Abstract
The central focus of this paper is upon the alleviation of the boundary problem when the probability density function has a bounded support. Mixtures of beta densities have led to different methods of density estimation for data assumed to have compact support. Among these methods, we mention Bernstein polynomials which leads to an improvement of edge properties for the density function estimator. In this paper, we set forward a shrinkage method using the Bernstein polynomial and a finite Gaussian mixture model to construct a semi-parametric density estimator, which improves the approximation at the edges. Some asymptotic properties of the proposed approach are investigated, such as its probability convergence and its asymptotic normality. In order to evaluate the performance of the proposed estimator, a simulation study and some real data sets were carried out.
1. Introduction
Density estimation is a widely adopted tool for multiple tasks in statistical inference, machine learning, visualization and exploratory data analysis. Existing density estimation algorithms can be categorized into either parametric, semi-parametric, or non-parametric approaches. In the non-parametric framework, several methods have been set forward for the smooth estimation of density and distribution functions. The most popular one, called kernel method, was introduced by [1]. The advances were carried out by [2] to estimate a density function. The reader is recommended to consult the paper [3] for an introduction to several kernel smoothing techniques. However, kernel methods display estimation problems at the edges, when we have a random variable X with density function f supported on a compact interval. Moreover, if is a sample with the same density f, it is well known, in non-parametric kernel density estimation, that the bias of the standard kernel density estimator
is of a larger order near the boundary than that in the interior, where K is a kernel (that is, a positive function satisfying ) and () is a bandwidth (that is, a sequence of positive real numbers that goes to zero). Let us now suppose that f has two continuous derivatives everywhere and that, as , and . Let for . Near the boundary, the expression of the mean and the variance are indicated as
and
These bias phenomena are called boundary bias. Numerous authors have elaborated methods for reducing these phenomena, such as data reflection [4], boundary kernels [5,6,7], local linear estimator [8,9], use of beta and gamma kernels [10,11] and bias reduction [12,13]. For a smooth estimator of a density function f with finite known support, there have been several methods, such as Vitale’s method [14], which is based on Bernstein polynomials and expressed as
where is the empirical distribution function and is the Bernstein polynomial. This estimator was investigated in the literatures [15,16,17,18] and, more recently, by [12,19,20].
Within the parametric framework, it is noteworthy that the Gaussian mixture model can be used to estimate any density function, without any problem of estimation on the edge. This refers to the fact that the set of all normal mixture densities is dense in the set of all density functions under the metric [21]. The investigation of mixture models stands for a full field in modern statistics. It is a probabilistic model introduced by [22] to illustrate the presence of subpopulations within an overall population. It has been developed so far by various authors, such as [23]. It is used for data classification and it provides efficient approaches of model-based clustering. The authors of [24] demonstrated that, when a Gaussian mixture model is used to estimate a density non-parametrically, the density estimator that uses the Bayesian information criterion (BIC) of [25] to select the number of components in the mixture is consistent [26].
However, we obtain the non-parametric kernel estimate of a density if we fit a mixture of n components in equal proportions , where n is the size of the observed sample. As a matter of fact, it can be inferred that mixture models occupy an interesting niche between parametric and non-parametric approaches to statistical estimation.
More recently, in the parametric context, [27] proposed a parametric model using Bernstein polynomials with positive coefficients to estimate the unknown density function f; this estimator is defined as follows:
where , for , (, , ) and are the estimators of the parameters , obtained by the Expectation Maximization (EM) algorithm as follows:
with for The proposed method gives a consistent estimator in distance under some conditions.
The problem at the edge does not arise for the parametric model. For this reason, the basic idea of this work is to consider a shrinkage method using Bernstein (Vitale’s estimator) and Gaussian mixture estimators, to construct a shrinkage density estimator, in order to improve the approximation at the edge. A shrinkage estimator is a convex combination between estimators [28]. Basically, this implies that a naive or raw estimate is improved by combining it with other information.
The remainder of this paper is organized as follows: In the next section, we recall some intrinsic properties of the classical EM algorithm in the context of the Gaussian mixture parameter estimation. In Section 3, we introduce a new semi-parametric estimation approach based on the shrinkage method using Bernstein polynomials and Gaussian mixture densities. In Section 4, the consistency of the proposed estimator is exhibited, as well as its asymptotic normality.
