1. Introduction
A brain network is defined by its nodes and edges. Different regions are considered nodes. Edges are the interactions between different regions. Each region consists of many voxels, and each voxel has a time series derived from fMRI data. There are different methods for defining the edges or interactions between different nodes. Functional connectivity (FC) is a well-known approach that produces a functional brain network. Analytically, FC is defined as the statistical interaction between the temporal activities of two distinct regions. Interactions between the regions support different cognitive processes [
1]. Deviation from the FC structure of normal individuals is considered a biomarker for some diseases such as schizophrenia [
2], bipolar depressive disorders [
3], and attention deficit disorder [
4]. Therefore, using FC as a biomarker has been widely considered recently.
Various methods have been proposed to estimate the FC between two regions. Some measures such as Granger causality (GC) and transfer entropy calculate the directed connectivity between two regions, while others such as Pearson correlation, independent component analysis (ICA), and coherence measures calculate undirectional interactions [
5,
6]. Moreover, some new measures such as interaction information defined based on mutual information have been introduced to estimate FC [
7]. Among the undirected measures focused on in this study, Pearson correlation (PCor) is the most common approach. While the calculation of this measure is straightforward, it has some disadvantages. Recent studies have found that PCor is not sufficient to characterize the statistical dependence between two regions [
8]. There are two distinct limitations to the linear correlation methods which can detect some spurious connections. Using this measure, signals from two anatomically separated brain regions may appear correlated and the regions may appear functionally connected [
9,
10,
11,
12]. However, a strong correlation between two regions may not guarantee that there is a functional connection between the underlying neurons. For instance, external or common inputs can lead to the correlation.
Linear correlation has two important disadvantages as an FC measure. First, the linear correlation is a bivariate measure that needs a single time series for each region as an input. Typically, multiple time series of voxels within each region are reduced to a single time series by averaging across voxels or by taking the first principal component. Techniques such as multivoxel pattern analysis and representation similarity analysis have shown that there are relative patterns across voxels within each region [
13,
14]. This reduction discards the spatial information distributed in thousands of signals within the voxels in a given region [
15,
16]. For instance, it has been shown that some information about mental processes and cognitive states is detected by multivariate pattern analysis, while average activity discards this information [
17,
18]. The second limitation of PCor is that the linear correlation cannot detect the nonlinear dependencies between brain regions. Previous studies have shown that there are nonlinear dependencies between time series during the resting state. This nonlinear analysis of fMRI signals performs better than linear correlation [
19,
20,
21,
22]. Su et al. [
23] have found that considering nonlinear dependencies between fMRI signals can better discriminate schizophrenic patients from healthy subjects. Moreover, individual cognitive differences can be predicted better by taking into account the nonlinear properties of region interactions [
24].
Recently, using information-theoretic quantities such as mutual information and transfer entropy has become more attractive in analyzing neuroimaging data [
25]. One application of these quantities is to find the interaction between neurons [
26,
27] or brain regions [
28]. For instance, a recent paper has proposed using a new measure, interaction information, to estimate the FC using the mutual information. Although this method takes into account the nonlinear interaction, it ignores the spatial information within voxels by taking the average across voxels [
7]. Generally, an outstanding advantage of the information-theoretic quantities such as mutual information is that they do not rely on the prior assumptions about the relationship between the time series. On the other hand, linear correlation implicitly assumes a multivariate normal distribution for random variables.
In this paper, we propose using an information-theoretic measure as a functional connectivity metric that can overcome the two mentioned limitations. To this end, both nonlinear interaction and multidimensional signals have been considered. Here, we call this measure multivariate mutual information (mvMI). This measure is defined by mutual information and estimated by using the Gaussian copula notion. It is worth noting that we use the “multivariate” term as we use all voxel activities within each region to estimate the functional connectivity rather than using the average activity. Mutual information can be calculated by means of different approaches. Because of the complexity of computation and implementation, mutual information has gained less attention in the functional connectivity area. Using a copula as a statistical concept can simplify the
MI estimation for experimental data. Moreover, we show that by using a copula, mutual information can be extended to calculate the dependence between two multidimensional variables. This property can overcome the limitation of PCor which needs univariate inputs. Here, we use Gaussian copula mutual information which was proposed by Ince and colleagues to estimate mutual information [
29]. We start by presenting the theoretical background of the proposed measure, multivariate
MI (mvMI). Then, we generate simulation data and define different scenarios to evaluate the performance of the proposed measure in the face of the mentioned limitations. The simulation results indicate that mvMI can detect nonlinear and multidimensional dependences. Moreover, it is less sensitive to additive noise. Then, we apply the proposed measure to real resting-state fMRI data. We compare the proposed measure with linear correlation in terms of significance level and randomness. We show that the mvMI-based functional network architecture is closer to the well-known topology of the brain, i.e., small-world architecture. As a complex network that has a highly efficient small-world organization, the small-world organization of the brain supports efficient information flow at low wiring and energy cost [
30]. Brain dysfunctions and diseases lead to a deviation from the small-world architecture, shifting towards a random structure.
