inner and outer bounds.
Section 4 is devoted to a comparative extreme-SNR characterization of the lower and upper bounds on the total achievable sum rate. Illustrative numerical results are provided in
Section 5. Finally,
Section 6 ends this paper with some concluding remarks. Detailed proofs and some technical observations are deferred to the appendices.
2. System Model
Notation: We use boldface lower-case letters to denote vectors and boldface uppercase letters to denote matrices. denotes the -th entry of the matrix . denotes the transpose of , while denotes the corresponding conjugate (Hermitian) transpose. ⊗ denotes the Kronecker product. denotes the N-dimensional identity matrix. designates the distribution of a proper circularly symmetric complex Gaussian random vector with mean and covariance matrix . designates the probability distribution of a single mass at x. Equality in distribution is denoted by , stating that the distribution of the random variables on both sides of the equality sign is the same. denotes statistical expectation and designates that the expectation is taken with respect to the distribution of the random variable X. denotes differential entropy and denotes mutual information. For any , we use the notation . Base-2 logarithms are used throughout this paper unless otherwise stated (in which case the base of the logarithm is explicitly designated). For the sake of clarity, we use to denote the natural logarithm.
We consider a MAC, representing a single-cell uplink, where the users belong to either of two different classes distinguished by their received powers (henceforth referred to as “Class 1” and “Class 2”). Within each class, all users are assumed to be received at the same power level. The users’ signals are multiplexed over N shared orthogonal dimensions (resources), which may represent, e.g., orthogonal time–frequency slots. However, it is important to emphasize here that the setting is quite general and applies to any orthogonal coordinate system; therefore, the dimensions are, by no means, restricted to the time–frequency domain. Let and denote the number of users in Class 1 and Class 2, respectively, and let , denote the respective loads (users per resource). The total number of users is denoted by and the total system load reads .
Focusing on a generic non-fading Gaussian channel model, the
N-dimensional received signal at some arbitrary time instance reads
where
,
, is a
-dimensional complex vector comprising the coded symbols of the users in Class
i. Assuming Gaussian signaling, full symmetry, fixed powers and no cooperation among encoders corresponding to different users, the input vector
is distributed as
. The matrix
represents the
sparse signature matrix of Class-
i users, where the
kth column represents the spreading signature of user
k in Class
i. The non-zero entries of
designate the corresponding user-resource mapping, namely, user
k in Class
i occupies resource
n if
. Specifically, we adhere to the regular sparse NOMA paradigm [
37,
38,
39], where, for each Class
i,
, due to the sparsity of
, only a few of the users’ signals collide over any given orthogonal resource. The regularity assumption generally dictates that each column of
(respectively, row) has
exactly (respectively,
) non-zero entries. However, for notational simplicity, we assume henceforth that
, while noting that extension of the analysis to the case where
and
have a different fixed number of non-zero column entries is straightforward (hence omitted). Therefore,
d takes the role of the
system’s sparsity parameter. We assume here that
is chosen so that
,
, in order to avoid degenerate settings. The non-zero entries of
are assumed to be independent and identically distributed (i.i.d.), but may otherwise arbitrarily reside on the unit circle in the complex plane, in complete adherence to [
38,
39]. Thus, the normalization in (
1) ensures that the columns of
have unit norm. We also assume here that the signature matrices
and
are perfectly known at the receiving end and uniformly chosen, respectively, randomly and independently per each channel use and each user class
i, from the set of
-regular matrices. This assumption is only introduced here for the sake of concreteness and the setting, in fact, generalizes verbatim to the case where the signature matrix selection process is stationary and ergodic. Finally,
denotes the
N-dimensional circularly symmetric complex additive white-Gaussian-noise (AWGN) vector at the receiving end. Thus, the parameter
in (
1),
, designates the received signal-to-noise ratio (SNR) of each of the users in Class
i.
A key additional underlying assumption, which follows [
38,
39], is that the signature matrices
can be associated with the
adjacency matrices of certain random
-semiregular bipartite (factor) graphs
, with special properties to be stated next. To this end, we first introduce the following two definitions.