2. Background
The Gaussian Mixture Model and Em Algorithm
Let us consider , a sequence of independent and identically distributed (i.i.d.) with common Gaussian mixture density defined by
where
satisfies
and
Finally, for each observed data point , we associate a component label vector in order to manage the data clustering. This random vector is defined such that if the considered observation is drawn form the component of the mixture and otherwise. Consequently, is distributed as a multivariate Bernoulli distribution with vector parameters as follows:
The EM algorithm is a popular tool in statistical estimation problems involving incomplete data or problems which can be posed in a similar form, such as the mixture parameters estimation [23,29]. In the EM framework, corresponds to the complete data and stand for the hidden data. Hence, the complete-data log-likelyhood is expressed by
The two steps of the EM algorithm, after l iterations, are the following:
- (i)
- E-step: The conditional expectation of the complete-data log-likelyhood given the observed data, using the current fit , is defined byThe posterior probability that belongs to the component of the mixture at the iteration, is expressed asFinally, we obtain
- (ii)
- M-step: It consists of a global maximization of with respect to .The updated estimates are stated by
We repeat these two steps until where is a fixed threshold of convergence. The convergence properties of the EM algorithm have been investigated by [29] and by [30]. Relying upon Jensen’s inequality, it can be noticed that, as increases, the log-likelihood function also increases [29]. Consequently, the EM algorithm converges within a finite iteration number and gives the parameters’ maximum likelihood estimates. Therefore, under some conditions and according to [29], we have
In what follows, .
3. Proposed Approach
The proposed semi-parametric approach rests upon the shrinkage combination between the Gaussian mixture model and the Bernstein density estimators using the EM algorithm for the parameter estimations. The literature on shrinkage estimation is enormous. From this perspective, it is noteworthy to mention the most relevant contributions. The authors of [28] were the first to introduce the classic shrinkage estimator. The authors of [31] provided theory for the analysis of risk. Oman [32,33] developed estimators which shrink Gaussian density estimators towards linear subspaces. An in-depth investigation of shrinkage theory is displayed in Chapter 5 of [34].
The proposed semi-parametric approach based upon estimating the density function f relies on the same principle of Stein’s works and there are two aspects along this line. The first setting is non-parametric in the sense that we do not assume any parametric form of the density. The non-parametric setting is very important as it allows us to perform statistical inference without making any assumption on the parametric form of the true density f. The second setting is to consider the Gaussian mixture model as a parametric estimator of the unknown density f.
In what follows, we consider a sequence of i.i.d. random variables having a common unknown density function f supported on . We here develop a shrinkage method to estimate the density function, which is divided into the following three steps:
- Step 1
- We consider the Bernstein estimator of the density function f, which is defined as
- Step 2
- Step 3
- We consider the shrinkage density estimator form defined byand we use the EM algorithm to estimate the parameter of the proposed model.
By the same way as considered in Section 2, the two steps of the EM algorithm, after t iterations, are denoted in terms of the following:
- 1.
- E-step: The conditional expectation of the complete-data log-likelihood given the observed data, using the current , is provided bywhere is a discrete random vector, following a multivariate Bernoulli distribution with vector parameters . Using Bayes’s formula, we obtain the posterior probability in the iteration denoted byand
- 2.
- M-step: It consists of a global maximization of with respect to .The updated estimate of is indicated by
The estimation of is obtained from by iterating the EM algorithm until convergence.
Therefore, the proposed estimator of the density function f is defined by
Basically, it is a shrinkage estimator that shrinks the Bernstein estimator towards the Gaussian mixture density by a specified amount of . If , the estimator reduces to the Bernstein estimator .
4. Convergence
In this section, we derive some asymptotic properties of the proposed estimator when the sample size tends to infinity. First, we assume that and K are fixed. The following proposition gives the probability convergence of the proposed estimator .
Proposition 1
(Probability convergence). If , then, for , we have
where , for and denotes the convergence in probability.
The proof of Proposition 1 necessitates the following technical Lemma.
Lemma 1.
Let be a sequence of i.i.d. random variables in the space of square integral functions with a common mean μ and let be a sequence of random variables. Hence,
where denotes the mean quadratic convergence .
The proof of this lemma is reported in [35].
Proof of Proposition 1.
First, using Lemma 1 and following the same steps as the proof of Theorem 4.4 in [35], we prove that and Then, according to Slutsky’s Theorem, we obtain
Second, based on Theorem 3.1 in [16], we obtain
In addition, referring to (18) and (19) and grounded on the application of Slutsky’s Theorem, we conclude the proof. □
According to [21], the density is a close approximation to the mixture density . Thus, the estimator provides an approximation to the true density .
To study the asymptotic normality of the estimator given by (17), we set forward the following assumptions in [36].
- (A1)
- For almost and for all , the partial derivatives , and of the density g exist and satisfy that and are bounded, respectively, by , and , where and are integrable and , satisfies
- (A2)
- The Fisher information matrix is positively defined at .
Proposition 2
(Normality asymptotic). Under the regularity conditions(A1)–(A2), if for all , and , then, we obtain
where for , and denotes the convergence in distribution.
Proof of Proposition 2.
