
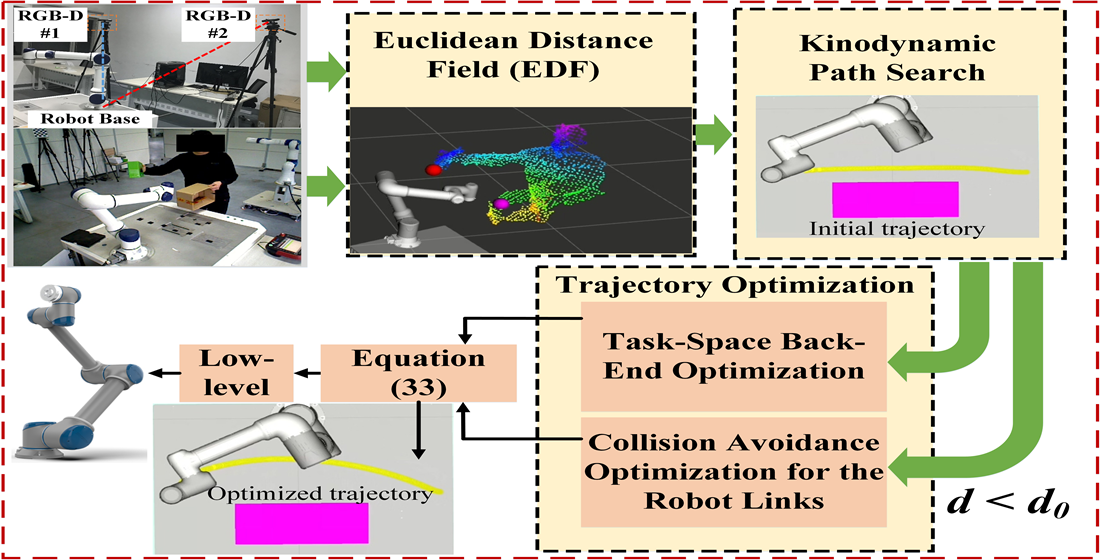
An Efficient Online Trajectory Generation Method Based on Kinodynamic Path Search and Trajectory Optimization for Human-Robot Interaction Safety

 ,
,
Abstract
:
1. Introduction
- (1)
- A complete and effective real-time online trajectory generation framework is developed bottom-up, which mainly includes kinodynamic path search, B-spline trajectory optimization, and links collision avoidance optimization.
- (2)
- A path search method considering links constraints and a trajectory optimization method using the B-spline convex hull property are presented. The former transforms a position-only geometric search into an efficient kinodynamic search by state-space motion primitive generation and heuristic cost evaluation. The latter fully considers dynamic constraints and converges quickly to generate a safe, dynamically feasible, and smooth trajectory.
- (3)
- A constraint-relaxed links collision avoidance optimization method is adopted, which effectively avoids link collisions while tracking the optimized task space trajectory.
- (4)
- The proposed algorithm is deployed on a physical collaborative robot experimental platform. Detailed simulation comparison experiments and real-world experiments are performed to demonstrate the effectiveness of the proposed method.
2. Problem Statement
- A safe and feasible initial trajectory from the starting position to the goal needs to be searched. Traditional path-planning algorithms such as A*, Dijkstra, and the sampling-based method RRT usually do not consider the nonstatic initial state of the robot, so there are problems in replanning. As shown in Figure 1a, the geometric shortest path may turn sharply, which may lead to the failure of path parameterization. Since the replanning has non-general dynamic characteristics, it is necessary to use the kinodynamic planner to achieve a nonstatic initial state to ensure dynamic feasibility.
- Since the initial trajectory search does not consider the distance cost, the initial trajectory tends to be close to obstacles (see Figure 1b). In addition, the uncertainty of dynamic obstacle motion may also make the initial trajectory unfeasible. Therefore, trajectory optimization and replanning strategies are necessary.
- Collision avoidance of the robot links needs to be considered. As shown in Figure 1c, although the red trajectory indicated by “yellow star” is feasible for the end-effector, the robot links will collide with obstacles if the end-effector runs along with it.
