
A Variational Bayesian Deep Network with Data Self-Screening Layer for Massive Time-Series Data Forecasting





Abstract
:1. Introduction
- (1)
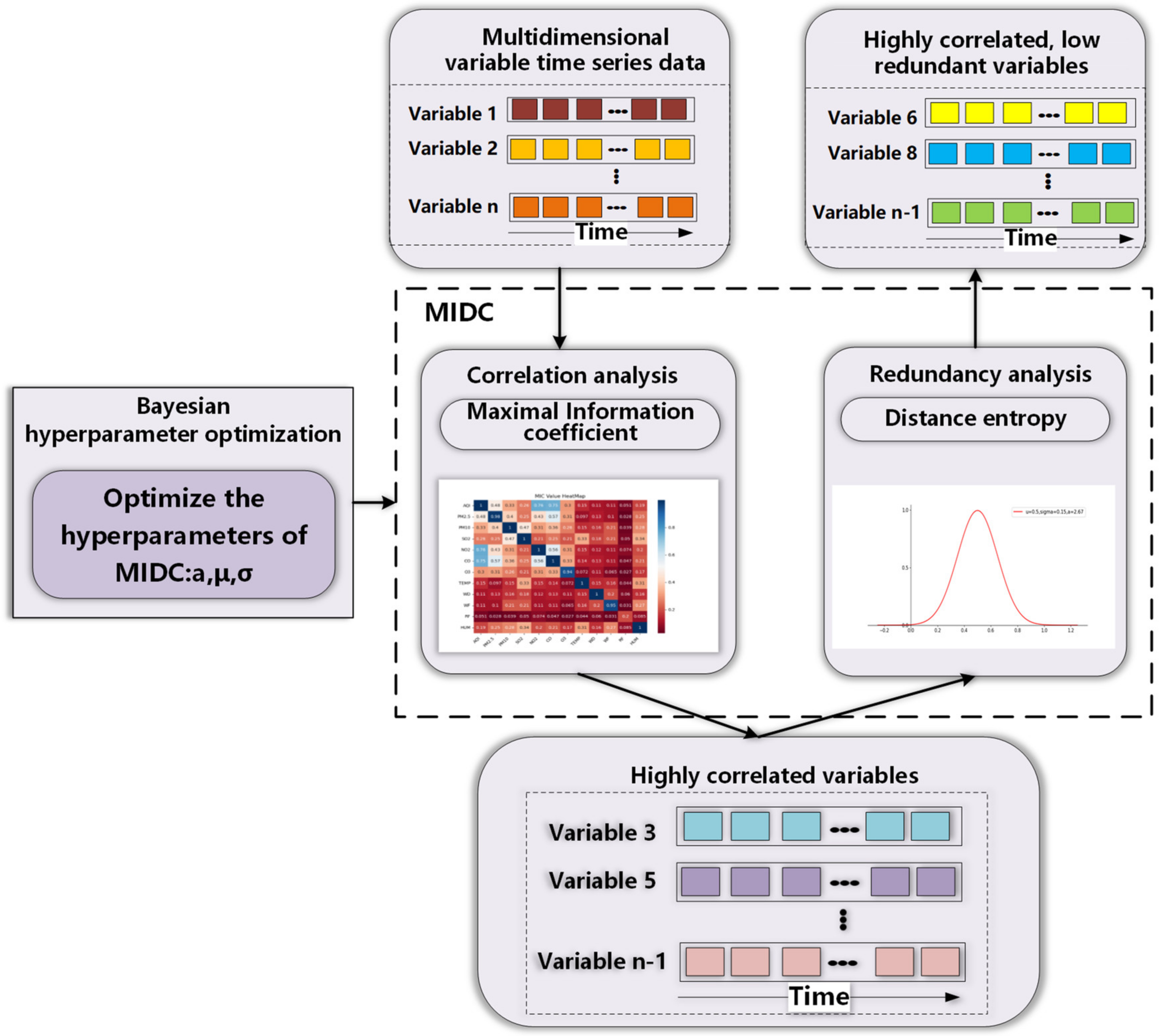
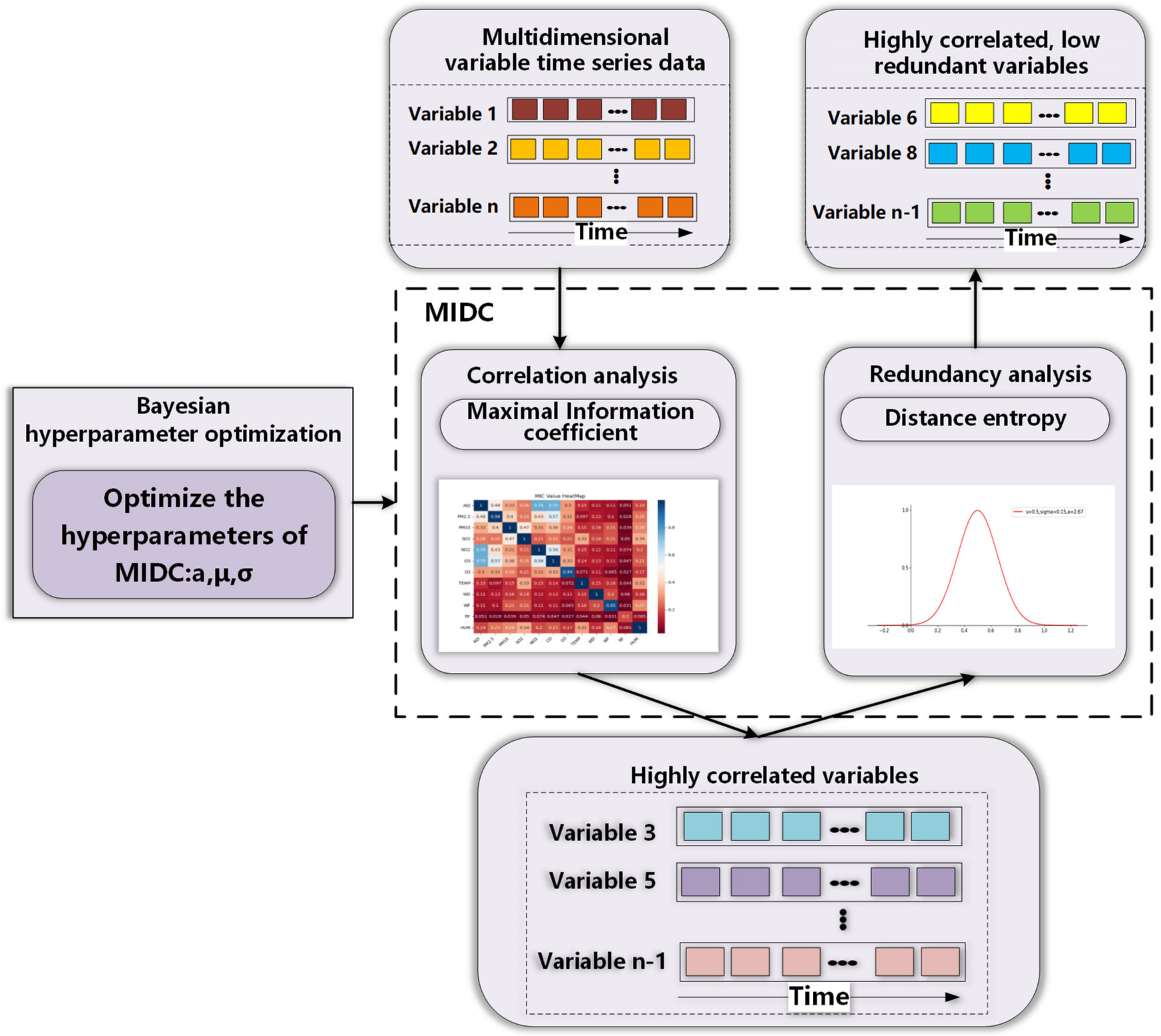
- The prediction network is constructed with the data self-screening layer. A maximal information distance coefficient (MIDC) with Bayesian hyperparameter optimization is designed to mine the correlation and redundancy of input data simultaneously, effectively extracting useful input information for deep learning networks and eliminating redundancy.
- (2)
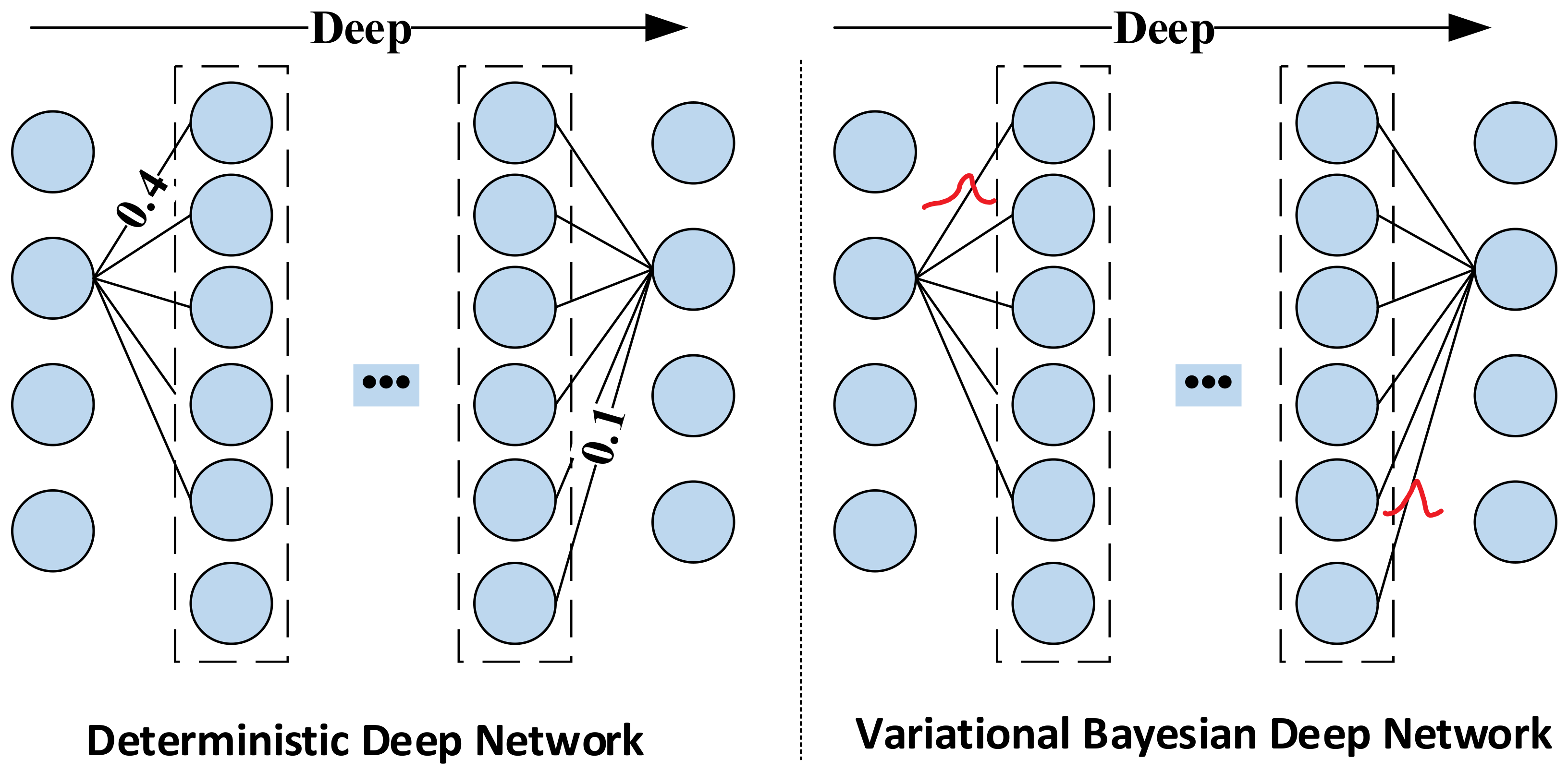
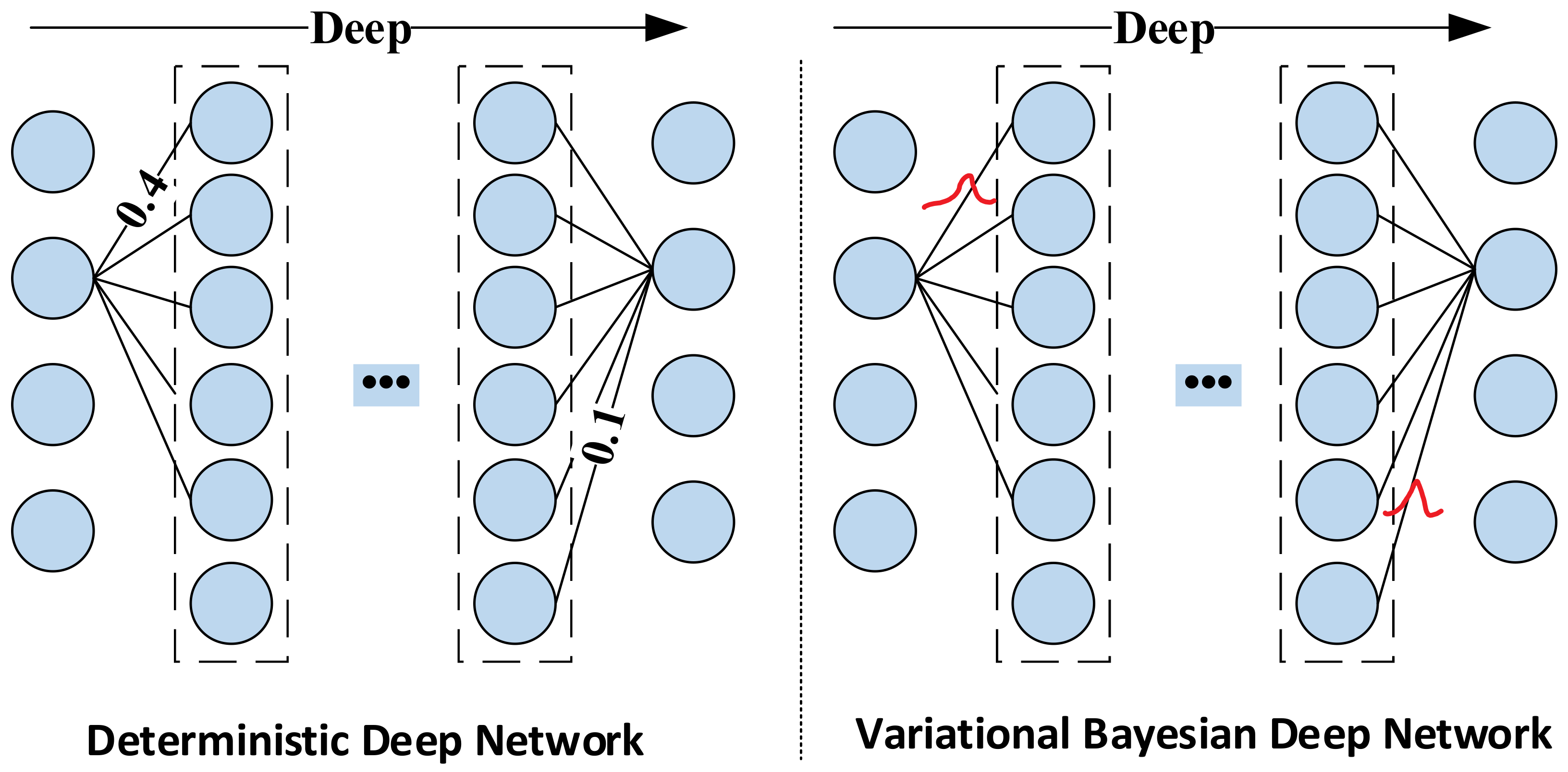
- The variational inference structure is introduced into the gated recurrent unit (GRU) to achieve a Gaussian distribution for the networks’ weights and biases, which can enhance the anti-noise ability of the network and effectively improve forecasting accuracy and generalization performance.