Definition 1 (Locally Tree-Like Graphs [
50,
51])
. Let denote the space of rooted isomorphism classes of rooted connected graphs. A sequence of random graphs , , in the space , with a root vertex chosen uniformly at random from the vertex set of , is said to converge locally (weakly) to a certain random rooted tree , if, for each , the sequence of balls with radius r (in graph distance) around converges in law to in the space . A more precise mathematical definition can be found, e.g., in [50,51]. Definition 2 (Bipartite Galton–Watson Tree (BGWT) [
50])
. A Galton–Watson tree (GWT) with degree
distribution is a rooted random tree obtained by a Galton–Watson branching process, where the root has offspring
distribution and all other genitors have offspring distribution F, where (assuming )A BGWT with degree distribution and parameter p is obtained from a Galton–Watson branching process with alternated
degree distribution. Namely, with probability p, the root has offspring distribution , all odd generation genitors have an offspring distribution G (related to analogously to F) and all even generation genitors (apart from the root) have an offspring distribution F. Similarly, with probability , the root has offspring distribution and the offspring distributions of all odd and even generation genitors are switched. See [50] for a more elaborate discussion. We now further assume that the random graphs associated with the signature matrices are locally tree-like and converge in the large-system limit to BGWTs having degree distribution and parameter as a weak limit, where . The term “large-system limit” refers here to the regime where while fixing , . We use henceforth the shorthand notation “” to designate this limiting regime.
From a practical perspective, it is important to note here that the aforementioned locally tree-like property is valid, e.g., for regular LDPC codes [
50,
52] and it essentially implies that, for large dimensions, short cycles are rare, which facilitates the use of iterative near-optimal multiuser detection algorithms (while applying MPAs over the underlying factor graphs). Moreover, the sparse signature matrices can in fact be constructed as weighted parity-check matrices of regular LDPC codes, which we, in fact, employ using Gallager’s construction [
53] to produce the finite dimensional simulation results in
Section 5 (see therein).
4. Extreme-SNR Characterization
To complement the analytical characterization of the achievable rate region by means of the bounds in Propositions 1–3, we focus on the achievable sum rate and provide, in this section, an in-depth investigation of the respective bounds in extreme-SNR regimes. Although all bounds take an explicit closed form, the corresponding expressions are still rather involved. Therefore, the main advantage of the extreme-SNR characterization is that, by means of certain simplifying approximations (appropriate for extreme SNRs), it leads to valuable insights that are otherwise hard to obtain, as is shown in the sequel. In particular, this characterization demonstrates the impact of the parameters
used in Propositions 1 and 2 on the tightness of the respective lower and upper bounds on the achievable sum rate. For symmetric settings (see
Section 3.4), it further allows us to identify which of the two upper bounds on the achievable sum rate stated in Propositions 2 and 3 is tighter; hence, the corresponding outer bound is more useful for characterizing the achievable region in extreme-SNR regimes. For the low-SNR regime, we specify conditions under which the former bound of Proposition 2 is tighter, while, for the high-SNR regime, it turns out that Proposition 3 generally provides a tighter bound in symmetric overloaded settings.
Our analysis examines the achievable sum rate as a function of
(the average SNR), as defined in (
19). Furthermore, without loss of generality, we assume henceforth that
for some
. This immediately implies (cf. (
19)) that
where
Starting with the low-SNR regime, the achievable sum rate is approximated as
where
denotes the low-SNR slope,
is the minimum system average
that enables reliable communications and
[
41]. The average SNR and
are related via
Let
denote the achievable sum rate expressed as a function of
in
nats/channel use per dimension. Then, the minimum
that enables reliable communications and the low-SNR slope read [
41]
where
and
denote the first and second derivatives at zero of
(note that (
22), (
24) and (
25) tacitly assume that the minimum
corresponds to the point of vanishing rate; a short discussion on this aspect is provided in
Appendix D).
Turning to the high-SNR regime, we approximate the achievable sum rate as [
41]
where
denotes the high-SNR slope (multiplexing gain) and
denotes the high-SNR power offset. Note that we use here a slightly different high-SNR approximation than the one originally proposed in [
41], in the sense that it relies on approximating the sum rate as a function of
(rather than
); consequently, the resulting high-SNR power offset differs by a
term when compared to [
41].
In the following sections, we employ the above approximations for the lower and upper bounds on the achievable sum rate and derive the corresponding extreme-SNR parameters. Specifically, we consider the sum-rate bounds in (
10) and (
12), which, when rewritten as functions of
, read
where we introduce the notation
For symmetric settings, we additionally rely on ([
38], Proposition 5; see also [
39], Proposition 4) for the extreme-SNR characterization of the sum-rate bound in (
14).