3. Links-Constrained Kinodynamic Path Search
| Algorithm 1 Links-constrained Kinodynamic Path Search Algorithm |
Input: Inital and goal state: , ; The safe distance threshold: ; Obstacle: ; Discretized control input sets U Output: Time-optimal initial trajectory: ;
|
3.1. Motion Primitives for Node Expansion
3.2. Search Cost Evaluation
4. Trajectory Optimization
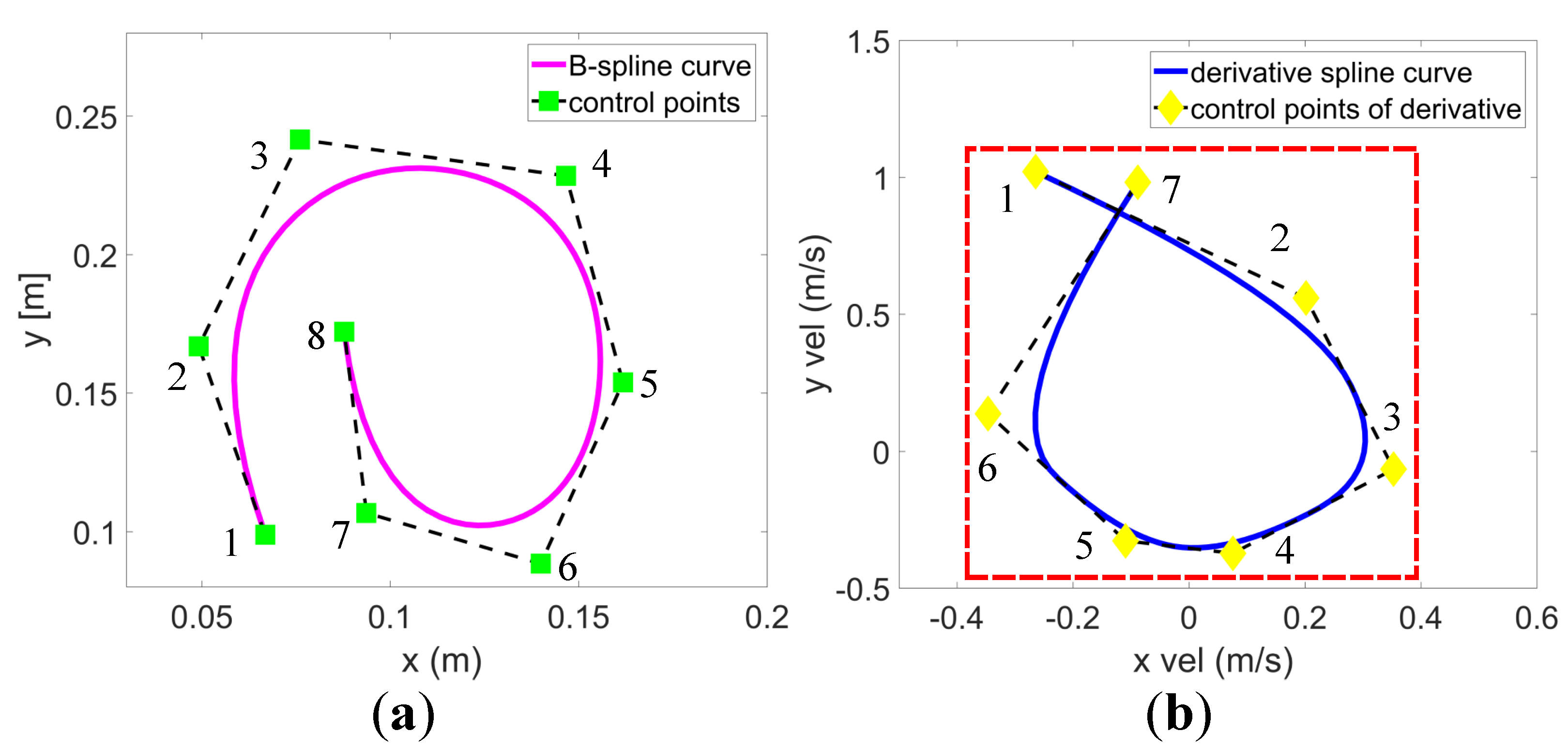
4.1. B-Spline Curve Formulation
4.2. Optimization Approach
- (1)
- Smoothness costs: For the smoothness penalty term, an elastic band function is designed to describe the smoothness of the position control points, which only uses the geometric information of the control points without involving time information. Moreover, the smoothness of the B-spline trajectory can also be improved by minimizing the acceleration and jerk control points [47]. Then, the smooth term penalty function is defined aswhere the scaling factor ensures that the relative distance between two adjacent control points remains unchanged, and is calculated between the control points. In fact, the first term of the smoothing function treats all control points as a deformable elastic band and behaves as an internal contractive force to make the trajectory as evenly distributed on the straight line as possible. The second and third terms smooth the whole trajectory by minimizing higher-order derivatives.