2. Related Work
- (1)
- The data redundancy, conflict, and inconsistency will reduce the learning effect and forecasting accuracy. Therefore, we cannot blindly use big data as the network’s input data. It is necessary to analyze their relationship and select the correct data to improve model training performances.
- (2)
- The noise and uncertainty introduced in the process of sensor measurement will cause the classical neural network to overfit during the training process, which will reduce the forecasting performance. The deep learning network operation mechanism must be reformed to make it applicable and robust to noise and improve the anti-noise ability of the network.
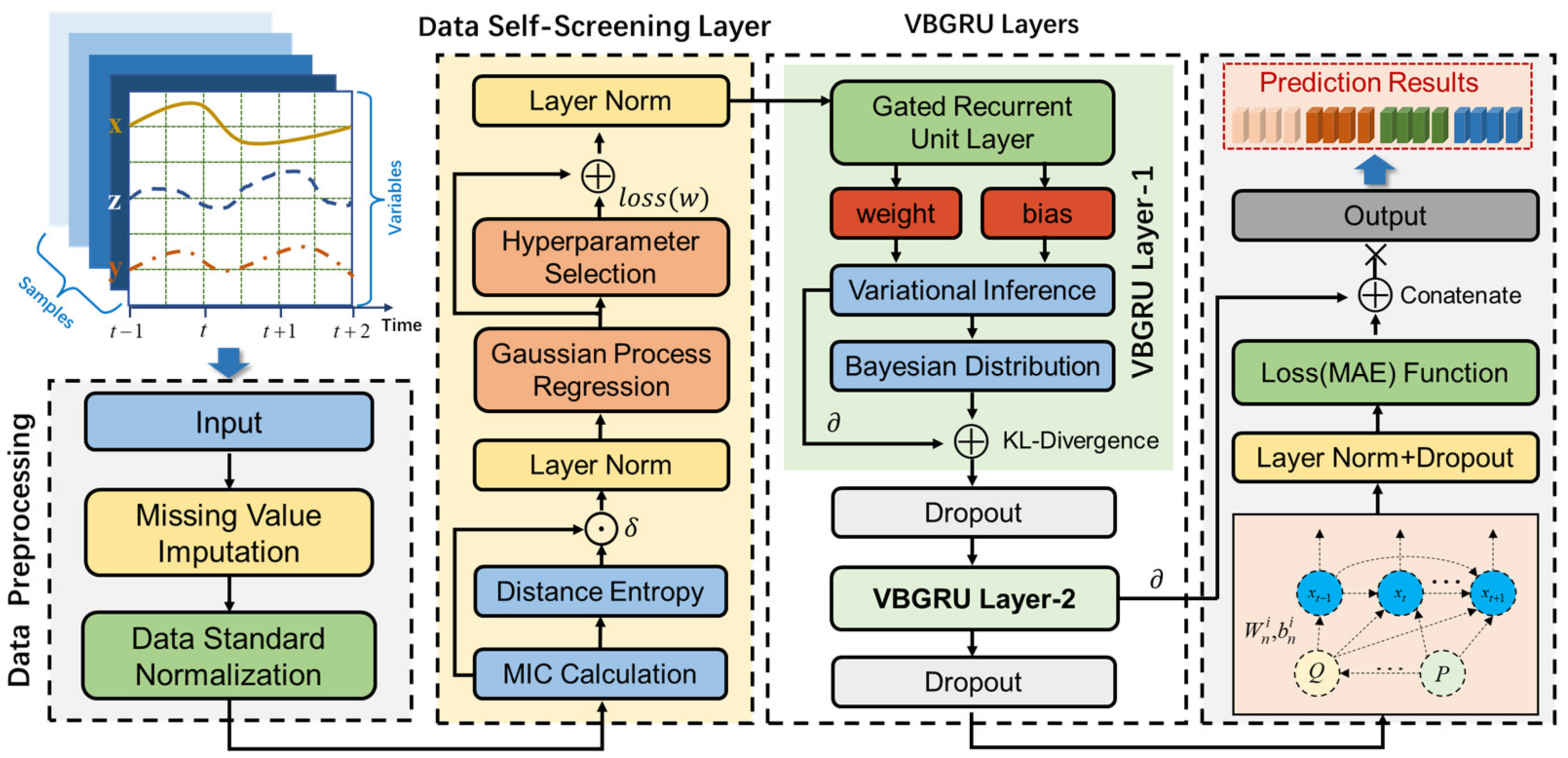
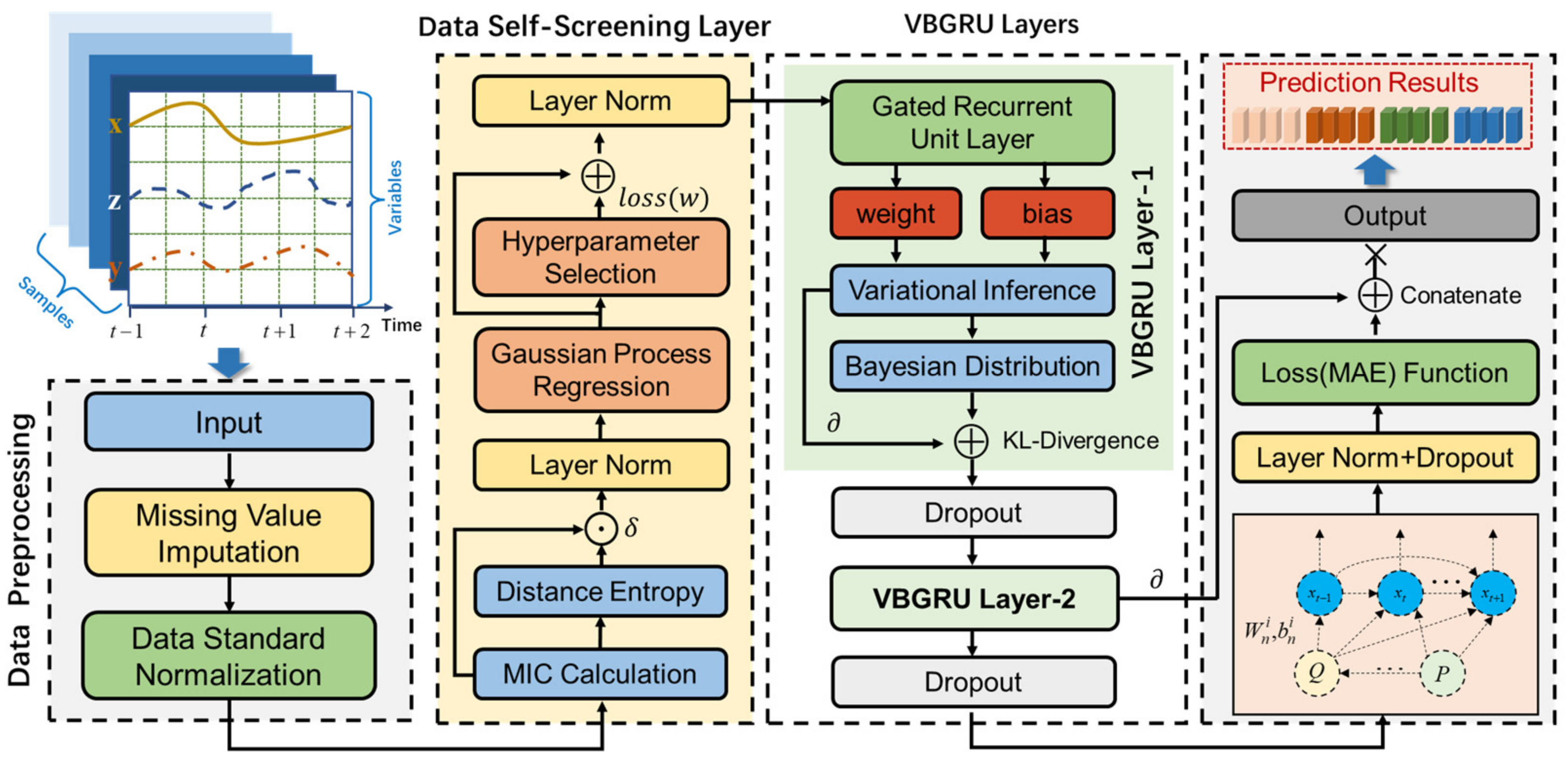
3. Data Self-Screening-Variational Bayesian GRU Model
- (1)
- Collect time-series data of multidimensional variables and fill in missing values for the collected data.
