
HMD-Net: A Vehicle Hazmat Marker Detection Benchmark


Abstract
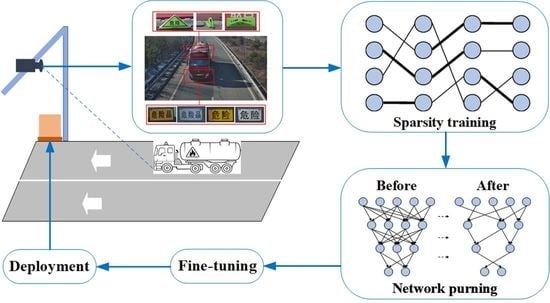
:
1. Introduction
- We release a large-scale vehicle hazmat marker dataset, which contains hazmat marker images captured under complex environmental conditions in a real expressway. To the best of our knowledge, this is the first open-sourced hazmat marker detection dataset.
- We build a hazmat marker detection network named HMD-Net, combining the merits of the cutting-edge detector and lightweight backbone, which help to achieve a trade-off between the accuracy and efficiency.
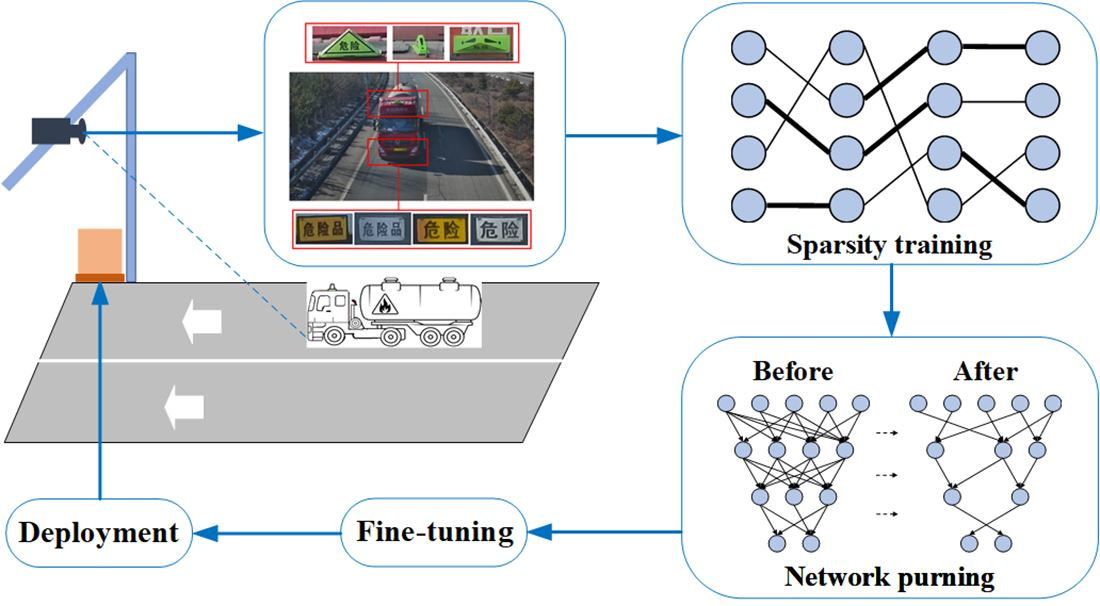
- We implement sparse training for the network and further compact the model by channel pruning operations, which enable the success of deploying the model on a resource-restricted edge device for real-time vehicle hazmat marker detection.