- (2)
- Collision costs: Since the initial trajectory may be close to the obstacles, the collision penalty function can keep the control point away from the obstacles by the repulsive action [7]. Therefore, the collision penalty term is defined aswhere is the minimum Euclidean distance between control points and the obstacles, is the repulsive force at the safe distance threshold , represents the maximum magnitude of the repulsive force, and is a shape parameter. This design allows the repulsive force magnitude to reach its maximum value when , while approaches 0 when and no repulsive force is generated.To facilitate fast distance detection, the Euclidean distance field (EDF) of the occupancy volume is calculated by an efficient algorithm [48] with complexity , where is the number of voxel grids, and N represents the size of the volume along a single axis. Furthermore, the trilinear interpolation technique is adopted to enhance the detection accuracy of distance [33], which compensates for voxel grid discretization errors and is beneficial for numerical optimization [41].
- (3)
- Feasibility costs: The higher-order derivative of a B-spline curve is also a B-spline with the convex hull property. In other words, if the derivative control points are bounded within the convex hull, expanded by the maximum allowed derivative, then the derivative-spline is also bounded [43]. Based on this property, we ensure the feasibility of the trajectory by designing a penalty function that constrains the higher-order derivatives of the control points as follows:where , , and are the weights of the penalty terms of velocity, acceleration, and jerk, respectively. The penalty term is defined as
4.3. Numerical Optimization Method
| Algorithm 2 L-BFGS algorithm |
Input: Start point: , the number of most recent iterations: m, ; Output: Optimal
|
4.4. Infeasible Derivative Control Points Adjustment Method
4.5. Local Replanning Strategy
5. Collision Avoidance Optimization for the Robot Links
- Collision detection between spheres (Case 1): The distance, d, between the centers of two spheres is measured to detect whether the two spheres collide. If , where and are the radii of the two spheres, then the two spheres do not collide.
- Collision detection between a cylinder and a sphere (Case 2): The center of the sphere is projected onto the axis of the cylinder to detect collisions between the cylinder and the sphere. Two cases need to be discussed. First, if the projection of the sphere center is inside the cylinder, the distance, d, between the sphere center and its projection on the cylinder axis is considered as the collision detection distance. If , the cylinder and the sphere do not collide. Second, if the projection of the sphere center is outside the cylinder, the distance, d, between the sphere center and the nearest cylinder end will be used as collision detection distance. If , then no collision occurs.
- Collision detection between cylinders (Case 3): The cylinders are reduced to two axes to detect collisions between two cylinders. Again, two possible cases that need to be discussed. First, if the intersection of the two cylinders axes is inside the first cylinder, the distance, d, between the closest points is used as the collision detection distance. If , the two cylinders do not collide. Second, if the intersection of two cylinders axes is outside the cylinders, then the closest distance is determined by the distance, d, between the ends of the two cylinders. If , then no collision occurs.