Furthermore, note that the
sum capacity (specifying the ultimate performance limit) is given by the sum-rate constraint in (
13), which, when expressed as a function of
, boils down to
Hence, the corresponding low-SNR parameters are
while the high-SNR parameters read
4.1. The low-SNR Regime
Starting with the sum-rate lower bound (
27), its low-SNR characterization is summarized in the following proposition.
Proposition 4. The low-SNR parameters of the asymptotic sum-rate lower bound (27) readwhere, as in Proposition 1, and . As implied by Proposition 4, the sum-rate lower bound optimization with respect to
(see
Section 3.2) takes a more explicit form in the low-SNR regime. Specifically, the low-SNR slope (
34) can be optimized by choosing
such that the denominator therein is minimized; namely, by setting
To demonstrate the usefulness of this observation, while simplifying the discussion, let us consider the symmetric setting where
. Then, the optimal choice for
reduces to
which yields
Substituting back into (
34), while accounting for the class-symmetry and setting
we obtain (following some algebra)
Note that
is strictly lower, for all
, than the corresponding low-SNR slope of the optimum spectral efficiency (total throughput) in a
single-class setting with load
and an SNR that equals
, as specified in Theorem 1, which reads ([
38], Proposition 5; see also [
39], Proposition 4)
In fact, (
40) also specifies the low-SNR slope of the sum-rate upper bound for the “symmetric construction”, as stated in Proposition 3 (cf. (
14)). Hence, (
39) and (
40) provide compact lower and upper bounds on the low-SNR slope of the achievable sum rate under class symmetry. Another interesting comparison is with the low-SNR slope of the maximum achievable sum rate with RS-CDMA, representing a practical manifestation of random
dense NOMA (see
Appendix G for a derivation of the RS-CDMA achievable region). For the symmetric setting, this slope reads (following (
A110), (
A114) and ([
41], Equation (147)))
which lets us conclude that
, as long as
hence, regular sparse NOMA is guaranteed to strictly outperform RS-CDMA in the low-SNR regime as long as (
42) is satisfied. Note, e.g., that setting
immediately implies that (
42) is satisfied for all
.
Turning to the sum-rate upper bound (
28), its low-SNR characterization is summarized in the following proposition.
Proposition 5. Let denote the setwhere, as in Proposition 2, and . Then, for , the low-SNR parameters of the asymptotic sum-rate upper bound (28) readFurthermore, the sum-rate upper bound (28) is not useful in the low-SNR regime for . Analogously to the characterization of the lower bound in Proposition 4, the low-SNR slope (
45) can be optimized by choosing
such that the denominator therein is maximized; namely, by setting
Note that, for
, the low-SNR slope
is strictly smaller than
(recall that
); hence, the upper bound (
28) is useful in this region of the parameters.
Additional insight can be gained by focusing again on the symmetric setting
. In such case, we obtain that the optimal choice for
simplifies to the following:
Note that, in fact, for
, the condition that specifies the set
simplifies to
. Then, rewriting the low-SNR slope (
45) as
we conclude that the sum-rate upper bound (
28) implied by Proposition 2 is
tighter in the low-SNR regime than the corresponding simple “symmetric construction“ bound in (
14), as long as there exists a pair of constants
such that (cf. (
40))
Note that the existence of such constants is not guaranteed for all choices of the underlying parameters. To see this, let
and let us recall that, since
, the ratio
must satisfy
. Then, (
49) can be rewritten as
or, equivalently,
where
and
Now, a careful examination of the constants
,
and
reveals that a
necessary condition for (
51) to hold is
That is, the sum-rate upper bound (
28) can be tighter than the corresponding “symmetric construction“ upper bound in (
14) only if
is relatively low. To determine
sufficiency, let us consider the polynomial
. Then, it can be verified that, subject to condition (
55), the coefficients
,
and
satisfy
Let
and
denote the roots of
, namely,
Then (noting that
),
and it turns out that, in addition to (
55), condition (
51) can only hold if the following additional conditions are satisfied:
4.2. The High-SNR Regime
As in
Section 4.1, we start with the sum-rate lower bound (
27) and derive its high-SNR characterization while focusing on the case where at least one of the two user classes is overloaded. For concreteness, we assume henceforth that
. Our main observations are summarized in the following proposition.
