
Local Lead–Lag Relationships and Nonlinear Granger Causality: An Empirical Analysis

Abstract
:1. Introduction
2. Methodology
2.1. The Local Gaussian Correlation
2.2. Testing for Distributional Granger Causality
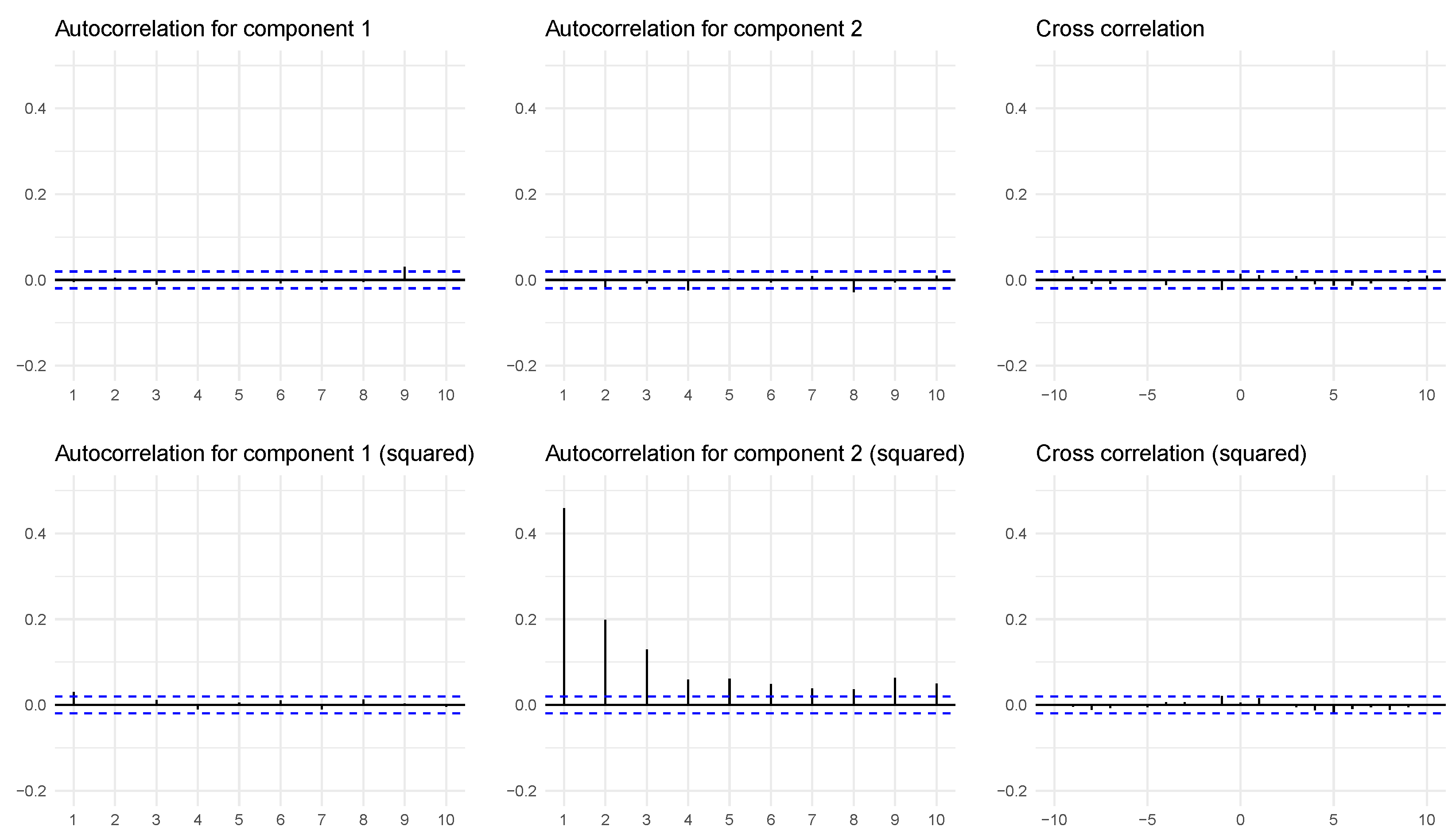
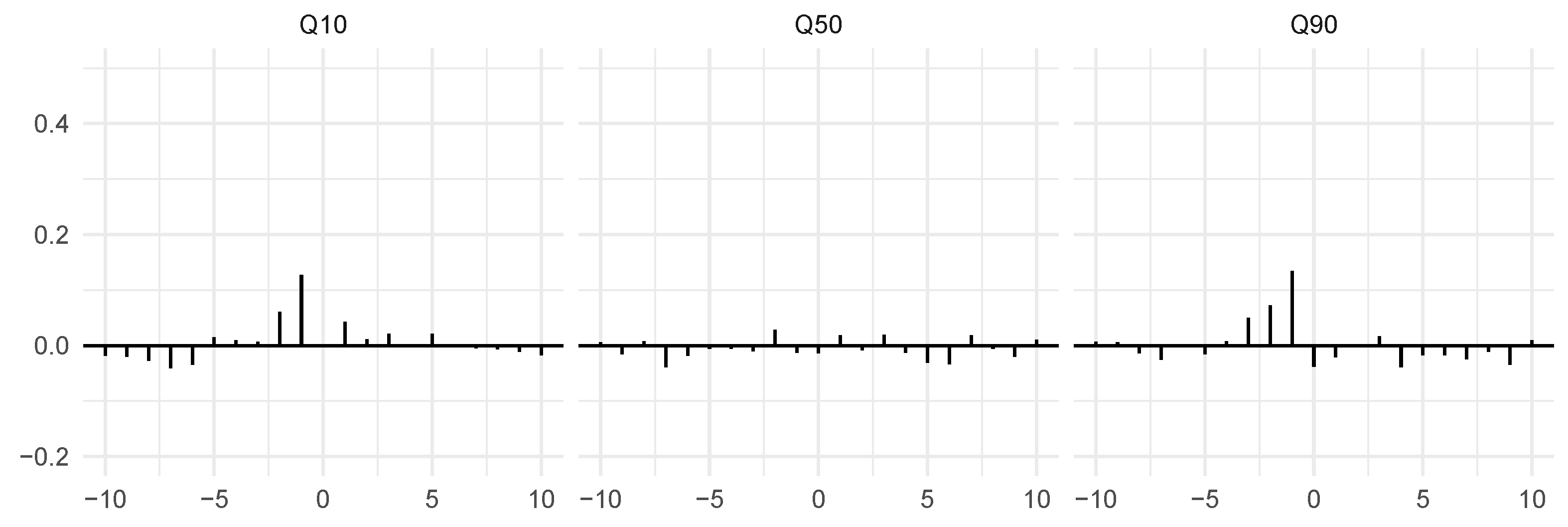
3. A Simulation Example
4. Lead–Lag Relations for Global and Local Correlations
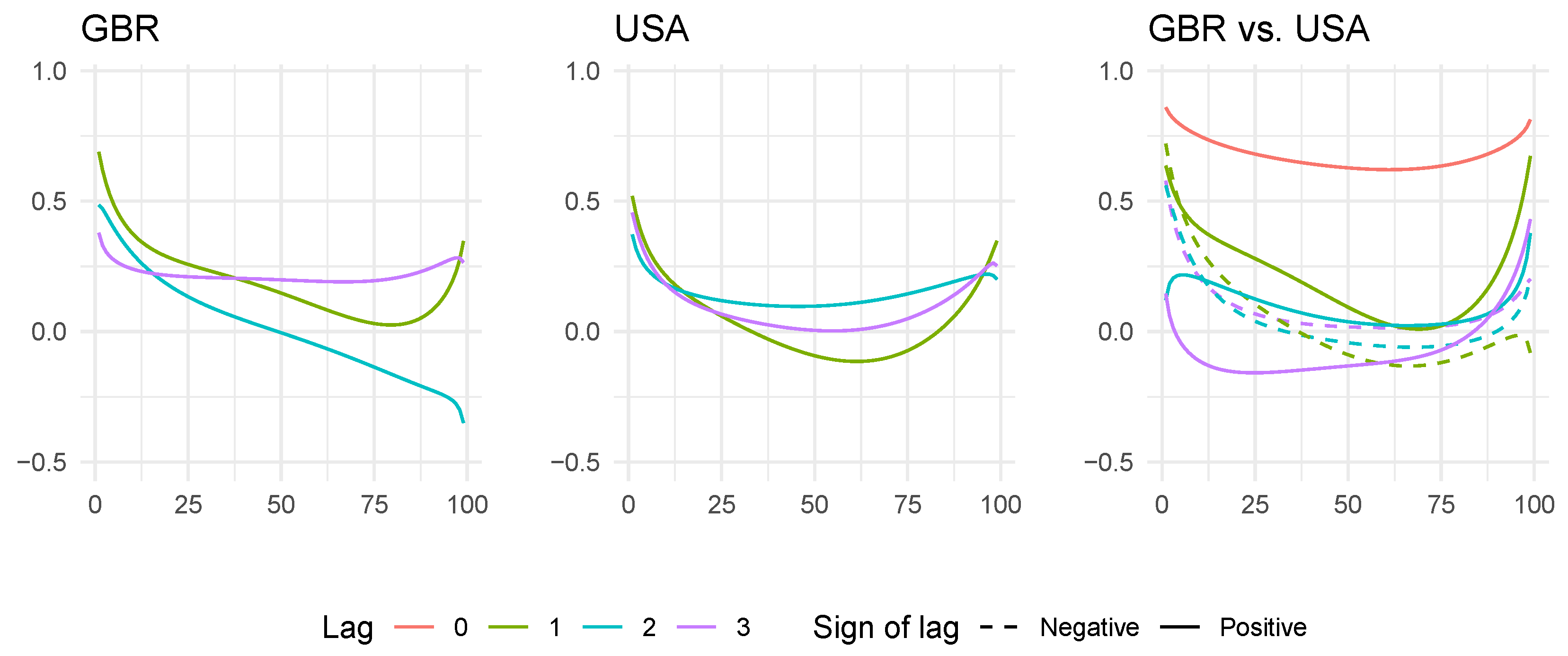
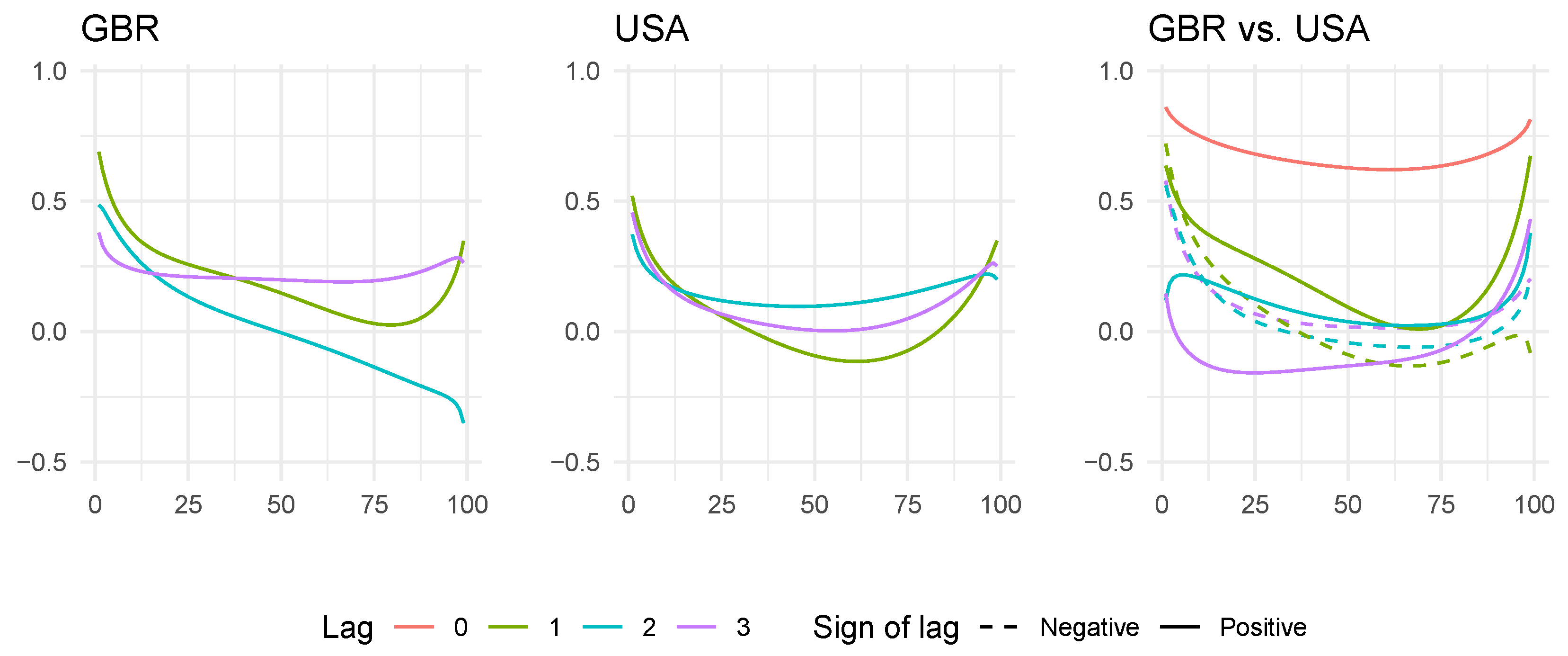
4.1. The Case of the US and the United Kingdom
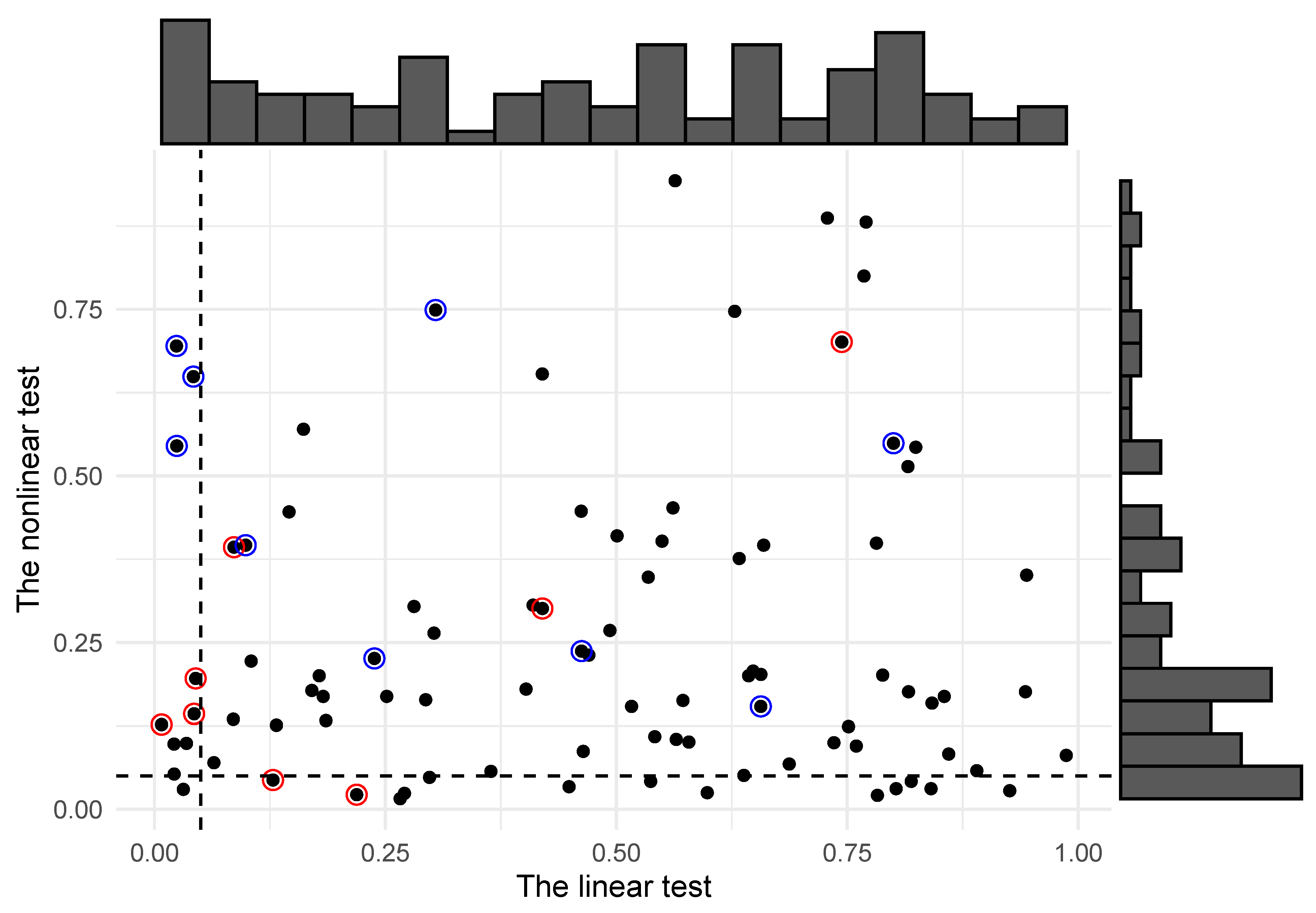