6. Simulation and Real-World Experiment Results
6.1. Experimental Settings
6.2. Simulation Experiments
6.2.1. Scenes with a Single Static and Dynamic Obstacle
6.2.2. Scenes with Multiple Static and Dynamic Obstacles
6.2.3. Quantitative Evaluation and Analysis of Simulation Results
6.3. Comparison of Trajectory Optimization
6.4. Real-World Experiments
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| order of the derivative | |
| center of the feasible set | |
| state transition matrix | |
| acceleration control point | |
| input (control) matrix | |
| basis vector | |
| control point span | |
| the i-th control point | |
| close set of node | |
| B-spline curve | |
| points of interest along the robot body | |
| Jacobian matrix | |
| jerk control point | |
| Jacobian of a interest point | |
| blending matrix | |
| contact normal | |
| open set of node | |
| current grid node | |
| end-effector position in the task space | |
| the i-th grid node | |
| goal joints configuration | |
| initial joints configuration | |
| velocity control point | |
| current state of the motion primitive | |
| end-effector goal state | |
| end-effector initial state | |
| the s-th control point span | |
| geometric line segment representation of the i-th link | |
| geometric line segment representation of the k-th link | |
| joint acceleration | |
| discrete step of the control input | |
| replanning horizon size | |
| joint velocity | |
| desired velocity profile generated by the back-end optimization step | |
| repulsion velocity within feasible set | |
| obstacle | |
| any axis in | |
| importance of the trajectory duration T relative to trajectory smoothness | |
| duration | |
| weight factor of the objective function | |
| normalized knot span | |
| coefficient of a polynomial trajectory | |
| search cost objective function | |
| collision cost | |
| feasibility cost | |
| smoothness cost | |
| minimum distance between the i-th control point and obstacles | |
| minimum distance between the k-th link and the i-th link | |
| minimum distance between the link segments and the obstacles | |
| safe distance threshold between the links and obstacles | |
| safe distance threshold of the self-collision | |
| self-collision distance | |
| magnitude of the repulsive force between the i-th control point and the closest obstacle | |
| search cost from the current node to the goal node | |
| penalty function | |
| search cost from the starting node to the current node | |
| k | degree |
| l | discrete factor |
| the -th derivative of a B-spline curve | |
| M | total number of motion primitives |
| number of B-spline knots | |
| minimum distance between points of interest and obstacles | |
| number of B-spline control points | |
| r | degree of a polynomial trajectory |
| polynomial trajectory along each axis () | |
| collision signal | |
| maximum value of control input | |
| repulsive force | |
| w | weight factor of the feasibility penalty function |
| end-effector trajectory in the task space | |
| discretized control input set | |
| discretized control input | |
| control input set | |
| control input | |
| B-spline basis function corresponding to the control point |
References
- Krüger, J.; Lien, T.; Verl, A. Cooperation of human and machines in assembly lines. CIRP Ann. 2009, 58, 628–646. [Google Scholar] [CrossRef]
- Ajoudani, A.; Zanchettin, A.M.; Ivaldi, S.; Albu-Schäffer, A.; Kosuge, K.; Khatib, O. Progress and prospects of the human–robot collaboration. Auton. Robot. 2018, 42, 957–975. [Google Scholar] [CrossRef] [Green Version]