Proposition 6. Assume that . Then, the high-SNR parameters of the asymptotic sum-rate lower bound (27) readandwhere , , denotes the high-SNR power offset of a single-class
setting with load (corresponding to Theorem 1), which reads ([38], Proposition 5) Remark 1. Analogous results for the case where the load is constrained to satisfy , as well as the case where , can be straightforwardly derived following similar lines to the proof in Appendix E. The details are omitted for conciseness. Note also that, for the case where both
user classes are underloaded (i.e., ), the corresponding derivation indicates that the sum-rate lower bound is too loose in the high-SNR regime and fails to capture the correct high-SNR slope. Remark 2. As indicated by (60) and (61), in sheer contrast to the low-SNR regime, the high-SNR parameters of the sum-rate lower bound do not
depend on the parameter κ for . The high-SNR characterization of the sum-rate upper bound (
28) is summarized next.
Proposition 7. Assume that . Then, the high-SNR parameters of the asymptotic sum-rate upper bound (28) readandwhere , , are specified in (62). Remark 3. Note that, for , the high-SNR parameters of the sum-rate upper bound turn out to be independent of the choice of . Derivations along the lines of Appendix F reveal that, for , the sum-rate upper bound follows the correct high-SNR slope only if , namely, when the (overall) system operates in the underloaded (or fully loaded) regime, which is of lesser interest in the NOMA framework. Furthermore, the analysis shows that, for all other choices of and (expect for ), the sum-rate upper bound (28) becomes too loose for the high-SNR regime and does not capture the correct high-SNR slope. To gain more insight, let us consider the symmetric overloaded setting where
. In such case, the high-SNR slope equals unity for both the lower and upper sum-rate bounds, namely,
Turning to the high-SNR power offset, note that, in the symmetric overloaded setting, one obtains (cf. (
21))
while
Hence, we conclude, from (
61) and (
67), that
Similarly, considering the high-SNR power offset of the sum-rate upper bound (
64), we obtain
The difference between the offsets (
68) and (
69) specifies the horizontal gap (in logarithmic scale) between these lower and upper bounds on the achievable sum rate in the high-SNR regime. However, it is also insightful to compare
to the corresponding high-SNR power offset induced by the “symmetric construction” outer bound of Proposition 3 (see (
14)). This offset is simply given by (
62), while substituting
instead of
, and reads
Note that
which can be verified to always take on negative values for
and
(in fact, in such case,
is even strictly smaller than
(
32)). Hence, we conclude that the “symmetric construction” sum-rate upper bound is tighter in the high-SNR regime for symmetric settings, when
. This observation is corroborated by the numerical results presented in
Section 5.
5. Numerical Results
In this section, we present some numerical results that demonstrate the effectiveness of the inner and outer bounds derived in
Section 3 for assessing the potential performance gains of regular sparse NOMA. The focus here is on
overloaded settings (
), corresponding to use cases where NOMA is of particular interest, while noting that the bounds also generally apply to underloaded regimes. The sparsity parameter
d of the signature matrices was set throughout to
, since, as shown in [
38,
39], it induces the highest achievable individual (per class) throughputs for regular sparse NOMA. Our numerical investigation complements the
analytical observations of
Section 4, by considering more general SNR regimes.
