
Probability Distribution on Full Rooted Trees



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Review of Literature and Motivation
1.2. The Objective of This Study
1.3. Organization of This Paper
2. Notations Used for Full Rooted Trees
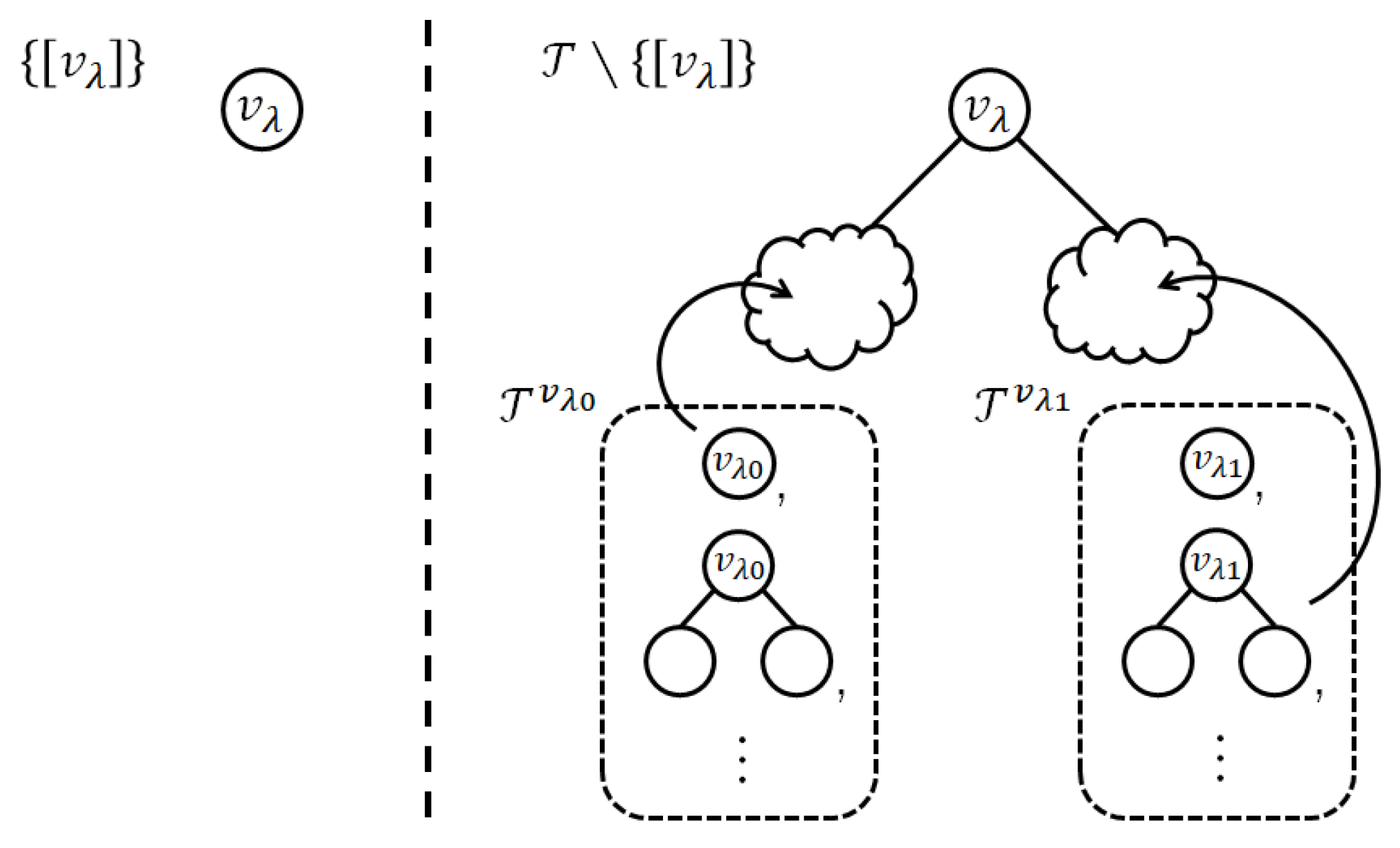
3. Definition of Probability Distribution on Full Rooted Subtrees
4. Properties of Probability Distribution on Full Rooted Subtrees
4.1. Probability of Events on Nodes
4.2. Mode
4.3. Expectation
4.4. Shannon Entropy
4.5. Conjugate Prior for a Probability Distribution on Full Rooted Subtrees
4.6. Probability Distribution on a Full Rooted Tree as a Conjugate Prior
5. Discussion
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B. Pseudocode to Calculate Mode
| Algorithm A1 Calculation of mode. |
|
References
- Willems, F.M.J.; Shtarkov, Y.M.; Tjalkens, T.J. The context-tree weighting method: Basic properties. IEEE Trans. Inf. Theory 1995, 41, 653–664. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Matsushima, T.; Inazumi, H.; Hirasawa, S. A class of distortionless codes designed by Bayes decision theory. IEEE Trans. Inf. Theory 1991, 37, 1288–1293. [Google Scholar] [CrossRef]
- Matsushima, T.; Hirasawa, S. A Bayes coding algorithm using context tree. In Proceedings of the 1994 IEEE International Symposium on Information Theory, Trondheim, Norway, 27 June–1 July 1994; p. 386. [Google Scholar] [CrossRef]
- Matsushima, T.; Hirasawa, S. Reducing the space complexity of a Bayes coding algorithm using an expanded context tree. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 719–723. [Google Scholar] [CrossRef]
- Papageorgiou, I.; Kontoyiannis, I.; Mertzanis, L.; Panotopoulou, A.; Skoularidou, M. Revisiting Context-Tree Weighting for Bayesian Inference. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 2906–2911. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Mertzanis, L.; Panotopoulou, A.; Papageorgiou, I.; Skoularidou, M. Bayesian Context Trees: Modelling and exact inference for discrete time series. arXiv 2020, arXiv:stat.ME/2007.14900. [Google Scholar]
- Nakahara, Y.; Matsushima, T. A Stochastic Model for Block Segmentation of Images Based on the Quadtree and the Bayes Code for It. Entropy 2021, 23, 991. [Google Scholar] [CrossRef] [PubMed]
- Dobashi, N.; Saito, S.; Nakahara, Y.; Matsushima, T. Meta-Tree Random Forest: Probabilistic Data-Generative Model and Bayes Optimal Prediction. Entropy 2021, 23, 768. [Google Scholar] [CrossRef] [PubMed]
- Kenneth, R. Discrete Mathematics and Its Applications, 7th ed.; McGraw-Hill Science: New York, NY, USA, 2011. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley & Sons, Inc.: New York, NY, USA, 2006. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakahara, Y.; Saito, S.; Kamatsuka, A.; Matsushima, T. Probability Distribution on Full Rooted Trees. Entropy 2022, 24, 328. https://doi.org/10.3390/e24030328
Nakahara Y, Saito S, Kamatsuka A, Matsushima T. Probability Distribution on Full Rooted Trees. Entropy. 2022; 24(3):328. https://doi.org/10.3390/e24030328
Chicago/Turabian StyleNakahara, Yuta, Shota Saito, Akira Kamatsuka, and Toshiyasu Matsushima. 2022. "Probability Distribution on Full Rooted Trees" Entropy 24, no. 3: 328. https://doi.org/10.3390/e24030328
APA StyleNakahara, Y., Saito, S., Kamatsuka, A., & Matsushima, T. (2022). Probability Distribution on Full Rooted Trees. Entropy, 24(3), 328. https://doi.org/10.3390/e24030328