- Haddadin, S.; De Luca, A.; Albu-Schäffer, A. Robot Collisions: A Survey on Detection, Isolation, and Identification. IEEE Trans. Robot. 2017, 33, 1292–1312. [Google Scholar] [CrossRef] [Green Version]
- Villani, V.; Pini, F.; Leali, F.; Secchi, C. Survey on human–robot collaboration in industrial settings: Safety, intuitive interfaces and applications. Mechatronics 2018, 55, 248–266. [Google Scholar] [CrossRef]
- Pairet, È.; Ardón, P.; Mistry, M.; Petillot, Y. Learning generalizable coupling terms for obstacle avoidance via low-dimensional geometric descriptors. IEEE Robot. Autom. Lett. 2019, 4, 3979–3986. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Han, K.; Li, X.; Zhang, S.; Xiong, Y.; Xie, Z. Hybrid Trajectory Replanning-Based Dynamic Obstacle Avoidance for Physical Human-Robot Interaction. J. Intell. Robot. Syst. 2021, 103, 41. [Google Scholar] [CrossRef]
- Flacco, F.; Kröger, T.; De Luca, A.; Khatib, O. A depth space approach to human-robot collision avoidance. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 338–345. [Google Scholar] [CrossRef] [Green Version]
- Nascimento, H.; Mujica, M.; Benoussaad, M. Collision Avoidance in Human-Robot Interaction Using Kinect Vision System Combined With Robot’s Model and Data. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2020; pp. 10293–10298. [Google Scholar] [CrossRef]
- Tulbure, A.; Khatib, O. Closing the loop: Real-time perception and control for robust collision avoidance with occluded obstacles. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 5700–5707. [Google Scholar]
- Lin, H.; Fan, Y.; Tang, T.; Tomizuka, M. Human guidance programming on a 6-DoF robot with collision avoidance. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2676–2681. [Google Scholar] [CrossRef]
- Lin, H.C.; Liu, C.; Fan, Y.; Tomizuka, M. Real-time collision avoidance algorithm on industrial manipulators. In Proceedings of the 2017 IEEE Conference on Control Technology and Applications (CCTA), Maui, HI, USA, 27–30 August 2017; pp. 1294–1299. [Google Scholar] [CrossRef]
- Lacevic, B.; Rocco, P. Kinetostatic danger field—A novel safety assessment for human-robot interaction. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2169–2174. [Google Scholar] [CrossRef]
- Lacevic, B.; Rocco, P.; Zanchettin, A.M. Safety Assessment and Control of Robotic Manipulators Using Danger Field. IEEE Trans. Robot. 2013, 29, 1257–1270. [Google Scholar] [CrossRef]
- Zanchettin, A.M.; Lacevic, B.; Rocco, P. A novel passivity-based control law for safe human-robot coexistence. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 2276–2281. [Google Scholar] [CrossRef]
- Parigi Polverini, M.; Zanchettin, A.M.; Rocco, P. Real-time collision avoidance in human-robot interaction based on kinetostatic safety field. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4136–4141. [Google Scholar] [CrossRef]
- Zucker, M.; Ratliff, N.; Dragan, A.D.; Pivtoraiko, M.; Klingensmith, M.; Dellin, C.M.; Bagnell, J.A.; Srinivasa, S.S. CHOMP: Covariant Hamiltonian optimization for motion planning. Int. J. Robot. Res. 2013, 32, 1164–1193. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Ho, J.; Lee, A.X.; Awwal, I.; Bradlow, H.; Abbeel, P. Finding locally optimal, collision-free trajectories with sequential convex optimization. In Proceedings of the Robotics: Science and Systems, New York, NY, USA, 27 June–1 July 2013; Volume 9, pp. 1–10. [Google Scholar]