4.2. A Wider Selection of Countries
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Box, G.; Jenkins, G. Time Series Analysis: Forecasting and Control; Holden Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-Spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Rapach, D.E.; Strauss, J.K.; Zhou, G. International Stock Return Predictability: What Is the Role of the United States? J. Financ. 2013, 68, 1633–1662. [Google Scholar] [CrossRef]
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques and Tools-Revised Edition; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Francq, C.; Zakoian, J.M. GARCH Models: Structure, Statistical Inference and Financial Applications; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Tjøstheim, D.; Otneim, H.; Støve, B. Statistical Modeling Using Local Gaussian Approximation; Academic Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Otneim, H.; Tjøstheim, D. The Locally Gaussian Partial Correlation. J. Bus. Econ. Stat. 2021, 1–13. [Google Scholar] [CrossRef]
- Hjort, N.L.; Jones, M.C. Locally Parametric Nonparametric Density Estimation. Ann. Stat. 1996, 24, 1619–1647. [Google Scholar] [CrossRef]
- Otneim, H.; Tjøstheim, D. The Locally Gaussian Density Estimator for Multivariate Data. Stat. Comput. 2017, 27, 1595–1616. [Google Scholar] [CrossRef]
- Otneim, H.; Tjøstheim, D. Conditional Density Estimation Using the Local Gaussian Correlation. Stat. Comput. 2018, 28, 303–321. [Google Scholar] [CrossRef]
- Jordanger, L.A.; Tjøstheim, D. Nonlinear Spectral Analysis: A Local Gaussian Approach. J. Am. Stat. Assoc. 2020, 1–18. [Google Scholar] [CrossRef]
- Geenens, G.; Charpentier, A.; Paindaveine, D. Probit Transformation for Nonparametric Kernel Estimation of the Copula Density. Bernoulli 2017, 23, 1848–1873. [Google Scholar] [CrossRef] [Green Version]
- Tjøstheim, D.; Otneim, H.; Støve, B. Statistical Dependence: Beyond Pearson’s ρ. Stat. Sci. 2022, 37, 90–109. [Google Scholar] [CrossRef]
- Terasvirta, T.; Tjostheim, D.; Granger, C.W. Modelling Nonlinear Economic Time Series; OUP Catalogue; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Macrobond. Total Return. Available online: https://www.macrobond.com/ (accessed on 20 December 2021).