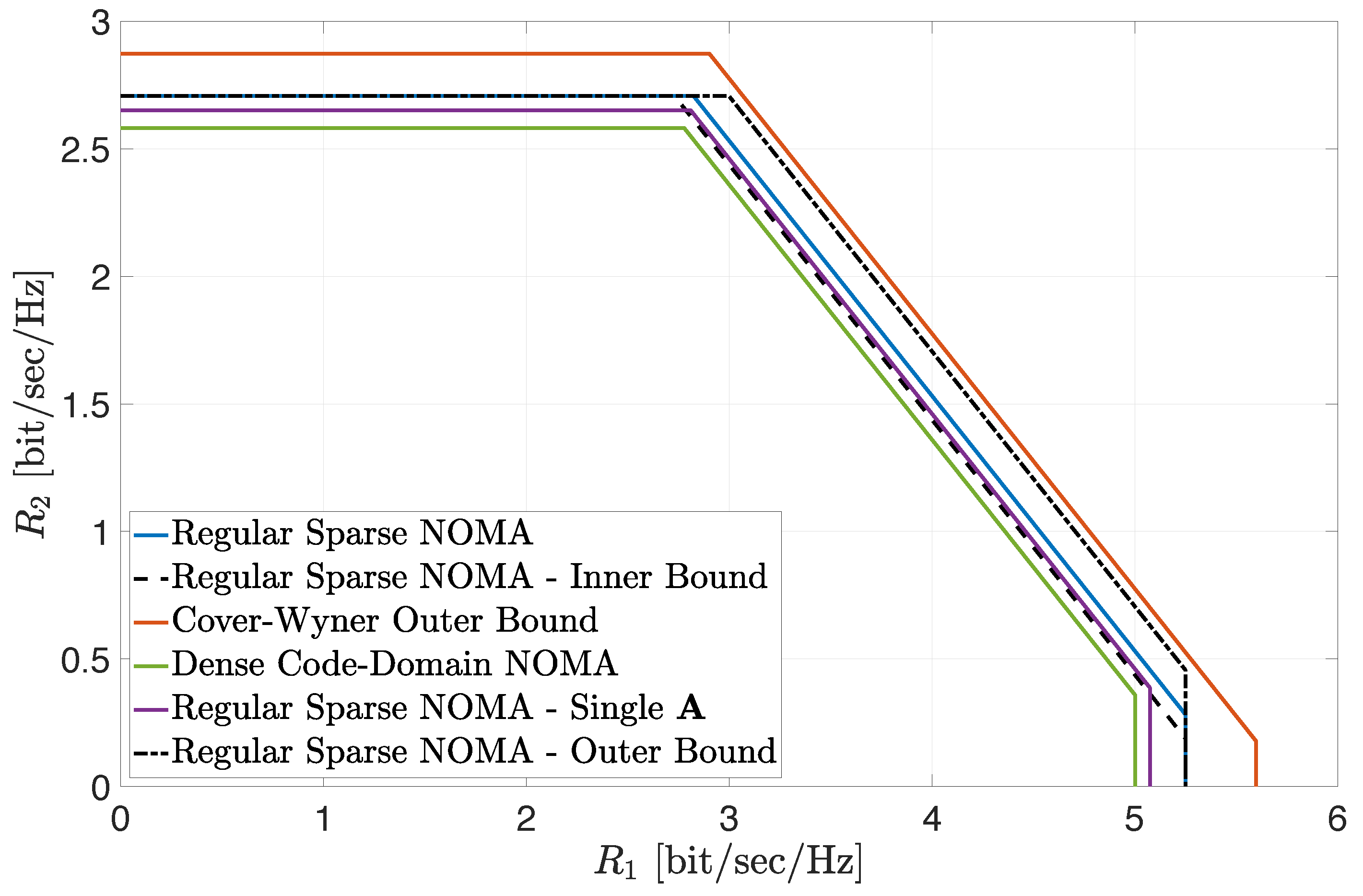
Figure 1 depicts the inner and outer bounds on the achievable region (
8) in the large-system limit, for the case where
and
(cf. (
10) and (
12)). The corresponding noise-split parameters were set to
,
and
(these values were numerically verified to be close to optimal). The SNRs of the two user classes were fixed to
and
. The cautious reader should note that this choice for the noise split parameters
is, by no means, a contradiction to the condition specified in Proposition 5 for the usefulness of the outer bound (see (
43)). This is since Proposition 5 only applies to the low-SNR regime, while, in
Figure 1, the two SNRs
do not yield a low average SNR setting. In fact, it can be numerically verified that choosing
in the low-SNR regime, which falls outside the region
in (
43), leads to a very loose upper bound on the achievable sum rate, significantly higher than the corresponding Cover–Wyner sum-rate upper bound in (
13). Hence, this choice is not useful in the low-SNR regime as predicted by Proposition 5 (see also the discussion in
Section 4.1). The boundary of the inner bound is represented
Figure 1 by the dashed black line, while the boundary of the outer bound is designated by the dash–dotted black line. Note that the two bounds differ only in the sum-rate constraint, while sharing the class–individual rate constraints (which are characterized in full via Theorem 1, as discussed in
Section 3.1). To assess the tightness of the bounds,
Figure 1 also shows an estimation of the boundary of the achievable region (
8) for a regular sparse NOMA system with a large but
finite number of orthogonal dimensions
. Here, all rate constraints of the corresponding region were evaluated based on Monte Carlo (MC) simulations of 1000 sparse matrix realizations using Gallager’s construction for parity-check matrices of LDPC codes [
38,
39,
53] (let us recall that the main motivation for the derivation of the inner and outer bounds on the achievable region is the fact that an exact analytical asymptotic result for the sum-rate constraint of this region is
still lacking; hence, we resorted to MC simulations). The boundary of this region is represented by the solid blue line. Note that both inner and outer bounds are rather tight and provide a very good assessment of the achievable region (specifically, the limiting upper bound on the sum-rate constraint is higher than the simulated constraint by about only
, while the corresponding lower bound is lower by less than
).