- Zanchettin, A.M.; Rocco, P. Motion planning for robotic manipulators using robust constrained control. Control Eng. Practice 2017, 59, 127–136. [Google Scholar] [CrossRef]
- Ragaglia, M.; Zanchettin, A.M.; Rocco, P. Trajectory generation algorithm for safe human-robot collaboration based on multiple depth sensor measurements. Mechatronics 2018, 55, 267–281. [Google Scholar] [CrossRef]
- Qureshi, A.H.; Simeonov, A.; Bency, M.J.; Yip, M.C. Motion Planning Networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2118–2124. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Zhou, X.; Wu, H.; Li, X.; Li, S. Motion Planning of Manipulators for Simultaneous Obstacle Avoidance and Target Tracking: An RNN Approach With Guaranteed Performance. IEEE Trans. Ind. Electron. 2022, 69, 3887–3897. [Google Scholar] [CrossRef]
- Song, Q.; Li, S.; Bai, Q.; Yang, J.; Zhang, A.; Zhang, X.; Zhe, L. Trajectory Planning of Robot Manipulator Based on RBF Neural Network. Entropy 2021, 23, 1207. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Jia, Q.; Huang, Z.; Wang, R.; Fei, J.; Chen, G. Reinforcement Learning-Based Reactive Obstacle Avoidance Method for Redundant Manipulators. Entropy 2022, 24, 279. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Qu, D.; Xu, F.; Zou, F.; Song, J.; Jia, K. A Human-Robot Collaboration Framework Based on Human Motion Prediction and Task Model in Virtual Environment. In Proceedings of the 2019 IEEE 9th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Suzhou, China, 29 July–2 August 2019; pp. 1044–1049. [Google Scholar] [CrossRef]
- Hauser, K. On responsiveness, safety, and completeness in real-time motion planning. Auton. Robot. 2012, 32, 35–48. [Google Scholar] [CrossRef]
- Sun, W.; Patil, S.; Alterovitz, R. High-frequency replanning under uncertainty using parallel sampling-based motion planning. IEEE Trans. Robot. 2015, 31, 104–116. [Google Scholar] [CrossRef] [Green Version]
- Otte, M.; Frazzoli, E. RRTX: Asymptotically optimal single-query sampling-based motion planning with quick replanning. Int. J. Robot. Res. 2016, 35, 797–822. [Google Scholar] [CrossRef]
- Völz, A.; Graichen, K. A Predictive Path-Following Controller for Continuous Replanning With Dynamic Roadmaps. IEEE Robot. Autom. Lett. 2019, 4, 3963–3970. [Google Scholar] [CrossRef]
- Pupa, A.; Arrfou, M.; Andreoni, G.; Secchi, C. A safety-aware kinodynamic architecture for human-robot collaboration. IEEE Robot. Autom. Lett. 2021, 6, 4465–4471. [Google Scholar] [CrossRef]
- Covic, N.; Lacevic, B.; Osmankovic, D. Path Planning for Robotic Manipulators in Dynamic Environments Using Distance Information. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4708–4713. [Google Scholar] [CrossRef]
- Liu, S.; Watterson, M.; Mohta, K.; Sun, K.; Bhattacharya, S.; Taylor, C.J.; Kumar, V. Planning Dynamically Feasible Trajectories for Quadrotors Using Safe Flight Corridors in 3-D Complex Environments. IEEE Robot. Autom. Lett. 2017, 2, 1688–1695. [Google Scholar] [CrossRef]
- Ding, W.; Gao, W.; Wang, K.; Shen, S. Trajectory Replanning for Quadrotors Using Kinodynamic Search and Elastic Optimization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7595–7602. [Google Scholar] [CrossRef] [Green Version]
- Usenko, V.; von Stumberg, L.; Pangercic, A.; Cremers, D. Real-time trajectory replanning for MAVs using uniform B-splines and a 3D circular buffer. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 215–222. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Gao, F.; Pan, J.; Shen, S. Robust Real-time UAV Replanning Using Guided Gradient-based Optimization and Topological Paths. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Online, 31 May–31 August 2020; pp. 1208–1214. [Google Scholar] [CrossRef]