In other words, using mvMI as an estimator of FC leads to a nonrandom topology. Finally, we measure the similarity of the FC matrices obtained for different subjects using different FC measures. The results show that the similarity between subjects in the mvMI approach is larger than that in the conventional PCor approach.
2. Materials and Methods
2.1. Participants
Fifty-five young healthy right-handed individuals were recruited from the academic community and the local population living in Tehran, Iran. Participants’ age was in the range of 18–26 years (22 females and 23 males). They were university undergraduate paid volunteers. Participants completed a brief questionnaire including questions regarding medical or psychiatric disorders. Ethical approval for the study was obtained from the Iran University of Medical Sciences, Tehran, Iran.
2.2. MRI Data Acquisition and Preprocessing
All MRI data were acquired on a Siemens 3 Tesla scanner with a 64-channel head coil. Structural images were acquired using a magnetization-prepared rapid acquisition with gradient echo (MPRAGE) pulse sequence with the following parameters: TR/TE = 2500/3.18 ms, flip angle = 8 degrees, voxel size = 1 mm isotropic, and field of view = 244 mm. Echo-planar images sensitive to BOLD contrast were acquired using the following parameters: TR/TE = 2000/30 ms, flip angle = 80 degrees, slice thickness = 4 mm, and voxel size = 4 × 3 × 3 . During the resting-state fMRI scan, the participants were asked to remain awake with their eyes open and not to think about anything in particular.
Functional MRI data were preprocessed using the CONN functional connectivity toolbox in MATLAB 2017b (
https://web.conn-toolbox.org/ accessed on 15 January 2021) [
31]. During the preprocessing steps, the functional images were slice-timing corrected, realigned, normalized (in the 2 mm Montreal Neurological Institute (MNI) space), and smoothed. The Artifact Detection Tool was used to detect outliers (>3 SD and >0.5 mm) for subsequent scrubbing regression. The structural images were segmented into gray matter, white matter (WM), and cerebral spinal fluid (CSF) and normalized to the MNI space. Then, linear regression using WM and CSF signals, linear trend, and subject motion (six rotation/translation motion parameters and six first-order temporal derivatives) was conducted to remove confounding effects. The residual blood-oxygen-level-dependent (BOLD) time series was band-pass filtered (0.01–0.1 Hz).
2.3. Information-Theoretic Estimation of Functional Connectivity
2.3.1. Information Theory Quantities
Information theory is a mathematical framework for the quantification, storage, and communication of information. Entropy, mostly known as the Shannon entropy, is a key quantity in information theory defined as the amount of uncertainty involved in the value of a random variable. Let
X and
Y be two continuous random variables having marginal pdf
and
respectively. Denote by
the joint pdf of
X and
Y. The Shannon entropy of variable
X is defined as
The joint entropy of
X and
Y is defined as
Mutual information is another fundamental quantity used to calculate the amount of information about one random variable by observing other random variables. For two discrete random variables,
X and
Y, mutual information is given by the following formula:
Mutual information can be rewritten based on Shannon entropy as
2.3.2. Information-Theoretic Quantities of Gaussian Variables
For the multivariate Gaussian random variables, there is a closed-form solution for entropy:
where
and
k are the covariance matrix and dimensionality of
X, respectively. Using this closed-form expression of entropy leads to an exact definition of mutual information. Based on Equations (4) and (5), the mutual information of two random variables with Gaussian distribution can be calculated as follows [
32]:
where
and
are the covariance matrices of
X and
Y, respectively, and
is the joint covariance matrix of variables
X and
Y. For two univariate random variables,
X and
Y, Equation (6) can be rewritten based on the Pearson correlation between
X and
Y, i.e.,
Corr(
X,Y), as follows:
2.3.3. Copulas
A copula is another approach for determining the dependency between random variables. The copula is a multivariate cumulative distribution function for which the marginal probability distribution of each variable is uniform in the interval [0, 1]. Sklar’s theorem states that a multivariate cumulative distribution function (CDF),
, can be defined by its marginal CDF,
, and a copula
C:
The theorem indicates that the copula is unique if the marginals
are continuous [
33]. Notably, a copula can be considered as the joint CDF of the random vector
, where each element is derived using the following transformation:
Thus, the copula can be defined as
The joint probability density function of random variables can be written as
where
is the copula density. Using Equation (3), mutual information can be rewritten as follows:
Thus, the
MI is equivalent to the negative of copula entropy.