Using Theorem 3.2 in [16], we obtain
Thus,
According to Theorem 3.1 in [36], we obtain Using the delta method, we obtain
where is the Jacobian matrix of and . Since if , then, using Slutsky’s Theorem, we conclude the proof. □
The following corollary is a consequence of the previous proposition which gives an asymptotic confidence interval of the density f, for a risk .
Corollary 1.
The asymptotic confidence interval of is given by
where is the normal quantile.
In the next section, we study the performance of the proposed estimator in estimating different distributions by comparing it to the performances of the Bernstein estimator and of the Gaussian kernel estimator.
5. Numerical Studies
5.1. Comparison Study
In this section, we investigate the performance of the proposed estimator given in (17), through estimating different densities by comparing it to the performance of the Bernstein estimator defined in (2), the standard Gaussian kernel estimator defined in (1) and the Guan’s estimator defined in (3). We apply the Bernstein estimator when the sample is concentrated on the interval . For this purpose, we need to make some suitable transformations in the different cases that are listed as follows:
- 1.
- Let us suppose that X is concentrated on a finite support ; then, we work with the sample values , where .
- 2.
- For the density functions concentrated on , we can use the transformed sample , which transforms the range to the interval .
- 3.
- For the support , we can use the transformed sample , which transforms the range to the interval .
If the support is infinite, say, , we can consider as the finite support of f, where and are the minimum and the maximum order, respectively. We choose a and b such that and are of , , and , where F is the distribution function [27]. Then, we can use the transformed sample, which transforms to the interval mentioned in the case 1.
In the simulation study, three sample sizes were considered, , , and , as well as the following density functions:
- (a)
- The beta mixture density ;
- (b)
- The beta mixture density ;
- (c)
- The normal mixture density ;
- (d)
- The chi-squared density.
- (e)
- The gamma mixture density ;
- (f)
- The gamma mixture density .
Our sample was decomposed into a learning sample of a size of 2/3 of the considered sample, on which the various statistical methods were constructed, and a second sample of a size of 1/3 of the considered sample, on which the predictive performance of the three methods were tested. For each density function f and sample size n, we computed the integrated squared error (), the integrated absolute error () and the Kullback–Leibler divergence () of the estimator over trials.
where is the estimator computed from the sample and
Indeed, it is advised to consider a learning sample bigger than a testing sample. In this work, our sample was decomposed into a learning sample of a size of 2/3 of the considered sample, on which the various statistical methods were constructed, and a second sample of a size of 1/3 of the considered sample, on which the predictive performances of the three methods were tested. Each run of the proposed estimator performed the following steps:
- -
- We first generated a random sample of size n from the models’ density .
- -
- We then split the generated data into a training set of a size of of the considered sample and a test set of a size of of the considered sample.
- -
- We applied the proposed estimator, using the observed data only from the training set, in order to estimate the density function.
- -
- The test set was then used to compute the estimation errors , and .
To select the optimal parameter K, we used the Gap Statistics algorithm [37]. We considered a Monte Carlo experiment to select the optimal choice of the degree m of the Bernstein polynomial and the bandwidth h of the kernel estimator, for each point . We determined the parameters m (for ) and h (for with ), which minimized the , which was approximated by the .
We considered random samples of sizes , and .

Table 1.
Average for trials of Bernstein estimator, standard Gaussian kernel estimator and the proposed estimator , for , and . The bold values indicate the smallest values of .
Table 2.
Average for trials of Bernstein estimator, standard Gaussian kernel estimator and the proposed estimator , for , and . The bold values indicate the smallest values of .
Table 3.
Average for trials of Bernstein estimator, standard Gaussian kernel estimator and the proposed estimator , for , and . The bold values indicate the smallest values of .