- Zhou, B.; Pan, J.; Gao, F.; Shen, S. RAPTOR: Robust and Perception-Aware Trajectory Replanning for Quadrotor Fast Flight. IEEE Trans. Robot. 2021, 37, 1992–2009. [Google Scholar] [CrossRef]
- Kappler, D.; Meier, F.; Issac, J.; Mainprice, J.; Cifuentes, C.G.; Wüthrich, M.; Berenz, V.; Schaal, S.; Ratliff, N.; Bohg, J. Real-time perception meets reactive motion generation. IEEE Robot. Autom. Lett. 2018, 3, 1864–1871. [Google Scholar] [CrossRef] [Green Version]
- Meguenani, A.; Padois, V.; Silva, J.D.; Hoarau, A.; Bidaud, P. Energy based control for safe human-robot physical interaction. In 2016 International Symposium on Experimental Robotics, Proceedings of the International Symposium on Experimental Robotics, Tokyo, Japan, 3–6 October 2016; Springer: Cham, Switzweland, 2016; pp. 809–818. [Google Scholar]
- Han, L.; Gao, F.; Zhou, B.; Shen, S. Fiesta: Fast incremental euclidean distance fields for online motion planning of aerial robots. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 4423–4430. [Google Scholar]
- Kant, K.; Zucker, S.W. Toward efficient trajectory planning: The path-velocity decomposition. Int. J. Robot. Res. 1986, 5, 72–89. [Google Scholar] [CrossRef]
- Liu, S.; Atanasov, N.; Mohta, K.; Kumar, V. Search-based motion planning for quadrotors using linear quadratic minimum time control. In Proceedings of the 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2872–2879. [Google Scholar]
- Zhou, B.; Gao, F.; Wang, L.; Liu, C.; Shen, S. Robust and efficient quadrotor trajectory generation for fast autonomous flight. IEEE Robot. Autom. Lett. 2019, 4, 3529–3536. [Google Scholar] [CrossRef] [Green Version]
- Mueller, M.W.; Hehn, M.; D’Andrea, R. A Computationally Efficient Motion Primitive for Quadrocopter Trajectory Generation. IEEE Trans. Robot. 2015, 31, 1294–1310. [Google Scholar] [CrossRef]
- Ding, W.; Gao, W.; Wang, K.; Shen, S. An Efficient B-Spline-Based Kinodynamic Replanning Framework for Quadrotors. IEEE Trans. Robot. 2019, 35, 1287–1306. [Google Scholar] [CrossRef] [Green Version]
- Piegl, L.; Tiller, W. The NURBS Book; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- de Boor, C. On calculating with B-splines. J. Approx. Theory 1972, 6, 50–62. [Google Scholar] [CrossRef] [Green Version]
- Qin, K. General matrix representations for B-splines. In Proceedings of the Pacific Graphics’ 98, Sixth Pacific Conference on Computer Graphics and Applications (Cat. No. 98EX208), Singapore, 26–29 October 1998; pp. 37–43. [Google Scholar]
- Zhou, X.; Wang, Z.; Ye, H.; Xu, C.; Gao, F. Ego-planner: An esdf-free gradient-based local planner for quadrotors. IEEE Robot. Autom. Lett. 2020, 6, 478–485. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Distance transforms of sampled functions. Theory Comput. 2012, 8, 415–428. [Google Scholar] [CrossRef]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Chitta, S.; Sucan, I.; Cousins, S. MoveIt! [ROS Topics]. IEEE Robot. Autom. Mag. 2012, 19, 18–19. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Source of Danger | Obstacle Representation | Real-Time | Convergence to Goal | Constraint Conditions (Safety, Smoothness, Dynamic Feasibility) | |
|---|---|---|---|---|---|---|
| Potential field | [7,8] | Obstacle /human | Depth point | Y | N | Safety |