- (2)
- Input the processed time-series data into DSSL, which mainly screens variables with high correlation and low redundancy with the target variable and adaptively changes the relevant parameters of the data self-screening layer according to the different input data, then normalize the parameters by layer norm to enhance the suitability of the network.
- (3)
- Input the variables selected by DSSL and target variables into the VBGRU network model for training; then, the dropout layer is used to randomly discard some neural network units to improve the robustness of the model, and finally obtain the prediction results of the target variables.
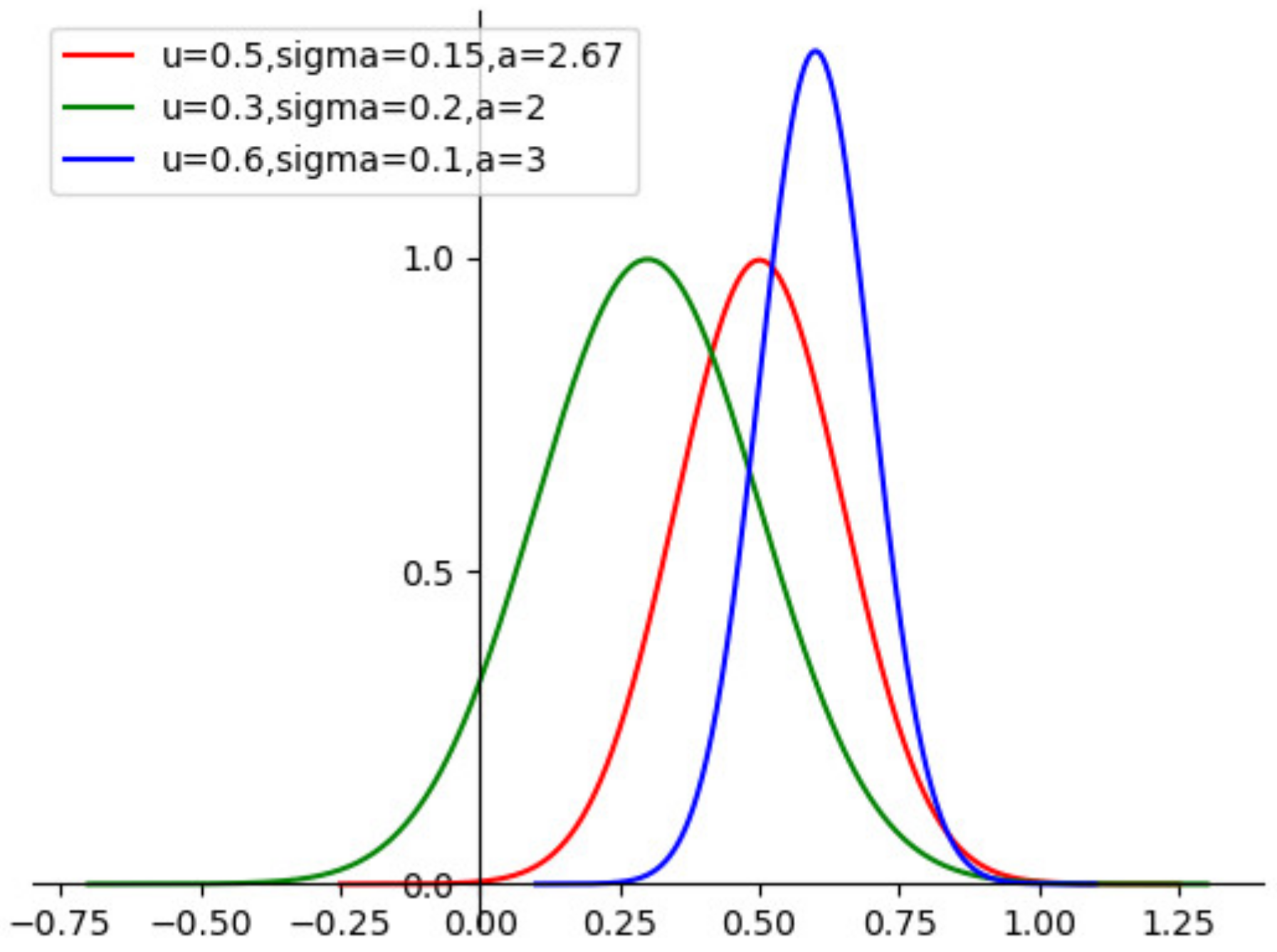
3.1. Data Self-Screening Layer
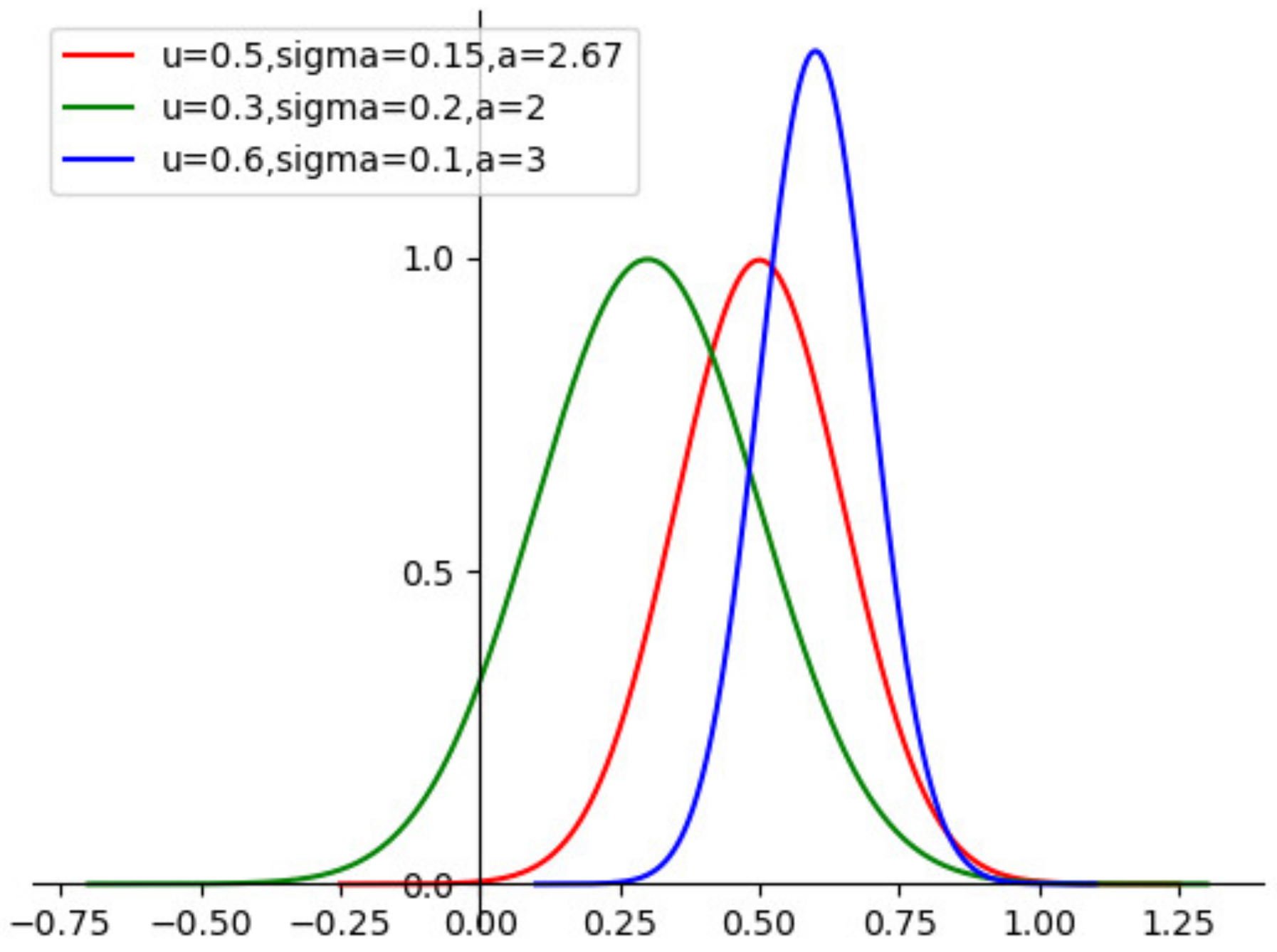
| Algorithm 1: Bayesian Hyperparameter Optimization |
| Input: |
| Initial observation set |
| Bounds for the search space |
| Output: |
| for t do |
| Fit the current data sample to get the GPR model |
| Solve the extreme points of the objective function : |
| Obtain new samples |
| Update data sample . |