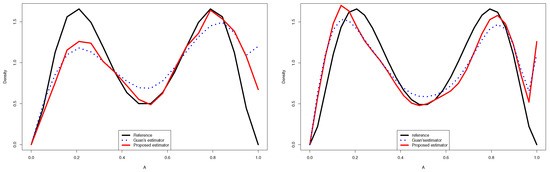
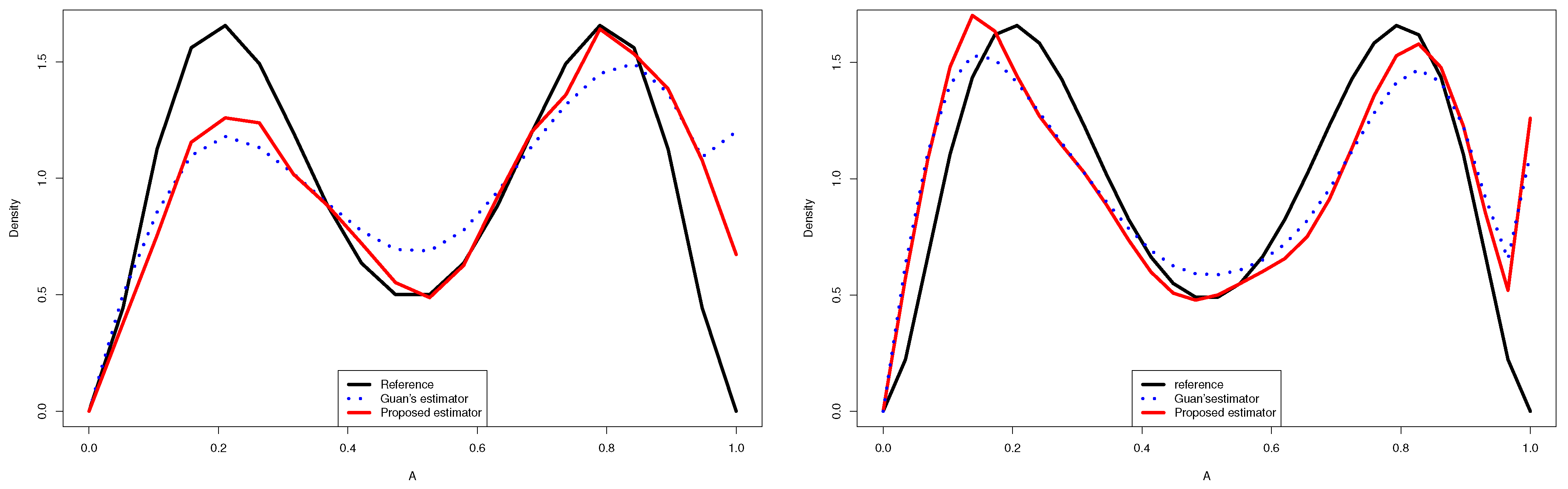
Figure 1.
Quantitative comparison between the proposed estimator and Guan’s estimator of for (left) and (right).
- -
- -
- Using the proposed estimator, we obtained better results than those given by the other estimators in a large part of the cases.
- -
- The Figure 2 and 3 give a better sense of where the error is located.
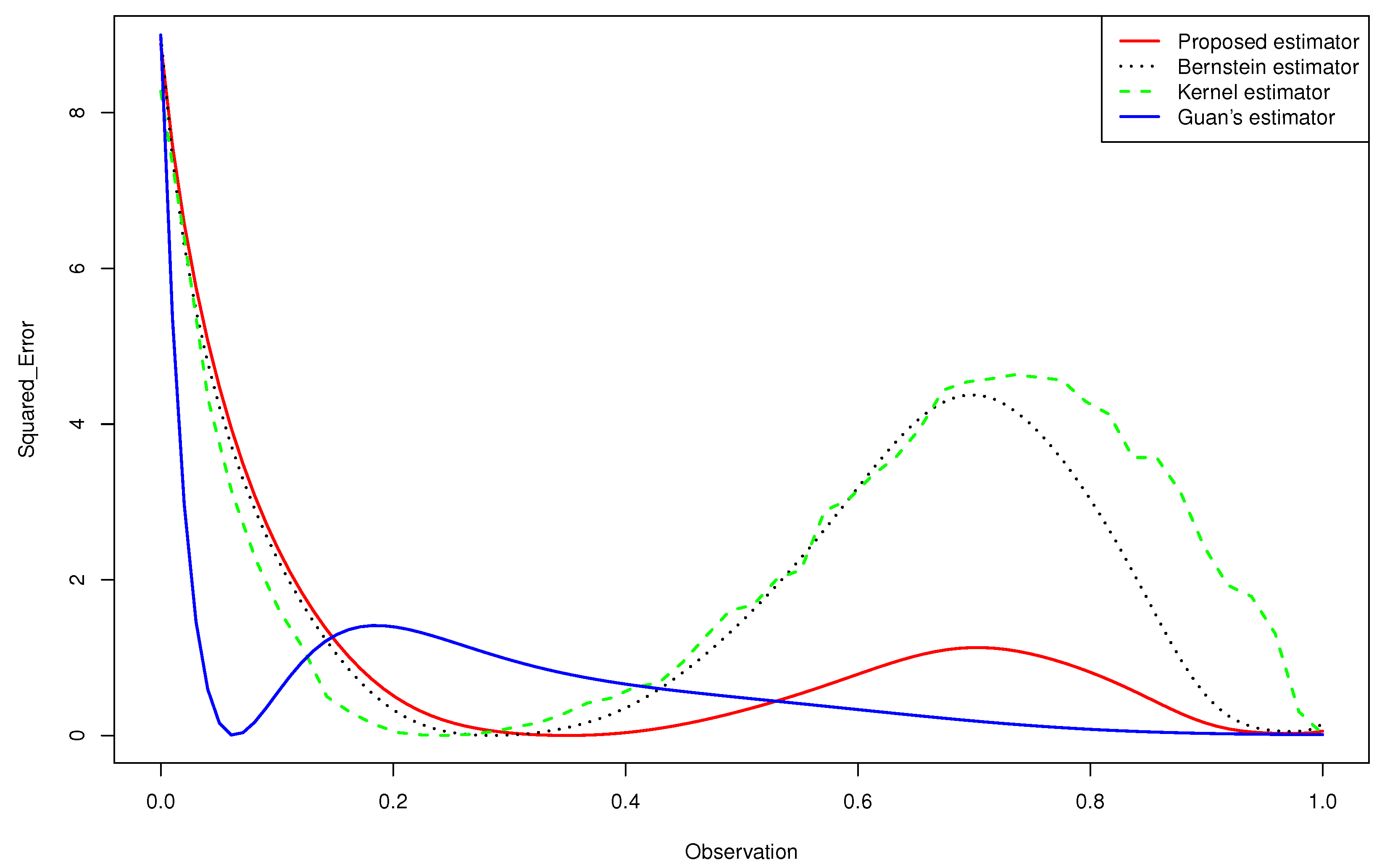
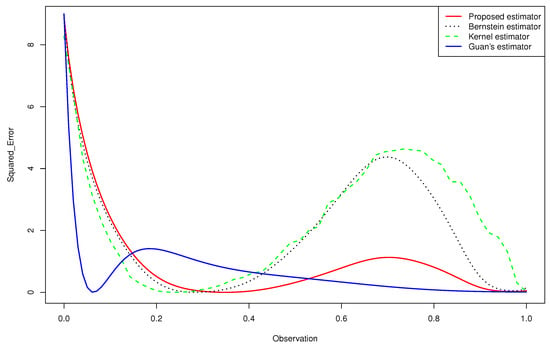 Figure 2. Quantitative comparison among the mean squared error of the kernel estimator, the Bernstein estimator, the Guan’s estimator and the proposed estimator of for .
Figure 2. Quantitative comparison among the mean squared error of the kernel estimator, the Bernstein estimator, the Guan’s estimator and the proposed estimator of for . - -
- For the case (e) of the gamma mixture, the average and of Guan’s estimator (1.3) were smaller than those obtained by the proposed density estimator (3.4) and the Bernstein estimator (1.2). However, in all the other cases, using an appropriate choice of the degree m, the average and of the proposed density estimator (3.4) were smaller than what achieved by the kernel estimator (1.1), the Bernstein estimator (1.2) and Guan’s estimator (1.3), even when the sample size was large for same cases.
- -
- When we changed the parameters of the gamma mixture density in the sense that we had a smaller bias, our estimator was more competitive than the other approaches and we obtained better results.