2. Preliminaries
2.1. Object Detection
2.2. Lightweight Models
2.3. Network Pruning
3. Hazmat Marker Detection Network
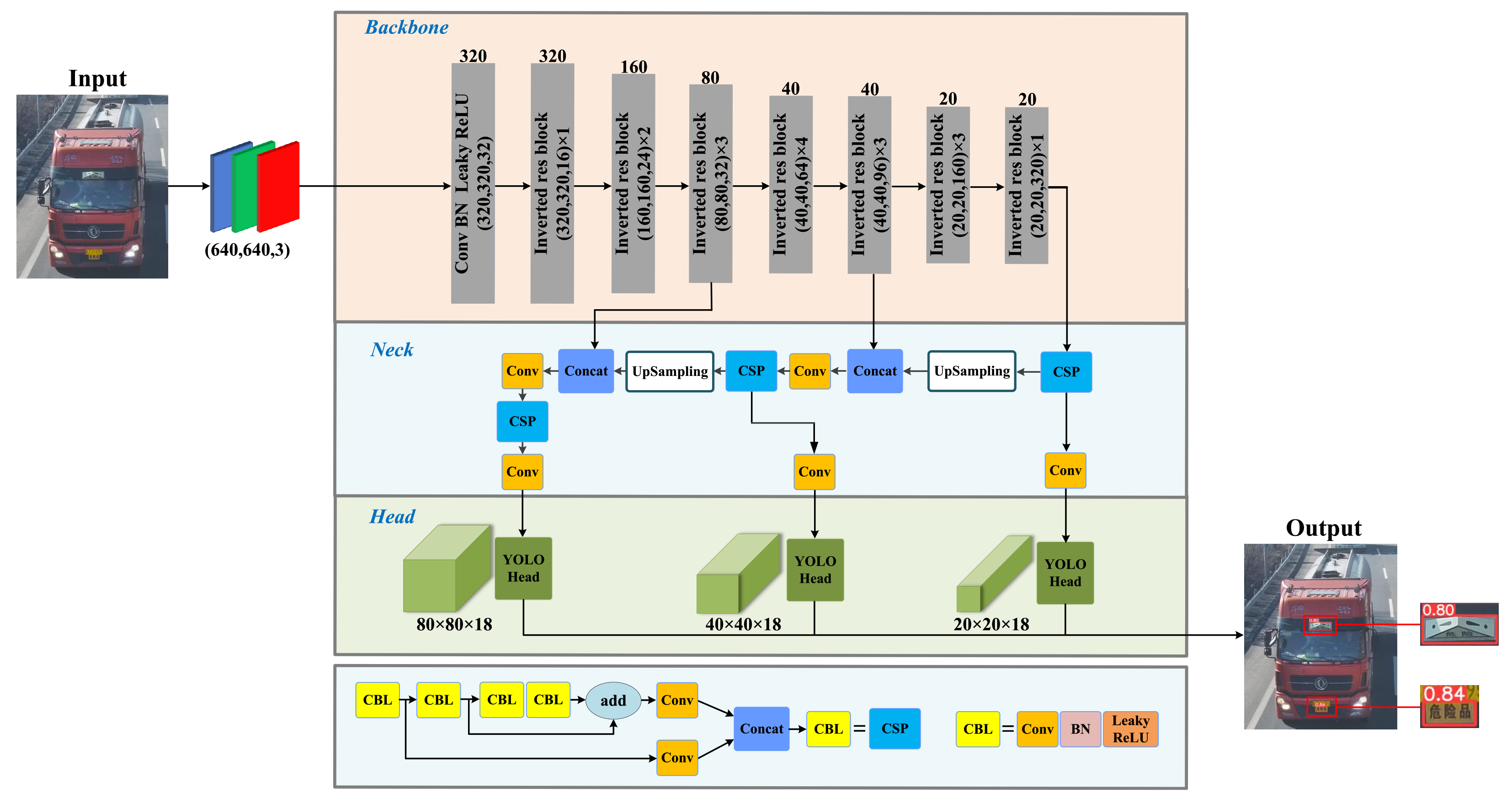
3.1. Network Architecture
3.2. Loss Functions
3.3. Channel Pruning
4. Experiments
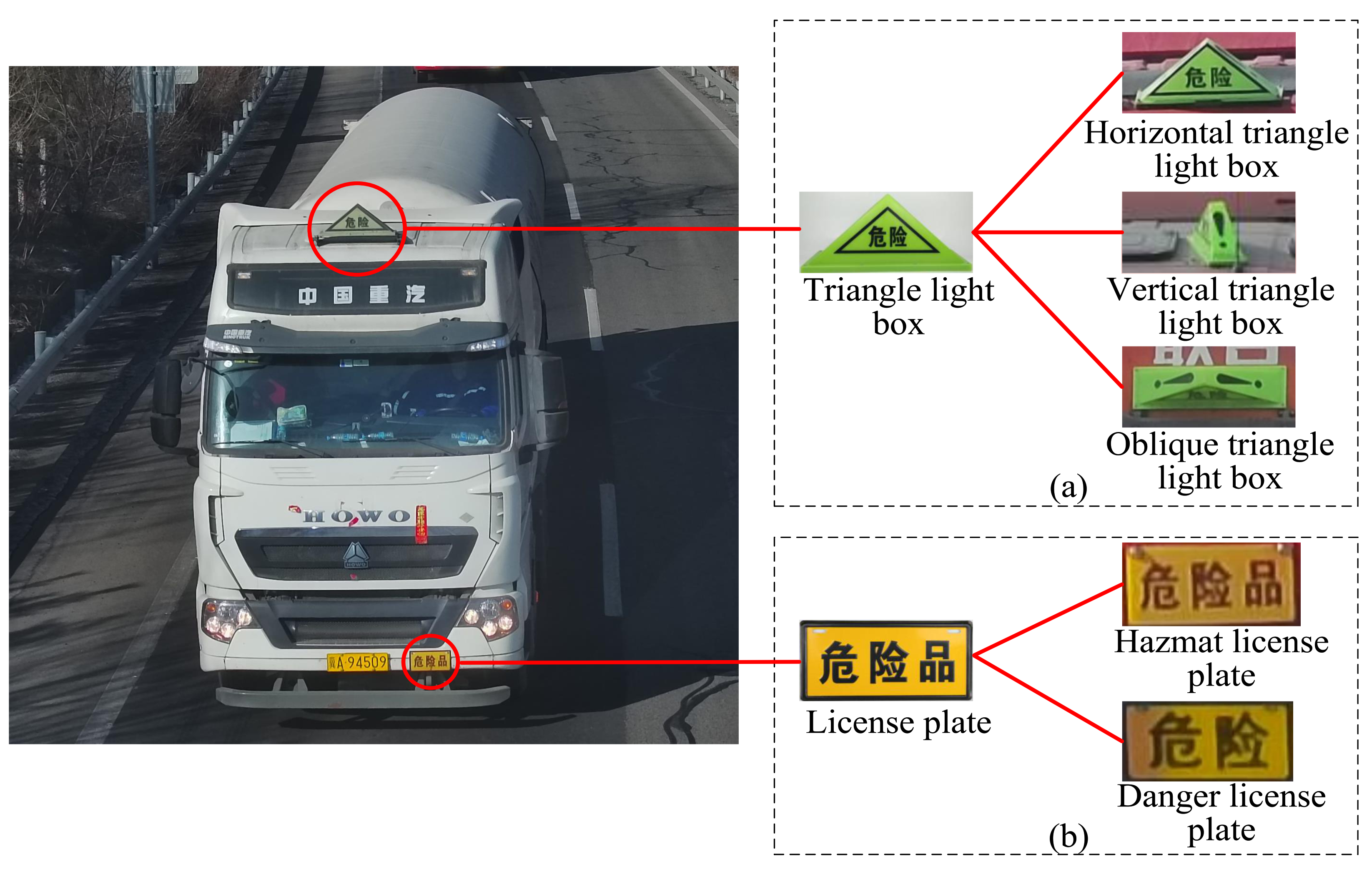
4.1. VisInt-VHM Dataset
4.2. Baseline Methods
- YOLOv3 [24]: It replaces the backbone of the initial YOLO with Darknet53 and predicts an objectness score for each bounding box using logistic regression. It extracts features from those scales using a similar concept to feature pyramid networks for multi-scale fusion, which help to detect objects of different sizes and thus significantly improve the detection accuracy.
- YOLOv3-Tiny (https://github.com/AlexeyAB/darknet, 1 February 2022): As a tiny version of YOLOv3, the backbone network uses a 7-layer convolution and Maxpool to extract features, and only retains two independent prediction branches with resolutions of and .
- YOLOv4 [26]: The backbone of YOLOv4 is CSPDarknet53, which contains 29 convolutional layers 3 × 3, a 725 × 725 receptive field and 27.6M parameters. It uses PANet as the method of parameter aggregation from different back- bone levels for different detector levels, instead of the FPN used in YOLOv3.