Figure 1 also indicates that the asymptotic class–individual rate constraints provide an
extremely tight assessment of the corresponding throughputs in large finite-dimensional systems, as already shown in [
38,
39]. We further note that extensive numerical investigations indicate that the EPI-based bounds become tighter as the powers allocated to each class of users become more unbalanced, which stems from the nature of the EPIs. This observation is further demonstrated in the sequel.
For the sake of comparison,
Figure 1 also includes the achievable regions of two other system settings of interest. The first region corresponds to dense code-domain NOMA, represented here by RS-CDMA. The corresponding boundary of the achievable region in the large-system limit is designated by the solid green line (see (
A119) in
Appendix G). The second region corresponds to a setting where the signatures of individual users are taken as the columns of a
single regular sparse matrix, where each user occupies
resources and each resource is utilized by exactly
users. No regularity is imposed within either of the two classes of users and the signature columns are allocated to the users in each class uniformly at random. The induced signature matrices
and
for each class of users (after reordering of the columns) are therefore
no longer row-regular. The boundary of the corresponding achievable region, based on MC simulations (while fixing
), is designated by the solid purple line (referred to as ‘Single
’). Finally,
Figure 1 also shows the Cover–Wyner region (
13). The boundary of this region is designated by the solid red line.
A comparison of all achievable regions in
Figure 1 lets us conclude the following (with the aid of additional investigations omitted for conciseness): Irregularity induces a loss in the achievable rate region. This is clearly observed when comparing the achievable region with a
single regular sparse signature matrix construction (‘Single
’) and the MC-based achievable region with two separate regular constructions of the signature matrices for the two classes of users. The superiority of separate constructions is also observed for the
class–individual rate constraints when considering the inner bound (
10). Comparing the regular sparse construction in (
1) and dense code-domain NOMA (here, RS-CDMA), the MC simulation results indicate that the corresponding achievable region strictly includes the achievable region with dense code-domain NOMA, in full agreement with the analytical observations made in [