| Update data self-screening layer parameters |
| end for |
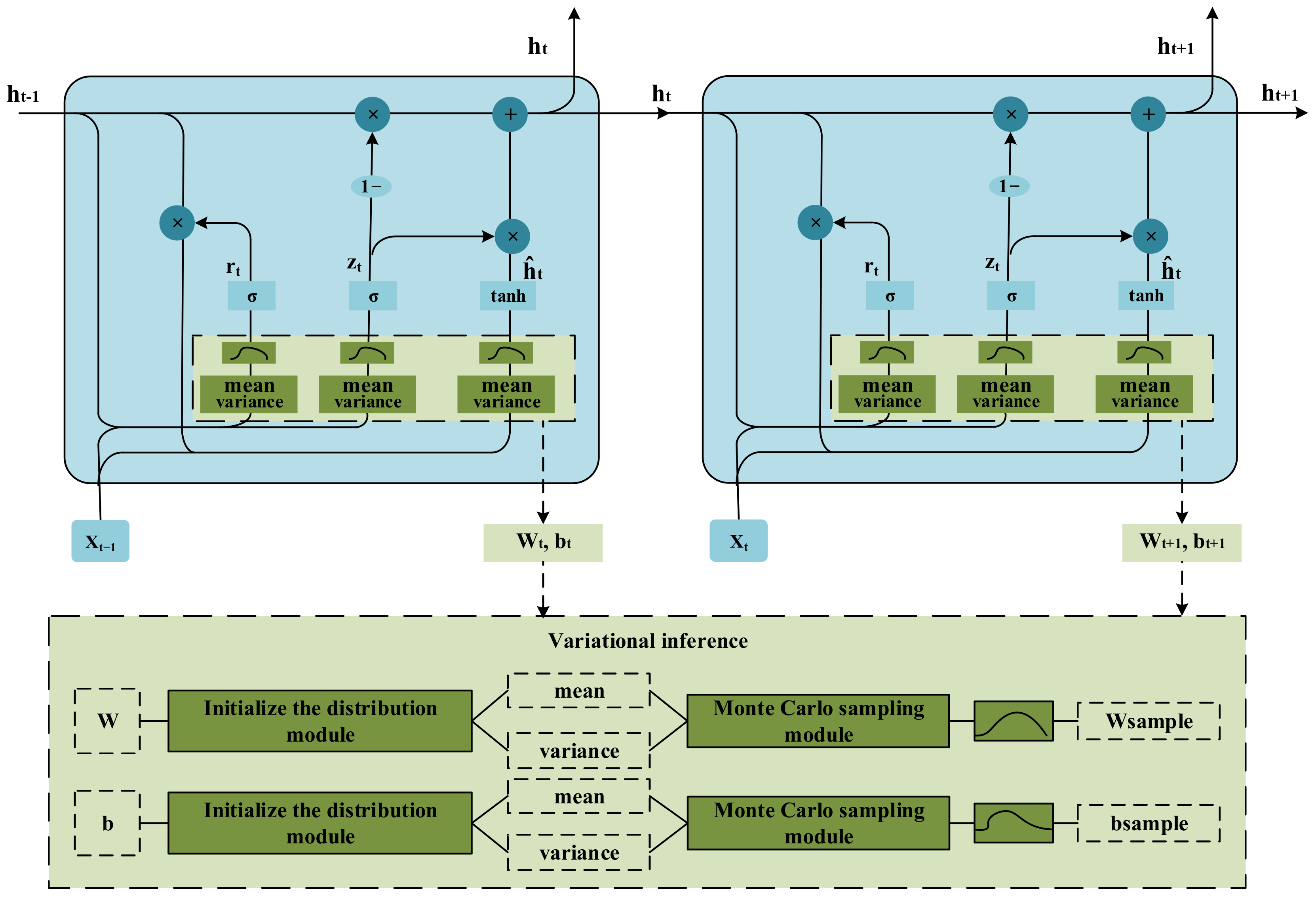
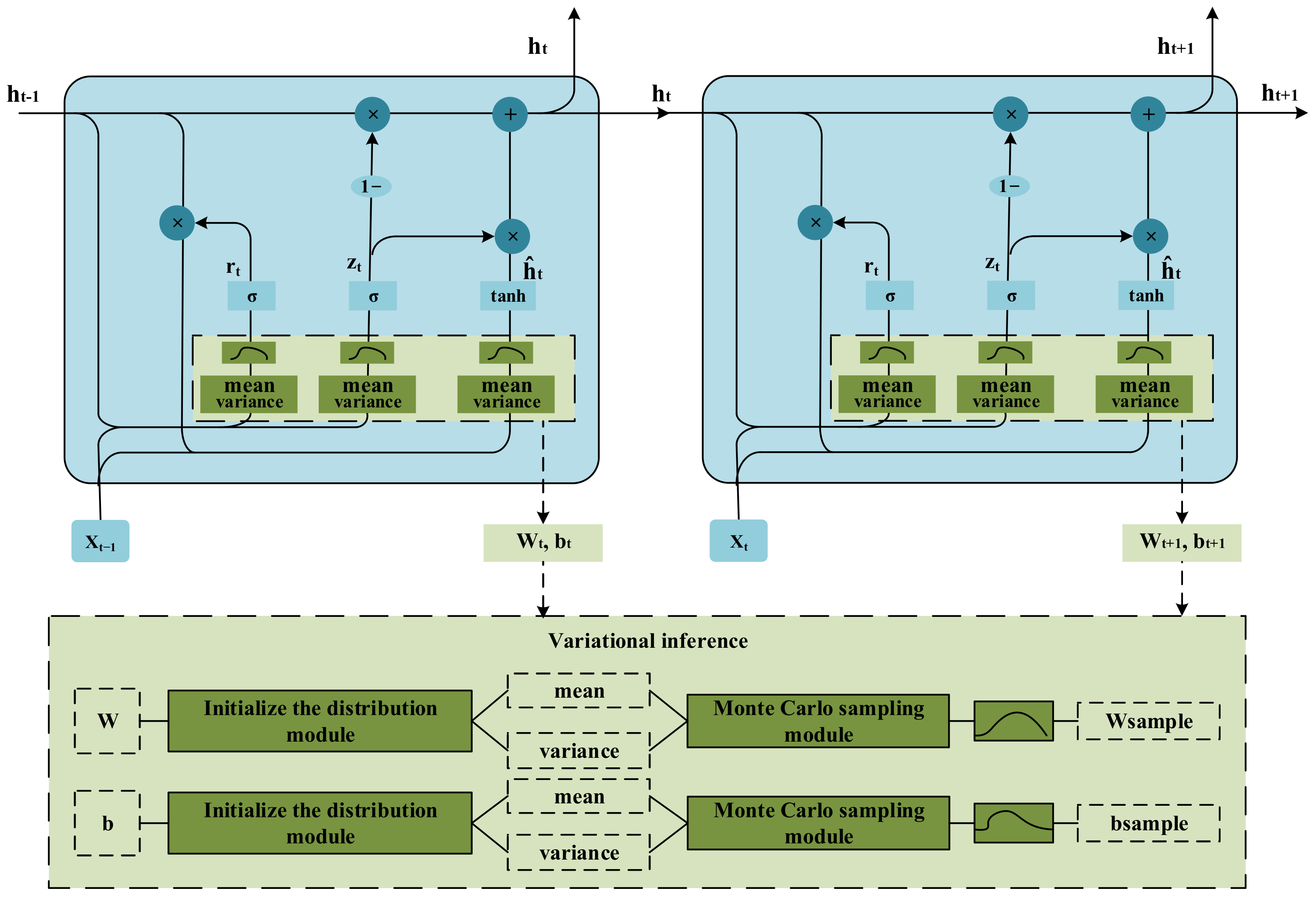
3.2. Variational Bayesian GRU
- (1)
- VBGRU initialization: set initialization weight distribution , bias distribution . Setting parameters , The weight , and bias after sampling are obtained by Monte Carlo sampling;
- (2)
- Given a total of samples for each batch: . Among them represents the network input data, represents the expected output of the network, the network output is ;
- (3)
- Use variational inference to sample the network weights and biases times and calculate the average loss:
- (4)
- Use Adam optimizer according to to update the weight and bias parameters: ;
- (5)
- Repeat the second to fourth steps of network convergence, that is, no longer drops;
- (6)
- Use the test set to evaluate the trained network model.
4. Experiment and Analysis
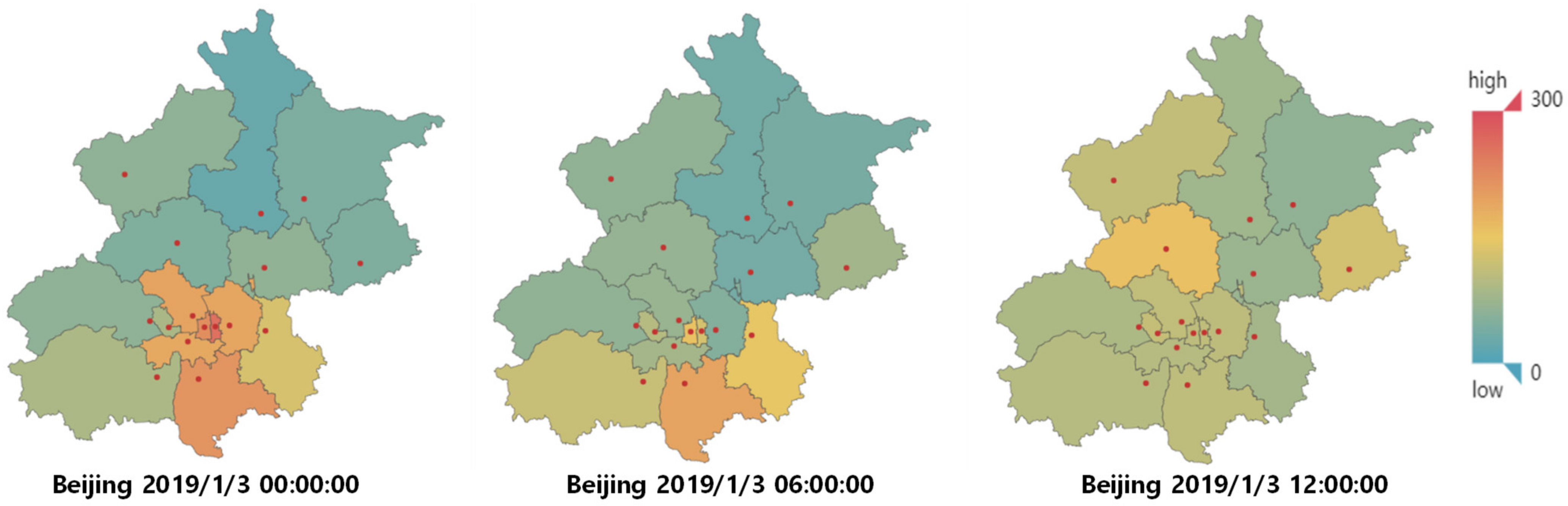
4.1. Data Set Description and Preprocessing
4.2. Experiment Establishment and Evaluation Function
- (1)
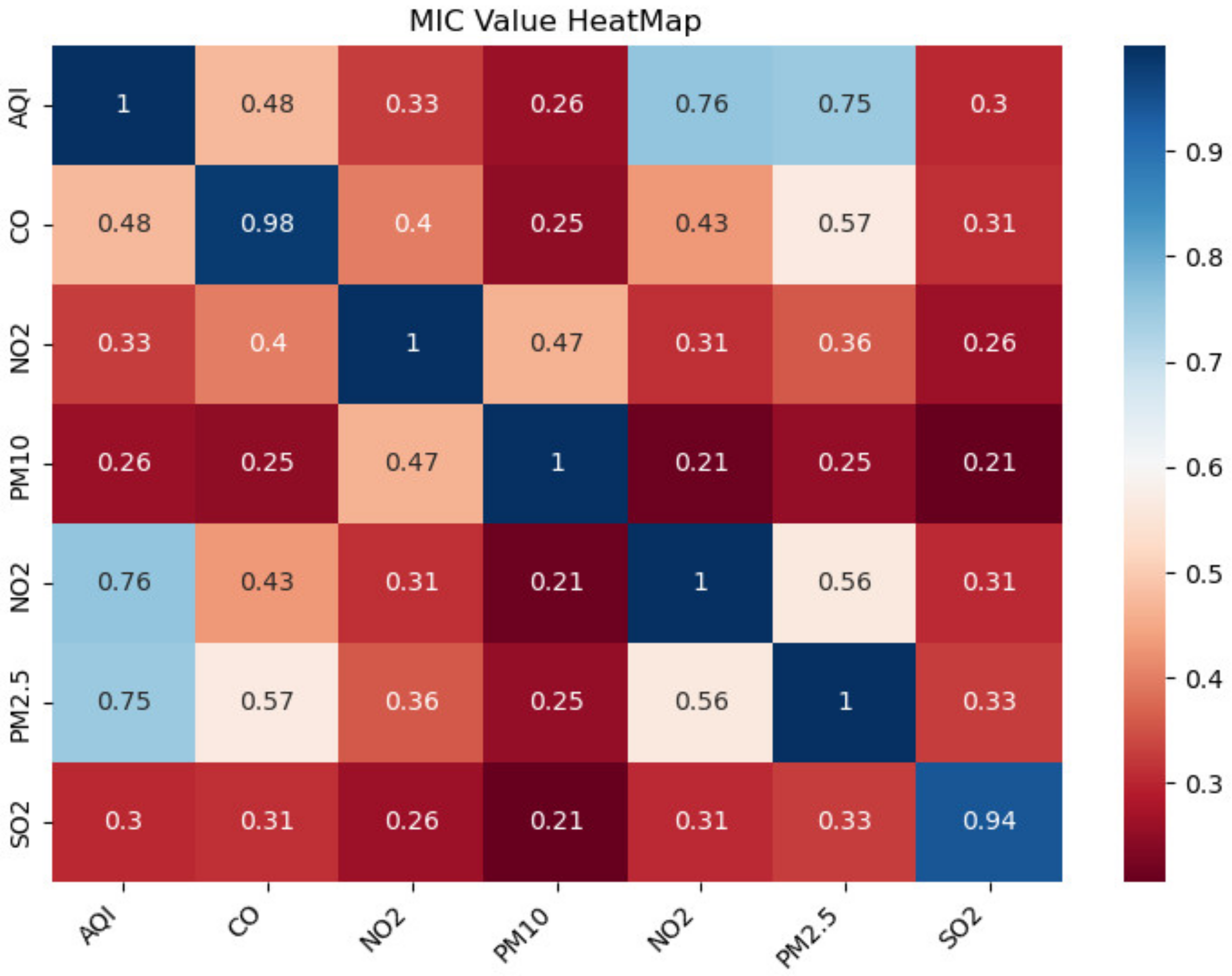