- -
- -
- In the considered distribution , by choosing the appropriate m, the curve of the proposed distribution estimator (3.4) was closer to the true distribution than that of Guan’s estimator (1.3), even when the sample size was very large.
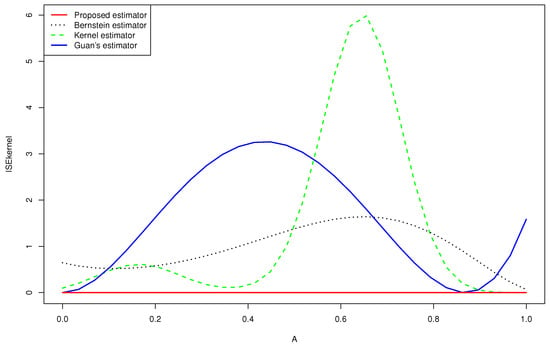
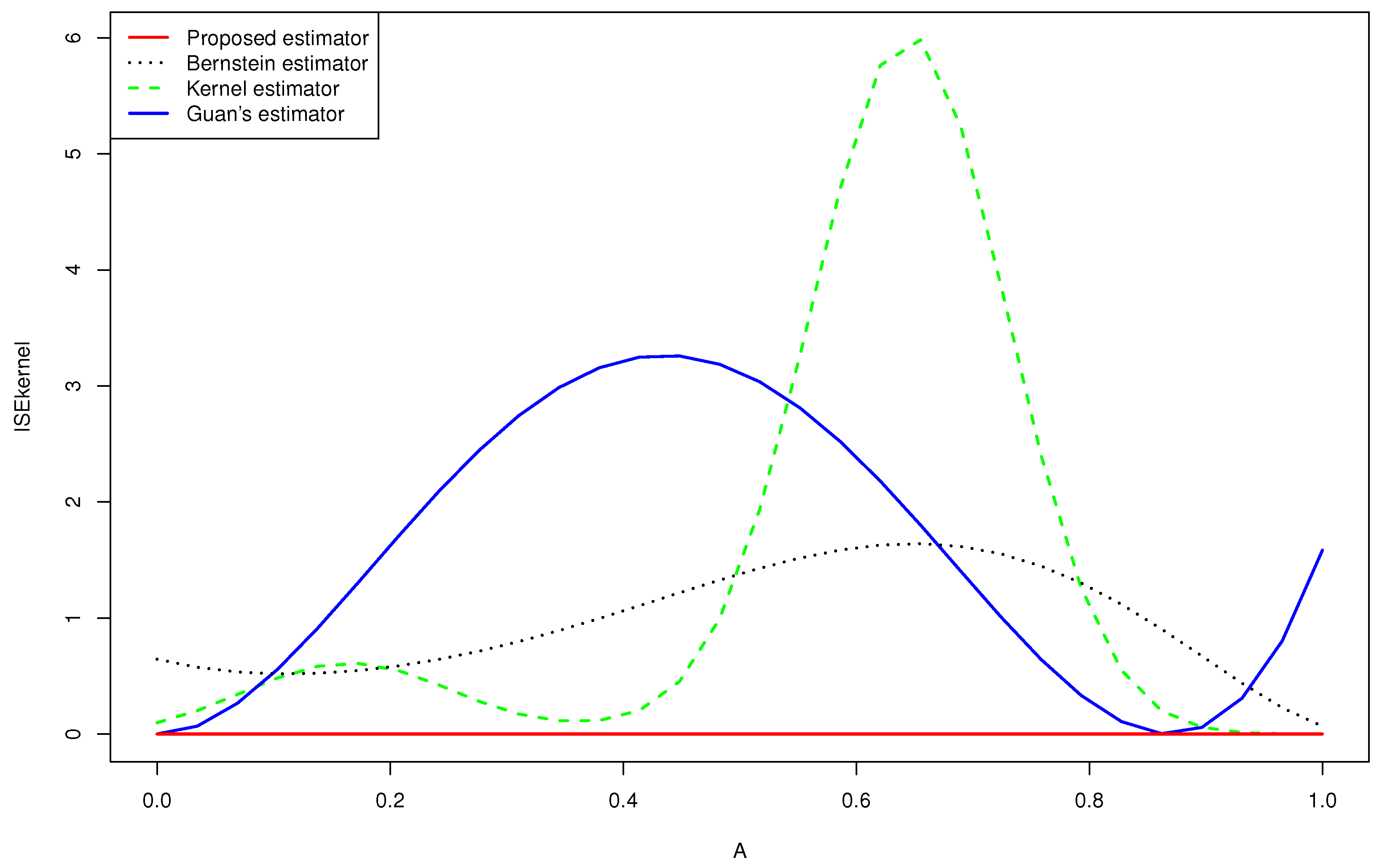
Figure 3.
Quantitative comparison among the mean squared error of the kernel estimator, the Bernstein estimator, the Guan’s estimator and the proposed estimator of for .
- -
- None of the estimators for the gamma mixture density had good approximations near . However, the of the proposed estimator was closer to zero than that of the Bernstein estimator and the kernel estimator, especially near the edge .
- -
- Guan’s estimator and the kernel estimator for the normal mixture density had good approximations near . However, the of the proposed estimator was closer to zero than that of the other estimators, especially near the two edges.
Therefore, we note that, for difficult distributions that diverge at the boundaries, the proposed method would fail, but not as badly as the standard methods without shrinkage. In addition, the performed simulations revealed that, on average, the proposed approach could lead to satisfactory estimates near the boundaries, better than the classical Bernstein estimator.
5.2. Real Dataset
5.2.1. COVID-19 Data
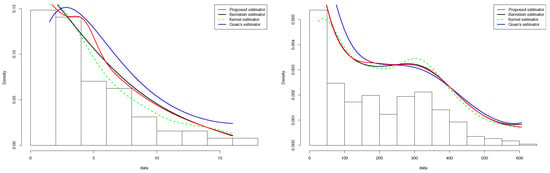
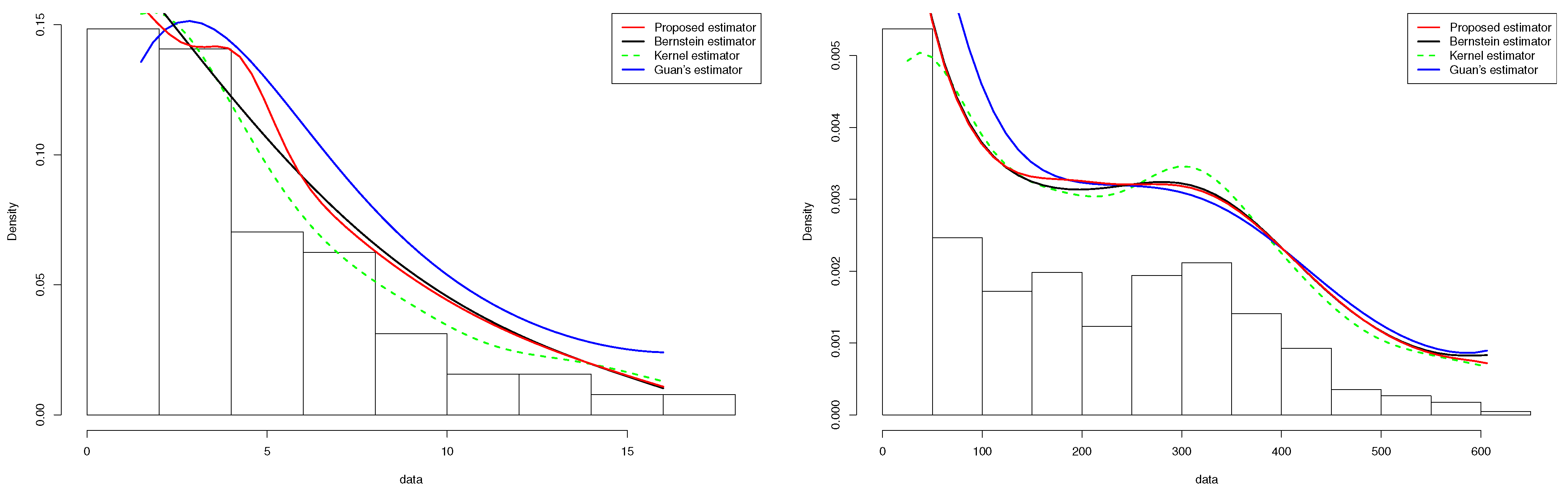