- YOLOv4-Tiny (https://github.com/AlexeyAB/darknet, 1 February 2022): As a small version of YOLOv4, it simplifies the backbone network of YOLOv4, uses leaky ReLU as the activation function, and removes the SPP module. In addition, FPN is used to extract feature maps of different scales, and only two prediction branches are retained.
- YOLOX-S [40]: YOLOX enables the detector of YOLO to work in an anchor-free manner and integrates some tricks like mixup augmentation [41] and optimal transport assignment [42] to further improve the detection performance. Based on YOLOX, YOLOX-S shrinks the number of channels by a large margin and serves as a small version of the standard models of YOLOX series.
- YOLOX-Tiny [40]: As a tiny version of YOLOX, it removes the hybrid enhancement and weakens the mosaic in the training phase. Compared with Yolov4-Tiny, the detection performance of Yolox-Tiny is significantly improved when the number of parameters is reduced by 1 M.
- YOLOX-Nano [40]: As a nano version of YOLOX, it follows the basic structure of YOLOX-Tiny but further simplifies the backbone network, making it can be easily deployed on mobile devices.
- YOLO-ResNet50 [43]: We replace the backbone network of YOLOv5 with Resnet50 and named YOLO-ResNet50. These residual networks are easier to optimize, and can gain accuracy from considerably increased depth.
- YOLO-MobileNetv2 [29]: We replaced the backbone network of YOLOv5 with the raw MobileNetv2 and named YOLO-MobileNetv2, which integrates a reverse residual structure with depth-wise separable convolution. MobileNetv2 is a neural network architecture that is specifically tailored for mobile and resource constrained environments.
4.3. Evaluation Metrics
4.4. Implementation Details
4.5. Performance Comparison
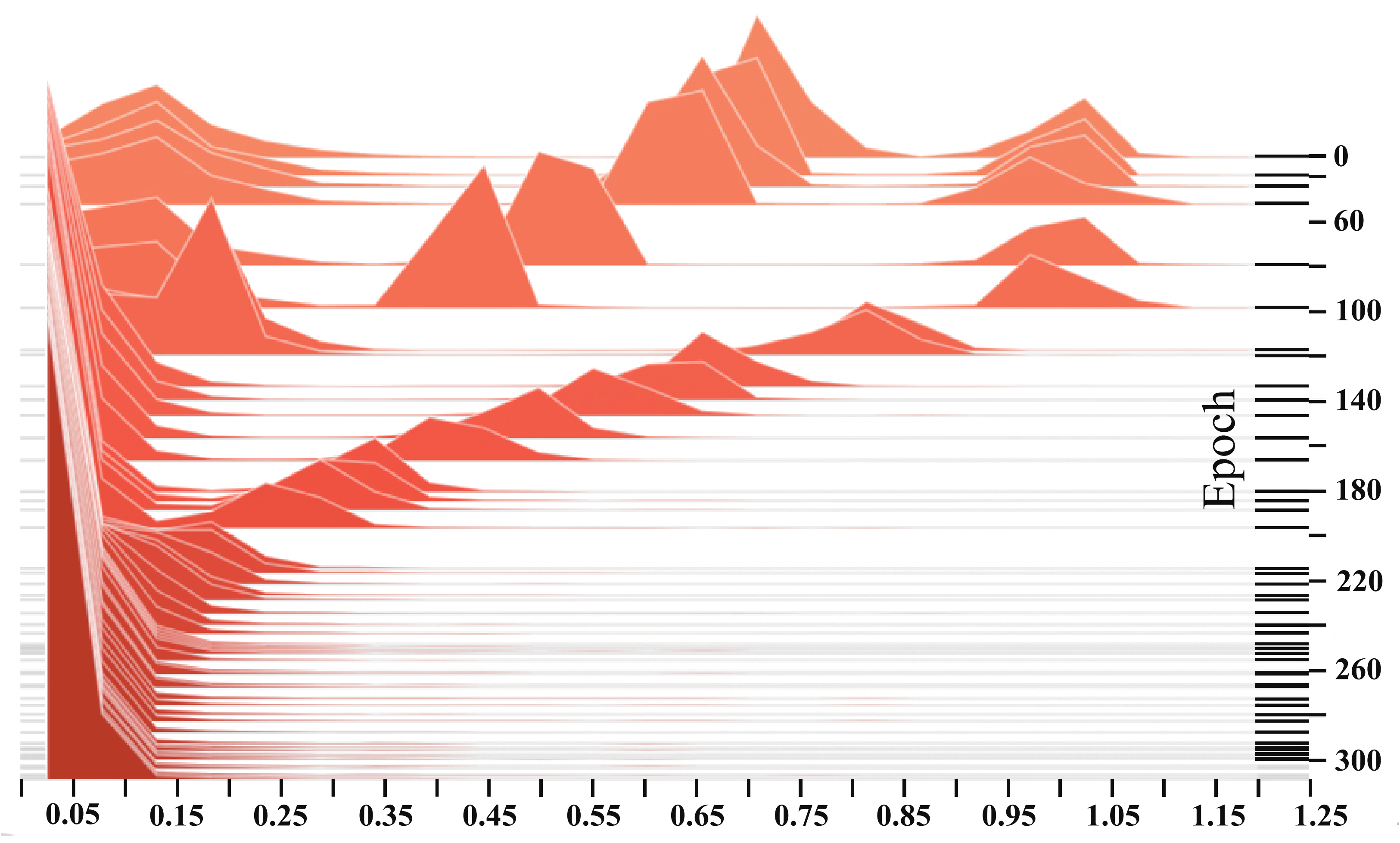
4.6. Effectiveness Verification of Sparse Regularizer
4.7. Deployment and Analysis
4.7.1. Deployment
4.7.2. Effect of Different Pruning Rates
4.7.3. Results of Ablation Studies
- YOLOv5-S: YOLOv5 with the smallest backbone that is widely deployed on edge devices.
- HMD-Net without pruning: YOLOv5 with our revised MobileNetV2 as the backbone.
- HMD-Net: YOLOv5 with our revised MobileNetV2 as the backbone and pruning.
5. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Torretta, V.; Rada, E.C.; Schiavon, M.; Viotti, P. Decision support systems for assessing risks involved in transporting hazardous materials: A review. Saf. Sci. 2017, 92, 1–9. [Google Scholar] [CrossRef]
- Liu, Y.; Qiu, T.; Wang, J.; Qi, W. A Nighttime Vehicle Detection Method with Attentive GAN for Accurate Classification and Regression. Entropy 2021, 23, 1490. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Wang, J.; Qiu, T.; Qi, W. An Adaptive Deblurring Vehicle Detection Method for High-Speed Moving Drones: Resistance to Shake. Entropy 2021, 23, 1358. [Google Scholar] [CrossRef] [PubMed]