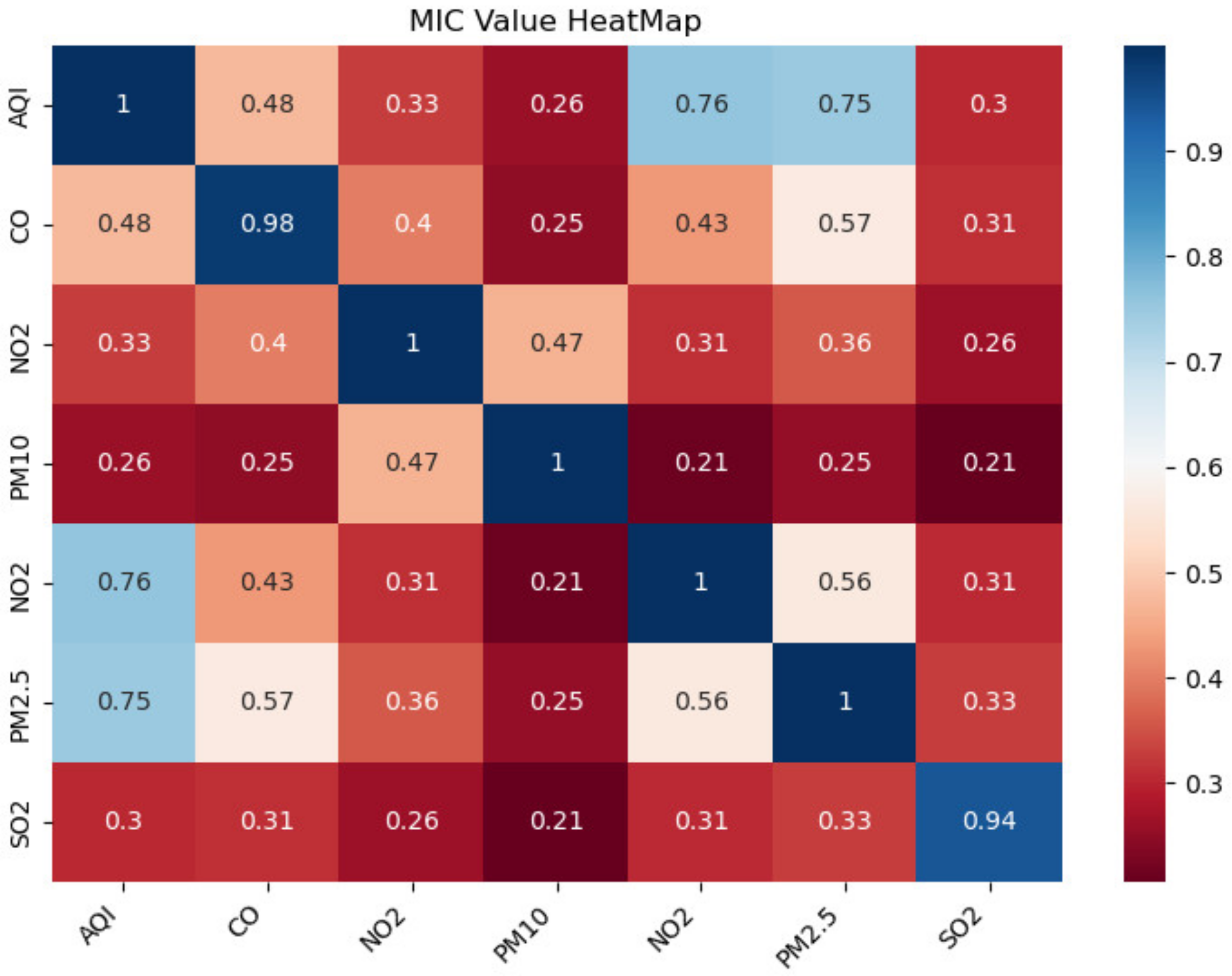
- DSSL mainly consists of MIDC and Bayesian hyperparameter optimization. MIDC is an essential part of DSSL to analyze and quantify the relationship between different variables. Therefore, the first experiment used MIDC to quantitatively analyze the relationship between the target variable and other air quality factors, select variables with high correlation and low redundancy, and then superimpose these variables in turn and input them into VBGRU to verify the impact of correlation and redundancy between data on prediction performance (see Section 4.3 for details).
- (2)
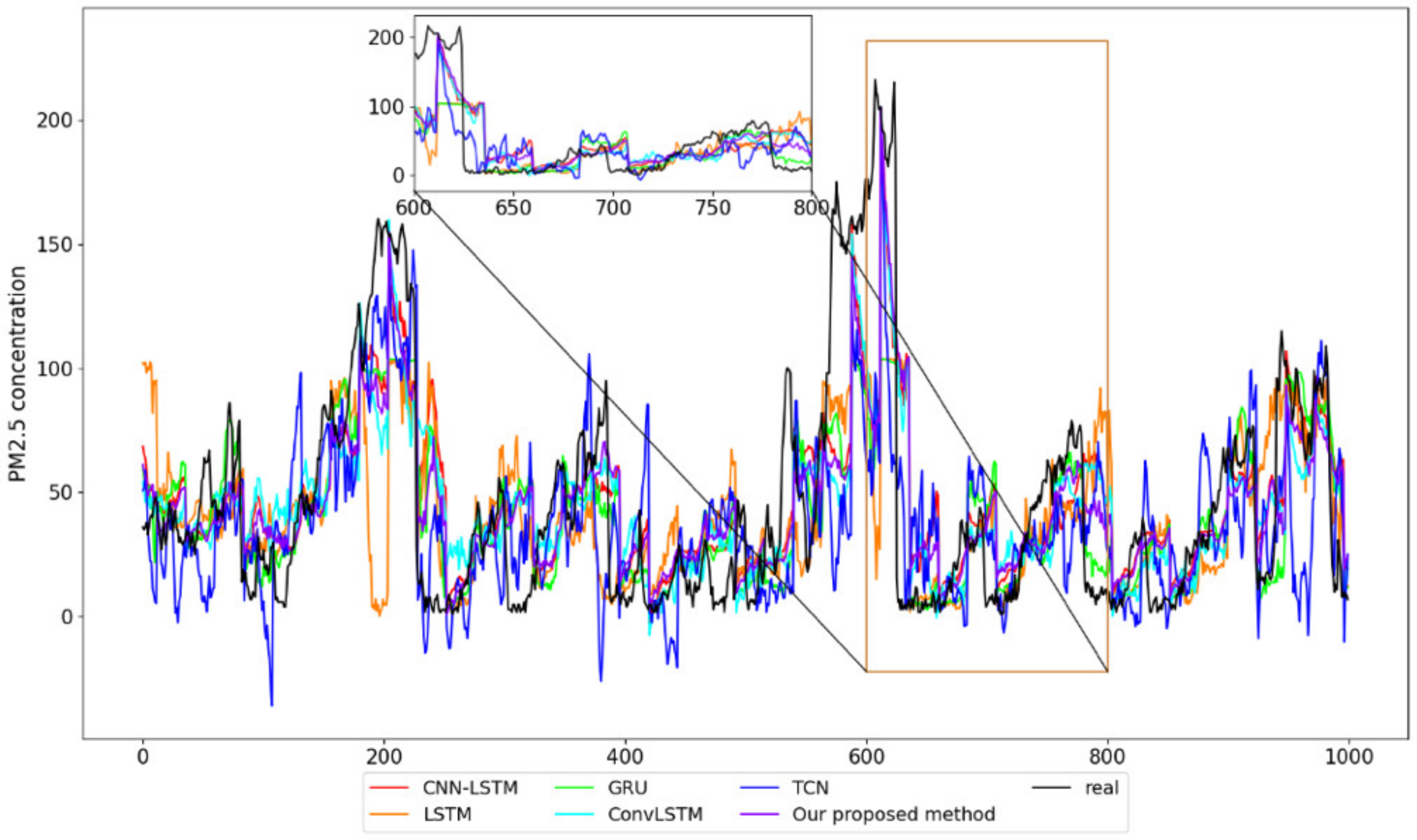
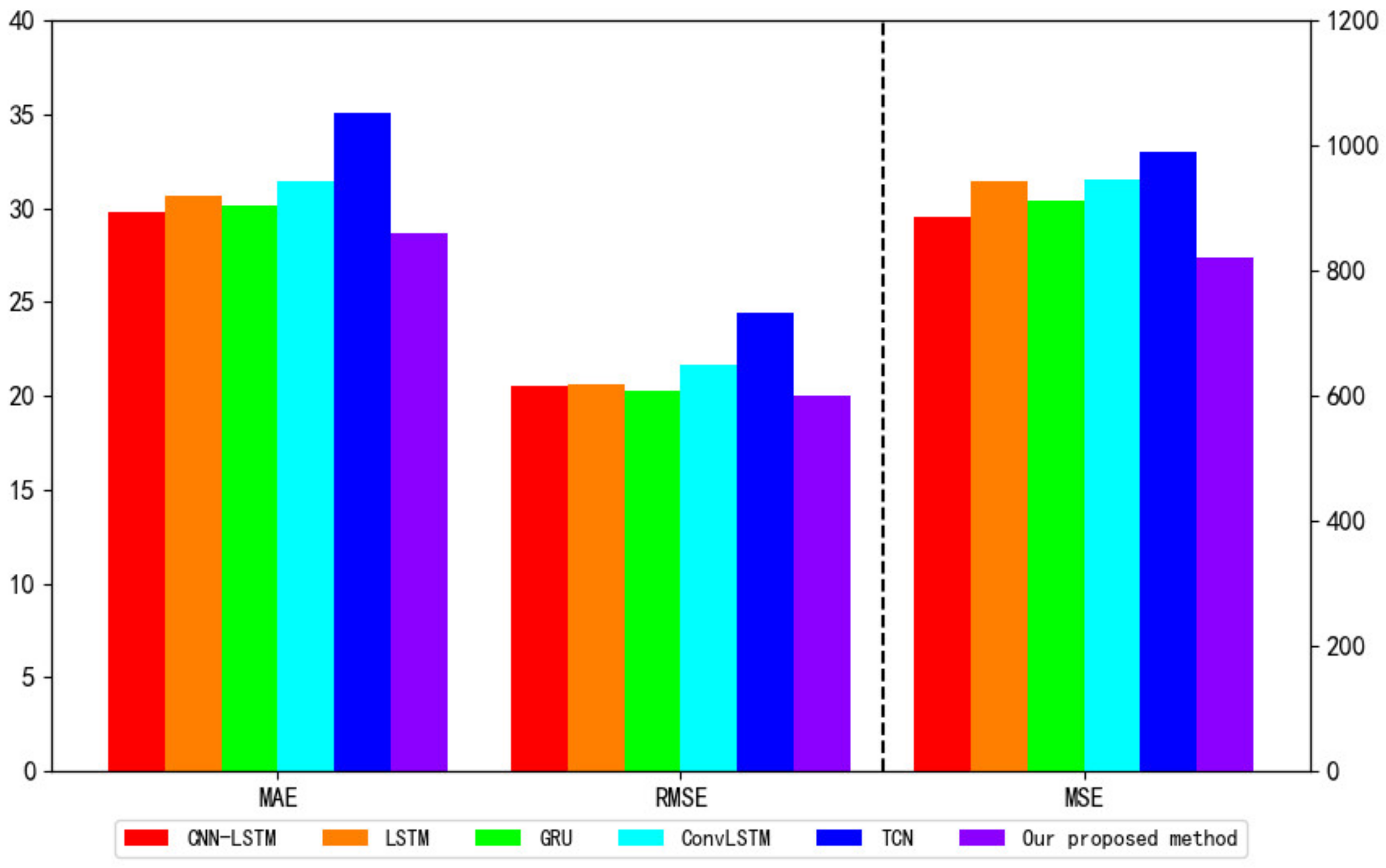
- Based on the variables filtered out using DSSL, we compare the prediction performance of VBGRU with LSTM, GRU, convolutional long short-term memory network (ConvLSTM), convolutional neural network-long short-term memory network (CNN-LSTM), and time convolutional network (TCN), and evaluate the pros and cons of the model’s predictive ability through the evaluation function (see Section 4.4 for details).