In this subsection, we consider the COVID-19 data displayed in the INED website https://dc-covid.site.ined.fr/fr/donnees/france/ (accessed on 16 February 2022). These data concern the numbers of deaths due to COVID-19 in France (daily) from 21 March 2021, for 454 days. These data are such that and . Then, it is convenient to assume that the density of the numbers of deaths is defined on the interval and transform the data into the interval unit. The Monte Carlo procedure was performed and resulted in for the standard kernel estimator defined in (1.1), for the Bernstein estimator defined in (1.2), the proposed estimator, and for Guan’s estimator. These estimators are exhibited in Figure 1 (right panel) along with a histogram of the data. All the estimators are smooth and seem to capture the pattern highlighted by the histogram. We record that the proposed estimator outperformed the other estimators near the boundaries.
5.2.2. Tuna Data
The last example concerns the tuna data reported in [38]. The data are derived from an aerial line transect survey of Southern Bluefin Tuna in the Great Australian Bight. An aircraft with two spotters on board flew randomly over allocated line transects. These data correspond to the perpendicular sighting distances (in miles) of 64 detected tuna schools to the transect lines. The survey was conducted in summer when tuna data tend to stay on the surface. The data are such that and . The Monte Carlo procedure was performed and resulted in for the standard kernel estimator defined in (1), for the Bernstein estimator defined in (2) and the proposed estimator, and for Guan’s estimator. These estimators are illustrated in Figure 4 (left panel) along with a histogram of the data. All the estimators are smooth and seem to capture the pattern highlighted by the histogram. We assert that the proposed estimator outperformed the other estimator, especially near the boundaries.
6. Conclusions
In this paper, we propose a shrinkage estimator of a density function based on the Bernstein density estimator and using a finite Gaussian mixture density. This method rests on three steps. The first step consists of considering the Bernstein estimator . The second relies upon the Gaussian Mixture density as an estimator of the unknown density f. The last step consists of considering the shrinkage form and EM algorithm in order to estimate the parameter . The asymptotic properties of this estimator were established. Afterwards, we demonstrate the effectiveness of the proposed method using some simulated and real data. We clarify how it can lead to very satisfactory estimates near the boundaries and in terms of , and . Eventually, we would simply assert that our research work is a step that may be taken further, extended and built upon as it lays the ground and paves the way for future works to elaborate a semi-parametric regression estimator using the shrinkage method. We also plan to work on the case where is a random variable. Another future research direction would be to extend our findings to the setting of serially dependent observations.