- Gossow, D.; Pellenz, J.; Paulus, D. Danger sign detection using color histograms and SURF matching. In Proceedings of the IEEE International Workshop on Safety, Security and Rescue Robotics, Sendai, Japan, 21–24 October 2008; pp. 13–18. [Google Scholar]
- Ellena, L.; Olampi, S.; Guarnieri, F. Technological risks management: Automatic detection and identification of hazardous material transportation trucks. WIT Trans. Ecol. Environ. 2004, 77, 763–771. [Google Scholar]
- Parra, A.; Zhao, B.; Haddad, A.; Boutin, M.; Delp, E.J. Hazardous material sign detection and recognition. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2640–2644. [Google Scholar]
- Gou, C.; Wang, K.; Yao, Y.; Li, Z. Vehicle License Plate Recognition Based on Extremal Regions and Restricted Boltzmann Machines. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1096–1107. [Google Scholar] [CrossRef]
- Sharifi, A.; Zibaei, A.; Rezaei, M. A deep learning based hazardous materials (HAZMAT) sign detection robot with restricted computational resources. Mach. Learn. Appl. 2021, 6, 100–104. [Google Scholar] [CrossRef]
- Wang, W.; Yang, J.; Chen, M.; Wang, P. A Light CNN for End-to-End Car License Plates Detection and Recognition. IEEE Access 2019, 7, 173875–173883. [Google Scholar] [CrossRef]
- Cai, J.; Hou, J.; Lu, Y.; Chen, H.; Kneip, L.; Schwertfeger, S. Improving CNN-based planar object detection with geometric prior knowledge. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics, Abu Dhabi, United Arab Emirates, 4–6 November 2020; pp. 387–393. [Google Scholar]
- Xie, L.; Ahmad, T.; Jin, L.; Liu, Y.; Zhang, S. A New CNN-Based Method for Multi-Directional Car License Plate Detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 507–517. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware Faster R-CNN for Robust Multispectral Pedestrian Detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, Y.; Pu, Z.; Hu, J.; Wang, Y. Illumination and Temperature-Aware Multispectral Networks for Edge-Computing-Enabled Pedestrian Detection. IEEE Trans. Netw. Sci. Eng. 2021. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Oza, P.; Yasarla, R.; Patel, V.M. Prior-Based Domain Adaptive Object Detection for Hazy and Rainy Conditions. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 763–780. [Google Scholar]
- Gaweesh, S.; Khan, M.N.; Ahmed, M.M. Development of a novel framework for hazardous materials placard recognition system to conduct commodity flow studies using artificial intelligence AlexNet Convolutional Neural Network. Transp. Res. Rec. 2021, 2675, 1357–1371. [Google Scholar] [CrossRef]