4.3. Performance Verification of MIDC
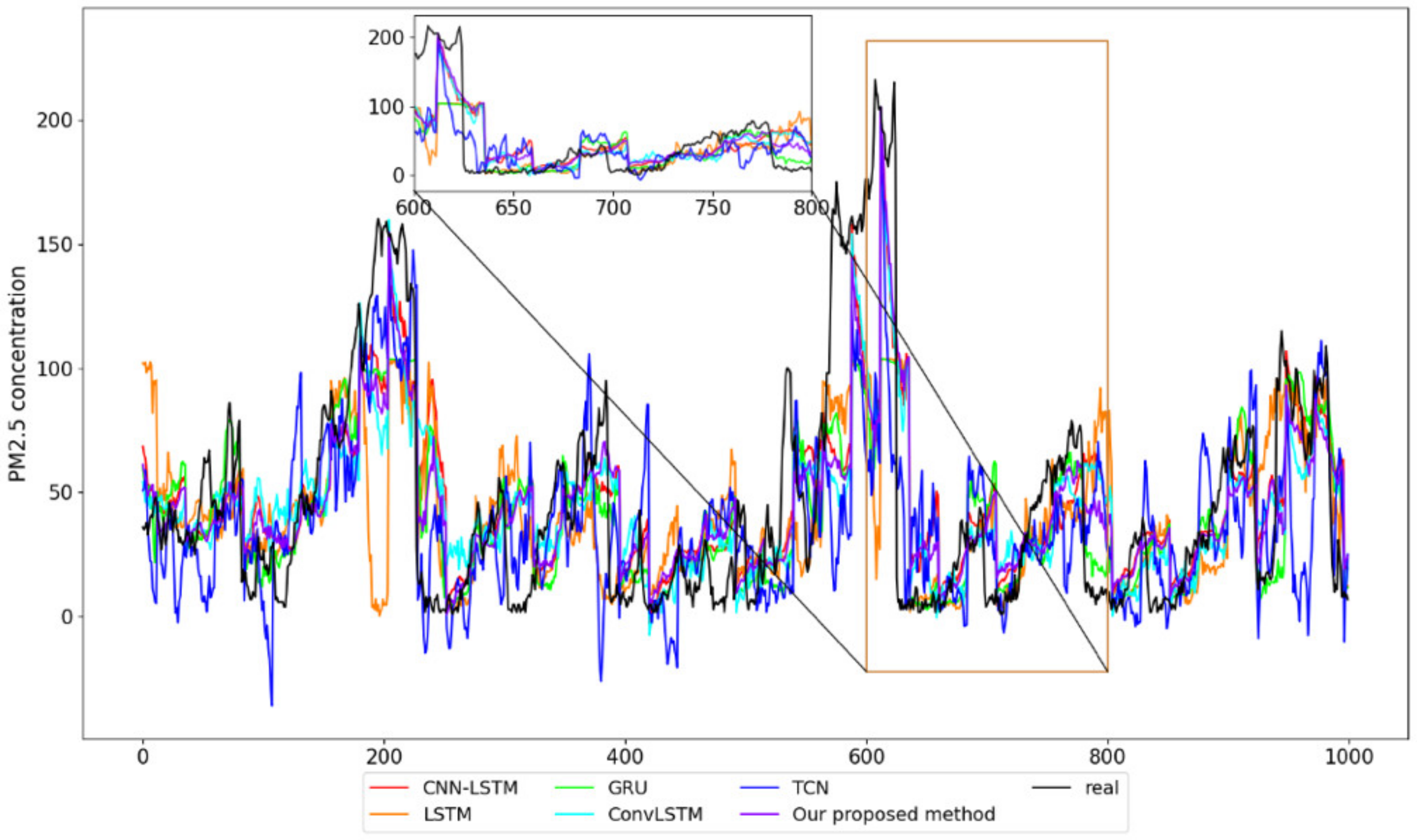
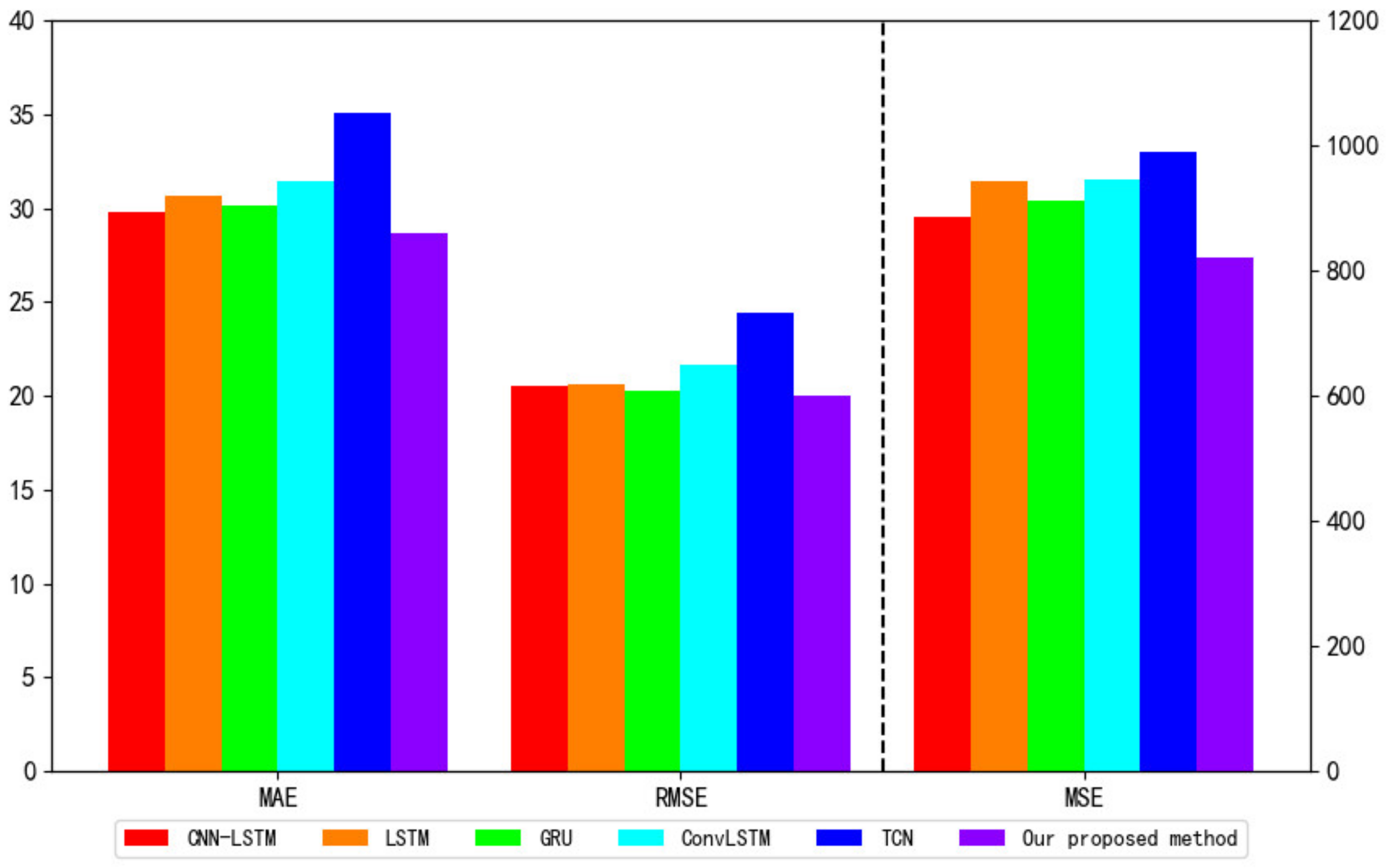
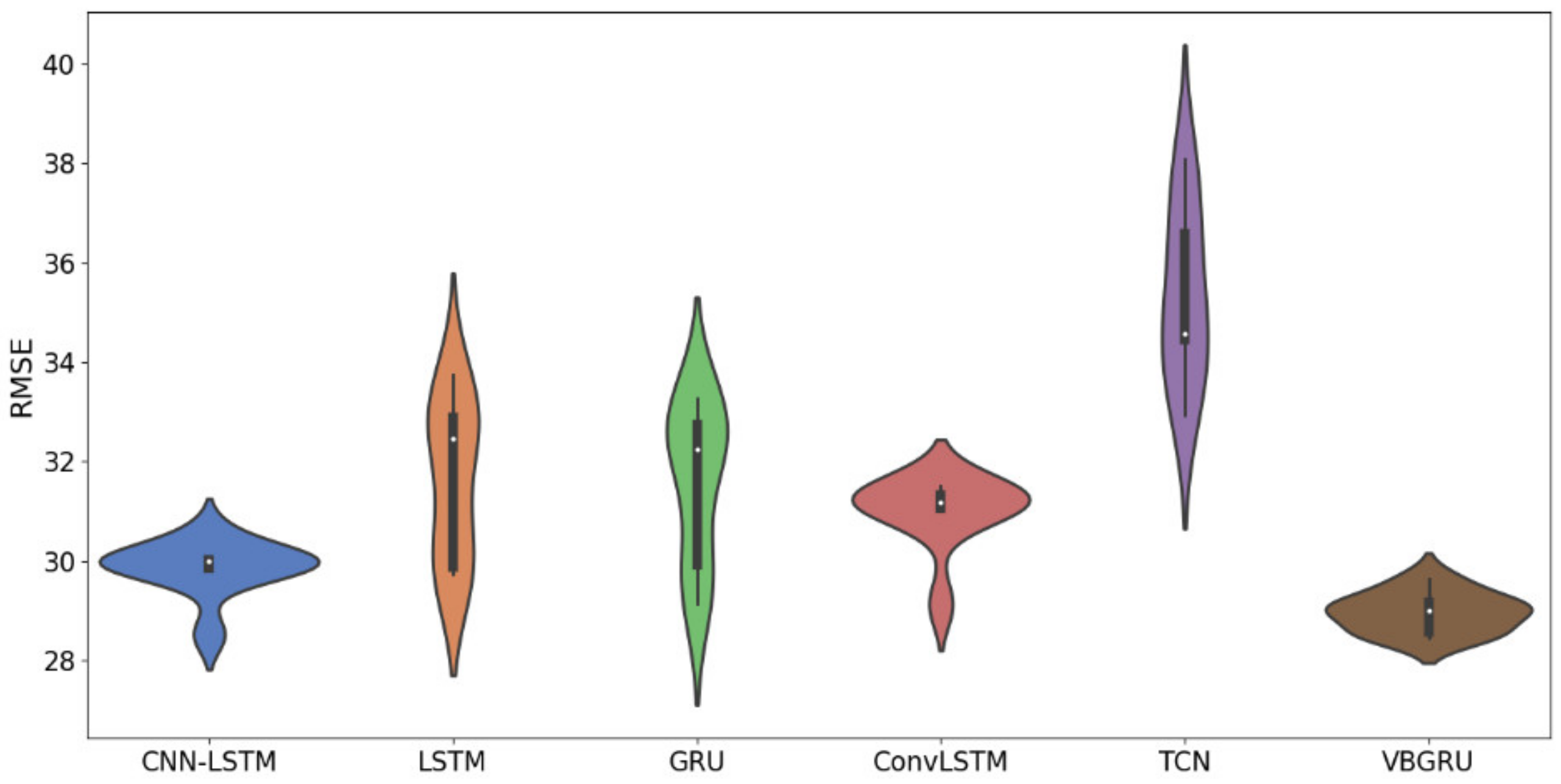
4.4. Compared with Other Models
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, W.; Liang, S.; Yu, Q. PM2.5 concentration prediction based on pseudo-F statistic feature selection algorithm and support vector regression. In Earth and Environmental Science, Proceedings of the Third International Workshop on Environment and Geoscience, Chengdu, China, 18–20 July 2020; IOP Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 569, p. 012039. [Google Scholar] [CrossRef]
- Guo, N.; Chen, W.; Wang, M.; Tian, Z.; Jin, H. Appling an Improved Method Based on ARIMA Model to Predict the Short-Term Electricity Consumption Transmitted by the Internet of Things (IoT). Wirel. Commun. Mob. Comput. 2021, 2021, 6610273. [Google Scholar] [CrossRef]
- Cholianawati, N.; Cahyono, W.E.; Indrawati, A.; Indrajad, A. Linear Regression Model for Predicting Daily PM2. 5 Using VIIRS-SNPP and MODIS-Aqua AOT. In Earth and Environmental Science, Proceedings of the International Conference On Tropical Meteorology And Atmospheric Sciences, Bandung, Indonesia, 19–20 September 2018; IOP Conference Series; IOP Publishing: Bristol, UK, 2019; Volume 303, p. 012039. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, H.; Palazoglu, A.; Singh, A.; Zhang, W.; Liu, S. Prediction of 24-hour-average PM2.5 concentrations using a hidden Markov model with different emission distributions in Northern California. Sci. Total Environ. 2013, 443, 93–103. [Google Scholar] [CrossRef] [PubMed]
- Kong, J.L.; Wang, H.; Wang, X.; Jin, X.B.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Kong, J.; Yang, C.; Wang, J.; Wang, X.; Zuo, M.; Jin, X.; Lin, S. Deep-stacking network approach by multisource data mining for hazardous risk iden-tification in IoT-based intelligent food management systems. Comput. Intell. Neurosci. 2021, 2021, 1194565. [Google Scholar] [CrossRef]
- Zhen, T.; Kong, J.L.; Yan, L. Hybrid Deep-Learning Framework Based on Gaussian Fusion of Multiple Spatiotemporal Networks for Walking Gait Phase Recognition. Complexity 2020, 2020, 8672431. [Google Scholar] [CrossRef]
- Zheng, Y.-Y.; Kong, J.-L.; Jin, X.-B.; Wang, X.-Y.; Su, T.-L.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.-Y.; Su, T.-L.; Wang, J.-L. Probability Fusion Decision Framework of Multiple Deep Neural Networks for Fine-grained Visual Classification. IEEE Access 2019, 7, 122740–122757. [Google Scholar] [CrossRef]
- Kong, J.L.; Wang, Z.N.; Ji, X.B.; Wang, X.-Y.; Su, T.-L.; Wang, J.-L. Semi-supervised segmentation framework based on spot-divergence super voxelization of multi-sensor fusion data for autonomous forest machine applications. Sensors 2018, 18, 3061. [Google Scholar] [CrossRef] [Green Version]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [Green Version]
- Qadeer, K.; Rehman, W.U.; Sheri, A.M.; Park, I.; Kim, H.K.; Jeon, M. A long short-term memory (LSTM) network for hourly estimation of PM2. 5 con-centration in two cities of South Korea. Appl. Sci. 2020, 10, 3984. [Google Scholar] [CrossRef]
- Becerra-Rico, J.; Aceves-Fernández, M.A.; Esquivel-Escalante, K.; Pedraza-Ortega, J.C. Airborne particle pollution predictive model using Gated Recurrent Unit (GRU) deep neural networks. Earth Sci. Inform. 2020, 13, 821–834. [Google Scholar] [CrossRef]
- Li, W.; Gao, X.; Hao, Z.; Sun, R. Using deep learning for precipitation forecasting based on spatio-temporal information: A case study. Clim. Dyn. 2021, 58, 443–457. [Google Scholar] [CrossRef]
- Wang, W.; Mao, W.; Tong, X.; Xu, G. A Novel Recursive Model Based on a Convolutional Long Short-Term Memory Neural Network for Air Pollution Prediction. Remote Sens. 2021, 13, 1284. [Google Scholar] [CrossRef]
- Ding, F.; Chen, T. Combined parameter and output estimation of dual-rate systems using an auxiliary model. Automatica 2004, 40, 1739–1748. [Google Scholar] [CrossRef]
- Ding, F.; Chen, T. Parameter estimation of dual-rate stochastic systems by using an output error method. IEEE Trans. Autom. Control 2005, 50, 1436–1441. [Google Scholar] [CrossRef]
- Ding, F.; Shi, Y.; Chen, T. Auxiliary model-based least-squares identification methods for Hammerstein output-error systems. Syst. Control Lett. 2007, 56, 373–380. [Google Scholar] [CrossRef]
- Zhou, Y.; Ding, F. Modeling Nonlinear Processes Using the Radial Basis Function-Based State-Dependent Autoregressive Models. IEEE Signal Process. Lett. 2020, 27, 1600–1604. [Google Scholar] [CrossRef]
- Zhou, Y.H.; Zhang, X.; Ding, F. Partially-coupled nonlinear parameter optimization algorithm for a class of multivariate hybrid models. Appl. Math. Comput. 2022, 414, 126663. [Google Scholar] [CrossRef]
- Zhou, Y.H.; Zhang, X.; Ding, F. Hierarchical Estimation Approach for RBF-AR Models with Regression Weights Based on the Increasing Data Length. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 3597–3601. [Google Scholar] [CrossRef]
- Ding, F.; Zhang, X.; Xu, L. The innovation algorithms for multivariable state-space models. Int. J. Adapt. Control Signal Process. 2019, 33, 1601–1618. [Google Scholar] [CrossRef]
- Ding, F.; Liu, G.; Liu, X.P. Parameter estimation with scarce measurements. Automatica 2011, 47, 1646–1655. [Google Scholar] [CrossRef]
- Liu, Y.J.; Ding, F.; Shi, Y. An efficient hierarchical identification method for general dual-rate sampled-data systems. Automatica 2014, 50, 962–970. [Google Scholar] [CrossRef]
- Zhang, X.; Ding, F. Optimal Adaptive Filtering Algorithm by Using the Fractional-Order Derivative. IEEE Signal Process. Lett. 2022, 29, 399–403. [Google Scholar] [CrossRef]
- Li, M.H.; Liu, X.M.; Ding, F. The filtering-based maximum likelihood iterative estimation algorithms for a special class of nonlinear systems with autoregressive moving average noise using the hierarchical identification principle. Int. J. Adapt. Control Signal Process. 2019, 33, 1189–1211. [Google Scholar] [CrossRef]
- Ding, J.; Ding, F.; Liu, X.P.; Liu, G. Hierarchical Least Squares Identification for Linear SISO Systems with Dual-Rate Sampled-Data. IEEE Trans. Autom. Control 2011, 56, 2677–2683. [Google Scholar] [CrossRef]
- Ding, F.; Liu, Y.; Bao, B. Gradient-based and least-squares-based iterative estimation algorithms for multi-input multi-output systems. Proc. Inst. Mech. Eng. Part I J. Syst. Control. Eng. 2012, 226, 43–55. [Google Scholar] [CrossRef]