MI between two random variables
X and
Y with transformation
can be obtained as
Thus, the
MI between two random variables can be obtained independently of the marginal distribution of the variables. For more details about the copula and its properties, see [
34].
2.3.4. Estimating MI Using Gaussian Copula
Calculating the mutual information through (3) is computationally complex. In other words, as estimation of the joint probability density function (pdf) of non-Gaussian distributed data is hard, the estimation of mutual information is also difficult. Thus, little attention has been paid to this method as an estimator of FC. In the previous section, we illustrated that copulas offer a natural approach for estimating mutual information, independently of the marginal distributions. As the copula entropy and thus the
MI do not depend on the marginal distributions, without loss of generality, the marginals can be transformed to the standard Gaussian distributions. Since the copula is mostly unknown, Robin Ince and colleagues used the Gaussian approximation [
29]. Here, we use the Gaussian copula as an estimation for the unknown copula.
The Gaussian copula entropy for two random variables
X and
Y can be derived as follows [
32]:
where
r is the correlation between the transformed Gaussian random variables. It is obvious that if the real copula is not Gaussian, the
MI derived using (14) is not accurate. Since for a given mean and covariance matrix, the joint Gaussian distribution has the maximum entropy [
35], the Gaussian copula also has the maximum entropy. As
MI is the negative copula entropy, the Gaussian copula provides a lower bound for the true
MI [
36].
2.3.5. Multivariate Mutual Information in Neuroimaging
FC is defined as the statistical dependence between each pair of brain regions. Each region consists of many voxels, and each voxel has a time series that is derived from the fMRI data. Most studies summarize each region’s activity in a single time series obtained by taking the average across voxels. This dimensional reduction from the voxel dimension to a one-dimensional signal leads to the loss of spatial information between voxels. The main reason for this dimension reduction is that most FC quantities such as Pearson correlation’s inputs should be one-dimensional. Mutual information as a dependence quantity has the capability to estimate the dependence between two multidimensional random variables. In the previous section, we showed that
MI can be calculated by means of the copula concept which is independent of the marginal distribution (Equation (12)). For a given covariance matrix
, the Gaussian copula can be written as
where
is the inverse cumulative distribution function of a standard normal distribution and
is the joint cumulative distribution function of a multivariate normal distribution with zero mean and correlation matrix equal to
. The density function can be written as
Equation (4) is the entropy of a multivariate normal distribution. We can use this equation to find the entropy of the Gaussian copula.
Here, to find the interaction between two regions which are multidimensional variables, we transform the marginal distribution of the variables to standard normal distribution. This transformation is performed since the MI is independent of the marginal distribution. Then, we use (4) to find the copula entropy of transformed variables, which is equal to MI based on (12).