| [9] | Obstacle /human | Point cloud | Y | Y | Safety | |
| [10] | Obstacle /human | Predefined position | Y | N | Safety | |
| Danger field | [12,13,14] | Robot | Linear | Y | N | Safety |
| Safety field | [15] | Obstacle /human | Triangular mesh | Y | N | Safety |
| Optimization- based | [16] | Obstacle | 3D voxel grids | N | Y | Safety, Smoothness |
| [19] | Human | Human skeleton swept volumes | N | N | Safety | |
| Learning- based | [20,23] | Obstacle | Predefined position | N | N | Safety |
| Replanning- based | [26] | Obstacle | Predefined position | Y (Additional GPU) | Y | Safety |
| [27] | Obstacle | Predefined position | Y | Y | Safety | |
| [29,30] | Obstacle /human | Predefined position | Y | Y | Safety | |
| Ours | Obstacle /human | 3D voxel grids | Y | Y | Safety, Smoothness, Dynamic feasibility | |
| Link 1 | Link 2 | Link 3 | Link 4 | Link 5 | Link 6 | |
| Link 1 | N | N | M | M | M | M |
| Link 2 | N | N | M | M | M | |
| Link 3 | N | N | M | M | ||
| Link 4 | N | N | N | |||
| Link 5 | N | N | ||||
| Link 6 | N |
| Succ. Rate (%) | Single Iteration Time (s) | Traj. Time (s) | Path Length (m) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Max | Std | Mean | Max | Std | Mean | Max | Std | |||
| Scenario 1 | RRTX | 100% | 0.179 | 0.287 | 0.0273 | 7.947 | 9.304 | 3.182 | 2.149 | 2.731 | 1.353 |
| DRGBT | 100% | 0.0117 | 0.162 | 0.0148 | 5.914 | 6.794 | 2.891 | 2.0126 | 2.516 | 1.263 | |
| Ours | 100% | 0.00562 | 0.0104 | 0.000734 | 3.076 | 4.082 | 0.0849 | 1.014 | 1.204 | 0.483 | |
| Scenario 2 | RRTX | 65% | 0.381 | 0.422 | 0.0329 | 20.074 | 23.634 | 4.551 | 2.749 | 3.338 | 1.775 |
| DRGBT | 92% | 0.1757 | 0.253 | 0.0218 | 16.237 | 20.525 | 4.272 | 2.6887 | 3.058 | 1.355 | |
| Ours | 100% | 0.00601 | 0.0559 | 0.00887 | 3.211 | 4.116 | 0.103 | 1.072 | 1.211 | 0.479 | |
| Scenario 3 | RRTX | 87% | 0.364 | 0.449 | 0.0299 | 15.886 | 17.376 | 3.313 | 2.713 | 3.134 | 1.544 |
| DRGBT | 100% | 0.2006 | 0.3662 | 0.0187 | 13.694 | 16.014 | 3.191 | 2.6065 | 3.724 | 1.346 | |
| Ours | 100% | 0.00573 | 0.0113 | 0.00081 | 3.128 | 4.026 | 0.0957 | 1.016 | 1.207 | 0.425 | |
| Scenario 4 | RRTX | 21% | 0.571 | 0.64 | 0.3011 | 18.633 | 23.912 | 5.047 | 3.184 | 4.267 | 1.774 |
| DRGBT | 85% | 0.3754 | 0.4563 | 0.2417 | 17.946 | 22.843 | 5.296 | 3.0795 | 4.096 | 1.536 | |
| Ours | 94% | 0.00639 | 0.0715 | 0.0128 | 3.371 | 4.1299 | 0.141 | 1.075 | 1.259 | 0.498 | |
| Succ. Rate (%) | Avg. Single Com. Time (s) | Mean Smoothness (m2/s5) | Total Optimization Time (s) | |
|---|---|---|---|---|
| CHOMP | 217/300 | 0.0567 | 158.91 | 5.574 |
| TrajOpt | 249/300 | 0.0692 | 97.67 | 1.942 |
| Ours | 300/300 | 0.000216 | 12.71 | 0.0635386 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Qu, D.; Xu, F.; Du, Z.; Jia, K.; Liu, M. An Efficient Online Trajectory Generation Method Based on Kinodynamic Path Search and Trajectory Optimization for Human-Robot Interaction Safety. Entropy 2022, 24, 653. https://doi.org/10.3390/e24050653
Liu H, Qu D, Xu F, Du Z, Jia K, Liu M. An Efficient Online Trajectory Generation Method Based on Kinodynamic Path Search and Trajectory Optimization for Human-Robot Interaction Safety. Entropy. 2022; 24(5):653. https://doi.org/10.3390/e24050653
Chicago/Turabian StyleLiu, Hongyan, Daokui Qu, Fang Xu, Zhenjun Du, Kai Jia, and Mingmin Liu. 2022. "An Efficient Online Trajectory Generation Method Based on Kinodynamic Path Search and Trajectory Optimization for Human-Robot Interaction Safety" Entropy 24, no. 5: 653. https://doi.org/10.3390/e24050653