- Xu, L.; Chen, F.Y.; Hayat, T. Hierarchical recursive signal modeling for multi-frequency signals based on discrete measured data. Int. J. Adapt. Control Signal Process. 2021, 35, 676–693. [Google Scholar] [CrossRef]
- Wang, Y.; Ding, F. Novel data filtering based parameter identification for multiple-input multiple-output systems using the auxiliary model. Automatica 2016, 71, 308–313. [Google Scholar] [CrossRef]
- Zhang, K.; Zheng, L.; Liu, Z.; Jia, N. A deep learning based multitask model for network-wide traffic speed prediction. Neurocomputing 2020, 396, 438–450. [Google Scholar] [CrossRef]
- Wang, G.; Awad, O.I.; Liu, S.; Shuai, S.; Wang, Z. NOx emissions prediction based on mutual information and back propagation neural network using correlation quantitative analysis. Energy 2020, 198, 117286. [Google Scholar] [CrossRef]
- Song, H.Y.; Park, S. An Analysis of Correlation between Personality and Visiting Place using Spearman’s Rank Correlation Coefficient. KSII Trans. Internet Inf. Syst. 2020, 14, 1951–1966. [Google Scholar] [CrossRef]
- Liu, Y.; Mu, Y.; Chen, K.; Li, Y.; Guo, J. Daily Activity Feature Selection in Smart Homes Based on Pearson Correlation Coefficient. Neural Process. Lett. 2020, 51, 1771–1787. [Google Scholar] [CrossRef]
- Mengfan, T.; Siwei, L.; Ge, S.; Jie, Y.; Lechao, D.; Hao, L.; Senlin, H. Including the feature of appropriate adjacent sites improves the PM2.5 concentration prediction with long short-term memory neural network model. Sustain. Cities Soc. 2021, 76, 103427. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-Fully connected (LSTM-FC) neural network for PM2. 5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef]
- Yeo, I.; Choi, Y.; Lops, Y.; Sayeed, A. Efficient PM2.5 forecasting using geographical correlation based on integrated deep learning algorithms. Neural Comput. Appl. 2021, 33, 15073–15089. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Miao, Q.; Huang, P. Remaining useful life estimation using deep metric transfer learning for kernel regression. Reliab. Eng. Syst. Saf. 2021, 212, 107583. [Google Scholar] [CrossRef]
- Shi, Y.; Li, W.; Zhu, L.; Guo, K.; Cambria, E. Stock trading rule discovery with double deep Q-network. Appl. Soft Comput. 2021, 107, 107320. [Google Scholar] [CrossRef]
- Jin, X.-B.; Zheng, W.-Z.; Kong, J.-L.; Wang, X.-Y.; Bai, Y.-T.; Su, T.-L.; Lin, S. Deep-Learning Forecasting Method for Electric Power Load via Attention-Based Encoder-Decoder with Bayesian Optimization. Energies 2021, 14, 1596. [Google Scholar] [CrossRef]
- Abdourahamane, Z.S.; Acar, R.; Serkan, Ş. Wavelet–copula-based mutual information for rainfall forecasting applications. Hydrol. Process. 2019, 33, 1127–1142. [Google Scholar] [CrossRef]
- Peng, Z.; Liu, W.Q.; An, S.J. Haze pollution causality mining and prediction based on multi-dimensional time series with PS-FCM. Inf. Sci. 2020, 523, 307–317. [Google Scholar] [CrossRef]
- Han, S.; Dong, H.; Teng, X.; Li, X.; Wang, X. Correlational graph attention-based Long Short-Term Memory network for multivariate time series prediction. Appl. Soft Comput. 2021, 106, 107377. [Google Scholar] [CrossRef]
- Jin, X.-B.; Yu, X.-H.; Su, T.-L.; Yang, D.-N.; Bai, Y.-T.; Kong, J.-L.; Wang, L. Distributed Deep Fusion Predictor for aMulti-Sensor System Based on Causality Entropy. Entropy 2021, 23, 219. [Google Scholar] [CrossRef]
- Zhou, F.; Yang, Q.; Zhong, T.; Chen, D.; Zhang, N. Variational Graph Neural Networks for Road Traffic Prediction in Intelligent Transportation Systems. IEEE Trans. Ind. Inform. 2020, 17, 2802–2812. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Zhang, Z.; Pei, S.; Wang, C.; Yu, X.; Jiang, Z.; Zhou, J. Ensemble spatiotemporal forecasting of solar irradiation using variational Bayesian convolutional gate recurrent unit network. Appl. Energy 2019, 253, 113596. [Google Scholar] [CrossRef]
- Brusaferri, A.; Matteucci, M.; Portolani, P.; Vitali, A. Bayesian deep learning based method for probabilistic forecast of day-ahead electricity prices. Appl. Energy 2019, 250, 1158–1175. [Google Scholar] [CrossRef]
- Jin, X.B.; Wang, H.X.; Wang, X.Y.; Bai, Y.-T.; Su, T.-L.; Kong, J.-L. Deep-learning prediction model with serial two-level decomposition based on bayesian optimization. Complexity 2020, 2020, 4346803. [Google Scholar] [CrossRef]
- Luo, X.; Gan, W.; Wang, L.; Chen, Y.; Ma, E. A Deep Learning Prediction Model for Structural Deformation Based on Temporal Convolutional Networks. Comput. Intell. Neurosci. 2021, 2021, 8829639. [Google Scholar] [CrossRef] [PubMed]
- Bokde, N.D.; Yaseen, Z.M.; Andersen, G.B. ForecastTB—An R package as a test-bench for time series forecasting—Application of wind speed and solar radiation modeling. Energies 2020, 13, 2578. [Google Scholar] [CrossRef]
- Wong, T.T.; Yeh, P.Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1586–1594. [Google Scholar] [CrossRef]
- Ding, F.; Lv, L.; Pan, J.; Wan, X.; Jin, X.-B. Two-stage Gradient-based Iterative Estimation Methods for Controlled Autoregressive Systems Using the Measurement Data. Int. J. Control. Autom. Syst. 2020, 18, 886–896. [Google Scholar] [CrossRef]
- Zhang, X.; Ding, F. Hierarchical parameter and state estimation for bilinear systems. Int. J. Syst. Sci. 2020, 51, 275–290. [Google Scholar] [CrossRef]
- Xu, L.; Ding, F.; Zhu, Q. Decomposition strategy-based hierarchical least mean square algorithm for control systems from the impulse responses. Int. J. Syst. Sci. 2021, 52, 1806–1821. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, L.; Ding, F.; Hayat, T. Combined state and parameter estimation for a bilinear state space system with moving average noise. J. Frankl. Inst. 2018, 355, 3079–3103. [Google Scholar] [CrossRef]
- Pan, J.; Jiang, X.; Wan, X.; Ding, W. A filtering based multi-innovation extended stochastic gradient algorithm for multivariable control systems. Int. J. Control Autom. Syst. 2017, 15, 1189–1197. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, E.F. State estimation for bilinear systems through minimizing the covariance matrix of the state estimation errors. Int. J. Adapt. Control Signal Process. 2019, 33, 1157–1173. [Google Scholar] [CrossRef]
- Pan, J.; Ma, H.; Zhang, X.; Liu, Q.; Ding, F.; Chang, Y.; Sheng, J. Recursive coupled projection algorithms for multivariable output-error-like systems with coloured noises. IET Signal Process. 2020, 14, 455–466. [Google Scholar] [CrossRef]
- Ding, F.; Liu, G.; Liu, X.P. Partially Coupled Stochastic Gradient Identification Methods for Non-Uniformly Sampled Systems. IEEE Trans. Autom. Control 2010, 55, 1976–1981. [Google Scholar] [CrossRef]