38,
39] with respect to single-class systems. Furthermore, when the class-powers are far enough apart, this even holds for the inner bound (
10), as shown in
Figure 1, implying that regular sparse NOMA indeed strictly outperformed dense code-domain NOMA (RS-CDMA) in this setting. Finally, considering the outer bound on the achievable region (
12),
Figure 1 shows that, for power-unbalanced settings, it provides a good assessment of the gap to the ultimate performance limits, as designated by the Cover–Wyner capacity region.
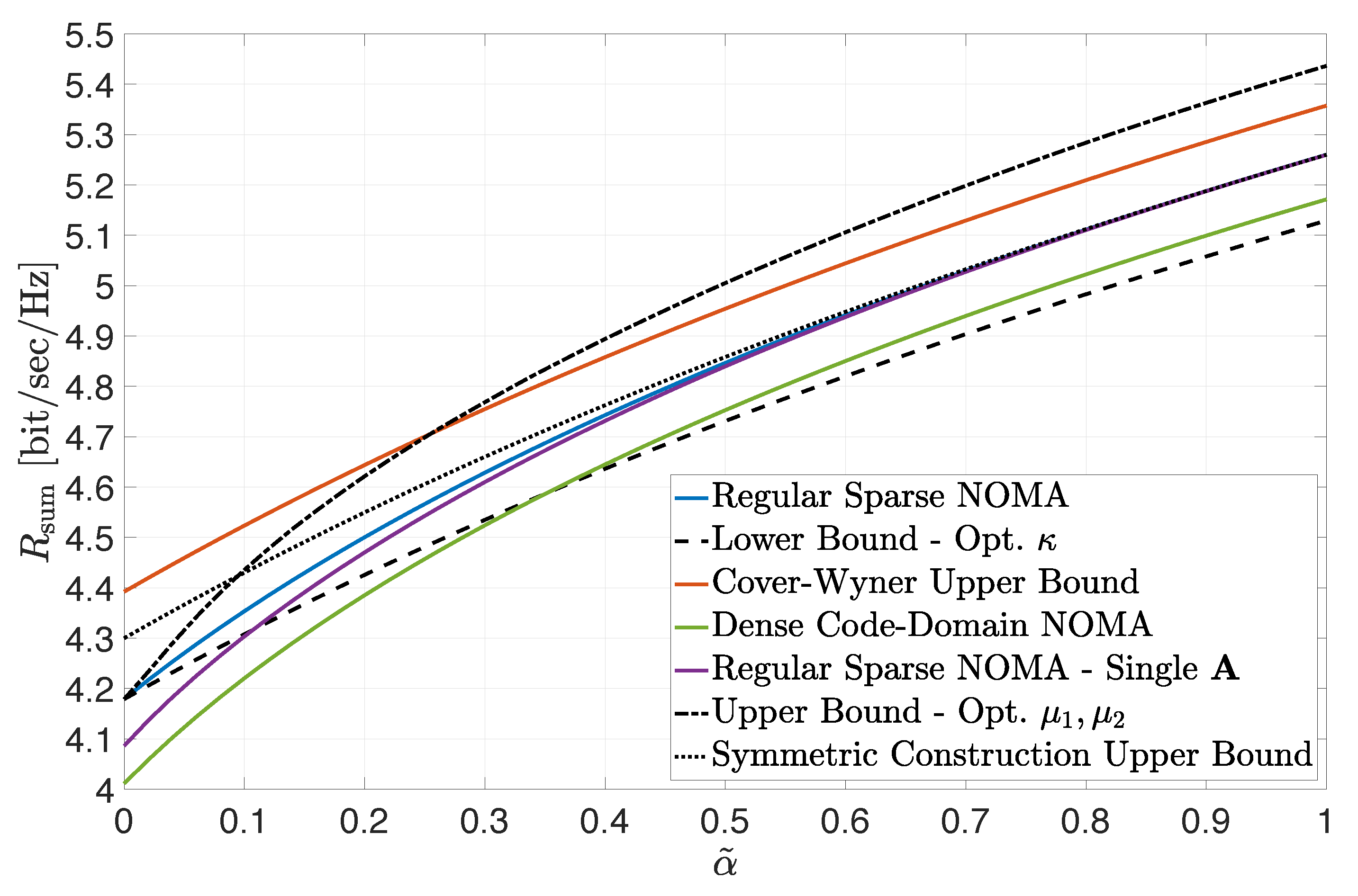
The impact of the SNR balance between the two classes of users is illustrated in
Figure 2. A load-symmetric setting is considered where
and the received SNR of Class 1 users was set to
. The received SNR of Class 2 users was set to
, where
. The figure depicts the sum-rate constraint of the rate region for the settings and bounds considered in
Figure 1 as a function of
. The lower and upper bounds, according to (
10) and (
12), were numerically optimized, respectively, by fine-tuning the values of
,
and
. In view of the load-symmetry in this example, the “symmetric construction” upper bound in (
14) is also included in the figure (designated by the dotted line). Similar conclusions to the ones discussed with respect to
Figure 1 can be reached. The tightness of all three bounds is clearly demonstrated in the low
region. In particular, note that a threshold value for
is observed, below which the sum-rate lower bound in (
10) already surpasses the dense code-domain NOMA achievable sum rate (thus guaranteeing the superiority of regular sparse NOMA). The results also indicate that the sum-rate upper bound in (
12) is meaningful and resides below the Cover–Wyner sum capacity, when
lies below a threshold (while, otherwise, it becomes too loose and ceases to be useful). Note that, in this load-symmetric setting, the simple “symmetric construction” upper bound in (
14) turns out to be the tightest for most values of
. In fact, by Jensen’s inequality, it also provides here a tight upper bound for the ‘Single
’ construction. However, neither of the two upper bounds (in (
12) or (
14)) is universally superior. Although
Figure 2 does not represent an extreme-SNR regime per se, the main observations
qualitatively corroborate the conclusions of the analytical examination in
Section 4.