2.4. Functional Connectivity Measures
Linear correlation methods such as Pearson correlation are the simplest approaches for calculating FC. For two time series,
x and
y with n time points, the Pearson correlation is defined as follows:
where
and
are the mean values of
x and
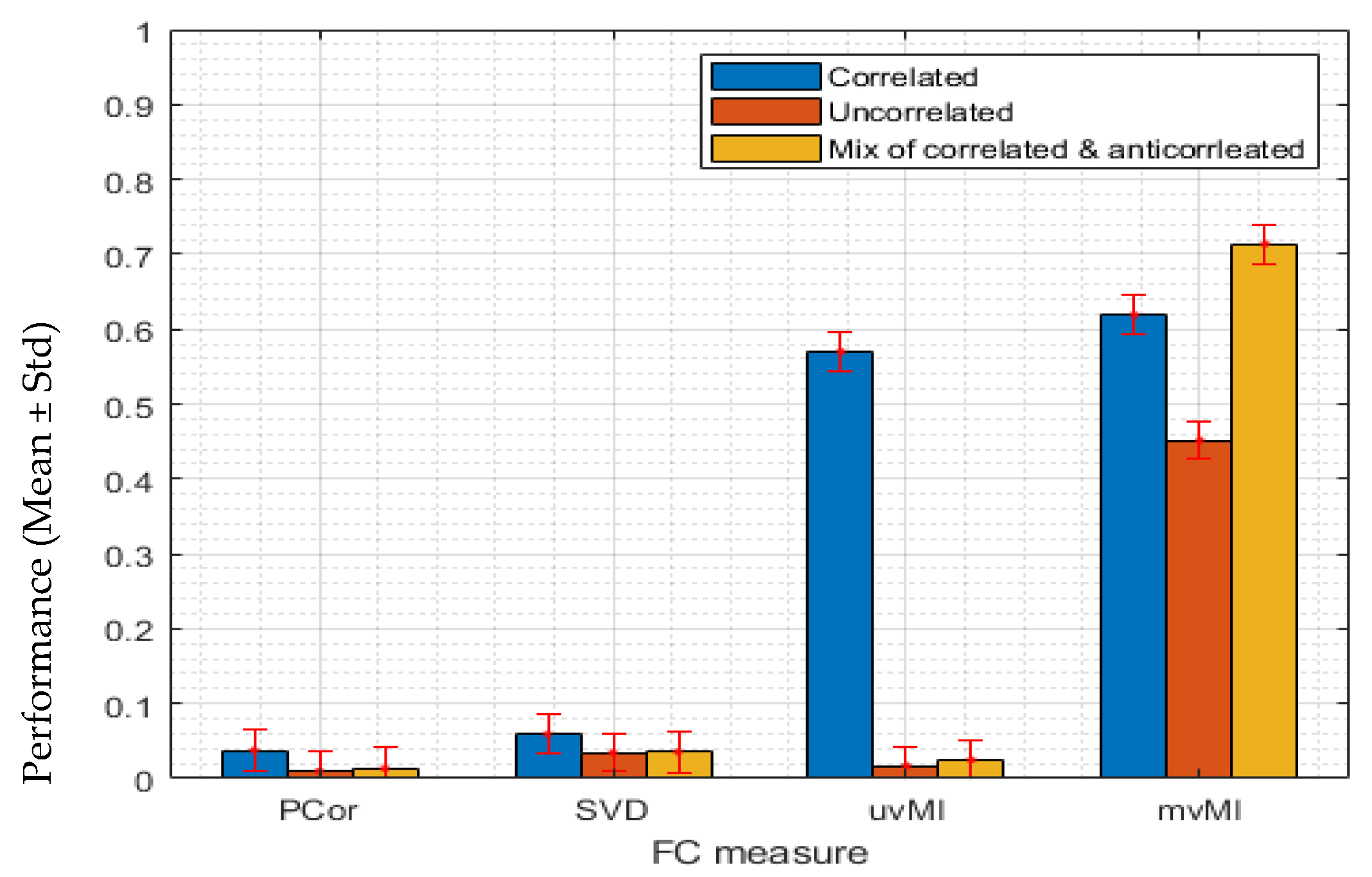
y, respectively. This measure can only detect the linear dependence between two univariate time series. Each region contains many signals related to different voxels. Before calculating the correlation between two regions, it is necessary to reduce each region’s activation to a single time series. Taking the average across voxels within each region is the most common method for this dimension reduction in functional connectivity studies. The Pearson correlation which uses the average signal is called PCor. If the voxel activities in a region are homogeneous, this approach is the best choice. However, as the homogeneity in the regions decreases, an average time series is not a good representative of the regional activity. Singular value decomposition is an alternative method, whose advantage arises when the regions are not homogeneous. As the second measure of FC, SVD, we summarize each region’s activity using the temporal singular vector corresponding to the largest singular value of the regional activity.
MI is a more general measure. As a multivariate estimator, one important feature of
MI is that it is capable of finding the statistical dependence between two multidimensional variables. Thus, for calculating the interaction between two regions with multiple voxels, it is not necessary to reduce the voxel time series within each region to a single time series, e.g., the average time series.
Another advantage of MI over PCor is that it is a nonlinear dependence estimator. To pinpoint which aspect of mvMI leads to a difference from PCor, we use both univariate and multivariate versions of MI in our investigation. For the univariate version, which we name uvMI, we use MI to estimate the association between the average time series of two brain regions. For the multivariate version, named mvMI, we use multiple time series from each region to quantify the FC between two regions. To calculate the mvMI, we start with a principal component analysis over each region’s time series and select the first 5 principal components of each region. Indeed, by applying principal component analysis (PCA) to each region’s time series, we select the most important components as a representation of that region’s activities. Then, FC between two regions is estimated by calculating the MI between the 5 selected principal components of the regions.