- Ding, F.; Shi, Y.; Chen, T. Performance analysis of estimation algorithms of non-stationary ARMA processes. IEEE Trans. Signal Process. 2006, 54, 1041–1053. [Google Scholar] [CrossRef]
- Wang, Y.J.; Ding, F.; Wu, M.H. Recursive parameter estimation algorithm for multivariate output-error systems. J. Frankl. Inst. 2018, 355, 5163–5181. [Google Scholar] [CrossRef]
- Xu, L. Separable Multi-innovation Newton Iterative Modeling Algorithm for Multi-frequency Signals Based on the Sliding Measurement Window. Circuits Syst. Signal Process. 2022, 41, 805–830. [Google Scholar] [CrossRef]
- Xu, L. Separable Newton Recursive Estimation Method Through System Responses Based on Dynamically Discrete Measurements with Increasing Data Length. Int. J. Control Autom. Syst. 2022, 20, 432–443. [Google Scholar] [CrossRef]
- Zhang, X.; Ding, F. Adaptive parameter estimation for a general dynamical system with unknown states. Int. J. Robust Nonlinear Control 2020, 30, 1351–1372. [Google Scholar] [CrossRef]
- Zhang, X.; Ding, F.; Xu, L. Recursive parameter estimation methods and convergence analysis for a special class of nonlinear systems. Int. J. Robust Nonlinear Control 2020, 30, 1373–1393. [Google Scholar] [CrossRef]
- Zhang, X.; Ding, F. Recursive parameter estimation and its convergence for bilinear systems. IET Control Theory Appl. 2020, 14, 677–688. [Google Scholar] [CrossRef]
- Liu, S.Y.; Ding, F.; Xu, L.; Hayat, T. Hierarchical Principle-Based Iterative Parameter Estimation Algorithm for Dual-Frequency Signals. Circuits Syst. Signal Process. 2019, 38, 3251–3268. [Google Scholar] [CrossRef]
- Wan, L.J. Decomposition- and gradient-based iterative identification algorithms for multivariable systems using the mul-ti-innovation theory. Circuits Syst. Signal Process. 2019, 38, 2971–2991. [Google Scholar] [CrossRef]
- Pan, J.; Li, W.; Zhang, H.P. Control Algorithms of Magnetic Suspension Systems Based on the Improved Double Exponential Reaching Law of Sliding Mode Control. Int. J. Control Autom. Syst. 2018, 16, 2878–2887. [Google Scholar] [CrossRef]
- Ma, H.; Pan, J.; Ding, W. Partially-coupled least squares based iterative parameter estimation for multi-variable out-put-error-like autoregressive moving average systems. IET Control Theory Appl. 2019, 13, 3040–3051. [Google Scholar] [CrossRef]
- Ding, F.; Liu, P.X.; Yang, H.Z. Parameter Identification and Intersample Output Estimation for Dual-Rate Systems. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 966–975. [Google Scholar] [CrossRef]
- Ding, F.; Liu, X.P.; Liu, G. Multiinnovation least squares identification for linear and pseudo-linear regression models. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 767–778. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Ding, F.; Yang, E.F. Auxiliary model multiinnovation stochastic gradient parameter estimation methods for nonlinear sandwich systems. Int. J. Robust Nonlinear Control 2020, 31, 148–165. [Google Scholar] [CrossRef]
- Xu, L.; Ding, F.; Wan, L.; Sheng, J. Separable multi-innovation stochastic gradient estimation algorithm for the nonlinear dynamic responses of systems. Int. J. Adapt. Control Signal Process. 2020, 34, 937–954. [Google Scholar] [CrossRef]
- Zhao, Z.Y.; Zhou, Y.Q.; Wang, X.Y.; Wang, Z.; Bai, Y. Water quality evolution mechanism modeling and health risk assessment based on stochastic hybrid dynamic systems. Expert Syst. Appl. 2022, 193, 116404. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, Z.Y.; Wang, X.Y.; Xiong, K.; Shi, C. Microbiological predictive modeling and risk analysis based on the one-step kinetic inte-grated Wiener process. Innov. Food Sci. Emerg. Technol. 2022, 75, 102912. [Google Scholar] [CrossRef]
- Jin, X.-B.; Gong, W.-T.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L. PFVAE: A Planar Flow-Based Variational Auto-Encoder Prediction Model for Time Series Data. Mathematics 2022, 10, 610. [Google Scholar] [CrossRef]
- Jin, X.-B.; Zheng, W.-Z.; Kong, J.-L.; Wang, X.-Y.; Zuo, M.; Zhang, Q.-C.; Lin, S. Deep-Learning Temporal Predictor via Bi-directional Self-attentive Encoder-decoder framework for IOT-based Environmental Sensing in Intelligent Greenhouse. Agriculture 2021, 11, 802. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Full Name | Abbreviation |
|---|---|
| Data self-screening layer | DSSL |
| Variational Bayesian gated recurrent unit | VBGRU |
| Maximal information distance coefficient | MIDC |
| Maximal information coefficient | MIC |
| Distance entropy | DE |
| Gaussian process regression | GPR |
| Kullback–Leibler | KL |
| Long short-term memory network | LSTM |
| Gated recurrent unit | GRU |
| Convolutional long short-term memory network | ConvLSTM |
| Convolutional neural network-long short-term memory network | CNN-LSTM |
| Time convolutional network | TCN |
| Root mean square error | RMSE |
| Mean square error | MSE |
| Mean absolute error | MAE |
| The Input Data | MIC | MIDC | RMSE | MSE | MAE | Train_Time |
|---|---|---|---|---|---|---|
| PM2.5, AQI | 0.76 | 0.26 | 28.87 | 833.48 | 20.29 | 48.44 s |
| PM2.5, CO | 0.57 | 0.91 | 28.66 | 821.18 | 20.02 | 44.81 s |
| Models | RMSE | MSE | MAE | Train_Time |
|---|---|---|---|---|
| CNN-LSTM [14] | 29.76 | 886.45 | 20.51 | 69.11 s |
| LSTM [12] | 30.66 | 942.24 | 20.60 | 36.73 s |
| GRU [13] | 30.13 | 911.26 | 20.28 | 39.97 s |
| ConvLSTM [15] | 31.45 | 990.17 | 21.61 | 78.26 s |
| TCN [49] | 35.05 | 1233.42 | 24.43 | 119.54 s |
| Our proposed VBGRU | 28.59 | 817.12 | 19.78 | 44.81 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, X.-B.; Gong, W.-T.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L. A Variational Bayesian Deep Network with Data Self-Screening Layer for Massive Time-Series Data Forecasting. Entropy 2022, 24, 335. https://doi.org/10.3390/e24030335
Jin X-B, Gong W-T, Kong J-L, Bai Y-T, Su T-L. A Variational Bayesian Deep Network with Data Self-Screening Layer for Massive Time-Series Data Forecasting. Entropy. 2022; 24(3):335. https://doi.org/10.3390/e24030335
Chicago/Turabian StyleJin, Xue-Bo, Wen-Tao Gong, Jian-Lei Kong, Yu-Ting Bai, and Ting-Li Su. 2022. "A Variational Bayesian Deep Network with Data Self-Screening Layer for Massive Time-Series Data Forecasting" Entropy 24, no. 3: 335. https://doi.org/10.3390/e24030335
APA StyleJin, X.-B., Gong, W.-T., Kong, J.-L., Bai, Y.-T., & Su, T.-L. (2022). A Variational Bayesian Deep Network with Data Self-Screening Layer for Massive Time-Series Data Forecasting. Entropy, 24(3), 335. https://doi.org/10.3390/e24030335