Author Contributions
Conceptualization, A.M. and Y.S.; Data curation, S.H.; Investigation, S.H. and Y.S.; Methodology, S.H., A.M. and Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research study received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Härdle, W. Smoothing Techniques with Implementation in S; S. Springer Science and Business Media: Berlin, Germany, 1991. [Google Scholar]
- Schuster, E.F. Incorporating support constraints into nonparametric estimators of densities. Comm. Stat. Theory Methods 1985, 14, 1123–1136. [Google Scholar] [CrossRef]
- Müller, H.-G. Smooth optimum kernel estimators near endpoints. Biometrika 1991, 78, 521–530. [Google Scholar] [CrossRef]
- Müller, H.-G. On the boundary kernel method for nonparametric curve estimation near endpoints. Scand. J. Statist. 1993, 20, 313–328. [Google Scholar]
- Müller, H.-G.; Wang, J.-L. Hazard rate estimation under random censoring with varying kernels and bandwidths. Biometrika 1994, 50, 61–76. [Google Scholar] [CrossRef]
- Lejeune, M.; Sarda, P. Smooth estimators of distribution and density functions. Comput. Stat. Data Anal. 1992, 14, 457–471. [Google Scholar] [CrossRef]
- Jones, M.C. Simple boundary correction for density estimation kernel. Stat. Comput. 1993, 13, 135–146. [Google Scholar] [CrossRef]
- Chen, S.X. Beta kernel estimators for density functions. Comput. Stat. Data Anal. 1999, 31, 131–145. [Google Scholar] [CrossRef]
- Chen, S.X. Probability density function estimation using gamma kernels. Ann. Inst. Stat. Math. 2000, 52, 471–480. [Google Scholar] [CrossRef]
- Leblanc, A. A bias-reduced approach to density estimation using Bernstein polynomials. J. Nonparametr. Stat. 2010, 22, 459–475. [Google Scholar] [CrossRef]
- Slaoui, Y. Bias reduction in kernel density estimation. J. Nonparametr. Stat. 2018, 30, 505–522. [Google Scholar] [CrossRef]
- Vitale, R.A. A bernstein polynomial approach to density function estimation. Stat. Inference Relat. Topics 1975, 2, 87–99. [Google Scholar]
- Ghosal, S. Convergence rates for density estimation with Bernstein polynomials. Ann. Stat. 2000, 29, 1264–1280. [Google Scholar] [CrossRef]
- Babu, G.J.; Canty, A.J.; Chaubey, Y.P. Application of Bernstein polynomials for smooth estimation of a distribution and density function. J. Stat. Plan. Inference 2002, 105, 377–392. [Google Scholar] [CrossRef]
- Kakizawa, Y. Bernstein polynomial probability density estimation. J. Nonparametr. Stat. 2004, 16, 709–729. [Google Scholar] [CrossRef]
- Rao, B.L.S.P. Estimation of distribution and density functions by generalized Bernstein polynomials. Indian J. Pure Appl. Math. 2005, 36, 63–88. [Google Scholar]
- Igarashi, G.; Kakizawa, Y. On improving convergence rate of Bernstein polynomial density estimator. J. Nonparametr. Stat. 2014, 26, 61–84. [Google Scholar] [CrossRef]
- Slaoui, Y.; Jmaei, A. Recursive density estimators based on Robbins-Monro’s scheme and using Bernstein polynomials. Stat. Interface 2019, 12, 439–455. [Google Scholar] [CrossRef] [Green Version]
- Li, J.Q.; Barron, A.R. Mixture density estimation. Adv. Neural Inf. Process. Syst. 2000, 12, 279–285. [Google Scholar]
- Pearson, K. Contributions to the mathematical theory of evolution. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1984, 185, 71–110. [Google Scholar]
- McLachlan, G.; Peel, D. Finite Mixture Models; John Wiley and Sons: New York, NY, USA, 2004. [Google Scholar]
- Roeder, K.; Wasserman, L. Practical Bayesian density estimation using mixtures of normals. J. Am. Stat. Assoc. 1997, 92, 894–902. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Leroux, B. Consistent estimation of a mixing distribution. Ann. Stat. 1992, 20, 1350–1360. [Google Scholar] [CrossRef]
- Guan, Z. Efficient and robust density estimation using Bernstein type polynomials. J. Nonparametr. Stat. 2016, 28, 250–271. [Google Scholar] [CrossRef] [Green Version]
- James, W.; Stein, C. Estimation with quadratic loss. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 443–460. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Stat. Methodol. 1997, 39, 1–22. [Google Scholar]
- Wu, C.J. On the convergence properties of the EM algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Stein, C. Estimation of the mean of a multivariate normal distribution. Ann. Stat. 1981, 9, 1135–1151. [Google Scholar] [CrossRef]
- Oman, S.D. Contracting towards subspaces when estimating the mean of a multivariate normal distribution. J. Multivar. Anal. 1982, 12, 270–290. [Google Scholar] [CrossRef] [Green Version]
- Oman, S.D. Shrinking towards subspaces in multiple linear regression. Technometrics 1982, 24, 307–311. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Zitouni, M.; Zribi, M.; Masmoudi, A. Asymptotic properties of the estimator for a finite mixture of exponential dispersion models. Filomat 2018, 32, 6575–6598. [Google Scholar] [CrossRef] [Green Version]
- Redner, R.A.; Walker, H.F. Mixture densities, maximum likelihood and the EM algorithm. SIAM Rev. 1984, 26, 195–239. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Chen, S.X. Empirical likelihood confidence intervals for nonparametric density estimation. Biometrika 1996, 83, 329–341. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).