Unlike the PCor, which has a value within the range of −1 to 1, the mutual information’s value is more open-ended and can range from 0 for complete independence to infinity for complete dependence. To have a fair comparison, we rescale both MI measures to the [0, 1] range using a power transformation. As the MI is a positive measure, the absolute values of PCor have been used throughout this article.
2.5. Simulation Design
We propose using MI as an FC metric because of two advantages of MI over Pearson correlation, the capabilities of detecting nonlinear and multidimensional dependence. In the previous section, a computationally efficient approximation of MI was presented. To evaluate if the approximation preserves the considered advantages, we use simulated data. We compare the performance of MI-based quantities and Pearson correlation through different dependencies between two simulated regions.
We simulate the time series of two distinct regions containing 100 and 150 voxels with 500 time points. The time series of the first region is generated using a multivariate normal distribution. The time series of the second region is calculated from those of the first region using a given mapping function f. This function controls the interaction between the two regions. It can be a nonlinear function such as a power function. By changing f, the performance of MI for linear and nonlinear interactions can be evaluated. To evaluate the performance of different measures by the simulated data, we estimate the null distribution of each measure by calculating the FC value between the regions of the null data, which is obtained by shuffling the time points randomly for each voxel. Then, we calculate the distance between each FC value and the 95th percentile of the null distribution. This distance is considered as the performance quantity.
Simulation Scenarios
In order to compare the performance of the mvMI measure with Pearson, four different simulated scenarios have been defined. In each scenario, we consider four different measures of FC, two Pearson correlation-based measures, and the two mutual information-based measures. Through different scenarios, we assess the performance of the proposed measure (mvMI) from different aspects. In each scenario, a different mapping function f is defined to generate the time series in the second region, based on the first region’s time series. Let
Xt and
Yt be two vectors containing the
Nx and
Ny values which represent the voxel activation within two regions at time point
t. For each scenario, the second region’s activation,
Yt, is defined as a function of the first one,
Xt:
where
T is the mapping matrix and
f is the function that determines the relation between the two regions. For example, for a linear voxel-to-voxel mapping from region 1 to region 2,
f is a multiplication function and
T is an
Nx ×
Ny mapping matrix in which
Nx ×
Nx elements are an identity matrix and the remaining elements are just random noise An independent Gaussian noise is added to both
Xt and
Yt as the measurement noise,
:
For instance, to compare the performance of different measures in detecting nonlinear interaction, we use the elementwise power function as a nonlinear function. Indeed, the second region’s activity at time
t is derived as
The homogeneity of voxels in a region is an important property that directly affects the average time series. In the situation where all voxels within a region have the same activation, reducing the ROI activation to a single time series does not lead to any loss of information. As the homogeneity of the ROI activation decreases, a greater amount of information will be lost by taking the average. We use the covariance matrix as a parameter to control the first region’s homogeneity level. In each scenario, we consider three different covariance matrices for the first region’s time series which demonstrates the homogeneity level of that region. We consider two extreme covariance matrices, constant and identity. We use the constant matrix to generate homogeneous activity, i.e., the time series are highly positively correlated. For identity one, the time series within each region will be uncorrelated or independent. One middle condition is taken into account which is constituted of two constant positive and negative values which indicate positively correlated and anticorrelated, respectively. These covariance matrices are illustrated in
Figure 1. Through these scenarios, the performances of different FC measures, PCor, SVD uvMI, and mvMI, are examined. Nonlinearity, multivariate dependencies, and sensitivity to the structured noise are the main properties that are investigated through these scenarios.
2.6. Real Data Analysis
The brain contains functional communities called resting-state networks. These networks show high-level within-community functional interaction and low-level interaction strengths between communities. The connections can be divided into within- and between-network categories. If the two nodes linked by the connection are located in the same network, the connection is considered a within-network connection; otherwise, the connection is considered a between-network connection. At first, we compare the functional brain networks derived using different estimators by calculating the correlation between different functional connectivity matrices for within and between connections.
Using different approaches, we compare the performance of the proposed estimator (mvMI) with the other measures. For each connection and estimator, it is examined whether the connections are significant or not. By shuffling the time points of voxel time series within each region, the null distribution is obtained. By comparing the true value of each connection with the 95th percentile threshold of the null distribution, the connection is characterized as significant or insignificant. If the true value is greater than the 95th percentile level, it will be considered a significant connection.