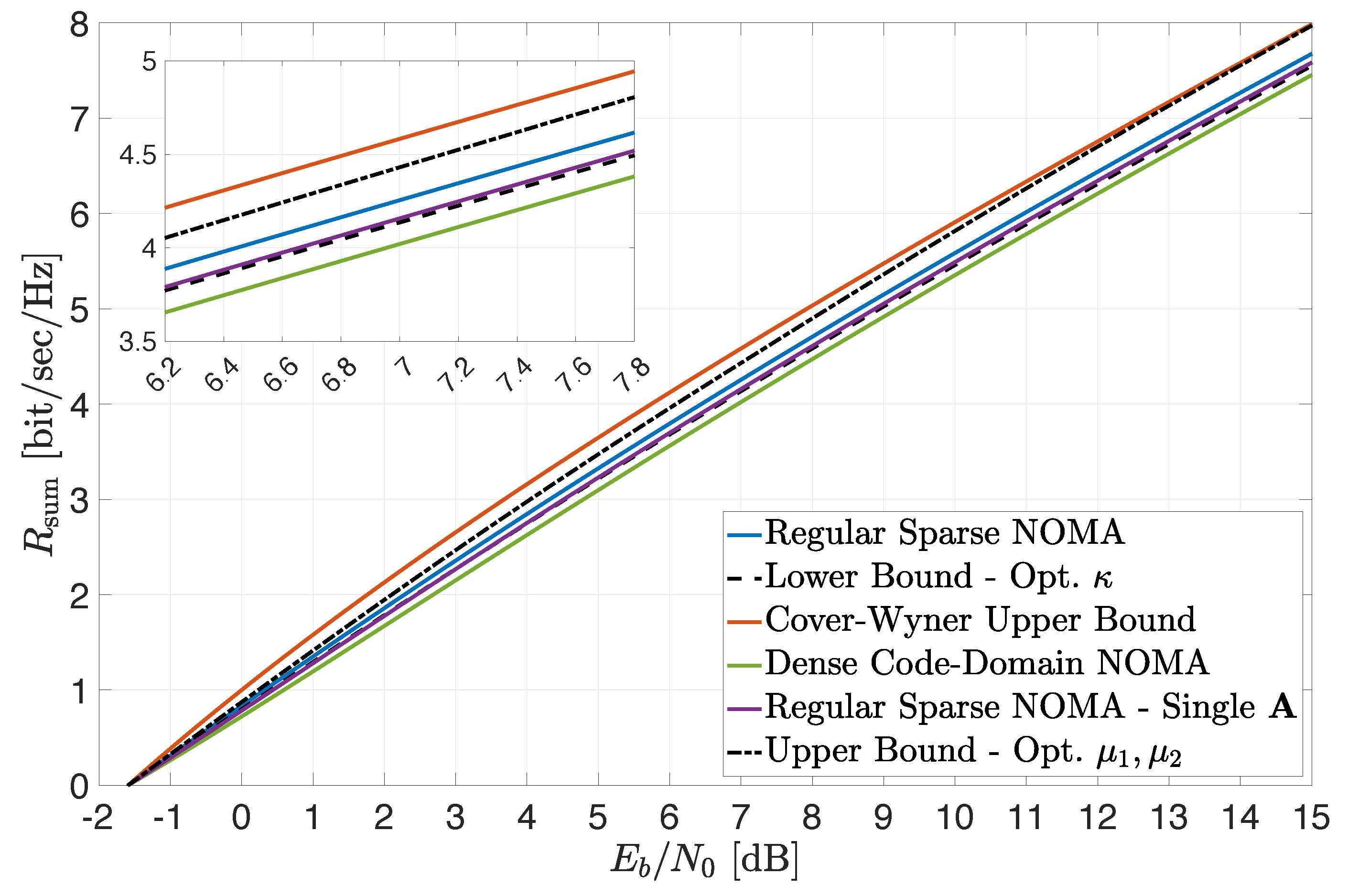
Finally, the preceding observations are further corroborated in
Figure 3, where a setting with
,
and
is considered (similarly to
Figure 1). Here, the sum-rate constraints depicted in
Figure 2 (excluding the “symmetric construction” upper bound (
14)) are plotted as a function of the system average
(see (
19) and (
23)). The tightness of the derived bounds over a wide range of
values is clearly demonstrated, as well as the superior performance of regular sparse NOMA compared to dense code-domain NOMA (which yields lower sum rates for all
values). Again, the results are in full agreement with the conclusions of
Section 4 regarding extreme-SNR regimes.




.png)
{kind=link}
{kind=link}
{kind=link}