- Sharifi, A.; Zibaei, A.; Rezaei, M. DeepHAZMAT: Hazardous materials sign detection and segmentation with restricted computational resources. arXiv 2020, arXiv:2007.06392. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Farhadi, A.; Redmon, J. YOLOv3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1804–2767. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1269–1277. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3123–3131. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal brain damage. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 598–605. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. MixUp: Beyond empirical risk minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. OTA: Optimal Transport Assignment for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:cs.CV/1512.03385. [Google Scholar]
- Samet, N.; Hicsonmez, S.; Akbas, E. Reducing label noise in anchor-free object detection. arXiv 2020, arXiv:2008.01167. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | AP (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|
| YOLOv3 | 99.41 | 78.72 | 154.57 |
| YOLOv3-Tiny | 98.81 | 8.67 | 12.91 |
| YOLOv4 | 99.48 | 81.03 | 140.98 |
| YOLOv4-Tiny | 96.62 | 5.87 | 16.14 |
| YOLOX-S | 90.88 | 8.94 | 26.64 |
| YOLOX-Tiny | 90.89 | 5.03 | 15.14 |
| YOLOX-Nano | 90.86 | 2.24 | 6.87 |
| YOLO-ResNet50 | 99.55 | 27.85 | 75.9 |
| YOLO-MobileNetv2 | 99.39 | 3.56 | 6.6 |
| HMD-Net | 99.35 | 0.29 | 1.2 |
| Model (Pruning Rate) | AP (%) | Parameters (M) | FLOPs (G) | FPS () |
|---|---|---|---|---|
| HMD-Net () | 99.43 | 0.42 | 1.4 | 37 |
| HMD-Net () | 98.53 | 0.13 | 0.8 | 39 |
| HMD-Net ( by default) | 99.35 | 0.29 | 1.2 | 38 |
| Model | AP (%) | Parameters (M) | FLOPs (G) | FPS () |
|---|---|---|---|---|
| YOLOv5-S | 99.46 | 6.85 | 11.5 | 32 |
| HMD-Net without pruning | 99.43 | 1.10 | 2.3 | 35 |
| HMD-Net | 99.35 | 0.29 | 1.2 | 38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Wang, J.; Wang, T.; Li, X.; Yu, H.; Li, Q. HMD-Net: A Vehicle Hazmat Marker Detection Benchmark. Entropy 2022, 24, 466. https://doi.org/10.3390/e24040466
Jia L, Wang J, Wang T, Li X, Yu H, Li Q. HMD-Net: A Vehicle Hazmat Marker Detection Benchmark. Entropy. 2022; 24(4):466. https://doi.org/10.3390/e24040466
Chicago/Turabian StyleJia, Lei, Jianzhu Wang, Tianyuan Wang, Xiaobao Li, Haomin Yu, and Qingyong Li. 2022. "HMD-Net: A Vehicle Hazmat Marker Detection Benchmark" Entropy 24, no. 4: 466. https://doi.org/10.3390/e24040466
APA StyleJia, L., Wang, J., Wang, T., Li, X., Yu, H., & Li, Q. (2022). HMD-Net: A Vehicle Hazmat Marker Detection Benchmark. Entropy, 24(4), 466. https://doi.org/10.3390/e24040466