As a property of a normal functional network, the randomness level of each measure’s connectivity matrix is measured. Previous studies have illustrated that the brain network has a nonrandom pattern. Deviation from this pattern leads to known neuropathologies [
37]. For each connectivity measure, the nonrandomness level is determined using the Networkx, a graph theory package (
https://networkx.org/ accessed on 15 December 2021). The main idea is to quantify how close a connectivity matrix is to a random matrix containing random elements. There is a baseline for functional brain networks which is dominated by common resting-state networks across participants. Indeed, recent studies have indicated that resting-state functional brain networks share certain similar patterns including the connectivity weights and the spatial distribution of resting-state networks [
38,
39]. For instance, the default mode network (DMN) and the frontoparietal network are two well-known networks thought to be activated during the resting state. These networks do not vary significantly across different healthy subjects [
40]. To investigate the similarity of functional networks between different subjects, the correlation between each subject’s connectivity matrix and the average connectivity matrix is computed.
4. Discussion
In summary, we investigated multivariate Gaussian copula mutual information as an estimator of FC. This estimator can be used as an alternative to the widely used measure PCor, which has two important limitations. These limitations motivated us to use mvMI, which is a more robust estimator than the linear correlation methods [
46]. As a linear measure, PCor misses nonlinear dependences. Another limitation of PCor is that it can only utilize the univariate time series as inputs. Consequently, the time series within each region should be reduced to a single time series using methods such as averaging. This dimension reduction causes a loss of voxel-level spatial information. Using simulated data, we compared the performance of mvMI with PCor from different aspects and showed that, in contrast to PCor, mvMI detects both linear and nonlinear interactions. Moreover, in situations where the ROIs have inhomogeneous activity, we showed that mvMI detected connectivity ignored by PCor. In addition, the sensitivity of FC measures to additive Gaussian noise was examined. The results illustrated less noise sensitivity of mvMI compared to the other measures.
We started our investigation on real data by comparing the connectivity matrices derived using different FC estimators. We evaluated the similarity between mvMI and PCor across different resting-state networks. The connections were divided into within- and between-network connections. All FC measures were similar in estimating within-network connections. For between-network connections, they behaved differently, and mvMI outperformed the others, especially for the visual and limbic networks. To better recognize which features of mvMI lead to this capability, we included the univariate version of MI (uvMI) in our investigations.
We verified the significance of each connection by comparing the FC value with the 95th percentile of the null distribution. We found that for between-network connections in which mvMI and PCor are considerably different, PCor connections were insignificant. For example, across visual and limbic networks, PCor was less similar to mvMI. Most insignificant connections of PCor were in these networks (see
Figure 8b and
Figure 9c). As an example, the similarity between PCor and mvMI for connections between the DMN and the frontoparietal network was high, and the number of insignificant PCor connections between these networks was small. In other words, the number of insignificant connections of PCor was directly correlated with its similarity with mvMI. The insignificant connections were those that were more different from mvMI. One approach to remove the insignificant PCor-based connections between networks is thresholding. In our investigation, we analyzed the performance of thresholding with mvGCM. Thresholding removed the insignificant connections but also removed some significant connections. Actually, some weak connections may be important in explaining the cognitive differences of individuals. For example, it has been declared that IQ variance is mostly explained by moderately weak, long-distance connections, with only a smaller contribution of stronger connections [
46]. Thus, thresholding methods may destroy some useful information.
According to previous studies, a functional brain network has a nonrandom structure with a specific architecture that supports different cognition functions [
47]. For example, the brain has a small-world topology of short path length and high clustering. Deviation from this nonrandom topology is considered a biomarker of some diseases. It has been shown that there is an alteration in the small-world organization of the functional network of the brain of some patients. In other words, there is a deviation toward a random structure [
48]. In addition, there is an association between the randomness level and ADHD disorder, where there is an increase in randomness during childhood and early adulthood [
49]. To better understand these disorders, characterization of the nonrandomness of brain connectivity has gained attention in recent years [
34]. Therefore, we assessed whether the proposed method generated a random structure or not. We found that the nonrandomness level of mvMI is greater than that of the other measures.
The resting-state networks, especially the DMN, are consistent across different subjects. We measured the similarity of functional networks across subjects. We found that the similarity of the connections estimated for different subjects using mvMI was the highest for both within- and between-network connections and was approximately 0.8. This result is consistent with that of a recent paper which has declared that the shared pattern of functional networks across different subjects generates an intersubject similarity of 0.822 ± 0.061 [
38].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