- Cheng, Y.-H.; Huang, Y.-M. A Conditional Independence Test for Dependent Data Based on Maximal Conditional Correlation. J. Multivar. Anal. 2012, 107, 210–226. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Index | Start Month | # Months |
|---|---|---|---|
| Australia | S&P/ASX 200 | 1 February 1980 | 502 |
| Canada | S&P/TSX Composite | 1 April 1988 | 404 |
| France | CAC 40 | 1 February 1988 | 406 |
| Germany | DAX 40 | 1 February 1971 | 610 |
| Japan | Nikkei 225 | 1 March 2013 | 105 |
| Norway | Oslo Stock Exchange, Benchmark Index | 1 February 1983 | 466 |
| Switzerland | SIX Swiss Exchange, Swiss All Share | 1 March 1999 | 273 |
| The Netherlands | Euronext Amsterdam, AEX Index | 1 May 2009 | 151 |
| The United Kingdom | FTSE 100 | 1 July 2005 | 197 |
| The United States | S&P 500 | 1 November 1989 | 385 |
| AUS | CAN | CHE | DEU | FRA | GBR | JPN | NED | NOR | USA | |
|---|---|---|---|---|---|---|---|---|---|---|
| Australia (AUS) | ∗ • | - - | - - | - - | - ∗ | - - | - - | ∗ - | - ∗ | |
| Canada (CAN) | - ∗ | - - | - - | - • | - - | - - | - - | - - | - ∗ | |
| Switzerland (CHE) | - • | ∗ • | - - | - ∗ | - - | - - | - - | - - | ∗ • | |
| Germany (DEU) | • • | - - | - - | - - | - ∗ | - - | - - | ∗ - | - - | |
| France (FRA) | • - | ∗ ∗ | - - | - - | - - | - - | - - | • - | - - | |
| United Kingdom (GBR) | - ∗ | ∗∗ - | ∗ - | • - | ∗ - | - - | - - | ∗ - | - ∗ | |
| Japan (JPN) | - ∗ | - ∗ | - - | - - | - - | - - | - • | - - | - - | |
| The Netherlands (NED) | - • | - ∗ | - - | - - | - • | - - | - - | - - | - - | |
| Norway (NOR) | - • | - - | - • | - - | - - | - • | - - | - - | - - | |
| United States (USA) | - - | - - | - • | - - | - ∗ | - ∗ | - - | - - | - - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Otneim, H.; Berentsen, G.D.; Tjøstheim, D. Local Lead–Lag Relationships and Nonlinear Granger Causality: An Empirical Analysis. Entropy 2022, 24, 378. https://doi.org/10.3390/e24030378
Otneim H, Berentsen GD, Tjøstheim D. Local Lead–Lag Relationships and Nonlinear Granger Causality: An Empirical Analysis. Entropy. 2022; 24(3):378. https://doi.org/10.3390/e24030378
Chicago/Turabian StyleOtneim, Håkon, Geir Drage Berentsen, and Dag Tjøstheim. 2022. "Local Lead–Lag Relationships and Nonlinear Granger Causality: An Empirical Analysis" Entropy 24, no. 3: 378. https://doi.org/10.3390/e24030378
APA StyleOtneim, H., Berentsen, G. D., & Tjøstheim, D. (2022). Local Lead–Lag Relationships and Nonlinear Granger Causality: An Empirical Analysis. Entropy, 24(3), 378. https://doi.org/10.3390/e24030378